
- 1技术管理成长计划(一):角色认知及转身_主计划角色认知
- 2深度学习进阶之路 - 从迁移学习到强化学习_深度学习和学习进阶的本质
- 3Hadoop的MapReduce详解_hadoop mapreduce
- 4web前端顶岗实习总结报告_web前端实习报告
- 5使用 Langchain 和 Ollama 的 PDF 聊天机器人分步指南
- 62019年全国电子设计竞赛H题电磁炮之定点打击_电赛电磁炮代码
- 7MySQL常见报错及解决方案_invalid default value for 'gender
- 8【Docker】搭建一个媒体服务器插件后端API服务 - MetaTube
- 9基于单片机的教室智能照明台灯控制系统的设计与实现_基于51单片机的教室智能照明控制设计
- 10如何用JAVA如何实现Word、Excel、PPT在线前端预览编辑的功能?_前端在页面上编辑ppt和word的插件
2024软件学院创新项目实训--大模型及微调相关知识_大模型实验项目
赞
踩
整体方案设计与规划
我们要做的项目是基于InternLM的考研政治题库系统,
项目灵感来源于我们组内成员都有考研需求,我们希望在面对没有答案解析的题目时能够有一个软件基于现有的知识进行分析给出一个合理的解释,于是我们决定做一款基于大模型的知识题库系统,旨在为考研提供方便。
文科题目“内容多,变化少”的特性,能够完美利用大模型能够处理大量数据、并进行简单思考的优势。于是我们决定以考研政治为主题,以市面上主流的语言大模型为基础,对其进行训练微调,进行独有的知识题库的构建,并应用所学知识搭建页面,使整个系统更加便捷、美观。
项目目标:能够正确回答单选题,多选题,并给出合理的答案解析。
对于材料分析大题能够给出合理的答案
本篇文章是我对轻量化大模型internLM相关知识进行学习之后的一些总结:旨在记录创新项目实训过程中对大模型的学习,方便为后续开发工作打下基础。
InternLM
一、开发过程
2023.06.07 InternLM 千亿参数大模型首次发布
2023.07.06 InernLM 千亿参数大模型全面升级:支持 8k 上下文、26 种语言;全面开源支持商用;同时发布 InternLM-7B 模型
2023.08.14 书生·万卷 1.0 多模态预训练语料库开源发布
2023.08.21 发布对话版模型 InternLM-Chat-7B v1.1 发布,开源智能体框架 Lagent
2023.08.28 InternLM 千亿参数模型参数量升级至 123B
2023.09.20 增强版 InternLM-20B 开源,开源工具链 xtuner 全面升级
二、系列模型
轻量级:InternLM-7B,70亿模型参数,10000亿训练token数据,支持 8k 上下文窗口长度,具备通用工具调用能力,支持多种工具调用模板
中量级:InternLM-20B,200亿参数规模,4k 训练语境长度,推理时可外推至16k
重量级:InternLM-123B,1230亿参数,各项性能指标全面升级
InternLM-20B 性能指标:全面领先同量级开源模型,甚至达到 Llama2-70B 水平

三、全链条开源体系
3.1 开源数据集
书生·万卷 1.0:2TB 数据,涵盖多种模态与任务。
- 文本数据:50亿个文档,数据量超 1TB
- 图像-文本数据集:超2200万个文件,数据量超 140G
- 视频数据:超1000个文件,数据量超 900G
数据特点:
- 多模态融合:包含文本、图像和视频等多模态数据,涵盖科技、文学、媒体、教育和法律等多个领域。对模型的知识内容、逻辑推理和泛化能力效果有显著提升
- 精细化处理:数据经过筛选、文本提取、格式标准化、数据过滤和清洗(基于规则和模型)、多尺度去重和数据质量评估等精细数据处理环节
- 价值观对齐:数据内容和主流中国价值观对齐,通过算法和人工评估结合提高语料库的纯净度
OpenDataLab:开放数据平台

3.2 预训练
并行训练,速度可达到 3600 tokens/sec/gpu

3.3 微调
XTuner:支持全量微调,LoRA 和 QLoRA 等低成本微调。
针对下游应用数据微调的两种方式:
- 增量续训:
- 场景:让基座模型学习一些新的领域知识
- 训练集:领域数据集,文本、书籍、代码等
- 有监督微调:
- 场景:让模型学会理解和遵循各种指令,或注入少量领域知识
- 训练集:高质量的对话、问答数据
显存占用:

InternLM-7B QLoRA 微调,2048 输入长度,显存占用 11.9G,这真是人类之光
3.4 部署
LMDeploy:推理性能达到每秒生成 2000+ tokens

3.5 评测
目前国内外评测体系:

OpenCompass 评测平台:80套评测集,40万道题目


中文大模型评测榜单:https://opencompass.org.cn/leaderboard-llm
自家模型不进前三,一看就很公平公正,不过为什么 InternLM-20B 系列模型整体不如 Intern-7B 系列呢。
3.6 应用
大模型微调
在学习了Fine-Tuning相关知识后,我认识到大模型微调是利用特定领域的数据集对已预训练的大模型进行进一步训练的过程。它旨在优化模型在特定任务上的性能,使模型能够更好地适应和完成特定领域的任务。

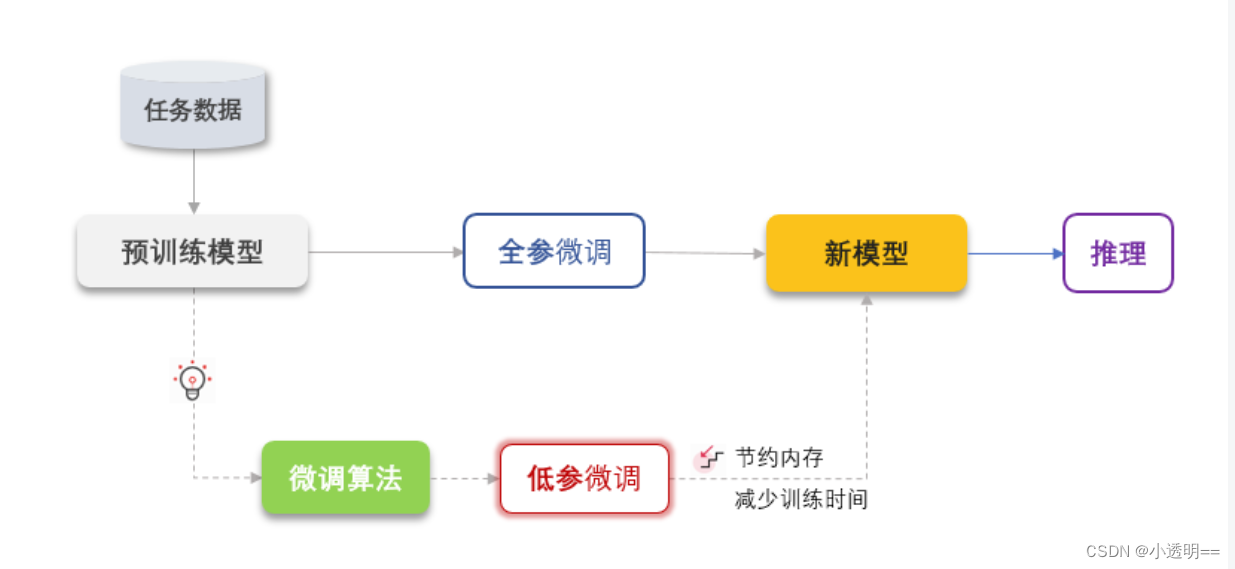
Xtuner

我们使用的微调工具为Xtuner,XTuner是一个高效、灵活、全能的轻量化大模型微调工具库。
- 支持大语言模型 LLM、多模态图文模型 VLM 的预训练及轻量级微调。XTuner 支持在 8GB 显存下微调 7B 模型,同时也支持多节点跨设备微调更大尺度模型(70B+)。
- 2.支持 QLoRA、LoRA、全量参数微调等多种微调算法,支撑用户根据具体需求作出最优选择。

总结
该文章总结我对大模型InternLM相关知识的学习,从中我认识了大模型的基本观念,了解到其广泛应用,并对大模型的微调fine-tunning(概念、方法以使用工具)进行了学习,有助于后续工作小组工作的进行。

