
- 1一篇文章彻底理解SharedPreferences_shared_prefs
- 2图论最短路径以及floyd算法的MATLAB实现
- 3基于Prometheus监控Kubernetes集群_prometheus 监控集群
- 4如何快速构建自己的AI客服 将GPT接入淘宝,抖店,拼多多,美团等电商平台 实现当前最强的客服机器人_轻简客服
- 5深度解析MFCC特征提取
- 6中洺科技:有多少智能,背后就有多少数据标注员_中洛科技有限公司数据标注
- 7华为畅享20se是鸿蒙系统吗,1299元的华为畅享20SE,你觉得值得入手吗?
- 8金融×元宇宙:虚实交融共进下的金融体系_但存在脱实
- 9adb进入recovery 以及fastboot模式_adb reboot recovery
- 10PostGIS 测试 - 基本类型(WKT & WKB)
细粒度图像识别
赞
踩
问题介绍
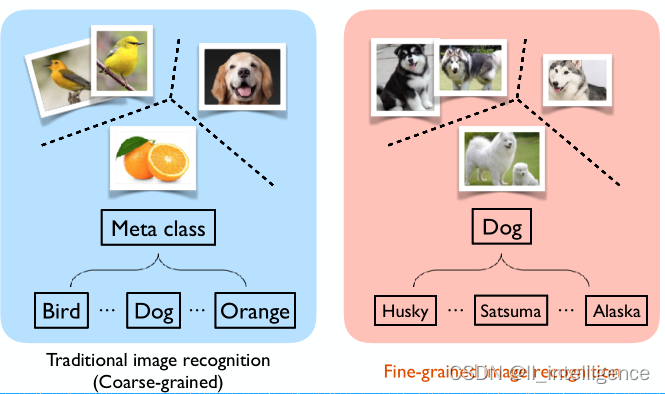
一般而言,图像识别分为两种:传统图像识别和细粒度图像识别。前者指的是对一些大的类别比如汽车、动物、植物等大的类别进行分类,这是属于粗粒度的图像识别。而后者则是在某个类别下做进一步分类。比如在狗的类别下区分狗的品种是哈士奇、柯基、萨摩还是阿拉斯加等等,这是属于细粒度图像识别。
数据集
在细粒度图像识别领域,经典的基准数据集包括:
- 鸟类数据集CUB200-2011,11788张图像,200个细粒度分类
- 狗类数据集Stanford Dogs,20580张图像,120个细粒度分类
- 花类数据集Oxford Flowers,8189张图像,102个细粒度分类
- 飞机数据集Aircrafts,10200张图像,100个细粒度分类
- 汽车数据集Stanford Cars,16185张图像,196个细粒度分类
细粒度图像分类作为一个热门的研究方向,每年的计算机视觉顶会都会举办一些workshop和挑战赛,比如Workshop on Fine-Grained Visual Categorization和iFood Classification Challenge。
挑战

上图展示的是CUB20鸟类数据集的部分图片。不同行表示的不同的鸟类别。很明显,这些鸟类数据集在同一类别上存在巨大差异,比如上图中每一行所展示的一样,这些差异包括姿态、背景等差异。但在不同类别的鸟类上却又存在着差异性小的问题,比如上图展示的第一列,第一列虽然分别属于不同类别,但却又十分相似。
因此可以看出,细粒度图像识别普遍存在类内差异性大(large intra-class variance)和类间差异性小(small inter-class variance)的特点。
方法
细粒度图像识别同样是作为图像分类任务,因此也可以直接使用通用图像识别中一些算法来做,比如直接使用resnet,vgg等网络模型直接训练识别,通常在数据集上,比如CUB200上就可以达到75%的准确率,但这种方法离目前的SOTA方法的精度至少差了10个点。
目前细粒度图像识别方法大致可以分为两类:
1.基于强监督学习方法:这里指的强监督信息是指bounding box或者landmark,举个例子,针对某一种鸟类,他和其他的类别的差异一般在于它的嘴巴、腿部,羽毛颜色等
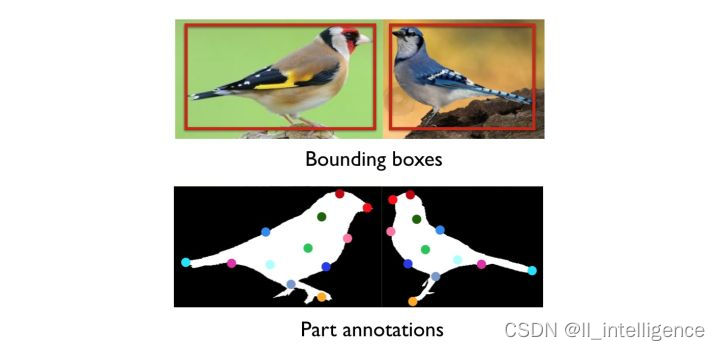
主流的方法像Part-based R-CNN,Pose Normalized CNN,Part-Stacked CNN等。
2.基于弱监督学习方法:什么是弱监督信息呢?就是说没有bounding box或者landmark信息,只有类别信息,开山之作应该属于2015年Bilinear CNN,这个模型当时在CUB200上是state of the art,即使和强监督学习方法相比也只是差1个点左右。
关于细粒度图像分析的综述,可以参考这里。由于强监督学习方法中对于大规模数据集来说,bounding box和landmark标注成本较高,因此,现在主流的研究方法都是是基于弱监督学习方法。
商业应用
典型算法Bilinear CNN
算法原理简介
介绍1,参考魏秀参《「见微知著」——细粒度图像分析进展综述》
双线性模型是近年来广泛应用的一种细粒度图像分类模型。该模型使用的是两个并列的CNN模型构建结构。
深度学习成功的一个重要精髓,就是将原本分散的处理过程,如特征提取,模型训练等,整合进了一个完整的系统,进行端到端的整体优化训练。不过,在以上所有的工作中,我们所看到的都是将卷积网络当做一个特征提取器,并未从整体上进行考虑。Bilinear CNN曾经在CUB200-2011数据集上取得了弱监督细粒度分类模型的最好分类准确度。
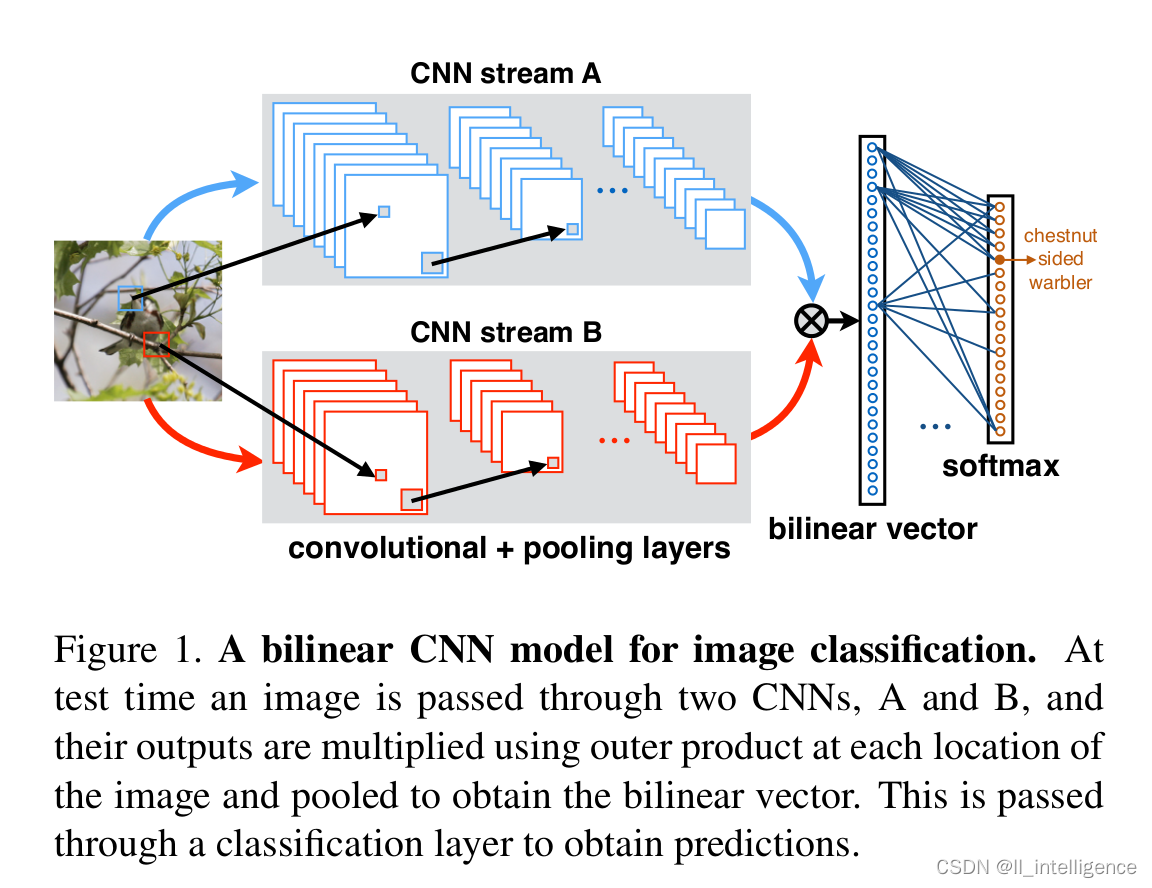
一个Bilinear模型
B
\mathcal { B }
B由一个四元组组成:
B
=
(
f
A
,
f
B
,
P
,
C
)
\mathcal { B } = \left( f _ { A } , f _ { B } , \mathcal { P } , \mathcal { C } \right)
B=(fA,fB,P,C)。其中
f
A
,
f
B
f _ { A } , f _ { B }
fA,fB代表特征提取函数,即图中的网络A、B,
P
\mathcal { P }
P是一个池化函数(pooling function),
C
\mathcal { C }
C则是分类函数。
特征提取函数f (·)的作用可以看作一个函数映射
f
:
L
×
I
→
R
c
×
D
f : \mathcal { L } \times \mathcal { I } \rightarrow R ^ { c \times D }
f:L×I→Rc×D,将输入图像
I
\mathcal { I }
I与位置区域
L
\mathcal { L }
L映射为一个cXD 维的特征。而两个特征提取函数的输出,可以通过双线性操作进行汇聚,得到最终的bilinear特征:
bilinear
(
l
,
I
,
f
A
,
f
B
)
=
f
A
(
l
,
I
)
T
f
B
(
l
,
I
)
\text { bilinear } \left( l , \mathcal { I } , f _ { A } , f _ { B } \right) = f _ { A } ( l , \mathcal { I } ) ^ { T } f _ { B } ( l , \mathcal { I } )
bilinear (l,I,fA,fB)=fA(l,I)TfB(l,I). 其中池化函数
P
\mathcal { P }
P的作用是将所有位置的bilinear特征汇聚成一个特征。
论文中所采用的池化函数是将所有位置的bilinear特征累加起来:
ϕ
(
I
)
=
∑
l
∈
L
bilinear
(
l
,
I
,
f
A
,
f
B
)
\phi ( \mathcal { I } ) = \sum _ { l \in \mathcal { L } } \text { bilinear } \left( l , \mathcal { I } , f _ { A } , f _ { B } \right)
ϕ(I)=∑l∈L bilinear (l,I,fA,fB)。到此bilinear向量即可表示该细粒度图像,后续则为经典的全连接层进行图像分类。
一种对Bilinear CNN模型的解释是,网络A的作用是对物体/部件进行定位,即完成前面介绍算法的物体与局部区域检测工作,而网络B则是用来对网络A检测到的物体位置进行特征提取。两个网络相互协调作用,完成了细粒度图像分类过程中两个最重要的任务:物体、局部区域的检测与特征提取。
介绍2,参考细粒度视觉识别之双线性CNN模型
细粒度识别
对同属一个子类的物体进行分类,通常需要对高度局部化、且与图像中姿态及位置无关的特征进行识别。例如,“加利福尼亚海鸥”与“环状海鸥”的区分就要求对其身体颜色纹理,或羽毛颜色的微细差异进行识别。
通常的技术分为两种:- 局部模型:先对局部定位,之后提取其特征,获得图像特征描述。缺陷:外观通常会随着位置、姿态及视角的改变的改变。
- 整体模型:直接构造整幅图像的特征表示。包括经典的图像表示方式,如Bag-of-Visual-Words,及其适用于纹理分析的多种变种。
基于CNN的局部模型要求对训练图像局部标注,代价昂贵,并且某些类没有明确定义的局部特征,如纹理及场景。
作者思路
- 局部模型高效性的原因:本文中,作者声称局部推理的高效性在于其与物体的位置及姿态无关。纹理表示通过将图像特征进行无序组合的设计,而获得平移无关性。
- 纹理表征性能不佳的思考:基于SIFT及CNN的纹理表征已经在细粒度物体识别上显示出高效性,但其性能还亚于基于局部模型的方法。其可能原因就是纹理表示的重要特征并没有通过端到端训练获得,因此在识别任务中没有达到最佳效果。
- 洞察点:某些广泛使用的纹理表征模型都可以写作将两个合适的特征提取器的输出,外积之后,经池化得到。
- 首先,(图像)先经过CNNs单元提取特征,之后经过双线性层及池化层,其输出是固定长度的高维特征表示,其可以结合全连接层预测类标签。最简单的双线性层就是将两个独立的特征用外积结合。这与图像语义分割中的二阶池化类似。
实验结果:作者在鸟类、飞机、汽车等细粒度识别数据集上对模型性能进行测试。表明B-CNN性能在大多细粒度识别的数据集上,都优于当前模型,甚至是基于局部监督学习的模型,并且相当高效。
!wget http://www.vision.caltech.edu/visipedia-data/CUB-200-2011/CUB_200_2011.tgz
!tar -xzf CUB_200_2011.tgz
- 1
- 2
引入工具库
import math import time import sys import os import random import shutil import pickle import numpy as np import tensorflow as tf import tensorflow.keras as keras from tensorflow.keras import layers, applications, backend, utils from tensorflow.keras.preprocessing import image import cv2 import PIL import PIL.Image import matplotlib.pyplot as plt ## 内存设定,可以调整内存占用百分比 config = tf.ConfigProto() config.gpu_options.allow_growth = True # config.gpu_options.per_process_gpu_memory_fraction = 0.5 session = tf.Session(config=config) tf.keras.backend.set_session(session) ## 数据集根目录 PATH_DATA_ROOT_CUB200 = "./CUB_200_2011" ## 总共200类 NO_CLASS = 200

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
训练集验证集切分
!rm -rf ./CUB_200_2011/splitted/train
!rm -rf ./CUB_200_2011/splitted/valid
!mkdir -p ./CUB_200_2011/splitted/train
!mkdir -p ./CUB_200_2011/splitted/valid
- 1
- 2
- 3
- 4
def split_trainval_CUB200(path_root_CUB200, n_sample=0): # 路径拼接 path_data_all = path_root_CUB200+"/images" path_data_train = os.path.join(path_root_CUB200, "splitted/train") path_data_valid = os.path.join(path_root_CUB200, "splitted/valid") # 遍历文件夹和文件 for subdir, dirs, files in os.walk(path_data_all): # 文件夹名为类别 name_class = os.path.basename(subdir) if name_class == os.path.basename(path_data_all): continue path_dir_train = path_data_train + '/' + name_class path_dir_valid = path_data_valid + '/' + name_class # 创建文件夹 if not os.path.exists(path_dir_train): os.mkdir(path_dir_train) if not os.path.exists(path_dir_valid): os.mkdir(path_dir_valid) # 遍历文件名和标签文件 list_path_file = np.genfromtxt(os.path.join(path_root_CUB200, 'images.txt'), dtype=str) list_label_file = np.genfromtxt(os.path.join(path_root_CUB200, 'image_class_labels.txt'), dtype=np.uint8) list_flg_split = np.genfromtxt(os.path.join(path_root_CUB200, 'train_test_split.txt'), dtype=np.uint8) max_file = len(list_path_file) list_mean_train = np.zeros(3) list_std_train = np.zeros(3) list_sample = [] count_train = 0 count_valid = 0 for i in range(len(list_path_file)): path_file = os.path.join(path_data_all, list_path_file[i, 1]) image = PIL.Image.open(path_file) if image.getbands()[0] == 'L': image = image.convert('RGB') image_np = np.array(image) image.close() if count_train + count_valid < n_sample: list_sample.append(image_np) if list_flg_split[i, 1] == 1: count_train += 1 path_file_copy = os.path.join(path_data_train, list_path_file[i, 1]) if not os.path.exists(path_file_copy): shutil.copy(path_file, path_file_copy) for dim in range(3): list_mean_train[dim] += image_np[:,:,dim].mean() list_std_train[dim] += image_np[:,:,dim].std() else: count_valid += 1 path_file_copy = os.path.join(path_data_valid, list_path_file[i, 1]) if not os.path.exists(path_file_copy): shutil.copy(path_file, path_file_copy) list_mean_train /= count_train list_std_train /= count_valid print("训练集样本数量 \n\t", count_train) print("验证集样本数量 \n\t", count_valid) print("训练集样本均值 \n\t", list_mean_train) print("训练集样本标准差\n\t", list_std_train) return np.asarray(list_sample)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
trainval = split_trainval_CUB200(path_root_CUB200=PATH_DATA_ROOT_CUB200, n_sample=10)
- 1
训练集样本数量
5994
验证集样本数量
5794
训练集样本均值
[123.82988033 127.3509729 110.25606303]
训练集样本标准差
[47.94397369 47.77511017 50.84676899]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
图像数据预处理
# opencv resize图片 def resize_image(x, size_target=None, flg_keep_aspect=False, rate_scale=1.0, flg_random_scale=False): # 转成numpy array if not isinstance(x, np.ndarray): img = np.asarray(x) else: img = x # 计算resize系数 if len(img.shape) == 4: _o, size_height_img, size_width_img, _c , = img.shape img = img[0] elif len(img.shape) == 3: size_height_img, size_width_img, _c , = img.shape if len(size_target) == 1: size_heigth_target = size_target size_width_target = size_target if len(size_target) == 2: size_heigth_target = size_target[0] size_width_target = size_target[1] if size_target == None: size_heigth_target = size_height_img * rate_scale size_width_target = size_width_img * rate_scale coef_height = 1 coef_width = 1 if size_height_img < size_heigth_target : coef_height = size_heigth_target / size_height_img if size_width_img < size_width_target : coef_width = size_width_target / size_width_img # 从小图到大图做scale low_scale = rate_scale if flg_random_scale: low_scale = 1.0 coef_max = max(coef_height, coef_width) * np.random.uniform(low=low_scale, high=rate_scale) # resize图片 size_height_resize = math.ceil(size_height_img*coef_max) size_width_resize = math.ceil(size_width_img*coef_max) # method_interpolation = cv2.INTER_LINEAR method_interpolation = cv2.INTER_CUBIC # method_interpolation = cv2.INTER_NEAREST if flg_keep_aspect: img_resized = cv2.resize(img, dsize=(size_width_resize, size_height_resize), interpolation=method_interpolation) else: img_resized = cv2.resize(img, dsize=(int(size_width_target*np.random.uniform(low=low_scale, high=rate_scale)), int(size_heigth_target*np.random.uniform(low=low_scale, high=rate_scale))), interpolation=method_interpolation) return img_resized def resize_images(images, **kwargs): max_images = len(images) for i in range(max_images): images[i] = resize_image(images[i], **kwargs) return images # 中心截取(center crop)图片 def center_crop_image(x, size_target=(448,448)): # 转成numpy array if not isinstance(x, np.ndarray): img = np.asarray(x) else: img = x # 设定尺寸 if len(size_target) == 1: size_heigth_target = size_target size_width_target = size_target if len(size_target) == 2: size_heigth_target = size_target[0] size_width_target = size_target[1] if len(img.shape) == 4: _o, size_height_img, size_width_img, _c , = img.shape img = img[0] elif len(img.shape) == 3: size_height_img, size_width_img, _c , = img.shape # 截取图片 h_start = int((size_height_img - size_heigth_target) / 2) w_start = int((size_width_img - size_width_target) / 2) img_cropped = img[h_start:h_start+size_heigth_target, w_start:w_start+size_width_target, :] return img_cropped # 随机截取图片 def random_crop_image(x, size_target=(448,448)): # 转成numpy array if not isinstance(x, np.ndarray): img = np.asarray(x) else: img = x # 设定尺寸 if len(size_target) == 1: size_heigth_target = size_target size_width_target = size_target if len(size_target) == 2: size_heigth_target = size_target[0] size_width_target = size_target[1] if len(img.shape) == 4: _o, size_height_img, size_width_img, _c , = img.shape img = img[0] elif len(img.shape) == 3: size_height_img, size_width_img, _c , = img.shape # 截取图片 margin_h = (size_height_img - size_heigth_target) margin_w = (size_width_img - size_width_target) h_start = 0 w_start = 0 if margin_h != 0: h_start = np.random.randint(low=0, high=margin_h) if margin_w != 0: w_start = np.random.randint(low=0, high=margin_w) img_cropped = img[h_start:h_start+size_heigth_target, w_start:w_start+size_width_target, :] return img_cropped # 水平翻转图片 def horizontal_flip_image(x): if np.random.random() >= 0.5: return x[:,::-1,:] else: return x # 归一化(feature-wise normalization) def normalize_image(x, mean=(0., 0., 0.), std=(1.0, 1.0, 1.0)) : x = np.asarray(x, dtype=np.float32) if len(x.shape) == 4: for dim in range(3): x[:,:,:,dim] = ( x[:,:,:,dim] - mean[dim] ) / std[dim] if len(x.shape) == 3: for dim in range(3): x[:,:,dim] = ( x[:,:,dim] - mean[dim] ) / std[dim] return x def check_images(images): fig=plt.figure(figsize=(8, 8)) columns = 3 rows = 3 for i in range(1, columns*rows+1): fig.add_subplot(rows, columns, i) plt.imshow(images[i-1]) plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
验证上述工具函数
check_images(trainval)
- 1
trainval_resized = resize_images(trainval, size_target=(448,448), flg_keep_aspect=True)
check_images(trainval_resized)
- 1
- 2
trainval_resized_flipped = trainval_resized.copy()
for i in range(9):
trainval_resized_flipped[i] = horizontal_flip_image(trainval_resized_flipped[i])
check_images(trainval_resized_flipped)
- 1
- 2
- 3
- 4
trainval_resized_cropped = trainval_resized.copy()
for i in range(9):
trainval_resized_cropped[i] = center_crop_image(trainval_resized_cropped[i])
check_images(trainval_resized_cropped)
- 1
- 2
- 3
- 4
trainval_resized_cropped = trainval_resized.copy()
for i in range(9):
trainval_resized_cropped[i] = random_crop_image(trainval_resized_cropped[i])
check_images(trainval_resized_cropped)
- 1
- 2
- 3
- 4
加载数据
import tensorflow.keras as keras import tensorflow.keras.backend as backend from tensorflow.keras.preprocessing.image import load_img from tensorflow.keras.preprocessing.image import img_to_array from tensorflow.keras.preprocessing.image import array_to_img class DirectoryIterator(keras.preprocessing.image.DirectoryIterator): def _get_batches_of_transformed_samples(self, index_array): batch_x = np.zeros( (len(index_array),) + self.image_shape, dtype=backend.floatx()) grayscale = self.color_mode == 'grayscale' # 构建一个batch的图像数据 for i, j in enumerate(index_array): fname = self.filenames[j] img = load_img(os.path.join(self.directory, fname), grayscale=grayscale, target_size=None, interpolation=self.interpolation) x = img_to_array(img, data_format=self.data_format) # PIL工具库的话,要额外手动close if hasattr(img, 'close'): img.close() x = self.image_data_generator.standardize(x) batch_x[i] = x # 把数据扩增过后的图像写到硬盘,方便debug if self.save_to_dir: for i, j in enumerate(index_array): img = array_to_img(batch_x[i], self.data_format, scale=True) fname = '{prefix}_{index}_{hash}.{format}'.format( prefix=self.save_prefix, index=j, hash=np.random.randint(1e7), format=self.save_format) img.save(os.path.join(self.save_to_dir, fname)) # 构建一个batch的标签 if self.class_mode == 'input': batch_y = batch_x.copy() elif self.class_mode == 'sparse': batch_y = self.classes[index_array] elif self.class_mode == 'binary': batch_y = self.classes[index_array].astype(backend.floatx()) elif self.class_mode == 'categorical': batch_y = np.zeros( (len(batch_x), self.num_classes), dtype=backend.floatx()) for i, label in enumerate(self.classes[index_array]): batch_y[i, label] = 1. else: return batch_x return batch_x, batch_y class ImageDataGenerator(keras.preprocessing.image.ImageDataGenerator): def flow_from_directory(self, directory, target_size=(256, 256), color_mode='rgb', classes=None, class_mode='categorical', batch_size=16, shuffle=True, seed=None, save_to_dir=None, save_prefix='', save_format='png', follow_links=False, subset=None, interpolation='nearest'): return DirectoryIterator( directory, self, target_size=target_size, color_mode=color_mode, classes=classes, class_mode=class_mode, data_format=self.data_format, batch_size=batch_size, shuffle=shuffle, seed=seed, save_to_dir=save_to_dir, save_prefix=save_prefix, save_format=save_format, follow_links=follow_links, subset=subset, interpolation=interpolation)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
def load_data(path_data_train=None,path_data_valid=None, size_width=448,size_heigth=448,size_mini_batch=16,flg_debug=False,**kwargs): # 设定图像预处理函数 func_train = lambda x :normalize_image( random_crop_image(horizontal_flip_image(resize_image(x, size_target=(size_heigth,size_width), flg_keep_aspect=True))), mean=[123.82988033, 127.3509729, 110.25606303] ) func_valid = lambda x :normalize_image( center_crop_image(resize_image(x, size_target=(size_heigth,size_width), flg_keep_aspect=True)), mean=[123.82988033, 127.3509729, 110.25606303] ) # 设置图像数据generator gen_train = ImageDataGenerator(preprocessing_function=func_train) gen_valid = ImageDataGenerator(preprocessing_function=func_valid) gen_dir_train = gen_train.flow_from_directory( path_data_train, target_size=(size_heigth, size_width), batch_size=size_mini_batch ) gen_dir_valid = gen_valid.flow_from_directory( path_data_valid, target_size=(size_heigth, size_width), batch_size=size_mini_batch, shuffle=False ) return gen_dir_train, gen_dir_valid
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
gen_dir_train, gen_dir_valid = load_data(
path_data_train=PATH_DATA_ROOT_CUB200+"/splitted/train",
path_data_valid=PATH_DATA_ROOT_CUB200+"/splitted/valid",
size_mini_batch=9
)
- 1
- 2
- 3
- 4
- 5
Found 5994 images belonging to 200 classes.
Found 5794 images belonging to 200 classes.
- 1
- 2
x_train, y_train = gen_dir_train.next()
check_images(x_train)
- 1
- 2
WARNING: Logging before flag parsing goes to stderr.
W0623 07:05:53.617257 139782910048128 image.py:648] Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
W0623 07:05:53.633468 139782910048128 image.py:648] Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
W0623 07:05:53.648106 139782910048128 image.py:648] Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
W0623 07:05:53.661940 139782910048128 image.py:648] Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
W0623 07:05:53.675533 139782910048128 image.py:648] Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
W0623 07:05:53.688506 139782910048128 image.py:648] Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
W0623 07:05:53.702074 139782910048128 image.py:648] Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
W0623 07:05:53.717030 139782910048128 image.py:648] Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
W0623 07:05:53.731333 139782910048128 image.py:648] Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
构建模型
from keras.initializers import glorot_normal def outer_product(x): """ 计算2个tensors的外积 x为包含2个tensor的list,tensor维度为(size_minibatch, total_pixels, size_filter) """ return keras.backend.batch_dot(x[0], x[1], axes=[1,1]) / x[0].get_shape().as_list()[1] def signed_sqrt(x): """ 计算1个tensor的逐元素符号平方根(element-wise signed square root) """ return keras.backend.sign(x) * keras.backend.sqrt(keras.backend.abs(x) + 1e-9) def L2_norm(x, axis=-1): """ 计算L2-norm """ return keras.backend.l2_normalize(x, axis=axis) def build_model(size_heigth=448, size_width=448, no_class=200, no_last_layer_backbone=17, name_optimizer="adam", rate_learning=1.0, rate_decay_learning=0.0, rate_decay_weight=0.0, name_initializer="glorot_normal", name_activation_logits="softmax", name_loss="categorical_crossentropy", flg_debug=False, **kwargs): keras.backend.clear_session() print("-------------------------------") print("parameters:") for key, val in locals().items(): if not val == None and not key == "kwargs": print("\t", key, "=", val) print("-------------------------------") # 加载预训练模型 tensor_input = keras.layers.Input(shape=[size_heigth,size_width,3]) model_detector = keras.applications.vgg16.VGG16(input_tensor=tensor_input, include_top=False, weights='imagenet') # bi-linear pooling实现 # detector抽取特征 x_detector = model_detector.layers[no_last_layer_backbone].output shape_detector = model_detector.layers[no_last_layer_backbone].output_shape if flg_debug: print("shape_detector : {}".format(shape_detector)) # extractor抽取特征 shape_extractor = shape_detector x_extractor = x_detector if flg_debug: print("shape_extractor : {}".format(shape_extractor)) # rehape成(minibatch_size, total_pixels, filter_size)的维度 x_detector = keras.layers.Reshape([ shape_detector[1] * shape_detector[2] , shape_detector[-1] ])(x_detector) if flg_debug: print("x_detector shape after rehsape ops : {}".format(x_detector.shape)) x_extractor = keras.layers.Reshape([ shape_extractor[1] * shape_extractor[2] , shape_extractor[-1] ])(x_extractor) if flg_debug: print("x_extractor shape after rehsape ops : {}".format(x_extractor.shape)) # 特征tensor求外积,输出维度为(minibatch_size, filter_size_detector*filter_size_extractor) x = keras.layers.Lambda(outer_product)([ x_detector, x_extractor ]) if flg_debug: print("x shape after outer products ops : {}".format(x.shape)) # rehape成(minibatch_size, filter_size_detector*filter_size_extractor)的维度 x = keras.layers.Reshape([shape_detector[-1]*shape_extractor[-1]])(x) if flg_debug: print("x shape after rehsape ops : {}".format(x.shape)) # signed square-root x = keras.layers.Lambda(signed_sqrt)(x) if flg_debug: print("x shape after signed-square-root ops : {}".format(x.shape)) # L2 normalization x = keras.layers.Lambda(L2_norm)(x) if flg_debug: print("x shape after L2-Normalization ops : {}".format(x.shape)) # 后接全连接层 if name_initializer != None: name_initializer = eval(name_initializer+"()") x = keras.layers.Dense( units=no_class ,kernel_regularizer=keras.regularizers.l2(rate_decay_weight) ,kernel_initializer=name_initializer )(x) if flg_debug: print("x shape after Dense ops : {}".format(x.shape)) tensor_prediction = keras.layers.Activation(name_activation_logits)(x) if flg_debug: print("prediction shape : {}".format(tensor_prediction.shape)) # 给定头尾指定模型 model_bilinear = keras.models.Model( inputs=[tensor_input], outputs=[tensor_prediction] ) # 把前面的层次固定住,只让后面的层次学习 for layer in model_detector.layers: layer.trainable = False # 优化器 opt_adam = tf.keras.optimizers.Adam(lr=rate_learning, decay=rate_decay_learning) opt_rms = tf.keras.optimizers.RMSprop(lr=rate_learning, decay=rate_decay_learning) opt_sgd = tf.keras.optimizers.SGD(lr=rate_learning, decay=rate_decay_learning, momentum=0.9, nesterov=False) optimizers ={ "adam":opt_adam, "rmsprop":opt_rms, "sgd":opt_sgd } # 编译 model_bilinear.compile( loss=name_loss, optimizer=optimizers[name_optimizer], metrics=["categorical_accuracy"] ) # 如果debug,输出模型结构 if flg_debug: model_bilinear.summary() return model_bilinear
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
model = build_model(
no_class = NO_CLASS,
no_last_layer_backbone = 17,
rate_learning=1.0 ,
rate_decay_weight=1e-8 ,
flg_debug=True
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
------------------------------- parameters: flg_debug = True name_loss = categorical_crossentropy name_activation_logits = softmax name_initializer = glorot_normal rate_decay_weight = 1e-08 rate_decay_learning = 0.0 rate_learning = 1.0 name_optimizer = adam no_last_layer_backbone = 17 no_class = 200 size_width = 448 size_heigth = 448 ------------------------------- shape_detector : (None, 28, 28, 512) shape_extractor : (None, 28, 28, 512) x_detector shape after rehsape ops : (?, 784, 512) x_extractor shape after rehsape ops : (?, 784, 512) x shape after outer products ops : (?, 512, 512) x shape after rehsape ops : (?, 262144) x shape after signed-square-root ops : (?, 262144) x shape after L2-Normalization ops : (?, 262144) x shape after Dense ops : (?, 200) prediction shape : (?, 200) Model: "model" __________________________________________________________________________________________________ Layer (type) Output Shape Param # Connected to ================================================================================================== input_1 (InputLayer) [(None, 448, 448, 3) 0 __________________________________________________________________________________________________ block1_conv1 (Conv2D) (None, 448, 448, 64) 1792 input_1[0][0] __________________________________________________________________________________________________ block1_conv2 (Conv2D) (None, 448, 448, 64) 36928 block1_conv1[0][0] __________________________________________________________________________________________________ block1_pool (MaxPooling2D) (None, 224, 224, 64) 0 block1_conv2[0][0] __________________________________________________________________________________________________ block2_conv1 (Conv2D) (None, 224, 224, 128 73856 block1_pool[0][0] __________________________________________________________________________________________________ block2_conv2 (Conv2D) (None, 224, 224, 128 147584 block2_conv1[0][0] __________________________________________________________________________________________________ block2_pool (MaxPooling2D) (None, 112, 112, 128 0 block2_conv2[0][0] __________________________________________________________________________________________________ block3_conv1 (Conv2D) (None, 112, 112, 256 295168 block2_pool[0][0] __________________________________________________________________________________________________ block3_conv2 (Conv2D) (None, 112, 112, 256 590080 block3_conv1[0][0] __________________________________________________________________________________________________ block3_conv3 (Conv2D) (None, 112, 112, 256 590080 block3_conv2[0][0] __________________________________________________________________________________________________ block3_pool (MaxPooling2D) (None, 56, 56, 256) 0 block3_conv3[0][0] __________________________________________________________________________________________________ block4_conv1 (Conv2D) (None, 56, 56, 512) 1180160 block3_pool[0][0] __________________________________________________________________________________________________ block4_conv2 (Conv2D) (None, 56, 56, 512) 2359808 block4_conv1[0][0] __________________________________________________________________________________________________ block4_conv3 (Conv2D) (None, 56, 56, 512) 2359808 block4_conv2[0][0] __________________________________________________________________________________________________ block4_pool (MaxPooling2D) (None, 28, 28, 512) 0 block4_conv3[0][0] __________________________________________________________________________________________________ block5_conv1 (Conv2D) (None, 28, 28, 512) 2359808 block4_pool[0][0] __________________________________________________________________________________________________ block5_conv2 (Conv2D) (None, 28, 28, 512) 2359808 block5_conv1[0][0] __________________________________________________________________________________________________ block5_conv3 (Conv2D) (None, 28, 28, 512) 2359808 block5_conv2[0][0] __________________________________________________________________________________________________ reshape (Reshape) (None, 784, 512) 0 block5_conv3[0][0] __________________________________________________________________________________________________ reshape_1 (Reshape) (None, 784, 512) 0 block5_conv3[0][0] __________________________________________________________________________________________________ lambda (Lambda) (None, 512, 512) 0 reshape[0][0] reshape_1[0][0] __________________________________________________________________________________________________ reshape_2 (Reshape) (None, 262144) 0 lambda[0][0] __________________________________________________________________________________________________ lambda_1 (Lambda) (None, 262144) 0 reshape_2[0][0] __________________________________________________________________________________________________ lambda_2 (Lambda) (None, 262144) 0 lambda_1[0][0] __________________________________________________________________________________________________ dense (Dense) (None, 200) 52429000 lambda_2[0][0] __________________________________________________________________________________________________ activation (Activation) (None, 200) 0 dense[0][0] ================================================================================================== Total params: 67,143,688 Trainable params: 52,429,000 Non-trainable params: 14,714,688 __________________________________________________________________________________________________
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
模型训练
!rm -rf ./model/BCNN_keras/
!mkdir -p ./model/BCNN_keras/
- 1
- 2
def train_model(model=None, name_model="BCNN_keras", gen_dir_train=None, gen_dir_valid=None, max_epoch=50): path_model = "./model/{}/".format(name_model) if not os.path.exists(path_model): os.mkdir(path_model) now = time.strftime("%Y%m%d%H%M%S", time.localtime()) # 设定callbacks callback_logger = keras.callbacks.CSVLogger( path_model + "log_training_{}.csv".format(now), separator=',', append=False ) callack_saver = keras.callbacks.ModelCheckpoint( path_model + "E[{epoch:02d}]" + "_LOS[{val_loss:.3f}]" + "_ACC[{val_categorical_accuracy:.3f}]" + ".hdf5", monitor='val_loss', verbose=0, mode='auto', period=10, save_best_only=True ) callback_reducer = keras.callbacks.ReduceLROnPlateau( monitor='val_loss', factor=0.5, patience=5, min_lr=1e-6, min_delta=1e-3 ) callback_stopper = keras.callbacks.EarlyStopping( monitor='val_loss', min_delta=1e-3, patience=10, verbose=0, mode='auto' ) # callback列表 list_callback = [callback_logger, callack_saver, callback_reducer, callback_stopper] hist = model.fit_generator(gen_dir_train, epochs=max_epoch, validation_data=gen_dir_valid, callbacks=list_callback, workers=3, verbose=1 ) model.save_weights( path_model + "E[{}]".format(len(hist.history['val_loss'])) + "_LOS[{:.3f}]".format(hist.history['val_loss'][-1]) + "_ACC[{:.3f}]".format(hist.history['val_categorical_accuracy'][-1]) + ".h5" ) return hist
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
# 跑一个epoch试试
hist =train_model(
model=model,
gen_dir_train=gen_dir_train,
gen_dir_valid=gen_dir_valid,
max_epoch=1
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
W0623 07:13:55.044794 139782910048128 callbacks.py:875] `period` argument is deprecated. Please use `save_freq` to specify the frequency in number of samples seen.
666/666 [==============================] - 316s 474ms/step - loss: 367.7586 - categorical_accuracy: 0.3222 - val_loss: 418.5829 - val_categorical_accuracy: 0.3398
- 1
- 2
- 3
- 4
# fine-tuning全连接层
hist =train_model(
model=model
,gen_dir_train=gen_dir_train
,gen_dir_valid=gen_dir_valid
,max_epoch=50
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
W0623 07:19:38.975768 139782910048128 callbacks.py:875] `period` argument is deprecated. Please use `save_freq` to specify the frequency in number of samples seen. Epoch 1/50 666/666 [==============================] - 313s 469ms/step - loss: 274.4080 - categorical_accuracy: 0.5911 - val_loss: 437.1781 - val_categorical_accuracy: 0.3911 Epoch 2/50 666/666 [==============================] - 312s 469ms/step - loss: 271.4677 - categorical_accuracy: 0.6643 - val_loss: 457.2765 - val_categorical_accuracy: 0.4298 Epoch 3/50 666/666 [==============================] - 312s 469ms/step - loss: 290.3985 - categorical_accuracy: 0.6797 - val_loss: 507.5210 - val_categorical_accuracy: 0.4094 Epoch 4/50 666/666 [==============================] - 313s 469ms/step - loss: 301.3113 - categorical_accuracy: 0.6945 - val_loss: 514.2174 - val_categorical_accuracy: 0.4182 Epoch 5/50 666/666 [==============================] - 312s 469ms/step - loss: 305.5629 - categorical_accuracy: 0.7077 - val_loss: 513.8465 - val_categorical_accuracy: 0.4337 Epoch 6/50 666/666 [==============================] - 312s 469ms/step - loss: 324.8585 - categorical_accuracy: 0.6954 - val_loss: 525.4210 - val_categorical_accuracy: 0.4527 Epoch 7/50 666/666 [==============================] - 312s 469ms/step - loss: 208.0807 - categorical_accuracy: 0.8897 - val_loss: 305.6433 - val_categorical_accuracy: 0.5677 Epoch 8/50 666/666 [==============================] - 312s 469ms/step - loss: 148.8199 - categorical_accuracy: 0.8967 - val_loss: 280.6470 - val_categorical_accuracy: 0.5259 Epoch 9/50 666/666 [==============================] - 312s 469ms/step - loss: 135.8768 - categorical_accuracy: 0.8507 - val_loss: 251.0476 - val_categorical_accuracy: 0.5331 Epoch 10/50 666/666 [==============================] - 316s 474ms/step - loss: 139.0174 - categorical_accuracy: 0.8170 - val_loss: 283.5227 - val_categorical_accuracy: 0.4838 Epoch 11/50 666/666 [==============================] - 312s 469ms/step - loss: 137.4044 - categorical_accuracy: 0.8207 - val_loss: 290.1516 - val_categorical_accuracy: 0.4515 Epoch 12/50 666/666 [==============================] - 312s 469ms/step - loss: 134.7534 - categorical_accuracy: 0.8207 - val_loss: 265.6031 - val_categorical_accuracy: 0.5022 Epoch 13/50 666/666 [==============================] - 312s 469ms/step - loss: 134.4180 - categorical_accuracy: 0.8125 - val_loss: 255.2964 - val_categorical_accuracy: 0.5090 Epoch 14/50 666/666 [==============================] - 312s 469ms/step - loss: 126.0793 - categorical_accuracy: 0.8310 - val_loss: 250.7778 - val_categorical_accuracy: 0.5038 Epoch 15/50 666/666 [==============================] - 312s 468ms/step - loss: 129.4782 - categorical_accuracy: 0.8161 - val_loss: 268.4170 - val_categorical_accuracy: 0.4765 Epoch 16/50 437/666 [==================>...........] - ETA: 56s - loss: 125.5669 - categorical_accuracy: 0.8248
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
# 放开前面的层次一起fine-tuning
for layer in model.layers:
layer.trainable = True
opt_sgd = keras.optimizers.SGD(lr=1e-3, decay=1e-9, momentum=0.9, nesterov=False)
model.compile(
loss="categorical_crossentropy"
, optimizer=opt_sgd
, metrics=["categorical_accuracy"]
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
# 跑一个epoch试试
hist =train_model(
model=model
,gen_dir_train=gen_dir_train
,gen_dir_valid=gen_dir_valid
,max_epoch=1
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
# 全部fine-tuning
hist =train_model(
model=model
,gen_dir_train=gen_dir_train
,gen_dir_valid=gen_dir_valid
,max_epoch=33
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7

