
- 1Stable Diffusion Prompt用法_stable diffusion 反向提示词
- 2知识补充---vue2+scss+elementui+vuex_vue2 scss
- 3【Unity】Obi插件系列(四)—— Distance Fields、Particle attachments、Particle rendering_obi vertex和particle对应关系
- 4MFC中子线程中调用主线程的窗口指针_在mfc sdi程序任何地方引用主窗口hwnd
- 5渗透测试 ( 5 ) --- 扫描之王 nmap、渗透测试工具实战技巧合集
- 6Qt 错误提示1: invalid use of incomplete type ‘***‘
- 7Unity开发安卓游戏(2):基于安卓游戏的优化方案总结!_基于unity的安卓唇同步
- 8【YOLO系列result中的map、loss、pr、F1绘图】根据v5、v8、v7训练后生成的result文件用matplotlib进行绘图_怎么根据yolov5的训练结果重新画图?
- 9获取视频播放进度及播放百分比_前端获取2个视频的进度条
- 10EasyAR_实现AR涂涂乐_easyar 涂涂乐
存算一体与存内计算计算杂谈
赞
踩
存算一体与存内计算计算杂谈
参考文献链接
https://mp.weixin.qq.com/s/PkJDADkQjUhCDrNOyUc8bg
https://mp.weixin.qq.com/s/Uhq4zTrNyavscxlZvbNYgA
https://mp.weixin.qq.com/s/7DBRyslROM3KEOT-KNTUkA
https://mp.weixin.qq.com/s/N6_09MhCho-UHJV6kSRnNw
存内计算爆发
存算一体的基本概念最早可以追溯到上个世纪七十年代,但是受限于芯片设计复杂度与制造成本问题,以及缺少杀手级大数据应用进行驱动,存算一体一直不温不火,但最近几年,存算一体似乎已经进入爆发前夕。
尤其是国内一大批存算一体技术公司伴随着融资信息浮出水面,如知存科技、苹芯科技、九天睿芯、后摩智能、合肥恒烁、闪忆科技、新忆科技、杭州智芯科等,动辄亿元起的融资金额也充分证明了资本对存算一体这个赛道的青睐。国外的三星和Myhtic也是该领域的潜心研究者,近来也动作频频,在最近的hotchips上,三星就披露了HBM-PIM方案,Myhtic的存算一体模拟AI芯片也有了新进展。一个新的存储计算时代似乎将要来临。
存内计算市场为何被看好?
今年5月Myhtic C轮融资了7000万美元,迄今为止已共计筹集了1.65亿美元;6月10日,知存科技宣布完成亿元A3轮融资,产品线扩充及新的产品量产,加上此前的两轮融资,截至目前,知存科技已完成累计近3亿元的A轮系列融资;6月25日九天睿芯获亿元级A轮融资,用于新产品研发和人员扩充的工作;7月2日,杭州智芯科完成近亿元的天使轮融资,用于继续搭建团队,启动ACIM下一阶段技术研发与市场拓展;8月24日,后摩智能宣布完成3亿元人民币Pre-A轮融资,将用于加速芯片产品技术研发、团队拓展,早期市场布局及商业落地;8月24日,苹芯科技完成近千万美元Pre-A轮融资,据悉,本轮融资将主要用于芯片研发相关工作。
从融资金额的用途也可以窥见,这些存算一体芯片公司有的处于团队搭建阶段,有的是正在芯片研发阶段,还有的已经到了产品线扩充和量产阶段。前几年(2019年左右)这个市场国内也就仅有3-4家崭露头角的企业,但现在存算一体这个赛道显然已经开始变得热闹起来了。
动辄亿元的资本涌入,前仆后继的玩家踊跃跳入。为何存算一体芯片市场会如此被看好?
存算一体技术(PIM :Processing in-memory)被视为人工智能创新的核心。将存储和计算有机结合,直接利用存储单元进行计算,极大地消除了数据搬移带来的开销,解决了传统芯片在运行人工智能算法上的“存储墙”与“功耗墙”问题,可以数十倍甚至百倍地提高人工智能运算效率,降低成本。
在知存科技CEO王绍迪的眼中,一直看好存算一体技术的原因有三:一是算力和运算数据量每年都在指数级增加,然而摩尔定律已经接近于到极限,每代芯片只有10-20%的性能提升。二是冯诺依曼架构的算力已经被内存墙所限制,只有解决内存墙问题才能进一步提高算力。在各种解决方案中,存内计算是最直接也是最高效的。
苹芯科技CEO杨越则认为,万物互联+的人工智能的时代已经到来。智能产品覆盖面积越来越大,产品形态的多样性将迎来爆发式的增长。可以预见,由于传输延迟或数据安全考虑,很多数据处理及推理运算将在端侧发生。通用性计算芯片在服务特定AI算法方面并不具备性价比优势,为AI定制的芯片将成为人工智能产业链条上的底层核心技术。存内计算作为创新性极强的芯片架构形式,由于突破了困扰业界多年的存储墙问题,且与深度学习网络运算模型中的基本算子高度契合,使得基于存内计算架构的芯片相比于市场已有的AI加速芯片,在计算效率(TOPS/Watt)方面有数量级上的提升。在智能时代里,从可穿戴到自动驾驶,功耗约束下场景里的计算效率都是永恒的主题,存内计算是解放算力、提升能效比最强有力的武器之一。
而且与其他低功耗计算,如低电压亚阈值数字逻辑ASIC、神经模态(Neuromorphics)计算和模拟计算比较,存内计算的优势也尽显。
王绍迪表示,低功耗亚阈值计算是对现有逻辑计算的功耗优化,一般能效可以提升2-4倍,但是算力相应降低,只能进行针对性的优化。而存内计算是新型的运算架构,做的是二维和三维矩阵运算,能效和算力可以提高100-1000倍。神经模态运算是为类脑算法而设计的芯片,有不同的实现方式,如模拟计算、数字计算、无时钟计算、或者存算一体的实现方式。其实上述三种技术解决的问题是不一样的。后摩尔时代下,无法通过工艺的提升来优化整体算力,异构计算和新架构变得更为重要。
在杨越看来,与亚阈值数字逻辑相比,存内计算仍工作在正常供电范围,可具有实现高算力的可能性。存内计算的原理就是模拟计算。存内计算与神经形态计算有交集,就是用存内计算的原理去实现synaptic connection,可提供高平行度、高能效地synaptic weighting的计算。
存内计算的三条主流技术路径
在认准了赛道之后,就是选择存内计算的技术路径。对于存算一体技术来说,处于多种存储介质百花齐放的格局,如SRAM,DRAM,Flash等。目前选择SRAM介质阵营的主要有苹芯科技、后摩智能、九天睿芯。Flash阵营的代表玩家有知存科技、合肥恒烁、美国的Mythic。DRAM阵营的还相对偏少。
那么该如何选择合适的技术路径,这些技术路径又有何特点、壁垒和优势呢?苹芯CEO杨越认为,技术路线选择的出发点有多个,包括工艺成熟度、加入计算功能的复杂度及结果精度、向上对神经网络算法要求的支持程度、以及落地成本等方面的考虑。
从器件工艺成熟度来看,知存科技认为,SRAM、DRAM和Flash都是成熟的存储技术,其中SRAM可以在先进工艺上如5nm上制造,DRAM和Flash可在10-20nm工艺上制造。密度方面,Flash最高,其次是DRAM,再次是SRAM。
在电路设计难度上,存内计算的DRAM > 存内计算SRAM > 存内计算Flash ,在存内计算方面,SRAM和DRAM更难设计,是易失性存储器,工艺偏差会大幅度增加模拟计算的设计难度,尤其是当容量增大到可实用的MB以上,目前市面上还没有SRAM和DRAM的存内计算产品;Flash是非易失存储器,他的状态是连续可编程的,可以通过编程等方式来校准工艺偏差,从而提高精度。而近存计算的设计相对简单,可采用成熟的存储器技术和逻辑电路设计技术。
而谈到量产难度方面,王绍迪给出的答案是DRAM> Flash >SRAM。
“过去做过多种存算一体介质的流片,包括Flash、SRAM、RRAM和MRAM。最终发现,Flash是密度最高的存储介质,Flash的单个单元可以存储的bit数最高(8-bit),这两个特点都可以大幅度增加存内计算的算力。”王绍迪告诉笔者,所以从密度、可量产性、能效层面多方面综合考量,知存科技最终选择了Flash介质。
杨越表示,Flash和SRAM 路线各自具备优势。选择SRAM方案出于几个考虑:一,SRAM的速度是所有memory类型中最快的,且没有写次数的限制,对于追求快响应的场景几乎是必选。二,SRAM可以向先进制程兼容,从而达到更高的能效比,更高的面效比等。三,苹芯现阶段的研究工作可大幅提高SRAM相关计算精度,从而降低了对相关上层算法补偿的要求。四,相对新型存储器,SRAM的工艺成熟度较高,可以相对较快的实现技术落地与量产。
存内计算的最终产品形态
在讨论存内计算最终的产品形态之前,让首先来看下存内计算的卖点究竟是什么?应该被认为是一个有计算能力的存储器,还是高能效比的计算模块。如果是前者,则往往需要和台积电等有志于推动下一代存储器的厂商一起合作。而后者则更倾向于以AI芯片的形式做design house。
苹芯CEO杨越认为,存内计算硬件的出现,本身在催生一种编程观念上的革命,也就不能再套用传统的功能上分离的思维去理解。从功能上来说,存内计算既可以存储数据,又可以做特定的计算,本身并不矛盾。从programmability的角度讲,面向AI 的存算一体技术的出现将会很大程度上影响人们如何去编写软件,或者说为更有效率的去编写软件提供了一个非常好的基础平台和机会。
知存科技王绍迪则表示,两种方案所需要解决的问题不一样:1)有算力的存储还是冯诺依曼架构下的存储器,做一些加密类和低算力计算,从而节省存储与CPU之间的带宽。存内计算是非冯诺依曼架构,通过存储单元完成二维和三维矩阵运算(这类运算占据了AI中95%以上的算力),提供大算力,存储数据是为了高效完成运算,本质不是做存储器。
对于存算产品,有芯片和IP两个选择。而目前观察到,大多数企业也都是以芯片为主。
“存内计算相关的IP是很难做的,存内计算针对的是运算场景,不是存储标品。需要针对不同场景的算力、成本、功耗需求提供更多种类的IP,并且针对不同的工艺去设计,需要投入的周期很长。从测试方面,客户集成存算IP的芯片需要增加特殊的测试步骤。个人觉得以单芯片和Chiplet形式提供存算一体算力是最佳的方式。”王绍迪告诉笔者。
存内计算的应用市场广阔,但仍需时间的打磨
关于存内计算的具体应用市场方向,王绍迪认为,存内计算的发展类似于存储器的发展路径,随着设计能力不断提升,工艺不断成熟、算力每年可以有5-10倍提升,能效每年会有1-2倍提升,成本每年会有30-50%下降,未来的存算产品可以用在大多数AI应用场景,因为成本算力能效都可以做到最优。
苹芯CEO杨越的观点是,存内计算的应用方向及产品形态将随着存算技术成熟度而演进。中早期产品将更多的出现在端侧对低功耗和高能效有强烈需求的场景下。值得强调的是,随着智能城市、智能生态等应用的普及,预测从边缘端接入的智能设备的市场体量将快速增长,应用场景的多样性也将不断快速拓展。长远地看,存算产品的适用范围也可能会延伸至超大算力领域,将持续积极探索,为未来的应用场景做好技术储备与战略规划。
据了解,目前苹芯已开发实现了多款基于SRAM的存内计算加速单元并已完成流片,处于外部测试和demo阶段,公司正与智慧穿戴、图像物体识别领域的头部客户做技术验证。
“存内计算技术的发展是一条追求高能效计算的重要技术路线,如何有效控制存内计算接口是一个重要挑战。谁拥有兼顾计算密度与存储密度的存内计算硬件架构,谁就拥有了打开高能效计算的金钥匙。未来的存内计算一定会渗透到大大小小各种规模的应用中去,大大提高计算的能量效率。”杨越坦言道。
在王绍迪看来,存算一体面临的挑战就是时间,还有很多事情没有做,这些都需要通过不断的实验去验证和解决,需要时间,还在发展初期,有广阔的提升空间,这也是最喜欢一点。距离存算一体的能力极限可能还有1000倍的空间,每年都能把提升2-5倍,随着算力提升和成本降低,应用场景会越来越广。
写在最后
“存算一体”打破了运行70年的冯诺依曼架构,将成为AI时代主流的计算架构。目前国内外在存算一体方面都处于起步阶段,存算一体正处于学术界向工业界迁移的关键时期,所以这可能是发展国产芯片的另一大重要方向。
存内计算浅谈

随着芯片制造技术的发展,到目前为止芯片的制造技术已经到达5nm,并且随着芯片制造工艺越来越小,芯片的集成度越来越高。1965年被戈登-摩尔提出来的摩尔定律,即当价格不变时,集成电路上可容纳的元器件的数目,约每隔 18-24 个月便会增加一倍,性能也将提升一倍,变得越来越不适用。通过减小晶体管的特征尺寸来提高芯片性能这一手段变得越来越困难。
01
大数据吞吐量给芯片架构带来挑战
摩尔定律 即将完全失效,“摩尔时代”即将结束。并且,人类科技发展中至今,已经进入人工智能时代,与之相关的机器学习,语音识别,图像识别等大量应用涌现,这些应用通常需要很大的计算量,基本的计算主要是线性代数运算,如张量处理,同时处理过程中参数量巨大。
并且随着应用的复杂性上升,神经网络的深度也会逐步提高,对数据的处理量也会爆发式增加。这些特点为目前冯-诺依曼架构的计算机带来巨大挑战,因为需要高效的计算处理,大量的数据存储,并且在计算和存储之间高速交换数据。
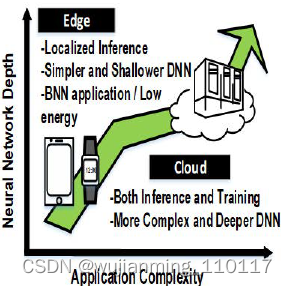
02冯-诺依曼架构带来的限制
冯-诺依曼架构的计算机有着俩个无法避免的问题:存储墙问题和功耗墙问题。这两大问题并称为冯-诺依曼瓶颈。所谓存储墙是指计算单元与存储单元速度的不匹配,在过去的20年至今,处理器的时钟频率和性能以超乎人们想象的速度提升着,但是内存的性能提升却却缓慢的多,导致处理的的时钟频率比存储器的时钟频率快的多,虽然cache和预存额能减小由于不匹配带来的问题,但是存储单元的速度依据影响着计算机速度的瓶颈。
功耗墙问题指由于物理上的分离处理器和存储器,数据信号需要在存储器和处理器之间来回进行频繁的传播。存储器和处理器之间的数据总线所带来的寄生电容和寄生电阻将导致信号传播延迟,以及额外的功耗损失,这就是所谓的功耗墙问题。
为了解决冯-诺伊曼瓶颈带来的问题,最直接的做法是增加数据总线的带宽或者时钟频率,增大数据总线的数据吞吐量。但是随之而来的就是更大的功耗和硬件电路开销。
另一种做法是将存储器和处理器的空间距离减少,减少数据传输距离,减小数据总线的长度,也就减少了数据总线的寄生电容和寄生电阻所引起的数据传播延迟和额外功率的消耗。
目前世界上各企业广泛研发和应用的是增加片上缓存这一手段,这一手段可以减小处理器和存储器速度不匹配所带来的问题。但是这些方法并没有改变存储器和处理器分离这一问题,也就仅仅是减少冯-诺伊曼瓶颈所带来的影响,并不能真正解决-诺伊曼结构的速度瓶颈问题。
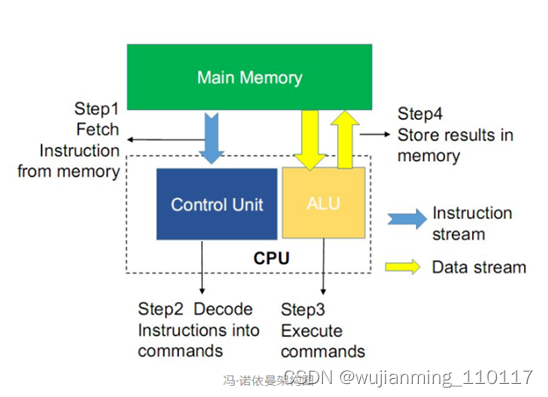
传统的冯-诺依曼体系架构的计算机遇到的冯-诺依曼瓶颈是物理上分离的存储器和处理器这一架构特性所带来的。针冯-诺依曼,学术界以及工业界正在寻找新的计算机体系结构来解决物理上分离的存储器和处理器所带来的存储器与处理器性能不匹配以及数据总线所带来的信号延迟和额外功耗这些问题。
根据目前学术研究,存内计算电路确实是一个解决冯-诺依曼瓶颈的方法。由于存算一体化,数据不需要在存储器和处理器之间来回传输,传输所需要的数据总线也可以不复存在。由数据总线带来的寄生电容和寄生电阻所引起的信号延迟和额外功率消耗问题也迎刃而解。并且存储和计算一体也解决了存储器和处理器速度不匹配所带来的问题。
传统的计算机架构是以计算为中心的,而存内计算则是以数据为中心的架构,直接利用存储器对数据进行直接处理,把数据的存储和计算融为一体,消除了冯-诺依曼瓶颈带来的问题,特别适用于需要大数据处理的领域,比如云计算以及人工智能等领域。
03存内计算
存内计算最初是由斯坦福研究所的Kautz等于1969年提出的。后续的研究工作主要围绕这一基本概念,在集成电路,计算机架构,操作系统等方面深入开展。早期,由于大数据,人工智能,云计算等需要大量数据处理的应用还没展开,存内计算仅仅停留在理论研究阶段,并未实现实际的应用。例如:加州大学伯克利分校的Patterson等在1997年通过把处理器集成在DRAM上,实现了存储与计算的结合。
近年来,随着大数据,人工智能等应用的兴起,人们又一次把目光投向了存内计算的研究。世界知名的IC企业和高校都推出了存内计算的架构,包括英特尔,英伟达,三星等。2010年,惠普实验室的Williams教授用忆阻器实现了简单的布尔逻辑运算。2016年,用于深度学习神经网络的RRAM存算一体架构被加州大学圣塔芭芭拉分校的谢源教授团队提出。该存算一体架构可以高效地实现向量-矩阵乘法运算,与传统的冯-诺依曼结构的计算机相比,在计算速度,功耗等方面有重大提升,被业界广泛关注。
除此之外,杜克大学,新加坡南洋理工大学,斯坦福大学以及英特尔,镁光等高校和企业也发表了相关论文,进行了相关芯片的测试。应着这阵风口,存内计算产业也开始迅猛发展,知存科技、九天睿芯、智芯科、后摩智能、苹芯科技等国内专注存内计算赛道的新兴公司纷纷获得融资,加速在该领域的早期市场布局及商业落地。
存内计算芯片的主流研发方向主要根据存储介质的不同分为俩类,即基于易失性存储器的存内计算架构以及基于非易失性存储器的存内计算架构。
随机存储器如DRAM,SRAM就是易失性存储器,缺点就是掉电后存储的数据会丢失。SRAM作为二值存储器可以用于存内计算电路,等效于XOR累加运算。SRAM存内计算的基本逻辑是将网络权重存在SRAM上,而神经网络的输入通过WL输入,从而完成乘加运算。
常见的非易性存储器如RRAM,PCM, FLASH闪存。其基本运算逻辑是将每个存储单元当做一个可变的电阻或者电导,通过编程操作将存储单元的电阻或者电导进行设置来代表网络权重值。再通过给每行施加激励电流或者电压信号,每一列就能得到乘加的模拟量结果。
综合来看,存内计算的实现基于相对成熟的易失性存储和不太成熟的非易失性存储,但无论是哪种路线的实现都存在一定的挑战,几大技术方向也都在发展中。易失性存储路线在融合处理器工艺和存储器工艺上存在诸多难题,在冯·诺依曼架构下,处理器与存储器的区隔明显,从设计、制造、封装全流程,各自都发展出了独立的生态,想要把两者融合成一体,其工艺难度可想而知。知存科技走的就是易失性存储路线,其CEO王绍迪曾形容过该路线早期开发的难度:“早期研发的时候,由于缺乏晶圆工厂和EDA工具的支持,开发工作很多就要从自动变成手动。”非易失性存储对存储目前厂商和工艺也均未成熟。
存内计算进展
图神经网络小样本学习广泛应用于推荐系统、社交网络、物理建模和芯片设计等领域,但其硬件实现面临着图数据特征提取困难、能耗高以及难以集成等问题。针对上述问题,微电子所重点实验室科研团队在40nm 256Kb RRAM 芯片上实现了图神经网络小样本学习的功能验证。在算法层面,研究团队开发了记忆增强图神经网络(Memory-augmented graph neural network, MAGNN)模型。该模型采用具有随机固定权重的回声状态图网络(Echo state graph neural network, ESGNN)作为控制器提取图数据特征,采用二值神经网络(Binary neural network, BNN)作为编码器,将全精度图数据特征向量转化为二值特征向量存储到外部记忆单元中用于检索。在硬件层面,研究团队采用40nm 256Kb RRAM芯片以存内计算方式实现了完整的MAGNN模型(包括控制器、编码器和外部记忆单元),并在引文网络CORA数据集上实现78%的准确率。相比于传统数字系统,基于RRAM芯片的MAGNN模型的核心检索延时和推理功耗分别降低70和60倍。基于该成果的文章“Few-shot graph learning with robust and energy-efficient memory-augmented graph neural network (MAGNN) based on homogeneous computing-in-memory”入选2022 VLSI。微电子所博士生张握瑜为第一作者,尚大山研究员和香港大学王中瑞博士为通讯作者。
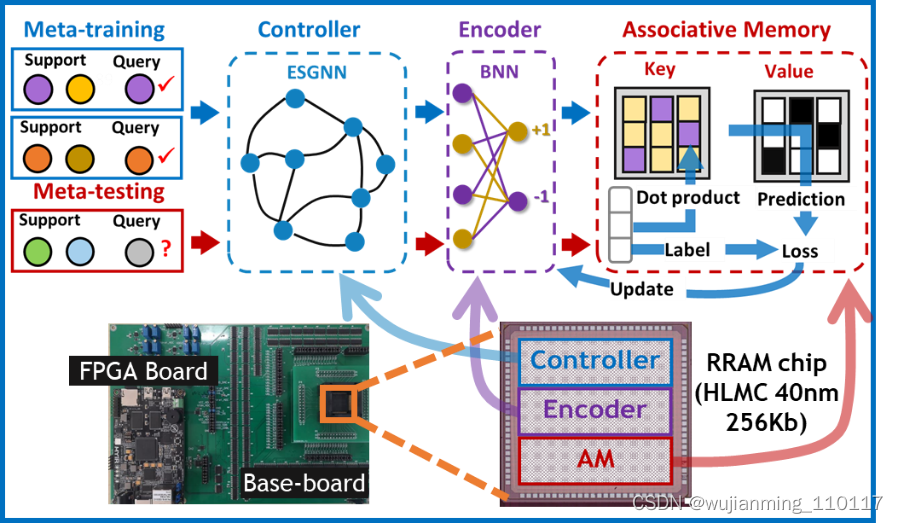
图1. 基于RRAM芯片的记忆增强图神经网络模型
自动驾驶芯片的算力焦虑
自动驾驶芯片,越来越「热闹」了。近年来,自动驾驶的普及以肉眼可见的速度加快,根据1月12日工信部数据,2021年新能源汽车销售352.1万辆,其中搭载组合辅助驾驶系统的乘用车新车市场占比达到20%。而两年前,L2级辅助驾驶的渗透率仅为3.3%。相伴而生的,是汽车「大脑」自动驾驶AI芯片的竞争加剧。英伟达、英特尔等老牌芯片企业早就瞄准了这一赛道,特斯拉、蔚来、小鹏等车企,黑芝麻、地平线、芯驰科技、寒武纪、后摩智能等国内芯片厂商也都纷纷入局。比如,蔚来汽车有自研芯片的计划;高通去年宣布和宝马合作,2025年使用高通骁龙Ride自动驾驶平台;初创公司有的直接聚焦在自动驾驶上,也有的业务范围更广,覆盖自动驾驶、智能座舱、中央网关、高可靠MCU等;收购、合作等关系网也在不断变动,这一战场的发令枪已经拉响了。然而,与常见的数据中心AI芯片不同,应用于汽车场景的AI芯片,在算力、功耗、性能方面都提出了更极端的要求。在摩尔定律逐渐失效、“存储墙”问题日益凸显的当下,汽车AI芯片到底需要提供多大算力?何种路径才是突破摩尔定律的存储墙壁垒的最接近落地方法?面对山头林立、秩序井然的芯片市场,初创公司的市场机遇和差异化优势又是什么?「存算一体」也许是个值得研究的答案。
一笔取舍账,自动驾驶需要多少算力
过去几年中,用于衡量一款自动驾驶芯片最直接的标准之一,就是算力高低。自动驾驶级别越高时,产生的数据越多,对芯片的算力要求也就越高。2014年时,最早应用Mobileye的第一代EyeQ芯片,算力只有0.256TOPS;2015年,就已有专门面向自动驾驶的平台,每年要迭代1-2次;英伟达也预告将在2025年上市1000T算力的Atlan芯片。算力的不断提升,是否意味着自动驾驶的需求已经得到了满足,自动驾驶玩家们可以跑出算力焦虑了?远还没有。一方面,大算力也意味着更高的成本。实际上在现有的自动驾驶芯片中,单片算力很难满足高级别自动驾驶的需求,车企或自动驾驶企业多会采取“堆料”的方式,用芯片数量的增加来实现大算力。成本的增加不可避免,难以推动自动驾驶技术的规模化应用,车企也很难实现技术和商业的平衡。另一方面,除了对算力需求高,智能驾驶场景也对芯片的功耗和散热有很高的要求。服务于丰田的创业者Amnon Shashua曾在多个场合表示过,效率比算力更重要。具体解释,算力、功耗、成本就像是一个三角架构,一角的增减要用另一角来填补才行。除此之外,「算力」并不真正代表着「性能」。1000Tops的芯片参数,并不意味着这块芯片在实际应用中能够发挥出1000Tops的真实性能。在当前的冯·诺伊曼架构当中,内存系统的性能提升速度大幅落后于处理器的性能提升速度,有限的内存带宽无法保证数据高速传输,形成了一道“存储墙”。一方面,大量的计算单元受限于带宽的限制,无法发挥作用,造成算力利用率很低;另一方面,数据来回传输又会产生巨大功耗,进一步加大汽车电动化大潮下的里程焦虑。因此,仅仅简单用算力高低来评估,远远达不到自动驾驶的需求。汽车AI芯片不仅需要大算力,更要有实际利用率的大算力,而且能够保障低功耗、低延迟以及可承受的成本。
存算一体,金字塔从头建起
为了解决“存储墙”问题,当前业内主要有三种方案:用GDDR 或HBM来解决存储墙问题的冯·诺依曼架构策略;算法和芯片高度绑定在一起的DSA方案;以及存算一体的方案。HBM是目前业内超大算力芯片常用的方案之一,其优势在于能够暂时缓解“存储墙”的困扰,但其性能天花板明显,并且成本较高。DSA方案以牺牲灵活性换取效率提升,算法和硬件高度耦合,适用于已经成熟的AI算法,但并不适用于正处于快速迭代的自动驾驶AI算法中。最后是存算一体方案,这是一项诞生于实验室的新兴技术,其创新性在于打破了传统·冯诺伊曼架构局限性,实现了计算与存储模块一体化的整合创新,解决了传统芯片架构中计算与存储模块间巨大的数据传输延迟、能量损耗痛点,既增加了数据处理速度,又大大降低了数据传输的功耗,从而使芯片能效比(即每瓦能提供的算力)得到2-3个数量级(>100倍)的提升。达摩院计算技术实验室科学家郑宏忠曾讲过:“存算一体是颠覆性的芯片技术,天然拥有高性能、高带宽和高能效的优势,可以从底层架构上解决后摩尔定律时代芯片的性能和能耗问题。”因此,存算一体架构可以把算力做的更大,其芯片算力天花板比传统冯·诺依曼架构更高;同时,大幅降低了数据传输的能量损耗,提升了能效比;另外,还能得到更低的延时,存储和计算单元之间数据搬运的减少,大幅缩短了系统响应时间。更重要的是,用存算一体架构做大算力AI芯片另一大优势在于成本控制。不依赖于GDDR 或HBM,存算一体芯片的成本能够相应的降低50%~70%。换句话说,真正创新架构的AI芯片是将上文中提到的算力、功耗、成本三角形结构从原来的位置往上挪了三个档位。不仅可以提高算力,还可以达到降低功耗、控制成本的效果。
摘取「高挂的果实」
最近几年,在缺芯的时代背景下,随着政策支持的不断加码,看到国内半导体产业迎来了发展的良机。芯片的“国产替代”已经在很多细分领域取得了进展,深受资本市场青睐。但是资本市场也有越来越多的人意识到,热门芯片赛道的“国产替代”创业项目已经日趋饱和。一部分嗅觉敏锐的投资人开始关注后摩尔时代的“创新架构”,认为要想在纯市场化竞争中挑战英伟达等国际芯片巨头,必须另辟蹊径。于是差异化的技术创新成为芯片投资中的重要策略。HBM、DSA、存算一体都属于芯片行业当前的技术创新路径,三者对比来看,存算一体可以算作是一条难度最大、颠覆性最强、风险最高,但差异化和创新性也最显著的路径。近年来,国内外涌现出不少专注于存算一体芯片的新兴创企,巨头们纷纷加快了产业布局,资本也对其青睐有加。国内最近一笔相关融资来自今年4月,国内存算一体明星创企「后摩智能」宣布获得数亿人民币Pre-A+轮融资。不过,一直以来,传统的存算一体研究大多集中在低功耗、低算力的「小」芯片场景中,比如语音、AIoT、安防等边缘领域。能够应用在车载AI的存算一体「大」算力芯片,即便在学术界也是一大难题,产业界敢于迎战者更是屈指可数。想要将二者融合,既需要存储单元阵列、AI core、工具链等各个方面都需要有深厚积累的团队,又需要进行整体的协同优化设计,才能最终实现一款高效的基于存算一体的大算力AI芯片。所幸,这一创新性技术已经让市场看到了落地可能性。5月23日,后摩智能首款基于SRAM的存算一体大算力AI芯片已成功点亮,并跑通智能驾驶算法模型。首次在存内计算架构上跑通了智能驾驶场景下多场景、多任务算法模型,为高级别智能驾驶提供了一条全新的技术路径。

存算一体很难,存算一体大芯片更难。但在产业巨头林立,市场秩序森严的芯片产业,新兴创企若是只愿意选择容易走的路、采摘「低垂的果实」,是难以取得成功的。在保证存算一体带来的高能效比、高性价比的前提下,又能将其成功扩展到满足自动驾驶「大」算力需求的级别,属于产业中「高挂的果实」。从成立之初就聚焦于存算一体大算力芯片的后摩智能,正是瞄准了这一道路。以团队组成来说,后摩智能的核心创始团队既有来自美国普林斯顿大学、UCSB, Penn State大学等海内外知名高校的学术人才,又有在AMD、Nvidia、华为海思、地平线等一线芯片企业中拥有丰富大芯片设计与实战经验的产业专家。今年5月大算力存算一体芯片宣布点亮,对于后摩智能来说,离摘取「高挂的果实」已经越来越近了。传统高算力芯片山头林立,后来者想要在现有赛道上实现超越,确实是充满挑战的。但随着HBM等昂贵方案的不断的提出,冯·诺伊曼架构的最后一丝红利已经被榨干,市场迫切地需要新架构、新出路。
在AI算法快速迭代,摩尔定律逐渐失效的当下,期待看到越来越多像后摩智能这样愿意投身于基础创新的芯片创企,不断推进产业走向下一个时代。
后摩智能点亮首款基于SRAM的「存算一体」大算力AI芯片,迎战自动驾驶芯片算力焦虑。
参考文献链接
https://mp.weixin.qq.com/s/PkJDADkQjUhCDrNOyUc8bg
https://mp.weixin.qq.com/s/Uhq4zTrNyavscxlZvbNYgA
https://mp.weixin.qq.com/s/7DBRyslROM3KEOT-KNTUkA
https://mp.weixin.qq.com/s/N6_09MhCho-UHJV6kSRnNw

