
- 1ToDesk远程控制_pemm.top
- 2Qwen-Agent自定义Tool
- 3python绘制热力图
- 4Elasticsearch报错received plaintext traffic on an encrypted channel, closing connection Netty4TcpChann
- 5【GitHub项目推荐--7个最佳开源免费库存/仓库管理系统(WMS)】【转载】_github 仓库管理系统
- 6手把手教你安装搭建进销存源码|erp软件|仓库出入库登记系统源码(附源码下载)_erp系统仓库管理系统源码
- 7HDFS-HA模式概念_hdfs ha
- 8Linux Ext4文件系统可能引发数据丢失问题
- 9问题描述:无法在vscode中调试python程序。_vscode不能调试python
- 10数据结构PT1——线性表/链表
手工微调embedding模型RAG检索能力_embedding模型微调
赞
踩
在RAG应用中,有一个我们可以去提升的环节就是——Embedding模型,我在之前的文章《大模型主流应用RAG的介绍——从架构到技术细节》也说过可以去微调embedding模型以便增强我们整体的检索能力。
最早我们用的是OpenAI的Embedding模型text-embedding-ada-002,但这个模型后面不一定可以在正式环境中使用,而且我们也没办法去微调,因此让我们在本文中探索对开源Embedding模型进行微调。
BAAI/bge-small-en
目前HuggingFace的MTEB(海量文本Embedding基准)排行榜上排名第一的Embedding模型是big-large-en,它由北京人工智能研究院(BAAI,智源)开发。它是一种预训练的transformer模型,可用于各种自然语言处理任务,如文本分类、问答、文本生成等。该模型在海量文本和代码数据集上进行训练,并在海量文本Embedding基准(MTEB)上进行了微调。
在本文中,我们将使用 big-large-en的缩小版big-small-en,这是一个384维的小规模模型(OpenAI是1500+维),具有竞争力的性能,非常适合在Google Colab中运行。大家也可以选择中文版的bge-base-zh-v1.5,只有0.1G。当然你的硬件环境允许,也可以使用1.3G的bge-large-zh-v1.5等embedding模型。
微调Embedding模型与微调LLM
与LLM(大语言模型)微调相比,big-small-en微调的实现有一些不一样,下面简单说一下异同点:
相似点
- 两种类型的微调都遵循相同的方法,即生成用于训练和评估的数据集,微调模型,最后评估基本模型和微调模型之间的性能。
- 使用LLM自动生成训练和评估数据集。
不同点
- 数据集内容在LLM微调和Embedding模型微调之间有所不同。用于LLM微调的数据集包含LLM生成的问题。在微调过程中,包括问题、答案、系统prompt等在内的一系列数据将以JSON行(
jsonl)文件的形式传递给要进行微调的模型。
不同的是,用于Embedding模型微调的数据集包含以下三组:
queries:node_id映射和LLM生成的问题的集合。corpus:node_id映射和相应节点中的文本的集合。relevant_docs:查询的node_id和语料库node_id之间的交叉引用映射的集合。给定一个查询,它告诉Embedding模型要查找哪个文本节点/语料库。
- 由于我们使用开源Embedding模型
bge-small-en,微调的前提就是要先把它下载到您的本地环境。以Google Colab为例,经过微调的模型将被下载到笔记本的根目录中。 - 评估方法在微调Embedding模型和微调LLM之间有所不同,我们可以使用Ragas框架来衡量精准度和答案相关性。然而,当使用Embedding模型微调时,我们无法测量答案的正确性,因为我们只能为我们的问题检索相关节点。相反,我们使用一个称为“命中率”的简单度量,这意味着对于每个
(query, relevant_doc)对,我们用查询检索top-k文档,如果结果包含relevant_doc,则它被认为是“命中”的。该指标可用于专有Embeddings,如OpenAI的Embedding模型和开源Embedding模型。对于开源Embedding模型,我们还可以使用来自sentence_transformers的InformationRetrievalEvaluator进行评估,因为它提供了一套更全面的指标。
微调Embedding模型似乎涉及到很多问题。幸运的是,LlamaIndex(我个人感觉LlamaIndex目前的发展可能会在RAG方面打败LangChain)在最近的0.8.21版本中引入以下关键类/函数,使得微调Embedding模型变得超级简单:
SentenceTransformersFinetuneEnginegenerate_qa_embedding_pairsEmbeddingQAFinetuneDataset
这些类和函数为我们抽象了底层的详细集成逻辑,使开发人员能够非常直观地调用它。
微调方法
为了可视化微调BAAI/big-small-en所涉及的主要任务,让我们看看下图:
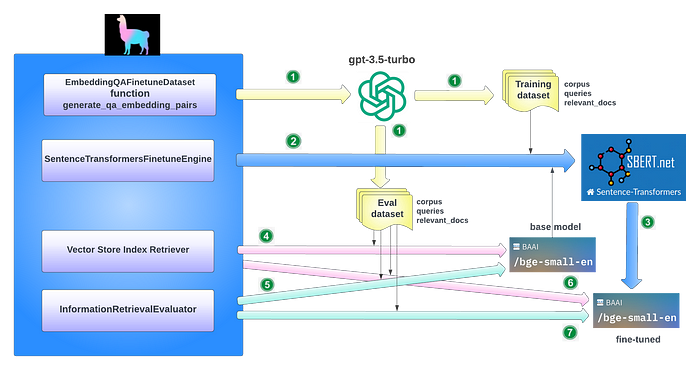
如图中的数值所示,主要任务包括:
- 通过调用
EmbeddingQAFinetuneDataset函数generate_qa_embedding_pairs,自动生成评估和训练数据集的数据。 - 通过传入基本模型和训练数据集来构造
SentenceTransformersFinetuneEngine,然后调用其finetune函数来训练基本模型。 - 创建经过微调的模型。
- 调用向量存储索引检索器检索相关节点并评估基本模型的命中率。
- 调用
InformationRetrievalEvaluator来评估基本模型。 - 调用向量存储索引检索器检索相关节点并评估微调模型的命中率。
- 调用
InformationRetrievalEvaluator来评估经过微调的模型。
基于LlamaIndex的微调Embeddings指南(文末有链接),我们将在我们的用例中微调bge-small-en模型。
实现细节
Step 1: 生成数据集
让我们使用LLM来自动生成训练和评估的数据集。
- Load corpus
在我们的用例中NVIDIA的SEC 10-K文件(代码中和文末都有链接)是一个169页的PDF文档(你可以用你自己的中文PDF),所以我们需要在生成数据集时将文档分成两部分——一部分用于训练数据集,另一部分用于evalals数据集。
使用单独的数据集进行训练和评估被认为是一种很好的ML实践。可以调用load_corpus函数来收集训练数据集(前90页)或eval数据集(其余页面)的节点。下面是load_corpus的代码片段:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | !curl https://d18rn0p25nwr6d.cloudfront.net/CIK-0001045810/4e9abe7b-fdc7-4cd2-8487-dc3a99f30e98.pdf --output nvidia-sec-10k-2022.pdf
def load_corpus(docs, for_training=False, verbose=False):
parser = SimpleNodeParser.from_defaults()
if for_training:
nodes = parser.get_nodes_from_documents(docs[:90], show_progress=verbose)
else:
nodes = parser.get_nodes_from_documents(docs[91:], show_progress=verbose)
if verbose:
print(f'Parsed {len(nodes)} nodes')
return nodes
SEC_FILE = ['nvidia-sec-10k-2022.pdf']
print(f"Loading files {SEC_FILE}")
reader = SimpleDirectoryReader(input_files=SEC_FILE)
docs = reader.load_data()
print(f'Loaded {len(docs)} docs')
train_nodes = load_corpus(docs, for_training=True, verbose=True)
val_nodes = load_corpus(docs, for_training=False, verbose=True)
|
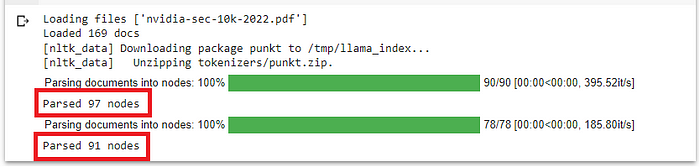
请记住,在LlamaIndex中,节点和页面并不完全匹配。对于一个169页的文档,结果显示它为训练数据集解析了97个节点,为evals数据集解析了91个节点。这两个数据集的节点数量足够接近。让我们继续。
- 生成合成查询和数据集
现在,让我们生成训练和评估的数据集。请注意,我们这里没有传递LLM (gpt-3.5-turbo-0613),只有OpenAI API密钥。这是因为LlamaIndex的默认LLM是gpt-3.5-turbo-0613;如果没有定义LLM,只要提供OpenAI API密钥,则默认为它。
generate_qa_embedding_pairs是一个生成数据集的方便函数。基于上面load_corpus函数返回的节点,它为每个节点生成问题(默认为每个节点两个问题,可以自定义),然后用所有三组数据构建数据集:queries,corpus和relevant_docs(queries与corpus之间的映射对应的node_id)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | from llama_index.finetuning import (
generate_qa_embedding_pairs,
EmbeddingQAFinetuneDataset,
)
from llama_index.llms import OpenAI
os.environ["OPENAI_API_KEY"] = "sk-############"
openai.api_key = os.environ["OPENAI_API_KEY"]
train_dataset = generate_qa_embedding_pairs(train_nodes)
val_dataset = generate_qa_embedding_pairs(val_nodes)
train_dataset.save_json("train_dataset.json")
val_dataset.save_json("val_dataset.json")
train_dataset = EmbeddingQAFinetuneDataset.from_json("train_dataset.json")
val_dataset = EmbeddingQAFinetuneDataset.from_json("val_dataset.json")
|
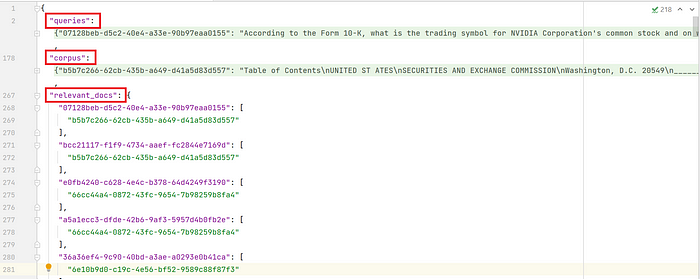
下面是样本训练数据集的样子。注意queries和corpus在截图中是折叠的,因为每个都有超过100个数据对:
Step 2: 微调Embedding模型
SentenceTransformersFinetuneEngine就是为这个任务设计的。在底层,它执行多个子任务:
- 通过构建
SentenceTransformer加载预训练模型,传入BAAI/big-small-en模型id。 - 定义数据加载器。它加载我们的训练数据集,将其解析为
查询,语料库和relevant_docs。然后循环查询,将relevant_docs中的node_id与corpus中的文本节点进行映射,构造InputExample,其列表依次传递到创建DataLoader中. - 定义loss(损失函数)。它使用
sentence_transformersmultiplenegativerankingloss来训练检索设置的Embeddings。 - 定义评估器。它设置了一个带有eval数据集的评估器来监控Embedding模型在训练期间的表现。
- 运行训练。它插入上面定义的数据加载器、损失函数和评估器来运行训练。
LlamaIndex将微调Embedding模型的所有详细子任务封装在一个SentenceTransformersFinetuneEngine中,我们所需要做的就是调用它的finetune函数。下面,您可以看到展示LlamaIndex的代码片段:
1 2 3 4 5 6 7 8 9 10 11 12 | from llama_index.finetuning import SentenceTransformersFinetuneEngine
finetune_engine = SentenceTransformersFinetuneEngine(
train_dataset,
model_id="BAAI/bge-small-en",
model_output_path="test_model",
val_dataset=val_dataset,
)
finetune_engine.finetune()
embed_model = finetune_engine.get_finetuned_model()
|
Step 3: 评估微调后的模型
如上所述,我们使用两种不同的评估方法:
-
命中率:对每个
query/relevant_doc对进行简单的top-k检索。如果搜索结果包含relevant_doc,那么它就是一个“命中”。这可以用于专有的Embeddings,例如OpenAI的Embedding模型和开源Embedding模型。请参阅下面代码片段中的evaluate函数。 -
InformationRetrievalEvaluator:一个更全面的用于评估开源Embeddings的度量套件。请参阅下面代码片段中的evaluate_st函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 | from llama_index.embeddings import OpenAIEmbedding
from llama_index import ServiceContext, VectorStoreIndex
from llama_index.schema import TextNode
from tqdm.notebook import tqdm
import pandas as pd
# function for hit rate evals
def evaluate(
dataset,
embed_model,
top_k=5,
verbose=False,
):
corpus = dataset.corpus
queries = dataset.queries
relevant_docs = dataset.relevant_docs
service_context = ServiceContext.from_defaults(embed_model=embed_model)
nodes = [TextNode(id_=id_, text=text) for id_, text in corpus.items()]
index = VectorStoreIndex(nodes, service_context=service_context, show_progress=True)
retriever = index.as_retriever(similarity_top_k=top_k)
eval_results = []
for query_id, query in tqdm(queries.items()):
retrieved_nodes = retriever.retrieve(query)
retrieved_ids = [node.node.node_id for node in retrieved_nodes]
expected_id = relevant_docs[query_id][0]
is_hit = expected_id in retrieved_ids # assume 1 relevant doc
eval_result = {
"is_hit": is_hit,
"retrieved": retrieved_ids,
"expected": expected_id,
"query": query_id,
}
eval_results.append(eval_result)
return eval_results
from sentence_transformers.evaluation import InformationRetrievalEvaluator
from sentence_transformers import SentenceTransformer
def evaluate_st(
dataset,
model_id,
name,
):
corpus = dataset.corpus
queries = dataset.queries
relevant_docs = dataset.relevant_docs
evaluator = InformationRetrievalEvaluator(queries, corpus, relevant_docs, name=name)
model = SentenceTransformer(model_id)
return evaluator(model, output_path="results/")
|
- 评测OpenAI
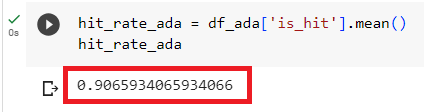
现在,让我们评估一下OpenAI的Embedding模型text-embedding-ada-002。代码如下:
1 2 3 4 5 6 | ada = OpenAIEmbedding() ada_val_results = evaluate(val_dataset, ada) df_ada = pd.DataFrame(ada_val_results) hit_rate_ada = df_ada['is_hit'].mean() |
结果:
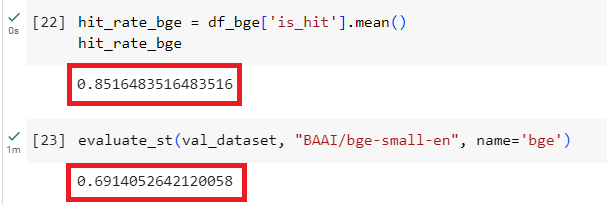
- 评测
BAAI/bge-small-en
1 2 3 4 5 6 7 8 | bge = "local:BAAI/bge-small-en" bge_val_results = evaluate(val_dataset, bge) df_bge = pd.DataFrame(bge_val_results) hit_rate_bge = df_bge['is_hit'].mean() evaluate_st(val_dataset, "BAAI/bge-small-en", name='bge') |
结果:
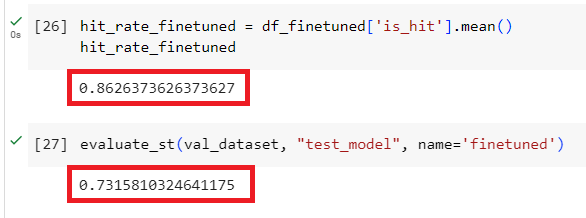
- 评估微调后的model
1 2 3 4 5 6 7 8 | finetuned = "local:test_model" val_results_finetuned = evaluate(val_dataset, finetuned) df_finetuned = pd.DataFrame(val_results_finetuned) hit_rate_finetuned = df_finetuned['is_hit'].mean() evaluate_st(val_dataset, "test_model", name='finetuned') |
查看结果:
- Summary of results
把评测结果放在一起,让我们仔细看看。
命中率:我们的微调模型比其基本模型bge-small-en的性能提高了1.29%。与OpenAI的Embedding模型相比,我们的微调模型的性能仅低了4.85%。
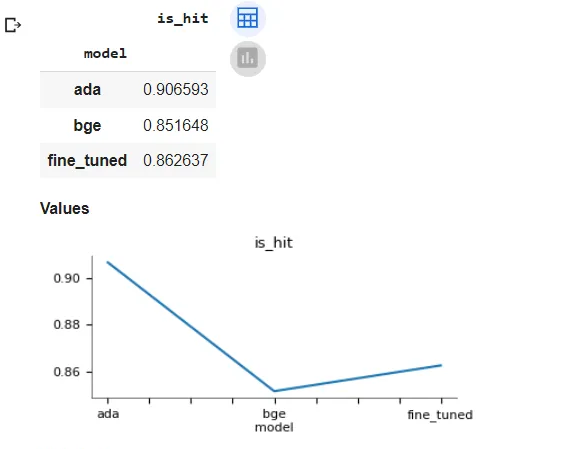
InformationRetrievalEvaluator结果:经过微调的模型比其基本模型的性能提高了5.81%。与基本模型相比,微调模型对这30多个指标列中的每一个都有更好的数字。

总结
在本文中,我们探讨了微调RAG管道的Embedding模型所涉及的步骤。我们使用开源的sentence_transformers模型BAAI/big-small-en作为我们的基本Embedding模型,介绍了如何生成用于训练和评估的数据集,如何对其进行微调,以及如何评估基本模型和微调模型之间的性能差异。
评估结果表明,微调Embedding模型的性能比基本模型提高了1-6%,与OpenAI的Embedding模型相比,微调模型的性能损失仅为4.85%。这种性能提升可能因数据集的质量和数量而异。
我们还简要探讨了LlamaIndex的最新版本,该版本对任何Embedding模型的线性适配器进行了微调,从而提高了性能并避免了在RAG管道中重新嵌入文档。
引用
- LlamaIndex的Finetune Embeddings指南:https://www.wpsshop.cn/w/不正经/article/detail/499387

