
- 1IntelliJ IDEA创建一个spark的项目_idea创建javaspark项目
- 2人工智能的落地对行业针对性以及实际运用成本提出更高要求_人工智能成本高
- 3python爬虫去哪儿网上爬取旅游景点14万条,可以做大数据分析的数据基础_去哪儿网景点数据采集
- 4如何选择合适的北斗短报文模块_北斗短报文模组
- 5HarmonyOS Next,你真的足够了解它么?_harmonyos next 开发语言(2)_arkts与仓颉编程语言
- 6kubelet 命令行参数_--enable_load_reader=true
- 7讨论OOV(新词,也叫未登录词,词典之外的词语)问题的解决方案_oov问题
- 8react 低代码图编辑探索
- 9Harmony鸿蒙南向驱动开发-GPIO
- 10【车间调度】基于GA/PSO/SA/ACO/TS优化算法的车间调度比较(Matlab代码实现)_fjsp中 机器只能同时进行一道加工工序吗
Hive-Sql复杂面试题
赞
踩
参考链接:hive sql面试题及答案 - 知乎
有哪些好的题目都可以给我哦 我来汇总到一起
1、编写sql实现每个用户截止到每月为止的最大单月访问次数和累计到该月的总访问次数
数据:
userid,month,visits
A,2015-01,5
A,2015-01,15
B,2015-01,5
A,2015-01,8
B,2015-01,25
A,2015-01,5
A,2015-02,4
A,2015-02,6
B,2015-02,10
B,2015-02,5
A,2015-03,16
A,2015-03,22
B,2015-03,23
B,2015-03,10
B,2015-03,1
预期结果:

- create table u_visit(
- userid STRING ,month STRING ,visits BIGINT
- ) LIFECYCLE 1;
- INSERT into u_visit values
- ('A','2015-01',5)
- ,('A','2015-01',15)
- ,('B','2015-01',5)
- ,('A','2015-01',8)
- ,('B','2015-01',25)
- ,('A','2015-01',5)
- ,('A','2015-02',4)
- ,('A','2015-02',6)
- ,('B','2015-02',10)
- ,('B','2015-02',5)
- ,('A','2015-03',16)
- ,('A','2015-03',22)
- ,('B','2015-03',23)
- ,('B','2015-03',10)
- ,('B','2015-03',1);
-
-
- 思路:
- 截至当前累计 over中加order by 时间
- 全累计 over中不加order by 时间
-
-
- SELECT userid
- ,MONTH
- ,visits
- ,max(visits) OVER(PARTITION BY userid ) AS max_visit
- ,max(visits) OVER(PARTITION BY userid ORDER BY MONTH ASC ) AS max_visit --截止到当月最大值
- ,SUM(visits) OVER(PARTITION BY userid ORDER BY MONTH ASC ) AS sum_visit
- FROM (
- SELECT userid
- ,MONTH
- ,sum(visits) visits
- FROM u_visit
- GROUP BY userid
- ,MONTH
- ) A
- ;
-
结果
用户id 月份 月访问数 截止目前最大访问数 截止当前月最大访问数 截止当前月总访问数
userid month visits max_visit max_visit2 sum_visit
A 2015-01 33 38 33 33
A 2015-02 10 38 33 43
A 2015-03 38 38 38 81
B 2015-01 30 34 30 30
B 2015-02 15 34 30 45
B 2015-03 34 34 34 79
2、求出每个栏目的被观看次数及累计观看时长
数据:
vedio表
用户id 栏目id 时长
Uid channl min
1 1 23
2 1 12
3 1 12
4 1 32
5 1 342
6 2 13
7 2 34
8 2 13
9 2 134
这个好简单 pass
3、编写连续7天登录的总人数
数据:
t1表
Uid dt login_status(1登录成功,0异常)
1 2019-07-11 1
1 2019-07-12 1
1 2019-07-13 1
1 2019-07-14 1
1 2019-07-15 1
1 2019-07-16 1
1 2019-07-17 1
1 2019-07-18 1
2 2019-07-11 1
2 2019-07-12 1
2 2019-07-13 0
2 2019-07-14 1
2 2019-07-15 1
2 2019-07-16 0
2 2019-07-17 1
2 2019-07-18 0
3 2019-07-11 1
3 2019-07-12 1
3 2019-07-13 1
3 2019-07-14 1
3 2019-07-15 1
3 2019-07-16 1
3 2019-07-17 1
3 2019-07-18 1
- create TABLE t1(
- Uid bigint,dt STRING , login_status BIGINT COMMENT '(1登录成功,0异常)'
- ) LIFECYCLE 1;
- INSERT INTO t1 VALUES
- (1, '2019-07-11', 1)
- ,(1, '2019-07-12', 1)
- ,(1, '2019-07-13', 1)
- ,(1, '2019-07-14', 1)
- ,(1, '2019-07-15', 1)
- ,(1, '2019-07-16', 1)
- ,(1, '2019-07-17', 1)
- ,(1, '2019-07-18', 1)
- ,(2, '2019-07-11', 1)
- ,(2, '2019-07-12', 1)
- ,(2, '2019-07-13', 0)
- ,(2, '2019-07-14', 1)
- ,(2, '2019-07-15', 1)
- ,(2, '2019-07-16', 0)
- ,(2, '2019-07-17', 1)
- ,(2, '2019-07-18', 0)
- ,(3, '2019-07-11', 1)
- ,(3, '2019-07-12', 1)
- ,(3, '2019-07-13', 1)
- ,(3, '2019-07-14', 1)
- ,(3, '2019-07-15', 1)
- ,(3, '2019-07-16', 1)
- ,(3, '2019-07-17', 1)
- ,(3, '2019-07-18', 1);
- --思路1
- -- 1、先按照每个人登录时间排序成如下数据结构
- -- 1 07-01 1
- -- 1 07-02 2
- -- 1 07-03 3
- --2、 时间与排序做date_sub,变成如下结果
- -- 1 07-01 1 06-30
- -- 1 07-02 2 06-30
- -- 1 07-03 3 06-30
- -- 3、根据id聚合时间差,变成如下结果:
- --1 06-30 3 07-01 07-03 证明用户1 连续登录了3天 起始登录时间是07-01 结束连续登录是07-03
- SELECT Uid
- ,COUNT(dtadd) AS countadd
- ,COUNT(dtsub) AS countsub
- ,MIN(dt) mindt
- ,MAX(dt) maxdt
- FROM (
- SELECT Uid
- ,dt
- ,DATEADD(dt,-rk,'dd') dtadd
- ,date_sub(dt,rk) dtsub
- FROM (
- SELECT Uid
- ,to_date(dt,'yyyy-mm-dd') dt
- ,ROW_NUMBER() OVER(PARTITION BY uid ORDER BY dt ASC ) AS rk
- FROM t1
- WHERE login_status = 1
- ) A
- ) B
- GROUP BY uid
- HAVING COUNT(dtadd) >= 7
- ;
结果:
uid countadd countsub mindt maxdt
1 8 8 2019-07-11 00:00:00 2019-07-18 00:00:00
3 8 8 2019-07-11 00:00:00 2019-07-18 00:00:00
- -- 思路2:
- -- 1、先按照每个人登录时间排序成如下数据结构
- -- 1 07-01 1
- -- 1 07-02 2
- -- 1 07-03 3
- --2、 利用lead或lag函数 上下错位,并计算时间差
- -- 1 07-01 07-02 1
- -- 1 07-02 07-03 1
- -- 1 07-03 null
- -- 3、根据id聚合时间差,变成如下结果:
- --1 2(因为有null,得再加个1) 证明用户1 连续登录了3天
- SELECT
- uid
- ,COUNT(dtdiff)+1 AS 登录总次数
- FROM
- (SELECT Uid
- ,dt
- ,LEAD(dt,1) OVER (PARTITION BY uid ORDER BY dt ASC) leadrk
- ,DATEDIFF(dt,LEAD(dt,1) OVER (PARTITION BY uid ORDER BY dt ASC),'dd') dtdiff
- FROM (
- SELECT Uid
- ,to_date(dt,'yyyy-mm-dd') dt
- ,ROW_NUMBER() OVER(PARTITION BY uid ORDER BY dt ASC ) AS rk
- FROM t1
- WHERE login_status = 1
- ) A
- ) B
- where (dtdiff=-1 or dtdiff is null)
- group by uid
- HAVING COUNT(dtdiff)+1>=7
- ;
结果:
uid 登录总次数
1 8
3 8
4、编写sql语句实现每班前三名,分数一样并列,同时求出前三名按名次排序的依次的分差:
数据:
stu表
Stu_no class score
1 1901 90
2 1901 90
3 1901 83
4 1901 60
5 1902 66
6 1902 23
7 1902 99
8 1902 67
9 1902 87
- create table stu(
- Stu_no BIGINT , class BIGINT , score BIGINT
- ) LIFECYCLE 1;
- INSERT INTO stu VALUES
- (1 ,1901, 90)
- ,(2 ,1901, 90)
- ,(3 ,1901, 83)
- ,(4 ,1901, 60)
- ,(5 ,1902, 66)
- ,(6 ,1902, 23)
- ,(7 ,1902, 99)
- ,(8 ,1902, 67)
- ,(9 ,1902, 87);
-
- -- 思路1
- -- 1、各班自行排序,可并列 应使用 dense_rank 区别rankrk
- -- 2、利用lag或lead函数,上下错误,并计算分差
- SELECT stu_no
- ,class
- ,score
- ,LEAD(score,1) OVER (PARTITION BY class ORDER BY score DESC ) leadscore
- ,LAG(score,1) OVER (PARTITION BY class ORDER BY score DESC ) lagscore
- ,score-nvl(LEAD(score,1) OVER (PARTITION BY class ORDER BY score DESC ),0) AS 分差lead
- ,LAG(score,1) OVER (PARTITION BY class ORDER BY score DESC )-score AS 分差lag
- FROM (
- SELECT stu_no
- ,class
- ,score
- ,DENSE_RANK() OVER (PARTITION BY class ORDER BY score DESC ) denserk
- ,RANK() OVER (PARTITION BY class ORDER BY score DESC ) rankrk
- FROM stu
- ) A
- WHERE denserk <= 3
- ;
第一步结果:
stu_no class score denserk rankrk
1 1901 90 1 1
2 1901 90 1 1
3 1901 83 2 3
4 1901 60 3 4
7 1902 99 1 1
9 1902 87 2 2
8 1902 67 3 3
5 1902 66 4 4
6 1902 23 5 5
结果 [具体向上取分差还是向下取分差按实际情况即可]:
stu_no class score leadscore lagscore 分差lead 分差lag
1 1901 90 90 \N 0 \N
2 1901 90 83 90 7 0
3 1901 83 60 90 23 7
4 1901 60 \N 83 60 23
7 1902 99 87 \N 12 \N
9 1902 87 67 99 20 12
8 1902 67 \N 87 67 20
5、每个店铺的当月销售额和累计到当月的总销售额
数据:
店铺,月份,金额
a,01,150
a,01,200
b,01,1000
b,01,800
c,01,250
c,01,220
b,01,6000
a,02,2000
a,02,3000
b,02,1000
b,02,1500
c,02,350
c,02,280
a,03,350
a,03,250
参考1思路
6、分析用户的行为习惯,找到每个用户的第一次行为
数据:user_action_log
uid time action
1 time1 Read
3 time2 Comment
1 time3 Share
2 time4 Like
1 time5 Write
2 time6 Share
3 time7 Write
2 time8 Read
思路,
1、排序取第一个
2、first_value函数
7、订单及订单类型行列互换
t_order表:
order_id order_type order_time
111 N 10:00
111 A 10:05
111 B 10:10
是用hql获取结果如下:
order_id order_type_1 order_type_2 order_time_1 order_time_2
111 N A 10:00 10:05
111 A B 10:05 10:10
- create table t_order
- (order_id BIGINT , order_type STRING , order_time STRING )
- LIFECYCLE 1;
-
- INSERT INTO t_order VALUES
- (111, 'N', '10:00')
- ,(111, 'A', '10:05')
- ,(111, 'B', '10:10');
-
- --思路
- -- 1、按照时间升序排列数据
- -- 2、利用lead函数取下一个数据,取不到的排除掉
- SELECT *
- FROM (
- SELECT order_id
- ,order_type AS order_type_1
- ,LEAD(order_type,1) OVER (PARTITION BY order_id ORDER BY order_time ASC ) AS order_type_2
- ,order_time AS order_time_1
- ,LEAD(order_time,1) OVER (PARTITION BY order_id ORDER BY order_time ASC ) AS order_time_2
- FROM (
- SELECT order_id
- ,order_type
- ,order_time
- ,ROW_NUMBER() OVER (PARTITION BY order_id ORDER BY order_time ASC ) rk
- FROM t_order
- ) A
- )
- WHERE order_type_2 IS NOT NULL
- ;
结果:
order_id order_type_1 order_type_2 order_time_1 order_time_2
111 N A 10:00 10:05
111 A B 10:05 10:10
8、某APP每天访问数据存放在表access_log里面,包含日期字段 ds,用户类型字段user_type,用户账号user_id,用户访问时间 log_time,请使用hive的hql语句实现如下需求:
(1)、每天整体的访问UV、PV?
(2)、每天每个类型的访问UV、PV?
(3)、每天每个类型中最早访问时间和最晚访问时间?
(4)、每天每个类型中访问次数最高的10个用户?
(1)思路
UV = count(user_id)
PV = sum(user_id)
select
count(user_id) over(distribute by user_id) uv,
sum(user_id) over(distribute by log_time) pv
from access_log
(2)思路
select
count(user_id) uv
sum(user_id) over(distribute by log_time) pv
from access_log al1
inner join
access_log al2
group by
user_type
(3)思路
select
first_value(log_time) over(distribute by user_type order by log_time) first_time,
last_value(log_time) over(distribute by user_type order by log_time)
from access_log
(4)思路
select
user_id
from
(select
count(user_id) cnt
row_number() over(distribute by user_type order by count(user_id)) rows
from access_log) tmp
where tmp.rows<=10
9、每个用户连续登陆的最大天数?
数据:
login表
uid,date
1,2019-08-01
1,2019-08-02
1,2019-08-03
2,2019-08-01
2,2019-08-02
3,2019-08-01
3,2019-08-03
4,2019-07-28
4,2019-07-29
4,2019-08-01
4,2019-08-02
4,2019-08-03
结果如下:
uid cnt_days
1 3
2 2
3 1
4 3
- create table login(
- uid BIGINT ,logindate STRING
- ) LIFECYCLE 1;
- INSERT INTO login VALUES
- (1,'2019-08-01')
- ,(1,'2019-08-02')
- ,(1,'2019-08-03')
- ,(2,'2019-08-01')
- ,(2,'2019-08-02')
- ,(3,'2019-08-01')
- ,(3,'2019-08-03')
- ,(4,'2019-07-28')
- ,(4,'2019-07-29')
- ,(4,'2019-08-01')
- ,(4,'2019-08-02')
- ,(4,'2019-08-03');
-
- --思路
- --1、先排序 升序
- --2、通过date_sub计算时间差
- --3、通过date_sub时间差+用户id 分组计算 每次连续登录次数
- --4、通过用户id分组 获取最大连续登录次数
- SELECT uid
- ,MAX(loginCount)
- FROM (
- SELECT uid
- ,subdate
- ,COUNT(logindate) loginCount
- FROM (
- SELECT uid
- ,logindate
- ,date_sub(logindate,rk) subdate
- FROM (
- SELECT uid
- ,logindate
- ,ROW_NUMBER() OVER(PARTITION BY uid ORDER BY logindate ASC) rk
- FROM login
- ) A
- ) B
- GROUP BY uid
- ,subdate
- ) C
- group by uid
- ;
结果:
uid _c1
1 3
2 2
3 1
4 3
10、使用hive的hql实现男女各自第一名及其它
id sex chinese_s math_s
0 0 70 50
1 0 90 70
2 1 80 90
1、男女各自语文第一名(0:男,1:女)
不需要取id的话
select
sex
,max(chinese_s)
from t
group by sex
需要取id的话
select
iD
,sex
,max(chinese_s) over(partition by sex)
from t
2、男生成绩语文大于80,女生数学成绩大于70
select *
from t
where (sex=1 and chinese_s>80) or (sex=0 and math_s>70)
11、使用hive的hql实现最大连续访问天数
log_time uid
2018-10-01 18:00:00,123
2018-10-02 18:00:00,123
2018-10-02 19:00:00,456
2018-10-04 18:00:00,123
2018-10-04 18:00:00,456
2018-10-05 18:00:00,123
2018-10-06 18:00:00,123
参考9
12、编写sql实现行列互换

行转列:
1、使用case when 查询出多列即可,即可增加列。
列转行:
1、lateral view explode(),使用炸裂函数可以将1列转成多行,被转换列适用于array、map等类型。 lateral view posexplode(数组),如有排序需求,则需要索引。将数组炸开成两行(索引 , 值),需要 as 两个别名。
2、case when 结合concat_ws与collect_set/collect_list实现。内层用case when,外层用 collect_set/list收集,对搜集完后用concat_ws分割连接形成列。
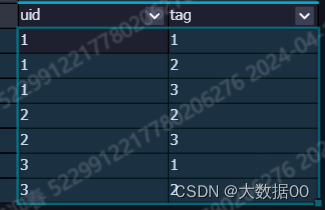
13、编写sql实现如下:
数据:
t1表
uid tags
1 1,2,3
2 2,3
3 1,2
编写sql实现如下结果:
uid tag
1 1
1 2
1 3
2 2
2 3
3 1
3 2
- create TABLE tags(
- uid bigint ,tags STRING
- ) LIFECYCLE 1;
-
- INSERT INTO tags VALUES
- (1, '1,2,3')
- ,(2, '2,3')
- ,(3, '1,2');
-
- SELECT uid
- ,tag
- FROM tags
- LATERAL VIEW EXPLODE(split(tags,",")) temp AS tag
- ;
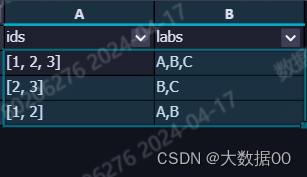
14、用户标签连接查询
数据:
T1表:
Tags
1,2,3
1,2
2,3
T2表:
Id lab
1 A
2 B
3 C
根据T1和T2表的数据,编写sql实现如下结果:
ids tags
1,2,3 A,B,C
1,2 A,B
2,3 B,C
预期结果:

- SELECT collect_list(id) as ids
- ,WM_CONCAT(',',name) as labs
- FROM (
- SELECT tag
- ,rk
- FROM (
- SELECT *
- ,ROW_NUMBER() OVER (PARTITION BY 1) AS rk
- FROM tags
- ) tags
- LATERAL VIEW EXPLODE(split(tags,",")) temp AS tag
- ) A
- LEFT JOIN (
- SELECT 1 AS id
- ,'A' AS name
- UNION ALL
- SELECT 2 AS id
- ,'B' AS name
- UNION ALL
- SELECT 3 AS id
- ,'C' AS name
- ) B
- ON A.tag = B.id
- group by rk
- ;
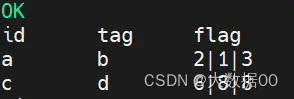
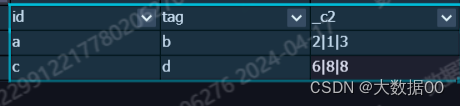
15、用户标签组合
数据:
t1表:
id tag flag
a b 2
a b 1
a b 3
c d 6
c d 8
c d 8
编写sql实现如下结果:
id tag flag
a b 1|2|3
c d 6|8
预期结果:
- SELECT
- id,tag,WM_CONCAT("|",flag)
- from
- (select 'a' as id, 'b' as tag, 2 as flag union all
- select 'a' as id, 'b' as tag, 1 as flag union all
- select 'a' as id, 'b' as tag, 3 as flag union all
- select 'c' as id, 'd' as tag, 6 as flag union all
- select 'c' as id, 'd' as tag, 8 as flag union all
- select 'c' as id, 'd' as tag, 8 as flag ) temp
- group by id,tag;
16、户标签行列互换
数据:
t1表
uid name tags
1 goudan chihuo,huaci
2 mazi sleep
3 laotie paly
编写sql实现如下结果:
uid name tag
1 goudan chihuo
1 goudan huaci
2 mazi sleep
3 laotie paly
炸裂函数~~
17、hive实现词频统计
数据:
t1表:
uid contents
1 i|love|china
2 china|is|good|i|i|like
统计结果如下,如果出现次数一样,则按照content名称排序:
content cnt
i 3
china 2
good 1
like 1
love 1
is 1
- SELECT tag
- ,COUNT(id)
- FROM (
- SELECT id
- ,tag
- FROM (
- SELECT 1 AS id
- ,'i|love|china' AS tags
- UNION
- SELECT 2 AS id
- ,'china|is|good|i|i|like'
- ) temp
- LATERAL VIEW EXPLODE (split(tags,'\\|')) temp1 AS tag --|需要转义
- )
- GROUP BY tag
- ORDER BY COUNT(id) DESC
- ,tag DESC
- ;

18、课程行转列
数据:
t1表
id course
1,a
1,b
1,c
1,e
2,a
2,c
2,d
2,f
3,a
3,b
3,c
3,e
根据编写sql,得到结果如下(表中的1表示选修,表中的0表示未选修):
id a b c d e f
1 1 1 1 0 1 0
2 1 0 1 1 0 1
3 1 1 1 0 1 0
- SELECT
- id
- ,max(case when course='a' then 1 else 0 end ) as a
- ,max(case when course='b' then 1 else 0 end ) as b
- ,max(case when course='c' then 1 else 0 end ) as c
- ,max(case when course='d' then 1 else 0 end ) as d
- ,max(case when course='e' then 1 else 0 end ) as e
- ,max(case when course='f' then 1 else 0 end ) as f
- FROM
- (select 1 as id ,'a' as course union all
- select 1 as id ,'b' as course union all
- select 1 as id ,'c' as course union all
- select 1 as id ,'e' as course union all
- select 2 as id ,'a' as course union all
- select 2 as id ,'c' as course union all
- select 2 as id ,'d' as course union all
- select 2 as id ,'f' as course union all
- select 3 as id ,'a' as course union all
- select 3 as id ,'b' as course union all
- select 3 as id ,'c' as course union all
- select 3 as id ,'e' as course ) temp
- group by id;

19、兴趣行转列
t1表
name sex hobby
janson 男 打乒乓球、游泳、看电影
tom 男 打乒乓球、看电影
hobby最多3个值,使用hql实现结果如下:
name sex hobby1 hobby2 hobby3
janson 男 打乒乓球 游泳 看电影
tom 男 打乒乓球 看电影
- SELECT name
- ,sex
- ,max(split(hobby,'、')[0]) AS hobby1
- ,max(split(hobby,'、')[1]) AS hobby2
- ,max(split(hobby,'、')[2]) AS hobby3
- FROM (
- SELECT 'janson' AS name
- ,'男' AS sex
- ,'打乒乓球、游泳、看电影' AS hobby
- UNION ALL
- SELECT 'tom ' AS name
- ,'男' AS sex
- ,'打乒乓球、看电影' AS hobby
- ) temp
- GROUP BY name
- ,sex
- ;
name sex hobby1 hobby2 hobby3
janson 男 打乒乓球 游泳 看电影
tom 男 打乒乓球 看电影 \N
20、用户商品行列互换
t1表:
用户 商品
A P1
B P1
A P2
B P3
请你使用hql变成如下结果:1代表购买过的商品0代表未购买
用户 P1 P2 P3
A 1 1 0
B 1 0 1
参考18,选修课
21、求top3英雄及其pick率
id names
1 亚索,挖掘机,艾瑞莉娅,洛,卡莎
2 亚索,盖伦,奥巴马,牛头,皇子
3 亚索,盖伦,艾瑞莉娅,宝石,琴女
4 亚素,盖伦,赵信,老鼠,锤石
请用 HiveSQL 计算出出场次数最多的 top3 英雄及其 pick 率(=出现场数/总场数)
-
- SELECT
- name
- ,COUNT(1) 出现次数
- ,COUNT(1)/max(id) pick率
- from
- (SELECT
- id,name
- from
- (select 1 as id, '亚索,挖掘机,艾瑞莉娅,洛,卡莎' as names UNION all
- select 2 as id, '亚索,盖伦,奥巴马,牛头,皇子' UNION all
- select 3 as id, '亚索,盖伦,艾瑞莉娅,宝石,琴女' UNION all
- select 4 as id, '亚索,盖伦,赵信,老鼠,锤石' ) temp
- LATERAL VIEW EXPLODE (split(names,',')) temp1 as name
- ) group by name
- ;
name 出现次数 pick率
亚索 4 1.0
卡莎 1 1.0
奥巴马 1 0.5
宝石 1 0.3333333333333333
挖掘机 1 1.0
洛 1 1.0
牛头 1 0.5
琴女 1 0.3333333333333333
皇子 1 0.5
盖伦 3 0.75
老鼠 1 0.25
艾瑞莉娅 2 0.6666666666666666
赵信 1 0.25
锤石 1 0.25
21、使用hive求出两个数据集的差集
数据
t1表:
id name
1 zs
2 ls
t2表:
id name
1 zs
3 ww
结果如下:
id name
2 ls
3 ww
SELECT tab4.*
FROM tab4
LEFT JOIN tab5 ON tab4.id=tab5.id
WHERE tab5.id IS NULL
UNION
SELECT tab5.*
FROM tab5
LEFT JOIN tab4 ON tab4.id=tab5.id
WHERE tab4.id IS NULL;
22、两个表A 和B ,均有key 和value 两个字段,写一个SQL语句, 将B表中的value值置成A表中相同key值对应的value值
A:
key vlaue
k1 123
k2 234
k3 235
B:
key value
k1 111
k2 222
k5 246
使用hive的hql实现,结果是B表数据如下:
k1 123
k2 234
k5 246
23、有用户表user(uid,name)以及黑名单表Banuser(uid)
1、用left join方式写sql查出所有不在黑名单的用户信息
2、用not exists方式写sql查出所有不在黑名单的用户信息
24、使用什么来做的cube
使用with cube 、 with rollup 或者grouping sets来实现cube。
详细解释如下:
0、hive一般分为基本聚合和高级聚合
基本聚合就是常见的group by,高级聚合就是grouping set、cube、rollup等。
一般group by与hive内置的聚合函数max、min、count、sum、avg等搭配使用。
1、grouping sets可以实现对同一个数据集的多重group by操作。
事实上grouping sets是多个group by进行union all操作的结合,它仅使用一个stage完成这些操作。
grouping sets的子句中如果包换() 数据集,则表示整体聚合。多用于指定的组合查询。
2、cube俗称是数据立方,它可以时限hive任意维度的组合查询。
即使用with cube语句时,可对group by后的维度做任意组合查询
如:group a,b,c with cube ,则它首先group a,b,c 然后依次group by a,c 、 group by b,c、group by a,b 、group a 、group b、group by c、group by () 等这8种组合查询,所以一般cube个数=2^3个。2是定 值,3是维度的个数。多用于无级联关系的任意组合查询。
3、rollup是卷起的意思,俗称层级聚合,相对于grouping sets能指定多少种聚合,而with rollup则表示从左 往右的逐级递减聚合,如:group by a,b,c with rollup 等价于 group by a, b, c grouping sets( (a, b, c), (a, b), (a), ( )).直到逐级递减为()为止,多适用于有级联关系的组合查询,如国家、省、市级联组合查 询。
4、Grouping__ID在hive2.3.0版本被修复过,修复后的发型版本和之前的不一样。对于每一列,如果这列 被聚合 过则返回0,否则返回1。应用场景暂时很难想到用于哪儿。
5、grouping sets/cube/rollup三者的区别: 注: grouping sets是指定具体的组合来查询。 with cube 是group by后列的所有的维度的任意组合查询。
with rollup 是group by后列的从左往右逐级递减的层级组合查询。 cube/rollup 后不能加()来选择列,hive是要求这样。
25、访问日志正则提取
表t1(注:数据时正常的访问日志数据,分隔符全是空格)
8.35.201.160 - - [16/May/2018:17:38:21 +0800] "GET
/uc_server/data/avatar/000/01/54/22_avatar_middle.jpg HTTP/1.1" 200 5396
使用hive的hql实现结果如下:
ip dt url
8.35.201.160 2018-5-16 17:38:21
/uc_server/data/avatar/000/01/54/22_avatar_middle.jpg
26、30日内留存、留存率计算
假设我们有一个名为user_activity的表,它记录了App用户的活动信息。表结构如下:
user_activity ( user_id INT, -- 用户ID activity_time TIMESTAMP, -- 活动发生时间 activity_type VARCHAR(255) -- 活动类型 -- 可能还有其他字段,但本题仅考虑上述字段 )
求30日内留存量与留存率
-
- select
- logindate
- ,count(distinct user_id) 新增用户数DNC
- ,count(distinct case when days=1 then user_id else null end) as 次日留存量
- ,count(distinct case when days=1 then user_id else null end)/count(user_id) as 次日留存率
- ,count(distinct case when days=3 then user_id else null end) as 3日留存量
- ,count(distinct case when days=3 then user_id else null end)/count(user_id) as 3日留存率
- ,count(distinct case when days=7 then user_id else null end) as 7日留存量
- ,count(distinct case when days=7 then user_id else null end)/count(user_id) as 7日留存率
- ,count(distinct case when days=30 then user_id else null end) as 30日留存量
- ,count(distinct case when days=30 then user_id else null end)/count(user_id) as 30日留存率
- from
- (select
- A.user_id,
- A.activity_time as logindate
- datediff(a.activity_time,b.activity_time,'dd') days
- (select user_id,activity_time,activity_type
- from user_activity where activity_type ='注册'
- and datediff(getdate(),activity_time,'dd')<=30) A
- left join
- (select user_id,activity_time,activity_type
- from user_activity where activity_type ='登录'
- and datediff(getdate(),activity_time,'dd')<=30) B
- On a.user_id=b.user_id
- and a.activity_time<=b.activity_time
- ) C
- group by logindate
| 日期 | 新增用户数DNC | 次日留存用户数 | 次日留存率 | 7日留存用户数 | 7日留存率 | 30日留存用户数 | 30日留存率 |
| 20220430 | 8,099 | 1,040 | 12.84% | 582 | 7.19% | 386 | 4.77% |
| 20220429 | 11,077 | 1,049 | 9.47% | 531 | 4.79% | 331 | 2.99% |
| 20220428 | 9,098 | 1,106 | 12.16% | 518 | 5.69% | 382 | 4.20% |
| 20220427 | 8,111 | 890 | 10.97% | 370 | 4.56% | 237 | 2.92% |
| 20220426 | 7,372 | 953 | 12.93% | 449 | 6.09% | 301 | 4.08% |
| 20220425 | 7,351 | 994 | 13.52% | 460 | 6.26% | 313 | 4.26% |
| 20220424 | 6,034 | 1,006 | 16.67% | 542 | 8.98% | 375 | 6.21% |
| 20220423 | 5,810 | 954 | 16.42% | 454 | 7.81% | 311 | 5.35% |
| 20220422 | 6,988 | 868 | 12.42% | 440 | 6.30% | 265 | 3.79% |
| 20220421 | 6,649 | 853 | 12.83% | 377 | 5.67% | 242 | 3.64% |
| 20220420 | 6,304 | 844 | 13.39% | 389 | 6.17% | 218 | 3.46% |
| 20220419 | 6,715 | 868 | 12.93% | 447 | 6.66% | 292 | 4.35% |
|
日期
|
20220430
|
20220429
|
20220428
|
20220427
|
20220426
|
20220425
|
20220424
|
20220423
|
20220422
|
20220421
|
20220420
|
20220419
|
|
新增用户数DNC
|
8,099
|
11,077
|
9,098
|
8,111
|
7,372
|
7,351
|
6,034
|
5,810
|
6,988
|
6,649
|
6,304
|
6,715
|
|
次日留存用户数
|
1,040
|
1,049
|
1,106
|
890
|
953
|
994
|
1,006
|
954
|
868
|
853
|
844
|
868
|
|
次日留存率
|
12.84%
|
9.47%
|
12.16%
|
10.97%
|
12.93%
|
13.52%
|
16.67%
|
16.42%
|
12.42%
|
12.83%
|
13.39%
|
12.93%
|
|
7日留存用户数
|
582
|
531
|
518
|
370
|
449
|
460
|
542
|
454
|
440
|
377
|
389
|
447
|
|
7日留存率
|
7.19%
|
4.79%
|
5.69%
|
4.56%
|
6.09%
|
6.26%
|
8.98%
|
7.81%
|
6.30%
|
5.67%
|
6.17%
|
6.66%
|
|
30日留存用户数
|
386
|
331
|
382
|
237
|
301
|
313
|
375
|
311
|
265
|
242
|
218
|
292
|
|
30日留存率
|
4.77%
|
2.99%
|
4.20%
|
2.92%
|
4.08%
|
4.26%
|
6.21%
|
5.35%
|
3.79%
|
3.64%
|
3.46%
|
4.35%
|
27、计算每个品牌总的打折销售天数
如下为平台商品促销数据:字段为品牌,打折开始日期,打折结束日期
brand stt edt
oppo 2021-06-05 2021-06-09
oppo 2021-06-11 2021-06-21
vivo 2021-06-05 2021-06-15
vivo 2021-06-09 2021-06-21
redmi 2021-06-05 2021-06-21
redmi 2021-06-09 2021-06-15
redmi 2021-06-17 2021-06-26
huawei 2021-06-05 2021-06-26
huawei 2021-06-09 2021-06-15
huawei 2021-06-17 2021-06-21
计算每个品牌总的打折销售天数,注意其中的交叉日期,比如vivo品牌,第一次活动时间为2021-06-05到2021-06-15,
第二次活动时间为2021-06-09到2021-06-21其中9号到15号为重复天数,只统计一次,
即vivo总打折天数为2021-06-05到2021-06-21共计17天。
- create table t_brand (brand STRING , stt STRING ,edt STRING ) LIFECYCLE 1;
- INSERT INTO t_brand VALUES
- ('oppo' ,'2021-06-05', '2021-06-09')
- ,('oppo' ,'2021-06-11', '2021-06-21')
- ,('vivo' ,'2021-06-05', '2021-06-15')
- ,('vivo' ,'2021-06-09', '2021-06-21')
- ,('redmi' ,'2021-06-05', '2021-06-21')
- ,('redmi' ,'2021-06-09', '2021-06-15')
- ,('redmi' ,'2021-06-17', '2021-06-26')
- ,('huawei' ,'2021-06-05', '2021-06-26')
- ,('huawei' ,'2021-06-09', '2021-06-15')
- ,('huawei' ,'2021-06-17', '2021-06-21');
-
- -- 思路一:
- -- 既然是交叉问题,那每个品牌都可能有这样的问题,我们观察完数据,第一反应就是能不能把同一个品牌在某段时间有交叉日期的数据标记出来,
- -- 然后再用group by 根据品牌和标记出来的字段分组,这样我们就可以把某段时间有交叉日期的数据分到同一个组,然后我们就可以用该分组内
- -- 打折结束日期的最大值减去打折开始日期的最小值,就可以得到某个时间段的打折天数,然后最终我们就可以根据不同的品牌计算出总天数。具体看下面HQL
- -- 思路二:
- -- 按照品牌字段分组,stt字段从小到大排序,如果不存在交叉数据,那么头一条数据的结束时间一定要比第二条的开始时间小,如以上数据的oppo品牌。
- -- 那么出现交叉数据的问题,肯定就是头一条数据的结束时间一定要比第二条的开始时间大。所以如果这条数据的开始时间都要比这条数据的之前的结束时间大,
- -- 那么这样就不会存在交叉的数据问题了。按照这个思路,我们创建一个新的开始时间new_stt,如果开始时间stt这个字段和前面数据不存在交叉问题,
- -- 那么我们就用stt字段充当new_stt,如果和前面的数据存在交叉问题,那么我们用前面数据的结束日期的最大值+1来充当new_stt字段。
- -- 这样我们用结束时间减去新的开始时间就可以得到打折的天数了,如果结束时间减去开始时间是负数,那么这就是出现了交叉问题的数据,我们直接忽略掉就可以。
-
-
- select
- brand,
- sum(diff) days
- from
- (
- select
- brand,
- datediff(max(edt),min(stt))+1 diff
- from
- (
- select
- *,
- sum(f) over (partition by brand order by stt) su
- from
- (
- select
- *,
- max(edt) over(partition by brand order by stt rows between unbounded preceding and 1 preceding),
- if(datediff(max(edt) over(partition by brand order by stt rows between unbounded preceding and 1 preceding),stt)>=0,0,1) f
- from t_brand
- )t1
- )t2
- group by brand,su
- )t3
- group by brand;
-
-
- select
- brand,
- sum(if(diff>0,diff+1,0)) days
- from
- (
- select
- brand,
- datediff(edt,new_stt) diff
- from
- (
- select
- brand,
- stt,
- if(datediff(m,stt)>0,date_add(m,1),stt) new_stt,
- edt
- from
- (
- select
- *,
- max(edt) over(partition by brand order by stt rows between unbounded preceding and 1 preceding) m
- from t_brand
- )t1
- )t2
- )t3
- group by brand;
28、对于同一个id的数据,需要计算主键id外,任意两列之间的关系,两列均为1,关系为1,否则为0
表t
id,a,b,c,d,e
00001,0,1,1,0,1
00002,......
结果示例如下
id,c1,c2,relation
00001,a,b,0
00001,a,c,0
00001,a,d,0
00001,a,e,0
00001,b,c,1
00001,b,d,0
00001,b,e,1
00001,c,d,0
00001,c,e,1
00001,d,e,0
00002,......

