
万字长文 | 多目标跟踪最新综述(基于Transformer/图模型/检测和关联/孪生网络)...
赞
踩
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心技术交流群
后台回复【目标跟踪综述】获取单目标、多目标、基于学习方法的领域综述!
论文链接:https://arxiv.org/pdf/2209.04796.pdf
摘要
随着自动驾驶技术的发展,多目标跟踪已成为计算机视觉领域研究的热点问题之一。MOT 是一项关键的视觉任务,可以解决不同的问题,例如拥挤场景中的遮挡、相似外观、小目标检测困难、ID切换等。为了应对这些挑战,研究人员尝试利用transformer的注意力机制、利用图卷积神经网络获得轨迹的相关性、不同帧中目标与siamese网络的外观相似性,还尝试了基于简单 IOU 匹配的 CNN 网络、运动预测的 LSTM。为了把这些分散的技术综合起来,作者研究了过去三年中的一百多篇论文,试图提取出近年来研究者们更加关注的解决 MOT 问题的技术。作者罗列了大量的应用以及可能的方向,还有MOT如何与现实生活联系起来。作者的综述试图展示研究人员长期使用的技术的不同观点,并为潜在研究人员提供一些未来方向。此外,作者在这篇综述中还包括了流行的基准数据集和指标。
简介
目标跟踪是计算机视觉中非常重要的任务之一。它刚好在目标检测之后出现。为了完成目标跟踪任务,首先需要将目标定位在一帧中。然后给每个目标分配一个单独的唯一id。然后连续帧中的每个相同目标将生成轨迹。在这里,一个目标可以是任何类别,比如行人、车辆、运动中的运动员、天空中的鸟等。如果作者想在一帧中跟踪多个目标,那么它被称为多目标跟踪或MOT。
过去几年也有一些关于MOT的综述论文[1]、[2]、[3]、[4]。但它们都有局限性。其中一些方法只包括基于深度学习的方法,只关注数据关联,只分析问题,没有很好地对论文进行分类,并且缺少现实中应用的介绍。
因此,综上所述,作者以以下方式组织了本工作:
找出MOT的主要挑战
列出常用的各种MOT方法
MOT基准数据集简介
MOT指标摘要
探索各种应用场景
MOT的主要挑战
遮挡
当想要看到的目标被同一帧中的另一个目标完全或部分隐藏或遮挡时,就会发生遮挡问题。大多数MOT方法仅基于没有传感器数据的相机。这就是为什么当目标相互遮挡时,跟踪器要跟踪目标的位置有点困难的原因。此外,在拥挤的场景中,为了建模人与人之间的交互,遮挡变得更加严重[5]。随着时间的推移,使用边界框定位目标在MOT社区中非常流行。但在拥挤的场景中,[6]遮挡很难处理,因为groundtruth边界框通常相互重叠。通过联合处理目标跟踪和分割任务,可以部分解决这个问题[7]。在文献中,作者可以看到外观信息和图形信息用于查找全局属性以解决遮挡问题[8],[9],[10],[11]。然而,频繁的遮挡对MOT问题中较低的精度有显著影响。因此,研究人员试图在没有任何提示的情况下解决这个问题。在下图a中,对遮挡进行了说明。在下图b中,红衣女子几乎被灯柱遮盖。这是遮挡的一个示例。

轻量化架构
尽管大多数问题的最新解决方案是依赖于重量级架构,但它们非常吃资源。因此在 MOT 中,重量级架构对于实时目标跟踪非常不利。因此,研究人员一直很重视轻量级体系结构。对于 MOT 中的轻量级结构,还有一些额外的挑战需要考虑[12]。Bin 等人提到了轻量级体系结构面临的三个挑战,比如: 目标跟踪体系结构需要预训练权重来实现良好的初始化,并对跟踪数据进行微调。因为 NAS 算法需要来自目标任务的指导,同时还需要可靠的初始化。NAS 算法需要同时关注骨干网络和特征提取,以便最终的结构能够完全适合目标跟踪任务。最终架构需要编译紧凑和低延迟的构建模块。
其它常见挑战
MOT体系结构经常受到不准确的目标检测的影响。如果没有正确检测到目标,那么跟踪目标的所有努力都将白费。有时,目标检测的速度成为MOT体系结构的一个主要因素。对于背景失真,目标检测有时变得非常困难。照度在目标检测和识别中也起着至关重要的作用。因此,所有这些因素在目标跟踪中变得更加重要。由于相机或目标的运动,运动模糊使MOT更具挑战性。很多时候,MOT体系结构发现很难确定一个目标是否为真正的输入目标。挑战之一是检测和tracklet之间的正确关联。在许多情况下,不正确和不精确的目标检测也是精度低的结果。还有一些挑战,例如相似的外观经常混淆模型,轨迹的开始和终止在MOT中是一个关键的任务,多个目标之间的交互,ID切换(同一目标在连续帧中识别为不同)。由于形状和其他外观特性的非刚性变形和类间相似性,在许多情况下,人和车辆会带来一些额外的挑战[13]。例如,车辆的形状和颜色与人们的衣服不同。最后,较小尺寸的目标可以形成各种不同的视觉元素。Liting等人尝试用更高分辨率的图像和更高的计算复杂度来解决这个问题。他们还将分层特征图与传统的多尺度预测技术相结合[14]。
MOT方法
多目标跟踪任务通常分为两个步骤:目标检测和目标关联。有些侧重于目标检测,有些关注数据关联。这两个步骤有多种方法。无论是检测阶段还是关联阶段,这些方法都不是完全独立的。
Transformer
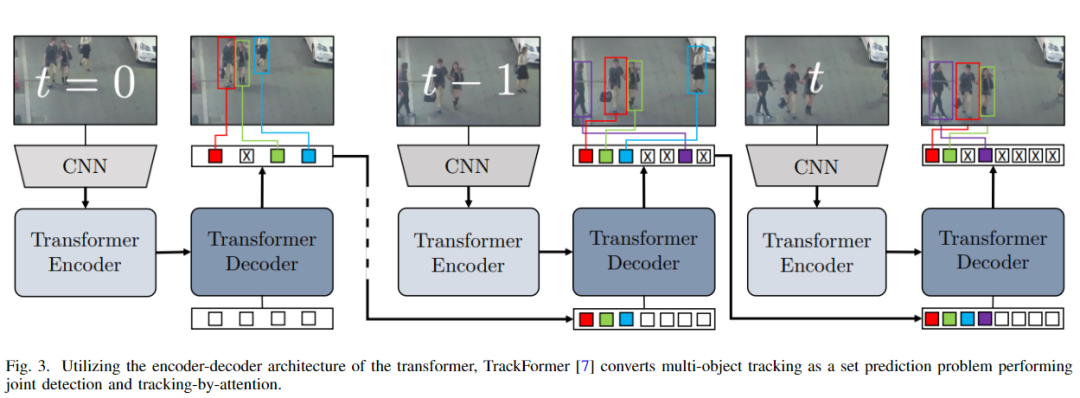
Transformer是一个深度学习模型,与其他模型一样,它有两个部分:编码器和解码器[16]。编码器捕获自注意力,而解码器捕获交叉注意力。这种注意机制有助于长期记忆上下文。基于查询键方式,使用转换器预测输出。尽管过去它仅仅被用作一种语言模型,但近年来,视觉研究人员将重点放在了它上,以利用语境记忆。在大多数情况下,在MOT中,研究人员试图根据之前的信息预测目标下一帧的位置,作者认为transformer是最好的方案。由于transformer专门处理序列信息,所以transformer可以完美地完成逐帧处理。下图是一个Transformer的跟踪例子。
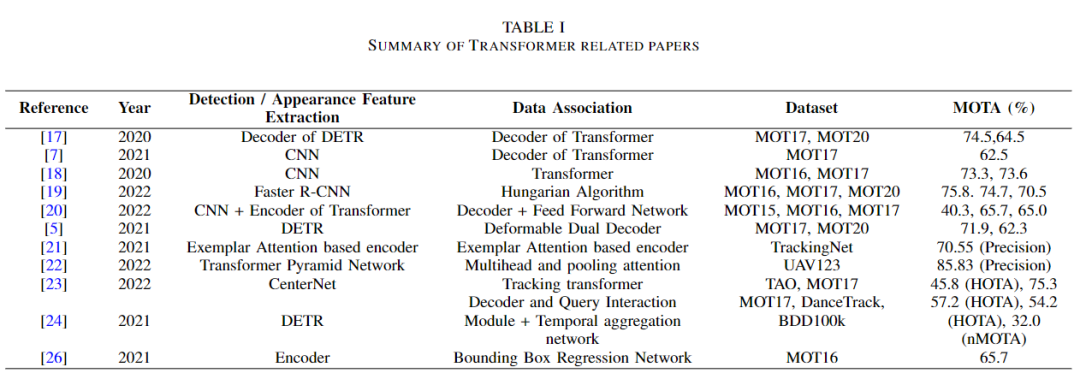
下表给出了MOT中基于transformer的方法的完整总结。
图模型
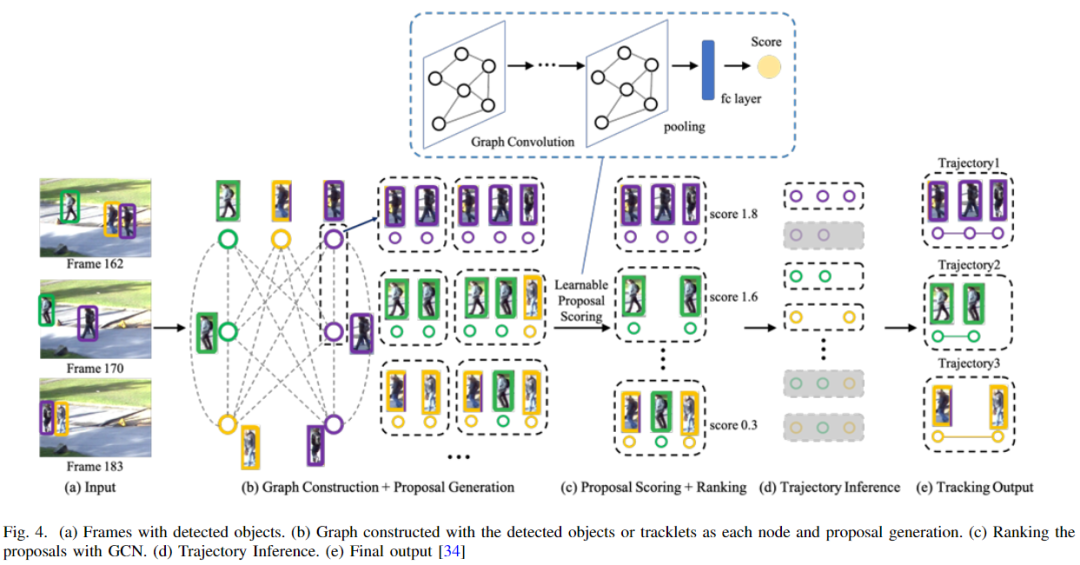
图卷积网络(GCN)是一种特殊的卷积网络,其中神经网络以图形的形式而不是线性的形式应用[27]。此外,最近的趋势是使用图模型来解决 MOT 问题,其中从连续帧中检测到的一组目标被视为一个节点,两个节点之间的链接被视为一个边缘。通常情况下,数据关联是通过应用匈牙利算法来完成的[28]。下图为基于GCN的目标跟踪示例。
下表给出了用图模型解决 MOT 问题的概述。

检测和目标关联
在这种方法中,检测是通过任何深度学习模型来完成的。但主要的挑战是关联目标,即跟踪感兴趣的目标的轨迹[37]。在这方面,不同的论文遵循不同的方法。
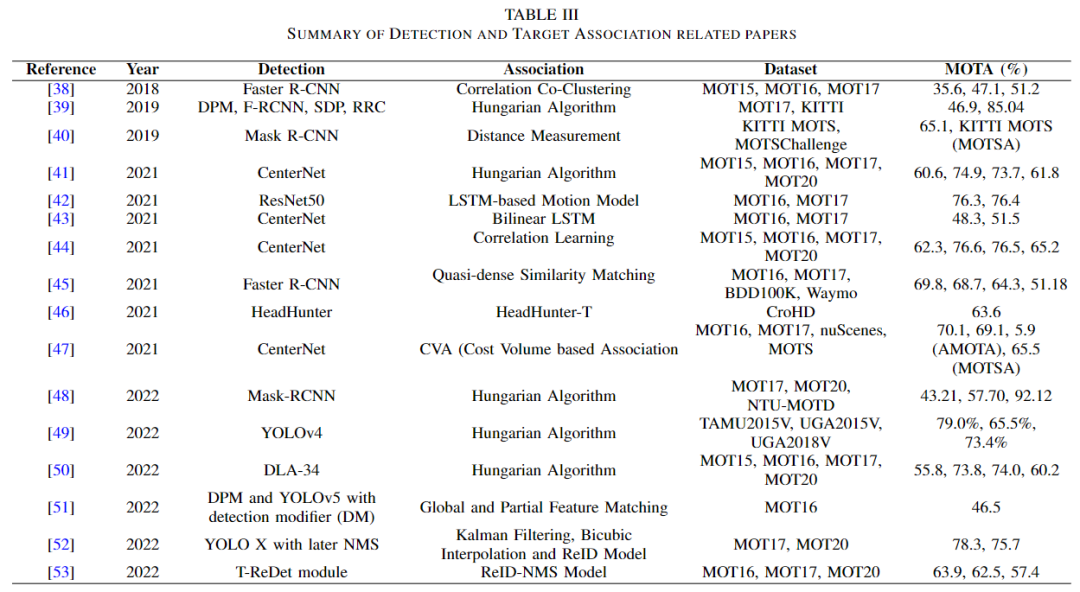
如上表所示,主要介绍部分方案。Margret 等人选择了自下而上的方法和自上而下的方法[38]。在自底向上的方法,点轨迹确定。但是在自顶向下的方法中,确定了边界框。然后,通过结合这两个,一个完整的轨迹的目标可以找到。在[39]中,为了解决关联问题,Hasith 等人简单地检测了目标,并使用著名的匈牙利算法来关联信息。2019年,Paul 等人提出了 Track-RCNN [40] ,这是 R-CNN 的一个延伸,显然是 MOT 领域的一个革命性任务。到2022年,作者可以看到 MOT 问题陈述的多样性。Oluaffunmilola 等人在进行目标预测的同时也进行了目标跟踪[50]。他们使用 FairMOT [54]检测了边界框,然后堆叠了一个预测网络,并制作了联合学习架构(JLE)。智洪等人提取了每个帧的新特征,以获得全局信息,并积累了部分特征用于遮挡处理[51]。他们融合了这两种特征来准确地检测行人。除了[52]之外,没有论文采取任何措施来保留重要的边界框,以便在数据关联阶段不会消除它们。在检测之后,Hong 等人在跟踪阶段应用Non-Maskable Suppression(NMS)来减少重要边界框被移除的概率[53]。Jian 等人还使用 NMS 来减少来自检测器的冗余边界框。它们通过比较特征和借助 IoU 重新识别边界框来重新检测轨迹定位。最终的结果是一个联合再检测和再识别跟踪器(JDI)。
注意力模块
为了重新识别被遮挡的目标,需要注意力。注意力意味着作者只考虑感兴趣的目标,通过消除背景,使其特征被记住很长时间,甚至在遮挡之后也能如此。注意力模块在 MOT 领域的应用概述见下表。
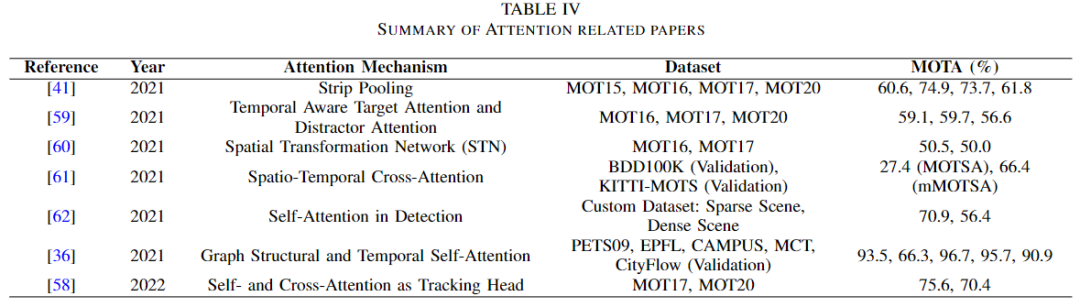
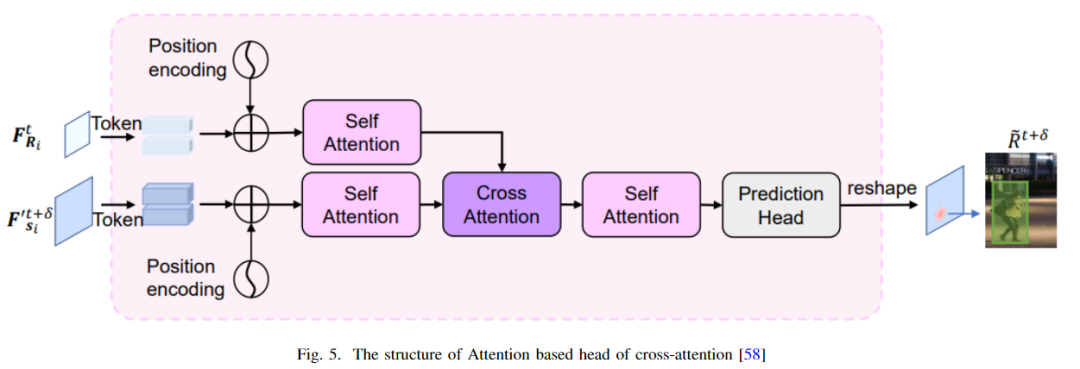
在[41]中,姚野等人引入了一个条形注意模块来重新识别被背景遮挡的行人。这个模块实际上是一个池化层,其中包括 max 和 mean 池化,它能够更有效地从行人中提取特征,这样当它们被遮挡时,模型不会忘记它们,并能够进一步重新识别。宋等人希望在数据关联中使用目标定位的信息,在目标定位中使用数据关联的信息。为了将两者联系起来,他们使用了两个注意力模块,一个用于目标,另一个用于分散注意力。然后他们最终应用了一个记忆聚合来制造增强的注意力。天一等人提出了空间注意机制[60] ,通过在外观模型中实现空间转换网络(STN)来迫使模型只关注前景。另一方面,雷等人首先提出了原型交叉注意模块(PCAM)从过去的帧中提取相关特征。然后他们使用原型交叉注意网络(PCAN)在整个帧中传输前景和背景的对比特征[61]。汇源等人提出了自注意机制来检测车辆[62]。本文[36]还有一个应用于动态图中的自注意力模块,用于组合摄像机的内部和外部信息。贾旭等人以一种轻量级的方式使用了交叉注意力和自注意力[58]。如下图所示,大家可以看到该体系结构的交叉注意力头。利用自注意模块提取鲁棒特征,减少背景遮挡。然后将数据传递给交叉注意模块进行实例关联。
运动模型
运动是目标的必然属性。因此,该特征可以用于多目标跟踪领域,无论是检测还是关联。目标的运动可以通过目标在两帧之间的位置差来计算。根据这个衡量标准,可以做出不同的决定,如下表所示。
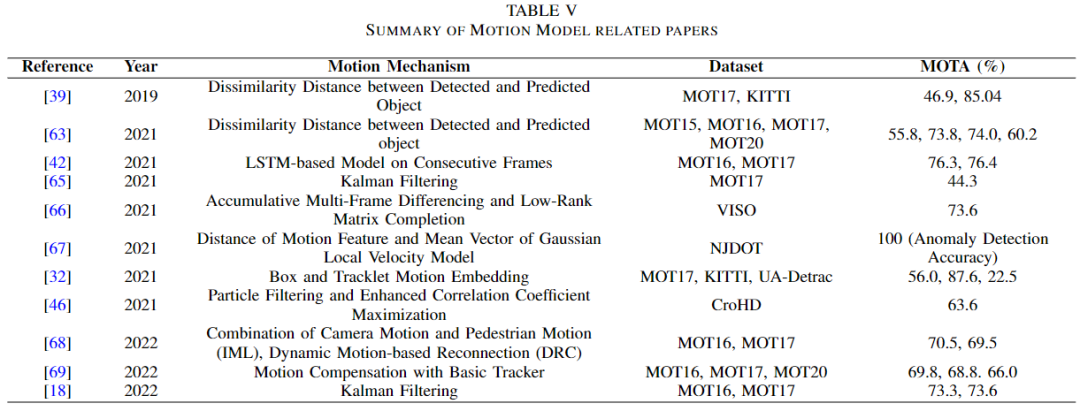
Hasith 等人和 Oluaffunmilola 等人分别在[39]和[63]中使用运动来计算差异代价。根据实际位置与预测位置的差值计算运动。为了预测被遮挡目标的位置,Bisheng 等人使用了基于 LSTM 的运动模型[42]。Wenyuan 等人将运动模型与深度亲和网络(DAN)相结合[64] ,通过消除目标不可能位于的位置来优化数据关联[65]。倩等人还通过累积多帧差分(AMFD)和低秩矩阵完成(LRMC)测量连续卫星帧的距离来计算运动[66] ,并形成了运动模型基线(MMB)来检测和减少虚警的数量。韩等人在车辆驾驶领域使用运动特征识别前景目标[67]。他们通过比较运动特征和 GLV 模型来检测相关目标。Gaoang 等人提出了一种局部-全局运动(LGM)跟踪器,它可以找出运动的一致性,从而将轨迹关联起来[32]。除此之外,Ramana 等人还使用运动模型来预测目标的运动,而不是数据关联,这些数据关联有三个模块: 综合运动定位(IML) ,动态重连上下文(DRC) ,3D 积分图像(3DII)[46]。在2022年,Shoudong 等人通过提出运动感知跟踪器(MAT) ,将运动模型用于运动预测和目标关联。智博等人提出了补偿跟踪器(CT) ,它可以获得具有运动补偿模块的丢失目标[69]。Xiaotong 等使用运动模型来预测目标的边界框[18] ,就像在[67]中所做的那样,但是如Transformer章节中所讨论的那样制作图像patches。
Siamese Network
两帧之间的相似性信息对目标跟踪有很大的帮助。因此,Siamese网络试图学习相似之处,并区分输入。该网络由两个并行子网络共享相同的权值和参数空间。最后将双子网络之间的参数绑定在一定的损失函数上进行训练,以度量双子网络之间的语义相似度。下表给出了Siamese网络在MOT任务中的应用概况。

戴涛等人提出了一个金字塔网络,嵌入了一个轻量级的transformer注意力层。他们提出的Siamese transformer金字塔网络增强了横向交叉注意力金字塔特征之间的目标特征。因此,它产生了健壮的特定于目标的外观表示[22]。如下图所示:
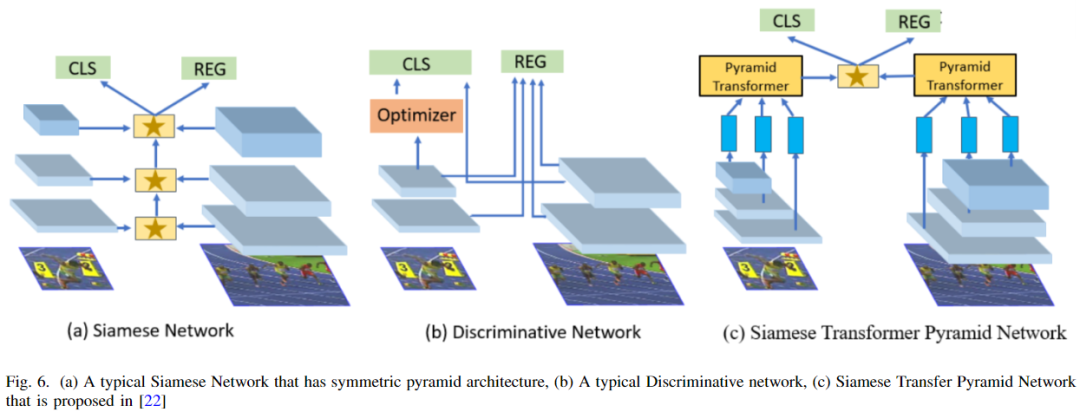
Bing 等人试图通过结合运动建模来提升基于区域的多目标跟踪网络[70]。他们将Siamese网络跟踪框架嵌入到较快的RCNN中,通过轻量级跟踪和共享网络参数来实现快速跟踪。Cong 等人提出了一种使用Siamese双向GRU(SiaBiGRU)对轨迹进行后处理以消除轨迹损坏的切割网络。然后他们建立了重新连接网络来连接这些轨迹并制造轨迹[31]。在典型的MOT网络中,有预测和检测模块。所述预测模块试图预测下一帧中目标的外观,所述检测模块检测所述目标。这两个模块的结果用于特征匹配和目标轨迹更新。新文等人提出了Siamese RPN(区域提案网络)结构作为预测因子。他们还提出了一种数据关联模块的自适应阈值确定方法[71]。因此,Siamese网络的整体稳定性得到了改善。与transformer模型相反,贾旭等人提出了一种基于注意力的在Siamese网络的结构下的轻量级跟踪头,增强了前景目标在目标框内的定位[58]。另一方面,Philippe 等人已经将他们的有效transformer层合并到Siamese跟踪网络中,他们用transformer层取代了卷积层[21]。
Tracklet Association
感兴趣目标的一组连续帧称为tracklet。在检测和跟踪目标时,首先使用不同的算法对轨迹进行识别。然后把它们联系在一起,建立一个轨迹。轨迹关联显然是一个具有挑战性的任务在 MOT 问题。一些论文特别关注这个问题。不同的论文采取了不同的方法。如下表所示。

金龙等人提出了轨迹平面匹配(TPM)[72] ,其中首先从被检测的目标创建短轨迹,并且它们在轨迹平面中对齐,其中每个轨迹根据其开始和结束时间分配超平面。这样就形成了巨大的轨迹。这个过程还可以处理非相邻和重叠的tracklet。为了改善这种情况,他们还提出了两个方案。Duy 等人首先用3D几何算法制作了tracklet[73]。他们已经形成了多个摄像机的轨迹,由于这一点,他们通过制定空间和时间信息优化了全局关联。在[31]中,Cong等人提出了位置投影网络(PPN)来实现从局部环境到全局环境的轨迹转换。Daniel等人通过根据运动将新来的目标分配给先前发现的被遮挡的目标来重新识别被遮挡的目标。然后他们实现了已经发现的进一步回归轨迹,使用by-regression approach。此外,他们还通过提取时间方向来扩展工作,以提高性能。
在[75]中,可以看到与前者不同的策略。将每个轨迹作为一个中心向量,建立了轨迹中心存储库(TMB) ,并对其进行动态更新和成本计算。整个过程称为多视点轨迹对比学习(MTCL)。此外,他们还创建了可学习的视图采样(LVS) ,它将每个检测作为关键点,帮助在全局上下文中查看轨迹。他们还提出了相似引导特征融合(SGFF)方法来避免模糊特征。et,al等人已经开发了轨迹助推器(TBooster)[76]来减轻关联过程中发生的错误。TBooster有两个组件: 拆分器和连接器。在第一个模块中,在ID切换发生的地方拆分tracklet。因此,可以解决为多个目标分配相同ID的问题。在第二个模块中,将同一目标的tracklet链接起来。通过这样做,可以避免将相同的ID分配给多个tracklet。Tracklet嵌入可以通过连接器完成。
MOT Benchmarks
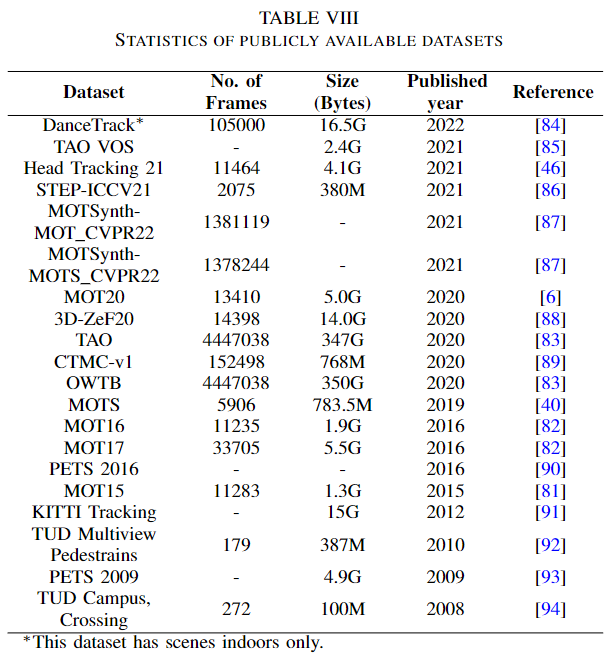
典型的 MOT 数据集包含视频序列。在这些序列中,每个目标都由一个唯一的 id 标识,直到它不再出现。一旦一个新目标进入帧,它就会得到一个新的唯一标识。MOT 有很多基准。其中,MOT 挑战基准有多个版本。自2015年以来,他们几乎每年都会发布一个变化更多的新基准。还有一些流行的基准,如 PETS、 KITTI、 STEPS 和 DanceTrack。到目前为止,MOT 挑战有17个目标跟踪数据集,其中包括 MOT15[81] ,MOT16[82] ,MOT20,[6]和其他。MOt15基准包含威尼斯,KITTI,ADL-Rundle,eTH-Pescross,eTH-Sunnyday,PET,TUd-cross 数据集。这个基准是在一个不受约束的环境中拍摄的,有静态摄像机和运动摄像机。MOT16和 MOT17基本上是从 MOT15更新的基准,具有较高的groundtruth精度和严格遵循的协议。MOT20是一个行人探测挑战赛。这个基准有8个具有挑战性的视频序列(4列火车,4测试)在无约束的环境[6]。除了目标跟踪,MOTS 数据集也有分割任务[40]。一般来说,跟踪数据集有一个边界框,框中的目标有一个唯一标识符。
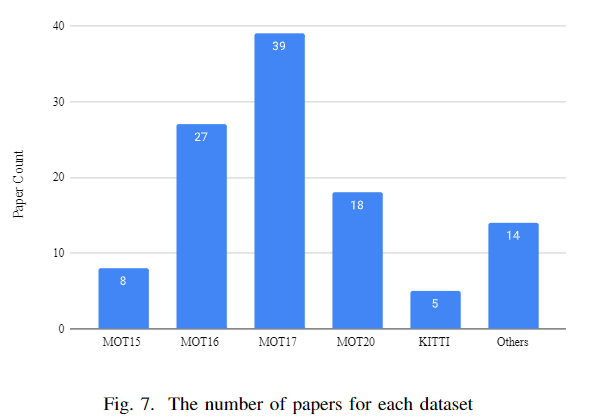
TAO [83]数据集有一个巨大的规模,由于跟踪每一个目标在一帧内。有一个叫Head Tracking 21的数据集。这个基准的任务是跟踪每个行人的头部。STEP 数据集对每个像素进行了分割和跟踪。还有一些其他的数据集。下图显示了作者审阅的论文中使用的数据集的频率。从图表中可以看出,MOT17数据集的使用频率高于其他数据集。
MOT 指标
MOTP
多目标跟踪精度(MOTP)。无论跟踪器是否有能力识别目标形状和保持一致的轨迹,它都是根据跟踪器在寻找目标位置时的精确程度给出的分数。由于 MOTP 只能提供定位精度,因此经常与 MOTA (Multiple Object Tracking Accuracy)结合使用,因为 MOTA 不能单独说明定位误差。定位(Localization)是 MOT 任务的输出之一。它让大家知道目标在本帧中的位置。单凭它不能提供一个完整的跟踪器的性能。
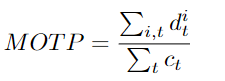
Dit: 在时间t时刻,实际目标与其各自假设之间的距离,在一个单帧内,对于集合中的每个目标Oi,跟踪器分配一个假设hi。Ct: 在t时刻目标和假设之间匹配的数量。
MOTA
多目标跟踪准确度。这个度量衡量跟踪器在不考虑精度的情况下检测目标和预测轨迹的能力。这个度量标准考虑了三种类型的误差:
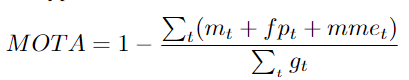
Mt: 在t时刻丢失的数量;fpt误检数量;mmet: ID切换的数量 gt: 在t时刻出现的真实目标的数量。
MOTA过分强调精确检测的效果。它侧重于检测级别的预测和真值之间的匹配,并没有考虑关联。当考虑没有ID切换的MOTA,度量会更偏向于被较差的精度影响。上述的局限性可能会导致研究人员调整他们的跟踪器,使其在检测水平上更具精度和准确性,同时忽略了跟踪的其他重要方面。MOTA 只能考虑短期关联。它只能评估算法执行一阶关联的效果,而不能评估算法在整个轨迹中的关联效果。且它根本没有考虑关联精度/ID转换。事实上,如果一个跟踪器能够纠正任何关联错误,它会惩罚它而不是奖励它。MOTA 的最高分是1,但是没有一个固定的最小值,这会导致 MOTA 的分数为负。
IDF1
ID度量。它试图将预测的轨迹与实际轨迹进行映射,这与MOTA等在检测级别执行双射线映射的指标形成对比。它被设计用来测量“识别”,不同于检测和关联,它与轨迹有关.

IDTP:代表ID真正例,预测得到的目标轨迹与groundtruth目标轨迹匹配。IDFN:ID假反例。任何未被发现的groundtruth值并且其轨迹未被匹配。IDFP:ID误检。任何错误的预测结果。
由于MOTA对检测精度的高度依赖,一些人更喜欢IDF1,因为该指标更注重关联性。然而,IDF1也有一些缺陷。在IDF1中,最佳unique的双映射不会导致预测轨迹和实际轨迹之间的最佳对齐。最终结果将为更好的匹配留下空间。即使检测正确,IDF1分数也会降低。如果有很多不匹配的轨迹,分数也会降低。这促使研究人员增加unique的总数量,而不是专注于进行合理的检测和关联。
Track-mAP
这种度量匹配GroundTruth轨迹和预测轨迹。当轨迹相似性得分Str大于或等于阈值αtr时,在轨迹之间进行匹配。此外,预测的轨迹必须具有最高的置信度得分。
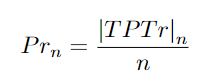
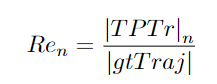
n:预测轨迹的总数。预测轨迹按照置信度得分降序排列。Prn:计算跟踪器的精度。TPTr:真正轨迹。找到匹配的任何预测轨迹。|TPTr|n:n条预测轨迹中的真正轨迹数。Ren:Measures Re-call。|gtTraj |:目标轨迹真值,使用精度和召回方程进行进一步计算,以获得最终Track−mAP分数。
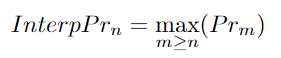
作者首先对精度值进行插值,得到每个n值的InterpPr。然后,作者将每个n值绘制一个InterpPr与 Ren 对应的图。作者现在有了精确-召回曲线。这条曲线的积分会给出 Track-mAP 得分。Track-mAP 也有一些缺点。轨迹mAP的跟踪结果很难直观地显示出来。它对于单个轨道有多个输出。低置信度得分的轨迹对最终得分的影响是模糊的。有一种方法可以“黑掉”这个度量标准。研究人员可以得到一个较高的分数,通过创造几个有较低置信度分数的预测。这将增加获得合适匹配的机会,从而增加得分。然而,这并不是一个良好跟踪的指标。跟踪 mAP 无法指示跟踪器是否具有更好的检测和关联。
HOTA
Higher Order Tracking Accuracy。原论文[96]将 HOTA 描述为: “ HOTA 测量匹配检测的轨迹对齐程度,并对整体匹配检测进行平均,同时惩罚不匹配的检测。”HOTA 应该是一个单一的分数,可以涵盖跟踪评估的所有要素。它还应该被分解为子度量。HOTA 弥补了其他常用指标的缺点。虽然像 MOTA 这样的指标忽略关联并且严重依赖于检测(MOTA)或反之亦然(IDF1),但是 TPA,FPA 和 FNA 等新概念的发展使得关联可以像TP,FNs 和 FP 用于测量检测一样进行测量。
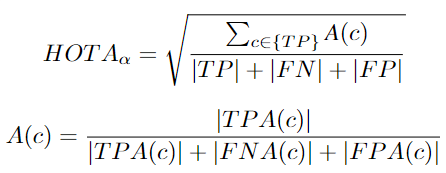
A(c):测量预测轨迹和groundtruth轨迹的相似程度。TP:真正例,在S ≥ α的条件下,将groundtruth检测与预测检测相匹配。S是定位相似度,α是阈值。FN: 假反例。漏掉的groundtruth检测 FP: 假正例。一种没有与任何groundtruth匹配的预测。TPA: 真正关联正例。与给定的 TPC 具有相同的groundtruth ID和相同的预测ID的真正正例的集合。
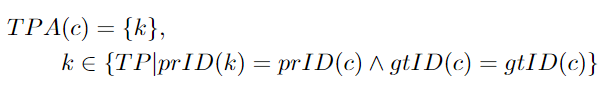
FNA: 具有与给定TPC相同的groundtruth ID的一组groundtruth检测目标。然而,这些检测目标被分配了一个不同于c或根本没有的预测ID。
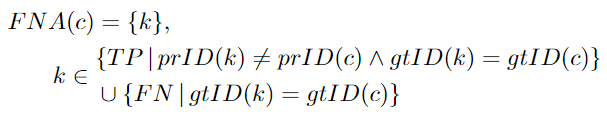
FPA:与给定TPc具有相同预测ID的预测检测集。然而,这些检测目标被分配了一个不同于c的groundtruth ID,或者根本没有。
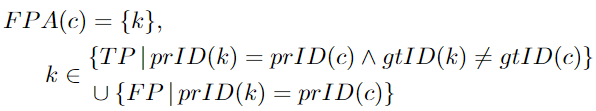
HOTaα 是计算α的特殊值的HOTA。需要进一步计算才能得到最终的HOTA分数。作者找到了不同α的值对应的HOTA,α范围从0到1,然后计算它们的平均值。
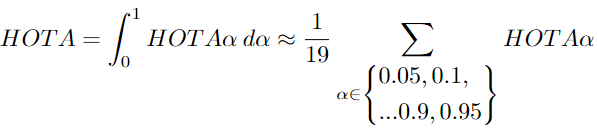
作者能够将 HOTA 分解为几个子指标。这很有用,因为可以采用跟踪评估的不同元素,并使用它们进行比较。可以更好地了解跟踪器正在产生的错误。跟踪中常见的错误有五种类型: 假反例、假正例、碎片化、合并和偏差。这些可以分别通过检测召回、检测精度、关联召回、关联精度和定位来衡量。
LocA
Localization Accuracy[96].
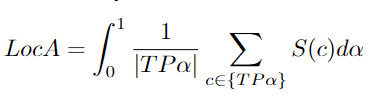
S(c): 预测检测与groundtruth之间的空间相似性得分。这个子度量处理错误类型偏差或定位错误。当预测检测和groundtruth不一致时,就会产生定位误差。这与 MOTP 类似,但又不同,因为它包含几个定位阈值。常用的度量标准,如 MOTA 和 IDF1没有考虑到定位。
AssA:Association Accuracy Score
根据 MOT 基准: “所有匹配检测的关联Jaccard索引的平均值,平均值超过定位阈值”[96]。关联是MOT 任务结果的一部分,它让大家知道不同帧中的目标是属于同一个还是不同的目标。这些目标具有相同的ID,并且是相同轨迹的一部分。关联精度给出了匹配轨迹之间的平均对齐度。它主要关注关联错误。这是由于groundtruth中的单个目标被给予了两种不同的预测,或者一个单独的预测被给予了两种不同的groundtruth目标。
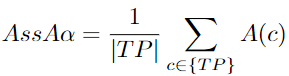
DetA:Detection Accuracy
根据 MOT 基准: “检测 Jaccard 索引平均超过定位阈值”[96]。检测是 MOT 任务的另一个输出。它只是帧内的目标。检测精度是正确检测的一部分。当groundtruth被忽略或者存在虚假检测时,检测误差就会存在。
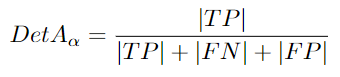
DetRe:Detection Recall
给出了一个定位阈值的计算方程。需要平均所有定位阈值[96]:
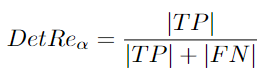
检测召回错误是假反例。它们发生时,跟踪器错过了一个真实目标,检测精度可分为检测召回和检测精度。
DetPr:
给出了一个计算定位阈值的方程,需要对所有定位阈值进行平均[96]:
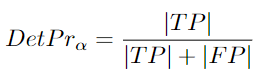
如前所述,检测精度是检测精度的一部分。检测精度误差为假正例(误检)。当追踪器做出不存在于groundtruth中的预测时,它们就会发生。
AssRe:Association Recall
需要计算下面的公式,然后计算所有匹配检测的平均值。最后,平均结果要超过定位阈值[96]:
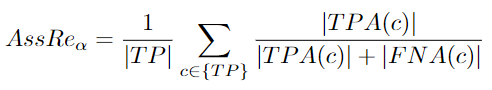
当跟踪器将不同的预测轨迹分配给相同的groundtruth轨迹时,就会发生关联召回错误。关联精度可分为关联召回和关联精度。
AssPr:Association Precision
作者需要计算下面的方程,然后对所有匹配检测进行平均。最后,结果的平均值超过定位阈值[96]:
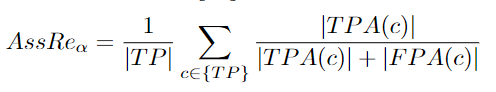
关联精度是关联精度的一部分。当两条不同的groundtruth轨迹具有相同的预测ID时,就会出现关联错误。
MOTSA: Multi Object Tracking and Segmentation Accuracy
这是 MOTA 度量的一种变体,因此也可以评估分割任务的跟踪器性能。
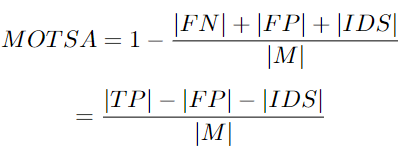
这里 M 是一组 N 个非空的groundtruth掩模。每个mask被分配一个groundtruth跟踪ID。TP 是一组真正例。当一个假设的掩码映射到一个groundtruth掩码时,真正例出现。FP 是假正例的,没有任何groundtruth,FN是一组假反例,有真值但没有任何相应的检测结果。IDS、ID切换是属于同一轨道但被分配了不同ID的groundtruth掩码。MOTSA 算法的缺点包括: 使检测比关联更加重要,并且会受到匹配阈值选择的影响。
AMOTA: Average Multiple Object Tracking Precision
这是通过平均所有recall的MOTA值来计算的:
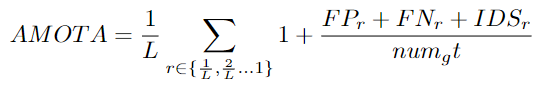
numg数值是所有帧中groundtruth目标的数量。对于一个特定的召回值r,FP的数目、FN的数目和ID切换的数目表示为 FPr、 FNr 和 IDSr。召回值的数量用 L 表示。
应用
MOT有无数应用程序。许多工作都涉及到跟踪各种目标,包括行人、动物、鱼、车辆、体育运动员等。实际上,多目标跟踪的领域不能仅限于几个领域。但是,为了从应用的角度获得一个想法,作者将根据具体的应用涵盖论文。
自动驾驶
自动驾驶可以说是多目标跟踪中最常见的任务。这是近年来人工智能领域的一个热门话题。高等人提出了一个自动驾驶的双重注意力网络,他们整合了两个注意力模块[97]。傅先生等人首先利用自注意力机制检测车辆,然后利用多维信息进行关联。他们还通过重新跟踪失踪的车辆来处理堵塞问题[62]。庞等人将车辆检测与基于随机有限集(RFS)引入3D MOT 的多测量模型滤波器(RFS-M3)相结合[98]。罗等人还应用了3D MOT技术,提出了模拟跟踪技术,该技术可以通过激光雷达捕捉到的点云来检测和关联飞行器。Mackenzie 等人做了两项研究: 一项是关于自动驾驶汽车的,另一项是关于运动的。他们研究了多目标避让(MOA)的整体表现,这是一种测量自动驾驶中行动注意力的工具。邹等人提出了一个轻量级的框架,用于路边摄像机拍摄的2D交通场景的全栈感知。Cho等人通过YOLOv4和DeepSORT的交通监控摄像头,在将图像从局部到全局坐标系统投影后,识别并跟踪了这些车辆[101]。
其它
行人跟踪:是多目标跟踪系统中最常见的任务之一。由于街头摄像头的视频很容易被捕捉,人们已经做了很多关于人类或行人跟踪的工作。
车辆监控:与自动驾驶一样,也是一项非常重要的任务。为了监控车辆的活动,可以应用MOT技术。
运动员跟踪:在人工智能时代,对任何运动中的运动员进行严格的分析都是最重要的战术之一。因此 MOT 在许多方面被用来跟踪运动员。
野生动物追踪:MOT 的一个潜在应用案例是野生动物跟踪。它可以帮助野生动物研究人员避免昂贵的传感器,这些传感器在某些情况下并不那么可靠。MOT在跟踪鱼类等水下生物方面也发挥着至关重要的作用。在[118]中,李等人提出了 CMFTNet,它通过应用联合检测和嵌入来提取和关联特征来实现。在复杂背景下,采用可变形卷积方法进一步提高特征的锐化能力,并借助重量平衡损失的方法实现对鱼的精确跟踪。
在视觉监控领域,Ahmed 等人提出了一个基于SSD和YOLO的协作机器人框架,用于检测和一系列跟踪算法的组合[120]。
还可以看到MOT在农业中的实施。为了跟踪番茄种植,Ge 等人使用基于YOLO的shufflenetv2作为基线,CBAM 作为注意力机制,BiFPN 作为多尺度融合结构,DeepSORT 作为跟踪[125]。Tan 等人还使用 YOLOv4作为棉花幼苗的检测器和一种基于光流的跟踪方法来跟踪幼苗[49]。
MOT还可以应用于各种现实生活中的应用,如安全监控、社会距离监控、雷达跟踪、活动识别、智能老年护理、犯罪跟踪、人员重识别、行为分析等。
未来方向
由于 MOT 是一个多年来的研究热点,人们已经在它上面做了大量的努力。但是,这个领域仍然有很大的发展空间。在这里,作者想指出一些MOT的潜在的方向:
在多个摄像头下进行多目标跟踪有点困难。主要的挑战是如何融合这些场景。但是,如果将非重叠摄像机的场景融合在一起,投影到虚拟世界中,那么 MOT 就可以在一个较长的区域内连续跟踪目标。类似的努力可以在[31]中看到。一个相对较新的数据集多摄像机多人跟踪也可用[126]。Xindi等人提出了一种用于多目标多摄像机跟踪的实时在线跟踪系统[127]。
基于类的跟踪系统可以与多目标跟踪相结合。MOT算法试图跟踪一帧中几乎所有的运动目标。如果可以进行基于类的跟踪,这将更好地应用于实际场景中。例如,鸟类跟踪MOT系统在机场非常有用,因为为了防止鸟类与飞机在跑道上相撞,目前采用了一些人工预防机制。它可以完全自动使用基于类的MOT系统。基于类的跟踪在许多方面有助于监视。因为它有助于有效地跟踪特定类型的目标。
MOT 在二维场景中有着广泛的应用。虽然这是一个有点具有挑战性的任务,利用MOT分析3D视频将是一个很好的研究课题。三维跟踪可以提供更精确的跟踪和遮挡处理。正如在三维场景深度信息保存,因此它有助于克服一个主要的挑战,MOT中的遮挡问题。
到目前为止,大多数transformer都被用作黑匣子。但transformer可以更具体地用于解决不同的MOT任务。一些方法是完全基于检测和进一步的回归被用来预测下一帧的边界框[128]。在这种情况下,DETR[25]可用于检测,因为它在检测目标方面有非常高的效率。
在任何应用程序中,轻量级体系结构对于实际应用程序都非常重要。因为轻量级体系结构是资源有效的,而且在实际场景中,资源是有限的。在MOT中,如果想在物联网嵌入式设备中部署一个模型,轻量级架构也是非常关键的。同时在实时跟踪中,轻量级体系结构起着非常重要的作用。因此,在不降低精度的情况下,如果能够实现更多的fps,那么它就可以在实际应用中实现,在实际应用中,轻量级体系结构是非常必要的。
在现实生活中,在线多目标跟踪是唯一可行的解决方案。因此,推理时间起着至关重要的作用。作者观察到近年来从研究人员那里获得更多准确性的趋势。但是,如果能够实现超过30帧率的推理时间,那么就可以使用MOT作为实时跟踪。由于实时跟踪是监控的关键,因此它是未来 MOT 研究的主要方向之一。
近年来,量子计算在计算机视觉中的应用呈现出一种趋势。量子计算也可以用于MOT。Zaech等人在Ising模型的帮助下发表了MOT使用绝热量子计算(AQC)的第一篇论文[129]。他们期望AQC能够在将来的关联过程中加速N-P硬分配问题。由于量子计算在不久的将来具有很大的潜力,这可能是一个非常有前途的研究领域。
总结
本文试图对计算机视觉在MOT中的最新发展趋势进行总结和回顾。作者试图分析其局限性和重大挑战。与此同时,作者发现,除了一些主要的挑战,如遮挡,ID切换,也有一些小的挑战。这项研究包括了与每种方法相关的简要理论,试图平等地关注每一种方法。作者也添加了一些流行的基准数据集以及他们自己的见解。根据最近的MOT趋势,展望了一些MOT未来可能的方向。作者发现,最近研究人员更多地关注基于transformer的结构,这是因为transformer的上下文信息存储能力。由于轻量级架构的transformer仍然是很吃资源的,所以开发新的模块也很必要。最后,希望本文的研究能够对多目标跟踪领域的研究者起到补充作用,开启多目标跟踪研究的新篇章。
往期回顾
3D多目标跟踪新思路!基于多传感器融合的加权几何距离关联方法
【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、多传感器融合、SLAM、光流估计、轨迹预测、高精地图、规划控制、AI模型部署落地等方向;
加入我们:自动驾驶之心技术交流群汇总!
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!


