
- 1Centos7安装RabbitMQ最新版3.8.5,史上最简单实用安装步骤_centos7 rabbitmq3.8.5安装
- 2SQL Server 新建登录名以及用户授权_sql server 登录
- 3关于stc89c52驱动舵机代码_stc89c52控制舵机
- 4玩转MySQL:如何正确应用索引_如何关闭 index skip scan扫描
- 5一步一步实现STM32-FOTA系列教程之BIN文件解包_fota bin
- 6如何使用 Docker 来安装 ONLYOFFICE Workspace 12.0?
- 7latex自定义参考文献_latex 参考文献
- 8Pod控制器应用进阶三_container image already present on machine
- 9【网络原理】网络通信,网络协议,协议分层,网络设备的分层,封装和分用
- 10探索XQuartz:Mac OS上的开源X窗口系统
Mamba论文笔记
赞
踩
结合序列建模任务通俗地解释什么是状态空间模型?
状态空间模型(State Space Model, SSM)是一种数学模型,它可以用来描述一个系统在时间序列上如何演化。在序列建模任务中,状态空间模型通常用来预测或分析一系列时间点上的观测数据。想象你在看一部电影,电影中的每一帧都可以看作是一个观测点,而整部电影就是一个序列。状态空间模型就好比一个导演,根据电影的情节来决定下一帧画面应该是什么样子。
具体到状态空间模型,它包含两个主要部分:
-
状态(State):在我们的电影比喻中,状态好比是隐藏在幕后的故事线,它包含了电影情节的核心信息,但观众并不能直接看到。在实际的序列建模中,状态通常是无法直接观察到的,但它包含了系统过去和现在的所有重要信息,能够用来预测未来的行为。
-
观测(Observation):这就像电影的每一帧画面,是我们可以直接看到的。在序列建模任务中,观测是我们能够测量和记录下来的数据。
状态空间模型的一个关键特点是它描述了状态之间的转换(也就是从一帧到下一帧电影情节的转变),以及如何从状态产生观测(即如何将故事情节转化为观众可以看到的画面)。通常,这两个过程都通过数学方程来描述。
例如,在天气预测中,模型的状态可能包含温度、湿度和气压等因素,而我们的观测可能就是实际的温度记录。状态空间模型会告诉我们基于当前的温度、湿度和气压,未来的温度可能是多少。
在选择性状态空间模型中,这个模型变得更加智能,它可以根据当前输入的具体内容(比如,如果今天是阴天,那么模型会考虑这一点来预测明天的天气),来调整它预测未来的方式。这种选择性使模型能够更好地应对复杂或者非常长的序列,比如一系列复杂的天气变化。
创新点和贡献
这篇论文提出了一种名为"Mamba"的新型序列建模架构,它基于选择性状态空间模型(Selective State Space Models, SSMs)。这项工作的主要创新点和贡献包括:
-
选择性状态空间模型(SSM):论文中提出了一种新的状态空间模型,通过让SSM参数成为输入的函数,允许模型根据输入内容选择性地传播或遗忘信息。这一改变解决了以往状态空间模型在处理离散数据时效率低下的问题。
-
硬件感知算法:为了适应新的选择性SSM,作者设计了一种硬件感知的并行算法。这种算法采用递归模式,优化了GPU内存层级之间的数据访问,提高了计算效率。
-
简化的神经网络架构:Mamba模型简化了以往深度序列模型架构,将SSM与传统的MLP(多层感知机)块结合,形成一个统一的结构块。这种简化的设计有助于提高模型的训练和推理速度。
-
实验验证:Mamba模型在多种数据模态上(如语言、音频和基因组数据)达到了最先进的性能。特别是在语言建模方面,Mamba模型在预训练和下游任务评估中均显示出优越的性能,处理速度比同等规模的Transformer模型快5倍,且在序列长度线性扩展方面表现出色。
类比而言,选择性状态空间模型(Selective State Space Model, SSM)可以在某种程度上类比为一种广义的注意力机制。
信息选择:
- 注意力机制通过计算注意力分数来选择性地“关注”序列中的某些部分。高注意力分数的位置对输出的影响更大。
- 选择性SSM通过其参数化的变换(如根据输入动态调整的参数)来选择性地处理信息,选择哪些信息传递到下一状态。
长距离依赖:
- 注意力机制(自注意力)能够直接模型输入序列中任意两点之间的关系,无论它们之间的距离有多远,这有助于捕获长距离依赖关系。
- 选择性SSM同样旨在捕获长距离依赖关系,但不是通过权重分配,而是通过状态空间的动态特性和递归计算来实现。
计算效率:
- 传统的注意力机制具有二次复杂度,因为它需要计算序列中所有元素对的注意力分数。
- 选择性SSM旨在提供更高的计算效率,具有线性时间复杂度,使得模型能够高效处理长序列。
参数化:
- 注意力机制通常依赖于输入的内容(通过Query和Key的点积)来计算权重。
- 选择性SSM通过使模型参数(如状态转移矩阵)成为输入的函数,实现了对输入内容的参数化处理。
总的来说,注意力机制通过显式的权重分配进行选择性处理,而选择性SSM通过状态空间的动态调整来实现相似的目标。虽然两者的机制不同,但都旨在提高模型对序列数据中重要信息的识别和处理能力,特别是在处理需要长期依赖的复杂序列时。选择性SSM可以被视为一种新的机制,它提供了类似于注意力机制的功能,但以不同的方式实现和优化。
这些创新使得Mamba模型在处理长序列数据时更加高效,并在多个任务和领域中展示了其强大的建模能力。
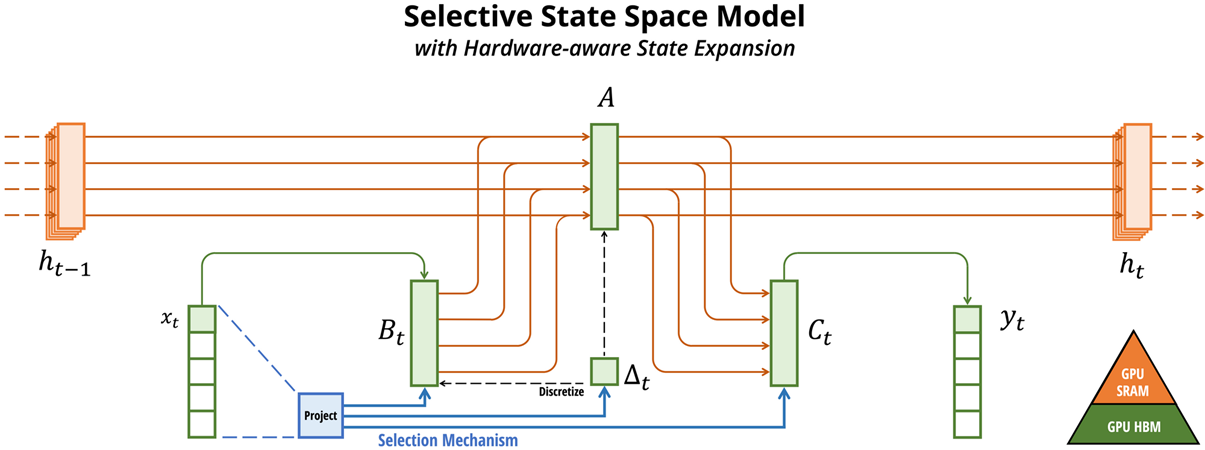
这张图展示了选择性状态空间模型(Selective State Space Model)的计算框架及其与硬件的交互。具体来说,它描述了一个时刻
t
t
t的状态转换过程,以及如何通过选择机制和硬件感知状态扩展来增强模型的性能。下面详细解释每个部分:
- x t x_t xt:当前时刻的输入。
- h t − 1 h_{t-1} ht−1:前一个时刻的隐藏状态。
- 投影(Project):这表明输入 x t x_t xt通过一个线性变换或投影层,为选择机制做准备。
- 选择机制(Selection Mechanism):基于当前输入的内容,动态决定状态空间模型的参数。这里特别标注了 B t B_t Bt和 C t C_t Ct,表示这些参数是输入依赖的。
- 离散化(Discretize):连续状态空间的参数通过离散化转换为可以在数字计算中使用的形式。
- Δ t \Delta_t Δt:当前时刻的时间间隔参数,它也可以基于输入动态调整。
- 矩阵 A A A:在状态空间模型中, A A A矩阵代表了隐藏状态的转换逻辑。
- h t h_t ht:当前时刻更新后的隐藏状态。
- y t y_t yt:由当前隐藏状态 h t h_t ht经过输出投影得到的输出。
- GPU SRAM与GPU HBM:这代表了模型的两个不同的硬件存储层级,SRAM是高速缓存存储,而HBM是高带宽内存。图示说明了状态扩展是如何利用不同级别的内存来优化计算效率的。
总体而言,这张图描绘了一个选择性状态空间模型在一个时间步的操作流程,并特别强调了模型如何根据输入内容调整其参数,以及计算是如何在硬件的不同内存层次中进行优化的。这种选择性机制和硬件感知的设计是Mamba架构的核心特色,它能够在处理长序列时提供计算上的优势。
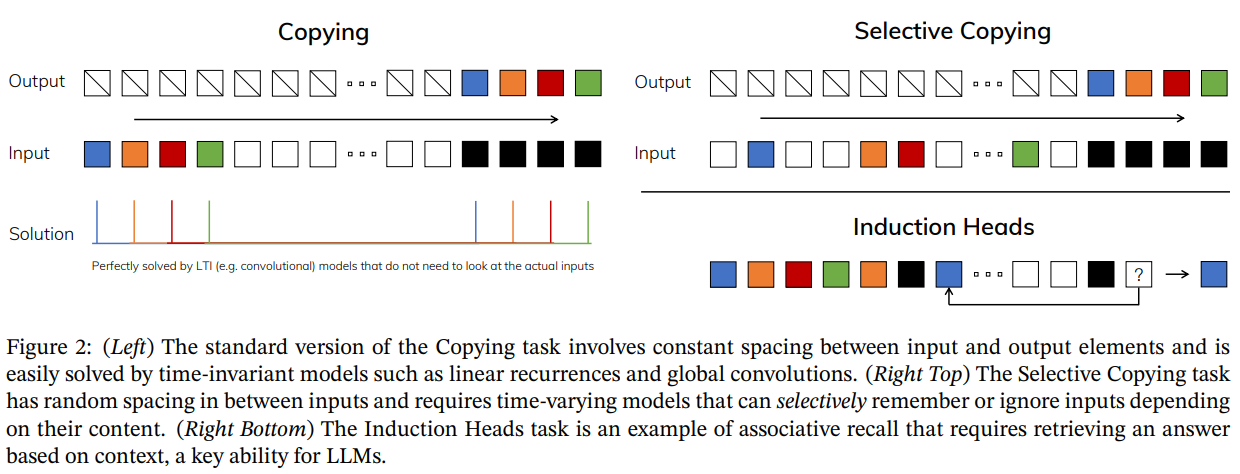
这张图展示了三个不同的序列建模任务,以及它们各自的解决方案:
-
复制(Copying)任务(左侧):
- 输入:一系列不同颜色的方块表示的是输入序列,白色方块表示待复制的序列的开始和结束。
- 输出:白色方块后是一系列的空白,然后是与输入序列相同颜色顺序的方块。
- 解决方案:这个任务通常可以被线性时不变模型(如线性递归和全局卷积模型)轻松解决,因为它们不需要查看实际的输入内容,只需根据时间间隔进行复制。
-
选择性复制(Selective Copying)任务(右上角):
- 输入:类似于复制任务,但输入序列之间的空白间隔是随机的。
- 输出:模型必须选择性地记住或忽略输入,具体取决于它们的内容,并正确地在输出序列中复制这些颜色。
- 解决方案:这个任务要求模型拥有时变特性,能够基于内容选择性记忆,因此传统的线性时不变模型在这里不再适用。
-
归纳头(Induction Heads)任务(右下角):
- 输入:一系列不同颜色的方块,其间隔为白色方块。
- 输出:模型需要在见到输入序列中特定的颜色方块之后,预测下一个颜色(例如,在图中,蓝色方块之后应该是什么颜色?)。
- 解决方案:这个任务是关联记忆的一个例子,它要求模型基于上下文检索答案,这是大型语言模型(LLMs)的关键能力。
总结来说,这三个任务展示了不同类型的序列处理能力:复制任务检测模型是否能简单地复制序列,选择性复制任务检验模型是否能基于输入内容做出决策,而归纳头任务测试模型是否能利用上下文来进行关联推理。论文通过这些任务来说明其提出的模型能够有效地处理复杂的序列建模问题,尤其是在内容选择和上下文推理方面。
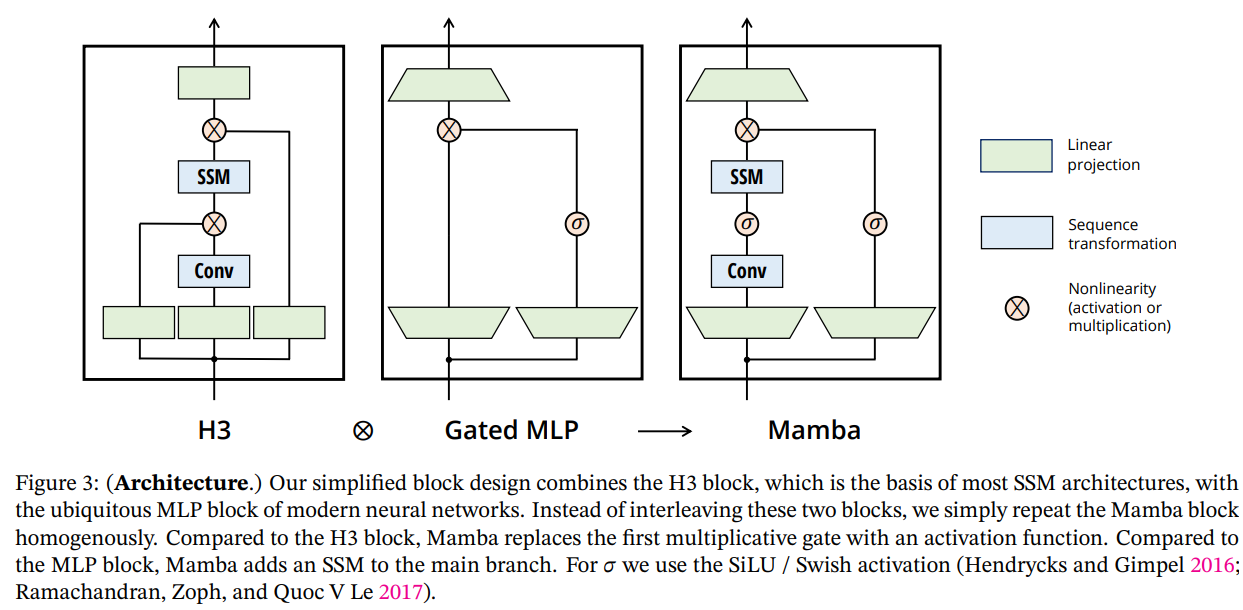
这张图比较了三种不同的神经网络块结构,它们是在处理序列数据时使用的常见构件。
-
H3结构:H3是一种基于状态空间模型(State Space Model, SSM)的神经网络块结构,它包括一个SSM层和一个卷积层(Conv),以及两个乘法门控操作(表示为圆圈中的x)。底部的盒子代表MLP块,它在每个块的最底部进行非线性变换。
-
门控MLP(Gated MLP):这是一种变体,它通过在MLP之前增加一个门控单元来增强模型的非线性处理能力。门控操作由一个圆圈和一个sigma符号(σ)表示,通常是一个非线性激活函数。
-
Mamba结构:这是文章提出的新结构,与H3相比,它去掉了第一个乘法门控,并引入了一个额外的SSM层。Mamba结构的一个关键特点是它在MLP块之间重复使用相同的Mamba块,简化了整体的网络架构设计。此外,Mamba使用SiLU/Swish激活函数作为非线性操作,这是一种在神经网络中常用的激活函数。
图中所示的每个块都有以下共同部分:
- 线性投影:对输入数据进行线性变换。
- 序列变换:由SSM或卷积层执行的对序列的操作。
- 非线性变换:通过激活函数或乘法门控实现的非线性处理。
整个图解释了Mamba结构是如何通过简化和优化块结构来提高处理效率,以及如何通过重复使用块结构来简化网络的设计,这使得Mamba能够在长序列数据建模任务中获得更好的性能。
为什么Mamba模型擅长捕获long range dependencies?
Mamba模型擅长捕获长期依赖(long-range dependencies),主要是因为它采用了选择性状态空间模型(SSM),这种模型具有以下特性,使其能够有效处理长序列数据:
-
参数化的状态传递:在Mamba模型中,状态空间的参数是可变的,可以根据输入序列的内容动态调整。这意味着模型可以根据当前的输入决定如何传递或遗忘过去的信息。相比固定参数的传统RNN或LSTM,这种动态性允许模型更灵活地处理长期依赖。
-
线性时间复杂度:Mamba通过选择性SSM在计算上实现线性时间复杂度,这允许它在长序列上运行而不会遭遇传统注意力机制中的二次复杂度问题。因此,模型能够在不牺牲性能的前提下处理更长的序列。
-
硬件感知计算:选择性SSM通过利用GPU的内存层次结构,高效地进行计算,确保状态扩展和序列转换在不同层次的内存之间有效运行。这种计算方式使得Mamba可以快速处理长序列,同时减少了内存消耗。
-
有效的状态管理:Mamba模型的设计允许它有效地管理状态,即选择性地记住和忘记信息。对于长序列数据,模型可以通过这种状态管理来维持和利用重要的历史信息,同时丢弃不相关或冗余的内容。
这些特性综合起来,使得Mamba模型在处理需要考虑长时间步内依赖关系的任务,如文本处理、音频信号处理和时间序列分析等方面表现出色。通过对长期信息进行有效管理和利用,Mamba能够在复杂的序列建模任务中捕获关键的上下文信息,并提高预测的准确性。
Transformer 模型的复杂的是 O ( n 2 ) O(n^2) O(n2) 很容易理解,为什么 Mamba 模型的复杂度是线性的?


