
- 1大模型训练推理如何选择GPU?一篇文章带你走出困惑(附模型大小GPU推荐图)_训练一个语音识别模型需要多大的gpu
- 2【SD】openpose+深度编辑 手部细节_sd openpose
- 3一文搞定Docker安装常用软件再也不用到处找了!!!【一】_容器中常用的软件
- 4深入探索 Stable Diffusion:AI图像创新的新纪元_stablediffusion是最优的工具吗 ai技术趋势
- 5Activity Recognition行为识别
- 6Python3.7+Annaconda +Pytorch安装—完全解决方案(这一篇就够了)_python3.7安装pytorch 2.0
- 7JAVA - String 中删除指定字符(11种方法)_javastring删除指定字符
- 8【vue开发问题-解决方法】(五)vue Element UI 日期选择器获取日期格式问题 t.getTime is not a function...
- 92024 全国人工智能大赛 AI+无线通信,【秋招面试专题解析】_全国人工智能大赛2024年
- 10VehicleHal.java - fwk层对应VehicleService
CART 算法——决策树_cart决策树
赞
踩
目录
CART是英文“classification and regression tree”的缩写,翻译过来是分类与回归树,与前面说到的ID3、C4.5一致,都是决策树生成的一种算法,同样也由特征选择、树的生成以及剪枝组成,既可以用于分类也可以用于回归。CART算法由决策树的生成以及决策树剪枝两部分组成。
1.CART的生成:
决策树的生成就是递归地构建二叉决策树的过程。对回归树用平方差最小化准则,对分类树用基尼指数最小化准则,进行特征选择,生成二叉树。
分类树与回归树的一个区别是:如果目标变量是离散型变量则用分类树,如果目标变量是连续型变量则用回归树。
(1)回归树的生成
回归树是用于目标变量是连续型变量的情况下,假设X与Y分别为输入和输出变量,并且Y是连续型变量,给定数据即D={(x1,y1),(x2,y2),...(xn,yn)},根据训练数据集D生成决策树。
前面说过,回归树的生成准则是平方差(总离差平方和:实际观察值与一般水平即均值的离差总和)最小化准则,即预测误差最小化,所以我们的目的就是找到一个分界点,以这个点作为分界线将训练集D分成两部分D1和D2,并且使数据集D1和D2中各自的平方差最小。然后然后再分别再D1和D2中找类似的分界点,继续循环,直到满足终止条件。
在具体找分解值的时候采用遍历所有变量的方法,依次计算平方差,选择平方差最小时对应的分解值。
(2)分类树的生成
分类树用基尼指数选择最优特征(与信息增益类似),同时决定该特征的最优二值切分点。
①基尼指数
基尼指数Gini(D)表示集合D的不确定性,基尼指数Gini(D,A)表示经A=a分割后集合D的不确定性。基尼指数数值越大,样本集合的不确定性越大。
分类问题中,假设有K个类,样本点属于第k类的概率为pk,则概率分布的基尼指数定义为:

对于二分类问题,若样本点属于第一类的概率为p,则概率分布的基尼指数为:Gini(p)=2p(1-p)。
对于样本给定的集合D,其基尼指数为:Gini(D)=1-∑(|Ck|/|D|)*2,这里Ck是D中属于第k类的样本子集,K是类的个数。
条件基尼指数:

上面公式表示在特征A的条件下,集合D的基尼指数,其中D1和D2表示样本集合D根据特征A是否取某一个可能值a被分割成的两部分。
②算法步骤
输入:训练数据集D,停止计算的条件
输出:CART决策树
根据训练数据集,从根节点开始,递归地对每个结点进行以下操作,构建二叉决策树:
设结点的训练数据集为D,计算现有特征对该数据集的基尼指数,此时,对每一个特征A,对其可能取的每一个值a,根据样本点A=a的测试为“是”或“否”将D分割成D1和D2两部分,然后计算Gini(D,A)。
在所有可能的特征A以及他们所有可能的切分点a中,选择基尼指数最小的特征及其对应的切分点作为最优特征与最佳切分点。依最优特征与最优切分点,从现结点生成两个子节点,将训练数据集依特征分配到两个子节点中去。
对两个子节点递归调用.1,.2,直至满足停止条件。
生成CART决策树。
算法停止计算的条件是结点中的样本个数小于预定的阈值,或样本集的基尼指数小于预定的阈值(样本基本属于同一类),或者没有更多特征。
2.CART剪枝:
我们再前面那一章节提过剪枝是为了避免数据发生过拟合现象,而避免这种情况发生的方法就是使损失函数最小化。
(1)损失函数
先看看损失函数的公式:

在α已知得情况下,要使上面得Cα(T)最小,就需要使|T|最小,即子树得叶节点数量最小;或者使训练误差最小,要使训练误差最小,就需要再引入新的特征,这样更会增加树得复杂度。所以我们主要通过降低|T|来降低损失函数,而这主要是通过剪去一些不必要得枝得到得。
但是在具体剪得过程中,我们需要有一个评判标准用来判断哪些枝可以剪,哪些使不可以剪得。而这个评判标准就是剪枝前后该树得损失函数是否减少,如果减小,就对该枝进行剪枝。
具体地,从整数T0开始剪枝,对T0的任意内部节点t,以t为单结点树(即该树没有叶节点)的损失函数是:Cα(t)=C(t)+α
以t为根节点的子树Tt的损失函数是:Cα(Tt)=C(Tt)+α|Tt|
当α=0或者充分小,有不等式:
![]()
当α继续增大时,在某一α处会有:

当α再继续增大时,在某一α处会有:
![]()
当下式成立时:
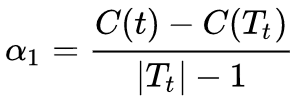
在这个时候,Tt与t有相同的损失函数值,而t的结点少,因此t比Tt更可取,对Tt进行剪枝。
为此,可以对T0中的每一内部节点t,计算g(t)=(C(t)-C(Tt))/(|Tt|-1),该式表示剪枝后整体损失函数减少的程度。在T0中剪去g(t)最小的Tt,将得到的子树作为T1,同时将最小的g(t)设为α1.T1为区间最小[α1,α2)的最优子数。如此剪枝下去,直至得到根节点,在这一过程中不断增加α的值,产生新的区间。
在剪枝得到的子树序列T0,T1,...,Tn中独立验证数据集,测试子树序列的T0,T1,...,Tn中各颗子树的平方误差或基尼指数。平方误差或基尼指数最小的决策树被认为是最优的决策树。
(2)算法步骤:
输入:CART算法生成的决策树T0
输出:最优决策树Tα
设k=0,T=T0
设α=+∞
自上而下地对各内部节点t计算C(Tt),|Tt|以及g(t),这里,Tt表示以t为根节点的子树,C(Tt)是对训练数据的预测误差。|Tt|是Tt的叶结点个数。
对g(t)=α的内部结点t进行剪枝,并对叶节点t以多数表决法决定其类得到树T。
设k=k+1,αk=α,Tk=T。
如果Tk不是由根节点及两个叶节点构成的树,则回到步骤(3);否则令Tk=Tn。
采用交叉验证法在子树序列T0,T1,...,Tn中选取最优子树Tα。

