
- 1AIGC内容分享(六十一):AIGC 算法揭秘及产业落地应用分享_祝天刚 京东
- 2【Python编程实战】基于Python语言实现学生信息管理系统
- 3简历空白怎么办?计算机专业应届生和在校生怎么写简历?_计算机简历非科班怎么写学历
- 410种排序算法的复杂度,比较,与实现_排序算法复杂度对比
- 5隐马尔科夫模型 HMM 与 语音识别 speech recognition (1):名词解释_hmm speech
- 6【C进阶】文件操作(下)(详解--适合初学者入门)
- 7gitee开源项目基于SSM实现的图书借阅管理系统_ssm图书管理系统开源
- 8CDH集群hue继承hdfs遇到问题_hdfs权限继承无效
- 9NLP 算法实战项目:使用 BERT 进行文本多分类_bert多文本分类
- 10django基于python的图书馆管理系统--python-计算机毕业设计_图书馆管理系统设计pythondjango报告csdn
机器学习——朴素贝叶斯语言分类python程序_实现一个分类贝叶斯算法的过程
赞
踩
机器学习——朴素贝叶斯语言分类python程序
参考文献:《机器学习——周志华》
1 理论介绍
朴素贝叶斯(Naive Bayes)是一种基于贝叶斯定理的统计分类算法,在自然语言处理和文本分类领域得到了广泛应用。它被称为"朴素"是因为它假设所有特征之间相互独立,但在实际情况中往往有一定的相关性。朴素贝叶斯算法的核心思想是通过计算给定特征条件下的类别的概率来进行分类。在文本分类中,朴素贝叶斯算法可以用来将文本分到不同的类别中,比如垃圾邮件分类、情感分析等。
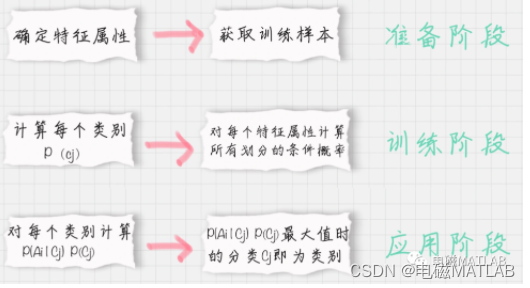
算法的实现过程可以分为以下几个步骤:
1)数据预处理:首先需要对文本数据进行预处理,包括去除停用词、标点符号、数字等,将文本转化为一系列的特征向量。可以使用词袋模型或者TF-IDF等方法对文本进行表示。
2)计算类别的先验概率:在朴素贝叶斯算法中,先验概率是指在没有任何其他信息的情况下,某个类别出现的概率。可以通过计算训练集中不同类别的文档所占比例得到。
3)计算条件概率:根据训练集中的文档和对应的类别标签,计算每个特征在给定类别条件下的概率。一般使用频率或者概率分布函数进行估计。
4)应用贝叶斯定理:根据贝叶斯定理,将先验概率和条件概率相乘,得到给定特征条件下属于某个类别的后验概率。最终选择后验概率最大的类别作为分类结果。
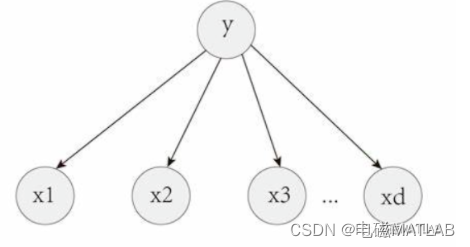
朴素贝叶斯算法的优点包括算法简单、计算效率高、对大规模数据集的处理效果好。然而,它的假设特征之间相互独立,这在某些情况下可能并不成立,导致分类结果偏离实际。另外,朴素贝叶斯算法对于处理缺失数据和处理连续型数据有一定的限制。除了文本分类,朴素贝叶斯算法还可以应用于很多其他领域,包括垃圾邮件过滤、情感分析、推荐系统等。在实际应用中,可以根据具体问题的特点选择相应的变体,如多项式朴素贝叶斯、高斯朴素贝叶斯等。总而言之,朴素贝叶斯是一种简单而有效的统计分类算法,特别适用于处理文本分类问题。通过计算给定特征条件下的类别的概率,可以高效地对文本进行分类,具有广泛的应用潜力。
2 原理
贝叶斯决策论(Bayesian decision theory)是概率框架下实施决策的基本方法.对分类任务来说,在所有相关概率都已知的理想情形下,贝叶斯决策论考虑如何基于这些概率和误判损失来选择最优的类别标记.下面我们以多分类任务为例来解释其基本原理。



3 算例分析
利用贝叶斯分类鉴别语言是否为侮辱性语言。0表示否,1表示是。
分类对象:
[‘love’, ‘nice’, ‘dalmation’]、[‘stupid’, ‘donkey’]
训练样本:

4 python程序运行结果

5 python程序
from numpy import *
def loadDataSet():
postingList=[[‘my’, ‘donkey’, ‘is’, ‘very’, ‘nice’],
[‘maybe’, ‘not’, ‘take’, ‘him’, ‘to’, ‘dog’, ‘park’, ‘stupid’],
[‘my’, ‘dalmation’, ‘is’, ‘so’, ‘cute’, ‘I’, ‘love’, ‘him’],
[‘stop’, ‘posting’, ‘stupid’, ‘worthless’, ‘garbage’],
[‘mr’, ‘licks’, ‘ate’, ‘my’, ‘steak’, ‘how’, ‘to’, ‘stop’, ‘him’],
[‘quit’, ‘buying’, ‘worthless’, ‘dog’, ‘food’, ‘stupid’]]
classVec = [0,1,0,1,0,1] #1 is abusive, 0 not
return postingList,classVec
def createVocabList(dataSet):
vocabSet = set([]) #create empty set
for document in dataSet:
vocabSet = vocabSet | set(document) #union of the two sets
return list(vocabSet)
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] = 1
else: print( “the word: %s is not in my Vocabulary!” % word)
return returnVec
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive = sum(trainCategory)/float(numTrainDocs)
p0Num = ones(numWords); p1Num = ones(numWords) #change to ones()
p0Denom = 2.0; p1Denom = 2.0 #change to 2.0
for i in range(numTrainDocs):
if trainCategory[i] == 1:
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = log(p1Num/p1Denom) #change to log()
p0Vect = log(p0Num/p0Denom) #change to log()
return p0Vect,p1Vect,pAbusive
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
p1 = sum(vec2Classify * p1Vec) + log(pClass1) #element-wise mult
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0
def testingNB():
listOPosts,listClasses = loadDataSet()
myVocabList = createVocabList(listOPosts)
trainMat=[]
for postinDoc in listOPosts:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
p0V,p1V,pAb = trainNB0(array(trainMat),array(listClasses))
testEntry = [‘love’, ‘nice’, ‘dalmation’]
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print (testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb))
testEntry = [‘stupid’, ‘donkey’]
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print (testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb))
#文本分类
testingNB()

