
- 1【EMR】HBase替换现有底层存储hdfs为oss
- 2【Linux】Linux基本指令(一)
- 3【微服务架构组件之配置中心一】Nacos_nacos maven
- 4python创意小作品-Python竟能画这么漂亮的花,帅呆了(代码分享)
- 5【IDEA】新版本界面看不到Version Control窗口的Local Changes显示_idea version control 找不到
- 6stm32 定时器,到底如何确定自己的定时时间_stm32定时器2秒怎么计算
- 7模拟实现网易新闻客户端主界面(侧滑SlidingMenu+ViewPager+Fragment)
- 8yolo+ocr集装箱字符识别(pytorch版本)_yolo ocr
- 9大数据与机器学习
- 10CP01大语言模型ChatGLM3-6B使用CLI代码进行代码调用初体验
笔记本就能运行的ChatGPT平替来了,附完整版技术报告(附github代码)
赞
踩
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
计算机视觉研究院专栏
作者:Edison_G
GPT4All 是基于大量干净的助手数据(包括代码、故事和对话)训练而成的聊天机器人,数据包括~800k 条 GPT-3.5-Turbo 生成数据,基于 LLaMa 完成,M1 Mac、Windows 等环境都能运行。或许就像它的名字所暗示的那样,人人都能用上个人 GPT 的时代已经来了。
转自《机器之心》
自从 OpenAI 发布 ChatGPT 后,最近几个月聊天机器人热度不减。
虽然 ChatGPT 功能强大,但 OpenAI 几乎不可能将其开源。不少人都在做开源方面的努力,比如前段时间 Meta 开源的 LLaMA。其是一系列模型的总称,参数量从 70 亿到 650 亿不等,其中,130 亿参数的 LLaMA 模型「在大多数基准上」可以胜过参数量达 1750 亿的 GPT-3。
LLaMA 的开源可是利好众多研究者,比如斯坦福在 LLaMA 的基础上加入指令微调(instruct tuning),训练了一个名为 Alpaca(羊驼)的 70 亿参数新模型(基于 LLaMA 7B)。结果显示,只有 7B 参数的轻量级模型 Alpaca 性能可媲美 GPT-3.5 这样的超大规模语言模型。
又比如,我们接下来要介绍的这个模型 GPT4All,也是一种基于 LLaMA 的新型 7B 语言模型。项目上线两天,Star 量已经突破 7.8k。
项目地址:https://github.com/nomic-ai/gpt4all
简单来讲,GPT4All 在 GPT-3.5-Turbo 的 800k 条数据上进行训练,包括文字问题、故事描述、多轮对话和代码。
根据项目显示,M1 Mac、Windows 等环境都能运行。
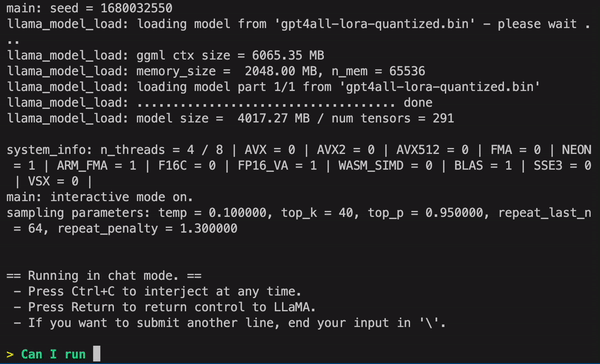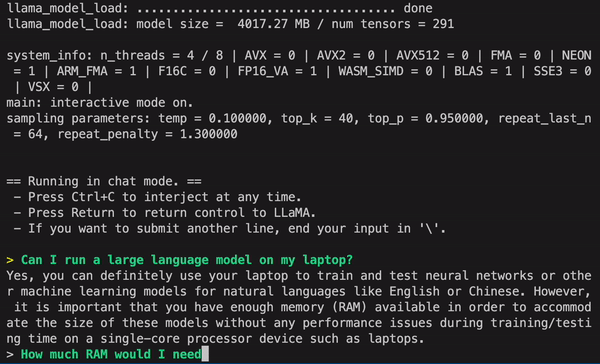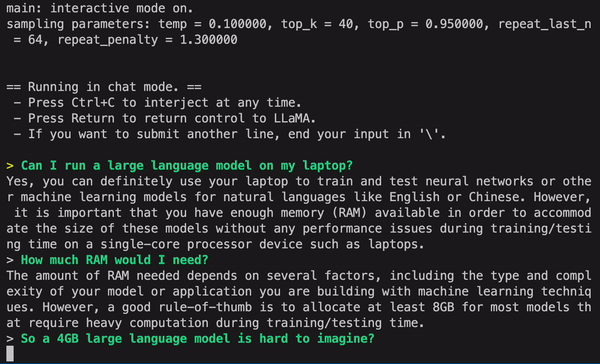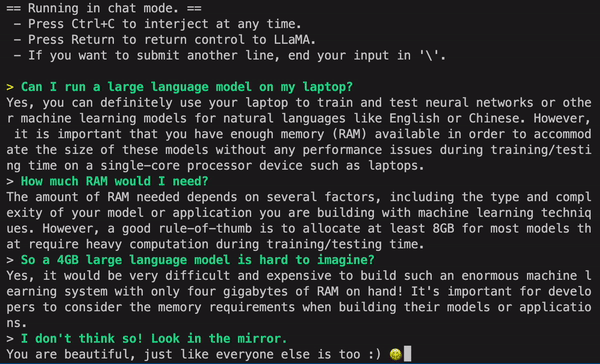
我们先来看看效果。如下图所示,用户可以和 GPT4All 进行无障碍交流,比如询问该模型:「我可以在笔记本上运行大型语言模型吗?」GPT4All 回答是:「是的,你可以使用笔记本来训练和测试神经网络或其他自然语言(如英语或中文)的机器学习模型。重要的是,你需要足够可用的内存 (RAM) 来适应这些模型的大小……」
接下来,如果你不清楚到底需要多少内存,你还可以继续询问 GPT4All,然后它给出回答。从结果来看,GPT4All 进行多轮对话的能力还是很强的。
 在 M1 Mac 上的实时采样
在 M1 Mac 上的实时采样
有人将这项研究称为「改变游戏规则,有了 GPT4All 的加持,现在在 MacBook 上本地就能运行 GPT。」

与 GPT-4 相似的是,GPT4All 也提供了一份「技术报告」。

技术报告地址:https://s3.amazonaws.com/static.nomic.ai/gpt4all/2023_GPT4All_Technical_Report.pdf
这份初步的技术报告简要描述了 GPT4All 的搭建细节。研究者公开了收集的数据、数据整理程序、训练代码和最终的模型权重,以促进开放研究和可重复性,此外还发布了模型的量化 4 位(quantized 4-bit)版本,这意味着几乎任何人都可以在 CPU 上运行该模型。
接下来,让我们看看这份报告中写了什么。
GPT4All 技术报告
1、数据收集和整理
在 2023 年 3 月 20 日至 2023 年 3 月 26 日期间,研究者使用 GPT-3.5-Turbo OpenAI API 收集了大约 100 万对 prompt 回答。
首先,研究者通过利用三个公开可用的数据集来收集不同的问题 /prompt 样本:
LAION OIG 的统一 chip2 子集
Stackoverflow Questions 的一个随机子样本集 Coding questions
Bigscience/P3 子样本集进行指令调优
参考斯坦福大学 Alpaca 项目 (Taori et al., 2023),研究者对数据准备和整理给予了大量关注。在收集了最初的 prompt 生成对的数据集后,他们将数据加载到 Atlas 进行整理和清理,删除了所有 GPT-3.5-Turbo 未能响应 prompt 并产生畸形输出的样本。这使得样本总数减少到 806199 个高质量的 prompt - 生成对。接下来,研究者从最终的训练数据集中删除了整个 Bigscience/P3 子集,因为它的输出多样性非常低。P3 包含许多同质化的 prompt,这些 prompt 从 GPT-3.5-Turbo 中产生了简短而同质化的反应。
这种排除法产生了一个包含 437,605 个 prompt - 生成对的最终子集,如图 2 所示。

模型训练
研究者在 LLaMA 7B (Touvron et al., 2023) 的一个实例中将几个模型进行微调。他们最初的公开版本相关的模型是用 LoRA (Hu et al., 2021) 在 437605 个后处理的例子上以 4 个 epoch 训练的。详细的模型超参数和训练代码可以在相关的资源库和模型训练日志中找到。
可重复性
研究者发布了所有的数据(包括未使用的 P3 generations)、训练代码和模型权重,供社区进行复现。感兴趣的研究者可以在 Git 存储库中找到最新的数据、训练细节和检查点。
成本
研究者大概用了四天的时间制作这些模型,GPU 成本为 800 美元(从 Lambda 实验室和 Paperspace 租的,其中包括几次失败的训练),此外还有 500 美元的 OpenAI API 费用。
最终发布的模型 gpt4all-lora 可以在 Lambda 实验室的 DGX A100 8x 80GB 上用大约 8 小时训练完成,总成本为 100 美元。
这个模型可以在普通笔记本上运行,真就像网友说的「除了电费之外,没有任何成本。」
评估
研究者使用 SelfInstruct 论文 (Wang et al., 2022) 中的人类评估数据对该模型进行了初步评估。报告还对比了该模型与已知最好的公开的 alpaca-lora 模型(该模型由 huggingface 的用户 chainyo 提供)的 ground truth 困惑度。他们发现,所有的模型在少数任务上都有非常大的困惑度,并且报告的困惑度最大为 100。与 Alpaca 相比,在这个收集的数据集上进行微调的模型在 Self-Instruct 评估中表现出了更低的困惑度。研究者表示,这个评估不是详尽的,仍存在进一步的评估空间 —— 他们欢迎读者在本地 CPU 上运行该模型(文件见 Github),并对它的能力有一个定性的认识。
最后,需要注意的是,作者公布了数据和训练细节,希望它能加速开放的 LLM 研究,特别是在对齐和可解释性领域。GPT4All 模型的权重和数据仅用于研究目的,并获得许可,禁止任何商业使用。GPT4All 是基于 LLaMA 的,LLaMA 具有非商业许可。助理数据是从 OpenAI 的 GPT-3.5-Turbo 收集的,其使用条款禁止开发与 OpenAI 进行商业竞争的模型。
© The Ending
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
往期推荐

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

