
- 1SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in
- 2Kafka 生产环境部署指南_kafka生产者,需要开通2181端口吗
- 3FreeRTOS面试题汇总
- 4大二上学期(回顾与展望)_大二开学展望
- 5AI绘画Stable Diffusion插件:提示词还能这么写?!
- 6ip_vs 的管理以及 keepalived + lvs 案例_ipvs-vs
- 7win10下安装sql2000_win10安装sql2000
- 8Gradle安装配置下载_gradle下载安装
- 9eclipse关联git不成功_详解Eclipse提交项目到GitHub以及解决代码冲突
- 10VBA-函数Len、Loc、LOF_vba lof
【AI工具声音克隆】——OpenVoice一键部署&modelScope一键使用_openvoice本地部署
赞
踩
一、声音/音色克隆简介
声音或音色克隆的原理实现步骤主要基于深度学习技术,特别是语音合成和生成模型。以下是声音/音色克隆的大致实现步骤:
- 数据收集:
- 收集语音数据,作为模型的训练样本。
- 数据应尽可能多样化,包括不同的语速、语调、音量以及不同的语境下的语音。
- 预处理:
- 对收集到的语音数据进行清洗,去除噪声、静音片段和其他不需要的部分。
- 进行语音分割,将连续的语音信号切割成较小的语音片段(如音素或单词)。
- 提取音频特征,如MFCC(Mel频率倒谱系数)、频谱图等,这些特征将用于后续的声音建模。
- 模型训练:
- 使用深度学习技术,如循环神经网络(RNN)、长短时记忆网络(LSTM)或Transformer等,构建声音克隆模型。
- 模型通常由两部分组成:编码器(Encoder)和解码器(Decoder)。编码器负责从目标说话人的语音数据中提取声音特征,并生成一个低维表征向量(如speaker embedding),这个向量包含了目标说话人的音色信息。解码器则负责根据这个表征向量和输入文本,生成与目标说话人音色相似的新语音。
- 通过大量的训练数据,模型能够学习到如何将文本转换为特定音色的语音。
- 声音合成:
- 当给定一段文本时,声音克隆模型首先使用编码器生成一个与目标说话人音色相似的表征向量。
- 然后,解码器使用这个表征向量和输入文本,通过一定的合成算法(如波形合成、参数合成等),生成与目标说话人音色相似的新语音。
- 后处理与优化:
- 对生成的语音进行后处理,如去噪、平滑等,以提高语音质量。
- 可以通过一些优化技术,如微调模型参数、增加训练数据等,来进一步提高声音克隆的效果。
- 评估与测试:
- 对生成的声音进行主观和客观的评估,以验证其是否与目标说话人的音色相似。
- 可以使用各种评估指标,如MOS(Mean Opinion Score)评分、相似度评分等,来量化评估声音克隆的效果。
- 应用与部署:
- 将训练好的声音克隆模型部署到实际应用中,如智能客服、语音助手、有声读物等。
- 根据具体应用场景,对模型进行定制和优化,以满足不同用户的需求。
二、OpenVoice
OpenVoice原型是Github发布的一个项目链接如下:
OpenVoice-github项目![]() https://github.com/myshell-ai/OpenVoice
https://github.com/myshell-ai/OpenVoice
使用时需要本地部署,但对新手来说,本地部署较为复杂,所以我们采用下面的较为简单的使用流程!
使用流程:
1、浏览器打开下面的Colab 笔记本文件链接
Colaboratory (简称为ColabQ)是由Google开发的一种基于云端的交互式笔记本环境。它提供了免费的计算资源(包括CPU、GPU和TPU) ,可让用户在浏览器中编写和执行代码,而无需进行任何配置和安装。

点击运行符号,即可一键在colab上布置好这个项目所需要的各种环境。几分钟后运行完成,会提供一个链接:

点击链接即可跳转到项目的使用界面:
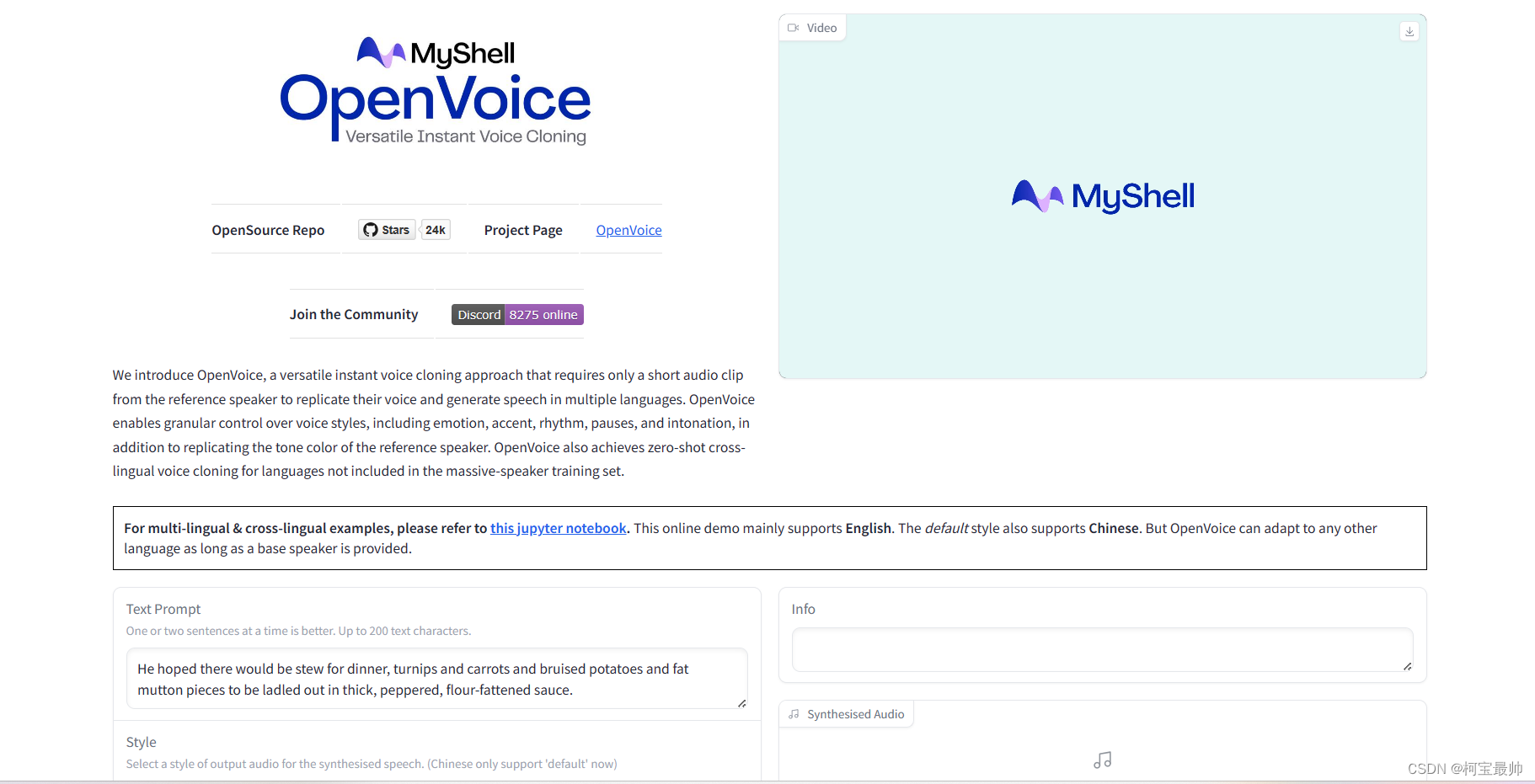
这个支持上传任意话语的音频文件,或者自己麦克风录制,不会让你读规定的文本:
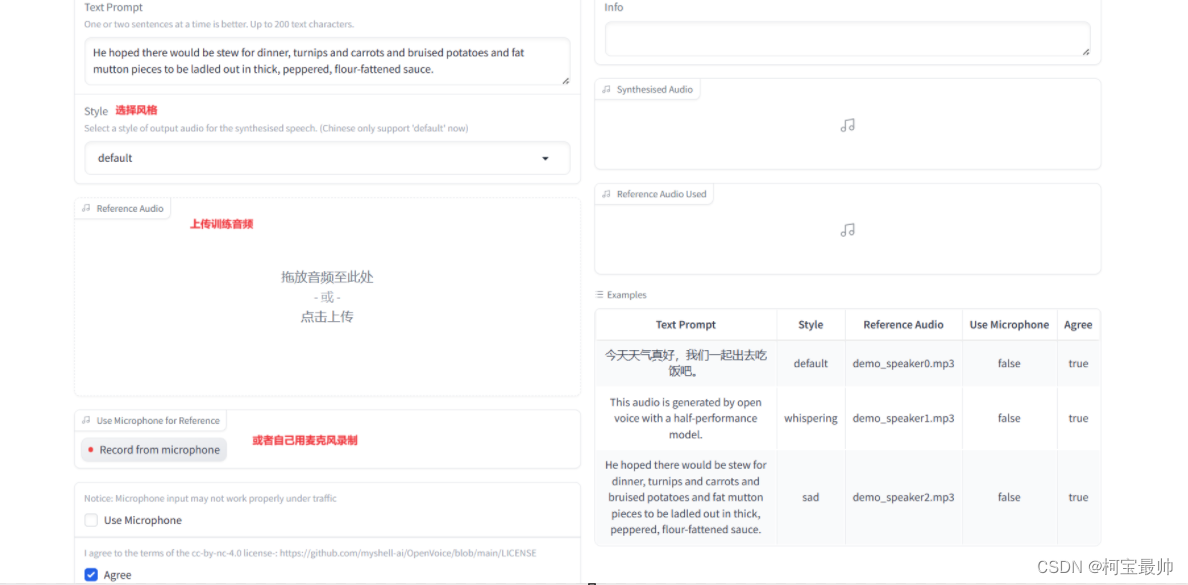
这里我上传了一段工藤新一的中配干声文件(去除过背景音乐和噪声等),然后进行训练:
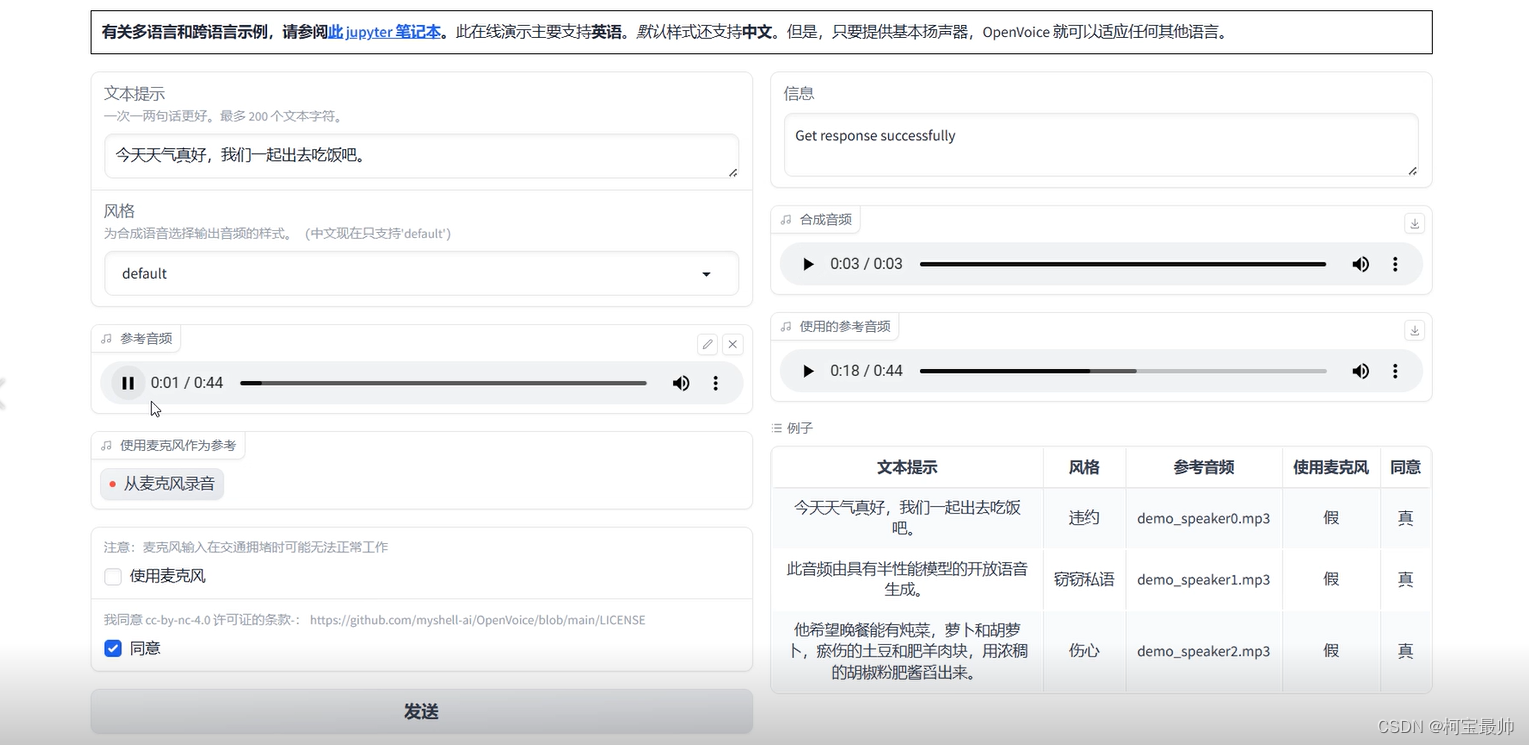
几秒就好了,很快,但是结果一言难尽。。。可能中文效果不好吧,不知怎么回事竟然把新一训练成一个“老嫂子”的女人声音。。。。
三、ModelScope
若想简单点的可以用这个,ModelScope工具链接:
modelscope官网![]() https://www.modelscope.cn/home
https://www.modelscope.cn/home
官网登陆后搜索声音,个人声音定制里即可:
 但这个训练时只能录制它提供的语句,大概需要读20句话,但是是免费的,与剪映新出的功能差不多!
但这个训练时只能录制它提供的语句,大概需要读20句话,但是是免费的,与剪映新出的功能差不多!
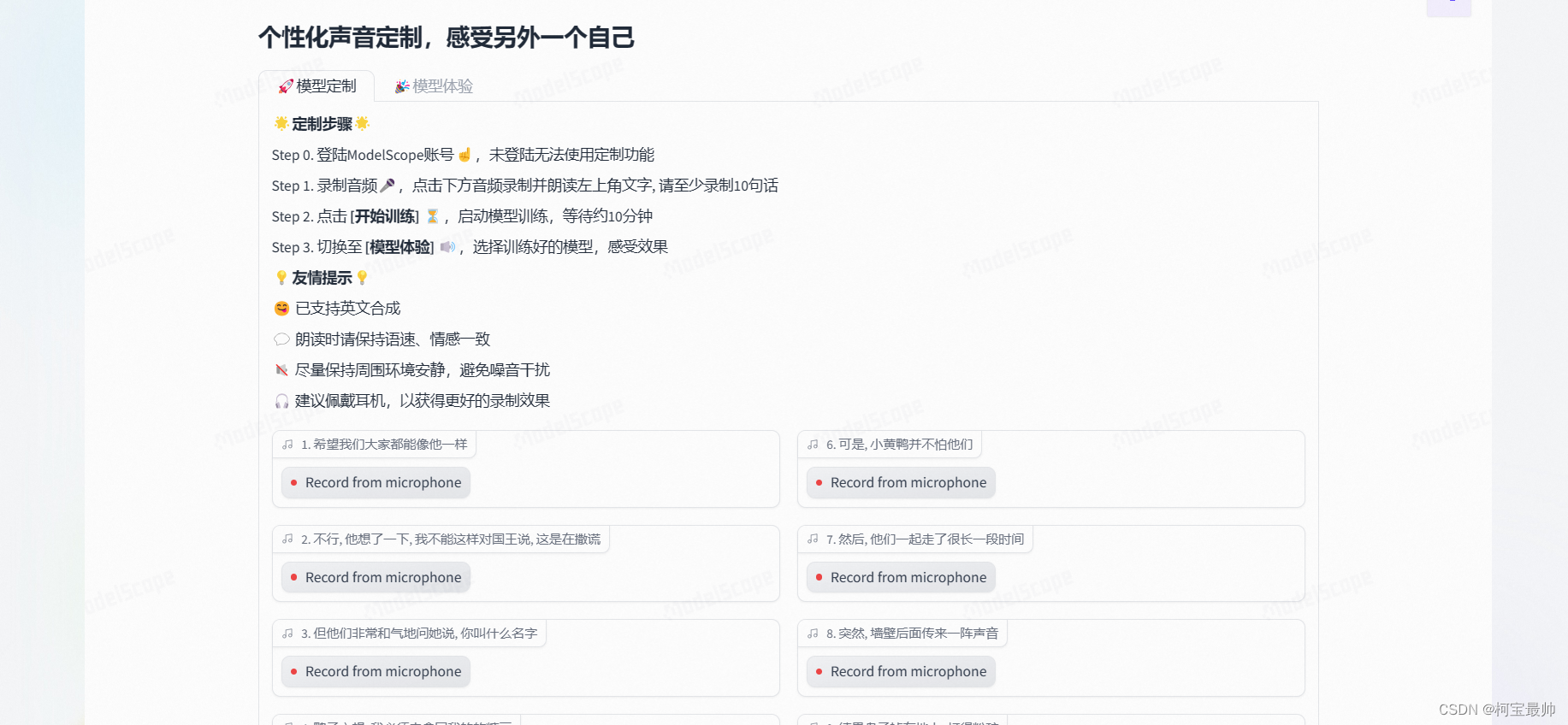
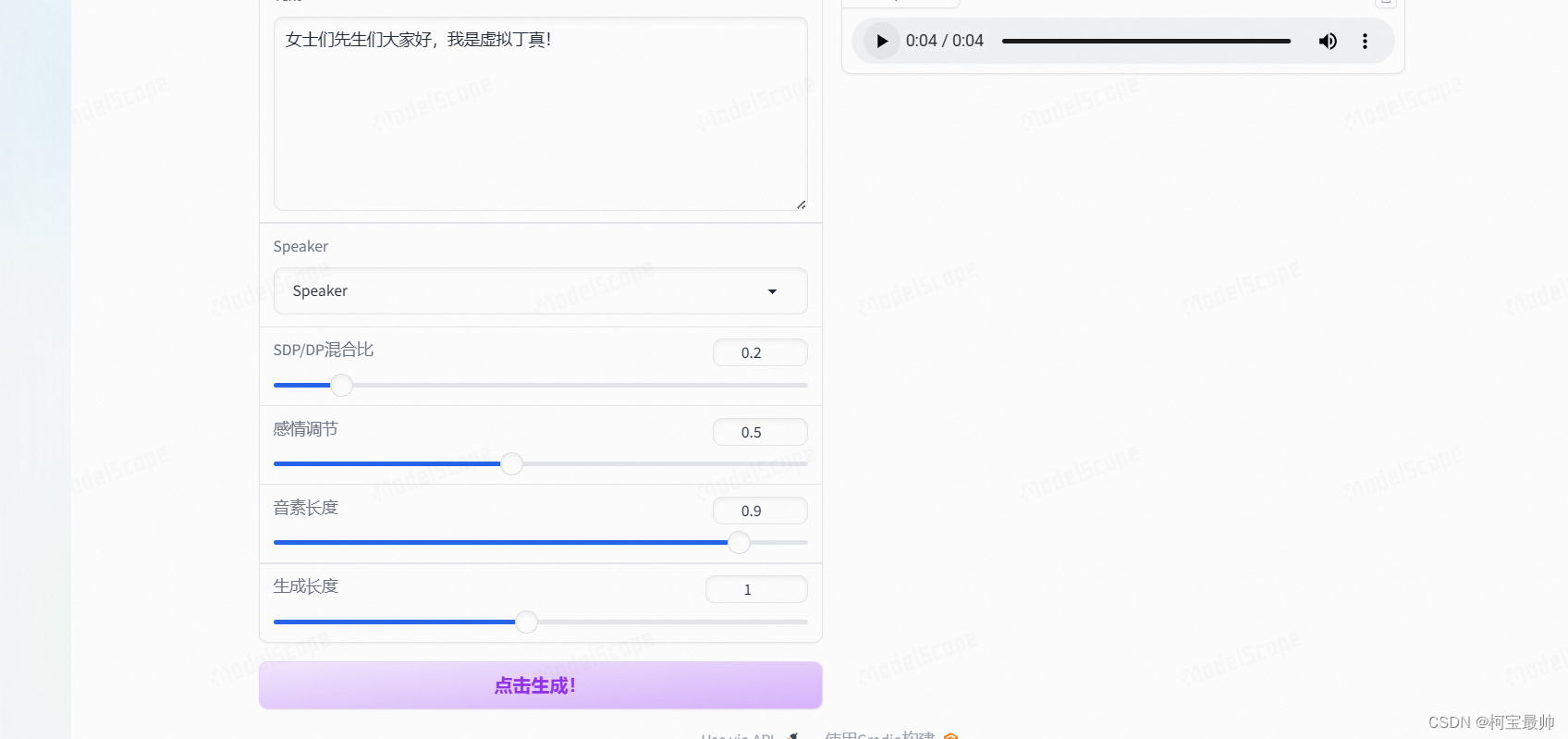
还提供了一些免费的训练好的音色模型,如下面丁真音色模型:

支持SDP/DP混合比,感情调节,音素长度和生成长度等的调节。
知识加油站:
1、详细介绍下OpenVoice?
OpenVoice是一个创新的开源项目,它利用最先进的深度学习技术,为开发者提供强大且易用的语音合成工具。以下是关于OpenVoice的详细介绍:
功能与特点:
- OpenVoice是一种多功能的即时声音克隆方法,只需要参考发言者的一小段音频片段,就可以复制他们的声音,并用多种语言生成语音。
- 它允许对声音风格进行细粒度控制,包括情感、口音、节奏、停顿和语调,此外还可以复制参考发言者的音色。
- OpenVoice还实现了零样本跨语言声音克隆,适用于未包含在大规模发言者训练集中的语言。
- 在计算上,OpenVoice也非常高效,其成本比市面上提供的性能较差的商业API低数十倍。
开源优势:
- OpenVoice是一个完全免费且开源的项目,开发者可以自由使用、修改和分享代码。
- 由于其开源性质,OpenVoice鼓励社区参与和贡献,从而促进了技术的持续发展和创新。
应用场景:
- 智能助手与聊天机器人:OpenVoice赋予机器自然的语言交流能力,提升用户体验。
- 有声读物与音频内容创作:自动转化电子书或文章,制作高质量的有声读物。
- 无障碍技术:帮助视障人士阅读网页、电子邮件或其他文字信息。
- 教育与培训:创建个性化的教学音频,提高学习效率。
2、详细介绍下modelscope?
ModelScope官网是一个AI模型社区及创新平台,由阿里巴巴达摩院联合CCF开源发展委员会共同推出。该平台致力于通过开放的社区合作,构建深度学习、机器学习等领域的创新应用。
- 提供了一站式的模型探索体验、推理、训练、部署和应用服务
- 用户可以在该平台上发现、学习、定制和分享心仪的模型
- 不仅汇聚了各领域最先进的机器学习模型,还提供了CPU资源和GPU算力,以支持AI开发者的研究和创新
- 还作为一个模型与数据集的托管平台,为AI开发者提供灵活、易用、低成本的一站式模型服务产品。这使得开发者能够更方便地利用先进的AI技术,推动创新应用的发展。
3、SDP/DP是什么?
在音频克隆模型中,通常会有两个主要的路径:一个是依赖于特定说话人(SDP)的路径,另一个是不依赖于特定说话人(DP)的路径。
- SDP路径:这个路径专注于捕捉和模拟特定说话人的声音特征,如音调、音色、语速等。它通常需要使用大量的该说话人的语音数据来进行训练,以确保生成的音频能够准确地模仿该说话人的声音。
- DP路径:这个路径则更加通用,不依赖于特定的说话人。它主要关注于语音的普遍特征,如语言结构、语法、语义等。DP路径可以使用来自多个不同说话人的语音数据进行训练,以提高模型的泛化能力。

往期精彩
STM32专栏(9.9)![]() http://t.csdnimg.cn/A3BJ2
http://t.csdnimg.cn/A3BJ2
OpenCV-Python专栏(9.9)![]() http://t.csdnimg.cn/jFJWe
http://t.csdnimg.cn/jFJWe
AI底层逻辑专栏(9.9)![]() http://t.csdnimg.cn/6BVhM
http://t.csdnimg.cn/6BVhM
机器学习专栏(免费)![]() http://t.csdnimg.cn/ALlLlSimulink专栏(免费)
http://t.csdnimg.cn/ALlLlSimulink专栏(免费)![]() http://t.csdnimg.cn/csDO4电机控制专栏(免费)
http://t.csdnimg.cn/csDO4电机控制专栏(免费)![]() http://t.csdnimg.cn/FNWM7
http://t.csdnimg.cn/FNWM7

