
热门标签
热门文章
- 1Windows上CLion配置和使用教程_clion edit configuration怎么配置
- 2ROS2+mid360建图教程(2)_fastlio mid360 ros2
- 3pip安装报错ERROR: Could not find a version that satisfies the requirement pycryptodome (from versions: n
- 4VS Code Json格式化插件-JSON formatter_vscode json格式化插件
- 5pli测试50题题库_【马士基销售代表面试】性格测试+12分钟50道题。-看准网
- 6string类_string头文件
- 7【微服务】springcloud-alibaba 配置多环境管理使用详解_springcloud alibaba sercity如何配置
- 804_服务注册Eureka_服务注册到eureka
- 9Linux操作系统——定制自己的 Linux 系统_打造自己的linux
- 10Python常用的12个GUI框架,张口就来_python桌面应用框架
当前位置: article > 正文
Python脚本:用py处理PDF的五大功能_py脚本怎么写pdf输出
作者:一键难忘520 | 2024-06-27 07:57:27
赞
踩
py脚本怎么写pdf输出
一、代码
【第三方库】3个
【Py版本】3.9
【使用前提】关闭所有的word文档
- import os
- from datetime import datetime
- from docx2pdf import convert
- from pdf2docx import parse
- from PyPDF2 import PdfMerger
- from PyPDF2 import PdfReader,PdfWriter
-
-
- #将文件夹中的所有Word文档批量转换为PDF
- def wordtopdf(url):
- if not os.path.exists(url):
- return False
- result=convert(url)#若满足条件"result==None"则表明转换成功
- return result==None
-
- #将文件夹中的所有PDF批量转换为Word文档
- def pdftoword(url):
- if not os.path.exists(url):
- return False
- all_files_successful = True # 假设所有文件都成功转换
- for root, dirs, files in os.walk(url):
- for file in files:
- if file.endswith(".pdf"):
- pdf_file_path = os.path.join(root, file)
- result = parse(pdf_file_path)
- if result is not None: # 转换失败
- all_files_successful = False
- break # 如果有一个文件转换失败,就跳出内层循环
- return all_files_successful
-
- #合并指定路径的pdf文档(顺序:01 02 03开头文件名依次排序)
- def mergepdf(url):
- if not os.path.exists(url):
- return False
- merger = PdfMerger()
- output_path=url+f"\\合并pdf_{datetime.now().strftime('%Y%m%d%H%M%S')}.pdf"#输出路径
- # 遍历文件夹下的所有PDF文件并合并
- for root, dirs, files in os.walk(url):
- for file in files:
- if file.endswith(".pdf"):
- pdf_file_path = os.path.join(root, file)
- merger.append(pdf_file_path)
- # 将合并后的PDF保存到指定输出路径
- merger.write(output_path)
- merger.close()
- return True
-
- #提取pdf的图像
- def pdfimages(pdfurl):
- if not os.path.exists(pdfurl):
- return False
- reader = PdfReader(pdfurl)
- all = len(reader.pages) #返回pdf有多少页
- count = 0
- for i in range(0,all):
- page = reader.pages[i]
- for image_file_object in page.images:
- with open(f"{os.path.dirname(pdfurl)}/图{count+1}_{datetime.now().strftime('%Y%m%d%H%M%S')}.png", "wb") as fp:
- fp.write(image_file_object.data)
- count += 1
- return True
-
- # 在PDF文件中加水印函数
- def pdfcreatewater(pdfurl, pdf_watermark):
- if not os.path.exists(pdfurl) or not os.path.exists(pdf_watermark):
- return False
- # 把水印的文件读入
- watermark = PdfReader(pdf_watermark)
- # 取出水印文件的第1页
- waterpage = watermark.pages[0]
- # 读入要加入水印的PDF文件
- vreader = PdfReader(pdfurl)
- # 取得要加入水印的文件的页数
- n = len(vreader.pages)
- # print(n)
- # 生成一个PDF文件写对象
- vwriter = PdfWriter()
- # 通过循环给第一页加上水印
- for i in range(n):
- # 取得PDF文件的一页
- onepage = vreader.pages[i]
- # 通过mergePage将水印加到该页面
- onepage.merge_page(waterpage)
- # 在写对象中加入一页
- vwriter.add_page(onepage)
- # 打开最终形成的包含水印的文件
- with open(f"{os.path.dirname(pdfurl)}/合成水印_{datetime.now().strftime('%Y%m%d%H%M%S')}.pdf", 'wb') as f:
- # 通过写对象写到文件中
- vwriter.write(f)
- return True
二、附录:如何为PDF添加水印
第一步,打开word,按以下步骤添加水印


二、若水印不够多,则双击页眉,可以拖拽水印
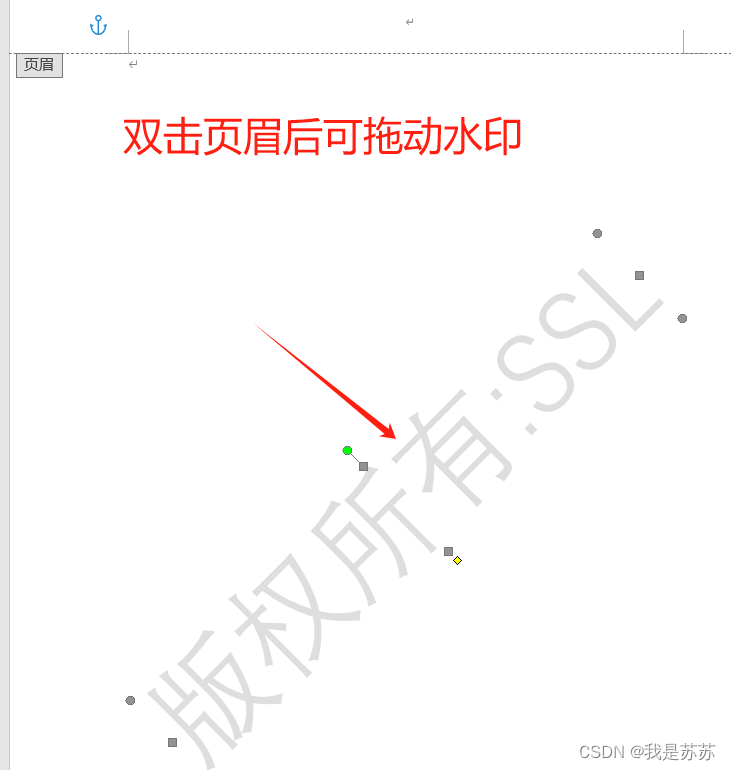
【注意】水印背景是透明的不准出现白色,若有覆盖情况请检查水印文件
【效果】

三、附录:如何设置合并顺序
按顺序命名即可,例如"01xxx","02xxx","03xxxx"…………

四、打包为GUI程序(Pyinstaller PyQt5)

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/一键难忘520/article/detail/761772
推荐阅读

相关标签

