
- 1外包公司值不值得去?_现在外包值得做吗
- 2【已解决】ModuleNotFoundError: No module named ‘torch._six‘_modulenotfounderror: no module named 'torch
- 3大数据工程师简历_成为大数据工程师所需的技能
- 4半球展开图_棱锥的展开图.ppt
- 5ECMAScript 与 JavaScript的联系 以及为什么会有浏览器兼容的问题?_ecmascript 兼容性
- 6推荐项目:CLIP-ONNX - 加速CLIP推理速度的神器!
- 7MyBatis——MyBatis实现多表查询_mybatis多表查询
- 8老徐WEB:最简单详细的轮播图原理和制作过程(一)_最简单的网页轮播图
- 9LoRA中值得注意的微调细节_lora微调
- 10Python 实战之淘宝手机销售分析(数据清洗、可视化、数据建模、文本分析)_数据可视化手机价位图的代码
【NLP入门】使用pytorch搭建第一个神经网络_搭建一个nlp
赞
踩
随着人工智能技术的不断进步,特别是大模型在自然语言处理领域的广泛应用,使得越来越多的人开始积极学习自然语言处理(NLP)。本文将为你揭示大模型在NLP领域的核心代码,这些代码是NLP应用的基石,没有涉及过多的复杂理论知识。我们将通过具体的示例和代码来解释这些大模型的工作原理和实现方式,让你轻松掌握NLP的实践技能。
1.pytorch
安装
用pip安装
pip3 install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cpu
查看是否按装成功
Mac用户
- import torch
- import math
- # this ensures that the current MacOS version is at least 12.3+
- print(torch.backends.mps.is_available())
- # this ensures that the current current PyTorch installation was built with MPS activated.
- print(torch.backends.mps.is_built())
Windows用户
- import torch
- print(torch.backends.cuda.is_built())
代码如果能正常运行则安装成功。
pytorch常用操作
1.使用GPU加速
- #Mac用户要使用device = torch.device("mps")
- device = torch.device("cuda")
- x = torch.linspace(-math.pi, math.pi, 2000, device=device, dtype=torch.float)
- y = torch.sin(x)
- print(y)
2.创建一个没有初始化的矩阵
x = torch.empty(3,3)3.创建一个有初始化的随机矩阵
x = torch.rand(3,3)4.创建一个全零矩阵并可指定数据元素的类型为long。
添加了device后则在GPU上运算。
- x = torch.zeros(3,3,dtype=torch.long,device= torch.device("mps"))
- print(x)
-
5.直接通过数据创建张量
tensor是一个多维数组,类似于numpy中的数组,但它是基于GPU加速的。
- x = torch.tensor([2,3,4])
- print(x)
6.通过已有的一个张量创建相同尺寸的新张量
- # 利用news_methods方法得到一个张量
- x=torch.tensor([1,2,3])
- x = x.new_ones(5, 3, dtype=torch.double)
- print(x)
-
- # 利用randn_like方法得到相同张量尺寸的一个新张量, 并且采用随机初始化来对其赋值
- y = torch.randn_like(x, dtype=torch.float)
- print(y)
7.得到张量的尺寸:
print(x.size())8.加法操作:
- #first method
- x = torch.tensor([1,2,3])
- print(x+1)
- #second method
- y=torch.tensor([1,1,1])
- print(torch.add(x,y))
- #third method
-
- out = torch.empty(3,device=torch.device("mps"))
-
- torch.add(x,y,out = out)
- print(out)
9.第四种加法方式: in-place (原地置换)
- #等价于 y=y+x
- y.add_(x)
- print(y)
10.改变张量的形状: torch.view()
- x= torch.tensor([1,2,3,4])
- y= x.view(4,1)
- print(y.size())
关于Torch Tensor和Numpy array之间的相互转换
Torch Tensor和Numpy array共享底层的内存空间, 因此改变其中一个的值, 另一个也会随之被改变
- ## tensor -> numpy
- a = torch.ones(5,5)
- print(a)
- b= a.numpy()
- print(b)
- ## numpy -> tensor
- a= torch.from_numpy(b)
- print(a)
打开autograd
开启autograd后,在后续需要计算梯度的地方会自动计算
- a = torch.randn(3,4,requires_grad=True)
- print(a)
关闭autograd
可以通过.detach()获得一个新的Tensor, 拥有相同的内容但不需要自动求导.
- ##first method
- a = torch.randn(3,3,requires_grad=True)
- print(a.requires_grad)
- b= a.detach()
- print(b.requires_grad)
通过代码块的限制来停止自动求导.
-
- ##second method
- with torch.no_grad():
- print((a**2).requires_grad)
构建第一个神经网络类
先看一下完整代码
- # 定义一个简单的网络类
- class Net(nn.Module):
-
- def __init__(self):
- super(Net, self).__init__()
- # 定义第一层卷积神经网络, 输入通道维度=1, 输出通道维度=6, 卷积核大小3*3
- self.conv1 = nn.Conv2d(1, 6, 3)
- # 定义第二层卷积神经网络, 输入通道维度=6, 输出通道维度=16, 卷积核大小3*3
- self.conv2 = nn.Conv2d(6, 16, 3)
- # 定义三层全连接网络
- self.fc1 = nn.Linear(16 * 6 * 6, 120)
- self.fc2 = nn.Linear(120, 84)
- self.fc3 = nn.Linear(84, 10)
-
- def forward(self, x):
- # 在(2, 2)的池化窗口下执行最大池化操作
- x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
- x = F.max_pool2d(F.relu(self.conv2(x)), 2)
- x = x.view(-1, self.num_flat_features(x))
- x = F.relu(self.fc1(x))
- x = F.relu(self.fc2(x))
- x = self.fc3(x)
- return x
-
- def num_flat_features(self, x):
- # 计算size, 除了第0个维度上的batch_size
- size = x.size()[1:]
- num_features = 1
- for s in size:
- num_features *= s
- return num_features

名词解释
1.卷积层
卷积运算的目的是提取输入的不同特征。第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网络能从低级特征中迭代提取更复杂的特征。
卷积运算
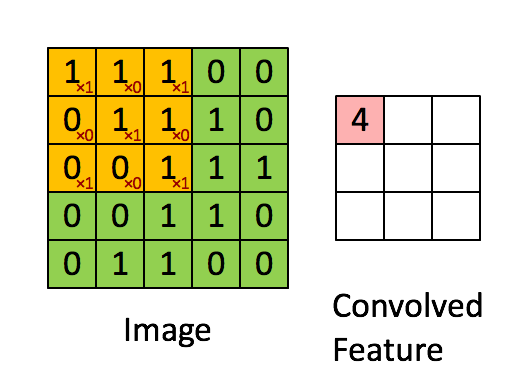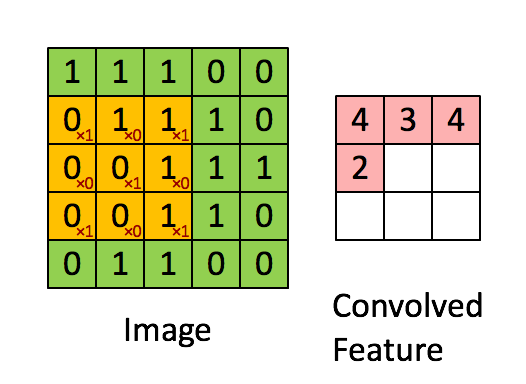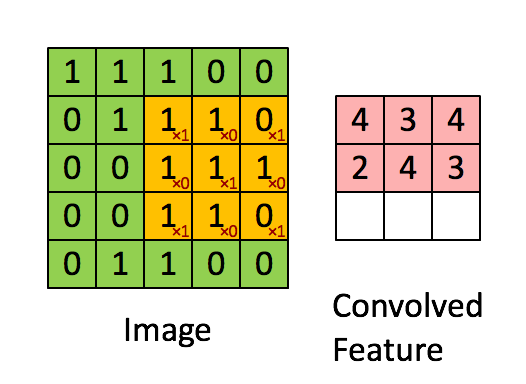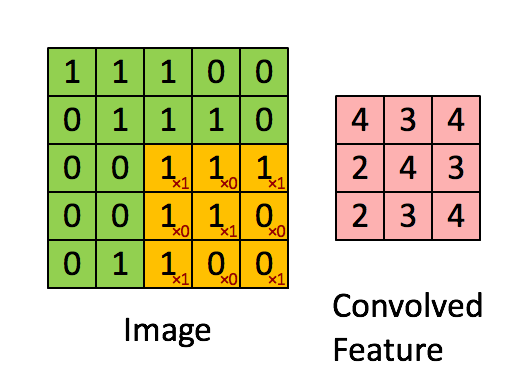
假如我们拥有一个6x6的灰度图,矩阵如下图表示,在矩阵右边还有一个3x3的矩阵。我们称之为过滤器(filter)或核
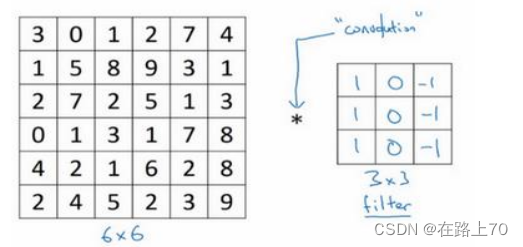
卷积核先从左上角开始进行卷积运算,蓝色矩阵每个小个子的左上角的数字就是过滤器对应位置上的数字,将每个格子的两个数字相乘:
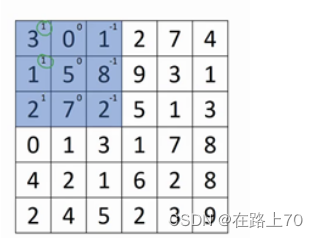
然后将得到的矩阵所有元素相加,即3+1+2+0+0+0+(-1)+(-8)+(-2)= -5,

然后将这个值放到新的矩阵的左上角,然后再按照从左到右从上到下的顺序依次进行相同操作,最后的新的矩阵是一个4*4的矩阵。
规律:n*n维的矩阵经过一个f*f过滤器后,得到一个(n-f+1)*(n-f+1)维度的新矩阵。最终经过卷积得到的图像,我们称之为特征图(Feature Map)
2.池化层
对于一个32x32像素的图像,假设我们使用400个3x3的过滤器提取特征,每一个过滤器和图像卷积都会得到含有 (32-3 + 1) × (32 - 3 + 1) = 900 个特征的feature map,由于有 400 个过滤器,所以每个样例 (example) 都会得到 900 × 400 = 360000 个特征。而如果是96x96的图像,使用400个8x8的过滤器提取特征,最终得到一个样本的特征个数为 3168400。对于如此大的输入,训练难度大,也容易发生过拟合。池化的主要目的是降维,即在保持原有特征的基础上最大限度地将数组的维数变小。
为了减少下一个卷积层的输入,引入了采样层(也叫池化层),采样操作分为最大值采样(Max pooling),平均值采样(Mean pooling)。
池化层是模仿人的视觉系统对数据进行降维,用更高层次的特征表示图像常见的池化层是一种形式的降采样,有多种不同形式的非线性池化函数,而其中“最大池化(Max pooling)”是最为常见的,它是将输入的图像划分为若干个矩形区域,对每个子区域输出最大值,这种机制能够有效地使模型更加关注是否存在某些特征而不是特征具体的位置。池化层会不断地减小数据的空间大小,因此参数的数量和计算量也会下降,这在一定程度上也控制了过拟合。通常来说,CNN的卷积层之间都会周期性地插入池化层。
举个例子,我们用3x3的过滤器以1为步长去扫描图像,每次将重叠的部分的最大值提取出来,作为这部分的特征,过程如下:

我们也可以使用2x2的过滤器。以2为步长进行特征值的提取。最终得到的图像长度和宽度都缩小一半:
全连接层
全连接层通常出现在卷积神经网络的最后几层中,用来对前面提取到的特征做加权和,用来把前边提取到的特征综合起来。。全连接层中的每一个结点都与上一层的所有结点相连,其输出的每个值都是根据上一层所有神经元的输出来计算的。全连接层一般采用ReLU或sigmoid等非线性函数作为激活函数,以增加模型的表达能力
在经过几次卷积和池化的操作之后,卷积神经网络的最后一步是全连接层,全连接层的个数可能不止一个: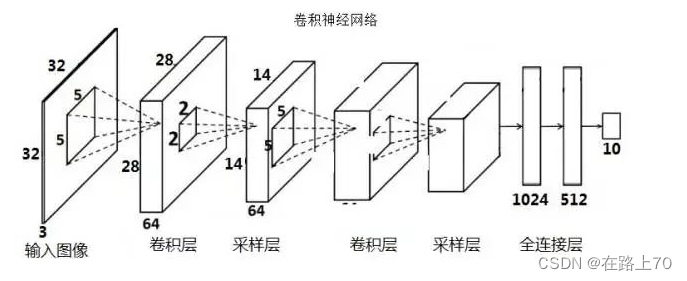
激活函数
卷积神经网络(CNN)中常用的激活函数包括以下几种:
Sigmoid函数:Sigmoid函数是一个典型的逻辑函数,用于将输入值映射到0和1之间,其数学表达式为sigmoid(x)=1/(1+exp(-x))。由于Sigmoid函数具有连续、可导的特性,因此在训练过程中,可以利用反向传播算法对权重进行梯度下降更新。但是,Sigmoid函数在输入值非常大或非常小的时候,会出现梯度消失的问题。
ReLU函数:ReLU(Rectified Linear Unit)函数是一种常用的激活函数,其数学表达式为ReLU(x)=max(0,x)。ReLU函数的优点在于计算速度快,而且不会出现梯度消失的问题。在训练过程中,ReLU函数可以有效地提高网络的收敛速度。但是,ReLU函数在输入值为负数时,会出现梯度为0的问题,这可能会导致一些神经元无法被激活。
Tanh函数:Tanh函数是一种改进的Sigmoid函数,其数学表达式为tanh(x)=2/(1+exp(-2x))-1。Tanh函数的输出值范围为-1到1之间,相对于Sigmoid函数而言,Tanh函数的梯度更大,因此在训练过程中可以更快地收敛。但是,Tanh函数仍然存在梯度消失的问题。
Softmax函数:Softmax函数常用于多分类问题中,其数学表达式为softmax(x)i=exp(x_i)/∑j^n(exp(x_j))。Softmax函数的输出值为概率值,总和为1。在训练过程中,Softmax函数可以使得网络的输出值具有概率分布的特性。
构建神经网络类
1.导入必要的库
-
torch: PyTorch库,一个用于深度学习的开源库。 -
torch.nn: PyTorch的神经网络模块,提供了构建神经网络所需的层。 -
torch.nn.functional: PyTorch的功能模块,提供了一些函数,可以在神经网络中应用。- # 导入若干工具包
- import torch
- import torch.nn as nn
- import torch.nn.functional as F
2.定义神经网络类:
Net是一个继承自nn.Module的类,它定义了一个简单的卷积神经网络。nn.Module是所有神经网络模块的基类,你的网络结构需要继承这个类并重写__init__和forward方法
-
初始化方法:
-
在
__init__方法中,定义了网络的层。这些层包括两个卷积层和三个全连接层。 -
nn.Conv2d是卷积层,其中参数1是输入通道数,参数2是输出通道数,参数3是卷积核的大小(这里是3x3)。 -
全连接层使用
nn.Linear实现,其中参数1是输入特征数,参数2是输出特征数。
-
- class Net(nn.Module):
-
- def __init__(self):
- super(Net, self).__init__()
- # 定义第一层卷积神经网络, 输入通道维度=1, 输出通道维度=6, 卷积核大小3*3
- self.conv1 = nn.Conv2d(1, 6, 3)
- # 定义第二层卷积神经网络, 输入通道维度=6, 输出通道维度=16, 卷积核大小3*3
- self.conv2 = nn.Conv2d(6, 16, 3)
- # 定义三层全连接网络
- self.fc1 = nn.Linear(16 * 6 * 6, 120)
- self.fc2 = nn.Linear(120, 84)
- self.fc3 = nn.Linear(84, 10)
-
前向传播方法:
-
forward方法定义了输入数据通过网络的方式。它首先通过两个卷积层和最大池化层,然后将数据展平并通过三个全连接层。 -
F.relu是ReLU激活函数,用于添加非线性特性。 -
F.max_pool2d是最大池化层,用于减小空间维度(这里是2x2和2)。 -
展平操作
x.view(-1, self.num_flat_features(x))将数据的维度从 (batch_size, channels, height, width) 变为 (batch_size, channelsheightwidth)。
-
- def forward(self, x):
- # 在(2, 2)的池化窗口下执行最大池化操作
-
- x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
-
- x = F.max_pool2d(F.relu(self.conv2(x)), 2)
-
- x = x.view(-1, self.num_flat_features(x))
-
- x = F.relu(self.fc1(x))
- x = F.relu(self.fc2(x))
- x = self.fc3(x)
- return x
-
计算全连接层的输入维度:
-
num_flat_features方法计算了全连接层的输入维度。它通过计算卷积操作后的特征图大小(除了batch size)并计算其乘积来得到总的特征数。
-
- def num_flat_features(self, x):
- # 计算size, 除了第0个维度上的batch_size
- size = x.size()[1:]
- num_features = 1
- for s in size:
- num_features *= s
- return num_features
简单的神经网络搭建完成了,这期内容到此结束。感谢你花时间阅读本文。如果你对本文的内容有任何疑问或建议,欢迎评论区留言。再次感谢您的阅读和理解。祝您生活愉快!

