
- 1Vue项目中代码规范(Prettier + ESLint)_vue代码格式化插件
- 2Docker学习-04-容器管理工具 Docker架构及部署_docker管理器
- 31024与自己做爱做的事情
- 4计算机视觉方面的三大顶级会议:ICCV,CVPR,ECCV(统称ICE)
- 5Spring-Boot (二) application.properties配置文件内容_springboot中application配置内容
- 6贝塞尔曲线曲面原理及推导过程_贝塞尔曲面
- 7完美解决MSSQL安装问题“Polybase要求安装Oracle JRE 7更新51(64位)”方案
- 8CNN 模型所需的计算力(FLOPs)和参数(parameters)_3d-cnn作为预测模型需要确定那些模型参数
- 9解决安装Fiddler后无法上网的问题_安装fiddler后电脑无法上网
- 10【干货】requests的使用方法_requests.mount
人工智能,机器学习,强化学习傻傻分不清?_feature和label的区别
赞
踩
机器学习
近十年来人工智能越来越热门了,在我们的日常学习中,我们经常听到一大堆专有名词,像人工智能,机器学习,监督学习,非监督学习,深度学习,强化学习这些,那它们之间存在什么样的关系呢?
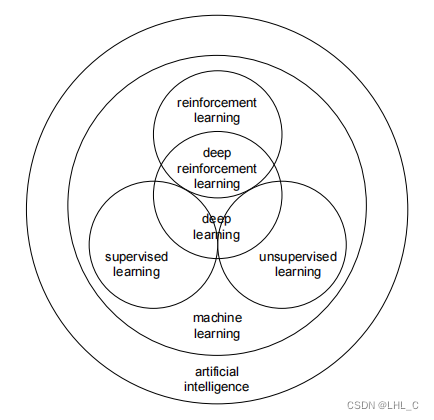
通过上图,我们可以看到其实都是学习,那么什么是学习?
学习的整个过程应该包含输入,处理,输出,反思。比如说,读书,思考,做笔记,应用到实际,再反思。
学:输入。习:输出实践。
我们所看到的机器学习,其实就是让机器去学习,当然我这里说的是一句废话。
简单来说,就是给我们机器输入一些数据,机器通过某种方式对数据进行运算,然后输出结果,根据这个结果就可以解决预测二和分类等问题。
为什么要学习
人类要生存, 每时每刻遇到的问题和发生的事件,都是不确定的未知的。 无法提前给出所有问题的解决办法, 我们需要学习出一种解决问题的模型或者说是思路,套用这个思路就可以解决未知的问题。
下面我们来举个栗子吧! 每天我都想多睡一会, 所以我想预测小车到达小区门口的时间。
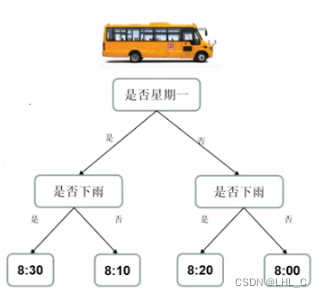
通过旧的问题和答案, 学习出来的规律. 应用规律去解决新的问题,得到新的预测。
我们预测校车到达时间, 7:30出发,从A—>B, 预测到达B地的时间. 第一次乘车, 我们预测可能不太准, 但是随着乘车经验的增加, 我们对这条线路越来越书序, 预测就会越来越准确。
机器学习
让机器具有自我学习的能力,程序的执行结果跟机器获取的数据量有关,增加新的输入,可以生成新的模型,最终程序执行的结果也就会发生变化,就像我们人只要不停的接受新的知识,我们就会对事物有新的认知。
机器学习实际上包含很多熟悉方法,会涉及到统计学,概率论,信息论等知识。利用已知的数据,创建一种模型,最终利用这种模型进行相应的预测。
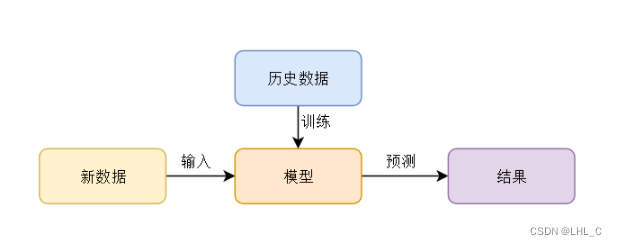
机器学习:用大量数据进行训练,获取到一个数据模型,预测就是应用训练的模型,来解决一个未知的问题。
学习方法
那么我们如何去学习机器学习呢?
我们应该尝试去理解原理, 通过简单的输入与输出, 理解数学背后的原理, 我们是为了解决实际问题,才使用数学的,我们应当避免抽象数学以及理论数学。
对于数学公式, 用实际案例去理解计算过程,不畏惧算法,不畏惧论文,不对公式进行数学证明, 靠编写程序直接盐城。
机器学习的步骤:
- 确定与问题相关的数据**(明确输入)**
- 收集与问题相关的数据**(数据准备,学)**
- 分析预测结果的类型**(分类,回归,是预测天气,还是判断是或否)**
- 根据预测结果的类型,选择合适的算法**(套路)**,找到输入和输出之间的关系
- 用这个算法去解决新的问题**(习)**
市面上很多机器学习教程都是从第3步开始的,实际开发中1,2俩步同样是非常重要的。
理解常用术语
feature和label
feature是特征是自变量。label是标签的意思,是因变量
用我们最熟悉的直线方程y = mx + b来解释的话,其中x是特征,它是自变量,是函数的输入,y是因变量,是输出的结果。
feature:自变量,输入
label:因变量,输出
f(feature) = label <===> f(x) = y
举个栗子吧:f(海啸等级) = 经济损失
俩大问题
机器学习解决的是两大类问题,一个是分类问题,另一个是回归。
分类问题:classification,数据结果往往是离散的。
- 根据学习努力情况,判断是否通过考试。
- 根据email内容,判断是否为垃圾邮件。
回归问题:regression,数据往往是连续的。
- 根据车的品牌,车龄,型号,预测车的价值。
- 根据每天的卡路里以及运动量,预测一周后的体重。
- 基于树的直径,预测树的年龄。
注意事项
- 输入输出,就是自变量和因变量,对应的faeature和label。
- 数据集必须是规范的,格式统一的,方便计算机处理。
- 分类的问题答案有限的,可以理解成选择题和判断题,回归的问题,答案不能用简单的分类来描述。
- 确定feature和label之间的关系,有无数种的算法,每种算法都有自己的优缺点。
- 根据预测的情况,我们可能需要重新调整算法和生成的模型。

