
- 1Pytorch里.t()的作用
- 2js中set的使用_js set 批量添加
- 3IntelliJ IDEA安装
- 4美通企业日报 | 麦德龙在重庆开第4家店;假日品牌在华第100家酒店开业
- 5十几年老Java咳血推荐,你薪资涨一波没毛病!小AD以为我端午都干嘛去了?
- 6docker 安装及常见命令_docker run bash
- 7AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.04.25-2024.05.01
- 8计算机毕业设计:500个开源项目推荐(源码+论文)大数据+JAVA+Python+深度学习✅_计算机开源项目
- 9【工具】创客贴会员|创客贴截止2024年6月所有AI功能效果实测(热门推荐和图片编辑部分)
- 10uni-app(3)— globalStyle全局配置和页面配置
浅析扩散模型与图像生成【应用篇】(九)——Pix2pix-zero_扩散模型生成图片实例
赞
踩
9. Zero-shot Image-to-Image Translation
该文提出一种无需训练,即可对图像进行文本驱动编辑的方法。在准确修改目标对象的同时,保证原图的背景和布局等内容不受太多的影响。下图展示了几种文本驱动图像编辑的效果,如将猫变成狗,将马变成斑马等。

该文主要做了以下几点工作,首先将输入的图像
x
~
\tilde{x}
x~利用Stable Diffusion编码到潜在空间得到
x
0
x_0
x0,并按照DDIM中的确定性过程将其扩散为噪声编码
x
i
n
v
x_{inv}
xinv。然后,利用BLIP模型得到输入图像对应的文本描述
c
c
c,并计算其与目标文本提示
t
t
t之间的均值差异
Δ
c
e
d
i
t
\Delta c_{edit}
Δcedit,将其作为图像编辑的方向引入到生成过程中。最后,为了保持图像的背景和布局保持不变,作者引入了交叉注意力机制进行引导。该方法的流程如下图所示
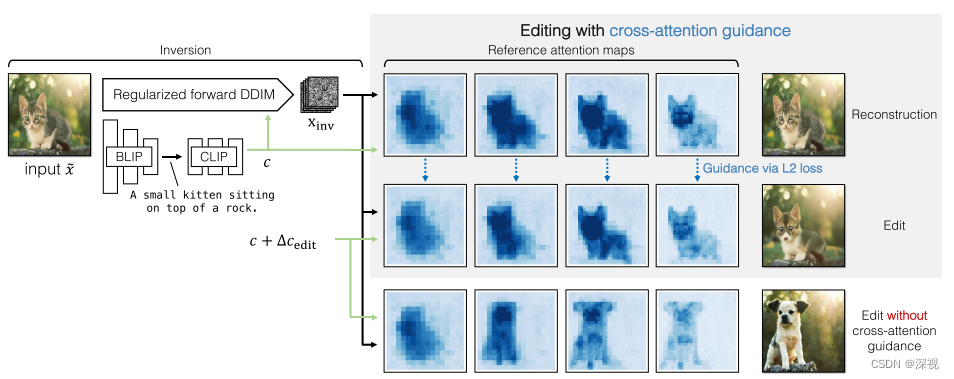
1. 逆转真实图像
首先得到真实图像 x ~ \tilde{x} x~对应的潜在特征 x 0 x_0 x0后,作者利用DDIM中的确定性过程将其扩散为纯噪声,过程如下 x t + 1 = α ˉ t + 1 f θ ( x t , t , c ) + 1 − α ˉ t + 1 ϵ θ ( x t , t , c ) x_{t+1}=\sqrt{\bar{\alpha}_{t+1}} f_{\theta}\left(x_{t}, t, c\right)+\sqrt{1-\bar{\alpha}_{t+1}} \epsilon_{\theta}\left(x_{t}, t, c\right) xt+1=αˉt+1 fθ(xt,t,c)+1−αˉt+1 ϵθ(xt,t,c)其中, ϵ θ \epsilon_{\theta} ϵθ是基于UNet模型的噪声估计器, f θ f_{\theta} fθ是根据当前的噪声图像 x t x_t xt,时刻 t t t和文本描述特征 c c c来估计得到的 x ^ 0 \hat{x}_0 x^0过程如下 f θ ( x t , t , c ) = x t − 1 − α ˉ t ϵ θ ( x t , t , c ) α ˉ t f_{\theta}\left(x_{t}, t, c\right)=\frac{x_{t}-\sqrt{1-\bar{\alpha}_{t}} \epsilon_{\theta}\left(x_{t}, t, c\right)}{\sqrt{\bar{\alpha}_{t}}} fθ(xt,t,c)=αˉt xt−1−αˉt ϵθ(xt,t,c)
这里很有意思,作者并不是直接使用DDIM中的扩散过程来增加噪声的,而是将原本已知的 x 0 x_0 x0换成了估计得到的 x ^ 0 \hat{x}_0 x^0,把可以随机采样的噪声 ϵ \epsilon ϵ变成了预测得到的 ϵ θ \epsilon_{\theta} ϵθ,我认为这样做的目的是为了在扩散过程中就把文字描述特征 c c c引入进去。
但是估计得到的噪声 ϵ θ \epsilon_{\theta} ϵθ存在一个问题,他不一定满足统计学上的不相关性,也就是说它不是一个完全的高斯白噪声,这将导致由最终的扩散结果 x i n v x_{inv} xinv生成的图像效果不好。为了解决这个问题,作者引入了两个正则化条件, L p a i r \mathcal{L}_{pair} Lpair和 L K L \mathcal{L}_{KL} LKL。为了计算 L p a i r \mathcal{L}_{pair} Lpair,作者将 ϵ θ \epsilon_{\theta} ϵθ输出的噪声图 η 0 ∈ R 64 × 64 × 4 \eta^0\in\mathbb{R}^{64\times64\times4} η0∈R64×64×4利用2*2的全局池化层将其逐步下采样到尺寸为 8 × 8 8\times8 8×8的噪声图,构建一个4层的噪声图金字塔 { η 0 , η 1 , η 2 , η 3 } \{\eta^0,\eta^1,\eta^2,\eta^3\} {η0,η1,η2,η3},然后,利用下式来计算 L p a i r \mathcal{L}_{pair} Lpair L pair = ∑ p 1 S p 2 ∑ δ = 1 S p − 1 ∑ x , y , c η x , y , c p ( η x − δ , y , c p + η x , y − δ , c p ) \mathcal{L}_{\text {pair }}=\sum_{p} \frac{1}{S_{p}^{2}} \sum_{\delta=1}^{S_{p}-1} \sum_{x, y, c} \eta_{x, y, c}^{p}\left(\eta_{x-\delta, y, c}^{p}+\eta_{x, y-\delta, c}^{p}\right) Lpair =p∑Sp21δ=1∑Sp−1x,y,c∑ηx,y,cp(ηx−δ,y,cp+ηx,y−δ,cp)其中,下标 x , y x,y x,y表示位置, c c c表示通道号, δ \delta δ表示位置偏移量, S p S_p Sp表示噪声图的尺寸。另一方面,使用变分自动编码器中的KL散度损失 L K L \mathcal{L}_{KL} LKL,来约束生成的噪声满足零均值单位方差的要求。最后,两个损失函数通过加权求和作为最终的自动互相关(auto-correlation)正则化项 L a u t o = L p a i r + λ L K L \mathcal{L}_{auto}=\mathcal{L}_{pair}+\lambda\mathcal{L}_{KL} Lauto=Lpair+λLKL。
2. 计算编辑方向
作者把原本的文本描述
c
c
c作为源提示
s
s
s,把编辑后的文本描述作为目标提示
t
t
t,并利用GPT-3语言模型,根据这两个提示分别生成一系列的句子,然后利用CLIP的文本编码器得到这些句子的嵌入式特征,并计算二者之间的均值差异
Δ
c
e
d
i
t
\Delta c_{edit}
Δcedit,如下图所示。这个差异将作为图像编辑的方向引入到生成过程中。
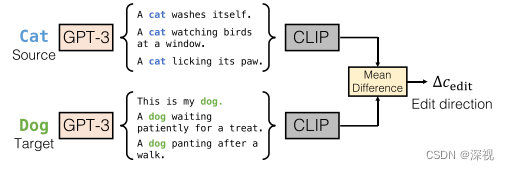
3. 基于交叉注意力引导的图像编辑
此时我们已经得到了扩散后的噪声图像
x
i
n
v
x_{inv}
xinv和原本的图像描述
c
c
c,以及图像编辑的方向
Δ
c
e
d
i
t
\Delta c_{edit}
Δcedit。最直接的方法就是将图像描述和编辑方向相加后
c
e
d
i
t
=
c
+
Δ
c
e
d
i
t
c_{edit}=c+\Delta c_{edit}
cedit=c+Δcedit作为条件,引入噪声估计网络
ϵ
θ
(
x
t
,
t
,
c
e
d
i
t
)
\epsilon_{\theta}(x_t,t,c_{edit})
ϵθ(xt,t,cedit),并按照一般的反向去噪过程得到生成图像,如本文中第二幅图的最后一行表示的过程。但这样带来一个问题,就是虽然目标对象按照编辑的内容发生了改变,但由于缺少约束和引导,图像的背景布局以及目标的结构和姿态都发生了变化,这是我们不希望看到的。因此为了解决这个问题,作者引入了基于交叉注意力机制的引导方法。
其实在Prompt-to-prompt这篇文章中,我们就已经揭示了交叉注意力图和图像内容以及文字描述之间的对应关系,如下所示
Attention
(
Q
,
K
,
V
)
=
M
⋅
V
where
M
=
Softmax
(
Q
K
T
d
)
第一步,直接使用原本的图像描述
c
c
c获得交叉注意力图
M
t
r
e
f
M_t^{ref}
Mtref;第二步,使用编辑后的描述
c
e
d
i
t
c_{edit}
cedit获得交叉注意力图
M
t
e
d
i
t
M_t^{edit}
Mtedit,计算两者差异的L2范数关于
x
t
x_t
xt的梯度
Δ
x
t
=
∇
x
t
(
∥
M
t
edit
−
M
t
ref
∥
2
)
\Delta x_{t}=\nabla_{x_{t}}\left(\left\|M_{t}^{\text {edit }}-M_{t}^{\text {ref }}\right\|_{2}\right)
Δxt=∇xt(
Mtedit −Mtref
2),并将其作用于
x
t
x_t
xt,得到
x
~
t
=
x
t
−
λ
x
a
Δ
x
t
\tilde{x}_t=x_t-\lambda_{xa}\Delta x_{t}
x~t=xt−λxaΔxt后,再次计算噪声
ϵ
e
d
i
t
^
←
ϵ
θ
(
x
t
−
λ
xa
Δ
x
t
,
t
,
c
edit
)
\epsilon^{\hat {edit }} \leftarrow \epsilon_{\theta}\left(x_{t}-\lambda_{\text {xa }} \Delta x_{t}, t, c_{\text {edit }}\right)
ϵedit^←ϵθ(xt−λxa Δxt,t,cedit )。最后,根据
ϵ
e
d
i
t
^
\epsilon^{\hat {edit }}
ϵedit^进行反向去噪,得到
x
t
−
1
x_{t-1}
xt−1。完整的算法流程如下图所示


