
- 1【Python】pandas:排序、重复值、缺省值处理、合并、分组
- 2Postman 无法请求https_postman 请求 invalid app id in request
- 3Python中的第三方库_python常用第三方库
- 4动态规划斐波那契_c++ 动态规划 斐波那契
- 5如何配置Gitlab的双因子验证(Two-Factor Authentication)_gitlab two-factor authentication
- 6动手编写一个以太坊智能合约_ts 写以太坊合约
- 7XCode各版本与Mac OS各版本对应列表
- 8第五届大数据、人工智能与软件工程国际研讨会(ICBASE 2024)
- 92024年软件测试最新Jmeter tcp 压测实践_jmeter tcp压测 close,2024年最新理解透彻_用jmeter做tcp压力测试
- 10openmv和K210零基础快速上手训练模型识别_openmv人脸识别 训练模型
【NLP】基于Transformer的机器翻译(日->中)
赞
踩
一、数据预处理
1.1导入相关库
- import math # 导入数学模块,用于数学函数
- import torch # 导入PyTorch库
- import torch.nn as nn # 从PyTorch导入神经网络模块
- from torch import Tensor # 从PyTorch导入Tensor类
- from torch.nn.utils.rnn import pad_sequence # 从PyTorch导入pad_sequence函数,用于序列填充
- from torch.utils.data import DataLoader # 从PyTorch导入DataLoader,用于批处理数据加载
- from collections import Counter # 从collections模块导入Counter,用于计数可哈希对象
- from torchtext.vocab import Vocab # 从torchtext.vocab导入Vocab类,用于处理词汇表
- from torch.nn import TransformerEncoder, TransformerDecoder, TransformerEncoderLayer, TransformerDecoderLayer
- # 从PyTorch导入Transformer模块,包括Transformer编码器和解码器相关类
- import io # 导入io模块,用于处理流
- import time # 导入time模块,用于时间相关功能
- import pandas as pd # 导入pandas库,用于数据处理和分析
- import numpy as np # 导入numpy库,用于数值操作
- import pickle # 导入pickle模块,用于Python对象的序列化和反序列化
- import tqdm # 导入tqdm模块,用于显示进度条
- import sentencepiece as spm # 导入sentencepiece,用于分词
-
- torch.manual_seed(0) # 设置PyTorch的随机种子,以确保实验结果可重现
- device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
- # 检查并将设备设置为GPU(如果可用),否则设置为CPU
- # print(torch.cuda.get_device_name(0))
-

1.2数据获取
我们使用“zh-ja.bicleaner05.txt”文件作为我们中日翻译的训练数据,共83892条文本
链接:https://pan.baidu.com/s/1xpVigy3leO0L28sQf95lBw
提取码:57y8
 注意:
注意:
以下代码/注释中的en/“英文”均理解为zh/“中文”(因为我们的任务是日译中而非日译英)
- # 读取CSV文件到DataFrame中,使用制表符 '\t' 作为分隔符进行解析
- df = pd.read_csv('zh-ja.bicleaner05.txt', sep='\\t', engine='python', header=None)
-
- # 从DataFrame中选择第3列(索引为2的列),并将其转换为Python列表 trainen
- # 这里使用 .values.tolist() 将DataFrame列转换为包含所有数据的列表
- trainen = df[2].values.tolist()
-
- # 从DataFrame中选择第4列(索引为3的列),并将其转换为Python列表 trainja
- # 同样使用 .values.tolist() 将DataFrame列转换为包含所有数据的列表
- trainja = df[3].values.tolist()
-
1.3数据处理
1.3.1分词处理
与英语或其他字母语言不同,日语句子中不包含用于分隔单词的空格。我们可以使用JParaCrawl提供的分词器,该分词器是使用SentencePiece为日语和英语创建的(我们用英文的分词器来训练中文,大家可以自行选择更好的中文分词器),可以通过访问JParaCrawl网站来下载它们
链接:https://pan.baidu.com/s/1bYiJcfU6bD5AgIv2PEU1Xg
提取码:ivtw
- # 初始化一个 SentencePieceProcessor 对象用于英文分词处理
- # 'spm.en.nopretok.model'模型文件包含了预先训练的分词器配置
- en_tokenizer = spm.SentencePieceProcessor(model_file='spm.en.nopretok.model')
-
- # 初始化一个 SentencePieceProcessor 对象用于日文分词处理
- # 'spm.ja.nopretok.model'模型文件包含了预先训练的分词器配置
- ja_tokenizer = spm.SentencePieceProcessor(model_file='spm.ja.nopretok.model')
在加载分词器后,你可以通过执行以下代码来测试它们
- en_tokenizer.encode("All residents aged 20 to 59 years who live in Japan must enroll in public pension system.", out_type='str')
-
- ja_tokenizer.encode("年金 日本に住んでいる20歳~60歳の全ての人は、公的年金制度に加入しなければなりません。", out_type='str')

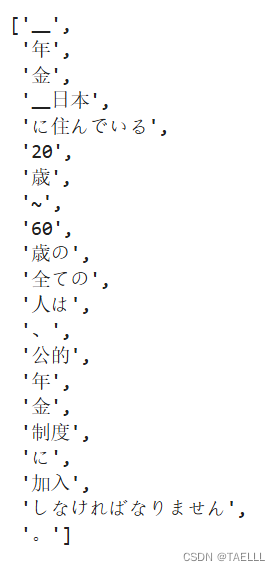
1.3.2构建词汇表
使用分词器处理原始文本数据后,接下来的步骤是利用TorchText库创建词汇表对象
构建词汇表所需的时间会受到数据集规模和计算机性能的影响,可能从几秒钟到几分钟不等。此外,选用的分词器种类也会对构建词汇表的速度产生影响。在尝试了多个日语分词器之后,SentencePiece在效果和速度上都比较理想
- # 定义一个函数用于构建词汇表
- def build_vocab(sentences, tokenizer):
- # 使用 Counter 对象来统计词频
- counter = Counter()
-
- # 遍历每个句子
- for sentence in sentences:
- # 使用指定的分词器 tokenizer 对句子进行分词,并更新词频统计
- counter.update(tokenizer.encode(sentence, out_type=str))
-
- # 使用统计的词频创建一个 Vocab 对象,同时指定特殊符号
- return Vocab(counter, specials=['<unk>', '<pad>', '<bos>', '<eos>'])
-
- # 使用 build_vocab 函数构建日语的词汇表 ja_vocab
- ja_vocab = build_vocab(trainja, ja_tokenizer)
-
- # 使用 build_vocab 函数构建英语的词汇表 en_vocab
- en_vocab = build_vocab(trainen, en_tokenizer)
1.3.3构建张量
当我们有了词汇表对象后,接下来我们可以使用这些词汇表和分词器对象来为训练数据构建张量
- # 定义一个函数用于处理日语和英语文本数据,将其转换为模型可以处理的张量形式
- def data_process(ja, en):
- data = []
- # 使用 zip 函数同时迭代日语列表 ja 和英语列表 en 中的元素
- for (raw_ja, raw_en) in zip(ja, en):
- # 使用日语分词器 ja_tokenizer 对 raw_ja 进行分词,并转换为对应的索引张量 ja_tensor_
- ja_tensor_ = torch.tensor([ja_vocab[token] for token in ja_tokenizer.encode(raw_ja.rstrip("\n"), out_type=str)],
- dtype=torch.long)
-
- # 使用英语分词器 en_tokenizer 对 raw_en 进行分词,并转换为对应的索引张量 en_tensor_
- en_tensor_ = torch.tensor([en_vocab[token] for token in en_tokenizer.encode(raw_en.rstrip("\n"), out_type=str)],
- dtype=torch.long)
-
- # 将处理后的日语张量和英语张量作为元组添加到 data 列表中
- data.append((ja_tensor_, en_tensor_))
-
- return data
-
- # 使用 data_process 函数处理训练数据 trainja 和 trainen,生成 train_data
- train_data = data_process(trainja, trainen)
1.3.4创建DataLoader对象
此外,为了适应不同的硬件资源和数据规模,我们需要创建一个DataLoader对象,以便在模型训练过程中进行高效的数据迭代
为避免内存不足,我将BATCH_SIZE设置为16,在训练时可以根据自己的实际情况来调整批次大小
- # 定义批处理大小
- BATCH_SIZE = 8
-
- # 获取特殊符号在日语词汇表中的索引
- PAD_IDX = ja_vocab['<pad>']
- BOS_IDX = ja_vocab['<bos>']
- EOS_IDX = ja_vocab['<eos>']
-
- # 定义生成批次数据的函数
- def generate_batch(data_batch):
- ja_batch, en_batch = [], []
- for (ja_item, en_item) in data_batch:
- # 在日语句子的开头和结尾添加起始和结束符号,并将其转换为张量
- ja_batch.append(torch.cat([torch.tensor([BOS_IDX]), ja_item, torch.tensor([EOS_IDX])], dim=0))
-
- # 在英语句子的开头和结尾添加起始和结束符号,并将其转换为张量
- en_batch.append(torch.cat([torch.tensor([BOS_IDX]), en_item, torch.tensor([EOS_IDX])], dim=0))
-
- # 使用 pad_sequence 函数对日语批次数据进行填充,padding_value 参数指定填充值为 PAD_IDX
- ja_batch = pad_sequence(ja_batch, padding_value=PAD_IDX)
-
- # 使用 pad_sequence 函数对英语批次数据进行填充,padding_value 参数指定填充值为 PAD_IDX
- en_batch = pad_sequence(en_batch, padding_value=PAD_IDX)
-
- # 返回填充后的日语批次数据和英语批次数据
- return ja_batch, en_batch
-
- # 使用 DataLoader 加载训练数据 train_data,并将其转换为批次数据 train_iter
- train_iter = DataLoader(train_data, batch_size=BATCH_SIZE,
- shuffle=True, collate_fn=generate_batch)
二、Seq2Seq模型—Transformer
2.1构建模型
- from torch.nn import (TransformerEncoder, TransformerDecoder,
- TransformerEncoderLayer, TransformerDecoderLayer)
-
- class Seq2SeqTransformer(nn.Module):
- def __init__(self, num_encoder_layers: int, num_decoder_layers: int,
- emb_size: int, src_vocab_size: int, tgt_vocab_size: int,
- dim_feedforward:int = 512, dropout:float = 0.1):
- # 初始化Seq2SeqTransformer类,继承自nn.Module
- super(Seq2SeqTransformer, self).__init__()
- # 创建Transformer编码器层
- encoder_layer = TransformerEncoderLayer(d_model=emb_size, nhead=NHEAD,
- dim_feedforward=dim_feedforward)
- # 创建Transformer编码器
- self.transformer_encoder = TransformerEncoder(encoder_layer, num_layers=num_encoder_layers)
- # 创建Transformer解码器层
- decoder_layer = TransformerDecoderLayer(d_model=emb_size, nhead=NHEAD,
- dim_feedforward=dim_feedforward)
- # 创建Transformer解码器
- self.transformer_decoder = TransformerDecoder(decoder_layer, num_layers=num_decoder_layers)
-
- # 创建生成器,用于将编码器的输出转换为目标词汇表的大小
- self.generator = nn.Linear(emb_size, tgt_vocab_size)
- # 创建源语言的词嵌入层
- self.src_tok_emb = TokenEmbedding(src_vocab_size, emb_size)
- # 创建目标语言的词嵌入层
- self.tgt_tok_emb = TokenEmbedding(tgt_vocab_size, emb_size)
- # 创建位置编码层
- self.positional_encoding = PositionalEncoding(emb_size, dropout=dropout)
-
- def forward(self, src: Tensor, trg: Tensor, src_mask: Tensor,
- tgt_mask: Tensor, src_padding_mask: Tensor,
- tgt_padding_mask: Tensor, memory_key_padding_mask: Tensor):
- # 对源语言序列进行词嵌入和位置编码
- src_emb = self.positional_encoding(self.src_tok_emb(src))
- # 对目标语言序列进行词嵌入和位置编码
- tgt_emb = self.positional_encoding(self.tgt_tok_emb(trg))
- # 使用编码器对源语言序列进行编码
- memory = self.transformer_encoder(src_emb, src_mask, src_padding_mask)
- # 使用解码器对目标语言序列进行解码
- outs = self.transformer_decoder(tgt_emb, memory, tgt_mask, None,
- tgt_padding_mask, memory_key_padding_mask)
- # 使用生成器将解码器的输出转换为目标词汇表的大小
- return self.generator(outs)
-
- def encode(self, src: Tensor, src_mask: Tensor):
- # 对源语言序列进行词嵌入和位置编码,然后使用编码器进行编码
- return self.transformer_encoder(self.positional_encoding(
- self.src_tok_emb(src)), src_mask)
-
- def decode(self, tgt: Tensor, memory: Tensor, tgt_mask: Tensor):
- # 对目标语言序列进行词嵌入和位置编码,然后使用解码器进行解码
- return self.transformer_decoder(self.positional_encoding(
- self.tgt_tok_emb(tgt)), memory,
- tgt_mask)
2.2位置编码
- class PositionalEncoding(nn.Module):
- def __init__(self, emb_size: int, dropout, maxlen: int = 5000):
- super(PositionalEncoding, self).__init__()
- # 计算位置编码的分母
- den = torch.exp(- torch.arange(0, emb_size, 2) * math.log(10000) / emb_size)
- # 生成位置序列
- pos = torch.arange(0, maxlen).reshape(maxlen, 1)
- # 初始化位置嵌入矩阵
- pos_embedding = torch.zeros((maxlen, emb_size))
- # 计算位置嵌入矩阵的偶数列
- pos_embedding[:, 0::2] = torch.sin(pos * den)
- # 计算位置嵌入矩阵的奇数列
- pos_embedding[:, 1::2] = torch.cos(pos * den)
- # 增加一个维度
- pos_embedding = pos_embedding.unsqueeze(-2)
-
- # 定义dropout层
- self.dropout = nn.Dropout(dropout)
- # 注册位置嵌入矩阵为buffer,不会被训练
- self.register_buffer('pos_embedding', pos_embedding)
-
- def forward(self, token_embedding: Tensor):
- # 将位置嵌入矩阵与输入的词嵌入相加,并应用dropout
- return self.dropout(token_embedding +
- self.pos_embedding[:token_embedding.size(0),:])
-
- class TokenEmbedding(nn.Module):
- def __init__(self, vocab_size: int, emb_size):
- super(TokenEmbedding, self).__init__()
- # 定义词嵌入层
- self.embedding = nn.Embedding(vocab_size, emb_size)
- self.emb_size = emb_size
-
- def forward(self, tokens: Tensor):
- # 将输入的token转换为对应的词嵌入,并进行缩放
- return self.embedding(tokens.long()) * math.sqrt(self.emb_size)
2.3构建掩码
- # 定义一个函数,用于生成平方矩阵的掩码
- def generate_square_subsequent_mask(sz):
- # 创建一个上三角矩阵,然后转置得到下三角矩阵
- mask = (torch.triu(torch.ones((sz, sz), device=device)) == 1).transpose(0, 1)
- # 将掩码中的0和1分别替换为负无穷和0
- mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
- return mask
-
- # 定义一个函数,用于创建源序列和目标序列的掩码
- def create_mask(src, tgt):
- # 获取源序列和目标序列的长度
- src_seq_len = src.shape[0]
- tgt_seq_len = tgt.shape[0]
-
- # 生成目标序列的掩码
- tgt_mask = generate_square_subsequent_mask(tgt_seq_len)
- # 创建一个全零矩阵作为源序列的掩码
- src_mask = torch.zeros((src_seq_len, src_seq_len), device=device).type(torch.bool)
-
- # 获取源序列和目标序列的填充掩码
- src_padding_mask = (src == PAD_IDX).transpose(0, 1)
- tgt_padding_mask = (tgt == PAD_IDX).transpose(0, 1)
- return src_mask, tgt_mask, src_padding_mask, tgt_padding_mask
2.4参数设置与定义训练评估函数
- # 设置源语言词汇表大小
- SRC_VOCAB_SIZE = len(ja_vocab)
- # 设置目标语言词汇表大小
- TGT_VOCAB_SIZE = len(en_vocab)
- # 设置嵌入层大小
- EMB_SIZE = 512
- # 设置多头注意力机制的头数
- NHEAD = 8
- # 设置前馈神经网络隐藏层维度
- FFN_HID_DIM = 512
- # 设置批量大小
- BATCH_SIZE = 16
- # 设置编码器层数
- NUM_ENCODER_LAYERS = 3
- # 设置解码器层数
- NUM_DECODER_LAYERS = 3
- # 设置训练轮数
- NUM_EPOCHS = 16
- # 创建Seq2SeqTransformer模型实例
- transformer = Seq2SeqTransformer(NUM_ENCODER_LAYERS, NUM_DECODER_LAYERS,
- EMB_SIZE, SRC_VOCAB_SIZE, TGT_VOCAB_SIZE,
- FFN_HID_DIM)
-
- # 初始化模型参数
- for p in transformer.parameters():
- if p.dim() > 1:
- nn.init.xavier_uniform_(p)
-
- # 将模型放到设备上(GPU或CPU)
- transformer = transformer.to(device)
-
- # 定义损失函数,忽略PAD_IDX位置的损失
- loss_fn = torch.nn.CrossEntropyLoss(ignore_index=PAD_IDX)
-
- # 定义优化器
- optimizer = torch.optim.Adam(
- transformer.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9
- )
-
- # 定义一个训练周期的函数
- def train_epoch(model, train_iter, optimizer):
- model.train()
- losses = 0
- for idx, (src, tgt) in enumerate(train_iter):
- src = src.to(device)
- tgt = tgt.to(device)
-
- tgt_input = tgt[:-1, :]
-
- src_mask, tgt_mask, src_padding_mask, tgt_padding_mask = create_mask(src, tgt_input)
-
- logits = model(src, tgt_input, src_mask, tgt_mask,
- src_padding_mask, tgt_padding_mask, src_padding_mask)
-
- optimizer.zero_grad()
-
- tgt_out = tgt[1:,:]
- loss = loss_fn(logits.reshape(-1, logits.shape[-1]), tgt_out.reshape(-1))
- loss.backward()
-
- optimizer.step()
- losses += loss.item()
- return losses / len(train_iter)
-
- # 定义一个评估模型的函数
- def evaluate(model, val_iter):
- model.eval()
- losses = 0
- for idx, (src, tgt) in (enumerate(valid_iter)):
- src = src.to(device)
- tgt = tgt.to(device)
-
- tgt_input = tgt[:-1, :]
-
- src_mask, tgt_mask, src_padding_mask, tgt_padding_mask = create_mask(src, tgt_input)
-
- logits = model(src, tgt_input, src_mask, tgt_mask,
- src_padding_mask, tgt_padding_mask, src_padding_mask)
- tgt_out = tgt[1:,:]
- loss = loss_fn(logits.reshape(-1, logits.shape[-1]), tgt_out.reshape(-1))
- losses += loss.item()
- return losses / len(val_iter)
2.5模型训练
- # 导入进度条库
- import tqdm
-
- # 定义训练轮数
- NUM_EPOCHS = 10
-
- # 使用tqdm库创建一个进度条,用于显示训练轮数的进度
- for epoch in tqdm.tqdm(range(1, NUM_EPOCHS+1)):
- # 记录当前时间,用于计算每轮训练所需的时间
- start_time = time.time()
-
- # 调用train_epoch函数进行一轮训练,并返回训练损失值
- train_loss = train_epoch(transformer, train_iter, optimizer)
-
- # 记录当前时间,用于计算每轮训练所需的时间
- end_time = time.time()
-
- # 打印当前轮数、训练损失值以及本轮训练所需时间
- print((f"Epoch: {epoch}, Train loss: {train_loss:.3f}, "
- f"Epoch time = {(end_time - start_time):.3f}s"))

2.6模型推理
- def greedy_decode(model, src, src_mask, max_len, start_symbol):
- # 将源序列和掩码移动到设备(如GPU)上
- src = src.to(device)
- src_mask = src_mask.to(device)
- # 使用模型对源序列进行编码,得到编码后的内存表示
- memory = model.encode(src, src_mask)
- # 初始化一个包含起始符号的目标序列 ys
- ys = torch.ones(1, 1).fill_(start_symbol).type(torch.long).to(device)
- # 循环生成目标序列
- for i in range(max_len-1):
- # 将内存表示移动到设备(如GPU)上
- memory = memory.to(device)
- # 创建目标序列的掩码
- memory_mask = torch.zeros(ys.shape[0], memory.shape[0]).to(device).type(torch.bool)
- tgt_mask = (generate_square_subsequent_mask(ys.size(0))
- .type(torch.bool)).to(device)
- # 使用模型对目标序列进行解码,得到输出概率分布
- out = model.decode(ys, memory, tgt_mask)
- out = out.transpose(0, 1)
- prob = model.generator(out[:, -1])
- # 选择概率最大的单词作为下一个单词
- _, next_word = torch.max(prob, dim = 1)
- next_word = next_word.item()
- # 将下一个单词添加到目标序列中
- ys = torch.cat([ys,
- torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=0)
- # 如果遇到结束符,则停止生成
- if next_word == EOS_IDX:
- break
- return ys
-
- def translate(model, src, src_vocab, tgt_vocab, src_tokenizer):
- # 将源文本转换为源序列
- tokens = [BOS_IDX] + [src_vocab.stoi[tok] for tok in src_tokenizer.encode(src, out_type=str)]+ [EOS_IDX]
- num_tokens = len(tokens)
- src = (torch.LongTensor(tokens).reshape(num_tokens, 1) )
- src_mask = (torch.zeros(num_tokens, num_tokens)).type(torch.bool)
- # 使用贪婪搜索算法生成目标序列
- tgt_tokens = greedy_decode(model, src, src_mask, max_len=num_tokens + 5, start_symbol=BOS_IDX).flatten()
- # 将目标序列转换为文本并返回
- return " ".join([tgt_vocab.itos[tok] for tok in tgt_tokens]).replace("<bos>", "").replace("<eos>", "")
接下来,我们只需调用翻译函数并传入所需的参数即可
translate(transformer, "辛いものが苦手な人は、辛味の入れすぎには注意が必要です!! 「関山 中尊寺」 腹ごしらえを済ませた後は、ついに「関山 中尊寺」へ。)", ja_vocab, en_vocab, ja_tokenizer)
- trainen.pop(6)
- trainja.pop(6)


-------------------------------------------------------------------------------分割线------------------------------------------------------------------------------------
此次训练使用RXT3090在Autodl JupyterLab进行训练

第一次租借服务器 配置过程遇到不少问题也学到很多
模型训练老师说只需要一顿饭的时间 看着训练一小时还没结果的我表示深深的困惑??! 陆陆续续中断、又重新训练浪费了我三四块大洋[可怜] [可怜]
最后发现一直卡在词汇表构建那里,原来是txt文件只上传了一半就开始运行,导致用的训练数据都是不完整的。这个教训我深深记住了! money不是问题,老师给我高高的分就可以了[拜托][拜托]

