
- 1鸿蒙(harmonyOS)开发,就是新风口
- 2数量关系:高频考点常用解题方法(二)_2名去a部门,b、c两个部门中选1个部门去2名
- 32024三掌柜赠书活动第十六期:AI时代Python金融大数据分析实战
- 4电脑有网但是浏览器无法连接到服务器_浏览器显示无法连接服务器怎么办
- 5程序员 你读过的书,藏着自己的命运 | 技术类(一)_ssm源碼技術內幕
- 6Module was compiled with an incompatible version of Kotlin.The binary version of its metadata is....
- 75个可以让你的模型在边缘设备上高效推理的算法
- 8【数学】【深度优先搜索】【图论】【欧拉环路】753. 破解保险箱
- 9分析:香港2亿港元诈骗案的风险特征及技术检测思路
- 10mysql按逗号拼接起来_MySql逗号拼接字符串查询的两种方法_mysql中查询逗号拼接的字段(有个字段值保存的是用逗号拼接的用户id)
百度PLATO-2 摘取DSTC9国际对话技术竞赛4项桂冠_为什么plato-2模型的短期记忆能力很好
赞
踩

欢迎关注【百度NLP】官方公众号,及时获取自然语言处理领域核心技术干货!!
阅读原文:https://mp.weixin.qq.com/s/tf1RxBzKlhTumM5FdUAwwA
全球人工智能学术竞赛DSTC是对话系统技术领域的顶级赛事。2020年度第九届国际对话技术竞赛 DSTC9共设有4个赛道(Track-1~Track-4),主办方包括Facebook、亚马逊、微软、卡内基梅隆大学、清华大学等,参与者广泛覆盖了企业和高校的参赛团队。近期DSTC9官方陆续公布各个赛道排名。
百度参与了DSTC9前3个赛道中4项任务的角逐,并在最终的榜单中拔得头名,成绩令人瞩目。这些赛道全面涵盖了开放域闲聊、知识对话、任务型对话等关键问题。据悉,百度在这些任务中所使用的核心技术,均基于其最近开源的开放域对话模型PLATO-2。
PLATO-2 是基于隐空间技术的大规模开放域对话模型,参数规模高达16亿,可就开放域话题深度畅聊,在中英文效果上,已全面超越Google Meena、Facebook Blender、微软小冰等先进模型。
PLATO-2采用了课程学习进行训练,其过程包括两个阶段:第一阶段,基于简化的“一对一”映射,训练得到基础的回复生成模型;第二阶段包含生成-评估两个模型,针对开放域对话的“一对多”问题,通过引入离散隐变量进行建模,训练得到更高质量的回复生成模型,同时训练评估模型,从多个候选中选择出最合适的回复。
这种框架具有很强的通用能力,在预训练各个阶段所获得的模型可广泛支持多种类型的对话系统。这次DSTC9的比赛结果就充分展示了PLATO-2在对话领域强大的通用能力。
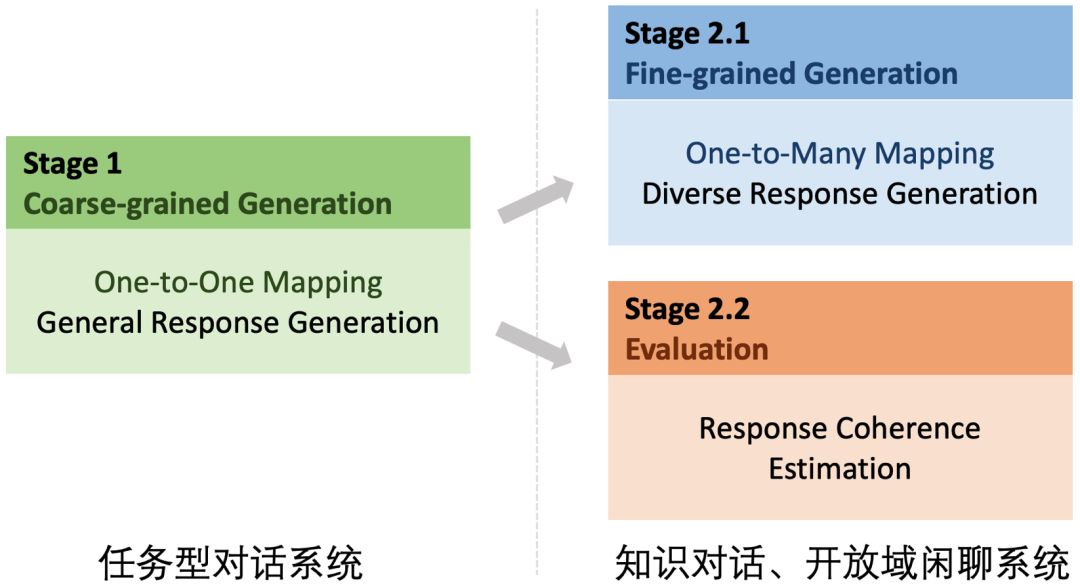
接下来,我们一起了解DSTC9中的4个任务以及基于PLATO-2的解决方案。
-
Track-1: Beyond Domain APIs: Task-oriented Conversational Modeling with Unstructured Knowledge Access
经典的任务型对话系统在回复用户时,依赖于查询结构化的数据库信息,但是在实际应用场景下,用户询问的问题会很多样,数据库常常缺乏相关信息。相比之下,非结构化知识信息,像FAQ等涵盖的范围更广,可以辅助系统回复用户。针对这个问题,该赛道共设置了3个级联的子任务:
-
判断当前对话上文是否需要使用外部非结构化的知识;
-
选取跟当前对话上文最匹配的 k 条非结构化知识;
-
根据选取的非结构化知识,进行系统回复生成。
参赛的系统需要完成3个级联的子任务,百度在最终的人工评估中,排名第一。在该赛道中,百度基于预训练模型进一步训练了前两个子任务的分类和排序模型,从而实现精准的知识选择,并得以辅助PLATO-2模型生成知识增强的回复。
如下图示例,系统根据对话上文,从大规模知识库中选出合适的知识,并合理的利用知识生成了高质量的回复,从该实例中可以看出,PLATO-2模型已经具备了一定的推理能力。

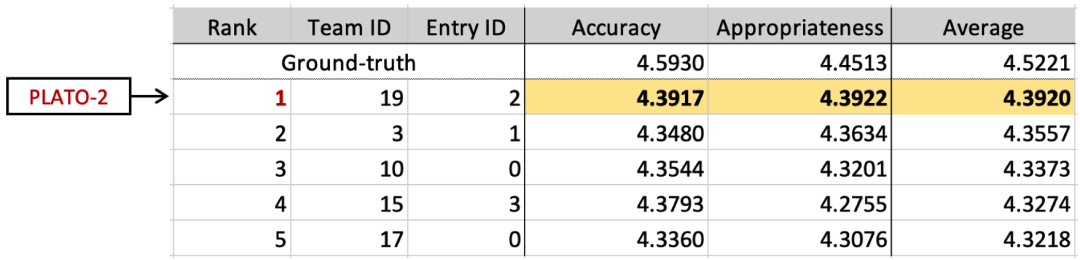
该赛道的人工评估综合考虑了回复中知识的准确度以及回复与上文的合适度,除了参赛系统,测试集人工标注的ground-truth也一起参与了评估。
结果显示,百度取得了4.39的分数,排名第一,跟人工标注结果仅有0.13的细微差距。这一结果表明,在此类极具挑战性的任务型对话场景下,模型能够以相对低廉的成本、较快的响应速度,为用户提供高质量的回复。
-
Track-2: Multi-domain Task-oriented Dialog Challenge II
和Track-1 类似,Track-2也是面向任务型的对话系统,但没有使用额外的非结构化知识。传统的任务型对话系统大多是模块化的,各个模块NLU、DST、Policy、NLG独立建模,且整个流程中涉及较多的人工干预。最新的技术开始探索端到端的任务型对话系统,模型可根据对话上文直接生成回复。该赛道共有2个独立的子任务:
Task 1: End-to-end Multi-domain Task Completion Dialog
Task 2: Cross-lingual Multi-domain Dialog State Tracking
百度参与了子任务1,并在最终的人工评估中,与另外一个团队并列第一。基于PLATO-2第一阶段模型,百度在该跨领域任务对话上进行了Fine-tuning,模型可以端到端地生成对话状态、对话动作以及高质回复。
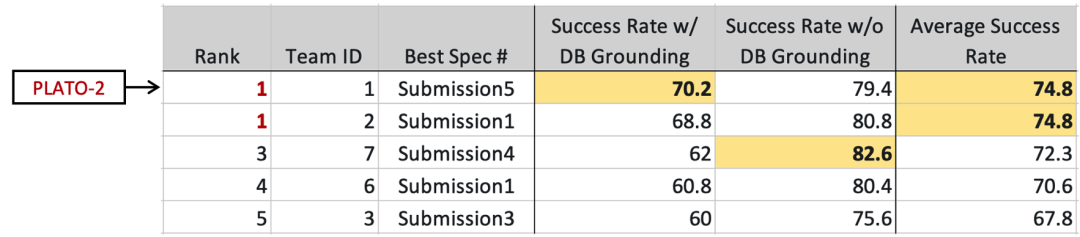
子任务1评估中,考虑了宽松和严格2种场景下的任务成功率:对于宽松评估(Success Rate w/o DB Grounding),众包人员跟系统交互,然后标注任务是否成功,该过程中不会审核系统的回复是否跟数据库信息冲突;对于严格评估(Success Rate w/ DB Grounding),针对众包人员标注任务成功的对话,会进一步审核系统回复是否跟数据库信息匹配,只有2个条件都满足才算任务成功。
宽松评估的区分度相对较弱,排名在前几位的方法差距较小;而严格评估则具有较强的区分度,且更能反映真实场景的性能,百度在该指标下排名第一,显著超越了其他系统。最终的榜单为宽松和严格评估的均值,百度和另外一个团队并列第一。
-
Track-3: Interactive Evaluation of Dialog
相比于前两个赛道,Track 3更接近开放域对话问题。它的特点是对于聊天的范围不设限制,也没有明确目标,以能和人类进行自由、有趣的交流为目的。
对于开放域对话,常用的评估方式有2种:静态评估以及交互评估。该赛道共有2个子任务,分别涉及知识对话的静态评估和开放域闲聊的人机交互评估:
Task 1: Static Evaluation of Dialog
Task 2: Interactive Evaluation of Dialog
在子任务1中,系统需要围绕话题进行回复生成,通过自动的选取知识和生成回复,可以跟用户就给定话题进行深入探讨。在子任务1的榜单中,百度PLATO-2模型排名第一。
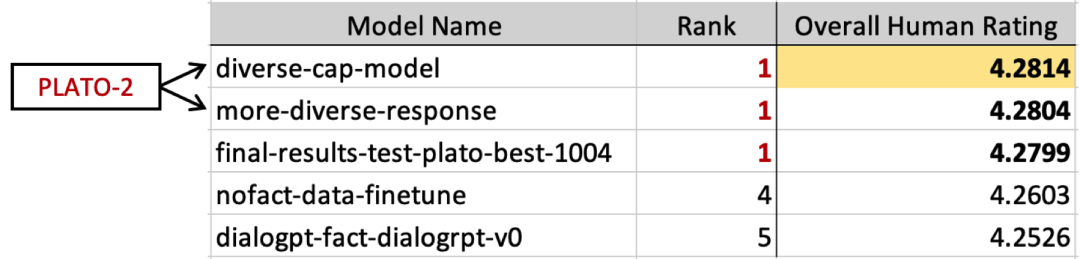
在子任务1中,系统需要针对给定的对话上文产出回复。在评估中,众包人员会从流畅性、相关性、准确度、参与度等8个方面对回复进行打分,并给出整体得分。榜单上,有3组模型的结果比较接近,最终并列头名,据悉前2组结果为百度提交的不同参数设置下的PLATO-2模型。因为PLATO-2已经开源,其他团队也有使用PLATO-2进行再训练提交结果。
在子任务2中,用户可以就任何话题进行聊天,系统需要精准理解用户,并产生连贯、有趣且有信息量的回复,这是当前对话技术最具挑战性的方向。在子任务2交互评估的榜单中,百度再次排名第一。
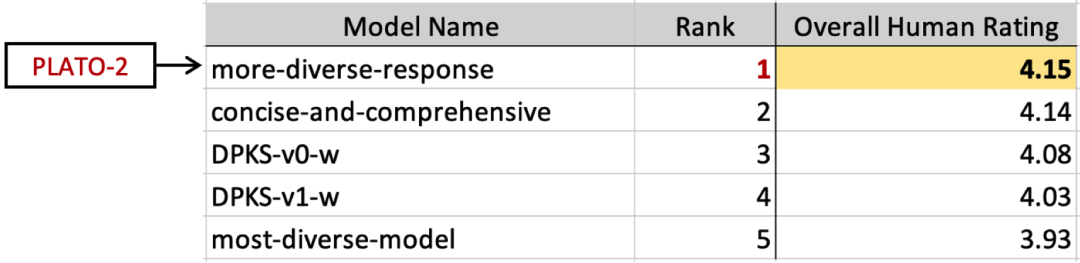
在子任务2中,互联网上的真实用户被邀请与机器人进行闲聊,且对话的内容和方向不设限制,以反映真实应用场景下对话系统的效果。收集到的人机交互对话会分发给众包人员进行评估,评估指标包括逻辑一致性、回复多样性、话题深度等10个方面,综合考量后给出整体得分。该子任务致力于评估开放域的人机交互效果,而这恰恰是PLATO-2的擅长之处。最终结果显示,该榜单前2名均被百度包揽,其中百度开源的PLATO-2模型排名第一。
在人机交互对话收集时,用户会被提前告知对方是机器人,因为PLATO-2表现比较优异,很多用户不禁询问系统到底是人类,还是机器人?不可否认,当前的对话系统在一些方面较人类水平尚有差距,但这些真实的人机交互记录显示,人工智能又朝着突破图灵测试迈进了坚实的一步。随着技术不断演进,智能对话未来的能力越发值得期待。
据悉,百度PLATO和PLATO-2均完全基于百度自主研发的飞桨深度学习平台。PLATO-2在训练过程中,利用了飞桨Fleet库的并行能力,使用了包括Recompute、混合精度训练等策略,基于高性能GPU集群进行训练。随着越来越多的AI能力的开放,百度飞桨也正在打造更加完整和成熟的技术生态。
开源链接:
https://github.com/PaddlePaddle/Knover
文章链接:
https://arxiv.org/abs/2006.16779
比赛地址:
https://sites.google.com/dstc.community/dstc9/tracks
百度自然语言处理(Natural Language Processing,NLP)以『理解语言,拥有智能,改变世界』为使命,研发自然语言处理核心技术,打造领先的技术平台和创新产品,服务全球用户,让复杂的世界更简单。
- 相关标签

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

