
- 1gitee使用之Pull Request_gitee pull request
- 2web安全学习指南(红队安全技能栈)_web安全学习指南教it的小王a
- 3【2020年数据分析岗面试题】不断更新...(含自己的理解、思考和简答)_p值 面试题
- 4逐飞mini车样品说明
- 514个网络管理员必备的最佳网络流量分析工具
- 6Anaconda 下配置 R 环境并配置 Jupyter Notebook 的 R Kernel_anaconda安装r语言
- 7[转]查看Zookeeper服务器状态信息的一些命令_本地的zoopkeeper服务怎么查看_如何查看本地zk服务
- 8报错sun.security.validator.ValidatorException: PKIX path building failed
- 9Sharding-JDBC之PreciseShardingAlgorithm(精确分片算法)
- 10开源交互式自动标注工具EISeg_开源自动视觉标注软件
一文带你UI界面玩转ChatGLM以及Llama的微调_chatglm ui
赞
踩
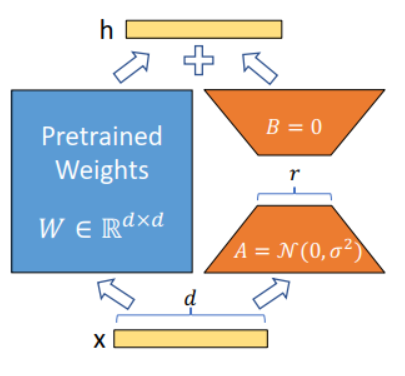
Lora微调的概念:
lora是Low-Rank Adaptation的缩写,是微软的Hu等人于2021年挂在ArXiv上(后又发表在ICLR2022上)的一篇论文《LoRA: Low-Rank Adaptation of Large Language Models》中提出的,通俗来讲,是一种降低模型可训练参数,又尽量不损失模型表现的大模型微调方法。为什么时隔两年,lora又突然火了一把呢?这一切都要感谢ChatGPT。
这里就简单介绍这么多,LORA微调系列(一):LORA和它的基本原理 - 知乎 (zhihu.com)这篇文章讲解的非常详细,有兴趣的同学可以去看一看。随着大模型的爆火,lora已经成为必不可少的工具之一了。下面就开始讲述如何在UI页面可视化的微调大模型。
step 1 下载源码
ChatGLM的微调
git clone https://github.com/hiyouga/ChatGLM-Efficient-Tuning.gitLlama的微调:
git clone https://github.com/hiyouga/LLaMA-Efficient-Tuning.gitstep 2 准备数据集
准备好数据集(json文件),放入./ChatGLM-Efficient-Tuning-main/data文件夹中
Step 3 查看数据集SHA-1哈希值
sha1sum /path/to/your/file.txtStep 4 添加数据集
将SHA-1哈希值添加到dataset_info.json文件中,例如:
- "alpaca_gpt4_zh": {
- "file_name": "alpaca_gpt4_data_zh.json",
- "file_sha1": "3eaa3bda364ccdd59925d7448a698256c31ef845"
- },
Step 5 运行程序
安装依赖:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
运行程序:
python ./ChatGLM-Efficient-Tuning-main/src/train_web.pyStep 6 修改参数&运行
UI页面:

Step 6.1 训练
1.修改Model Path:本地模型的地址
2.修改Fintuning method:微调方式(默认为lora)
3.选择需要训练的数据集
4.修改以下的超参数:
Learning rate:学习率(e-3~e-5),Epochs,Batchsize,Save steps
这里的Save steps是每多少步就保存一次Checkpoint文件。例如有3000个Total steps,Save steps为1000,那么就是每1000个step就保存一次Checkpoint文件,最后一共三个文件。
5.开始训练: 点击start
Step 6.2 测试
点击Evaluate,选择数据集,修改相关的参数,点start
Step 6.3 Chat
点击Load model(可以实时的查看微调结果或者模型结果)
Step 6.4 导出模型
输入导出模型的地址,以及模型最大文件的大小。
Llama的微调方式和ChatGLM的微调方式一样,这里就不多赘述了。
最后,希望大家都可以炼丹成功!!!

