
- 1搭建Nginx+AdGuard Home | 防止DNS劫持 | 过滤广告_adguardhome 上游dns推荐
- 2MySQL8.0 开启远程连接_mysql8开启远程连接
- 3基于小波变换和OMP的图像压缩算法matlab仿真_omp算法matlab
- 4django校园跑腿小程序(程序+开题报告)_校园跑腿系统开题报告
- 5Java哈希表_java 哈希表有哪些
- 6机器学习——基于R的svm练习_svm-rfe预后模型
- 7【论文阅读】iSAM贝叶斯树相关内容理解与学习
- 8嵌入式处理器选型指南_嵌入式系统处理器有哪几种?如何选择?
- 9php实例一实验报告心得,实验报告个人心得体会【两篇】
- 10JAVA初/中/高级程序员必须知道的知识_任务调度 java 初级 中级 高级
我的西皮优学习笔记(六)->verilog实战一_verilog产生一个周期脉冲
赞
踩
Verilog实战
1、组合逻辑和时序逻辑
1)组合逻辑和时序逻辑的比对
- 组合逻辑的输出状态和输入直接相关,时序逻辑必须在时钟上升沿触发后输出新值
- 组合逻辑容易出现竞争、冒险现象,时序逻辑一般不会出现竞争、冒险现象(毛刺)
- 组合逻辑的时序较难保证,时序逻辑更容易达到时序收敛,时序逻辑更可控
- 组合逻辑只适合简单的电路,时序逻辑能胜任大规模的逻辑电路
2)组合逻辑实现
- 方式一:always@(电平敏感列表)
- 在always 模块种可以使用if、case等语句
- 一般建议使用阻塞赋值语句**“=”**
- always 模块中的信号必须定义为reg型,仅仅是语法要求,实际实现仍然是wire类型
- 方式二:assign描述的赋值语句
- 信号只能被定义为wire型
3)时序逻辑实现
实现方式:always@(posedge clk) begin … end
- 时序逻辑always 块中定义的reg型信号都被综合成寄存器
- 时序逻辑中一般建议使用非阻塞赋值 “<=”
- 敏感列表中只要有时钟沿的变化即可,即每次触发输出变化都是时钟沿引入的
4)实现异或门
z=a^b

组合逻辑实现:
`timescale 1ns/1ps
module vlg_design1(
input a,b,
output z
);
/*
always @(a or b)begin
z = a ^ b;
end
*/
assign z = a^b;
endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
时序逻辑实现:
`timescale 1ns/1ps
module vlg_design2(
input clk,
input rst_n,
input a,b,
output reg z
);
always @(posedge clk)
if(!rst_n) z <= 1'b0;
else z <= a ^ b;
endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
testbench:
`timescale 1ns/1ps module testbench_top(); //参数定义 `define CLK_PERIORD 10 //ʱ����������Ϊ10ns��100MHz�� //接口声明 reg clk; reg rst_n; reg a,b; wire z1,z2; //对被测试的设计进行例化 vlg_design1 uut_vlg_design1( .a(a), .b(b), .z(z1) ); vlg_design2 uut_vlg_design2( .clk(clk), .rst_n(rst_n), .a(a), .b(b), .z(z2) ); //复位和时钟的产生 //时钟和复位初始化、复位产生 initial begin clk <= 0; rst_n <= 0; #1000; rst_n <= 1; end //时钟产生 always #(`CLK_PERIORD/2) clk = ~clk; //测试激励产生 initial begin a <= 0; b <= 0; @(posedge rst_n); //等待复位完成 repeat(10) begin @(posedge clk); end //a 和 b 同步变化 @(posedge clk); #2; a <= 1; b <= 0; @(posedge clk); #2; a <= 0; b <= 1; @(posedge clk); #2; a <= 0; b <= 0; //a 和 b 变化有延迟 @(posedge clk); //在实际的逻辑电路中a先变化,然后b变化,变化中有延迟 #2; a <= 1; #1; b <= 0; @(posedge clk); #2; a <= 0; #1; b <= 1; @(posedge clk); #2; a <= 0; #1; b <= 0; repeat(10) begin @(posedge clk); end $stop; end endmodule

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104

通过仿真可以看到在Z1里出现了毛刺,说明组合逻辑相对而言不是很稳定,如果要实现大规模的逻辑电路还是时序逻辑更加的合适。
2、分频计数器设计
-
分频时钟的工程应用
- 对FPGA系统时钟(频率较高)进行分频,产生分频时钟(频率较低)
- 分频时钟可以作为FPGA低速外设的同步时钟
- IIC总线(集成电路总线)的时钟( <= 400khz)
- 低速SPI(串行外设接口总线)总线的时钟(<= 1MHZ)
-
分频计数器的功能需求
- 输入时钟100MHZ,产生一个1MHZ的低频时钟
- 100MHZ / 1MHZ = 100
- 即需要对100MHZ时钟做100分频
- 计数器循环计数周期是 0 ~ 99
- 输入时钟100MHZ,产生一个1MHZ的低频时钟
-
分频计数器的代码设计
-
编写测试脚本,搭建测试平台
-
运行仿真,查看波形
设计文件:
`timescale 1ns/1ps module vlg_design( input clk, input rst_n, output reg clk_1mhz ); localparam CNT_MAX = 8'd100; localparam CNT_MAX_2 = 8'd50; /* 1/100m 1/1m */ reg[7:0] cnt; always @(posedge clk) if(!rst_n) cnt <= 8'd0; else if (cnt < (CNT_MAX-1)) cnt <= cnt +1'b1; else cnt <= 8'd0; always @(posedge clk) if(!rst_n) clk_1mhz <= 1'b0; else if (cnt < (CNT_MAX_2 - 1)) clk_1mhz<= 1'b1; else clk_1mhz <= 1'b0; endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
testbench:
`timescale 1ns/1ps module testbench_top(); `define CLK_PERIORD 10 reg clk; reg rst_n; wire clk_1mhz; vlg_design uut_vlg_design( .clk(clk), .rst_n(rst_n), .clk_1mhz(clk_1mhz) ); initial begin clk <= 0; rst_n <= 0; #1000; rst_n <= 1; end always #(`CLK_PERIORD/2) clk = ~clk; initial begin @(posedge rst_n); @(posedge clk); repeat(10) begin @(posedge clk); end #10_000; $stop; end endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
波形:

实现原理:
一开始一直没理解好这块的如何实现的分频,这里的分频时钟和流水线中的分频时钟不太一样所以造成了一些误导:
首先分频时钟的使用目的就是为了把高频的时钟转换成一个或者若干个低频的时钟。
实现:
时钟其实就是一段波动的电信号,时钟高电平也就是电信号高电平,这两个之间是没有什么区别的。那么就可以通过周期计算来实现这一过程:
100MHZ 的周期是 1/100M
1MHZ的周期是 1/1M
将100MHZ的时钟转换为1MHZ的时钟就是说,需要100个周期才能组成一个1个周期,对于一个1MHZ周期的时钟来说一般是高电平,一半是低电平。
所以在实现的时候就是通过cnt进行计数,如果cnt<100 就继续+1,如果=100 就归0。在cnt<50的时候将clk_1mhz 的信号置为高电位,大于等于20的时候就置为低电位,通过计数器来计数,然后再根据计的数设置电信号高低电平,进而就实现了分频计数器。
练习题:
需求:
对一个25MHZ的时钟,分频产生一个400KHZ的时钟
=25000KHZ -> 1/25000K T
=400KHZ -> 1/400K T
62.5 63 0~62
6 5:0
设计代码:
3、使能时钟设计
1)门控时钟
- 门控时钟就是通过一个使能信号控制时钟的开关

- 能否成功的输出时钟信号取决于使能信号,而对应的clk_in时钟输入信号是一个持续的方波
- 包含一个门电路,容易因为竞争产生不希望的毛刺
2)使能时钟
- 使能时钟的时钟信号会一直保持开启状态,每个时钟周期都能判断使能信号以确定是否进行逻辑处理
- 使能时钟不能像门控时钟一样降低系统功耗,因为时钟信号一直的都是开启的
- 使能时钟使用同步设计思想,更便于设计的实现与验证

使能时钟是通过使能信号和时钟周期来判断是否进行逻辑处理
门控时钟是根据使能信号来判断是否输出时钟
门控时钟可以控制时钟信号的输出所以一定程度上能减少资源的浪费,但是因为门控的特点容易产生毛刺,这是我们所不希望的。
3)用使能时钟代替分频时钟
- 在FPGA内部时钟使用逻辑计数分频产生的时钟,一般不推荐直接用于FPGA内部逻辑的时钟
- 如果不想使用PLL资源,可以考虑使用使能时钟的方式产生分频时钟
- 分频时钟改用使能时钟的好处
- 避免时钟满天飞(不稳定)
- 保持一个时钟,减少跨时钟域
- 时序设计可以使用“多周期约束”

4)设计
#1、功能需求
输入时钟100MHZ,产生一个5MHZ的时钟使能信号,并使能此时钟使能信号进行0~15的周期计数
- 100MHZ / 5MHZ = 20
- 对100MHZ时钟做20分频的计数(0~19)
- 每20个100MHZ的时钟周期,都要保持1个时钟周期的高脉冲信号产生
#2、代码
设计文件:
`timescale 1ns/1ps module vlg_design( input clk, //100mhz input rst_n, output reg[3:0] syscnt //使能信号计数参数 ); localparam CNT_MAX = 5'd20; //时钟信号计数最大值 localparam CNT_MAX_EN = 4'd15 ; //使能时钟计数最大值 reg clk_en; reg[4:0] clk_cnt; // //对输入时钟clk 100MHZ 做20分频计数 always @(posedge clk) if(!rst_n) clk_cnt<=5'b0; else if(clk_cnt < (CNT_MAX-1)) clk_cnt <= clk_cnt + 1'b1; else clk_cnt <='b0; //这种写法就是不管是多少位都清零 // //产生时钟使能信号,这个时钟使能信号每隔20个周期有一个高脉冲 always @(posedge clk) if (!rst_n) clk_en <= 1'b0; else if(clk_cnt == (CNT_MAX -1) ) clk_en <= 1'b1; else clk_en <= 1'b0; // //使用时钟使能信号进行计数 always @(posedge clk) if(!rst_n) syscnt <= 1'b0; else if(clk_en) syscnt <= syscnt+1'b1; else syscnt <= syscnt; //计数,如果使能信号高电平就+1,如果没有就寄存 endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
testbench:
`timescale 1ns/1ps module testbench_top(); //参数定义 `define CLK_PERIORD 10 //接口声明 reg clk; reg rst_n; wire[3:0] syscnt; //对被测试的设计进行例化 vlg_design uut_vlg_design( .clk(clk), .rst_n(rst_n), .syscnt(syscnt) ); //复位和时钟的产生 //时钟和复位初始化、复位产生 initial begin clk <= 0; rst_n <= 0; #1000; rst_n <= 1; end //时钟产生 always #(`CLK_PERIORD/2) clk = ~clk; //测试激励产生 initial begin @(posedge rst_n); //等待复位完成 @(posedge clk); repeat(20*16*2) begin @(posedge clk); end $stop; end endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
波形:

5)练习
对于一个25MHZ的时钟,分频产生一个5MHZ的时钟使能信号
循环计数 5
设计文件:
`timescale 1ns/1ps module vlg_design( input clk, //25MHZ input rst_n, output reg clk_en ); localparam cnt_mux = 5; reg[2:0] cnt; // //对时钟信号进行5 分频 always@(posedge clk) if(!rst_n) cnt <= 3'b0; else if(cnt < (cnt_mux - 1)) cnt <= cnt + 1'b1; else cnt <= 1'b0; // //生成使能信号 always@(posedge clk) if (!rst_n) begin clk_en <= 1'b0; end else if(cnt == (cnt_mux -1)) clk_en <= 1'b1; else clk_en <= 1'b0; endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
testbench:
`timescale 1ns/1ps module testbench_top(); //参数定义 `define CLK_PERIORD 2.5 //接口声明 reg clk; reg rst_n; wire clk_en; //对被测试的设计进行例化 vlg_design uut_vlg_design( .clk(clk), .rst_n(rst_n), .clk_en(clk_en) ); //复位和时钟的产生 //时钟和复位初始化、复位产生 initial begin clk <= 0; rst_n <= 0; #1000; rst_n <= 1; end //时钟产生 always #(`CLK_PERIORD/2) clk = ~clk; //测试激励产生 initial begin @(posedge rst_n); //等待复位完成 @(posedge clk); repeat(20*16*2) begin @(posedge clk); end $stop; end endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
testbench 还是不会写,比如说上面这个内容,repeat 中应该如何去计算输出几个周期,生成clk又应该如何去生成
4、基于Xilinx BUFGCE原语的门控时钟设计
1)传统门控时钟设计
基于组合逻辑中的与门,与门的两个输入端分别是使能信号和时钟信号,输出信号为时钟信号

时钟的有无决定于使能信号,在组合逻辑中用的很多
在功能模块不适用的时候,可以通过设置及使能信号调整关闭时钟,这是门控时钟的好处。但是不符合同步设计的思想,可能回影响到系统的设计,这是不推荐的设计,但是有些场合又需要在某个时间把时钟关闭掉,在一定程度上去降低功耗。
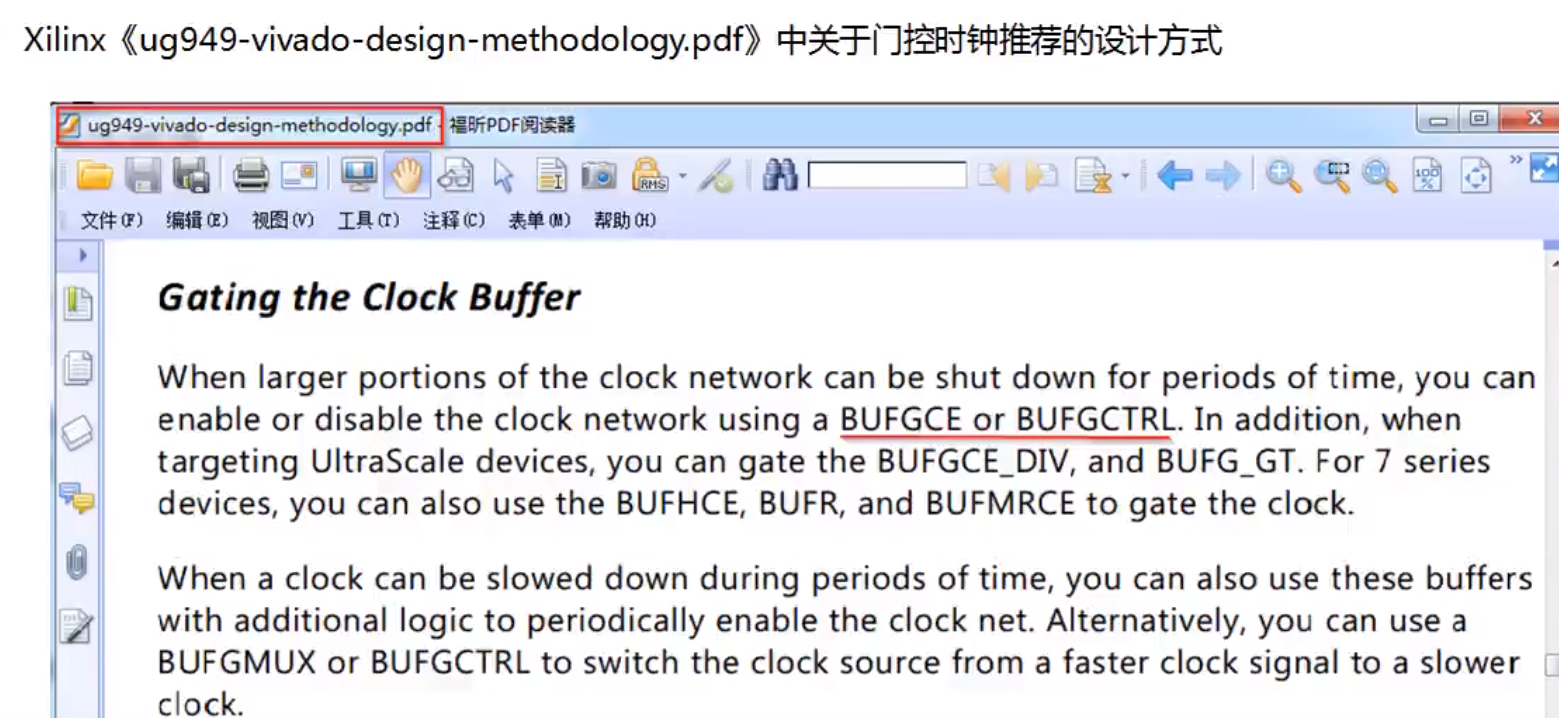
BUFGCE 和 BUFGCTRL 这两个设计原语是缓冲器,可以布局到FPGA内部的时钟的网络当中。也就是说,BUFGECE 和 BUFGCTRL 是经过特殊布局的,使用传统的门控电路设计可能会出现实现验证上的一些问题,但是使用原语设计可能不会出现相应的问题。

2)设计
#1、功能需求
- FPGA 系统时钟100MHZ
- 系统每秒进行一次数据的采集与处理,每次维持10ms ,其余时间空闲
- 希望系统空闲时,关闭100MHZ的工作时钟
- 使用BUFGCE 原语实现此功能
#2、代码
设计文件:
`timescale 1ns/1ps module vlg_design( input clk, //100MHZ input rst_n , output outclk ); `define SIMULATION `ifdef SIMULATION localparam TIMER_CNT_1S = 30'd1_000; //1s 计数的最大值 localparam TIMER_CNT_10MS = 30'd10; //10MS计数的最大值 `else localparam TIMER_CNT_1S = 30'd100_000_000; //1s 计数的最大值 localparam TIMER_CNT_10MS = 30'd1_000_000; //10MS计数的最大值 `endif /// //1s 周期计数器 reg[29:0] cnt; always @(posedge clk) if(!rst_n) cnt <= 'b0; else if(cnt < (TIMER_CNT_1S -1'b1)) cnt <= cnt +1'b1; else cnt <= 'b0; // //10ms 使能信号产生 reg en_10ms; always @(posedge clk) if(!rst_n) en_10ms <= 'b0; else if(cnt <= (TIMER_CNT_10MS - 1'b1)) en_10ms <= 'b1; else en_10ms <= 'b0; /// //例化BUFGCE 原语 /// BUFGCE BUFGCE_inst ( .O(outclk), // 1-bit output: Clock output .CE(en_10ms),// 1-bit input: Clock enable input for I0 .I(clk) // 1-bit input: Primary clock ); endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
测试文件:
`timescale 1ns/1ps module testbench_top(); //参数定义 `define CLK_PERIORD 10 //接口声明 reg clk; reg rst_n; wire outclk; //对被测试的设计进行例化 vlg_design uut_vlg_design( .clk(clk), .rst_n(rst_n), .outclk(outclk) ); //复位和时钟的产生 //时钟和复位初始化、复位产生 initial begin clk <= 0; rst_n <= 0; #1000; rst_n <= 1; end //时钟产生 always #(`CLK_PERIORD/2) clk = ~clk; //测试激励产生 initial begin @(posedge rst_n); //等待复位完成 @(posedge clk); #3_000_000 /* repeat(10) begin @(posedge clk); end */ $stop; end endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
波形:

5、理解FPGA设计的并行性
1)FPGA技术的三大优势
- 灵活性
- 可重编程,可定制,想读与ASIC而言
- 易于维护,方便移植、升级或扩展
- 降低NRE成本,加速产品上市的 时间
- 支持丰富的外设接口,可根据需求配置
- 并行性
- 更快的速度、更高的带宽,满足实时处理的要求
- 集成性
- 更多的接口和协议的支持
- 可将各种端接匹配元件整合到器件内部
- 降低BOM成本
- 单片解决方案,可以替代很多数字芯片、
- 减少扳级走线,有效降低布局布线的难度
2)verilog 中的并行设计
- 不同的always 语句的执行都是可以相互独立且并行工作的
- 同一个always 语句内部的不同逻辑处理都具有并行性
- 满足时序逻辑设计
- 使用非阻塞语句(<=)
3)实例一、
两个always 语句分别实现四位的加法器, 看这两个四位的加法器计数值是不是同步的变化 ,看看工具是否综合出两套完全相同的四位加法器出来,还是说是综合出了一套出来,而且分时赋用(如果这样就和软件一样了)
最终应该是有两套完全一样的四位加法器,完全并行的工作
代码规范:如果是输入就是加上i_前缀,如果是输出就加上o _前缀
vivado 使用技巧:
可以选中设计文件然后把指定文件设置未顶层文件
可以选中Schematic 将设计文件编译出一个原理图出来

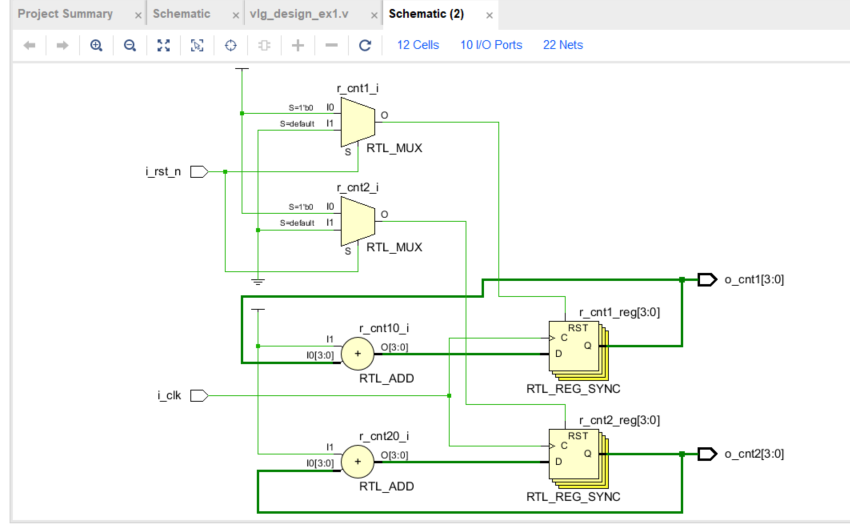
设计文件:
`timescale 1ns/1ps module vlg_design( input i_clk, input i_rst_n, output[3:0] o_cnt1,o_cnt2 ); reg[3:0] r_cnt1,r_cnt2; always @(posedge i_clk) if(!i_rst_n) r_cnt1 <= 'b0; else r_cnt1 <= r_cnt1 + 1'b1; always @(posedge i_clk) if(!i_rst_n) r_cnt2 <= 'b0; else r_cnt2 <= r_cnt2 + 1'b1; /* 如果是软件的思想: 那么在计数的时候应该是r_cnt1 先执行完计数,然后 r_cnt2 再执行计数 如果是硬件的思想: 两者是同时计数的,从这个角度去理解计数的方式 */ assign o_cnt1 = r_cnt1; assign o_cnt2 = r_cnt2; endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
原理图:

从原理图中可以看出,verilog在设计的时候是实现了两个完全一样的加法器,因此从电路上验证了是两组独立电路的实现
波形:

波形也是并行执行的。
4)实例二、
- 不同always 语句的执行都是可以相互独立且并行工作的
- 同一个always 语句内的不同逻辑处理都是并行性
- 时序逻辑设计
- 使用非阻塞赋值语句(<= )
分别将同一个递增变化的输入值赋值给同一个always 语句中的两个不同寄存器,看这两个寄存器的值是否同步递增
设计文件:
`timescale 1ns/1ps module vlg_design( input i_clk, input i_rst_n, input[3:0] i_cnt, output[3:0] o_cnt1,o_cnt2 ); reg[3:0] r_cnt1,r_cnt2; always @(posedge i_clk) if(!i_rst_n) begin r_cnt1 <= 'b0; r_cnt2 <= 'b0; end else begin r_cnt1 <= i_cnt; r_cnt2 <= i_cnt; end assign o_cnt1 = r_cnt1; assign o_cnt2 = r_cnt2; endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
原理图:

在编译生成原理图时,编译器识别到我们做的是同样的操作,为减少布线,就直接只编译出了一个寄存器,在结果最后进行了赋值,实现资源利用率最大会

从波形图上也可以看出是同步变化的,没有时间差
5)小结
不同的always 语句可以实现不同的电路同时执行,同一always 语句内部也可以实现不同的电路同时执行,只要使用非阻塞赋值语句,且符合代码规范那么设计出来的电路一定是并行执行
FPGA 会对电路进行优化,根据意图复用执行。
6、同步复位与异步复位
1)复位写法
//同步复位
always @(posedge clk) begin
if(!rst_n) ...
else ....
end
//异步复位
always @(posedge clk or negedge rst_n) begin
if(!rst_n) ....
else .....
end
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
xilinx 比较推荐使用同步复位的方式,因为在Xilinx 的FPGA 架构中有更多的资源。异步复位存在很多问题,可能会带来更多时序设计上的复杂性,造成时序无法收敛,如果一定要用就一定对异步复位信号进行同步处理,然后再让异步复位信号供给每个逻辑。
何时何地需要复位:
在Xilinx FPGA 中内置了global set/reset signal(GSR),会在FPGA设计完成之后对初上电元件进行初始化的赋值。
如果不设置复位电路,其实在FPGA电路中已经设置好了复位。
但是有的时候还是需要一些软复位,对元件的复位有可控性,这样一般就会专门去设计复位电路。
一般控制信号需要专门的复位赋值,而数据信号一般不太需要复位赋值。因为数据信号一般有效与否由控制信号来决定,在上电初始的时候,控制信号一定是需要复位的,保证不能随便的跳变,在每一个时刻都必须得有值。而数据信号取决于使能或者有效信号,所以数据信号有时候不需要一定给他赋一个初值。
如果在FPGA电路当中,如果能有效的减少不必要的复位信号,就可以减少复位信号的散出,以削减复位所需要的部位布线,进而简化复位所需要的时序,可以优化系统的性能和功耗
2)异步复位的同步处理
- 异步复位信号,一般不建议作为FPGA逻辑的全局异步复位信号使用
- 异步复位的“异步”很可能导致各个逻辑的复位“异步”,引发设计问题
- 异步复位可能占用更多的FPGA 布局布线资源,难以满足时序性能要求
- 若设计中一定要做异步复位,那么推荐对“异步”的复位信号,先做“同步处理”,再做异步复位信号使用
未进行过同步复位处理
设计文件:
`timescale 1ns/1ps module vlg_design( input i_clk, input i_rst_n, input[3:0] i_data, output reg[3:0] o_sync_data, output reg[3:0] o_asyn_data ); always @(posedge i_clk) if(!i_rst_n) o_sync_data <= 4'd0; else o_sync_data <= i_data; always @(posedge i_clk or negedge i_rst_n) if(!i_rst_n) o_asyn_data <= 4'd0; else o_asyn_data <= i_data; endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
testbench:
`timescale 1ns/1ps module testbench_top(); `define CLK_PERIORD 10 reg clk; reg rst_n; reg[3:0] i_data; wire[3:0] o_sync_data; wire[3:0] o_asyn_data; vlg_design uut_vlg_design( .i_clk(clk), .i_rst_n(rst_n), .i_data(i_data), .o_sync_data(o_sync_data), .o_asyn_data(o_asyn_data) ); initial begin clk <= 0; rst_n <= 0; #1000; rst_n <= 1; repeat(10) begin @(posedge clk); end //出复位 #4; rst_n <= 0; repeat(10) begin @(posedge clk); end //进入复位 rst_n <= 1; //出复位 end always #(`CLK_PERIORD/2) clk = ~clk; initial begin i_data <= 4'b1111; @(posedge rst_n); @(posedge clk); repeat(300000) begin @(posedge clk); end $stop; end endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
波形图:

从波形图上可以看出,异步复位在复位发生的时候立马发生复位,同步复位则是在复位发生之后的第一个上升沿才发生复位的动作。
在实际的应用当中,我们并不需要在一个时钟周期内立即复位,甚至延缓三到四个时钟周期都不会对我们本身的设计有影响,所以如果因为要立即复位而选择异步复位,浪费更多的FPGA资源,在本质上讲是得不偿失的。因此还是更推荐使用同步复位。
进行同步复位处理
设计文件修改为:
`timescale 1ns/1ps module vlg_design( input i_clk, input i_rst_n, input[3:0] i_data, output reg[3:0] o_sync_data, output reg[3:0] o_asyn_data, output reg[3:0] o_asyn_data2 ); always @(posedge i_clk) if(!i_rst_n) o_sync_data <= 4'd0; else o_sync_data <= i_data; always @(posedge i_clk or negedge i_rst_n) if(!i_rst_n) o_asyn_data <= 4'd0; else o_asyn_data <= i_data; //对复位信号进行同步处理,产生新的异步复位信号 reg r_rst_n; always @(posedge i_clk) r_rst_n <= i_rst_n; always @(posedge i_clk or negedge r_rst_n) if(!r_rst_n) o_asyn_data2 <= 4'd0; else o_asyn_data2 <= i_data; endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
波形图:

从图上观察可以发现,新添加的r_rst_n 信号是通过再延缓一拍之后新生成的信号,在复位的时候,虽然是异步复位,但是在波形显示上,与实际同步复位的时间点是一致的。
退出复位会相对于同步复位延迟一个时钟周期。这就是对异步复位信号进行同步处理,然后使用的一个方式。也就是相对没有处理过的异步信号延缓了一个周期,让其的行为与同步复位信号基本一致。
7、脉冲边沿检测设计
1)脉冲边沿检测原理
在时钟输入之外还有脉冲信号的输入,脉冲信号可以是同步的也可以是异步的,但是信号频率要小于时钟信号的频率,至少时钟信号的频率是脉冲频率的两倍以上。
脉冲边沿检测:
- 对输入脉冲信号进行两级寄存器的锁存
- 对两级寄存器进行逻辑运算,在其边沿脉冲电平变化时获取保持一个时钟周期的高电平

每次时钟的上升沿,寄存器1锁存脉冲信号的变化,寄存器2锁存寄存器1信号的变化,最后将寄存器1和寄存器2取反的信号相与就会活得一个稳定的一个时钟周期的高脉冲。这样就可以通过使用这个高脉冲来作为示意信号,当前这个脉冲有一个上升沿来到。下降沿也是类似的方式:高一级的寄存器取反和低一级的寄存器想与,得到下降沿的高脉冲检测 信号,
2)脉冲边沿检测的适用场景
- 无论是同步信号还是异步信号都可以使用这种方式去检验边沿的信号,尤其使用脉冲边沿检测法对异步信号进行同步,是非常简单使用的控制检测方式
- 对于异步信号的脉冲检测,采样时钟频率要高于检测信号的变化率(至少两倍于被检测信号的变化率),即检测信号的低电平或高电平都应该至少保持若干个时钟周期
- 应用:
- CPU外扩异步存储接口的控制信号检测

- CSN代表片选信号 ,CSN 拉低一次代表对外读或者写
- 相对于片选信号会有选通信号(RDn/WRn),会比片选信号要晚一些
- 数学有效(DB) 会介于片选信号和读写选通之间被拉为有效
- 控制或者命令信号的变化检测,中断信号的跳变检测
- 脉冲计数(异步脉冲的计数)
- 频率计数
- CPU外扩异步存储接口的控制信号检测
小结:
脉冲信号的特点:
边沿检测
3)设计
设计文件:
`timescale 1ns/1ps module vlg_design( input i_clk, input i_rst_n, input i_pulse, //脉冲信号 output[1:0] o_rise_edge //输出脉冲信号的边沿信号 ); reg[1:0] r_pulse; wire r_pulse1_invert; wire r_pulse2_invert; always @(posedge i_clk) if(!i_rst_n) r_pulse <= 2'b00; else r_pulse <= {r_pulse[0],i_pulse}; //并行性 //r_pulse[0] <= i_pulse //r_pulse[1] <= r_pulse[0] assign r_pulse1_invert = ~r_pulse[1]; assign r_pulse2_invert = ~r_pulse[0]; assign o_rise_edge ={ r_pulse[0] & r_pulse1_invert,r_pulse[1] & r_pulse2_invert}; endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
testbench:
`timescale 1ns/1ps module testbench_top(); `define CLK_PERIORD 10 reg clk; reg rst_n; reg i_pulse; //脉冲信号 wire o_rise_edge; //输出脉冲信号的边沿信号 vlg_design uut_vlg_design( .i_clk(clk), .i_rst_n(rst_n), .i_pulse(i_pulse), .o_rise_edge(o_rise_edge) ); initial begin clk <= 0; rst_n <= 0; #1000; rst_n <= 1; end always #(`CLK_PERIORD/2) clk = ~clk; initial begin i_pulse <= 1'b0; @(posedge rst_n); //等待复位完成 @(posedge clk); //等一个时钟周期 repeat(10) begin @(posedge clk); end #4; i_pulse <= 1'b1; repeat(10) begin @(posedge clk); end #4; i_pulse <= 1'b0; repeat(10) begin @(posedge clk); end $stop; end endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
波形图:

通过两次锁存,实现了脉冲边沿检测,上升沿的时候会有一次信号的产生,下降沿也会有一次检测脉冲信号的产生
小结:
其实就是一个边沿检测的思想,第一个锁存器锁存脉冲信号的上升沿,第二个锁存器锁存第一个信号,两个锁存器之间正好都差一个时钟周期,一个周期 一个取反与另一个相与,既能产生脉冲信号
4)双边沿检测
设计文件:
`timescale 1ns/1ps module vlg_design( input i_clk, input i_rst_n, input i_pulse, //脉冲信号 output o_rise_edge //输出脉冲信号的边沿信号 ); reg[1:0] r_pulse; wire r_pulse1_invert; always @(posedge i_clk) if(!i_rst_n) r_pulse <= 2'b00; else r_pulse <= {r_pulse[0],i_pulse}; //并行性 //r_pulse[0] <= i_pulse //r_pulse[1] <= r_pulse[0] assign r_pulse1_invert = ~r_pulse[1]; assign r_pulse2_invert = ~r_pulse[0]; assign o_rise_edge =(r_pulse[0] & r_pulse1_invert) | (r_pulse[1] & r_pulse2_invert); endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
波形图:

8、脉冲计数器
1)功能定义
输入脉冲:1路
使能信号:高电平时对脉冲进行计数,低电平则清零计数器
计数器:使能信号高电平期间,对脉冲信号的上升沿进行检测并递增计数值
2)设计
`timescale 1ns/1ps module vlg_design( input i_clk, input i_rst_n, input i_pulse, input i_en, output reg [15:0] o_pulse_cnt ); wire w_rise_edge; reg[1:0] r_pulse; / //脉冲边沿检测逻辑 always @(posedge i_clk) if(!i_rst_n) begin r_pulse <= 2'b00; o_pulse_cnt <= 'b0; end else r_pulse <= {r_pulse[0],i_pulse}; assign w_rise_edge = r_pulse & ~r_pulse[1]; / //脉冲计数逻辑 always @(posedge i_clk) if(i_en) begin if(w_rise_edge) o_pulse_cnt <= o_pulse_cnt + 1'b1; else o_pulse_cnt <= o_pulse_cnt; //锁存 end else o_pulse_cnt <= 'b0; endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
testbench:
`timescale 1ns/1ps module testbench_top(); `define CLK_PERIORD 10 reg clk; reg rst_n; reg i_pulse; reg i_en; wire [7:0] o_pulse_cnt; vlg_design uut_vlg_design( .i_clk(clk), .i_rst_n(rst_n), .i_pulse(i_pulse), .i_en(i_en), .o_pulse_cnt(o_pulse_cnt) ); initial begin clk <= 0; rst_n <= 0; #1000; rst_n <= 1; end always #(`CLK_PERIORD/2) clk = ~clk; integer i; initial begin i_pulse <= 1'b0; i_en <= 'b0; @(posedge rst_n); //等待复位完成 @(posedge clk); //等一个时钟周期 repeat(10) begin @(posedge clk); end #4; i_pulse <= 1'b1; i_en <= 1'b1; // 脉冲生成 for(i = 0 ; i < 50 ; i = i + 1) begin //每个begin end 内部是顺序执行的 #500; i_pulse <= 1'b1; #300; i_pulse <= 1'b0; end i_en <= 1'b0; //这里是顺序执行的,执行完for 才执行的这一 #10_000; i_en <= 1'b1; for(i = 0 ; i < 69 ; i = i + 1) begin //每个begin end 内部是顺序执行的 #500; i_pulse <= 1'b1; #300; i_pulse <= 1'b0; end i_en <= 1'b0; #10_000; i_en <= 1'b0; for(i = 0 ; i < 50 ; i = i + 1) begin //每个begin end 内部是顺序执行的 #500; i_pulse <= 1'b1; #300; i_pulse <= 1'b0; end i_en <= 1'b0; #10_000; $stop; end endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86

小结:
脉冲计数器的其实原理并不难,只不过是利用之前的脉冲边沿检测的设计,来计数而已,比较又意思的是在testbench 中不可综合代码的编写。
一是:for 循环后面的语句需要等for 循环执行完之后再执行,这里就成了顺序结构,比较有意思,是不是不在always 之外的都是组合逻辑,所以就是顺序结构呢?
二是:写这个testbench 如何能测试出自己预想的内容?编写testbench 本身就会在时间上把握好,比如说设置成高电平之后,延迟一段时间,就是代表要将高电平保持多长时间
integer i = 0; for(i = 0 ; i < 50 ; i = i + 1) begin //每个begin end 内部是顺序执行的 #500; i_pulse <= 1'b1; #300; i_pulse <= 1'b0; end
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
三是 上述代码是来设计有规律的脉冲信号的输出,如果一开始不给i 赋初值,观察到波形开始的一段是X不定值,所以我觉得最好还是在定义的时候就对这种数字变量初始化,其次在verilog 整形是用integer 来定义的,不允许在for 循环内定义。
其次就是 i = i+1;写惯JAVA这个地方还是得注意。

