- 1【git】一文让你入门git的使用_一文搞定git
- 2Spring详解(学习总结)_spring框架原理及流程
- 3如何保护Linux服务器安全?_linux 服务器怎么安全防护
- 4学习AI画画_stockimg.ai
- 5使用flink将mysql数据入湖delta_mysqlsource.
builder() - 6如何使用Spring Boot进行单元测试
- 7Studio One安装教程+软件安装包下载_studio one注册机
- 8c语言插入排序算法:直接插入排序和希尔排序_c语言的插入算法
- 9git clone 项目报错early EOF 的解决方式
- 10本地离线部署Ai大模型的三种方案,含安装教程!_本地ai大模型
基于python豆瓣电影评论的情感分析和聚类分析,聚类分析有手肘法进行检验,情感分析用snownlp_基于python电影评论的情感分析
赞
踩
基于Python的豆瓣电影评论的情感分析和聚类分析是一种用于探索电影评论数据的方法。
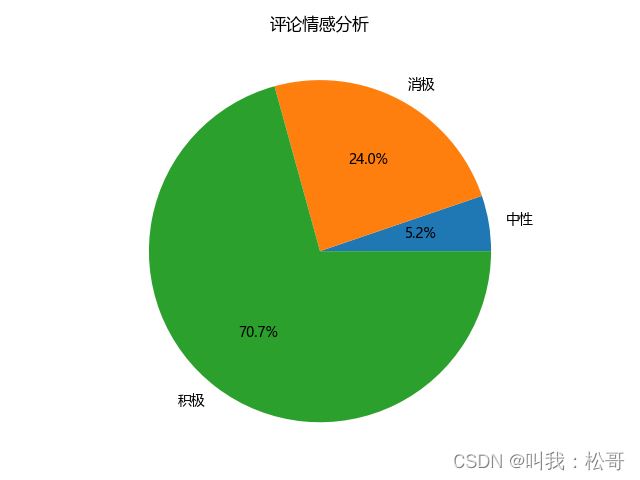
情感分析
情感分析旨在从文本中提取情感信息,并对其进行分类,如正面、负面或中性。在这里,我们使用了一个名为snownlp的Python库来进行情感分析。Snownlp是一个基于概率算法和自然语言处理技术的情感分析工具。
首先,我们需要收集豆瓣电影的评论数据。可以使用豆瓣API或其他方式获取评论文本。接下来,我们将使用snownlp库对每条评论进行情感分析。该库会对文本进行处理并返回情感得分,该得分可以表示评论的情感极性。通过设定阈值,我们可以将评论划分为正面、负面或中性。
情感分析可以帮助我们了解用户对电影的情感倾向,并评估电影的受欢迎程度。例如,通过统计正面评论的比例,我们可以获知电影是否受到观众的喜爱。
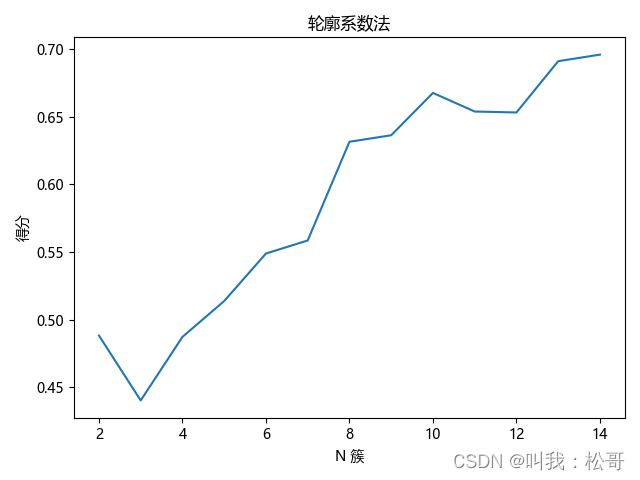
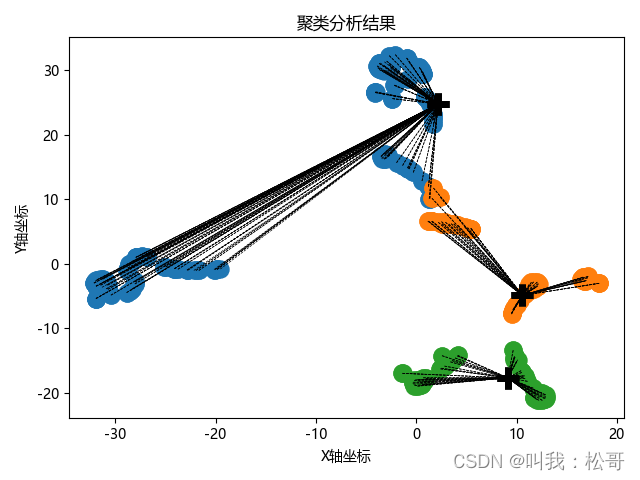
聚类分析
聚类分析是一种将数据划分为相似组的方法,以便发现其中的模式和结构。在豆瓣电影评论中,我们可以使用聚类分析来将评论划分为不同的群组,每个群组具有相似的主题或情感。
一种常用的聚类算法是K-means算法。它通过计算数据点之间的距离,并将数据点分配到最近的簇中。在聚类分析中,我们通常会使用手肘法(Elbow Method)来确定最佳的簇数。
手肘法通过绘制簇数与聚类误差(即数据点与其所属簇中心的距离之和)之间的关系图。随着簇数的增加,聚类误差通常会逐渐减少。然而,当簇数增加到一定程度时,再增加簇数对聚类误差的减少作用较小。这时,图形呈现出一个明显的“弯曲”点,被称为“手肘点”。手肘点所对应的簇数被认为是最佳的簇数。
聚类分析可以帮助我们发现豆瓣电影评论中的不同主题、观点或情感集群。通过对不同群组进行进一步分析,我们可以了解电影受众的兴趣爱好、意见和评价。
主要代码:
import pandas as pd
df=pd.read_csv('豆瓣评论 坚如磐石.csv')
from snownlp import SnowNLP
#获取情感分数
line0=[]
list1=[]
for line in df.values.tolist():
s = SnowNLP(str(line[1]))
print(s.sentiments)
list1.append(s.sentiments)
if (s.sentiments>= 0.6):
line0.append('积极')
elif (0.6>s.sentiments>= 0.4):
line0.append('中性')
else:
line0.append('消极')
print(line0)
df['情感分析']=line0
df['情感分数']=list1
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['FangSong'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
data=df.groupby(by=['情感分析'])['评论'].count().reset_index()
x=data['情感分析'].tolist()
y=data['评论'].tolist()
plt.figure(figsize=(20, 8), dpi=100)
# 绘制饼图
plt.pie(y, labels=x, autopct="%1.2f%%", colors=['b','r','g','y','c','m','y','k','c','g','y'])
# 显示图例
plt.legend()
# 添加标题
plt.title("情感分析饼图")
#为了让显示的饼图保持圆形,需要添加axis保证长宽一样
plt.axis('equal')
# 显示图像
plt.show()
运行效果