
- 1前端vue后端express项目服务器部署操作_前端vue3,后端express
- 2时间戳校验和计算
- 3STM32的QSPI在dual-flash双闪存模式下读写寄存器描述,译自H743参考手册_qspi双闪存模式
- 4推荐系统!基于tensorflow搭建混合神经网络精准推荐!_tenserflow 做内容推荐
- 52-报错“a component required a bean of type ‘微服务名称‘ that could”_微服务 启动报错a component required a bean of type 'com.s
- 6unity3d中平滑跟随的功能实现!!!!_smooth follow unity
- 7git命令大全(非常齐全)_linlin@tiger versa-activity % git pull feature/sig
- 8java正则验证时间戳_时间戳和正则表达式
- 910个python入门小游戏,零基础打通关,就能掌握编程基础_python编写的入门简单小游戏_python编程小游戏简单的
- 10Postgresql排序与limit组合场景性能极限优化_posterger limit
NNDL 实验六 卷积神经网络(5)使用预训练resnet18实现CIFAR-10分类_卷积神经网络训练伪代码
赞
踩
NNDL 实验六 卷积神经网络(5)使用预训练resnet18实现CIFAR-10分类
5.5 实践:基于ResNet18网络完成图像分类任务
图像分类(Image Classification)
计算机视觉中的一个基础任务,将图像的语义将不同图像划分到不同类别。
很多任务可以转换为图像分类任务。
比如人脸检测就是判断一个区域内是否有人脸,可以看作一个二分类的图像分类任务。

- 数据集:CIFAR-10数据集,
- 网络:ResNet18模型,
- 损失函数:交叉熵损失,
- 优化器:Adam优化器,Adam优化器的介绍参考NNDL第7.2.4.3节。
- 评价指标:准确率。
5.5.1 数据处理
5.5.1.1数据集导入
def load_cifar10_batch(folder_path, batch_id=1, mode='train'):
if mode == 'test':
file_path = os.path.join(folder_path, 'test_batch')
else:
file_path = os.path.join(folder_path, 'data_batch_' + str(batch_id))
with open(file_path, 'rb') as batch_file:
batch = pickle.load(batch_file, encoding='latin1')
imgs = batch['data'].reshape((len(batch['data']), 3, 32, 32)) / 255.
labels = batch['labels']
return np.array(imgs, dtype='float32'), np.array(labels)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
加载数据集:
imgs_batch, labels_batch = load_cifar10_batch(folder_path='C:/Users/20637/Documents/Tencent Files/2063716648/FileRecv/cifar-10-batches-py',batch_id=1, mode='train')
print("batch of imgs shape: ", imgs_batch.shape, "batch of labels shape: ", labels_batch.shape)
- 1
- 2
- 3
- 4
观察一下数据集中的一张图片:
import matplotlib.pyplot as plt
image, label = imgs_batch[1], labels_batch[1]
print("The label in the picture is {}".format(label))
plt.figure(figsize=(2, 2))
plt.imshow(image.transpose(1, 2, 0))
plt.savefig('cnn-car.pdf')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
5.5.1.2 划分训练集、验证集、测试集
import torch
from torch.utils.data import Dataset, DataLoader
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import PIL.Image as Image
- 1
- 2
- 3
- 4
- 5
- 6
划分训练集、验证集、测试集的函数:
class CIFAR10Dataset(Dataset): def __init__(self, folder_path='C:/Users/20637/Documents/Tencent Files/2063716648/FileRecv/cifar-10-batches-py', mode='train'): if mode == 'train': self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, batch_id=1, mode='train') for i in range(2, 5): imgs_batch, labels_batch = load_cifar10_batch(folder_path=folder_path, batch_id=i, mode='train') self.imgs, self.labels = np.concatenate([self.imgs, imgs_batch]), np.concatenate( [self.labels, labels_batch]) elif mode == 'dev': self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, batch_id=5, mode='dev') elif mode == 'test': self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, mode='test') self.transform = transforms.Compose( [transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])]) def __getitem__(self, idx): img, label = self.imgs[idx], self.labels[idx] img = img.transpose(1, 2, 0) img = self.transform(img) return img, label def __len__(self): return len(self.imgs)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
执行划分:
train_dataset = CIFAR10Dataset(folder_path='C:/Users/20637/Documents/Tencent Files/2063716648/FileRecv/cifar-10-batches-py', mode='train')
dev_dataset = CIFAR10Dataset(folder_path='C:/Users/20637/Documents/Tencent Files/2063716648/FileRecv/cifar-10-batches-py', mode='dev')
test_dataset = CIFAR10Dataset(folder_path='C:/Users/20637/Documents/Tencent Files/2063716648/FileRecv/cifar-10-batches-py', mode='test')
- 1
- 2
- 3
- 4
5.5.2 模型构建
使用飞桨高层API中的Resnet18进行图像分类实验。
torchvision.models.resnet18()
class RunnerV3(object): def __init__(self, model, optimizer, loss_fn, metric, **kwargs): self.model = model self.optimizer = optimizer self.loss_fn = loss_fn self.metric = metric self.dev_scores = [] self.train_epoch_losses = [] self.train_step_losses = [] self.dev_losses = [] self.best_score = 0 def train(self, train_loader, dev_loader=None, **kwargs): self.model.train() num_epochs = kwargs.get("num_epochs", 0) log_steps = kwargs.get("log_steps", 100) eval_steps = kwargs.get("eval_steps", 0) save_path = kwargs.get("save_path", "best_model.pdparams") custom_print_log = kwargs.get("custom_print_log", None) num_training_steps = num_epochs * len(train_loader) if eval_steps: if self.metric is None: raise RuntimeError('Error: Metric can not be None!') if dev_loader is None: raise RuntimeError('Error: dev_loader can not be None!') global_step = 0 for epoch in range(num_epochs): total_loss = 0 for step, data in enumerate(train_loader): X, y = data X = X.cuda() logits = self.model(X).cuda() y = y.to(dtype=torch.int64) y = y.cuda() loss = self.loss_fn(logits, y) total_loss += loss self.train_step_losses.append((global_step, loss.item())) if log_steps and global_step % log_steps == 0: print( f"[Train] epoch: {epoch}/{num_epochs}, step: {global_step}/{num_training_steps}, loss: {loss.item():.5f}") loss.backward() if custom_print_log: custom_print_log(self) self.optimizer.step() optimizer.zero_grad() if eval_steps > 0 and global_step > 0 and \ (global_step % eval_steps == 0 or global_step == (num_training_steps - 1)): dev_score, dev_loss = self.evaluate(dev_loader, global_step=global_step) print(f"[Evaluate] dev score: {dev_score:.5f}, dev loss: {dev_loss:.5f}") self.model.train() if dev_score > self.best_score: self.save_model(save_path) print( f"[Evaluate] best accuracy performence has been updated: {self.best_score:.5f} --> {dev_score:.5f}") self.best_score = dev_score global_step += 1 trn_loss = (total_loss / len(train_loader)).item() self.train_epoch_losses.append(trn_loss) print("[Train] Training done!") @torch.no_grad() def evaluate(self, dev_loader, **kwargs): assert self.metric is not None self.model.eval() global_step = kwargs.get("global_step", -1) total_loss = 0 self.metric.reset() for batch_id, data in enumerate(dev_loader): X, y = data y = y.to(torch.int64) X = X.cuda() y = y.cuda() logits = self.model(X).cuda() loss = self.loss_fn(logits, y).item() total_loss += loss self.metric.update(logits, y) dev_loss = (total_loss / len(dev_loader)) dev_score = self.metric.accumulate() if global_step != -1: self.dev_losses.append((global_step, dev_loss)) self.dev_scores.append(dev_score) return dev_score, dev_loss @torch.no_grad() def predict(self, x, **kwargs): self.model.eval() logits = self.model(x) return logits def save_model(self, save_path): torch.save(self.model.state_dict(), save_path) def load_model(self, model_path): state_dict = torch.load(model_path) self.model.load_state_dict(state_dict) import torch def accuracy(preds, labels): print(preds) if preds.shape[1] == 1: preds = torch.can_cast((preds >= 0.5).dtype, to=torch.float32) else: preds = torch.argmax(preds, dim=1) torch.can_cast(preds.dtype, torch.int32) return torch.mean(torch.tensor((preds == labels), dtype=torch.float32)) class Accuracy(): def __init__(self): self.num_correct = 0 self.num_count = 0 self.is_logist = True def update(self, outputs, labels): if outputs.shape[1] == 1: outputs = torch.squeeze(outputs, axis=-1) if self.is_logist: preds = torch.can_cast((outputs >= 0), dtype=torch.float32) else: preds = torch.can_cast((outputs >= 0.5), dtype=torch.float32) else: preds = torch.argmax(outputs, dim=1).int() labels = torch.squeeze(labels, dim=-1) batch_correct = torch.sum(torch.tensor(preds == labels, dtype=torch.float32)).cpu().numpy() batch_count = len(labels) self.num_correct += batch_correct self.num_count += batch_count def accumulate(self): if self.num_count == 0: return 0 return self.num_correct / self.num_count def reset(self): self.num_correct = 0 self.num_count = 0 def name(self): return "Accuracy"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
构建torchvision.models中的resnet18模型:
from torchvision.models import resnet18
resnet18_model = resnet18()
- 1
- 2
- 3
什么是“预训练模型”?什么是“迁移学习”?(必做)
预训练的简单概括就是使用尽可能多的训练数据,从中提取出尽可能多的共性特征,从而让模型对特定任务的学习负担变轻。 预训练方式表现在模型参数上,就是我之前已经拿到一个任务,这个任务和其他任务有很多相同之处,于是提前训练好了所有的模型参数(预训练)。因此我们不再需要从0开始训练所有参数了,但是针对我们目前这个任务,有些参数可能不合适,我们只需要在当前参数的基础上稍加修改(微调)就可以得到比较好的效果,这样学习时间必然会大大减小。而且,由于预训练过程和我们当前的任务不是同时进行的,所以可以提前花很长时间把几千亿乃至万万亿参数(现在应该还没)提前预训练好,以求和更多的具体任务都有重合,从而只需要我们微调就可以在各项任务达到不错的效果。
迁移学习(Transfer Learning)是机器学习中的一个名词,是指一种学习对另一种学习的影响,或习得的经验对完成其它活动的影响。迁移广泛存在于各种知识、技能与社会规范的学习中。
迁移学习专注于存储已有问题的解决模型,并将其利用在其他不同但相关问题上。比如说,用来辨识汽车的知识(或者是模型)也可以被用来提升识别卡车的能力。计算机领域的迁移学习和心理学常常提到的学习迁移在概念上有一定关系,但是两个领域在学术上的关系非常有限。
比较“使用预训练模型”和“不使用预训练模型”的效果。(必做)
预训练:
resnet = models.resnet18(pretrained=True)
- 1
结果:
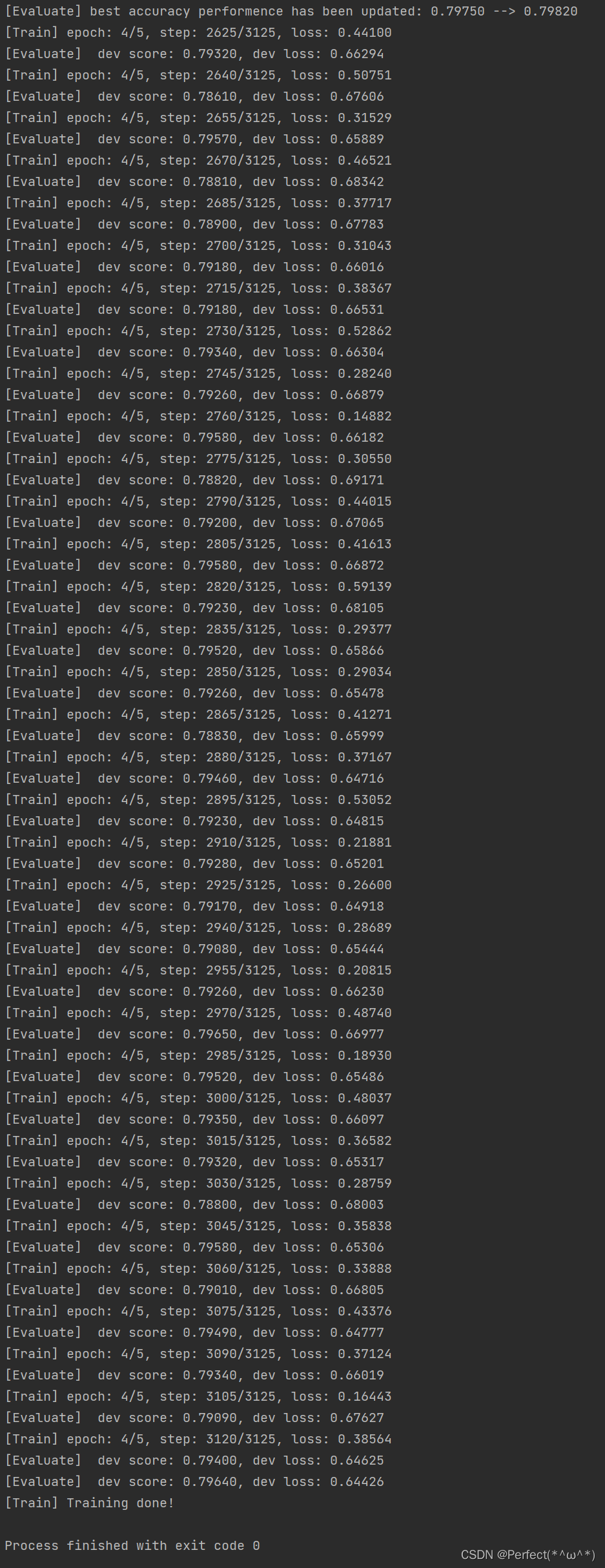
5.5.3 模型训练
import torch.nn.functional as F import torch.optim as opt device = torch.device("cuda" if torch.cuda.is_available() else "cpu") print(device) lr = 0.001 batch_size = 64 train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) dev_loader = DataLoader(dev_dataset, batch_size=batch_size) test_loader = DataLoader(test_dataset, batch_size=batch_size) model = resnet18_model model.to(device) optimizer = opt.SGD(model.parameters(), lr=lr, momentum=0.9) loss_fn = F.cross_entropy metric = Accuracy() runner = RunnerV3(model, optimizer, loss_fn, metric) log_steps = 15 eval_steps = 15 runner.train(train_loader, dev_loader, num_epochs=5, log_steps=log_steps, eval_steps=eval_steps, save_path="best_model.pdparams")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
结果:
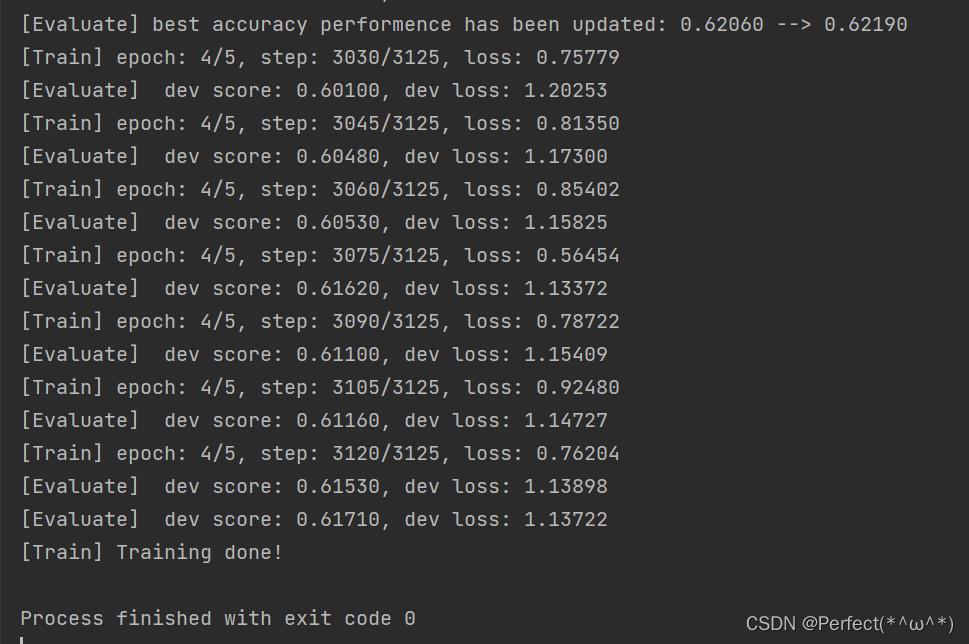
由于电脑配置的原因,因此将log_steps = 15、eval_steps = 15、num_epochs=5将这几个参数调小了一些,得到的结果在百分之六十多,如果将参数适当调大后,预测结果会升高。
5.5.4 模型评价
# 加载最优模型
runner.load_model('best_model.pdparams')
# 模型评价
score, loss = runner.evaluate(iter(test_loader))
print("[Test] accuracy/loss: {:.4f}/{:.4f}".format(score, loss))
- 1
- 2
- 3
- 4
- 5
- 6
结果:
5.5.5 模型预测
同样地,也可以使用保存好的模型,对测试集中的数据进行模型预测,观察模型效果,具体代码实现如下:
#获取测试集中的一个batch的数据 X, label = next(iter(test_loader)) X = X.cpu() logits = runner.predict(X) #多分类,使用softmax计算预测概率 pred = F.softmax(logits) #获取概率最大的类别 pred_class = torch.argmax(pred[2]).numpy() print(label[2].numpy()) label = label[2].numpy() #输出真实类别与预测类别 print("The true category is {} and the predicted category is {}".format(label, pred_class)) #可视化图片 plt.figure(figsize=(2, 2)) imgs, labels = load_cifar10_batch(folder_path='C:/Users/20637/Documents/Tencent Files/2063716648/FileRecv/cifar-10-batches-py', mode='test') plt.imshow(imgs[2].transpose(1,2,0)) plt.savefig('cnn-test-vis.pdf')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
结果:

思考题
1.阅读《Deep Residual Learning for Image Recognition》,了解5种深度的ResNet(18,34,50,101和152),并简单谈谈自己的看法。(选做)
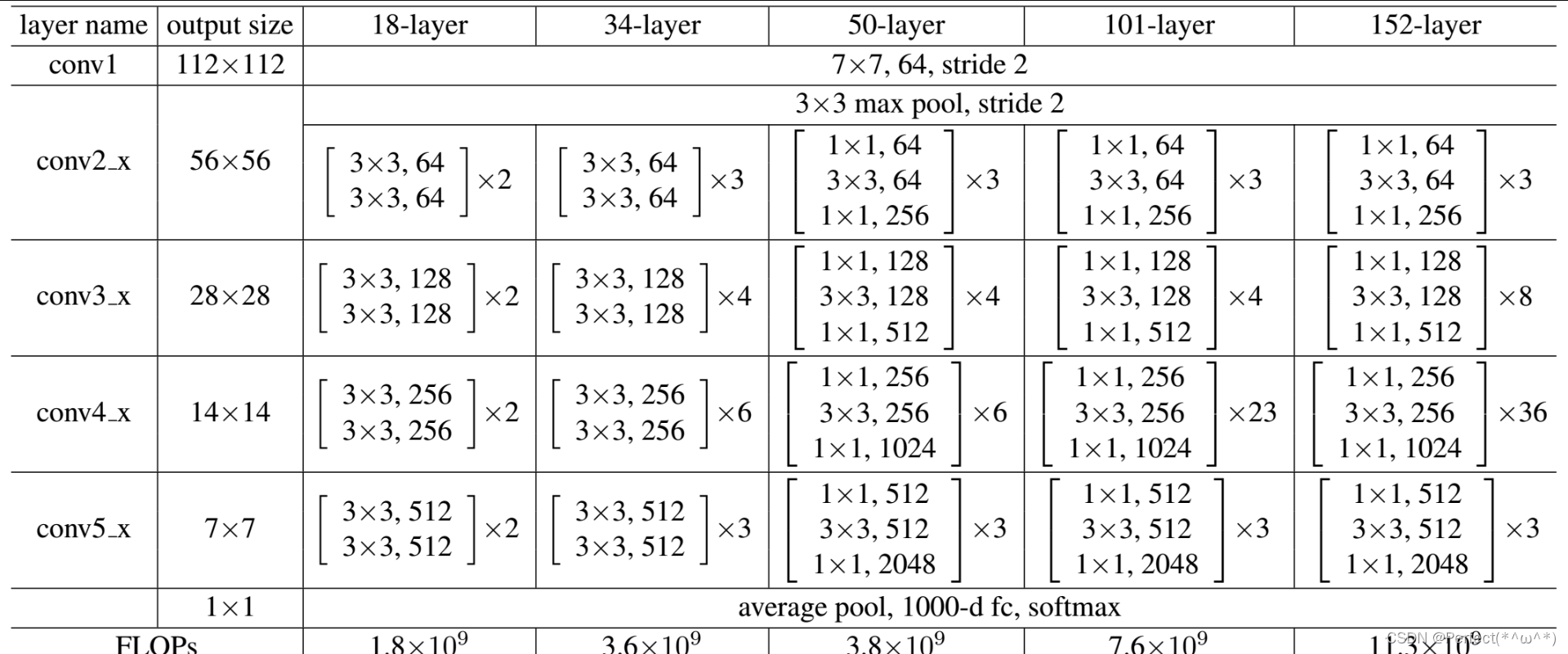
根据这个表格我们可以看出它一共给出了5种深度的resnet,分别是18,34,50,101和152,首先看表最左侧,我们发现所有的网络都分成5部分,分别是:conv1,conv2_x,conv3_x,conv4_x,conv5_x.
ResNet最大的创新点,正是标题中的《Deep Residual Learning for Image Recognition》体现,深度残差网络使得ResNet横空出世,ResNet的结构,它使用了一种连接方式叫做“shortcut connection”,shortcut翻译过来就是“抄近道”的意思。
2.用自己的话简单评价:LeNet、AlexNet、VGG、GoogLeNet、ResNet(选做)
LeNet:
LeNet是最早的卷积神经网络之一。LeNet通过连续使用卷积和池化层的组合提取图像特征。
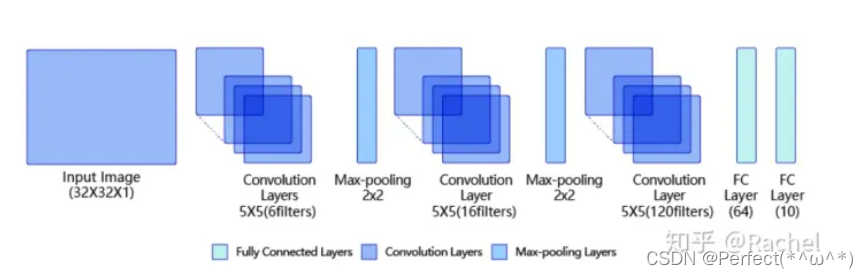
上图就是LeNet网络的结构模型,其中包含:
第一模块:包含5×5的6通道卷积和2×2的池化。卷积提取图像中包含的特征模式(激活函数使用sigmoid),图像尺寸从32减小到28。经过池化层可以降低输出特征图对空间位置的敏感性,图像尺寸减到14。
第二模块:和第一模块尺寸相同,通道数由6增加为16。卷积操作使图像尺寸减小到10,经过池化后变成5。
第三模块:包含5×5的120通道卷积。卷积之后的图像尺寸减小到1,但是通道数增加为120。将经过第3次卷积提取到的特征图输入到全连接层。第一个全连接层的输出神经元的个数是64,第二个全连接层的输出神经元个数是分类标签的类别数,对于手写数字识别其大小是10。然后使用Softmax激活函数即可计算出每个类别的预测概率。
AlexNet:
AlexNet与LeNet相比,具有更深的网络结构,包含5层卷积和3层全连接,同时使用了如下三种方法改进模型的训练过程:
数据增广:深度学习中常用的一种处理方式,通过对训练随机加一些变化,比如平移、缩放、裁剪、旋转、翻转或者增减亮度等,产生一系列跟原始图片相似但又不完全相同的样本,从而扩大训练数据集。通过这种方式,可以随机改变训练样本,避免模型过度依赖于某些属性,能从一定程度上抑制过拟合。
使用Dropout抑制过拟合
使用ReLU激活函数减少梯度消失现象
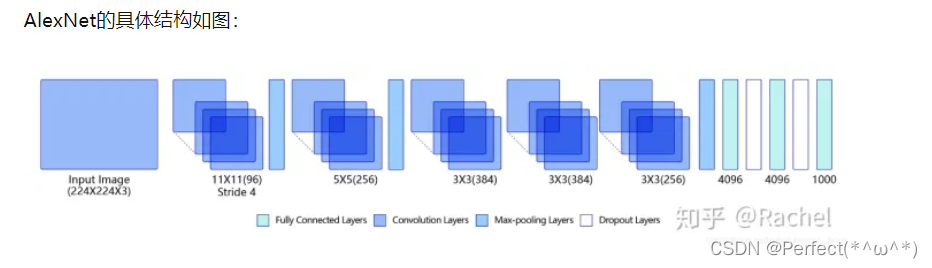
其中有四个模块:
第一模块:包含了11 x 11步长为4的96通道卷积以及一个最大池化
第二模块:包含了5 x 5步的256通道卷积以及一个最大池化
第三模块:包含了两个3 x 3的384通道以及一个3 x 3的256通道的卷积,后面加一个最大池化
第四模块:包含了两个4096通道输入的全连接层,每个全连接层后面加一个Dropout层来抑制过拟合,以及还有最后一个1000通道的全连接层
VGG:
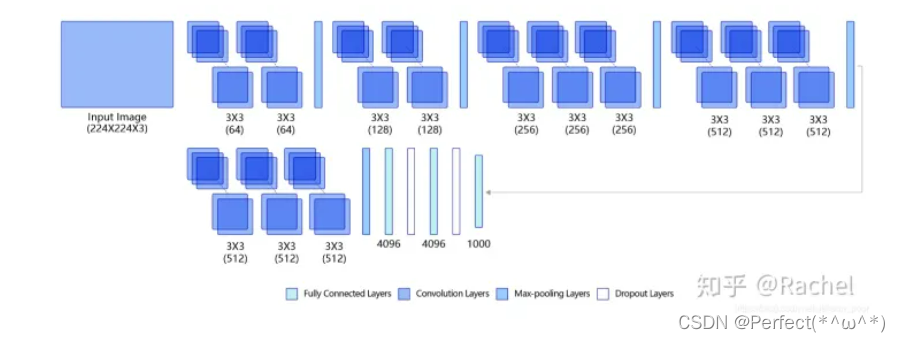
VGG网络的设计严格使用3×3的卷积层和池化层来提取特征,并在网络的最后面使用三层全连接层,将最后一层全连接层的输出作为分类的预测。 在VGG中每层卷积将使用ReLU作为激活函数,在全连接层之后添加dropout来抑制过拟合。
使用小的卷积核能够有效地减少参数的个数,使得训练和测试变得更加有效。比如使用两层3×3卷积层,可以得到感受野为5的特征图,而比使用5×5的卷积层需要更少的参数。由于卷积核比较小,可以堆叠更多的卷积层,加深网络的深度,这对于图像分类任务来说是有利的。VGG模型的成功证明了增加网络的深度,可以更好的学习图像中的特征模式。
VGG-16的网络结构示意图:
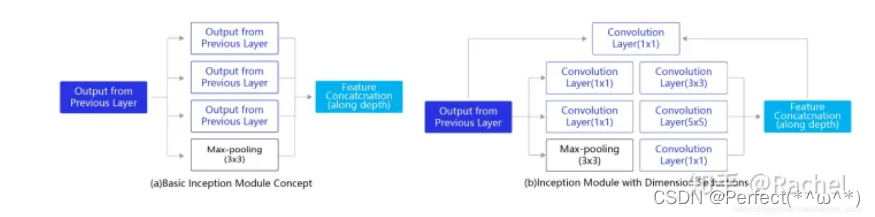
GoogLeNet:
它的主要特点是网络不仅有深度,还在横向上具有“宽度”。由于图像信息在空间尺寸上的巨大差异,如何选择合适的卷积核大小来提取特征就显得比较困难了。空间分布范围更广的图像信息适合用较大的卷积核来提取其特征,而空间分布范围较小的图像信息则适合用较小的卷积核来提取其特征。为了解决这个问题,GoogLeNet提出了一种被称为Inception模块的方案。如 下图 所示:
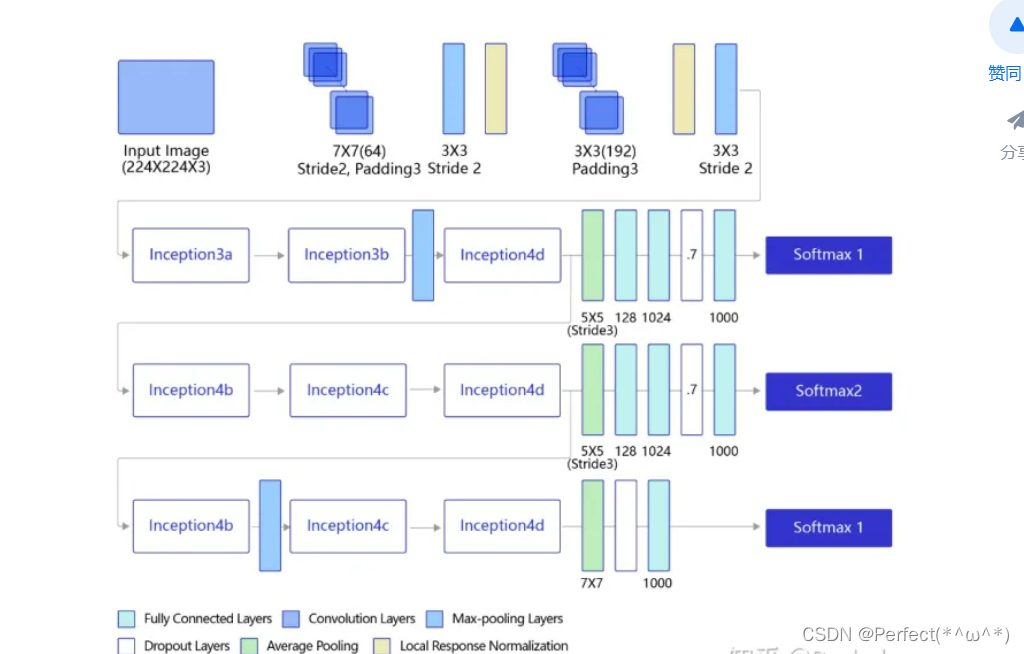
GoogLeNet的架构如 下图 所示,在主体卷积部分中使用5个模块(block),每个模块之间使用步幅为2的3 ×3最大池化层来减小输出高宽。
ResNet:
下图表示出了ResNet-50的结构,一共包含49层卷积和1层全连接,所以被称为ResNet-50。

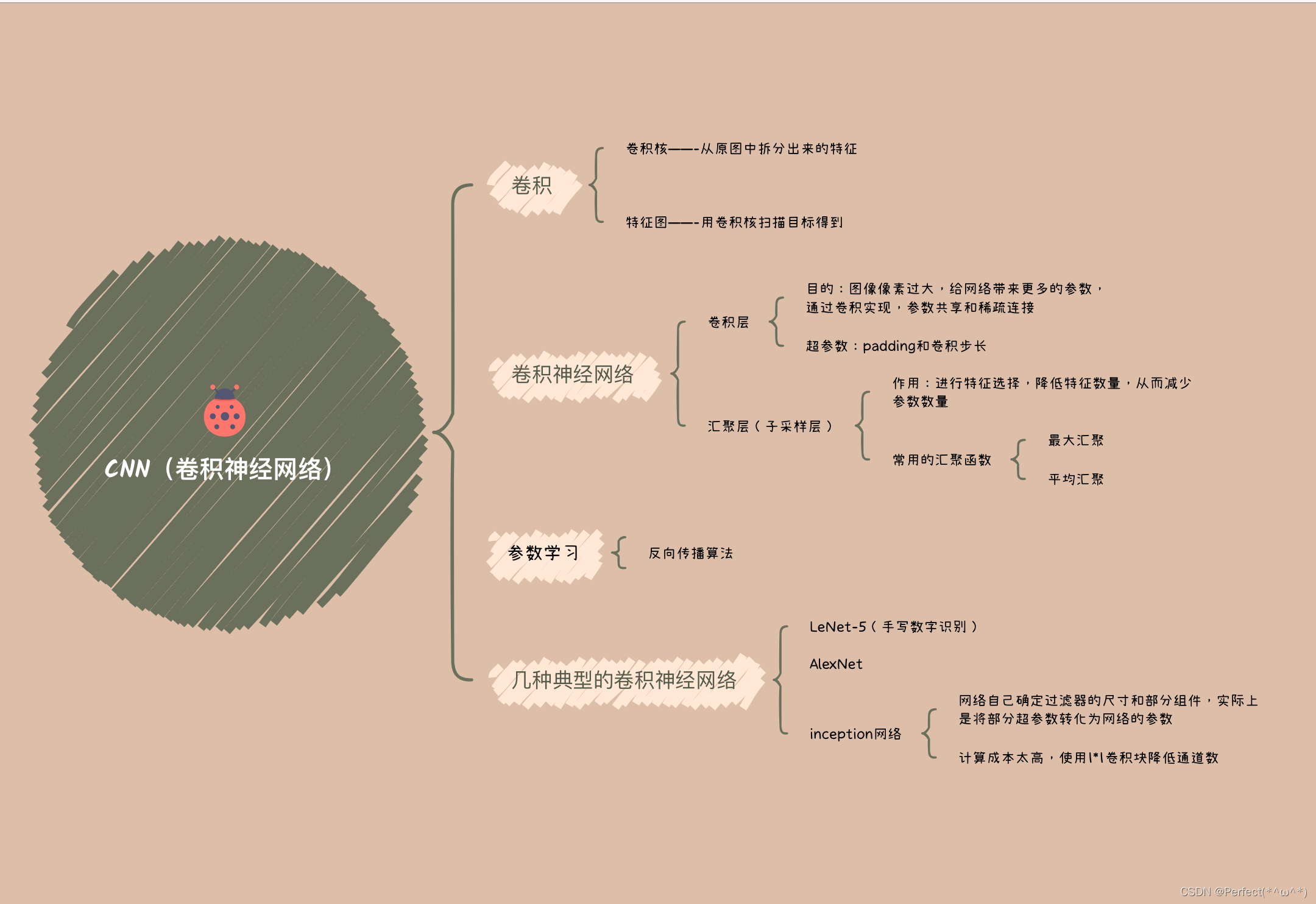
总结
使用思维导图全面总结CNN:
参考
NNDL 实验5(下) - HBU_DAVID - 博客园 (cnblogs.com)
预训练是什么?预训练和直接训练的区别?
一文读懂LeNet、AlexNet、VGG、GoogleNet、ResNet到底是什么?

