
- 1chatgpt赋能python:Python选择对话框:简化用户操作的实用工具_python 选择文件对话框
- 2千帆大模型|API调用_千帆大模型 api key
- 3算法力扣刷题 三十一【150. 逆波兰表达式求值】
- 4Docker Desktop - WSL distro terminated abruptly
- 5二进制部署K8s群集+Openebs+KubeSphere+Ceph群集_kubesphere openebs
- 6安全开发基础 -- DAST,SAST,IAST简单介绍_dast iast
- 7FPGA基于AXI 1G/2.5G Ethernet Subsystem实现UDP以太网通信,提供21套工程源码和技术支持_ethernet硬件实现
- 8Anaconda安装scrapy爬虫框架(图文版)_scrapy可以在anaconda里面安装吗
- 9Qualcomm工具_qdart
- 10ELK日志分析平台(三)----kibana数据可视化_kibana的主要功能
python程序设计基础:python序列_python序列下标
赞
踩
第二章 python序列
2.python序列概述
python序列类似于其他语言中的数组,但功能要强大的多。
python中常用的序列结构有列表(可变)、元组(不可变)、字符串(不可变),字典(可变)、集合(可变)以及range等对象,也支持很多类似的操作。
列表、元组、字符串(可变序列)支持双向索引,第一个元素下标为0,第二个元素下标为1,以此类推;最后一个元素下标为-1,倒数第二个元素下标为-2,以此类推。
2.1列表
列表是python中内置有序可变序列,列表的所有元素放在一对中括号“[ ]”中,并使用逗号分隔开;
当列表元素增加或删除时,列表对象自动进行扩展或收缩内存,保证元素之间没有缝隙;
在python中,一个列表中的数据类型可以各不相同,可以同时分别为整数、实数、字符串等基本类型,甚至是列表、元组、字典、集合以及其他自定义类型的对象。
[10,20,30,40]
['crunchy frog' 'ram bladder','lark vomit']
['spam'.2.0,5[10,20]]
[[file1,200,7],['file2',260,9]]
2.1.1列表常用方法
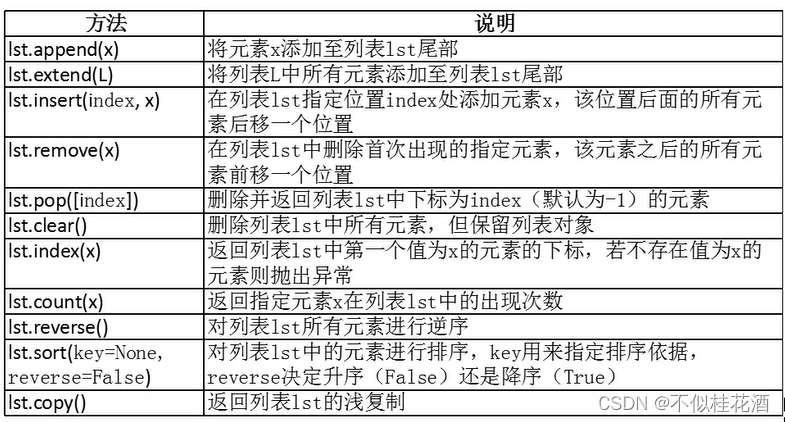
2.1.2列表的创建与删除
(1)=
使用“=”直接将一个列表赋值给变量即可创建列表对象
>>>a_list=['a','b','mpilgrim','z','example'] #创建列表
>>>a_list=[] #创建空列表
(2)list()
也可以使用list()函数将元组、range()对象、字符串或其他类型的可迭代对象类型的数据转换为列表。
>>>a_list=list((3,5,7,9,11)) #元组转换为列表
>>>a_list
[3, 5, 7, 9, 11]>>>list(range(1,10,2)) #range对象转换为列表
[1, 3, 5, 7, 9]>>>list('hello world') #字符串转换为列表
['h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd']
>>>x=list() #创建空列表
(3)del
当我们不再使用时,使用del命令删除整个列表,如果列表对象所指的值不再有其他对象指向,python将同时删除该值。
>>>del a_list #删除整个a_list列表
>>>a_list
Traceback (most recent call last):
File "<pyshell#8>", line 1, in <module>
a_list
NameError: name 'a_list' is not defined. Did you mean: 'list'?
2.1.3列表元素的增加
(1)“+”
可以使用“+”运算符将元素添加到列表中。
>>>aList=[3,4,5]
>>>aList=aList+[7]
>>>aList
[3, 4, 5, 7]
严格意义上来讲,这并不是真的为列表添加元素,而是创建一个新列表,并将原列表中的元素和新元素依次复制到新列表的内存空间。由于涉及大量元素的复制,该操作速度较慢,在涉及大量元素添加时不建议使用该方法。
(2)append()
使用列表对象的append()方法,在原地修改列表,是真正意义上的在列表尾部添加元素,速度较快。
>>>aList.append(9)
>>>aList
[3, 4, 5, 7, 9]
所谓“原地址”,是指不改变列表在内存中的首地址。
下面代码比较了”+“和append()这两种方法的速度差异
- import time #导入time模块
-
- result=[]
- start=time.time() #记录当前的时间
- for i in range(10000): #循环10000次
- result=result+[i] #每次循环在result列表中增加一个元素
- print(len(result),',',time.time()-start) #time.time()获取当前的时间-start记录的时间
-
- result=[]
- start=time.time()
- for i in range(10000):
- result.append(i) #使用append
- print(len(result),',',time.time()-start)

Python采用的是基于值的自动内存管理方式,当为对象修改值时,并不是真的直接修改变量的值,而是使变量指向新的值,这对于Python所有类型的变量都是一样的。
>>>a=[1,2,3]
>>>id(a) #返回对象的内存地址
2276903130176>>>a=[1,2] #实际上是指向了一个新的列表
>>>id(a)
2276903128064
列表中包含的是元素值的引用,而不是直接包含元素值。如果是直接修改序列变量的值,则与Python普通变量的情况是一样的,而如果是通过下标来修改序列中元素的值或通过可变序列对象自身提供的方法来增加和删除元素时,序列对象在内存中的起始地址是不变的,仅仅是被改变值的元素地址发生变化,也就是所谓的“原地操作”。
>>>a=[1,2,4]
>>>b=[1,2,3]
>>>a==b
False>>>id(a)==id(b)
False>>>id(a[0])==id(b[0])
True>>>a=[1,2,3]
>>>id(a)
2276871517056>>>a.append(4)
>>>a
[1, 2, 3, 4]>>>id(a)
2276871517056>>>a.remove(3) #删除一个元素
>>>a
[1, 2, 4]
>>>id(a)
2276871517056>>>a[0]=5 #通过下标修改值
>>>a
[5, 2, 4]
>>>id(a)
2276871517056
(3)extend()
使用列表对象的extend()方法可以将另一个迭代对象的所有元素添加至该列表对象尾部。通过extend()方法来增加列表元素也不改变其内存首地址,属于原地操作。
a.extend([7,8,9])
a
[5, 2, 4, 7, 8, 9]id(a)
2276871517056
(4)insert(位置,元素)
使用列表对象的insert()方法将元素添加到列表的指定位置。
a.insert(3,6) #在下标为3的位置插入元素6
a
[5, 2, 4, 6, 7, 8, 9]
应尽量从列表尾部进行元素的增加与删除操作。
列表的insert()可以在列表的任意位置插入元素,但由于列表的自动内存管理功能,insert()方法会涉及到插入位置之后所有元素的移动,这会影响处理速度。
类似的还有后面介绍的remove()方法以及使用pop()函数弹出列表非尾部元素和使用del命令删除列表非尾部元素的情况。
- import time
-
- def Insert():
- a=[]
- for i in range(10000):
- a.insert(0,i)
-
- def Append():
- a=[]
- for i in range(10000):
- a.append(i)
-
- start=time.time()
- for i in range(10):
- Insert()
- print("Insert:",time.time()-start)
-
- start=time.time()
- for i in range(10):
- Append()
- print("Append:",time.time()-start)
 '运行
'运行
乘法扩表
使用乘法来扩展列表对象,将列表与整数相乘,生成一个新列表,新列表是原列表中元素的重复。
>>> aList=[3,5,7]
>>>bList=aList #这两个列表同时指向同一个列表>>>id(aList)
2436236653440
>>>id(bList)
2436236653440>>>aList=aList*3 #让aList指向一个新列表
>>>aList
[3, 5, 7, 3, 5, 7, 3, 5, 7]
>>>bList
[3, 5, 7]>>>id(aList)
2436268201920
>>>id(bList)
2436236653440
当使用*运算符将包含列表的列表重复并创建新列表时,并不创建元素的复制,而是创建已有对象的引用。因此,当修改其中一个值时,相应的引用也会被修改。
>>>x=[[None]*2]*3 #重复三次是说重复最开始的列表
>>>x
[[None, None], [None, None], [None, None]]
>>>x[0][0]=5
>>>x
[[5, None], [5, None], [5, None]]>>>x=[[1,2,3]]*3
>>>x[0][0]=10
>>>x
[[10, 2, 3], [10, 2, 3], [10, 2, 3]]
(5)del
使用del命令删除列表中的指定位置上的元素。
>>>a_list=[3,5,7,9,11]
>>>del a_list[1]
>>>a_list
[3, 7, 9, 11]
(6)pop()
使用列表的pop()方法删除并返回指定(默认为最后一个)位置上的元素,如果给定的索引超出了列表的范围则抛出异常。
>>>a_list=list((3,5,7,9,11))
>>>a_list.pop()
11
>>>a_list
[3, 5, 7, 9]>>>a_list.pop(1) #删除并返回下标为1的
5
>>>a_list
[3, 7, 9]
(7)remove()
使用列表对象的remove()方法删除首次出现的指定元素,如果列表中不存在要删除的元素,则抛出异常。
>>>a_list=[3,5,7,9,7,11]
>>>a_list.remove(7)
>>>a_list
[3, 5, 9, 7, 11]
代码编写好后必须要经过反复测试,不能满足于几次测试结果正确。例如,下面的代码成功地删除了列表中的重复元素,执行结果是完全正确的。
>>>x=[1,2,1,2,1,2,1,2,1]
>>>for i in x:
if i==1:
x.remove(i)
>>>x
[2, 2, 2, 2]
>>>x=[1,2,1,2,1,1,1]
>>>for i in x:
if i==1:
x.remove(i)
>>>x
[2, 2, 1]
两组数据的本质区别在于,第一组数据中没有连续的“1”,而第二组数据中存在连续的“1”。出现这个问题的原因是列表的自动内存管理功能。
在删除列表元素时,Python会自动对列表内存进行收缩并移动列表元素以保证所有元素之间没有空隙,增加列表元素时也会自动扩展内存并对元素进行移动以保证元素之间没有空隙。每当插入或删除一个元素之后,该元素位置后面所有元素的索引就都改变了。
x=[1,2,1,2,1,1,1]
for i in x[::]:
if i==1:
x.remove(i)
x
[2, 2]x=[1,2,1,2,1,1,1]
for i in range(len(x)-1,-1,-1):
if x[i]==1:
del x[i]
x
[2, 2]
2.1.4列表元素访问与计数
(1)下标访问
使用下标直接访问列表元素,如果指定下标不存在,则抛出异常。
>>>aList=[3,4,5,6,7,8,9,11,13,15,17] #下标从0开始
>>>aList[3]
6>>>aList[3]=5.5 #修改列表中下标对应的元素
>>>aList
[3, 4, 5, 5.5, 7, 8, 9, 11, 13, 15, 17]>>>aList[15]
Traceback (most recent call last):
File "<pyshell#5>", line 1, in <module>
aList[15]
IndexError: list index out of range
(2)index()方法
使用列表对象的index()方法获取指定元素首次出现的下标,若列表对象中不存在指定对象元素,则抛出异常。
>>>aList
[3, 4, 5, 5.5, 7, 8, 9, 11, 13, 15, 17]>>>aList.index(7) #找元素7的下标
4 #返回元素7对象的下标为4
>>>aList.index(100)
Traceback (most recent call last):
File "<pyshell#8>", line 1, in <module>
aList.index(100)
ValueError: 100 is not in list
(3)count()方法
使用列表对象的count()方法统计指定元素在列表对象中出现的次数
>>>aList
[3, 4, 5, 5.5, 7, 8, 9, 11, 13, 15, 17]>>>aList.count(7) #看列表中7出现的次数
1
>>>aList.count(0)
0 #次数为0,该元素不存在>>>aList.count(8)
1>>>aList.count(2)
0
2.1.5成员资格判断
(1)in
如果需要判断列表中是否存在指定的值,可以使用count()方法,如果存在则返回值大于0,如果返回0则表示不存在。或者,使用更加简洁的“in”关键字来判断一个值是否存在于列表中,返回结果为“True”或“False”。
>>>aList
[3, 4, 5, 5.5, 7, 8, 9, 11, 13, 15, 17]>>>3 in aList #判断3是否在列表aList中
True>>>18 in aList
False>>>bList=[[1],[2],[3]]
>>>3 in bList
False>>>3 not in bList #判断3是不是不在列表bList中
True>>>[3] in bList #判断列表3([3])是否在bList中
True>>>aList=[3,5,7,9,11]
>>>bList=['a','b','c','d']>>>(3,'a') in zip(aList,bList) #zip函数,将两个列表压缩到一起,3、a;5、b..是一对
True>>>for a,b in zip(aList,bList): #使for循环,遍历zip对象中的内容
print(a,b)
3 a
5 b
7 c
9 d
2.1.6切片操作
切片是python序列的重要操作之一,适用于列表、元组、字符串、range对象等类型(支持下标操作,支持随机访问)。不适用于具有惰性求值特点的对象(zip,map,filter,enumerate:不支持随机访问,不支持下标操作)。
列表名[元素开始位置:元素结束位置:步长] 得到的是左闭右开的区间元素
切片使用2个冒号分隔的3个数字来完成,第一个数字表示切片开始位置(默认为0),第二个数字表示切片截止(但不包含)位置(默认为列表长度),第三个数字表示切片的步长(默认为1),当步长省略时可以顺便省略最后一个冒号。可以使用切片的来截取列表中的任何部分,得到的新列表,也可以通过切片来修改和删除列表中的部分元素,甚至可以通过切片操作为列表对象增加元素。
切片操作不会因为下标越界而抛出异常,而是简单地在列表尾部截断或者返回一个空列表,代码具有更强健壮性。
>>>aList=[3,5,7,8,9,11,13,15,17]
#从列表开始(列表0位置)到列表的长度位置(列表9位置),步长为1
>>>aList[::] #返回包含所有元素的新列表
[3, 5, 7, 8, 9, 11, 13, 15, 17]>>>aList[::-1] #开始比结束的数字大,步长为-1,逆序的所有元素
[17, 15, 13, 11, 9, 8, 7, 5, 3]>>>aList[::2] #从列表0位置到列表9位置,步长为2
[3, 7, 9, 13, 17]>>>aList[1::2] #从列表1位置带列表9位置,步长为2
[5, 8, 11, 15]>>>aList[3::] #从下标3开始的所有元素
[8, 9, 11, 13, 15, 17]>>>aList[3:6] #下标在[3,6)之间的所有元素
[8, 9, 11]>>>aList[0:100:1] #前100个元素,自动截断
[3, 5, 7, 8, 9, 11, 13, 15, 17]>>>aList[100:] #下标100之后的所有元素,自动截断
[]>>>aList[100] #直接使用下标访问会发生越界
Traceback (most recent call last):
File "<pyshell#38>", line 1, in <module>
aList[100]
IndexError: list index out of range
可以使用切片来原地修改列表内容
>>>aList=[3,5,7]
>>>aList[len(aList):] #在=[9] 尾部追加元素
>>>aList
[3, 5, 7, 9]>>>aList[:3]=[1,2,3] #切片连续,两边的元素个数可以不一样,替换前三个元素
>>>aList
[1, 2, 3, 9]>>>aList[:3]=[] #删除前三个元素,不可以删除不连续位置上的元素
>>>aList
[9]>>>aList=list(range(10))
>>>aList
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]>>>aList[::2]=[0]*5 #替换偶数位置上的元素
>>>aList
[0, 1, 0, 3, 0, 5, 0, 7, 0, 9]>>>aList[::2]=[0]*3 #切片不连续,左边切片和右边元素,两个元素个数必须一样多
Traceback (most recent call last):
File "<pyshell#50>", line 1, in <module>
aList[::2]=[0]*3
ValueError: attempt to assign sequence of size 3 to extended slice of size 5
使用del与切片结合来删除列表元素
>>>aList=[3,5,7,9,11]
>>>del aList[:3] #删除前3个元素
>>>aList
[9, 11]>>>aList=[3,5,7,9,11]
>>>del aList[::2] #删除偶数位置上的元素,可以删除不连续位置上的元素
>>>aList
[5, 9]
切片返回的是列表元素的浅复制
>>>aList=[3,5,7]
>>>bList=aList #bList和aList指向同一个内存
>>>bList
[3, 5, 7]>>>bList[1]=8 #修改其中一个对象会影响另一个
>>>aList
[3, 8, 7]>>>aList==bList #两个列表的对象完全一样
True>>>aList is bList #两个列表是同一个对象
True>>>id(aList) #内存地址相同
2206742643328
>>>id(bList)
2206742643328
所谓浅复制,是指生成一个新列表,并把原来列表中所有元素的引用都复制到新列表中。如果原列表中只包含整数、实数、复数等基本类型和元组、字符串这样的不可变类型的数据,一般是没有问题的。如果原列表中包含列表之类的可变数据类型,由于浅复制时只是把子列表的引用复制到新列表中,这样的话修改任何一个都不会影响另外一个。
>>>aList=[3,5,7]
>>>bList=aList[::] #切片,浅复制
>>>aList==bList #两个列表的元素完全一样
True>>>aList is bList #但不是同一个对象
False>>>id(aList)==id(bList) #内存地址不一样
False>>>bList[1]=8 #修改其中一个不会影响另一个
>>>bList
[3, 8, 7]>>>aList
[3, 5, 7]
2.1.7列表排序
(1)sort()
使用列表对象的sort()方法进行原地排序,支持多种不同的排序方法(key)。
>>>aList=[3,4,5,6,7,9,11,13,15,17]
>>>import random
>>>random.shuffle(aList) #shuffle随机乱序
>>>aList
[6, 11, 3, 4, 15, 5, 17, 13, 9, 7]>>>aList.sort() #reverse=False默认是升序排序
>>>aList.sort(reverse=True) #降序排序
>>>aList
[17, 15, 13, 11, 9, 7, 6, 5, 4, 3]>>>aList.sort(key=lambda x:len(str(x))) #key参数指定排序规则,lambda是一个函数,按转换成字符串的长度排序
>>>aList
[9, 7, 6, 5, 4, 3, 17, 15, 13, 11] #一样长,原来在前就在前;长的在后,短的在前
(2)sorted()
使用内置函数sorted()对列表进行排序返回新列表
aList
[9, 7, 6, 5, 4, 3, 17, 15, 13, 11]
sorted(aList) #需要告诉它对谁排序
[3, 4, 5, 6, 7, 9, 11, 13, 15, 17]
sorted(aList,reverse=True)
[17, 15, 13, 11, 9, 7, 6, 5, 4, 3]
(3)reverse()
使用列表对象的reverse()方法将元素原地逆序
>>>aList=[3,4,5,6,7,9,11,13,15,17]
>>>aList.reverse()
>>>aList
[17, 15, 13, 11, 9, 7, 6, 5, 4, 3]
(4)reversed()
使用内置函数reversed()对列表元素进行逆序排列并返回迭代对象
>>>aList=[3,4,5,6,7,9,11,13,15,17]
>>>newList=reversed(aList) #返回reversed对象,返回的对象具有惰性求值特点,已经访问过的元素,没法再访问了
>>>list(newList) #把reversed对象转换成列表,把里面的所有元素都访问过
[17, 15, 13, 11, 9, 7, 6, 5, 4, 3]>>>for i in newList:
print(i,end=' ') #这里没有输出内容#迭代对象已遍历结束
>>>newList=reversed(aList) #重新创建reversed对象
>>>for i in newList:
print(i,end=' ')
17 15 13 11 9 7 6 5 4 3
2.1.8用于序列操作的常用内置函数
(1)len(列表)
返回列表中的元素个数,同样适用于元组、字典、集合、字符串等。
(2)max(列表)、min(列表)
返回列表中的最大或最小元素,同样适用于元组、字典、集合、range对象等。
(3)sum(列表)
对列表的元素进行求和运算,对非数值型列表运算需要指定start参数,同样适用于元组、range。
>>>sum(range(1,11)) #sum()函数的start参数默认值是0
55
>>>sum(range(1,11),5) #指定start参数为5,等价于5+sum(range(1,11))
60
>>>sum([[1,2],[3],[4]],[]) #start默认值是0,在这里必须指定为[],这个操作占用空间较大,慎用
[1, 2, 3, 4]
(4)zip()
zip()函数返回可迭代的zip对象
>>>aList=[1,2,3]
>>>bList=[4,5,6]
>>>cList=zip(aList,bList) #返回zip对象,这个对象具有惰性求值特点,也就是不支持下标操作和随机访问,也就不支持切片
>>>cList
<zip object at 0x00000201CA3830C0> #把zip对象转换成列表
>>>list(cList)
[(1, 4), (2, 5), (3, 6)]
(5)enumerate(列表)
枚举列表元素,返回枚举对象,其中每个元素为包含下标和值的元组。该函数对元组、字符串同样有效。
for item in enumerate('abcdef'): #具有惰性求值特点
print(item)
(0, 'a')
(1, 'b')
(2, 'c')
(3, 'd')
(4, 'e')
(5, 'f')
2.1.9列表推导式
列表推导式使用非常简洁的方式来快速生成满足特定需求的列表,代码具有非常强的读性。
>>>aList=[x*x for x in range(10)] #把x的平方作为列表中的一个元素
相当于
>>>aList=[]
>>>for i in range(10): #循环10次
aList.append(x*x) #把x的平方追加到列表的尾部
也相当于
>>>aList=list(map(lambda x:x*x,range(10))) #使用map把lambda表达式(接收一个x,返回x的平方)映射到range函数上去 #把range对象中所有的元素都变成x的平方,返回一个map对象,用list转换成列表
阿凡提与国王比赛下棋,国王说要是自己输了的话,阿凡提想要什么他都可以拿的出来。阿凡提说那就要点米吧,棋盘一共64个小格子,在第一个格子里放1粒米,第二个格子放2粒米,第三个格子放4粒米,第四个格子放8粒米,以此类推,最后每个格子都是前面一个格子里的2倍,一直把64个格放满。需要多少粒米呢?
>>>sum([2**i for i in range(64)]) #2的i次方,[0,64)
18446744073709551615
使用列表推导式实现嵌套列表的平铺
>>>vec=[[1,2,3],[4,5,6],[7,8,9]]
>>>[num for elem in vec for num in elem] #先循环子列表,再循环子列表内的元素
[1, 2, 3, 4, 5, 6, 7, 8, 9]
相当于
>>>vec=[[1,2,3],[4,5,6],[7,8,9]]
>>>result=[]
>>>for elem in vec:
for num in elem:
result.append(num)
>>>result
[1, 2, 3, 4, 5, 6, 7, 8, 9]
如果不使用列表推导式,可以这样做
>>>vec=[[1,2,3],[4,5,6],[7,8,9]]
>>>sum(vec,[]) #start=[],空列表+第一个子类表+第二个子类表+第三个子类表
[1, 2, 3, 4, 5, 6, 7, 8, 9]
或
>>>vec=[[1,2,3],[4,5,6],[7,8,9]]
>>>from itertools import chain #chain函数
>>>list(chain(*vec)) #*:去掉外面最大的列表,chain把三个小列表出串起来,返回的是chain对象,用list转换成列表
[1, 2, 3, 4, 5, 6, 7, 8, 9]
列出当前文件夹下所有python源文件
>>>import os
>>>[filename for filename in os.listdir('.') if filename.endswith('.py','.pyw')]
#列出当前目录下所有的文件,如果文件的后缀是.py或.pyw的文件就留下
过滤不符合条件的元素
>>>aList=[-1,-4,6,7.5,-2.3,9,-11]
>>>[i for i in aList if i>0] #循环遍历列表,如果元素大于0,留下
>>>[6, 7.5, 9]
已知有一个包含一些同学成绩的字典,计算成绩的最高分、最低分、平均分,并查找所有最高分同学。
>>>scores={"zhang san":45,"li si":78,"wang wu":40,"zhou liu":96,"zhao qi":65,"sun ba":90,"zheng jiu":78,"wu shi":99,"dong shiyi":60} #字典 姓名:分数
>>>highest=max(scores.values()) #返回所有的值(字典由键和值)
>>>lowest=min(scores.values())
>>>average=sum(scores.values())*1.0/len(scores) #*1.0兼容python2.7
>>>highest,lowest,average
(99, 40, 72.33333333333333)>>>highestPerson=[name for name,score in scores.items() if score==highest]
#对于列表中每个名字和分数,如果分数是最高分,留名字name
>>>highestPerson
['wu shi']
在列表推导式中使用多个循环,实现多序列元素的任意组合,并且可以结合条件语句过滤特定元素
>>>[(x,y) for x in range(3) for y in range(3)] #看成外循环和内循环
[(0, 0), (0, 1), (0, 2), (1, 0), (1, 1), (1, 2), (2, 0), (2, 1), (2, 2)]>>>[(x,y) for x in [1,2,3] for y in [3,1,4] if x!=y]
[(1, 3), (1, 4), (2, 3), (2, 1), (2, 4), (3, 1), (3, 4)]
使用列表推导式实现矩阵转置(行列互换)
>>>matrix=[[1,2,3,4],[5,6,7,8],[9,10,11,12]]
>>>[[row[i] for row in matrix] for i in range(4)]#先看后面循环四次,循环遍历matrix列表,第一次输出的是每个子列表的第o0个元素,i随后面循环变化
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
也可以使用内置函数来实现矩阵转置
>>>list(zip(*matrix)) #序列解包
# *:把最外面的列表去掉,得到三个列表; zip:让三个列表对应位置上的元素在一起;最后对象转换成列表输出
[(1, 5, 9), (2, 6, 10), (3, 7, 11), (4, 8, 12)]
列表推导式中可以使用函数或复杂表达式
>>>def f(v):
if v%2==0: #如果是偶数
v=v**2 #返回v的平方
else:
v=v+1 #否则返回v+1
return v #返回计算好的v>>>[f(v) for v in [2,3,4,-1] if v>0] # [2,3,4,-1]中如果元素大于0,传给前面定义好的函数
[4, 4, 16]
>>>[v**2 if v%2==0 else v+1 for v in [2,3,4,-1] if v>0]
[4, 4, 16]
列表推导式支持文件对象迭代
#with是上下文管理语句,可以自动管理资源
>>>with open('C:\\RHDSetup.log','r') as fp: #打开文件,并传给fp
print([line for line in fp]) #输出文件中所有的行
使用列表推导式生成10以内的所有素数
>>>[p for p in range(2,100) if 0 not in [p%d for d in range(2,int(p**0.5)+1)]]
#从2到99中选一个数,这个数满足后面你的条件
#[]中:p对d的余数留下,d是2到根号下p+1
#如果0不在p对d的余数里面,就留下p,也就是说p不能被d整除
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97]
2.1.10使用列表实现向量运算
>>>import random
#randint返回1到100之间闭区间的数
>>>x=[random.randint(1,100) for i in range(10)] #得到10个1到100之间的数
>>>list(map(lambda i:i+5,x)) #把lambda表达式映射到x上去,所有元素同时+5
[17, 19, 18, 66, 60, 43, 25, 85, 33, 13]>>>x=[random.randint(1,10) for i in range(10)]
>>>y=[random.randint(1,10) for i in range(10)]
>>>import operator>>>sum(map(operator.mul,x,y)) #向量内积:x和y对应位置上的元素相乘,最后加起来
285
>>>sum((i*j for i,j in zip(x,y))) #用zip让x和y变成对应位置上一对一对的
285>>>list(map(operator.add,x,y)) #两个等长向量对应元素相加
[16, 12, 4, 12, 7, 11, 15, 6, 4, 16]
2.2元组
元组和列表类似,但属于不可变序列,元组一旦创建,用任何方法都不可以修改其元素。
元组的定义方式和列表相同,但定义时所有元素是放在一对圆括号“()”中,而不是方括号中。
2.2.1元组创建与删除
(1)=
使用“=”将一个元组赋值给变量
>>>a_tuple=('a','b','mpilgrim','z','example')
>>>a_tuple
('a', 'b', 'mpilgrim', 'z', 'example')>>>a=(3) #元组里只包含一个元素,相当于a=3
>>>a
3>>>a=(3,) #包含一个元素的元组,最后必须多写一个逗号(),列表不存在这个问题
>>>a
(3,)>>>a=3, #也可以这样创建元组
>>>a
(3,)>>>x=() #创建空元组
(2)tuple()
使用tuple函数将其他序列转换为元组
>>>tuple('abcdefg')
('a', 'b', 'c', 'd', 'e', 'f', 'g') #把字符串转换为元组
>>>aList=[-1,-4,6,7.5,-2.3,9,-11]
>>>aList
[-1, -4, 6, 7.5, -2.3, 9, -11]
>>>tuple(aList) #把列表转换为元组
(-1, -4, 6, 7.5, -2.3, 9, -11)>>>s=tuple() #创建空元组
>>>s
()
(3)del
使用del可以删除元组对象(整个元素),不能删除元组中的元素。
2.2.2元组与列表的区别
元组中的数据一旦定义就不允许更改。元组中的数据可以是列表、字典、集合。
>>>x=(1,2,[4,5])
>>>x[0]=6
Traceback (most recent call last):
File "<pyshell#17>", line 1, in <module>
x[0]=6
TypeError: 'tuple' object does not support item assignment>>>del x[0]
Traceback (most recent call last):
File "<pyshell#18>", line 1, in <module>
del x[0]
TypeError: 'tuple' object doesn't support item deletion>>>x[2]
[4, 5]>>>x[2].append(6) #本质上是对列表进行操作
>>>x
(1, 2, [4, 5, 6])
元组没有append()、extend()和insert()等方法,无法向元组中添加元素。
元组没有remove()或pop()方法,也无法对元组元素进行del操作,不能从元组中删除元素。
从效果上看,tuple()冻结列表,而list()融化元组。
轻量级列表
元组的速度比列表更快。如果定义了一系列常量值,而所需做的仅是对它进行遍历,那么一般使用元组而不用列表。
元组对不需要改变的数据进行“写保护”,将使得代码更加安全。(只能访问,不可变)
元组可以用作字典的键(特别是包含字符串、数值和其他元组这样的不可变数据的元组)。列表永远不能当作字典的键和集合里的元组元素使用,因为列表不是不可变的。
2.2.3序列解包
可以使用序列解包功能对多个变量同时赋值
>>>x,y,z=1,2,3 #多个变量同时赋值
>>>v_tuple=(False,3.5,'exp')
>>>(x,y,z)=v_tuple
>>>x,y,z=v_tuple #去掉(),上下的作用是一样的>>>x,y,z=range(3) #可以对range对象进行序列解包
>>>x,y,z=iter([1,2,3]) #iter:将一个对象转换成迭代器对象(可迭代的),使用迭代器对象进行序列解包
>>>x,y,z=map(str,range(3)) #使用可迭代的map对象进行序列解包
>>>a,b=b,a #交换两个变量的值
>>>x,y,z=sorted([1,3,2]) #sorted()函数返回排列后的列表
>>>a,b,c='ABC' #字符串也支持序列解包
>>>x=[1,2,3,4,5,6]
>>>x[:3]=map(str,range(5)) #切片也支持序列解包 #切片连续,等号两边的元素个数可以不一样
>>>x
['0', '1', '2', '3', '4', 4, 5, 6] #列表中的前3个,替换成了map对象转化后的5个
序列解包,等号左边的右边的元素个数一般是一样多的
>>>x,y,z=1,2,3,4,5
Traceback (most recent call last):
File "<pyshell#39>", line 1, in <module>
x,y,z=1,2,3,4,5
ValueError: too many values to unpack (expected 3)>>>x,y,z=1,2
Traceback (most recent call last):
File "<pyshell#40>", line 1, in <module>
x,y,z=1,2
ValueError: not enough values to unpack (expected 3, got 2)
序列解包对于列表和字典具有同样有效
>>>s={'a':1,'b':2,'c':3} #键:值(键是可哈希的)
>>>b,c,d=s.items() #.items():返回字典中所有的元素(一对)#分别赋值,无序赋值
>>>b
('a', 1)#使用字典时不用太考虑元素的顺序
>>>b,c,d=s #把一个字典给三个变量,是把字典的键赋值给了三个变量
>>>b
'a'>>>b,c,d=s.values() #.values():返回字典中所有的值
>>>print(b,c,d)
1 2 3
序列解包遍历多个序列
>>>keys=['a','b','c','d']
>>>values=[1,2,3,4]
>>>for k,v in zip(keys,values): #zip:将前面的两个列表压缩到一起,zip对象返回的元组
print((k,v),end=' ')
('a', 1) ('b', 2) ('c', 3) ('d', 4)
使用序列解包遍历enumerate对象
枚举序列和可迭对象
>>>x=['a','b','c']
>>>for i,v in enumerate(x): #enumerate对象返回的是每个元组对象(下标+值)
print('The value on position {0} is {1}'.format(i,v)) #字符串格式化
The value on position 0 is a
The value on position 1 is b
The value on position 2 is c
>>>aList=[1,2,3]
>>>bList=[4,5,6]
>>>cList=[7,8,9]
>>>dList=zip(aList,bList,cList) #zip:将上面三个列表压缩到一起
>>>for index,value in enumerate(dList): #enumerate:将dList列表进行枚举(下标+值)
print(index,':',value)
0 : (1, 4, 7)
1 : (2, 5, 8)
2 : (3, 6, 9)
python 3.5还支持下面的序列解包
>>>print(*[1,2,3],4,*(5,6)) #*:序列解包
1 2 3 4 5 6>>>*range(4),4 #,:使其变成元组
(0, 1, 2, 3, 4)>>>{*range(4),4,*(5,6,7)}
{0, 1, 2, 3, 4, 5, 6, 7}>>>{'x':1,**{'y':2}} #**:对字典进行解包
{'x': 1, 'y': 2}
2.2.4生成器推导式
生成器推导式的结果是一个生成器对象。使用生成器对象的元素时,可以根据需要将其转化为列表或元组,也可以使用生成器对象__next__()方法或内置函数next()进行遍历,或者直接将其作为迭代器对象(for...in...)来使用。
生成器对象具有惰性求值的特点,,只在需要时生成新元素,比列表推导式具有更高的效率,空间占用非常少,尤其适合大数据处理的场合。
不管哪种方法访问生成器对象,都无法再次访问已访问过的元素。(惰性求值特点)
使用生成器对象__next__()方法或内置函数next()进行遍历
>>>g=((i+2)**2 for i in range(10))
>>>g #返回生成器对象
<generator object <genexpr> at 0x000001AB95440E40>>>>tuple(g) #将生成器对象转换成元组
(4, 9, 16, 25, 36, 49, 64, 81, 100, 121)>>>list(g)
[]>>>g=((i+2)**2 for i in range(10))
>>>g.__next__() #生成器对象获取下一个元素
4
>>>g.__next__()
9
>>>next(g)
16
使用for循环直接迭代生成器对象中的元素
>>>g=((i+2)**2 for i in range(10))
>>>for item in g:
print(item,end=' ')
4 9 16 25 36 49 64 81 100 121>>>x=filter(None,range(20)) #过滤0-19中不等于0的元素
>>>5 in x #5在不在x中
True
>>>2 in x #2在不在,不在,上面在访问5在不在的时候已经访问过2,具有惰性求值特点
False>>>x=map(str,range(20)) #将字符串映射到range(20):将遍历的数字全部转化为字符串
>>>'0' in x
True
>>>'0' in x #不可再访问已经访问过的元素
False
2.3字典
字典是无序可变序列。
定义字典时,每个元素的键和值用冒号分隔,元素之间用逗号分隔,所有的元素放在一对大括号“{ }”中。
字典中的键可以为任意不可变数据,比如整数、实数、复数、字符串、元组等等。(列表不可以作为列表的键)
globals()返回字典包含当前作用域所有全局变量和值的字典。
locals()返回字典包含当前作用域内所有局部变量和值的字典。
2.3.1字典的创建与删除
(1)=
使用“=”将一个字典赋值给一个变量。
>>>a_dict={'server':'db.diveintopython3.org','database':'mysql'} #创建一个字典:{键:值}
>>>a_dict #输出此字典
{'server': 'db.diveintopython3.org', 'database': 'mysql'}>>>x={} #创建空字典
>>>x
{}
(2)dict()
使用dict利用已有数据创建字典:
>>>keys=['a','b','c','d'] #创建一个列表
>>>values=[1,2,3,4] #再创建一个列表
>>>dictionary=dict(zip(keys,values)) #zip压缩两个列表,返回的zip对象是元组,每个元组中有两个元素
>>>dictionary
{'a': 1, 'b': 2, 'c': 3, 'd': 4}>>>x=dict() #创建空字典
>>>x
{}
使用dict根据给定的键、值创建字典
>>>d=dict(name='Dong',age=37) #给定的键,给定的值
>>>d
{'name': 'Dong', 'age': 37}
以给定内容为键,创建值为空的字典
>>>adict=dict.fromkeys(['name','age','sex']) #.fromkeys方法:以给定的值为键,创建值为空的字典
>>>adict
{'name': None, 'age': None, 'sex': None} #这个字典,每个元素的值都是空的
(3)del
可以使用del删除整个字典
2.3.2字典元素的读取
(1)下标
以键作为下标可以读取字典元素,若键不存在则抛出异常
>>>aDict={'name':'Dong','sex':'male','age':37}
>>>aDict['name']
'Dong'>>>aDict['tel'] #键不存在,抛出异常
Traceback (most recent call last):
File "<pyshell#16>", line 1, in <module>
aDict['tel']
KeyError: 'tel' #抛出异常,不存在这个键
(2)get
使用字典对象的get方法获取指定键对应的值,并且可以在键不存在的时候返回指定的值。
>>>aDict={'name':'Dong','sex':'male','age':37}
>>>print(aDict.get('address')) #aDict字典中不存在address这个键,返回一个空值
>>>None>>>print(aDict.get('address','SDIBT')) #查找字典中是否有address对应的值,如果有就返回对应的值,没有就返回SDIBT
>>>SDIBT>>>aDict['score']=aDict.get('score',[]) #没有这个键,返回一个空列表
>>>aDict['score'].append(98) #对列表使用append方法
>>>aDict['score'].append(97)
>>>aDict
{'name': 'Dong', 'sex': 'male', 'age': 37, 'score': [98, 97]}
(3)items()、keys()、values()
使用字典对象的items()方法可以返回字典的键、值对列表
使用字典对象的keys()方法可以返回字典的键列表(返回的是迭代对象)
使用字典对象的values()方法可以返回字典的值列表
>>>aDict={'name':'Dong','sex':'male','age':37}
>>>for item in aDict.items(): #输出字典中所有元素
print(item)
('name', 'Dong')
('sex', 'male')
('age', 37)>>>for key in aDict: #不加特殊说明,默认输出键
print(key)
name
sex
age
>>>for key,value in aDict.items(): #序列解包用法
print(key,value)
name Dong
sex male
age 37>>>aDict.keys() #返回所有键
dict_keys(['name', 'sex', 'age'])>>>aDict.values() #返回所有值
dict_values(['Dong', 'male', 37])
2.3.3字典元素的添加与修改
(1)指定键赋值
当以指定键为下标为字典赋值时,若键存在,则可以修改该键的值;若不存在,则表示添加一个键、值对。
>>>aDict={'name':'Dong','sex':'male','age':37}
>>>aDict['age']=38 #修改已经存在的元素值
>>>aDict
{'name': 'Dong', 'sex': 'male', 'age': 38}>>>aDict['address']='SDIBT' #增加新元素
>>>aDict
{'name': 'Dong', 'sex': 'male', 'age': 38, 'address': 'SDIBT'}
(2)update
使用字典对象的update方法,将另一个字典的键、值对添加到当前字典对象
>>>aDict
{'name': 'Dong', 'sex': 'male', 'age': 38, 'address': 'SDIBT'}>>>aDict.items()
dict_items([('name', 'Dong'), ('sex', 'male'), ('age', 38), ('address', 'SDIBT')])>>>aDict.update({'a':'a','b':'b'})
>>>aDict
{'name': 'Dong', 'sex': 'male', 'age': 38, 'address': 'SDIBT', 'a': 'a', 'b': 'b'}
(3)del
使用del删除字典中指定键对应的元素
(4)clear()
使用字典对象的clear()方法来删除字典中所有元素
(5)pop()
使用字典对象的pop()方法删除并返回指定键的元素
(6)popitems
使用字典对象的popitem()方法删除并返回字典中的一个元素
2.3.4字典应用案例
(1)统计字符出现次数
首先,生成包含1000个随机字符的字符串,然后统计每个字符的出现次数。
>>>import string #导入字符串模块,其中有.ascii_letters常量(大小写字母),.digits(0-9),.punctuation(所有的标点符号)
>>>import random #导入random模块
>>>x=string.ascii_letters+string.digits+string.punctuation #三个字符串连接起来
>>>y=[random.choice(x) for i in range(1000)] #.choice(x):从x中随机选出一个字符来
>>>z=''.join(y) #用空串分隔符,将y里面1000个字符连起来
>>>d=dict() #创建一个空字典
>>>for ch in z: #遍历z里面的每个字符
d[ch]=d.get(ch,0)+1 #看z中出现的元素,第一次出现在字典中没有,赋值为0并加1,后面在出现直接加1
>>>import string
>>>import random
>>>x=string.ascii_letters+string.digits+string.punctuation
>>>y=[random.choice(x) for i in range(1000)]
>>>z=''.join(y)
>>>from collections import defaultdict
>>>frequences=defaultdict(int) #创建一个字典,默认值是整型
>>>frequences
defaultdict(<class 'int'>, {})>>>for item in z: #遍历1000个字符串中的每一个
frequences[item]+=1
>>>frequences.items()
使用collections模块的Counter类就可以快速实现这个功能,并且提供更多功能,例如查找出现次数最多的元素。
>>>import string
>>>import random
>>>x=string.ascii_letters+string.digits+string.punctuation
>>>y=[random.choice(x) for i in range(1000)]
>>>z=''.join(y)>>>from collections import Counter
>>>frequences=Counter(z) #将100个字符转化成Counter类,就是一个字典
>>>frequences.items() #这个字典就是每一个字符和每个字符出现的次数
dict_items([('g', 11), ('J', 7), ('6', 10), ('_', 14), ('[', 16), ('N', 23), ('P', 10), ('>', 10), ('\\', 12), ('v', 14), ('7', 13), (')', 18), ('=', 16), ('?', 9), ('2', 10), ('I', 11), ('Q', 7), ('o', 8), ('h', 17), ('A', 8), ('Y', 9), ('r', 9), ('.', 12), ('3', 12), ('(', 10), ('m', 9), ('$', 5), ('{', 12), ('n', 9), ('U', 9), ('z', 16), ('O', 7), ('x', 13), ('8', 10), ('E', 13), ('w', 11), ('!', 8), ('1', 7), ("'", 10), ('K', 13), (';', 7), ('X', 19), ('%', 14), ('"', 15), ('9', 7), ('5', 12), ('D', 10), ('<', 10), ('c', 16), ('b', 13), ('H', 10), ('`', 10), ('y', 16), ('|', 10), ('F', 13), ('B', 13), ('~', 12), ('#', 15), ('W', 13), ('L', 15), ('k', 12), (',', 12), ('T', 8), ('a', 5), ('0', 17), ('G', 9), ('d', 13), ('f', 9), ('C', 10), ('+', 7), ('/', 8), ('Z', 9), ('^', 10), ('-', 12), ('S', 10), (':', 4), ('s', 7), ('@', 13), ('i', 11), ('*', 7), ('&', 12), ('u', 7), ('V', 9), ('t', 7), ('M', 8), ('e', 6), (']', 15), ('4', 7), ('q', 7), ('R', 8), ('j', 7), ('p', 6), ('}', 4), ('l', 6)])
>>>frequences.most_common(1) #.most_common(1):出现次数最多的一个字符
[('N', 23)]
>>>frequences.most_common(3) #.most_common(3):出现最多的前三个
[('N', 23), ('X', 19), (')', 18)]
Counter对象用法实例
>>>cnt=Counter() #创建一个Counter对象
>>>for word in ['red','blue','red','green','blue','blue']: #遍历列表里的每个字符
cnt[word]+=1
>>>cnt
Counter({'blue': 3, 'red': 2, 'green': 1})>>>import re
>>>words=re.findall(r'\w+',open('hamlet.txt').read().lower())#.findall(正则表达式(首字母是w),字符串(打开文本,读里面的内容,将内容全部转换为小写))
>>>Counter(words).most_common(10) #上面返回的是列表,直接把列表转换为Counter类,看看哪十个单词出现的次数最多
2.3.5有序字典
python内置字典是无序的,如果需要一个可以记住元素插入顺序的字典,可以使用collections.OrderedDict。
>>>x=dict() #无序字典
>>>x['a']=3
>>>x['b']=5
>>>x['c']=8
>>>x
{'a': 3, 'b': 5, 'c': 8}>>>import collections #导入 collections模块
>>>x=collections.OrderedDict() #有序字典
>>>x['a']=3
>>>x['b']=5
>>>x['c']=8
>>>x
OrderedDict([('a', 3), ('b', 5), ('c', 8)])
2.3.6字典推导式
>>>s={x:x.strip() for x in ('he','she','I')} #{键:值 for循环(遍历元组里的每一个字符串)}
#.strip():删除当前元素两边的空白字符
>>>s
{'he': 'he', 'she': 'she', 'I': 'I'}>>>for k,v in s.items(): #字典支持序列解包
print(k,':',v)
he : he
she : she
I : I
>>>{i:str(i) for i in range(1,5)} #从1-4,自己作为键,自己转换为字符串作为值
{1: '1', 2: '2', 3: '3', 4: '4'}>>>x=['A','B','C','D']
>>>y=['a','b','b','d']
>>>{i:j for i,j in zip(x,y)} #把i作为键,把j作为值
{'A': 'a', 'B': 'b', 'C': 'b', 'D': 'd'}
2.4集合
集合是无序可变序列,使用“{}”(一对大括号)界定,元素不可重复,同一集合中每个元素都是唯一的。
集合中只能包含数字、字符串、元组等不可变类型(或者说可哈希)的数据,而不包含列表、字典、集合等可变类型的数据。
2.4.1集合的创建与删除
(1)=赋值
直接将集合赋值给变量
>>>a={3,5} #创建一个集合:把一个集合赋值给一个变量
>>>a.add(7) #向集合中添加元素,如果集合里面已经有7,此操作将被忽视
>>>a
{3, 5, 7}
>>>{1,2,3}
{1, 2, 3}>>>{(1,2),3}
{3, (1, 2)} #集合是无序可变的>>>{[1,2],3}
Traceback (most recent call last):
File "<pyshell#5>", line 1, in <module>
{[1,2],3}
TypeError: unhashable type: 'list' #列表对象是不可哈希的
(2)set转换
使用set将其他类型数据转换为集合
>>>a_set=set(range(8,14))
>>>a_set
{8, 9, 10, 11, 12, 13}>>>b_set=set([0,1,2,3,0,1,2,3,7,8]) #将列表对象转化为集合,自动去除重复
>>>b_set
{0, 1, 2, 3, 7, 8}>>>c_set=set() #空集合
>>>c_set
>>>set()
(3)字典和集合区分
>>>x={1,2,3}
>>>type(x)
<class 'set'>>>>y={1:2,2:3,3:4}
>>>type(y)
<class 'dict'>>>>z={1,2,3,4:5}
SyntaxError: invalid syntax>>>z={}
>>>type(z)
<class 'dict'>>>>zz=set()
type(zz)
<class 'set'>
(4)del
当不再使用某个集合时,可以使用del命令删除整个集合。
(5)pop()、remove()、clear()
集合对象的pop()方法删除并返回其中一个元素;
remove()方法直接删除指定元素;
clear()方法清空集合;
>>>a={1,4,2,3}
>>>a.pop()
1>>>a.pop() #集合本身是无序的,弹出的也是无序的
2
>>>a
{3, 4}>>>a.add(2)
>>>a
{2, 3, 4}>>>a.remove(3)
>>>a
{2, 4}
2.4.2集合操作
python集合支持交集、并集、差集等运算。
(1)交集、并集、差集
>>>a_set=set([8,9,10,11,12,13]) #列表转化为集合
>>>b_set={0,1,2,3,7,8} #直接创建一个集合>>>a_set | b_set #并集
{0, 1, 2, 3, 7, 8, 9, 10, 11, 12, 13}
>>>a_set.union(b_set) #并集
{0, 1, 2, 3, 7, 8, 9, 10, 11, 12, 13}>>>a_set & b_set #交集
{8}
>>>a_set.intersection(b_set) #交集
{8}>>>a_set.difference(b_set) #差集
{9, 10, 11, 12, 13}>>>a_set - b_set #差集(前面-后面)
{9, 10, 11, 12, 13}
(2)对称差集、子集
>>>a_set.symmetric_difference(b_set) #对称差集(我有你没有+你有我没有)
{0, 1, 2, 3, 7, 9, 10, 11, 12, 13}
>>>a_set ^ b_set
{0, 1, 2, 3, 7, 9, 10, 11, 12, 13}>>>x={1,2,3}
>>>y={1,2,5}
>>>z={1,2,3,4}
>>>x.issubset(y) #测试x是否为y的子集
False
>>>x.issubset(z) #测试x是否为z的子集
True>>>{3} & {4}
set()
>>>{3}.isdisjoint({4}) #如果两个结合的交集为空,返回True
True
(3)集合包含关系测试
>>>x={1,2,3}
>>>y={1,2,5}
>>>z={1,2,3,4}>>>x < y #比较集合大小/包含关系(如果成立x是y的子集)
False>>>x < z #只有小于,没有等于真子集(x是z的子集)
True>>>y < z
False
>>>{1,2,3} <= {1,2,3} #子集
True
(4)集合提纯
使用集合快速提取序列中单一元素
>>>import random
>>>listRandom=[random.choice(range(10000)) for i in range(100)]#从0-10000中选100次数
>>>noRepeat=[]
>>>for i in listRandom:
if i not in noRepeat:
noRepeat.append(i)
>>>len(listRandom)
100
>>>len(noRepeat)
100
>>>newSet=set(listRandom) #直接把列表转换为集合,就可以 去除重复的元素
2.4.3集合运用案例
(1)不重复随机数
生成不重复随机数的效率比较
>>>import random
>>>import time#使用列表来生成number个介于start和end之间的不重复随机数
>>>def RandomNumbers(number,start,end):
data=[]
n=0
while True: #死循环
element=random.randint(start,end)
if element not in data:
data.append(element)
n+=1
if n==number-1:
break
return data
>>>def RandomNumbers1(number,start,end):
data=[]
while True:
element=random.randint(start,end)
if element not in data:
data.append(element)
if len(data)==number:
break
return data
>>>def RandomNumbers2(number,start,end):
data=set() #创建一个集合
while True:
data.add(random.randint(start,end))
if len(data)==number:
break
return data
(2)电影推荐
根据已有的数据,查找与该用户爱好最相似的用户,也就是看过并喜欢的电影与该用户最接近,然后从那个用户喜欢的电影中选取一个当前用户还没看过的电影,进行推荐。
已有大量用户对若干电影的打分数据,现有某用户,也看过一些电影并进行过评分,要求根据已有打分数据为该用户进行推荐。
代码采用基于用户的协同过滤算法,也就是根据用户喜好来确定与当前用户最相似的用户,然后再根据最相似用户的喜好为当前用户进行推荐。
代码采用字典来存放数据,格式为{用户1:{电影名称1:打分1,电影名称2:打分2,...},用户2:{...}}
- from random import randrange
-
- #历史电影打分数据
- #循环遍历10次,来模拟10个用户use1,user2...
- #film是从[1,15)之间选择,评分是从[1,6)中选择
- data={'user'+str(i):{'film'+str(randrange(1,15)):randrange(1,6)
- for j in range(randrange(3,10))}
- for i in range(10)}
-
- #当前用户打分数据 循环5次,生成5个电影 film:这些电影的名字从(1,15)直接随机选择
- user={'film'+str(randrange(1,15)):randrange(1,6) for i in range(5)}
-
- #最相似的用户及其对电影打分情况 两个用户共同打分的电影最多 并且所有电影打分差值的平方和最小
- #从已有数据里面查找一个最小的元素
- #使用key指定排序的规则
- #&:位与运算符 集合的交集
- #对已有数据的每一项
- similarUser,films=min(data.items(),
- key=lambda item: (-len(item[1].keys()&user),#-:求相反数,如果最小,他们共同评分过的电影就最多
- sum(((item[1].get(film)-user.get(film))**2#平方和最小最接近
- for film in user.keys()&item[1].keys()))))
- print('known data'.center(50,'='))
- for item in data.items():
- print(len(item[1].keys()&user.keys()),
- sum(((item[1].get(film)-user.get(film))**2
- for film in user.keys()&item[1].keys())),
- item,
- sep=':')
- print('current user'.center(50,'='))
- print(user)
- print('most similar user and his films'.center(50,'='))
- print(similarUser,films,sep=':')
- print('recommended film'.center(50,'='))
- print(max(films.keys()-user.keys(),key=lambda film:films[film]))
-
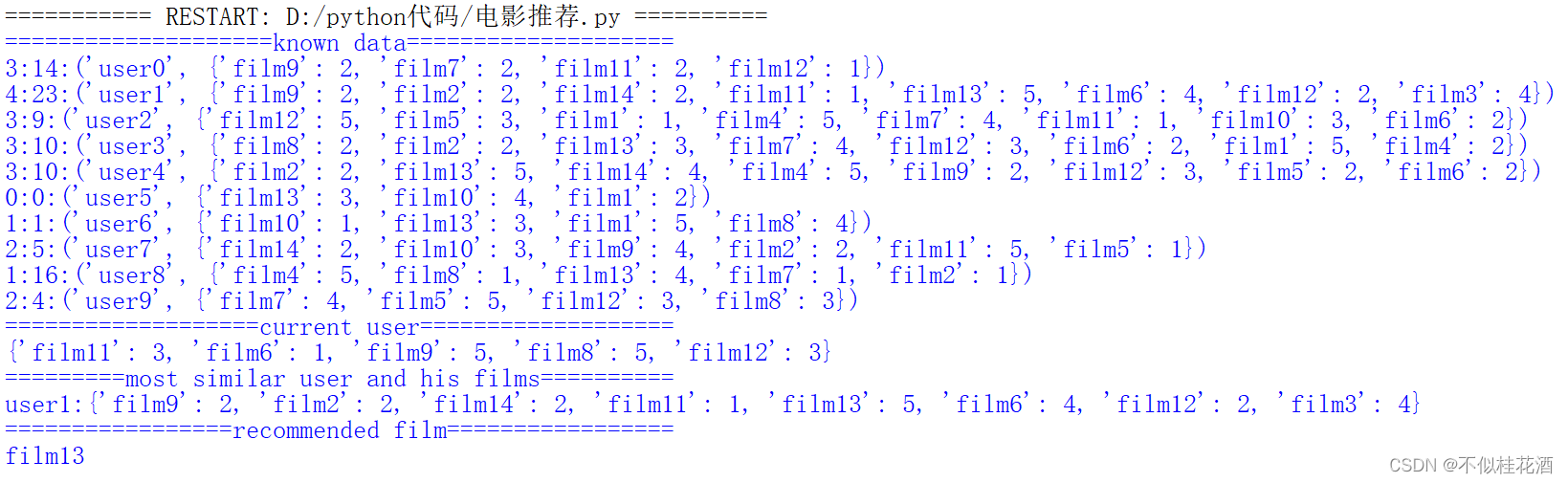
2.4.4集合推导式
>>>s={x.strip() for x in (' he ',' she ' , ',',' I ')} #.strip():去除字符串两边的空格
>>>s
{'she', 'I', ',', 'he'}
2.5再谈内置函数sorted()
列表对象提供了sort()方法支持原地排序,而内置函sorted()返回新列表,并不对原列表进行任何修改。
sorted()方法可以对列表、元组、字典、range对象进行排序。
列表的sort()方法和内置函数sorted()都支持key参数实现复杂排序要求,reverse指定升序还是降序。
(1)key参数
#一个列表,列表中每个元素是一个字典,字典里有name和age两个元组
>>>persons=[{'name':'Dong','age':37},{'name':'Zhang','age':40},{'name':'Li','age':50},{'name':'Dong','age':43}]
>>>print(persons)
[{'name': 'Dong', 'age': 37}, {'name': 'Zhang', 'age': 40}, {'name': 'Li', 'age': 50}, {'name': 'Dong', 'age': 43}]#使用key来指定排序依据,先按姓名升序排序,姓名相同的按年龄降序排序
#给person排序,规则key是一个lambda函数,这个函数的参数是x,x是字典里的每个元素:返回值是一个元组(字典里name对应的值,-age对应的值);最后是元组的比较,先比较第一个元素;-实现降序排列,仅限数值型
>>>print(sorted(persons,key=lambda x:(x['name'],-x['age'])))
[{'name': 'Dong', 'age': 43}, {'name': 'Dong', 'age': 37}, {'name': 'Li', 'age': 50}, {'name': 'Zhang', 'age': 40}]
(2)from operator import itemgetter
>>>phonebook={'Linda':'7750','Bob':'9345','Carol':'5834'}
>>>from operator import itemgetter #根据元素获取其中的内容
>>>sorted(phonebook.items(),key=itemgetter(1)) #itemgetter(1),获取每个元组位置是1的元素,也就是按字典中元素的值进行排序,默认升序[('Carol', '5834'), ('Linda', '7750'), ('Bob', '9345')]
>>>sorted(phonebook.items(),key=itemgetter(0)) #itemgetter(0)按字典中元素的键进行排序
[('Bob', '9345'), ('Carol', '5834'), ('Linda', '7750')]
>>>gameresult=[['Bob',95.0,'A'],['Alan',86.0,'C'],['Mandy',83.5,'A'],['Rob',89.3,'E']]
>>>sorted(gameresult,key=itemgetter(0,1)) #按姓名升序,姓名相同按分数升序排序
[['Alan', 86.0, 'C'], ['Bob', 95.0, 'A'], ['Mandy', 83.5, 'A'], ['Rob', 89.3, 'E']]>>>sorted(gameresult,key=itemgetter(1,0)) #按分数升序,分数相同按姓名升序排序
[['Mandy', 83.5, 'A'], ['Alan', 86.0, 'C'], ['Rob', 89.3, 'E'], ['Bob', 95.0, 'A']]>>>sorted(gameresult,key=itemgetter(2,0)) #按等级升序,等级相同按姓名升序
[['Bob', 95.0, 'A'], ['Mandy', 83.5, 'A'], ['Alan', 86.0, 'C'], ['Rob', 89.3, 'E']]
>>>gameresult=[{'name':'Bob','Wins':10,'losses':3,'rating':75.0},{'name':'David','Wins':3,'losses':5,'rating':57.0},{'name':'Carol','Wins':4,'losses':5,'rating':75.0},{'name':'Patty','Wins':9,'losses':3,'rating':72.8}]
>>>sorted(gameresult,key=itemgetter('Wins','name')) #对gameresult进行排序,按Wins升序,该值相同的按name升序排序
[{'name': 'David', 'Wins': 3, 'losses': 5, 'rating': 57.0}, {'name': 'Carol', 'Wins': 4, 'losses': 5, 'rating': 75.0}, {'name': 'Patty', 'Wins': 9, 'losses': 3, 'rating': 72.8}, {'name': 'Bob', 'Wins': 10, 'losses': 3, 'rating': 75.0}]
根据另一个列表的值对当前元素进行排序
>>>list1=["what","I`m","sorting","by"]
>>>list2=["something","else","to","sort"]
>>>pairs=zip(list1,list2)
>>>pairs=sorted(pairs) #对每对元组进行排序,也就是每个元组的第一个元素,第一个元素一样,按第二个元素进行排序,默认都是升序排序
>>>pairs
[('I`m', 'else'), ('by', 'sort'), ('sorting', 'to'), ('what', 'something')]>>>result=[x[1] for x in pairs] #留下pairs每对的元组下标为1的元素
>>>result
['else', 'sort', 'to', 'something']
2.6复杂数据结构
在解决时间问题时,还经常需要用到其他复杂的数据结构,如堆、栈、队列、树、图等等。
有些结构python已经提供,而有的则需要自己利用基本数据结构来实现。
2.6.1 堆
(1)2i+1和2i+2
>>>import heapq #heapq和random是python标准库
>>>import random>>>data=list(range(10))
>>>data
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]>>>random.choice(data) #随机选择一个元素
6>>>random.shuffle(data) #随机打乱顺序
>>>data
[2, 8, 5, 9, 4, 3, 1, 0, 7, 6]>>>heap=[]
>>>for n in data: #建堆
heapq.heappush(heap,n) #.heappush使用入堆的方式,把元素n依次插入heap的适当位置
>>>heap
[0, 1, 2, 4, 6, 5, 3, 9, 7, 8] #入堆和出堆,都保持任意i位置上的元素小于2i+1和2i+2>>>heapq.heappush(heap,0.5) #往heap中插入一个元素0.5 #入堆,自动重建
>>>heap
[0, 0.5, 2, 4, 1, 5, 3, 9, 7, 8, 6]>>>heapq.heappop(heap) #出堆,.heappop从堆里弹出一个最小元素,自动重建
0
>>>myheap=[1,2,3,5,7,8,9,4,10,333]
>>>heapq.heapify(myheap) #把一个列表给建堆
>>>myheap
[1, 2, 3, 4, 7, 8, 9, 5, 10, 333]>>>heapq.heapreplace(myheap,6) #.heapreplace,弹出最小元素,同时插入新元素
1>>>myheap
[2, 4, 3, 5, 7, 8, 9, 6, 10, 333]>>>heapq.nlargest(3,myheap) #.nlargest返回前3个最大的元素
[333, 10, 9]>>>heapq.nsmallest(3,myheap) #.nsmallest返回前3个最小的元素
[2, 3, 4]
2.6.2 队列
可以使用列表来模拟队列结构
(1)先入先出,后入后出queue
#队列的特点是先入先出,后入后出
>>>x=[1,2,3,4] #使用列表来模拟队列 #删除只能从头部,插入只能从尾部
>>>x.pop(0)
1
>>>x.pop(0)
2
>>>x.append(5)
>>>x.pop(0)
3
>>>x.pop(0)
4>>>x.pop(0)
5
>>>x.pop(0)
Traceback (most recent call last):
File "<pyshell#63>", line 1, in <module>
x.pop(0)
IndexError: pop from empty list
>>>import queue #queue是python标准库
>>>q=queue.Queue() #返回的是一个队列,也就是创建一个队列(空的)
>>>q.put(0) #入队,在尾部追加元素的(在后面插入一个)
>>>q.put(1)
>>>q.put(2)
>>>q.queue
deque([0, 1, 2])>>>q.get() #出队,从首部去获取元素(从前面获取一个)
0>>>q.queue #查看队列中的元素
deque([1, 2])>>>q.get()
1>>>q.queue
deque([2])
>>>import queue
>>>q=queue.Queue()
>>>q.get(timeout=2) #当队列是空的,等待2秒,看有没有人往里面放东西。两秒内方法东西,取出来;两秒内,没放东西抛出异常 #不写timeout的时间就会一直等下去
Traceback (most recent call last):
File "<pyshell#76>", line 1, in <module>
q.get(timeout=2)
_queue.Empty
>>>q=queue.Queue(3) #指定队列的长度
>>>q
<queue.Queue object at 0x0000022236A8F8E0>
>>>q.queue
deque([])>>>q.put(1)
>>>q.put(2)
>>>q.put(3)
>>>q.queue
deque([1, 2, 3])>>>q.put(4) #放不进去了,一直等待
(2)“后进先出”队列LifoQueue
queue模块还提供了“后进先出”队列和优先级队列
>>>from queue import LifoQueue #LIFO队列(last in fist out 后入先出队列)
>>>q=LifoQueue() #创建队列对象
>>>q.put(1) #在队列尾部插入元素
>>>q.put(2)
>>>q.put(3)>>>q.queue #查看队列中所有元素
[1, 2, 3]>>>q.get() #返回并删除队列尾部元素
3
>>>q.get()
2
>>>q.queue
[1]
>>>q.get()
1
>>>q.get() #对空队列调用get()方法会阻塞当前线程
(3)优先级队列PriorityQueue
>>>from queue import PriorityQueue #优先级队列
>>>q=PriorityQueue() #创建优先级队列对象
>>>q.put(3) #插入元素
>>>q.put(8) #插入元素
>>>q.put(100) #查看优先级队列中所有元素
>>>q.queue
[3, 8, 100]>>>q.put(1) #插入元素自动调正优先级队列
>>>q.put(2)
>>>q.queue
[1, 2, 100, 8, 3]>>>q.get() #返回并删除优先级最低的元素
1
>>>q.get()
2
>>>q.get()
3
(4)双端队列deque
python标准库collections提供了双端队列deque
>>>from collections import deque
>>>q=deque(maxlen=5) #创建双端队列,大小为5
>>>for item in [3,5,7,9,11]: #添加元素
q.append(item)
>>>q.append(13) #默认从右边添加,会把左边的挤出去。队列满,自动溢出
>>>q.append(15)
>>>q
deque([7, 9, 11, 13, 15], maxlen=5)
>>>q.appendleft(5) #从左侧添加元素,右侧自动溢出
>>>q
deque([5, 7, 9, 11, 13], maxlen=5)
2.6.3 栈
(1)先进后出(FILO)
栈是一种“后进先出(LIFO)”或“先进后出(FILO)”的数据结构。
python列表本身就可以实现栈结构的基本操作。例如,列表对象的append()方法就是在列表尾部追加元素,类似于入栈操作;pop()方法默认是弹出并返回列表的最后一个元素,类似于出栈操作。
但直接使用python列表对象模拟栈操作并不是很方便,例如当列表为空时再执行pop()出栈操作时,则会抛出一个很不友好的异常;另外,也无法限制栈的大小。
可以直接使用列表来实现栈结构
>>>myStack=[]
>>>myStack.append(3)
>>>myStack.append(5)
>>>myStack.append(7)
>>>myStack
[3, 5, 7]>>>myStack.pop()
7
>>>myStack.pop()
5
>>>myStack.pop()
3
>>>myStack.pop()
Traceback (most recent call last):
File "<pyshell#34>", line 1, in <module>
myStack.pop()
IndexError: pop from empty list
参考:
Python序列1:列表创建与元素增加_哔哩哔哩_bilibili
Python序列2:列表元素增加与删除_哔哩哔哩_bilibili
Python序列3:列表切片操作_哔哩哔哩_bilibili
Python序列6:序列解包与生成器表达式_哔哩哔哩_bilibili
Python序列7:字典语法及应用_哔哩哔哩_bilibili
Python序列8:集合语法及应用_哔哩哔哩_bilibili

