
- 1【2023最新版】MySQL安装教程_mysql最新版安装教程
- 2100种分析思维模型(5)
- 3关于成功得因素
- 4基于树莓派Qt+opencv+yolov5-Lite+C++部署深度学习推理_树莓派可以搭载深度学习模块么
- 5让 Android 应用在 Chrome 浏览器上运行_浏览器运行apk
- 6考研踩坑经验分享
- 7android webview js 声音,Android WebViewJSBridge分析
- 8数据结构-(Map和Set)超详细_set 和 map 数据结构
- 9Stable Diffusion Windows本地部署超详细教程(手动+自动+整合包三种方式)_stable diffusion windows 部署
- 10电子班牌系统服务器,智慧校园电子班牌系统解决方案
【论文笔记】Mamba: Linear-Time Sequence Modeling with Selective State Spaces_mamba arxiv
赞
踩
原文链接:https://arxiv.org/abs/2312.00752
1. 引言
基石模型(FM)的主干网络通常是序列模型,处理任意的输入序列。但现代FM主要基于Transformer这一序列模型,及其核心的注意力。但是,自注意力仅能在上下文窗口中密集地传递信息,而无法建模窗口外部的数据;此外,其尺度与窗口长度成二次方关系。注意力相关高效的改进牺牲了其有效性,因此也未被有效地用于不同领域。
最近,结构状态空间序列模型(SSM)作为序列建模的有前景方法,可被理解为RNN与CNN的结合,并受经典状态空间模型的启发。这类模型能高效计算,且尺度与序列长度成比例关系。此外,在部分模态下,还可建模长距离依赖关系,且在连续信号(如音频与视觉)下取得了成功。但对于离散且信息密集的数据(如文本)则不那么有效。
本文提出选择性状态空间模型,在前面的工作上做出改进,达到Transformer的建模能力,且尺度随序列长度线性增大。
选择机制:过去的方法缺乏以数据依赖的方式高效选择数据的能力(关注或忽视特定输入)。本文通过将SSM的参数基于输入参数化,设计选择机制,使模型过滤无关信息并记忆相关信息。
硬件感知的算法:所有之前的SSM需要是时不变和输入不变的,以高效计算。本文使用硬件感知的算法来克服这一问题,递归地使用扫描而非卷积计算模型,且不实现扩展状态以避免在GPU内存层次结构的不同层进行IO访问。这样,实施速度在理论上和现代硬件上均能超过过去的方法(伪线性时间)。
结构:本文将之前的SSM结构与Transformer的MLP组合为块(Manba),一种包含了选择性状态空间的简单而同质的结构设计。
选择性SSM与其扩展Manba均为完全递归的模型,适合作为以序列为输入的通用基石模型的主干网络。其关键属性为:
- 高质量:选择性能为密集模态(语言、基因组)带来强性能;
- 快速训练和推断:训练时的计算与存储尺度均随序列长度线性变化,推断时自回归地展开模型使得每步只需常数时间,因为无需过去元素的缓存。
- 长上下文:质量与效率使其能在1M长度序列上产生性能提升。
在语言、音频、基因组等领域上的实验表明,Mamba只需更少的参数量就能达到Transformer相同的性能,且速度更快。
2. 状态空间模型
结构状态空间模型(S4)与RNN、CNN以及经典状态空间模型相关。其受到特定连续系统的启发,该连续系统通过隐状态 h ( t ) ∈ R N h(t)\in\mathbb R^N h(t)∈RN映射1维函数或序列 x ( t ) ∈ R → y ( t ) ∈ R x(t)\in\mathbb R\rightarrow y(t)\in\mathbb R x(t)∈R→y(t)∈R。
S4模型由4个参数定义(
Δ
,
A
,
B
,
C
\Delta,A,B,C
Δ,A,B,C),包含序列到序列的两阶段变换(式(1)):
h
′
(
t
)
=
A
h
(
t
)
+
B
x
(
t
)
(
1
a
)
h
t
=
A
ˉ
h
t
−
1
+
B
ˉ
x
t
(
2
a
)
K
ˉ
=
(
C
B
ˉ
,
C
A
ˉ
B
ˉ
,
⋯
,
C
A
ˉ
k
B
ˉ
,
⋯
)
(
3
a
)
y
(
t
)
=
C
h
(
t
)
(
1
b
)
y
t
=
C
h
t
(
2
b
)
y
=
x
∗
K
ˉ
(
3
b
)
离散化:第一阶段通过固定公式
A
ˉ
=
f
A
(
Δ
,
A
)
,
B
ˉ
=
f
B
(
Δ
,
A
,
B
)
\bar A=f_A(\Delta,A),\bar B=f_B(\Delta,A,B)
Aˉ=fA(Δ,A),Bˉ=fB(Δ,A,B),将连续参数(
Δ
,
A
,
B
\Delta,A,B
Δ,A,B)转化为离散参数(
Δ
,
A
ˉ
,
B
ˉ
\Delta,\bar A,\bar B
Δ,Aˉ,Bˉ)。其中
f
A
,
f
B
f_A,f_B
fA,fB被称为离散规则。例如,零阶保持(ZOH)由下式定义:
A
ˉ
=
exp
(
Δ
A
)
,
B
ˉ
=
(
Δ
A
)
−
1
(
exp
(
Δ
A
)
−
I
)
⋅
Δ
B
\bar A=\exp(\Delta A),\bar B=(\Delta A)^{-1}(\exp (\Delta A)-I)\cdot\Delta B
Aˉ=exp(ΔA),Bˉ=(ΔA)−1(exp(ΔA)−I)⋅ΔB
离散化可为连续时间系统赋予额外特性,如分辨率不变性或保证模型被恰当地归一化。同时,离散化也与RNN的门控机制有关(见3.5节)。离散化可被简单地视为SSM前向过程计算图的第一步。一些类型的SSM可以直接参数化 ( A ˉ , B ˉ ) (\bar A,\bar B) (Aˉ,Bˉ),而绕过离散化步骤。
计算:得到离散化的模型后,可通过线性递归(式(2))或全局卷积(式(3))方式计算。通常会使用卷积模式进行并行训练(可一次获取整个序列),然后切换为递归模式进行自回归推断(一次只能获取一个时间步长的数据)。
线性时不变(LTI):式(1)(2)(3)的特点是模型动态随时间恒定,即 Δ , A , B , C \Delta,A,B,C Δ,A,B,C与 A ˉ , B ˉ \bar A,\bar B Aˉ,Bˉ恒定,称为LTI。LTI SSM与任何线性递归或卷积等价,因此可将LTI视为这些模型的总括术语。
目前位置,由于效率限制,所有的结构SSM均为LTI的(如通过卷积计算)。LTI模型在特定类型的数据上有局限性,本文则移除这一约束并克服效率瓶颈。
结构与维度:结构SSM需要强制矩阵 A A A的结构,如对角矩阵。这样 A ∈ R N × N , B ∈ R N × 1 , C ∈ R 1 × N A\in\mathbb R^{N\times N},B\in\mathbb R^{N\times1},C\in\mathbb R^{1\times N} A∈RN×N,B∈RN×1,C∈R1×N均可由 N N N个数表达。若输入序列 x x x的批量大小为 B B B,长度为 L L L,通道数为 D D D,则会对每个通道独立应用SSM。此时,总的隐状态维度为 D N DN DN,整个序列的计算需要 O ( B L D N ) O(BLDN) O(BLDN)的时间与存储。
通用状态空间模型:状态空间可以表达任何带有隐状态的递归过程,如马尔科夫决策过程、动态因果建模、卡尔曼滤波器、隐马尔科夫模型、线性动态系统、递归模型等。
SSM的结构:SSM可合并到端到端神经网络架构中。如线性注意力(含递归的自注意力近似,可视为退化线性SSM)、H3(门控连接之间加SSM,或在SSM层前加卷积)、Hyena(将H3的S4替换为MLP参数化的全局卷积)、RetNet(添加额外门控并使用更简单的SSM,使用多头注意力的变体而非卷积从而可并行计算)、RWKV(基于另一线性注意力近似的RNN,包含LTId递归,可视为两个SSM之比)。
3. 选择性状态空间模型
3.1 动机:选择为一种压缩方式
序列建模的基本问题是将上下文压缩为更小的状态。高效的模型需要小状态,而有效的模型需要包含上下文所有必要信息的状态。Transformer没有压缩上下文,因此是有效但低效的;递归模型有有限状态,是高效的,但其有效性受到上下文压缩程度的限制。
合成任务中的选择性复制与归纳头均需要内容感知的推理,这说明了LTI模型的缺陷。从递归角度看,其常数动态( A ˉ , B ˉ \bar A,\bar B Aˉ,Bˉ)不能使其选择上下文中正确的信息,或以输入依赖的方式影响隐状态。从卷积角度看,静态卷积核不能建模变化的输入输出关系。
本文提出建立序列模型的基本原则是选择性(或上下文感知能力),能够关注或过滤输入,得到序列状态。选择机制可以控制信息沿序列维度的传播与交互。
3.2 使用选择改进SSM
为模型引入选择性的方法之一是将影响序列交互的参数(如RNN的递归动态或CNN的卷积核)改为输入依赖的。

为SSM(算法1)添加选择机制的算法如算法2所示。主要的改动为将
B
B
B与
C
C
C改为输入的函数,使其参数与时间相关(维度
L
L
L表明参数为时变的)。这使得SSM失去了与卷积的等价性。
本文设置 s B ( x ) = L i n e a r N ( x ) , s C ( x ) = L i n e a r N ( x ) , s Δ ( x ) = B r o a d c a s t D ( L i n e a r 1 ( x ) ) s_B(x)=\mathtt{Linear}_N(x),s_C(x)=\mathtt{Linear}_N(x),s_\Delta(x)=\mathtt{Broadcast}_D(\mathtt{Linear}_1(x)) sB(x)=LinearN(x),sC(x)=LinearN(x),sΔ(x)=BroadcastD(Linear1(x)), τ Δ = s o f t p l u s \tau_\Delta=\mathtt{softplus} τΔ=softplus。其中 L i n e a r d \mathtt{Linear}_d Lineard的输出维度为 d d d。
3.3 选择性SSM的高效实施
由于时变的SSM失去了卷积计算能力,因此其计算效率受到了影响。
3.3.1 过去模型的动机
- 尽管递归模式比卷积模式更为灵活,但需要计算大小为 ( B , L , D , N ) (B,L,D,N) (B,L,D,N)的隐状态 h h h。因此,往往采用更为高效的卷积模式,绕过隐状态计算,并设置大小为 ( B , L , D ) (B,L,D) (B,L,D)的卷积核。
- LTI SSM使用双循环-卷积形式, N N N倍地增加有效的状态维度,而不影响效率。
3.3.2 选择性扫描概述:硬件感知的状态扩展
本文使用三种经典技巧处理选择性SSM的效率问题:核融合,并行扫描和重计算。注意到:
- 递归计算的FLOP为 O ( B L D N ) O(BLDN) O(BLDN),而卷积计算为 O ( B L D log ( L ) ) O(BLD\log(L)) O(BLDlog(L)),且前者的常系数更小。因此长序列和不大的状态维度下,递归模式的FLOP更低。
- 递归的顺序性与大存储消耗为两大挑战。为解决后者,本文不计算完整状态 h h h。
由于多数操作(包括扫描)会受限于存储带宽,本文使用核融合以减小存储器IO的次数,从而进行加速。
具体来说,不在GPU的高带宽存储器(HBM)中加载大小为 ( B , L , D , N ) (B,L,D,N) (B,L,D,N)的扫描输入 ( A ˉ , B ˉ ) (\bar A,\bar B) (Aˉ,Bˉ),而直接从较慢的HBM加载SSM参数 ( Δ , A , B , C ) (\Delta,A,B,C) (Δ,A,B,C)到较快的SRAM中,并在SRAM中进行离散化与递归。最后将大小为 ( B , L , D ) (B,L,D) (B,L,D)的输出写入HBM。
为避免顺序递归,可以使用并行扫描算法进行并行化。
为避免存储反向传播时必要的中间状态,在反向传播时对其进行重计算。因此,融合的选择扫描层与用FlashAttention优化的Transformer有着相同的存储需求。
完整的选择性SSM层如下图所示。

3.4 简化的SSM结构
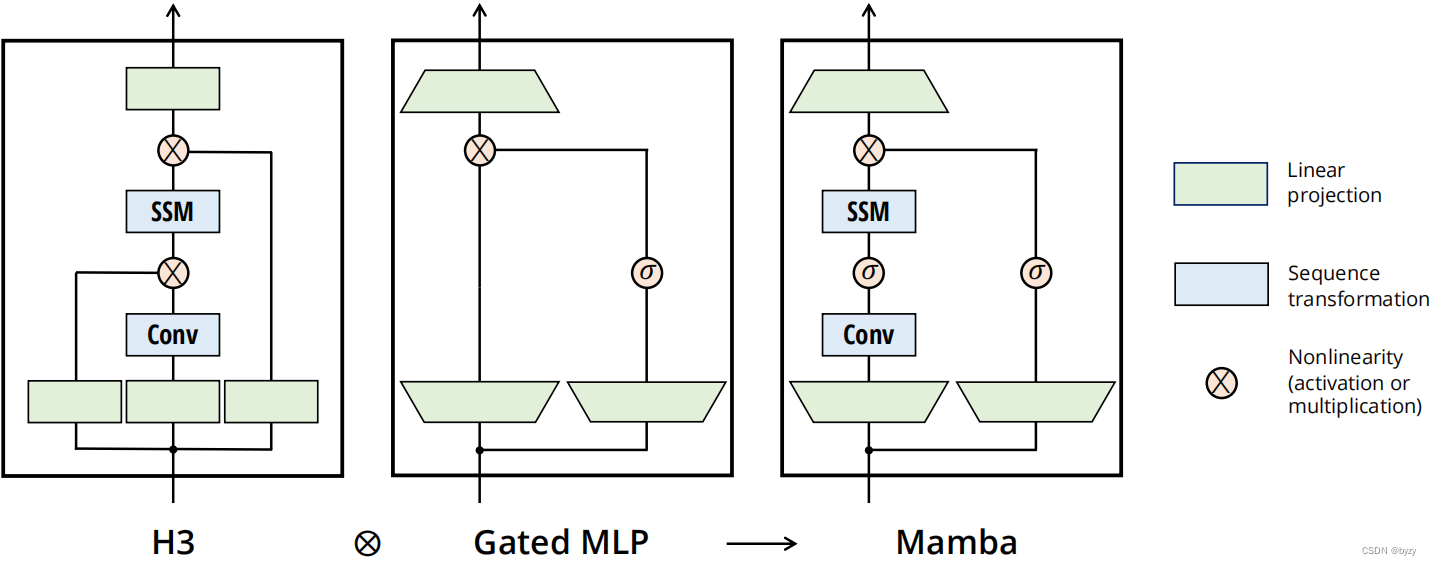
如图所示,本文将H3中的线性注意力与MLP合并。
首先,将模型维度 D D D乘以可控的扩张因子 E E E。此时,大多数参数位于线性投影层,SSM的参数占比很小。复制该块并插入标准归一化和残差连接,得到的Mamba。激活函数 σ \sigma σ使用SiLU或Swish。最后,额外使用可选的归一化层(LayerNorm)。
3.5 选择机制的特性
3.5.1 与门控机制的联系
RNN的经典门控机制是本文SSM选择性机制的实例。
3.5.2 选择机制的解释
可变间距:选择性使得模型可以跳过输入中的噪声token,这在各种模态中(尤其是离散模态)无处不在。
过滤上下文:尽管更多的上下文应该导致严格更高的性能,但许多序列模型在长上下文下并没有提升。这是因为它们不能忽略无关上下文(如全局卷积),而选择性模型可以在任何时刻重置状态,以删除无关的历史,因此性能可以随序列长度增加而单调递增。
边界重置:当多个独立序列被缝合时,Transformer可以通过注意力掩膜使其保持分离,而LTI模型会在各序列间传递信息。选择性SSM也可在边界处重置状态。
对 Δ \Delta Δ的理解: Δ \Delta Δ控制了对当前输入 x t x_t xt关注或忽略程度的平衡,其泛化了RNN的门控。大的 Δ \Delta Δ会重置状态 h h h并关注当前输入,而小的 Δ \Delta Δ则保留状态并忽视当前输入。SSM可视为按照时间步长 Δ \Delta Δ进行离散化, Δ → ∞ \Delta\rightarrow\infty Δ→∞表示系统关注当前输入而忽略其状态,而 Δ → 0 \Delta\rightarrow0 Δ→0则表明瞬态输入被忽略。
对 A A A的解释:尽管 A A A也可是选择性的,但 Δ \Delta Δ的选择性就可保证 A ˉ = exp ( Δ A ) \bar A=\exp(\Delta A) Aˉ=exp(ΔA)的选择性。
对 B B B与 C C C的理解:改变 B B B或 C C C,可以对输入 x t x_t xt是否影响状态 h t h_t ht或状态 h t h_t ht是否影响输出 y t y_t yt进行细粒度控制,即允许模型根据内容(输入)或上下文(隐状态)调节递归动态。
3.6 额外的模型细节
实数&复数:许多SSM使用复数状态 h h h以获取强性能,但某些设置下实数状态可能更好。这可能与数据模态相关,其中复数状态对连续模态有帮助,而实数状态对离散模态更好。
初始化:在复数(实数)情况下,本文使用S4D-Lin(S4D-Real)作为默认初始化方法,将 A A A的第 n n n个元素定义为 − 1 / 2 + n i -1/2+ni −1/2+ni( − ( n + 1 ) -(n+1) −(n+1))。
Δ \Delta Δ的参数化: Δ \Delta Δ被初始化为 τ Δ − 1 ( U n i f o r m ( [ 0.001 , 0.1 ] ) ) \tau_\Delta^{-1}(\mathtt{Uniform}([0.001,0.1])) τΔ−1(Uniform([0.001,0.1]))。此外,可将维度1泛化为更大的维度 R R R(设置为 D D D的因数),且将广播操作视为另一线性投影,从而得到 s Δ s_\Delta sΔ的另一形式: s Δ ( x ) = L i n e a r D ( L i n e a r R ( x ) ) s_\Delta(x)=\mathtt{Linear}_D(\mathtt{Linear}_R(x)) sΔ(x)=LinearD(LinearR(x))。
4. 经验评估
4.5 速度与存储基准
在长序列下,本文高效的SSM扫描比最快的注意力实施还快,且推断速度比同等大小的Transformer快很多。注意由于无需缓存 K V KV KV,因此Manba可以设置更大的批量大小。
4.6 模型消融
4.6.1 结构
- 过去LTI SSM的性能均相近。
- 将复数S4替换为实数,不会太影响性能,因为实数SSM可能是硬件高效的。
- 将上述任一方法替换为选择性SSM能极大地提高性能。
- Mamba的结构与H3的性能相近(当使用选择性层时,会略高)。
4.6.2 选择性SSM
考虑为 Δ , B , C \Delta,B,C Δ,B,C之间不同的组合添加选择性,实验表明 Δ \Delta Δ为最关键的参数,因其与RNN门控相关。
不同的SSM初始化方法在不同模态上的表现可能有较大差异。
增大 Δ , B , C \Delta,B,C Δ,B,C的维度,可以较小的参数量适中地增加性能。
增加状态大小 N N N可以极小的参数量极大地提高性能。

