
- 1第一章:大模型简介_3claude v1大模型的特点
- 2uniapp省市区3级联动组件_uniapp省市区三级联动插件
- 3测试循环结构经常踩坑?那些测试老司机们都这样处理~
- 4yolov5 结构知识点解析_yolov5模型结构
- 5测试人员如何体现自身的专业性?_你认为从哪些方面能体现测试工作专业度?
- 6如何判断自己的电脑里有没有cuda以及查看cuda版本_怎么看自己电脑显卡可不可以装cuda
- 7Android 编译环境搭建_google android编译环境清华镜像
- 8【STM32】--基于STM32最小系统点亮LED灯
- 92023年, 前端路上的开源总结(最新更新...)
- 10L1正则化和L2正则化比较_laplace regularizer
【Linux】Linux的管道_linux管道
赞
踩
管道是Linux由Unix那里继承过来的进程间的通信机制,它是Unix早期的一个重要通信机制。其思想是,在内存中创建一个共享文件,从而使通信双方利用这个共享文件来传递信息。由于这种方式具有单向传递数据的特点,所以这个作为传递消息的共享文件就叫做“管道”。
在管道的具体实现中,根据通信所使用的的文件是否具有名称,有“匿名管道”和“命名管道”。
管道与共享内存的区别
乍一看,感觉管道和共享内存并不是区别很大,这里介绍一下两者之间的区别:
- 管道需要在内核和用户空间进行四次的数据拷贝:由用户空间的buf中将数据拷贝到内核中 -> 内核将数据拷贝到内存中 -> 内存到内核 -> 内核到用户空间的buf。而共享内存则只拷贝两次数据:用户空间到内存 -> 内存到用户空间。
- 管道用循环队列实现,连续传送数据可以不限大小。共享内存每次传递数据大小是固定的;
- 共享内存可以随机访问被映射文件的任意位置,管道只能顺序读写;
- 管道可以独立完成数据的传递和通知机制,共享内存需要借助其他通讯方式进行消息传递。
也就是说,两者之间最大的区别就是: 共享内存区是最快的可用IPC形式,一旦这样的内存区映射到共享它的进程的地址空间,这些进程间数据的传递,就不再通过执行任何进入内核的系统调用来传递彼此的数据,节省了时间。
匿名管道
匿名管道是在具有公共祖先的进程之间进行通信的一种方式。
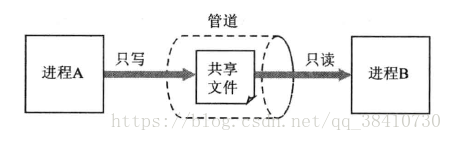
前面在介绍进程的创建时讲到,由父进程创建的子进程将会赋值父进程包括文件在内的一些资源。如果父进程创建子进程之前创建了一个文件,那么这个文件的描述符就会被父进程在随后所创建的子进程所共享。也就是说,父、子进程可以通过这个文件进行通信。如果通信的双方一方只能进行读操作,而另一方只能进行写操作,那么这个文件就是一个只能单方向传送消息的管道,如下图所示:
进程可以通过调用函数pipe()创建一个管道。函数pipe()的原型如下:
int pipe(int fildes[2]);与该函数pipe()相对应的系统调用sys_pipe()的原型如下:
asmlinkage int sys_pipe(unsigned long __user * fildes);从本质上来说,pipe()函数的功能就是创建一个内存文件,但与创建普通文件的函数不同,函数pipe()将在参数fildes中为进程返回这个文件的两个文件描述符fildes[0]和fildes[1]。其中,fildes[0]是一个具有“只读”属性的文件描述符,fildes[1]是一个具有“只写”属性的文件描述符,即进程通过fildes[0]只能进行文件的读操作,而通过fildes[1]只能进行文件的写操作。
这样,就使得这个文件像一段只能单向流通的管道一样,一头专门用来输入数据,另一头专门用来输出数据,所以称为管道。由于这种文件没有文件名,不能被非亲进程所打开,只能用于亲属进程间的通信,所以这种没有名称的文件形成的通信管道叫做“匿名管道”。
显然,如果父进程创建的这种文件只是用来通信,那么它感兴趣的只是该文件所占用的内存空间,所以也就没有必要创建一个正式文件,只需创建一个只存在于内存的临时文件。从这一点来看,匿名管道与共享内存具有共同点,只不过匿名管道时单向通信,而且这个通信只能在亲属进程间进行。
为支持匿名管道,内核初始化时由内核函数kernel_mount()安装了一种特殊的文件系统,在该系统中所创建的都是临时文件。
由于匿名管道是一个文件,所以它也有i节点,其结构如下:
- struct inode
- {
- ...
- struct file_operations *i_fop; //文件操作函数集
- struct pipe_inode_info *i_pipe; //管道文件指针
- ...
- };
可以看到,在i节点的结构中有一个pipe_inode_info类型的指针i_pipe,在普通文件中这个指针的值为NULL,而在管道文件中这个指针则只想一个叫做管道节点信息结构的pipe_inode_info,以表明这是一个管道文件。pipe_inode_info的结构如下:
- struct pipe_inode_info {
- wait_queue_head_t wait; //等待进程队列
- unsigned int nrbufs, curbuf;
- struct page *tmp_page;
- unsigned int readers;
- unsigned int writers;
- unsigned int waiting_writers;
- unsigned int r_counter; //以只读方式访问管道的进程计数器
- unsigned int w_counter; //以只写方式访问管道的进程计数器
- struct fasync_struct *fasync_readers;
- struct fasync_struct *fasync_writers;
- struct inode *inode;
- struct pipe_buffer bufs[PIPE_BUFFERS]; //缓冲区数组
- };
结构中的域bufs就是构成管道的内存缓冲区。该缓冲区用结构pipe_buffer来描述:
- struct pipe_buffer {
- struct page *page; //缓冲页的结构
- unsigned int offset, len;
- const struct pipe_buf_operations *ops; //缓冲区的操作函数集指针
- unsigned int flags;
- unsigned long private;
- };
从上面的数据结构中可以看到,管道实质上就是一个被当做文件来管理的内存缓冲区。
在创建一个管道的i节点时,结构inode中的域i_fop被赋予rdwr_pipefifo_fops,即管道文件本身是既可读又可写的。rdwr_pipefifo_fops在文件linux/fs/pipe.c中的定义如下:
- const struct file_operations rdwr_pipefifo_fops = {
- .llseek = no_llseek,
- .read = do_sync_read,
- .aio_read = pipe_read,
- .write = do_sync_write,
- .aio_write = pipe_write,
- .poll = pipe_poll,
- .unlocked_ioctl = pipe_ioctl,
- .open = pipe_rdwr_open,
- .release = pipe_rdwr_release,
- .fasync = pipe_rdwr_fasync,
- };
而为进程所创建的打开文件描述符fildes[0]和fildes[1]中的i_fop,则被分别赋予了只读的函数操作集read_pipefifo_fops和只写的函数操作集write_pipefifo_fops。
read_pipefifo_fops和write_pipefifo_fops这两个操作函数集在文件linux/fs/pipe.c中分别定义如下:
- const struct file_operations read_pipefifo_fops = {
- .llseek = no_llseek,
- .read = do_sync_read,
- .aio_read = pipe_read,
- .write = bad_pipe_w,
- .poll = pipe_poll,
- .unlocked_ioctl = pipe_ioctl,
- .open = pipe_read_open,
- .release = pipe_read_release,
- .fasync = pipe_read_fasync,
- };
-
- const struct file_operations write_pipefifo_fops = {
- .llseek = no_llseek,
- .read = bad_pipe_r,
- .write = do_sync_write,
- .aio_write = pipe_write,
- .poll = pipe_poll,
- .unlocked_ioctl = pipe_ioctl,
- .open = pipe_write_open,
- .release = pipe_write_release,
- .fasync = pipe_write_fasync,
- };

创建匿名管道的进程与管道之间的关系如下图所示:

当一个进程调用函数pipe()创建一个管道后,管道的连接方式如下所示:

从图中可以看到,由于管道的出入口都在同一个进程之中,这种管道没有多大的用途的。但是当这个进程在创建一个新进程之后,情况就变得大不一样了。
如果父进程创建一个管道之后,又创建了一个子进程,那么由于子进程继承了父进程的文件资源,于是管道在父子进程中的连接情况就变成如下图一样的情况了:

在确定管道的传输方向之后,在父进程中关闭(close())文件描述符fildes[0],在子进程中关闭(close())文件描述符fildes[1],于是管道的连接情况就变成如下情况的单向传输管道:

也可以想象,通过关闭文件描述符的方法,在两个兄弟进程之间也可以实现通信管道。
创建完管道之后,怎么利用管道来进行数据的通信呢?
管道使用read()和write()函数,采用字节流的方式,具有流动性,读数据时,每读一段数据,则管道内会清除已读走的数据。
- 读管道时,若管道为空,则被堵塞,直至管道另一端write将数据写入到管道为止。若写段已关闭,则返回0;
- 写管道时,若管道已满,则被阻塞,直到管道另一端read将管道内数据取走为止。
用close()函数,在创建管道时,写端需要关闭fildes[0]描述符,读端需要关闭fildes[1]描述符。当进程关闭前,每个进程需要将没有关闭的描述符都进行关闭。
匿名管道具有如下特点:
- 由于这种管道没有其他同步措施,所以为了不产生混乱,它只能是半双工的,即数据只能向一个方向流动。如果需要双方互相传递数据,则需要建立两个管道;
- 只能在父子进程或兄弟进程这些具有亲缘关系的进程之间进行通信;
- 匿名管道对于管道两端的进程而言,就是一个只存在于内存的特殊文件;
- 一个进程向管道中写的内容被管道另一端的进程读取。写入的内容每次都添加在管道缓冲区的末尾,并且每次都是从缓冲区的头部读取数据。
匿名管道的局限性主要有两点:一是由于管道建立在内存中,所以它的容量不可能很大;二是管道所传送的是无格式字节流,这就要求使用管道的双方实现必须对传输的数据格式进行约定。
例子:在父子进程之间利用匿名管道通信。
- #include <unist.h>
- #include <string.h>
- #include <wait.h>
- #include <stdio.h>
-
- #define MAX_LINE 80
-
- int main()
- {
- int testPipe[2], ret;
- char buf[MAX_LINE + 1];
- const char * testbuf = "主程序发送的数据";
-
- if (pipe(testbuf) == 0) {
- if (fork() == 0) {
- ret = read(testPipe[0], buf, MAX_LINE);
- buf[ret] = 0;
- printf("子程序读到的数据为:%s", buf);
- close(testPipe[0]);
- }else {
- ret = write(testPipe[1], testbuf, strlen(testbuf));
- ret = wait(NULL);
- close(testPipe[1]);
- }
- }
-
- return 0;
- }
命名管道
由于匿名管道没有名称,因此,它只能在一些具有亲缘关系的进程之间进行通信,这使它在应用方面受到极大的限制。
命名管道是在实际文件系统上实现的一种通信机制。由于它是一个与进程没有“血缘关系”的、真正且独立的文件,所以它可以在任意进程之间实现通信。由于命名管道不支持诸如lseek()等文件定位操作,严格遵守先进先出的原则进行传输数据,即对管道的读总是从开始处返回数据,对它的写总是把数据添加到末尾,所以这种管道也叫做FIFO文件。
同样,由于需要由管道自身来保证通信进程间的同步,命名管道也是一个只能单方向访问的文件,并且数据传输方式为FIFO方式。
也就是说,命名管道提供了一个路径名与之关联,以FIFO的文件形式存在于文件系统中,在文件系统中产生一个物理文件,其他进程只要访问该文件路径,就能彼此通过管道通信。在读数据端以只读方式打开管道文件,在写数据端以只写方式打开管道文件。
FIFO文件与普通文件的区别:
- 普通文件无法实现字节流方式管理,而且多进程之间访问共享资源会造成意想不到的问题;
- FIFO文件采用字节流方式管理,遵循先入先出原则,不涉及共享资源访问。
操作流程为:mkfifo -> open -> read(write) -> close ->unlink。


