
- 1【计算机网络实验】实验三 IP网络规划与路由设计(头歌)_头歌 静态路由配置 ping 命令测试
- 2Mysql 数据库APi 编程(c/c++)-1.0_mysql数据表 api
- 3RuntimeError: Failed to allocate graph: MYRIAD device is not opened
- 4vue跳转,v-model 双向绑定,-vuex的使用cookie:,视频第三方播放
- 5微软官宣:Windows11将成为第一个全局AI辅助的操作系统_win11有自带的ai工具吗
- 6git知识点以及git常见错误_hint: 'git pull ...') before pushing again. hint:
- 7微信小程序页面传递参数方法_微信小程序navigateto传参
- 8键盘上各按键对应的英文名(转载)_numplus是哪个键
- 9python输出自己的名字_使用Python实现自我介绍
- 10【PHP】PHP代码审计基础知识
第四范式涂威威:企业专属大模型技术需闭环数据、思维链学习、高落地效率...
赞
踩
近日,以“智行天下 能动未来”为主题的第七届世界智能大会隆重举办,第四范式副总裁、主任科学家涂威威出席高峰会,与中国工程院院士邬江兴、德国弗劳恩霍夫电子纳米系统研究所所长Harald Kuhn、高通公司中国区董事长孟樸等院士及企业代表,同台共话大模型等智能科技在产业中的创新应用。

涂威威表示,生成式AI让企业软件的人机交互和应用价值内核价值都有了质的提升,打造数据闭环是企业落地成功的关键,结合环境学习让机器从真实决策环境中学习更高层级的目标是打造更强智能助手的重要手段。
企业软件使用遵循“二八法则”,即用户普遍只能使用其中20%的功能,软件的价值难以充分发挥,此外,功能的开发和迭代效率低下。生成式AI的出现让企业软件以「对话框式」实现功能的调用,不再需要找到某个位于十几级菜单目录下的功能,或者耗费过多精力在软件界面的开发环节。
这样一个智能助理甚至可以通过思维链的方式调用多种功能,帮助企业用户完成多步骤复杂的任务,也可以利用AI对软件的核心功能进行智能化改造,让传统软件内核从增删改查等基础工具,变革为能够解决感知、预测、决策、执行等问题的生产力工具。
实现这个更强大的智能助理的核心就是大模型。涂威威同时指出,企业想要落地专属大模型应用,需要满足以下3大条件:形成高质量的闭环数据、具备多步推理思维链(Chain of thoughts)的学习能力、解决大模型落地效率问题。
在闭环数据方面,大模型的背后还是机器学习,即利用数据训练模型。数据的质量决定了模型的最终效果,所以优质的训练数据是大模型落地应用的重中之重。基于此,需要用户的反馈形成高质量的闭环数据,进一步优化迭代大模型。其中,面对大模型中“知识”过时等问题时,大模型可以借用Memory机制,在外部有策略地获得对大模型有帮助且更加实时、可信的数据,从而可靠地解决用户实际的问题。大模型在垂直场景落地时,实际效果往往取决于业务定义的优劣,而不只是语义上的相关与否,因此大模型需要从用户的反馈中学习,来帮助用户越用越好。
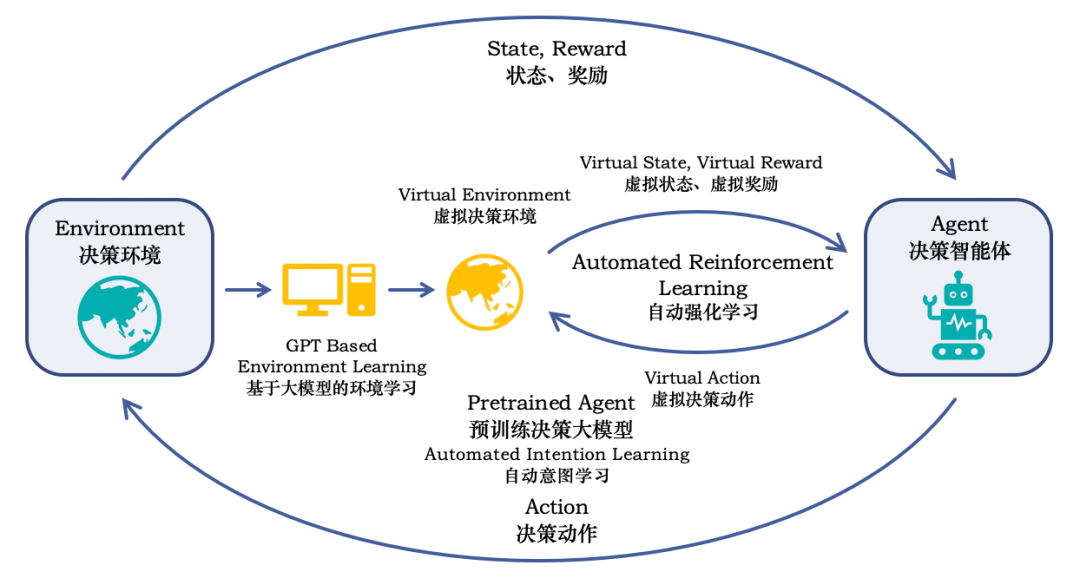
在思维链学习方面,为了让生成式AI这样的智能助手能够像人一样,处理更多复杂的问题,除了通过类似ChatGPT的Plugin模式以外,大模型还需要能够根据业务学习具备多步推理能力来形成长程序列决策的能力,即思维链学习的能力。现有的RLHF方法由于只是单步,所以本质上只是考虑当前回答是否满足用户定义的Reward Model。
解决更加复杂的多步序列决策任务,较为简单的方式是利用如模仿学习等方式让机器模仿专家解决复杂问题的过程,理想情况下可以逼近专家的水平,这样的方式的上限受限于人类专家的水平,就像AlphaGo单靠学习人类棋谱可以击败实力相对较弱的人类选手,但很难超越顶尖选手一样。为了能进一步提升,突破人类专家的能力上限,可以利用大模型提供的基础世界常识模型,结合环境学习,让机器从真实的决策环境中学习更高层级的目标,通过离线训练与在线微调结合的方式,在获得高阶推理能力的同时,大幅降低试错成本。这也是未来打造更强企业智能助手的核心手段。
在大模型落地效率方面,No Free Lunch定理告诉我们,没有哪一个模型能以最优的方式解决所有的问题,企业预算始终是有限的,企业落地大模型更合理的做法不是把所有的预算都投入到一个超级大模型中,而是可以通过组合多个专业模型各司其职来解决。这就如同人类大脑有不同的分区,不同分区负责不同职责一样。这种方式更利于模型迭代、维护,同时更利于控制成本。第四范式也正在基于南京大学LAMDA实验室提出的“学件”思想构建可重用、可演进和可了解的企业级大模型学件群组。

今年2月,第四范式正式发布了「式说」大模型,后提出“以生成式AI重构企业软件(AIGS)”的技术战略,提升企业级软件的体验及开发效率。目前已与金融、零售、制造、医疗、房产、运营商等近百家合作伙伴及企业探索大模型的落地合作。

