- 1【已解决】./nginx: error while loading shared libraries: libssl.so.10: cannot open shared object file: No
- 2spring boot - 引入 logback 日志_ch.qos.logback是那个包引进来的
- 3网络安全工程师必读的100本书籍
- 4《【面试突击】— Redis篇》-- Redis的主从复制?哨兵机制?_min-slaves-to-write为0
- 5Android蓝牙协议栈fluoride(三) - 系统管理_android 蓝牙协议栈
- 6顶象vivo滑块_顶象滑块vivo
- 7Java Jar包压缩、解压使用指南
- 8C语言的类型_c语言几种定义类型
- 9基于python爬虫技术的旅游景点信息采集系统的设计与实现(Django框架)_有关旅游爬虫的论文_python爬虫数据采集实现论文
- 10在IDEA使用HBase Java API连接_大数据 hbase实验连接idea
Nvidia GPU虚拟化_显卡虚拟化
赞
踩
目录
3.2 MPS(Multi-Process Service)
1 背景
随着Nvidia GPU在渲染、编解码和计算领域发挥着越来越重要的作用,各大软件厂商对于Nvidia GPU的研究也越来越深入,尽管Nvidia倾向于生态闭源,但受制于极大的硬件成本压力,提升GPU利用率、压榨GPU性能逐渐成为基础设施领域关注的焦点。自然地,为了追求GPU上显存资源和算力资源的时分复用和空分复用,大家都开始考虑软件定义GPU,GPU虚拟化应运而生。
2 GPU虚拟化
在深度学习领域,Nvidia GPU的软件调用栈大致如下图所示,从上至下分别为:
- User APP:业务层,如训练或推理任务等
- Framework:框架层,如tensorflow、pytorch、paddle、megengine等
- CUDA Runtime:CUDA Runtime及周边生态库,如cudart、cublas、cudnn、cufft、cusparse等
- CUDA User Driver:用户态CUDA Driver,如cuda、nvml等
- CUDA Kernel Driver:内核态CUDA Driver,参考官方开源代码,如nvidia.ko等
- Nvidia GPU HW:GPU硬件

理论上,上述每一层都可以做GPU虚拟化,但从工程化的角度来看,考虑可行性、可维护性、overhead和部署方面,在CUDA Driver或硬件层实现更合适。
2.1 用户态虚拟化
目前比较常用的方法是在用户态CUDA Driver的动态库做劫持,参考cuda hook开源代码。通过拦截CUDA Driver API的调用,实现显存资源和算力资源的隔离。不仅对用户代码零侵入,而且灵活性较高,无论是部署在Bare Metal,还是结合容器化进行部署,都比较方便。
2.2 内核态虚拟化
通过劫持CUDA Driver动态库部署,可能会存在用户篡改的风险,在公有云上一般不能容忍。而内核态的优势在于可以一定程度上防止用户篡改,但由于Nvidia的闭源性,在内核态做显存资源和算力资源的隔离,技术难度较高。目前阿里云、腾讯云和百度云已经实现部署。
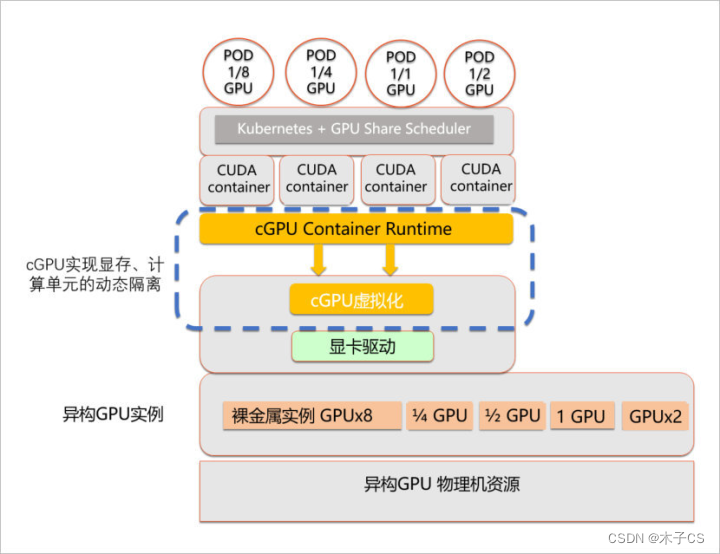
2.3 硬件虚拟化
Nvidia官方硬件虚拟化方案MIG(Multi-Instance GPU),从Ampere架构开始支持硬件层面的隔离,隔离程度更彻底,但最多只支持7个GPU实例的虚拟化环境。

3 其他
3.1 vGPU
Nvidia官方虚拟GPU解决方案,主要用于支持交付图形丰富的虚拟桌面和工作站,可以将GPU资源重新划分,以保证GPU资源可以在多个虚拟机之间共享,或者可以将多个GPU分配给一个虚拟机,可提升任意工作负载的性能。
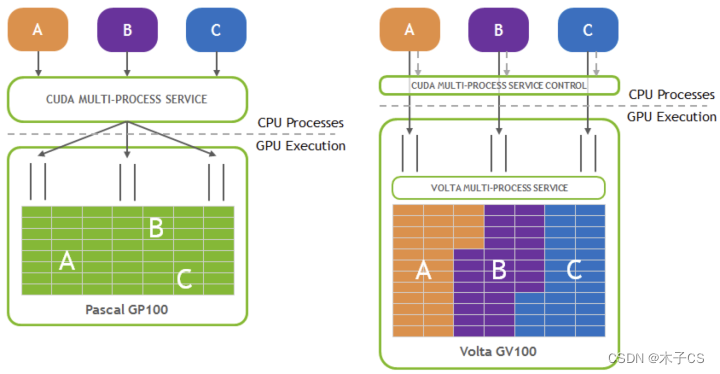
3.2 MPS(Multi-Process Service)
Nvidia官方多进程context融合方案,支持将多个进程上的kernel发送到MPS server或者直接发送到GPU上计算,避免了多进程在GPU上context的频繁切换。缺点是故障率较高,特别是故障在进程间扩散一般是不能容忍的。
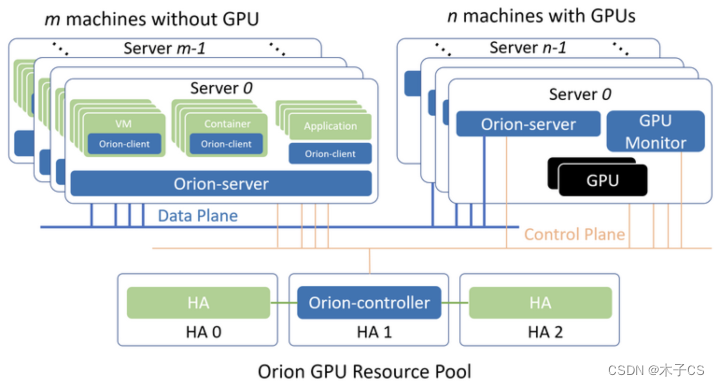
3.3 远程GPU
将GPU Server拉远,实现GPU池化,突破CPU与GPU的配比极限,拓展GPU虚拟化,可以最大限度地利用集群内的GPU碎片,提升GPU的利用率。趋动科技的OrionX方案,目前处于领先地位。