
- 1「SQL面试题库」 No_1 员工薪水中位数_sql求员工薪水中位数
- 2关于 QSound播放wav音频文件,播放失败“using null output device, none available” 的解决方法_qsound::play using null output device, none availa
- 3渗透测试工具Kali Linux安装与使用
- 4mysql分组统计占比/百分比_mysql 查询占比
- 5Git清除指定文件cached_git cache
- 6全国职业院校技能大赛 GZ037工业互联网集成应用赛项 赛题9_广西职业院校技能大赛 工业互联网集成应用
- 7什么是MySQL的预编译?_mysql预编译
- 8docker安装Homeassist
- 92019年上半年软考信息安全工程师上午真题及答案解析_我国sm3算法被采纳为新一代宽带无线移动通信系统 (lte) 国际标准
- 10用AI給人生開掛的正確方式: AI比人进化快的时代,學什麼才不落伍?
【自然语言处理】【多模态】ViT-BERT:在非图像文本对数据上预训练统一基础模型_bert-vit
赞
踩
论文地址:https://arxiv.org/pdf/2112.07074.pdf
相关博客:
【自然语言处理】【多模态】多模态综述:视觉语言预训练模型
【自然语言处理】【多模态】CLIP:从自然语言监督中学习可迁移视觉模型
【自然语言处理】【多模态】ViT-BERT:在非图像文本对数据上预训练统一基础模型
【自然语言处理】【多模态】BLIP:面向统一视觉语言理解和生成的自举语言图像预训练
【自然语言处理】【多模态】FLAVA:一个基础语言和视觉对齐模型
【自然语言处理】【多模态】SIMVLM:基于弱监督的简单视觉语言模型预训练
【自然语言处理】【多模态】UniT:基于统一Transformer的多模态多任务学习
【自然语言处理】【多模态】Product1M:基于跨模态预训练的弱监督实例级产品检索
【自然语言处理】【多模态】ALBEF:基于动量蒸馏的视觉语言表示学习
【自然语言处理】【多模态】VinVL:回顾视觉语言模型中的视觉表示
【自然语言处理】【多模态】OFA:通过简单的sequence-to-sequence学习框架统一架构、任务和模态
【自然语言处理】【多模态】Zero&R2D2:大规模中文跨模态基准和视觉语言框架
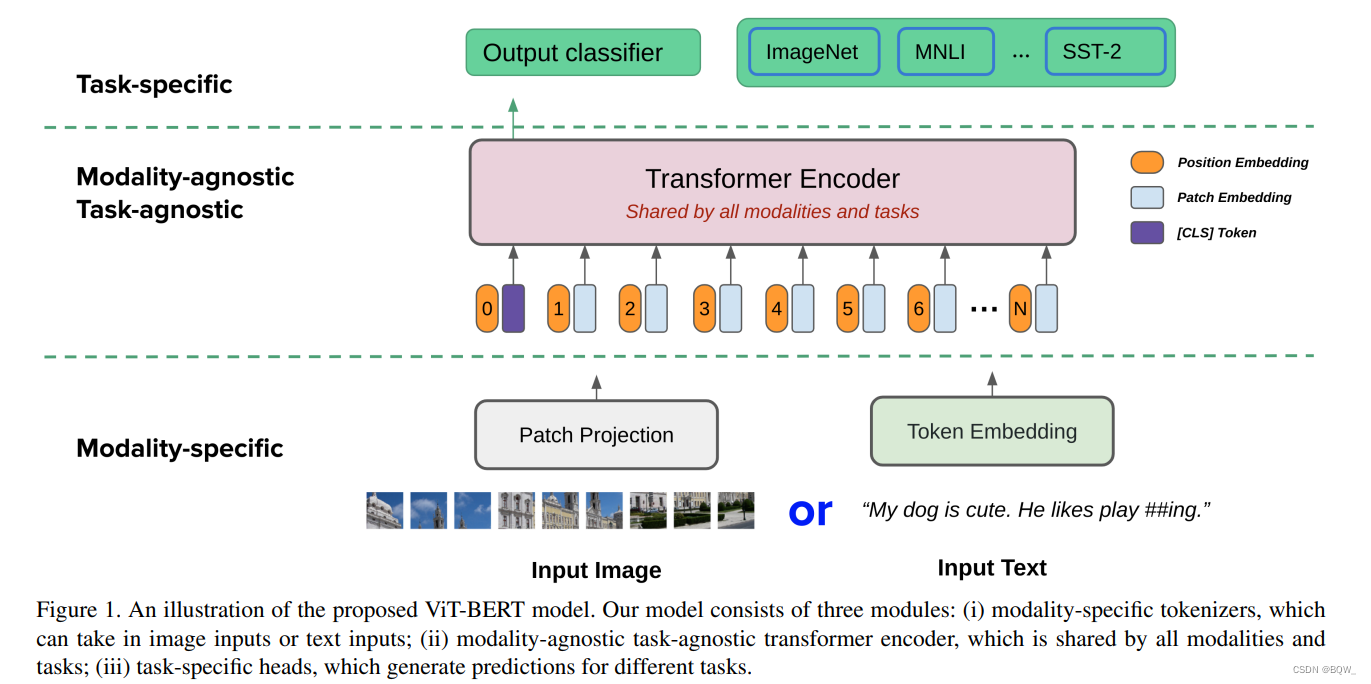
一、简介
本文的目标是建立一个可以应用在独立视觉任务或者独立文本任务的统一基础模型。从
BERT
\text{BERT}
BERT和
ViT
\text{ViT}
ViT出发,作者设计了一个统一的
Transformer
\text{Transformer}
Transformer,其由模态相关的tokenizer、一个共享
Transformer
\text{Transformer}
Transformer编码器和任务相关的输出头。为了在非成对的图像和文本上预训练提出的模型,作者提出了两个新颖的技术:(i) 单独训练
BERT
\text{BERT}
BERT和
ViT
\text{ViT}
ViT作为教师模型,然后利用知识蒸馏来提供额外且准确的监督信号用于联合训练。(ii) 提出了一种新颖的梯度遮蔽策略,用于平衡图像和文本预训练损失函数的更新。作者在图像分类任务和自然语言理解任务上联合预训练的模型。实验结果显示,产生的统一模型在纯视觉任务和纯文本任务上都工作的非常好。提出的知识蒸馏和梯度遮蔽策略也能有效的提高性能。
二、相关工作
1. 基于 Transformer \text{Transformer} Transformer的基础模型
最早使用基于多头自注意力机制的
Transformer
\text{Transformer}
Transformer是在
NLP
\text{NLP}
NLP领域用于机器翻译任务。由于其灵活性和可伸缩性,
Transformer
\text{Transformer}
Transformer很快就被应用在大规模语言预训练中。
NLP
\text{NLP}
NLP领域的许多工作,例如BERT,RoBERTa,ALBERT,GPT和T5,已经证明基于
Transformer
\text{Transformer}
Transformer的模型在大规模语料上预训练能够学习到自然语言的通用表示,这个通用表示能够通过微调迁移至广泛的下游任务并大幅度提高效果。
最近,基于
Transformer
\text{Transformer}
Transformer的模型被引入至计算机视觉领域。Image Transformer,iGPT,ViT,DETR和Swin Transformer等模型被应用在各种视觉任务,并在图像分类、目标检测、全景分割上实现了强劲的表现。
基于
Transformer
\text{Transformer}
Transformer的模型也被广泛应用在视觉-语言联合推理任务中。VisualBERT,VL-BERT,ViLBERT,LXMERT和UNITER已经展示了在大规模图像-文本对上预训练的模型在各种多模态任务上都大幅度领先先前的模型,例如:视觉问答、图片说明和图像-文本检索。这些模型都需要一个目标检索主干网络来抽取图像中的区域特征,然后输入至
Transformer
\text{Transformer}
Transformer中。
这些基于
Transformer
\text{Transformer}
Transformer的模型有时也被称为基础模型foundation model,基础模型能够通过预训练和微调的过程进行学习。预训练通常是在大规模数据集上进行的,例如Wikipedia,JFT-300M或者Conceptual Captions,然后在下游任务上使用较小的数据集微调预训练的模型。
2. 多任务学习
多任务学习的目标是开发出能够处理多任务且共享参数和计算的模型。多任务学习是机器学习、自然语言理解、计算机视觉和多模态推理等领域中长期存在的研究问题。例如, Mask-RCNN \text{Mask-RCNN} Mask-RCNN能够使用一个网络同时处理目标检测、分割和姿态估计任务。 MT-DNN \text{MT-DNN} MT-DNN是一个多任务语言理解模型,其共享低层的 Transformer \text{Transformer} Transformer并在上层使用 任务相关的层。
先前的多任务学习研究主要专注在单个模态。为了能够同时处理跨视觉和语言的多任务,Kaiser et al.提出了一个异构模型,其由处理图像的卷积层和处理自然语言的注意力和专家混合层组成。Hu et al.提出的
UiT
\text{UiT}
UiT,其是在单个模型中处理多任务和多模态的统一
Transformer
\text{Transformer}
Transformer编码器-解码器架构。
UiT
\text{UiT}
UiT在不同任务上仅共享了解码器,每个模态的编码器则是独立的。特别地,他们采用预训练的
DeTR
\text{DeTR}
DeTR作为视觉编码器,采用预训练
BERT
\text{BERT}
BERT作为文本编码器。Akbari et al.提出的
VATT
\text{VATT}
VATT来在单个模型中处理视频、音频和文本,该模型通过多模态对比学习进行训练,并且期望对齐跨模态数据三元组。
本文的工作与先前的多任务学习主要有两个不同。第一,作者的目标是能够应用在不同模态和不同领域上各种任务的统一基础模型。因此,本文的多任务学习是在预训练阶段进行,而不是在任务相关的训练阶段。第二,作者设计了一个具有最小模态相关参数的
Transformer
\text{Transformer}
Transformer模型。具体来说,提出的
ViT-BERT
\text{ViT-BERT}
ViT-BERT具有单层patch投影,其比
UiT
\text{UiT}
UiT中使用的分离编码器要轻量的多。
三、方法
1. 统一 Transformer \text{Transformer} Transformer
1.1 模态相关的 Tokenizer \text{Tokenizer} Tokenizer
这里考虑两种模态:图像和文本。作者并没有使用image-text对进行预训练,所以下面的公式并不会考虑将图像和文本对作为输入。
单独的视觉任务需要将图像作为输入。受
ViT
\text{ViT}
ViT的启发,这里将图像
I
∈
R
H
×
W
×
C
I\in\mathbb{R}^{H\times W\times C}
I∈RH×W×C划分为patch序列
V
∈
R
N
×
(
P
2
×
C
)
V\in\mathbb{R}^{N\times(P^2\times C)}
V∈RN×(P2×C),其中
(
P
,
P
)
(P,P)
(P,P)是patch的分辨率,且
N
=
H
W
/
P
2
N=HW/P^2
N=HW/P2则是patch的数量。然后,所有的patch被拉平并使用线性投影
V
∈
R
(
P
2
×
C
)
×
D
V\in\mathbb{R}^{(P^2\times C)\times D}
V∈R(P2×C)×D进行嵌入,最终追加一个分类token
v
c
l
s
v_{cls}
vcls以及位置嵌入
V
p
o
s
∈
R
N
×
D
V^{pos}\in\mathbb{R}^{N\times D}
Vpos∈RN×D。正式来讲,一个图像会被处理成patch嵌入向量的序列
I
=
[
v
c
l
s
,
v
1
V
,
…
,
v
N
V
]
+
V
p
o
s
(1)
I=[v_{cls},v_1V,\dots,v_NV]+V^{pos} \tag{1}
I=[vcls,v1V,…,vNV]+Vpos(1)
单独文本任务,输入数据的处理同
BERT
\text{BERT}
BERT
S
=
[
t
c
l
s
,
t
1
T
,
…
,
t
M
T
]
+
T
p
o
s
+
T
s
e
q
(2)
S=[t_{cls},t_1T,\dots,t_MT]+T^{pos}+T^{seq} \tag{2}
S=[tcls,t1T,…,tMT]+Tpos+Tseq(2)
其中,
T
T
T是嵌入矩阵,
T
p
o
s
T^{pos}
Tpos是文本的位置嵌入,
T
s
e
q
T^{seq}
Tseq是分段嵌入。
这里不会为模态类型添加额外的嵌入向量,因为在实验中并没有带来改善。
1.2 共享 Transformer \text{Transformer} Transformer编码器
Transformer
\text{Transformer}
Transformer编码器是由包含自注意力机制
(MSA)
\text{(MSA)}
(MSA)和
MLP
\text{MLP}
MLP的模块堆叠而成。
MLP
\text{MLP}
MLP包含两个具有
GELU
\text{GELU}
GELU激活函数的全链接层。每个
MSA
\text{MSA}
MSA或者
MLP
\text{MLP}
MLP之前都会应用
Layer normalization(LN)
\text{Layer normalization(LN)}
Layer normalization(LN)
z
0
=
I or S
z
^
l
=
MSA(LN
(
z
l
−
1
)
)
+
z
l
−
1
,
l
=
1
,
…
,
L
z
l
=
MLP(LN
(
z
^
l
)
)
+
z
^
l
Transformer
\text{Transformer}
Transformer编码器最终输出是最后一层的嵌入向量
z
L
z^L
zL,其会被用于不同的任务头。
1.3 任务相关的头
对于每个任务,任务具体的预测头会应用在
Transformer
\text{Transformer}
Transformer编码器的最终输出上。本文中解决的任务包括预训练任务和下游任务,其可以被转换为分类任务。为了预测输出类别,这里应用具有
GeLU
\text{GeLU}
GeLU激活函数的两层
MLP
\text{MLP}
MLP分类器,维度就是
Transformer
\text{Transformer}
Transformer编码器的hidden size。
z
=
W
2
⋅
GeLU
(
W
1
⋅
z
0
L
+
b
1
)
+
b
2
p
=
Softmax
(
z
)
其中,
W
1
W_1
W1和
b
1
b_1
b1是第一层的权重和偏差,
W
2
W_2
W2和
b
2
b_2
b2是第二层的权重和偏差,
p
p
p是对于输出类别的预测概率分布。
z
0
L
z_0^L
z0L是
Transformer
\text{Transformer}
Transformer编码器最后一层的类别token。
2. 联合预训练
联合预训练属于多任务学习,其一直被认为是非常具有挑战性的优化问题,如梯度冲突和灾难性遗忘。同时执行多任务来训练神经网络需要小心的校准单个任务,确保任务相关的损失函数不会支配另一个。在本文的例子中问题更加的严重,因为预训练包含许多噪音且需要数百万个优化steps来收敛,特别是文本的预训练。
作者从两个方面解决上面的问题:(i) 使用知识蒸馏为联合训练提供额外的监督;(ii) 设计了一种梯度遮蔽 gradient masking \text{gradient masking} gradient masking策略来调节不同任务的潜在冲突梯度。
2.1 知识蒸馏
本小节会介绍如何使用知识蒸馏来改善文本和图像的联合预训练。假设可以访问原始的BERT和ViT模型,这两个模型分别在文本和图像模态上进行预训练,其会成为统一模型的两个教师模型。这里的核心问题是如何使用两个教师进行训练。
知识蒸馏是通过最小化教师模型和学习模型概率分布的KL散度。令
z
t
z_t
zt表示教师模型预测的logits,
z
s
z_s
zs则是学生模型预测的logits,且
y
y
y是真实的标签。蒸馏目标函数是
L
=
(
1
−
α
)
L
C
E
(
ψ
(
z
s
)
,
y
)
+
α
KL
(
ψ
(
z
s
τ
)
,
ψ
(
z
t
τ
)
)
(7)
\mathcal{L}=(1-\alpha)\mathcal{L}_{CE}(\psi(z_s),y)+\alpha\text{KL}(\psi(\frac{z_s}{\tau}),\psi(\frac{z_t}{\tau})) \tag{7}
L=(1−α)LCE(ψ(zs),y)+αKL(ψ(τzs),ψ(τzt))(7)
其中,
ψ
\psi
ψ表示softmax函数,
α
\alpha
α平衡两个损失函数的超参,
τ
\tau
τ是蒸馏使用的temperature超参数。
因为需要同时在文本和图像上训练学生模型,每个训练batch中都包含图像和文本。从等式
(
7
)
(7)
(7)中能够获得两个损失函数项:
L
i
m
g
\mathcal{L}_{img}
Limg用于图像预训练任务,
L
t
x
t
\mathcal{L}_{txt}
Ltxt用于文本预训练任务。将两个损失函数进行简单的求和,并计算合并的梯度来更新模型,避免合并梯度冲突的方法在下一小节中描述。
2.2 梯度屏蔽
正如前一小节描述,具有图像预训练和文本预训练两个损失函数项。由于两个优化是用于不同模态和损失函数的,其在联合训练中可能产生冲突梯度。简单将两个损失函数相加意味着忽略梯度冲突,其会减缓模型的训练并使模型得到次优解。
因此,这里不直接将两个损失函数相加,而是从神经网络剪枝中汲取灵感来探索解决冲突梯度的新方法。人们普遍任务当然的大模型是高度过参数化的,消除神经网络中不必要参数的技术已经展示了,在不降低精度的情况下参数量甚至可以缩减90%。
受神经网络剪枝结果的启发,作者提出了一种新颖的梯度屏蔽策略来调和文本预训练和图像预训练的潜在梯度冲突。主要想法是保留文本预训练中最重要梯度的子集,并且忽略其他梯度来为图像预训练留下空间。更正式的来说,令
θ
\theta
θ为共享
Transformer
\text{Transformer}
Transformer编码器的参数,
L
t
x
t
\mathcal{L}_{txt}
Ltxt和
L
i
m
g
\mathcal{L}_{img}
Limg是文本预训练和图像预训练的损失函数。通过一个自适应掩码M来合并文本预训练和图像预训练任务的梯度。正式来说,
G
t
x
t
=
∂
L
t
x
t
∂
θ
,
G
i
m
g
=
∂
L
i
m
g
∂
θ
G
g
l
o
b
a
l
=
M
⊙
G
t
x
t
+
(
1
−
M
)
⊙
G
i
m
g
(8)
\text{G}_{txt}=\frac{\partial\mathcal{L}_{txt}}{\partial\theta},\;\text{G}_{img}=\frac{\partial\mathcal{L}_{img}}{\partial\theta} \\ \text{G}_{global}=M\odot\text{G}_{txt}+(1-M)\odot\text{G}_{img} \tag{8}
Gtxt=∂θ∂Ltxt,Gimg=∂θ∂LimgGglobal=M⊙Gtxt+(1−M)⊙Gimg(8)
直觉上,掩码M应该选择文本预训练中最重要的梯度,并为图像预训练留下剩余的空间。因此,基于
G
t
x
t
\text{G}_{txt}
Gtxt的大小来启发式的生成掩码M。受Iterative Magnitude Pruning算法的启发,作者设计了一种迭代梯度掩码程序来逐步增加掩码的稀疏度。迭代梯度掩码程序的额外计算成本可以忽略不计,因为掩码M在整个训练过程中仅更新少数几次。例如,最终的掩码率
(
β
)
(\beta)
(β)被设置为50%且每次迭代的掩码率
δ
\delta
δ被设置为10%,那么掩码仅会被更新5次。因此,梯度遮蔽策略并不会减慢训练过程。
算法1:迭代梯度掩码
输入: Transformer编码器 θ \theta θ,总训练步骤T,掩码M,掩码率 β \beta β,掩码更新间隔t,每次迭代的掩码率 δ \delta δ。
使用预训练BERT初始化 θ \theta θ,初始化掩码M为全1.
repeat
采样一个
batch并计算梯度 G t x t \text{G}_{txt} Gtxt和 G i m g \text{G}_{img} Gimg; 剪枝 M ⊙ ∣ G t x t ∣ M\odot|\text{G}_{txt}| M⊙∣Gtxt∣中最小的 δ \delta δ个非零元素并更新M;
使用梯度 G g l o b a l = M ⊙ G t x t + ( 1 − M ) ⊙ G i m g \text{G}_{global}=M\odot\text{G}_{txt}+(1-M)\odot\text{G}_{img} Gglobal=M⊙Gtxt+(1−M)⊙Gimg训练t步的 θ \theta θ;
until M的稀疏度达到 β \beta β,即 ∑ M / ∥ θ ∥ = β \sum M/\parallel\theta\parallel=\beta ∑M/∥θ∥=β;
继续训练直至总步数为T
四、总结
- 通过蒸馏的方式来训练混合模态的模型;
- 通过梯度屏蔽的方式解决多任务训练中的梯度冲突;

