- 1FPGA实现简易电梯控制系统设计_fpga电梯控制器的设计
- 2idea配置本地maven
- 3云账户实际业务SQL对比测试ClickHouse、TiDB和StarRocks_starrocks tidb
- 4django crud_Django Crud应用程序PostgreSQL
- 57-10 星际探险(SPFA_c++星际探险家在其最新的宇宙探险中遭遇了一系列新的挑战。此次探险中,探险家的飞
- 6hihocoder#1589 : 回文子串的数量(manacher)_manacher hash 回文数
- 7高精度语音识别框架——ASR_Theory
- 8ollama 使用,以及指定模型下载地址_ollama 模型下载
- 9C++语法08:链表算法:优势、应用、实现与示例_链表c++
- 10C# WinForm中控件与背景透明+c# linklabel 去掉下划线的方法
本地离线部署Ai大模型的三种方案,含安装教程!_本地ai大模型
赞
踩

1.为什么要本地离线部署Ai大模型?
离线部署AI大模型有多个重要原因,涵盖了安全性、隐私、成本、控制性和可靠性等方面。以下是一些主要的原因和详细解释:
1.1. 数据隐私和安全
-
敏感数据保护:某些应用需要处理高度敏感的个人或商业数据,如医疗记录、金融信息或知识产权数据。离线部署可以确保这些数据不离开本地环境,减少泄露的风险。
-
合规性:一些行业和地区对数据保护有严格的法规和要求(如GDPR),要求数据必须在本地存储和处理。
1.2. 成本控制
-
长期成本降低:虽然初期的硬件投资较高,但长期使用本地部署可能比持续支付云服务的使用费用更为经济,特别是在处理大量数据或频繁使用时。
-
避免云计算费用波动:使用云服务时,费用可能会因使用量波动而不可预测。离线部署能够提供更稳定的成本控制。
1.3. 性能和延迟
-
低延迟:本地部署可以提供更低的延迟,特别适合需要实时响应的应用,如自动驾驶、工业控制和实时通信。
-
高性能:在本地部署中,硬件资源专用于特定任务,可以进行更好的性能优化。
1.4. 控制和定制化
-
完全控制:本地部署允许你对硬件和软件环境进行完全控制,可以根据需要进行优化和定制,而无需依赖第三方提供商。
-
深度定制:你可以根据具体需求对模型和系统进行深度定制,而不受云服务提供商的限制。
1.5. 可靠性和可用性
-
避免网络依赖:本地部署可以在没有互联网连接的情况下工作,适合在网络连接不稳定或不可用的环境中使用,如远程或边缘设备。
-
减少停机时间:依赖云服务可能会遇到服务中断或限制,本地部署可以提供更高的可用性和可靠性。
1.6. 数据带宽和传输
-
减少数据传输需求:处理大量数据时,数据传输到云端可能需要大量带宽并且耗时。本地处理可以避免这些问题,提高处理效率。
1.7. 技术和创新
-
创新空间:在本地部署中,你可以自由地实验新的技术和方法,而不受云服务提供商的限制。这对前沿研究和开发特别重要。
当然也适用于有些工作环境只能使用内网的情况!!!
2.方案一:GPT4All
一个免费使用、本地运行、具有隐私意识的聊天机器人,无需 GPU 或互联网。

以下是GPT4All支持的Ai大模型!
GPT4All-J 6B v1.0 GPT4All-J v1.1-breezy GPT4All-J v1.2-jazzy GPT4All-J v1.3-groovy GPT4All-J Lora 6B GPT4All LLaMa Lora 7B GPT4All 13B snoozy GPT4All Falcon Nous-Hermes Nous-Hermes2 Nous-Puffin Dolly 6B Dolly 12B Alpaca 7B Alpaca Lora 7B GPT-J 6.7B LLama 7B LLama 13B Pythia 6.7B Pythia 12B Fastchat T5 Fastchat Vicuña 7B Fastchat Vicuña 13B StableVicuña RLHF StableLM Tuned StableLM Base Koala 13B Open Assistant Pythia 12B Mosaic MPT7B Mosaic mpt-instruct Mosaic mpt-chat Wizard 7B Wizard 7B Uncensored Wizard 13B Uncensored GPT4-x-Vicuna-13b Falcon 7b Falcon 7b instruct text-davinci-003
2.1.安装教程(以Window系统为例)
2.1.1.双击exe文件

2.1.2.点击下一步
2.1.3.选择安装目录,点击下一步

2.1.4.点击下一步

2.1.5.勾选“我接受许可”,点击下一步

2.1.6.点击下一步

2.1.7.点击安装
2.1.8.等待安装
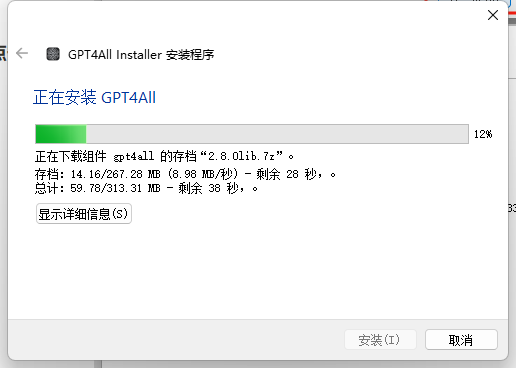
2.1.9.安装完成,点击下一步,点击完成即可

2.2.使用教程
2.2.1.桌面上找到GPT4All,双击打开

2.2.2.下载我们想要的模型,这里以目前在开源大模型领域,最强的Llama3为例!


2.2.3.选择下载的模型进行对话

3.方案二:LMstudio
LM Studio 是一个桌面应用程序,用于在计算机上运行本地 Ai大模型LLMs 。发现、下载并运行本地 LLMs!
支持常见的Ai大模型
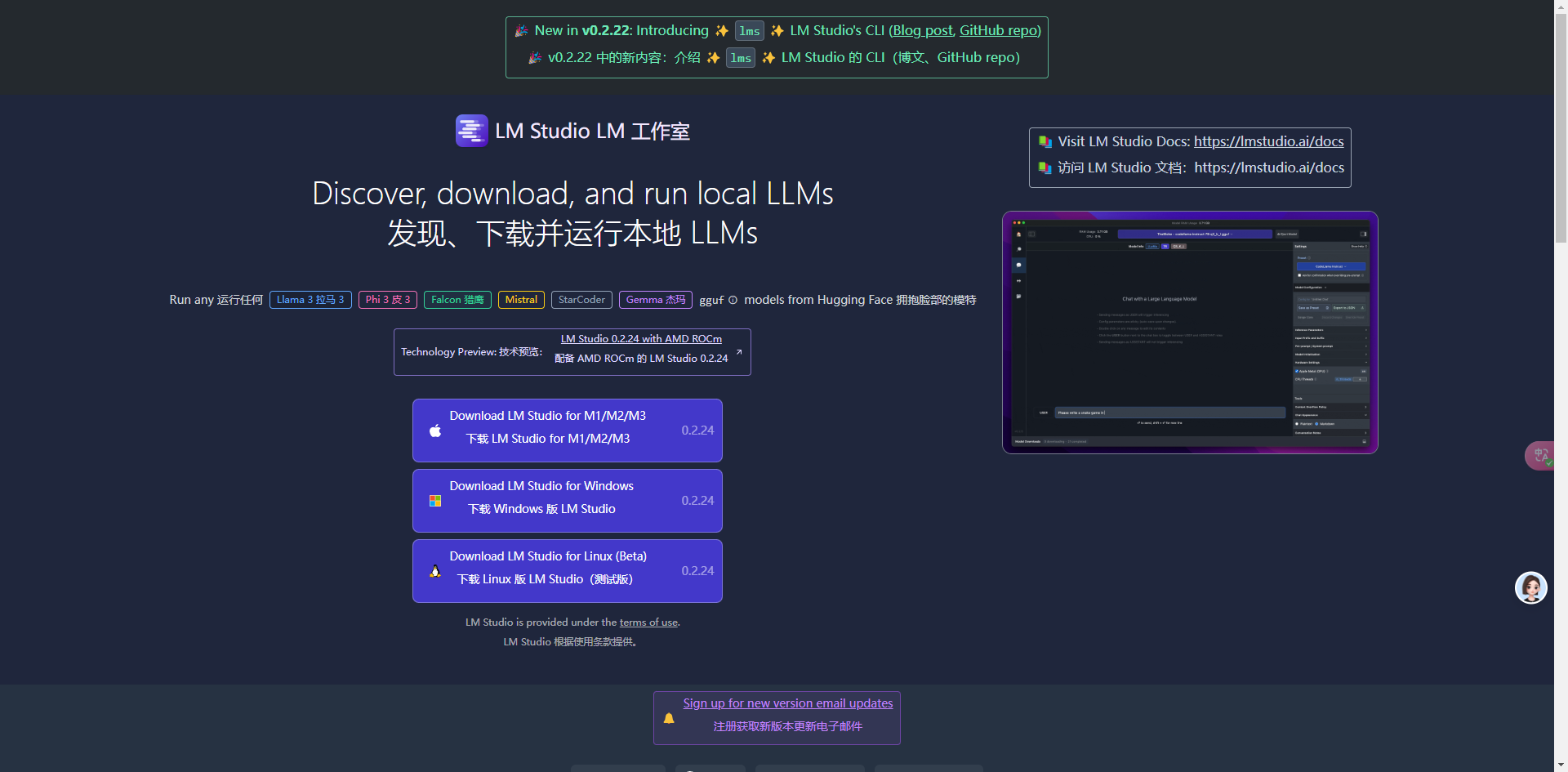
Llama 3
Phi 3
Falcon
Mistral
StarCoder
Gemma
3.1.安装教程(以window为例)
3.1.1.双击exe文件

3.1.2.点击仍要运行

3.1.3.自动安装完成


3.2.使用教程
3.2.1.桌面上找到LMstudio,双击运行

3.2.2.下载我们需要的模型(国内的小伙伴可能无法下载模型,我准备了一个模型)
以Llama 3为例演示!把我们的模型放到对应的文件夹中


注意:要在models下新建两级文件夹Publisher、Repository,模型文件放到Repository中

3.2.3.选择模型,开始对话


4.方案三:Ollama
本地启动并运行大型语言模型。支持运行 Llama 3、Phi 3、Mistral、Gemma 和其他模型。定制和创建您自己的模型。

4.1.安装教程
4.1.1.双击exe文件
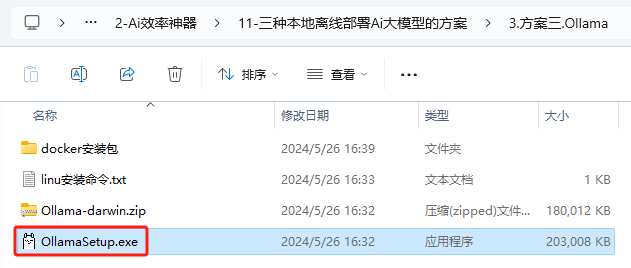
4.1.2.点击“Install”即可自动安装


4.1.3.安装完成

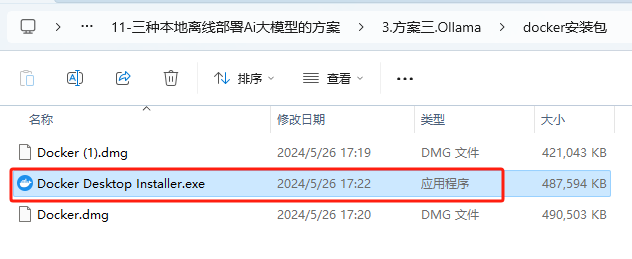
4.1.4.安装Docker
-
双击exe文件
-
点击ok等待安装完成


-
重启电脑

-
点击Accept

-
点击Finish

4.1.5.本地安装webUI
在CMD中安装,win+r,输入CMD即可
在CPU下运行:docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
在GPU下运行:docker run -d -p 3000:8080 --gpus=all -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollama

安装完成通过本地地址:http://127.0.0.1:3000 进行访问,看到下方页面说明安装成功!

4.2.使用教程
4.2.1.点击Sign up注册账号即可使用

4.2.2.下载我们想要的模型

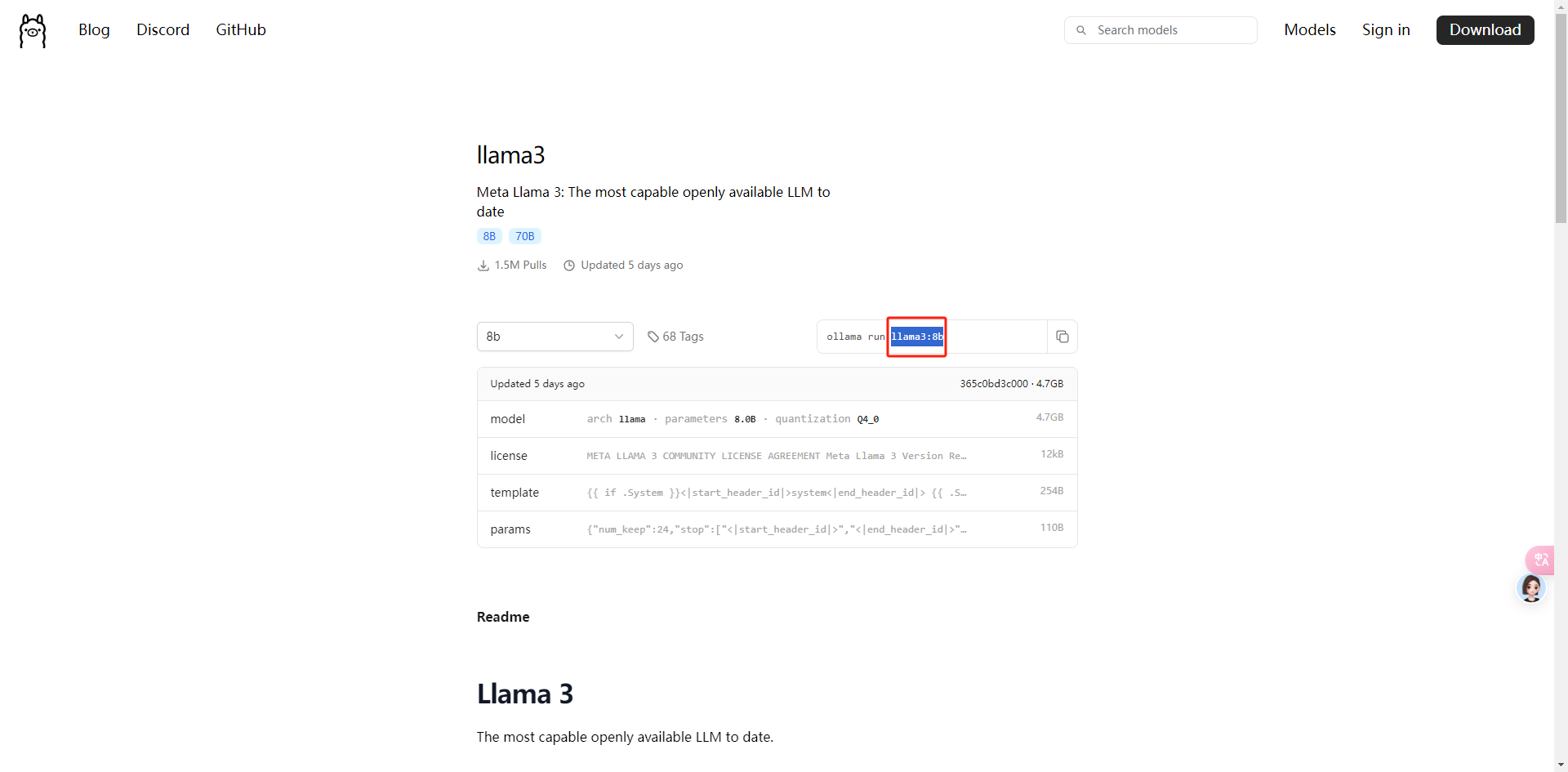

4.2.3.选择下载的模型,进行对话
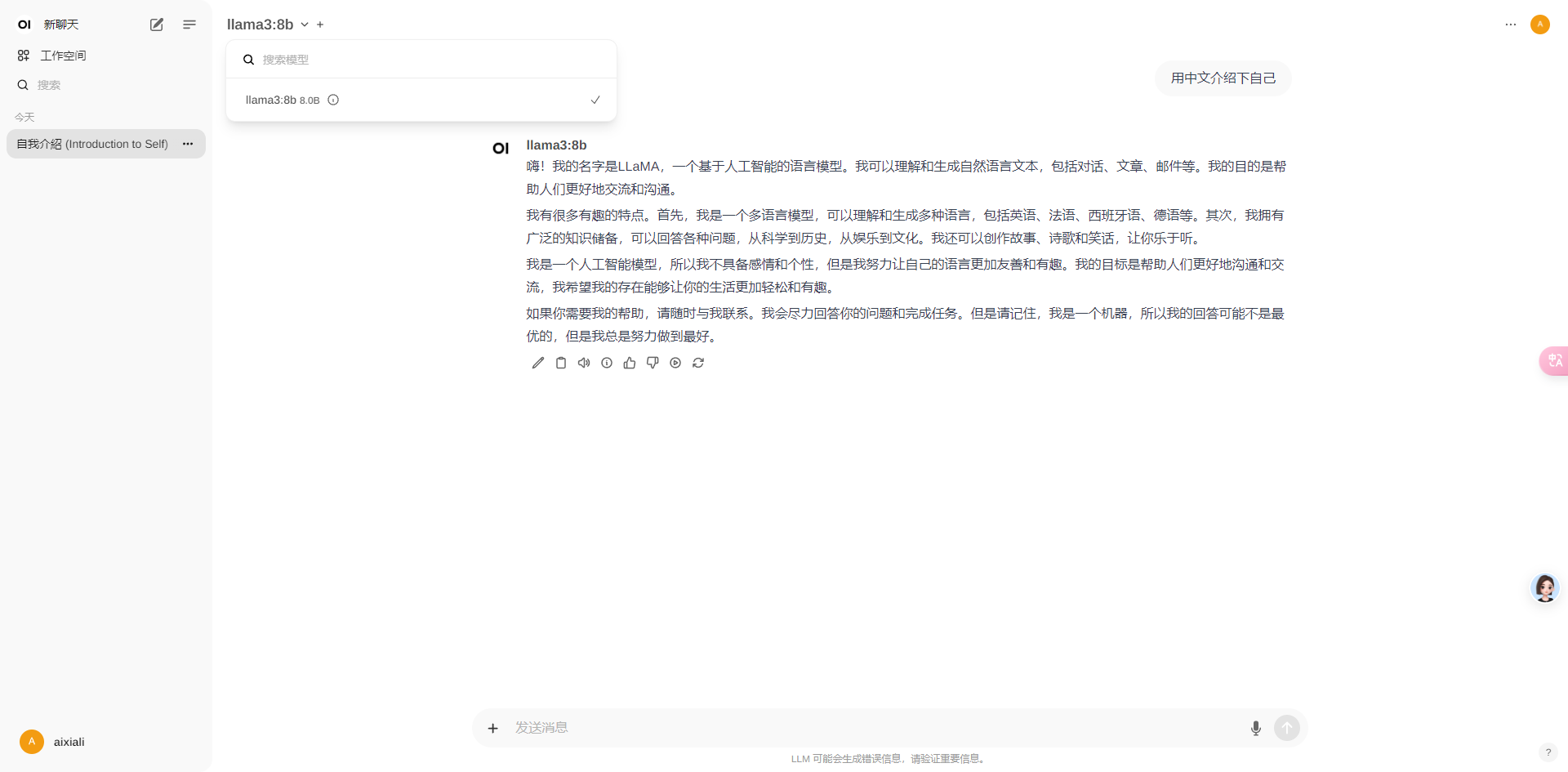
5.相关资料及模型领取地址