
- 1基于疫情打卡健康评测系统的设计与实现_健康监测系统e-r设计
- 2通过nodejs搭建客服系统还有闲谈
- 3linux常用桌面有两种,推荐!5款Linux常用桌面环境
- 4CorelDRAW Graphics Suite2024重磅发布,快来看看有哪些新功能吧!_coreldraw 插件大师系统工具cdr一键记账,自动识别文件生成效果图 账单#广告人 #插
- 5OpenAI开源"weak-to-strong"方法代码框架!我们带你一探究竟
- 6nlp-问答任务-抽取式问答
- 7如果把编程语言用中文来替代会怎么样?_如果编程用汉语
- 8小白在虚拟环境下安装transformers_pycharm 安装transformer
- 9ESXi 8.0 集成网卡驱动的简单方法_esxi8.0 网卡驱动
- 10Linux 终端命令之文件目录操作,对比Dos相关命令_dos linux 命令 对比
python中文词云分析_python爬虫——词云分析最热门电影《后来的我们》
赞
踩
1 模块库使用说明
1.1 requests库
requests 是用Python语言编写,基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库。它比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTTP 测试需求。
1.2 urllib库
urllib的request模块可以非常方便地抓取URL内容,也就是发送一个GET请求到指定的页面,然后返回HTTP的响应.
1.3jieba库
结巴”中文分词:做最好的 Python 中文分词组件
1.4 BeautifulSoup库
Beautiful Soup是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖析树(parse tree)。 它提供简单又常用的导航navigating,搜索以及修改剖析树的操作。
1.5pandas库
pandas是python的一个非常强大的数据分析库,常用于数据分析。
1.6 re库
正则表达式re(通项公式)是用来简洁表达一组字符串的表达式。优势是简洁。使用它来进行字符串处理。
1.7 wordcloud库
python中使用wordcloud包生成的词云图。我们最后要生成当前热映电影的分析词云。
2需求说明
介绍要做什么,将采用的方法、预期得到的结果是什么及其他需求说明。
爬取豆瓣网站https://movie.douban.com/cinema/nowplaying/ankang/ 城市为安康的豆瓣电影数据主要完成以下三个步骤
抓取网页数据
清理数据
用词云进行展示
使用的python版本是3.6.并使用中文分词,词云对豆瓣电影排行榜排行第一的电影进行数据分析,进行相应的词云展示。
3抓取和处理数据算法
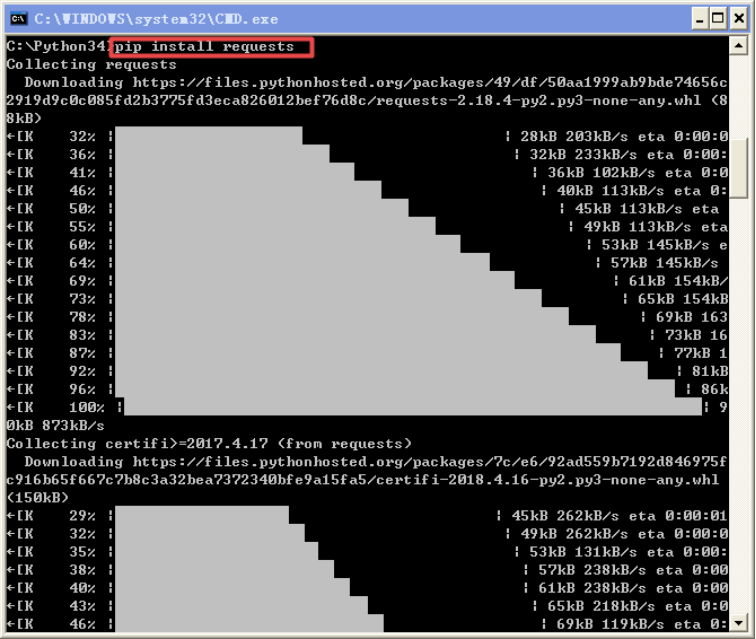
1)安装request模块
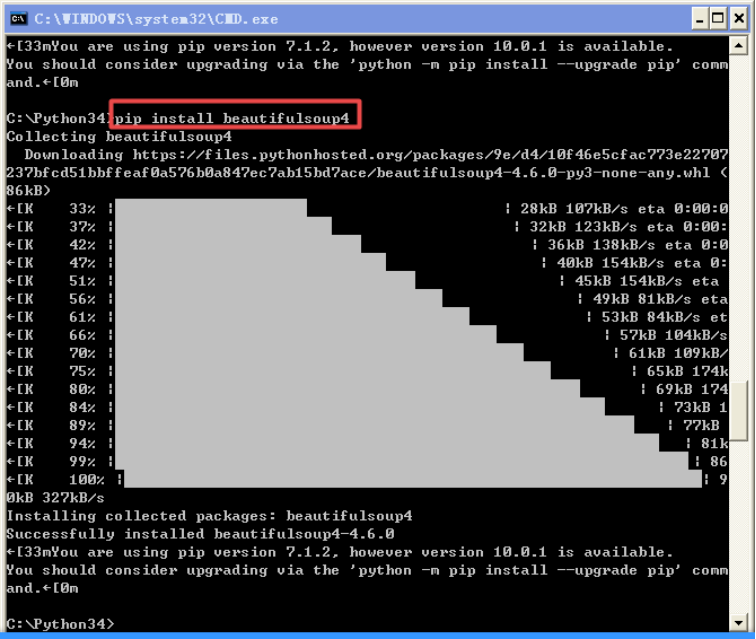
1.1)安装需要用到的beautifulsoup模块
2)查看要爬取网站的结构
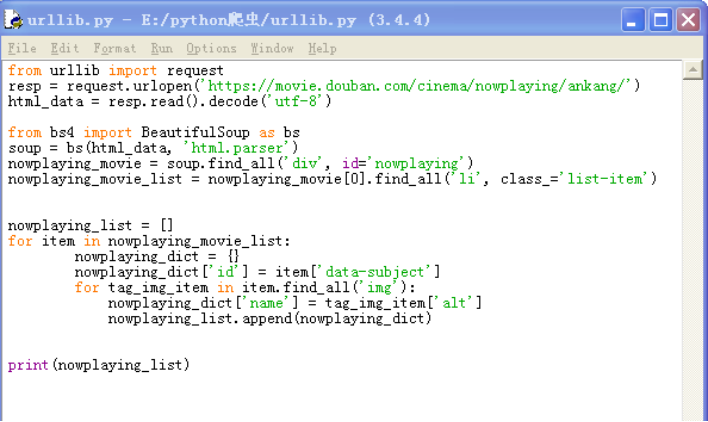
3)初步代码实现
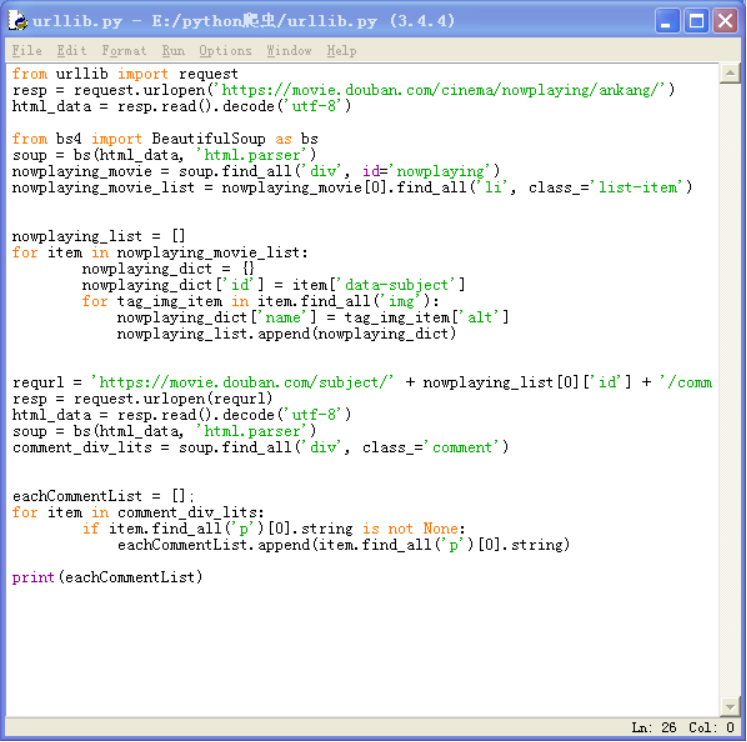
3.1)初步爬取到当前的院线上映信息
4.1)抓取到热映电影的第一个热评信息代码
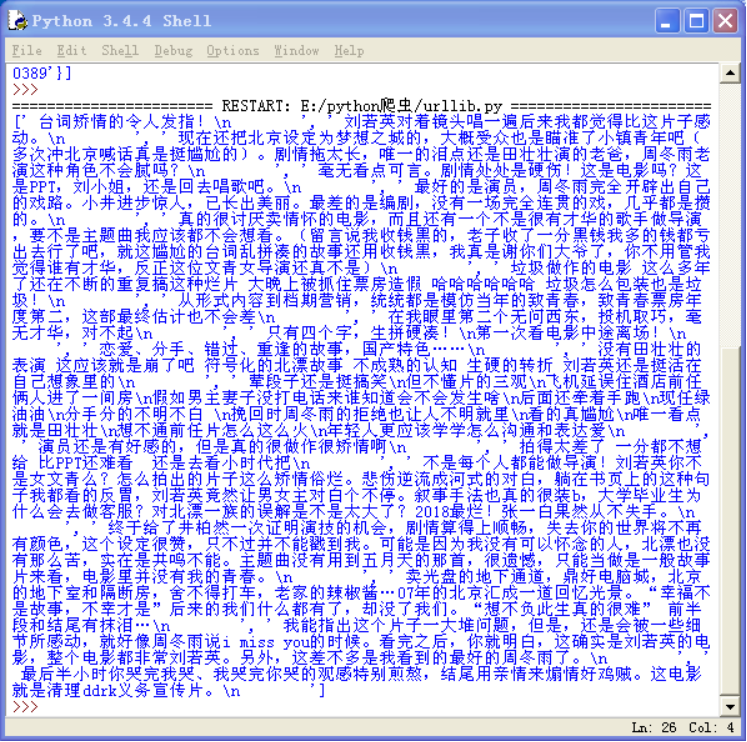
4.2)成功显示热评信息
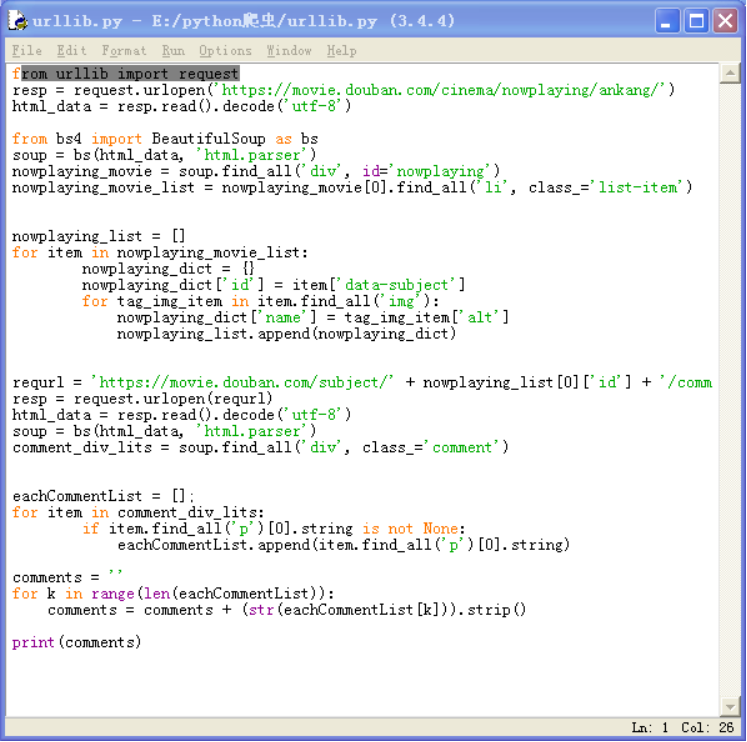
5.1)进行数据清洗上一步中格式错乱的代码
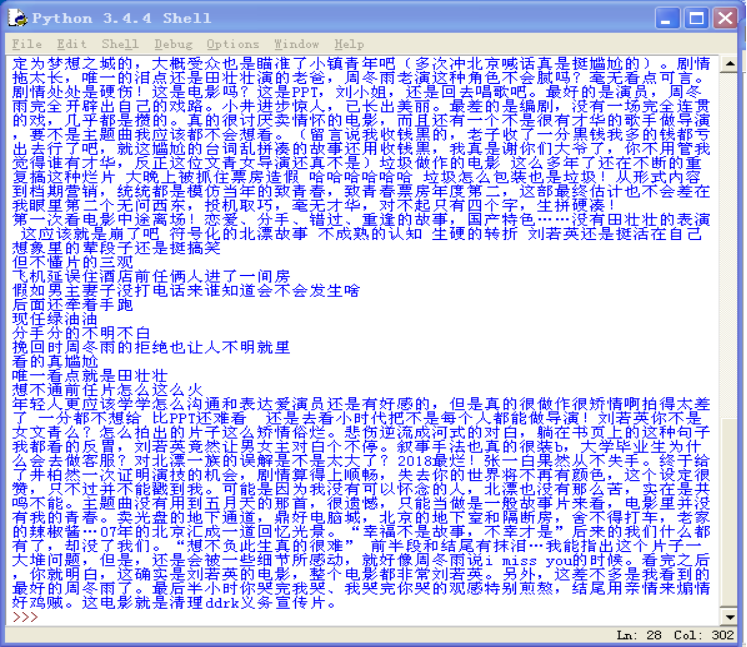
5.2)数据清洗后的《后来的我们》评论信息
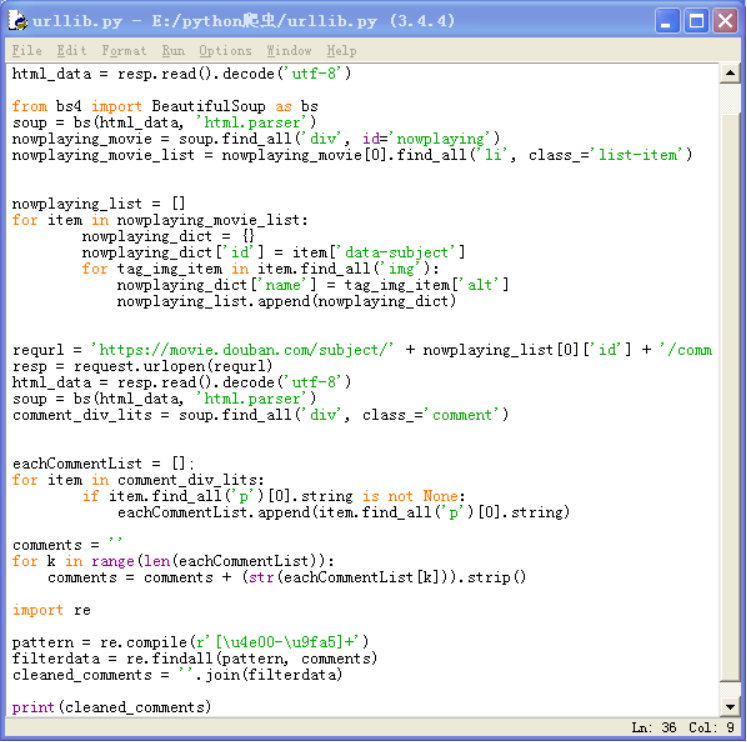
5.3)再次进行数据清洗去除掉标点符号代码
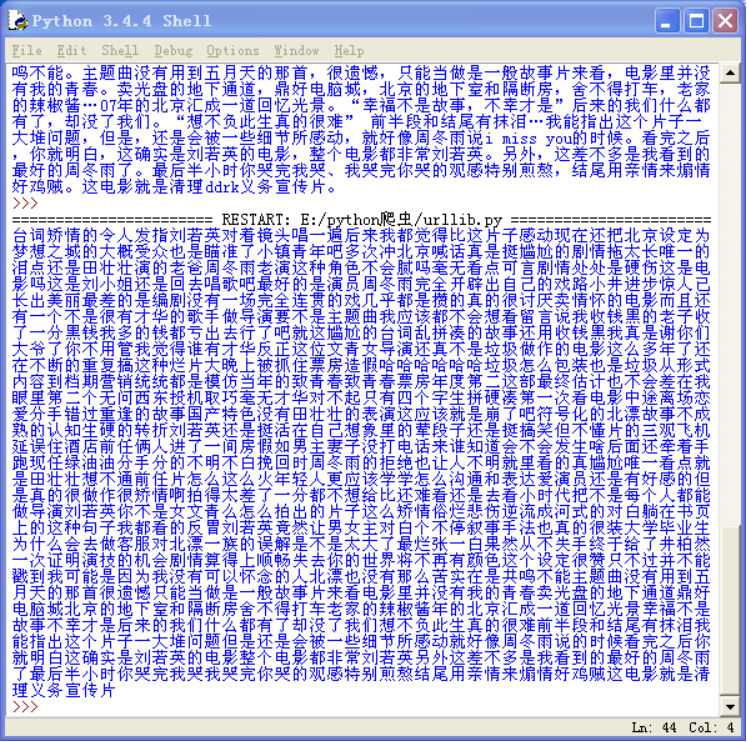
5.4)去除掉标点符号后的数据

6.1)安装pandas模块 ,用此方法依次安装wordcloud 库等。
def main():
# 循环获取第一个电影的前10页评论
commentList = []
NowPlayingMovie_list = getNowPlayingMovie_list()
for i in range(10):
num = i + 1
commentList_temp = getCommentsById(NowPlayingMovie_list[0]['id'], num)
commentList.append(commentList_temp)
使用for语句循环遍历获取排行榜第一的电影的前十页评论
完整代码:
# coding:utf-8
__author__ = 'LiuYang'
import warnings
warnings.filterwarnings("ignore")
import jieba # 分词包
import numpy # numpy计算包
import codecs # codecs提供的open方法来指定打开的文件的语言编码,它会在读取的时候自动转换为内部unicode
import re
import pandas as pd
import matplotlib.pyplot as plt
from urllib import request
from bs4 import BeautifulSoup as bs
import matplotlib
matplotlib.rcParams['figure.figsize'] = (10.0, 5.0)
from wordcloud import WordCloud # 词云包
# 分析网页函数
def getNowPlayingMovie_list():
resp = request.urlopen('https://movie.douban.com/nowplaying/ankang/') # 爬取安康地区的豆瓣电影信息
html_data = resp.read().decode('utf-8')
soup = bs(html_data, 'html.parser')
nowplaying_movie = soup.find_all('div', id='nowplaying')
nowplaying_movie_list = nowplaying_movie[0].find_all('li', class_='list-item')
nowplaying_list = []
for item in nowplaying_movie_list:
nowplaying_dict = {}
nowplaying_dict['id'] = item['data-subject']
for tag_img_item in item.find_all('img'):
nowplaying_dict['name'] = tag_img_item['alt']
nowplaying_list.append(nowplaying_dict)
return nowplaying_list
# 爬取评论函数
def getCommentsById(movieId, pageNum):
eachCommentList = [];
if pageNum > 0:
start = (pageNum - 1) * 20
else:
return False
requrl = 'https://movie.douban.com/subject/' + movieId + '/comments' + '?' + 'start=' + str(start) + '&limit=20'
print(requrl)
resp = request.urlopen(requrl)
html_data = resp.read().decode('utf-8')
soup = bs(html_data, 'html.parser')
comment_div_lits = soup.find_all('div', class_='comment')
for item in comment_div_lits:
if item.find_all('p')[0].string is not None:
eachCommentList.append(item.find_all('p')[0].string)
return eachCommentList
def main():
# 循环获取第一个电影的前10页评论
commentList = []
NowPlayingMovie_list = getNowPlayingMovie_list()
for i in range(10):
num = i + 1
commentList_temp = getCommentsById(NowPlayingMovie_list[0]['id'], num)
commentList.append(commentList_temp)
# 将列表中的数据转换为字符串
comments = ''
for k in range(len(commentList)):
comments = comments + (str(commentList[k])).strip()
# 使用正则表达式去除标点符号
pattern = re.compile(r'[\u4e00-\u9fa5]+')
filterdata = re.findall(pattern, comments)
cleaned_comments = ''.join(filterdata)
# 使用结巴分词进行中文分词
segment = jieba.lcut(cleaned_comments)
words_df = pd.DataFrame({'segment': segment})
# 去掉停用词
stopwords = pd.read_csv("stopwords.txt", index_col=False, quoting=3, sep="\t", names=['stopword'],
encoding='utf-8') # quoting=3全不引用
words_df = words_df[~words_df.segment.isin(stopwords.stopword)]
# 统计词频
words_stat = words_df.groupby(by=['segment'])['segment'].agg({"计数": numpy.size})
words_stat = words_stat.reset_index().sort_values(by=["计数"], ascending=False)
# 用词云进行显示
wordcloud = WordCloud(font_path="simhei.ttf", background_color="white", max_font_size=80)
word_frequence = {x[0]: x[1] for x in words_stat.head(1000).values}
word_frequence_list = []
for key in word_frequence:
temp = (key, word_frequence[key])
word_frequence_list.append(temp)
wordcloud = wordcloud.fit_words(dict (word_frequence_list))
plt.imshow(wordcloud)
plt.savefig("ciyun_jieguo .jpg")
# 主函数
main()
成功获取到结果
到代码路径获取词云结果图片如图:
词云结果图

4结果分析说明
选取安康地区院线电影排行信息,首先对正在上映的电影进行分析,获得最热门的电影信息,第二步对排行中最热门的电影《后来的我们》进行评论抓取,进行数据清洗,去除掉格式错误的错误信息,去除掉标点,中文的叠词,获取到出现频率最高的词汇,为了保证获取到的词云信息准确性,并且循环遍历十页评论信息,统计计数,再通过词云获取到此电影的词云信息。
由最终获得的词云分析图可知,我们顺利的爬取了安康地区的豆瓣电影信息,影院当前正在上映的电影信息,由此得到热门电影《后来的我们》此电影的特征标签,也基本上反映了这部电影的情况,观影者的感受,电影的主要角色,导演信息等一目了然。


