
- 1ELMO,BERT和GPT的原理和应用总结(李宏毅视频课整理和总结)_bert, elmo, and gpt
- 2Qt常见中文乱码问题解决方法总结_qt 中文乱码
- 3红蓝白三色球的排列,红色居前,白色居中,蓝色居后,算法设计,每个球只能查看一次_设有顺序放置的n个盒子,每个盒子装有一个颜色小球,小球颜色为红白蓝
- 4TDengine 发布主流时序数据库对比分析报告,与 InfluxDB、TimescaleDB 展开全面对比测试_clickhouse timescaledb 对比
- 5Redis数据迁移:方法一RDB_redis迁移rdb文件
- 6如何用Python实现一个简易的在线聊天机器人?_简单聊天机器人python
- 7neo4j数据库的创建简单的节点和关系_neo4j 创建节点
- 8AT32定时器-扩展32位计数器_at32 计数器
- 93D Gaussian Splatting 应用场景及最新进展【附10篇前沿论文和代码】_3d gaussian splatting论文
- 10本地部署Whisper Web结合内网穿透实现远程访问本地语音转文本模型
Java开发中有用的笔记_querywrapper inner join
赞
踩
笔记
一、lambda表达式
1. ::和->是什么
“::” 和 “->” 都是Java 8中引入的Lambda表达式的一部分,用于简化代码和增强语言的函数式编程能力。
“::” 符号通常称为“方法引用”,用于引用已有的方法或构造函数,并将其作为Lambda表达式的参数。具体来说,方法引用可以将方法名和参数列表与类或对象的名称分开,以简化代码和提高可读性。方法引用的形式有以下几种:
- 引用静态方法:ClassName::staticMethodName
(x) -> ClassName.staticMethodName(x)
- 1
可以使用静态方法引用的方式进行简化:
ClassName::staticMethodName
- 1
- 引用实例方法:instanceName::methodName
(x) -> instanceName.methodName(x)
- 1
可以使用实例方法引用的方式进行简化:
instanceName::methodName
- 1
- 引用构造函数:ClassName::new
() -> new ClassName()
- 1
可以使用构造函数引用的方式进行简化:
ClassName::new
- 1
- “->” 符号通常称为“Lambda箭头”,用于定义Lambda表达式的语法结构。具体来说,Lambda表达式由参数列表、箭头符号和表达式组成,例如:
(x, y) -> x + y
- 1
其中,参数列表指定Lambda表达式的参数,箭头符号 “->” 分隔参数列表和表达式,表达式则指定Lambda表达式要执行的操作。
(x, y) -> {
int sum = x + y;
System.out.println(sum);
}
- 1
- 2
- 3
- 4
可以理解为:
- 参数列表为 (x, y)
- 箭头符号 “->” 分隔参数列表和表达式
- 表达式为 { int sum = x + y; System.out.println(sum); }
需要注意的是,Lambda表达式和方法引用的使用都需要在Java 8及以上版本中才能实现。同时,还需要根据具体情况进行Lambda表达式的编写和调用,以确保代码的正确性和可读性。
2.foreach和.map
foreach 和 map 都是 Java 8 中的流操作,它们都可以帮助我们处理数据,但是它们有着明显的不同。
foreach 方法是一种遍历操作,它可以对流中的每一个元素执行某个操作,但是不会返回任何结果,它只是简单地对数据进行处理。
例如,我们有一个列表,列表中的每一个元素代表一个字符串,我们希望将列表中的所有字符串打印出来。我们可以使用 foreach 方法实现这个需求:
mathematicaCopy codeList<String> list = Arrays.asList("apple", "banana", "cherry");
list.stream().forEach(System.out::println);
- 1
- 2
map 方法是一种映射操作,它可以对流中的每一个元素执行某个操作,并将操作的结果作为新的流的元素。
例如,我们有一个列表,列表中的每一个元素代表一个整数,我们希望将列表中的每一个整数乘以 2,并得到一个新的列表。我们可以使用 map 方法实现这个需求:
mathematicaCopy codeList<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
List<Integer> result = list.stream().map(x -> x * 2).collect(Collectors.toList());
- 1
- 2
因此,foreach 和 map 都是 Java 8 中的流操作,它们都可以帮助我们处理数据,但是它们的目的和实现方式不同,需要根据具体的需求
map 方法与遍历的不同在于,它不仅仅遍历了流中的元素,还对每一个元素执行了一个操作,并将操作的结果作为新的流的元素。
因此,map 方法可以说是遍历,但是它不仅仅是遍历,它还是一种高效、易于使用、易于并行计算的数据处理方式。
总的来说,map 方法代表着一种将流中的元素进行处理,并将处理结果作为新的流的元素的操作。
3.可以用map代替foreach吗
般来说,map 方法不能代替 foreach 方法,因为它们的目的和实现方式不同。
foreach 方法是一种遍历操作,它可以对流中的每一个元素执行某个操作,但是不会返回任何结果,它只是简单地对数据进行处理。
而 map 方法是一种映射操作,它可以对流中的每一个元素执行某个操作,并将操作的结果作为新的流的元素。
因此,如果你需要遍历流中的元素,执行某个操作,但是不需要返回任何结果,那么应该使用 foreach 方法。如果你需要对流中的元素进行处理,并得到一个新的流,那么应该使用 map 方法。
二、金额计算
1. 在 Java 中,涉及到金额计算时,应该使用 BigDecimal 类型来确保精度和正确性。
BigDecimal 类型是一种高精度的数字类型,可以处理任意精度的十进制数,并提供了许多算术运算方法,例如加、减、乘、除、求余等等。与其他数字类型不同,BigDecimal 类型能够处理小数点后的任意位数,从而避免了浮点数计算时可能出现的舍入误差和精度丢失问题。
在处理金额时,由于金额通常需要精确到小数点后两位,因此使用 BigDecimal 类型可以保证计算结果的精度和正确性。同时,需要注意在创建 BigDecimal 对象时,应该使用字符串类型的构造方法,避免使用 double 或 float 类型转换而导致精度丢失。
List<PaymentInfoVO> list = ...; // 假设这是一个 PaymentInfoVO 类型的列表
BigDecimal totalAmount = list.stream()
.map(paymentInfoVO -> new BigDecimal(paymentInfoVO.getAmount()))
.reduce(BigDecimal.ZERO, BigDecimal::add);
System.out.println(totalAmount); // 输出 paymentInfoVO.getAmount() 的总和
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
在这个代码段中,我们使用 .map() 方法将每个 paymentInfoVO.getAmount() 的值转换为一个 BigDecimal 类型的对象,然后使用 .reduce() 方法计算它们的总和。其中,.map(paymentInfoVO -> new BigDecimal(paymentInfoVO.getAmount())) 表示将每个 paymentInfoVO.getAmount() 的值转换为一个 BigDecimal 类型的对象,.reduce(BigDecimal.ZERO, BigDecimal::add) 表示将所有 BigDecimal 类型的对象相加得到它们的总和,并使用 BigDecimal 类型来确保计算精度和正确性。最后,我们将结果保存在 totalAmount 变量中,并输出它的值。
总之,在处理金额计算时,使用 BigDecimal 类型可以确保计算结果的精度和正确性。如果要在 Stream 流中计算金额的总和,可以使用 .map() 方法将每个金额值转换为 BigDecimal 类型的对象,然后使用 .reduce() 方法计算它们的总和,并使用 BigDecimal 类型来确保计算精度和正确性。
2.BigDecimal.ZERO是什么
BigDecimal.ZERO 是 BigDecimal 类的一个静态常量,表示一个值为零的 BigDecimal 对象。
在使用 BigDecimal 类进行数值计算时,有时需要初始化一个初始值为零的 BigDecimal 对象,这时可以使用 BigDecimal.ZERO 来创建这个对象。例如:
BigDecimal number = BigDecimal.ZERO;
- 1
在这个例子中,我们使用 BigDecimal.ZERO 创建了一个值为零的 BigDecimal 对象,并将其赋值给 number 变量。由于 BigDecimal 类是不可变的,因此在对它进行运算或修改时,会返回一个新的 BigDecimal 对象,不会修改原始的 BigDecimal 对象。
因此,使用 BigDecimal.ZERO 可以方便地创建一个初始值为零的 BigDecimal 对象,并在 BigDecimal 类的计算中使用它。同时,由于 BigDecimal 类是高精度的十进制数类型,因此在处理数值计算时应该使用 BigDecimal 类型,并避免使用浮点数类型来确保计算结果的精度和正确性。
3.另外还有BigDecimal.ONE
是 BigDecimal 类的一个静态常量,表示一个值为 1 的 BigDecimal 对象。
在使用 BigDecimal 类进行数值计算时,有时需要初始化一个值为 1 的 BigDecimal 对象,这时可以使用 .ONE 来创建这个对象。例如:
BigDecimal number = BigDecimal.ONE;
- 1
4.乘法运算
在 Java 中,可以使用 BigDecimal 类型的 multiply() 方法来进行乘法运算。该方法接受一个 BigDecimal 类型的参数,表示要乘以的值,并返回一个新的 BigDecimal 对象,表示乘法运算的结果。
以下是一个示例代码,演示如何使用 BigDecimal 类型进行乘法运算:
BigDecimal num1 = new BigDecimal("12.34"); // 创建一个 BigDecimal 对象,表示第一个数值
BigDecimal num2 = new BigDecimal("5.67"); // 创建一个 BigDecimal 对象,表示第二个数值
BigDecimal result = num1.multiply(num2); // 使用 multiply() 方法进行乘法运算
System.out.println(result); // 输出乘法运算的结果
- 1
- 2
- 3
- 4
- 5
- 6
- 7
5.加减法
要进行加法和减法运算,可以使用BigDecimal类提供的add()和subtract()方法。
例如,如果要将availableAmount和settlementAmount相加,可以使用以下代码:
BigDecimal newAvailableAmount = availableAmount.add(settlementAmount);
如果要将willpayAmount和settlementAmount相减,可以使用以下代码:
BigDecimal newWillpayAmount = willpayAmount.subtract(settlementAmount);
在使用BigDecimal进行加减法运算时,需要注意以下几点:
- 必须使用BigDecimal的add()和subtract()方法进行运算,不要直接使用加减号。
- 进行运算的两个数必须都是BigDecimal类型的。
- 进行运算后会返回一个新的BigDecimal对象,原对象不会发生变化,因此需要将运算结果保存到一个新的BigDecimal对象中。
6.比较方法compareTo()
compareTo()方法是Java中Comparable接口的一个方法,用于比较两个对象的大小。在BigDecimal类中,这个方法用于比较两个BigDecimal对象的数值大小。
compareTo()方法的返回值如下:
- 当调用对象的数值小于传入参数对象的数值时,返回值为负数(通常是-1)。
- 当调用对象的数值等于传入参数对象的数值时,返回值为0。
- 当调用对象的数值大于传入参数对象的数值时,返回值为正数(通常是1)。
以下是一个使用compareTo()方法的简单示例:
import java.math.BigDecimal; public class BigDecimalCompareExample { public static void main(String[] args) { BigDecimal number1 = new BigDecimal("10.5"); BigDecimal number2 = new BigDecimal("20.5"); int comparisonResult = number1.compareTo(number2); if (comparisonResult < 0) { System.out.println("number1小于number2"); } else if (comparisonResult == 0) { System.out.println("number1等于number2"); } else { System.out.println("number1大于number2"); } } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
在这个示例中,我们创建了两个BigDecimal对象number1和number2,然后使用compareTo()方法对它们进行比较。根据返回值,我们可以确定它们之间的大小关系。
三、lambdaQueryWrapper语句
1.save和insert方法的区别
在 MyBatis-Plus 中,save 和 insert 方法都可以用来向数据库中插入一条新记录,但它们在使用上有以下几个区别:
- 参数类型不同:
save方法的参数类型是实体对象(Entity),而insert方法的参数类型是 Wrapper 对象或者实体对象(Entity)。 - 返回值不同:
save方法的返回值是一个 boolean 类型,表示插入操作是否成功,而insert方法的返回值是受影响的行数。 - 执行逻辑不同:
save方法会根据实体对象的主键属性是否有值来判断是插入还是更新操作,如果主键属性有值,就执行更新操作,否则执行插入操作;而insert方法只执行插入操作,不进行主键冲突检测。
因此,如果希望在插入新记录的同时进行主键冲突检测,可以使用 save 方法;如果只是简单地插入新记录,可以使用 insert 方法。
2.insert,add和save有什么区别
insert,add和save都是数据库操作中常用的用于插入数据的方法,不同的是在不同的数据库操作框架或者实现中可能有些许差异。
在一些ORM框架中,如Hibernate和MyBatis,它们的含义和用法如下:
- insert:insert是Hibernate和MyBatis中用于向数据库中插入数据的方法,用于将一个新的对象保存到数据库中。当使用Hibernate时,insert操作通常是通过Session的save()方法实现的;当使用MyBatis时,insert操作通常是通过Mapper接口的insert()方法实现的。
- add:add是Hibernate中用于向数据库中插入数据的方法,与insert类似,都是用于将一个新的对象保存到数据库中。不过,在Hibernate中,add操作通常是通过Session的persist()方法实现的。
- save:save是Hibernate中用于向数据库中插入数据的方法,与insert和add类似,都是用于将一个新的对象保存到数据库中。不过,在Hibernate中,save操作通常是通过Session的save()方法实现的,与insert的区别在于,save操作可以用于保存新的对象,也可以用于更新已经存在的对象。
需要注意的是,具体的操作方式和用法可能会因为具体的ORM框架或者实现而有所差异,因此在使用这些方法时,应该根据具体的情况进行使用和选择。
对于insert、add和save这三个方法,哪个更好需要根据具体的使用情况和需求进行选择。
一般来说,如果只是简单的插入一条新的记录,那么使用insert或add都可以,它们的实现方式和性能差异不大。但如果需要同时插入多条记录,或者需要支持一些高级的插入操作,那么就需要根据具体情况选择更为适合的方法。
在使用ORM框架时,一般建议使用ORM框架提供的方法进行操作,以便能够充分利用框架的特性和优化。但在某些特殊情况下,也可以考虑使用原生SQL语句进行操作,以获得更好的性能和控制力。
综上所述,需要根据具体的使用情况和需求进行选择,选择更为适合的方法。
3.除了以上三种方法外的其他插入方法
除了insert、add和save方法,还有其他一些更为适合的方法可以用于向数据库中插入数据,如:
- batch insert:批量插入是一种常见的向数据库中插入大量数据的方法,它通常比逐条插入数据要快得多。在使用ORM框架时,一般都会提供批量插入的支持,如Hibernate的batch插入。
- JDBC批量插入:使用JDBC进行批量插入是一种比较底层的方法,但是在插入大量数据时,性能通常会更好。在使用JDBC进行批量插入时,需要使用PreparedStatement和addBatch()方法。
- 使用存储过程:在一些特殊情况下,可以考虑使用存储过程来向数据库中插入数据。存储过程可以将多条SQL语句封装成一个过程,并在数据库中预编译和缓存,从而提高性能。
需要根据具体的使用情况和需求选择更为适合的方法,以获得更好的性能和控制力。
4.lambdaQueryWrapper中.eq和.in的区别
.eq方法是用于创建一个相等条件的查询,例如:
new LambdaQueryWrapper<User>().eq(User::getName, "John");
- 1
上面的代码表示在User表中查询所有名字等于"John"的记录。
.in方法则用于创建一个包含条件的查询,例如:
new LambdaQueryWrapper<User>().in(User::getId, Arrays.asList(1, 2, 3));
- 1
上面的代码表示在User表中查询所有id为1、2或3的记录。
因此,.eq用于创建单个条件,而.in用于创建多个条件。
五、方法
- eq:等于
- ne:不等于
- gt:大于
- ge:大于等于
- lt:小于
- le:小于等于
- between:区间
- notBetween:不在区间
- like:模糊匹配
- notLike:不模糊匹配
- likeLeft:左模糊匹配
- likeRight:右模糊匹配
- isNull:为空
- isNotNull:不为空
- in:在集合中
- notIn:不在集合中
如果你想通过姓名和身份证获取返回值,但是姓名和身份证不在一张表怎么办,你可能需要使用LambdaQueryWrapper的join方法来连接两张表,然后使用eq方法来指定查询条件。例如:
LambdaQueryWrapper wrapper = new LambdaQueryWrapper<>();
wrapper.join(User::getId, Staff::getUserId)// 连接User表和Staff表
.eq(User::getName, “张三”) // 查询姓名为张三
.eq(Staff::getIdCard, “123456789”); // 查询身份证为123456789
List list = userService.list(wrapper); // 获取返回值
.join方法是LambdaQueryWrapper中用于实现多表联查的方法,它可以指定要连接的表和连接条件,例如:
- wrapper.join(User::getDeptId, Dept::getId)表示连接User表和Dept表,条件是User.dept_id = Dept.id。
- wrapper.leftJoin(User::getDeptId, Dept::getId)表示左连接User表和Dept表,条件是User.dept_id = Dept.id。
- wrapper.rightJoin(User::getDeptId, Dept::getId)表示右连接User表和Dept表,条件是User.dept_id = Dept.id。
使用.join方法时,需要注意以下几点:
- .join方法只能用在自定义的mapper接口中,不能用在mybatis-plus提供的通用mapper接口中。
- .join方法需要配合.select方法来指定查询的字段,否则会报错。
- .join方法不支持嵌套查询或子查询,如果需要复杂的多表联查,请使用xml文件或注解方式。
5…apply方法
qwPayOrder
.ne( "rec_state" , 200 ) // 排除 rec_state 为 200 的 订单 这边加入了对时间的限制
.in("state", 60, 100) // 筛选 60 状态 和 100 状态 的 订单
.apply( "YEAR(update_time) = {0} AND MONTH(update_time) = {1}", year, month )
.select(
"IFNULL(SUM(CASE WHEN state = 100 THEN total_amount ELSE 0 END) + SUM(CASE WHEN state = 60 THEN total_amount - settled_amount ELSE 0 END), 0) as totalAmount",
"IFNULL(SUM(CASE WHEN state = 100 THEN total_service_amount ELSE 0 END) + SUM(CASE WHEN state = 60 THEN total_service_amount - settled_service_amount ELSE 0 END), 0) as totalServiceAmount",
"company_id"
)
.groupBy("company_id");
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
在这段代码中,apply 方法的作用是将传入的字符串参数应用到查询条件中。这里传入了一个字符串格式化表达式,其中 {0} 和 {1} 分别表示 year 和 month 参数,用来限定 update_time 的年份和月份。在实际查询时,year 和 month 会替换 {0} 和 {1},从而构成查询条件。例如,如果 year 为 2023,month 为 4,则查询条件为 YEAR(update_time) = 2023 AND MONTH(update_time) = 4。这样就实现了对 update_time 时间的限制。
四、数据库
1.索引
数据库索引是一种数据结构,用于快速查找数据库表中的数据。它是数据库管理系统(DBMS)用来优化查询性能的重要工具之一。通过在数据库表的一个或多个列上创建索引,可以显著提高查询效率,特别是在数据量较大时。索引可以是唯一的,也可以不是唯一的,取决于在创建索引时是否强制唯一性。在查询时,DBMS使用索引来定位需要的数据行,而不是扫描整个表,从而提高了查询效率。然而,索引也会占用额外的存储空间,并增加数据修改的成本,因此需要权衡索引的使用。

这是三个数据库表的索引信息:
- employer_id
company_idASC NORMAL BTREE:表示在该表中建立了一个名为 “employer_id” 的索引,该索引按照 “company_id” 字段的升序进行排序,索引类型是 BTREE。(BTREE 是一种数据库索引类型,它是一种平衡树结构的实现,用于加快数据库表中数据的查询速度。索引是一种数据结构,能够在进行查询时快速地定位到满足特定条件的数据。BTREE 索引使用一种基于二分查找的算法,将数据按照一定的规则保存在其中,并使用平衡树的思想减少搜索树的深度,快速找到需要的数据。这种索引类型通常用于数据量较大的表中,因为它可以显著地提高查询效率,并且对于定期更新的表也具有较高的效率。) - bank_main_account_id
bank_main_account_idASC NORMAL BTREE:表示在该表中建立了一个名为 “bank_main_account_id” 的索引,该索引按照 “bank_main_account_id” 字段的升序进行排序,索引类型是 BTREE。 - public_id
public_idASC NORMAL BTREE:表示在该表中建立了一个名为 “public_id” 的索引,该索引按照 “public_id” 字段的升序进行排序,索引类型是 BTREE。
索引是数据库中用于快速查找和排序数据的一种数据结构。它可以提高数据检索的速度和效率,尤其是当数据量很大时。
2.ACS
ACS是索引的一种类型,表示使用了“自适应哈希索引”(Adaptive Hash Indexing)的优化技术。在数据库中,ACS索引类型通常用于高并发的查询操作,能够显著提高查询效率。
在MySQL中,索引默认是升序的,所以这里的ASC可以省略不写。如果要定义为降序,则需要写DESC。
3.外键约束

这是一个数据库外键约束,约束名为
bank_main_account_ibfk_1,表示在bank_main_account表中有一个外键park_id,它引用了park表的主键id。约束条件为RESTRICT,表示当park表中被引用的主键记录被删除或更新时,会阻止在bank_main_account表中的外键记录被删除或更新。具体来说,当试图删除或更新park表中的一个主键记录时,如果在bank_main_account表中存在引用该主键记录的外键记录,则该操作将被拒绝并抛出一个异常。
4.@Transactional注解
- 在类上添加@Transactional注解会默认为此类中的所有public方法开启事务
- @Transactional注解只对public访问级别的方法有效,对于private、protected和默认访问级别的方法是不起作用的
- @Transactional注解的工作原理是在方法执行前开启一个事务,在方法执行结束后提交或回滚事务。因此,只有在被外部调用的public方法上使用@Transactional注解才有意义。而private方法通常只被类内部的其他方法调用,不会被外部调用,所以在private方法上使用@Transactional注解也没有意义。
- 如果在private方法中需要开启事务,可以考虑将该方法的逻辑提取到public方法中,然后在该public方法上添加@Transactional注解,以确保事务的一致性和完整性。
- 如果在public方法上添加注解,方法中调用了一个private方法,那么这个private方法不会开启事务
注意:当一个有 @Transactional 注解的 public 方法调用一个 private 方法时,private 方法会继承 public 方法的事务,它们属于同一个事务。也就是说,private 方法不会单独开启新的事务,但它会成为调用它的 public 方法事务的一部分。
5.事务
-
在Spring框架中,事务指的是一组数据库操作,这些操作要么全部执行成功,要么全部执行失败,确保了数据库操作的一致性和完整性。
具体来说,事务通常涉及到数据库的增、删、改等操作,这些操作需要在同一个事务中进行,以保证数据的一致性。如果一个事务中的任何一次数据库操作失败,整个事务都会被回滚,所有已经执行的操作都会被撤销,数据库恢复到事务执行前的状态。
因此,在需要对数据库进行多个操作的情况下,使用事务可以确保操作的原子性,以避免数据不一致的问题。而Spring框架提供的事务管理功能可以简化事务的处理,降低了代码的复杂度,提高了开发效率。
6.索引的唯一键

- "company_id"和"outer_order_no"是索引字段;
- "ASC"表示索引按升序排列;
- "UNIQUE"表示该索引是唯一索引,即"company_id"和"outer_order_no"组合在一起的值必须是唯一的;
- "BTREE"是索引类型,表示使用B-tree索引方法。
7.索引
在数据库中,通常有四种类型的索引,包括唯一索引、主键索引、Normal索引和全文索引。这些索引的作用如下:
- 唯一索引(UNIQUE):保证索引列中的值唯一。当插入或更新数据时,数据库会检查唯一索引是否存在相同的值,如果存在,则拒绝插入或更新操作。唯一索引可用于确保数据的完整性和减少重复数据。
- 主键索引:保证主键列中的值唯一。与唯一索引类似,但主键索引是一种特殊的唯一索引,用于标识表格中每一行数据的唯一性。主键索引可以提高查询效率,并且在许多数据库中是必需的。
- Normal索引:基于B-Tree数据结构实现,可用于加速等值查询和范围查询。Normal索引是最常用的索引类型之一,可以提高查询速度。
- 全文索引(FULLTEXT):用于在文本数据中进行关键字搜索。全文索引可用于加速文本搜索操作,例如在文章、博客等大量文本数据中搜索关键词。
综上所述,不同类型的索引都有其独特的作用和用途,您可以根据具体的数据需求选择适当的索引类型来提高数据库的性能和查询效率。
- 唯一索引(Unique Index):确保索引列中的值唯一,用于保证数据的完整性和减少重复数据。
- 主键索引(Primary Key Index):保证主键列中的值唯一,用于标识表格中每一行数据的唯一性。主键索引可以提高查询效率,并且在许多数据库中是必需的。
- Normal索引(B-Tree Index):基于B-Tree数据结构实现,可用于加速等值查询和范围查询。Normal索引是最常用的索引类型之一,可以提高查询速度。
- 全文索引(Full-text Index):用于在文本数据中进行关键字搜索。全文索引可用于加速文本搜索操作,例如在文章、博客等大量文本数据中搜索关键词。
8.多表联查以及数据库优化
多表联查确实可能对性能产生影响,特别是当表中数据量很大时。这里有一些方法可以帮助避免或优化多表联查的性能问题:
-
选择性地查询所需列:尽量只查询所需的列,而不是使用 SELECT * 从每个表中获取所有列。
-
使用索引:确保在查询中涉及的所有表上都创建了合适的索引。这可以帮助数据库快速查找需要的数据,从而提高查询性能。
-
使用 INNER JOIN 代替 OUTER JOIN:在可能的情况下,尽量使用 INNER JOIN 代替 OUTER JOIN。INNER JOIN 通常比 OUTER JOIN 更快,因为它只返回匹配的行。
-
减少表的连接数:在可能的情况下,尝试减少查询中涉及的表的数量。例如,如果可以通过子查询或临时表的方式减少表的连接数,这可能有助于提高查询性能。
-
优化 WHERE 子句:对 WHERE 子句进行优化,例如使用 AND 而不是 OR,避免使用 NOT IN,使用 EXISTS 或 NOT EXISTS 代替。
-
优化查询顺序:尝试调整查询中的表连接顺序,以便先过滤掉更多的无关数据。这样可以减少后续连接操作的计算量。
-
分页查询:如果查询结果集很大,可以考虑使用 LIMIT 和 OFFSET 子句进行分页查询,每次只返回一部分数据。这样可以减轻数据库负担并提高用户体验。
-
使用数据库优化器的建议:大多数数据库系统都有查询优化器,可以分析查询并提供优化建议。根据优化器的建议调整查询,以提高查询性能。
-
将计算移到应用程序中:在某些情况下,可以考虑将一部分计算从数据库查询中移出,将其移到应用程序代码中。这可以减轻数据库的负担,但可能会增加应用程序的复杂性。
-
物化视图:对于经常需要执行的复杂查询,可以考虑使用物化视图。物化视图是预先计算好的查询结果集,可以大大提高查询性能。但请注意,物化视图需要定期更新以保持数据的实时性。
请注意,优化查询性能是一个复杂的过程,可能需要根据具体的查询和数据库系统进行调整。在进行优化时,请务必确保查询的正确性和数据的一致性。
五、TypeReference类
1.用法
在Java中,如果需要将JSON字符串转换成Java对象,通常可以使用ObjectMapper类来实现。ObjectMapper类是Jackson库中的一个核心类,可以将JSON字符串转换成Java对象,并将Java对象转换成JSON字符串。
在转换JSON字符串时,通常需要使用Java的泛型来指定转换后的数据类型。但是,如果只是简单地使用泛型,可能会出现类型擦除的问题,导致转换失败。为了避免这种问题,可以使用TypeReference类来获取map中的数据类型,确保转换的正确性。
TypeReference类是Jackson库中的一个工具类,可以用来获取泛型类型的具体类型。例如,在将JSON字符串转换成Map<String, Object>类型时,可以使用以下代码:
ObjectMapper mapper = new ObjectMapper();
String jsonStr = "{\"key\":\"value\"}";
Map<String, Object> map = mapper.readValue(jsonStr, new TypeReference<Map<String, Object>>() {});
- 1
- 2
- 3
- 4
在这个示例中,使用TypeReference类来获取Map<String, Object>类型的具体类型,然后将JSON字符串转换成该类型的对象。这样可以确保转换的正确性,避免类型擦除的问题。
在上面的示例中,也使用了TypeReference类来获取map中的数据类型,具体代码如下:
Map<String, Object> map = mapper.readValue(requestAckData, new TypeReference<Map<String, Object>>() {});
- 1
在将JSON字符串转换成Map<String, Object>类型的对象时,使用了TypeReference类来获取该类型的具体类型,避免了类型擦除的问题,保证了转换的正确性。
因此,TypeReference类可以用来获取泛型类型的具体类型,确保转换的正确性,避免类型擦除的问题。
六、在pom文件里面添加个人profile
1.在pom.xml文件中添加个人profile,可以通过以下步骤完成:
- 在pom.xml文件中添加一个标签,用于定义不同的profile配置。
<profiles>
<profile>
<!-- 个人profile的id -->
<id>myprofile</id>
<!-- 个人profile的配置 -->
<properties>
<my.property>myvalue</my.property>
</properties>
</profile>
</profiles>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 在标签下的标签中添加标签,并指定个人profile的id。
<build>
<plugins>
<plugin>
<groupId>com.example</groupId>
<artifactId>my-plugin</artifactId>
<version>1.0</version>
<!-- 指定个人profile的id -->
<profiles>
<profile>myprofile</profile>
</profiles>
</plugin>
</plugins>
</build>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 在命令行中执行maven命令,指定使用个人profile的id来编译项目。
mvn clean install -Pmyprofile
- 1
七、关于Http请求
//默认头信息,创建自定义的httpclient对象
List<Header> defaultHeaders=new ArrayList<Header>();
defaultHeaders.add(new BasicHeader("Accept","text/html,application/xhtml+xml,application/xml,application/json;q=0.9,*/*;q=0.8"));
defaultHeaders.add(new BasicHeader("Accept-Language","zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2"));
defaultHeaders.add(new BasicHeader("Connection","close"));
defaultHeaders.add(new BasicHeader("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:59.0) Gecko/20100101 Firefox/59.0"));
defaultHeaders.add(new BasicHeader("Authorization", ""));
- 1
- 2
- 3
- 4
- 5
- 6
- 7

这段代码定义了HTTP请求的默认头部信息,具体含义如下:
- “Accept”: 表示客户端能够接收的响应类型,优先级从高到低依次是"test/html"、“application/xhtml+xml”、“application/xml”、“application/json”,最后是"/"。
- “Accept-Language”: 表示客户端能够接受的语言类型,优先级从高到低依次是"zh-CN"、“zh”、“zh-TW”、“zh-HK”、“en-US”、“en”。
- “Connection”: 表示请求完成后是否立即断开连接,这里设为"close"表示立即断开连接。
- “User-Agent”: 表示客户端的身份信息,这里设为"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:59.0) Gecko/20100101 Firefox/59.0",表示使用的是Firefox 59.0浏览器在Windows 10系统上。
八、String
1.为什么用append代替+=
在Java中,字符串是不可变的,也就是说,一旦字符串被创建,就不能再修改它。因此,如果需要对一个字符串进行拼接,通常会使用字符串拼接符“+”,将多个字符串拼接在一起。
但是,在循环中多次使用字符串拼接符“+”会导致性能问题,因为每次使用“+”时,都会创建一个新的字符串对象。如果需要对大量字符串进行拼接,会导致大量的对象创建和垃圾回收,从而影响程序的性能。
为了解决这个问题,可以使用Java中的StringBuilder或StringBuffer类。这两个类都是可变的字符串类,可以在不创建新对象的情况下对字符串进行修改和拼接。在循环中使用StringBuilder或StringBuffer类的append()方法可以显著提高程序的性能,因为它们只会创建一个StringBuilder或StringBuffer对象,并在每次迭代中修改该对象。
因此,使用StringBuilder或StringBuffer类的append()方法代替“+”符号可以提高程序的性能,特别是在需要对大量字符串进行拼接时。
九、项目
1.代发摘要
代发摘要是指在支付代发业务中,支付机构向代发企业发放的一份代表该企业本次代发工资的汇总信息,也称为“工资代发凭证”或“代发工资明细单”。
代发摘要通常包括以下信息:
- 代发企业名称和代发日期
- 员工姓名和身份证号码
- 工资发放金额及税前、税后工资明细
- 代扣项目,如社保、公积金等
- 实际发放金额及发放日期
代发摘要是代发企业和员工获取代发工资信息的重要渠道,同时也是代发支付机构进行账务核对的重要依据。代发企业和员工可通过代发摘要了解自己的工资发放情况,同时也可以及时发现和纠正发放错误,确保代发工资的准确性和及时性。
十、并发问题
1.如果有多个线程同时访问同一段代码块,可能会出现以下几种并发问题:
- 资源竞争:多个线程同时竞争同一资源(例如共享变量、文件、网络连接等),会导致数据不一致或程序出错。
- 死锁:多个线程互相等待对方释放锁的情况,导致程序无法继续执行。
- 饥饿:某些线程因为资源分配不足而无法继续执行,导致程序无法完成任务。
- 并发访问异常:多个线程同时访问同一数据结构,可能会导致数据结构出现异常,例如数组越界、链表死循环等。
以上并发问题都可能导致程序出错、运行缓慢或无法完成任务,因此在编写多线程程序时需要特别注意并发问题的处理。常见的处理方法包括使用锁机制、同步机制、线程池、消息队列等。
2.在Java中处理并发问题时,可以使用多种方法。这里列举了几种常见的处理方法,你可以根据自己的具体场景选择合适的方案。
- 使用线程池
线程池是一种创建和管理线程的机制,可以有效地控制并发线程的数量。使用线程池可以避免过多的线程创建导致的性能问题,同时可以降低资源消耗。
例如,你可以使用Java标准库中的ExecutorService和Executors类来创建线程池:
import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; public class ThreadPoolExample { public static void main(String[] args) { int poolSize = 10; ExecutorService executorService = Executors.newFixedThreadPool(poolSize); for (int i = 0; i < 100; i++) { executorService.execute(new Task()); } executorService.shutdown(); } static class Task implements Runnable { @Override public void run() { // 调用第三方接口 } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 使用同步代码块或同步方法
为了避免线程间的竞争,可以在调用第三方接口的关键部分添加同步代码块或同步方法。这可以确保每次只有一个线程能够访问共享资源。
同步代码块示例:
public class SynchronizedExample {
private final Object lock = new Object();
public void callApi() {
synchronized (lock) {
// 调用第三方接口
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
同步方法示例:
javaCopy codepublic class SynchronizedMethodExample {
public synchronized void callApi() {
// 调用第三方接口
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 使用信号量 (Semaphore)
信号量是一种同步工具,可以限制同时访问共享资源的线程数量。在Java中,可以使用java.util.concurrent.Semaphore类实现信号量。
import java.util.concurrent.Semaphore; public class SemaphoreExample { private final Semaphore semaphore = new Semaphore(10); public void callApi() { try { semaphore.acquire(); // 调用第三方接口 } catch (InterruptedException e) { e.printStackTrace(); } finally { semaphore.release(); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
以上方法都可以在一定程度上解决并发问题。你可以根据你的具体需求和场景选择合适的方法。同时,在使用第三方接口时,需要遵循接口提供商的限制和规范,确保在规定的频率范围内调用接口。
3.相关代码
package com.crestv.lgpt.config; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.scheduling.annotation.EnableAsync; import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor; import java.util.concurrent.Executor; import java.util.concurrent.ThreadPoolExecutor; @Configuration @EnableAsync public class AsyncConfig { @Bean public Executor initExecutor() { ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor(); executor.setCorePoolSize(80); executor.setMaxPoolSize(100); executor.setQueueCapacity(80); executor.setKeepAliveSeconds(60); executor.setThreadNamePrefix("ThreadPoolTaskExecutor- "); executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy()); executor.setWaitForTasksToCompleteOnShutdown(true); executor.setAwaitTerminationSeconds(60); executor.initialize(); return executor; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
这个配置中的参数含义如下:
- corePoolSize:线程池中的核心线程数,即线程池维护的最少线程数量。
- maxPoolSize:线程池中的最大线程数,即线程池维护的最多线程数量。
- queueCapacity:线程池中任务队列的容量,即可以等待执行的任务的数量。
- keepAliveSeconds:非核心线程的空闲存活时间,即当线程池中的线程数量超过核心线程数时,多余的空闲线程的存活时间。
- threadNamePrefix:线程池中线程的名称前缀。
- rejectedExecutionHandler:线程池的拒绝策略,即当任务无法被线程池执行时的处理方式。这里使用的是CallerRunsPolicy,表示由调用线程来执行该任务。
- waitForTasksToCompleteOnShutdown:是否等待所有任务执行完毕后再关闭线程池。
- awaitTerminationSeconds:等待线程池关闭的最大时间。
- executor.initialize():初始化线程池。
其中,corePoolSize就是线程池中的核心线程数,这里设置为80。当线程池中的任务数不超过80时,线程池中始终有80个线程在等待执行任务,即核心线程数不会变化。
十一、前端
1.写一个前端用于上传身份证
- 确保你已经安装了 Node.js 和 npm。你可以在这里下载和安装它们:https://nodejs.org/en/download/
- 使用 Vue CLI 创建一个新的 Vue.js 项目(如果你已经有一个现有的项目,可以跳过此步骤):
npm install -g @vue/cli
vue create my-project
cd my-project
- 1
- 2
- 3
替换 “my-project” 为你的项目名称。
创建好的项目如下:

- 将上述代码粘贴到一个新的
.vue文件中,例如:IDCardUpload.vue。将此文件放入项目的src/components文件夹中。 - 在你的项目中安装 axios 库,用于发送 HTTP 请求:
npm install axios
- 1
- 在你的项目中的
src/main.js文件中,引入 axios 并将其添加到 Vue 原型上:
import axios from 'axios';
import Vue from 'vue';
Vue.prototype.$axios = axios;
// 其他代码保持不变
- 1
- 2
- 3
- 4
- 5
- 6
- 在你的项目的
src/App.vue文件中,引入并使用刚刚创建的IDCardUpload组件:
<template>
<div id="app">
<IDCardUpload />
</div>
</template>
<script>
import IDCardUpload from './components/IDCardUpload.vue';
export default {
components: {
IDCardUpload,
},
};
</script>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 在项目根目录下运行以下命令启动开发服务器:
npm run serve
- 1
现在你可以在浏览器中打开 http://localhost:8080,看到你的 Vue.js 项目正在运行,同时包含了刚刚创建的 IDCardUpload 组件。在这个组件中,你可以选择一个身份证图片并点击 “提交” 按钮上传至后端。
注意:请根据你的实际需求替换代码中的后端接口地址。
2.Vue.js 项目中的各个模块功能
<template>:这个模块定义了 Vue 组件的 HTML 结构。它包含了组件的布局、样式和数据绑定等内容。在<template>中,你可以使用 Vue 指令、过滤器等功能。<script>:这个模块包含了 Vue 组件的 JavaScript 代码。在这里,你可以定义组件的数据、方法、计算属性、生命周期钩子等。它是 Vue 组件的逻辑部分。<style>:这个模块包含了 Vue 组件的 CSS 样式。你可以使用普通 CSS,也可以使用预处理器(如 SCSS、LESS 等)。如果你想让样式仅作用于当前组件,可以在<style>标签中添加scoped属性。main.js:这是 Vue.js 项目的入口文件。在这个文件中,通常会导入 Vue.js 框架、根组件、路由器(如果使用了 vue-router)、Vuex(如果使用了状态管理库)等,并创建一个 Vue 实例来挂载到 HTML 页面中。router.js或router/index.js:如果你的项目使用了 vue-router,那么这个模块将负责定义和配置路由规则。在这里,你可以设置各个页面组件的路径、导航守卫等。store.js或store/index.js:如果你的项目使用了 Vuex 进行状态管理,那么这个模块将负责定义全局状态、mutations、actions 和 getters。你可以在这里编写处理全局状态的逻辑。components文件夹:这个文件夹通常包含了项目中的所有 Vue 组件。组件可以是页面级别的,也可以是更小的可复用组件。通常我们会按照组件的功能和层次将它们组织在不同的子文件夹中。
3.关于App.vue
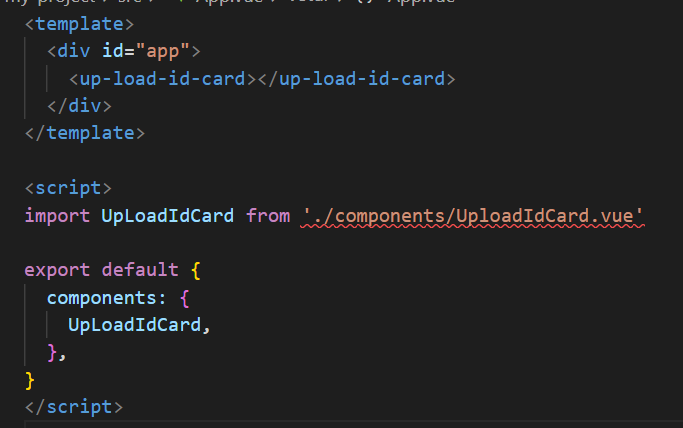
在这段代码中,是一个自定义Vue组件的标签,表示使用了名为“up-load-id-card”的Vue组件。尽管在这个标签中没有具体的代码,但它仍然实现了组件的注册和使用。
具体实现方面,该组件的具体实现在其他文件中,例如UploadIdCard.vue文件中。在该文件中,部分定义了组件的模板,
通过在父组件中使用标签,实现了将该组件渲染到父组件的模板中,并使得该组件的JavaScript代码被执行。这样,该组件就实现了上传身份证图片的功能,即选择图片、提交图片和将图片上传到指定的URL。
4.跨域
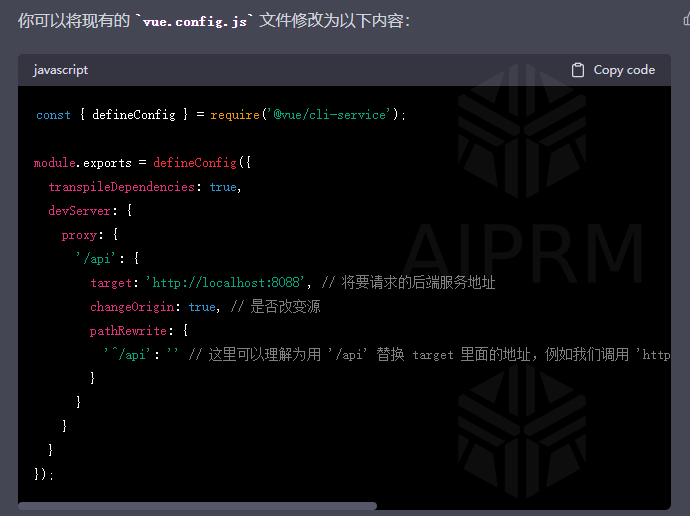
在上面的 vue.config.js 配置文件中,我们添加了一个 devServer 配置,用于配置开发服务器。主要修改的部分是添加了一个代理(proxy),这个代理会拦截以 ‘/api’ 开头的请求,并将其转发到指定的后端服务器。
关于各个配置项的解释如下:
/api: 此处定义的是需要代理的请求路径,以/api开头的请求都会被代理。target: 代理的目标服务器地址,即你的后端服务器地址。在本例中,目标服务器地址是http://localhost:8088。changeOrigin: 是否更改请求源。设置为true时,请求头中的Host会被设置为target的值。这样做可以避免跨域问题。pathRewrite: 路径重写规则。在本例中,我们将 ‘^/api’ 替换为空字符串。这意味着,当你访问http://localhost:8080/api/upload时,实际上请求的是http://localhost:8088/upload。这样,我们可以在不修改后端接口的情况下,通过前端配置实现跨域请求。
相关代码:
@Bean
CorsConfigurationSource corsConfigurationSource() {
UrlBasedCorsConfigurationSource source = new UrlBasedCorsConfigurationSource();
CorsConfiguration config = new CorsConfiguration();
config.setAllowCredentials(true);
List<String> orginList = Arrays.asList(StringUtils.split(origin, ",").clone());
config.setAllowedOriginPatterns(orginList);
config.setAllowedMethods(Arrays.asList("*"));
config.setAllowedHeaders(Arrays.asList("*"));
config.setMaxAge(Duration.ofHours(1));
source.registerCorsConfiguration("/**",config);
return source;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
这个方法创建了一个 CorsConfigurationSource Bean,用于定义 CORS 配置。配置允许所有的请求方法(GET、POST、PUT 等)和请求头,并允许接收带有凭证(cookies 等)的请求。origin 属性从配置文件中获取,表示允许的跨域请求来源。
5.上传身份证组件作用
<script> export default { data() { return { idCardImage: null, } }, methods: { onFileChange(event) { const file = event.target.files[0] const reader = new FileReader() reader.onload = (e) => { this.idCardImage = e.target.result } reader.readAsDataURL(file) }, async submit() { if (!this.idCardImage) { alert('请先选择图片') return } try { const response = await this.$axios.post( 'http://localhost:8088/api/upload', JSON.stringify(this.idCardImage) ) console.log(response) } catch (error) { console.error(error) } }, }, } </script>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
data():一个函数,返回组件的初始数据。这里定义了一个变量idCardImage,初始值为null,用于存储用户选择的图片。methods:一个对象,包含组件的方法。这里有两个方法:onFileChange和submit。onFileChange(event):当用户选择图片时触发的事件处理函数。它获取选中的文件,然后使用FileReader对象读取文件内容。当读取操作完成时,reader.onload事件处理函数被调用,将读取到的图片数据(Base64 编码)赋值给idCardImage。submit():提交按钮的点击事件处理函数。首先检查idCardImage是否有值,如果没有值则弹出提示让用户先选择图片。然后使用 Vue 的$axios方法发送 POST 请求,将图片数据(this.idCardImage)作为请求体发送到服务器(http://localhost:8088/api/upload)。请求成功后,控制台输出响应数据,如果出现错误,则在控制台输出错误信息。
6.前端框架react
1.
十二、限流
private final LoadingCache<String, RateLimiter> requestCaches = CacheBuilder.newBuilder()
.maximumSize(1000)
.expireAfterWrite(1, TimeUnit.MINUTES)
.build(new CacheLoader<String, RateLimiter>() {
@Override
public RateLimiter load(String appId) {
return rateLimiterRegistry.rateLimiter(appId);
}
});
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这段代码实现了一个LoadingCache缓存,用于存储每个appId对应的RateLimiter实例。在请求到来时,可以通过LoadingCache快速获取到对应的RateLimiter实例,从而进行限流操作。
具体来说,该缓存使用了Google Guava的CacheBuilder实现,设置了缓存的最大容量为1000,缓存的有效期为1分钟。在缓存中不存在对应的RateLimiter实例时,会使用CacheLoader来加载这个实例,具体的实现是使用rateLimiterRegistry从已经预定义好的RateLimiter配置中获取一个特定的RateLimiter实例,并将其缓存起来。
这个LoadingCache的作用是提高应用程序的性能和响应速度,同时降低限流操作的复杂度和时间成本。通过缓存RateLimiter实例,可以减少重复的限流器创建和销毁操作,提高限流器的复用性和效率。同时,该缓存还可以根据设定的有效期和缓存容量,自动清除已经过期或不再需要的缓存,避免资源浪费和内存泄露的问题。
//appid限流
return getRateLimiter(appId).executeSupplier(() -> {
try {
return joinPoint.proceed();
} catch (Throwable e) {
log.error(e.getMessage());
}
return null;
});
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这段代码是一个限流器的执行方法,它使用了RateLimiter实例来控制请求速率。getRateLimiter(appId)会从LoadingCache中获取appId对应的RateLimiter实例,如果实例不存在则会新建一个。executeSupplier方法会使用获取到的RateLimiter实例来执行传入的Supplier接口,其中Supplier接口的具体实现是通过lambda表达式传入的。
在这个Supplier接口中,首先调用joinPoint.proceed()方法来执行被注解@RateLimit修饰的方法,即切入点方法。如果执行过程中发生异常,则会捕获并使用log.error输出异常信息。最终返回值为null。
executeSupplier方法会根据RateLimiter的限流规则来决定是否执行Supplier接口中的代码,如果限流器未达到限制,则会执行Supplier接口中的代码,并返回执行结果;否则将抛出异常并拒绝执行Supplier接口中的代码。如果在执行Supplier接口的过程中出现异常,限流器也会拒绝执行并抛出异常。
这段代码的作用是在限制请求速率的同时,也确保了请求的正常执行。当请求速率超过限制时,它会拒绝执行,并防止系统过载,从而保证了系统的稳定性和可靠性。
十三、Redis
1.Redis五中数据类型
- String String是Redis最基本的数据类型,它是二进制安全的,可以存储任何格式的数据,如图片、序列化的对象等。在Redis中,String类型的值最大可以达到512MB。
- List List是一个链表结构,它支持从链表的两端进行元素的插入和删除操作。Redis中的List类型可以用来做队列、栈等数据结构。
- Set Set是一个无序的集合,集合中的元素不可重复。Redis中的Set类型可以用来做全局去重、共同好友等应用场景。
- Hash Hash是一个键值对集合,其中的每个键都对应一个值。在Redis中,Hash类型可以用来存储一些结构化的数据,如用户信息、文章信息等。
- Sorted Set Sorted Set是一个有序的集合,集合中的元素可以按照分数进行排序。Redis中的Sorted Set类型可以用来做排行榜、计分板等应用场景。
每个数据类型都有对应的操作命令,如String类型有get、set、incr等命令,List类型有lpush、rpush、lrange等命令,Set类型有sadd、srem、smembers等命令,Hash类型有hget、hset、hmget等命令,Sorted Set类型有zadd、zrange、zscore等命令。
十四、切面
1.以实现限流方法为例
新建一个注解
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
public @interface RateLimit {
}
- 1
- 2
- 3
- 4
切入点:
@Pointcut("@annotation(com.crestv.lgpt.config.annotation.RateLimit)")
public void pointcut() {
}
- 1
- 2
- 3
@Pointcut 是一个AOP注解,用于定义切入点,可以理解为一个方法签名,被该注解标注的方法可以在其他方法中作为一个切入点引用。
在上述代码中,@Pointcut("@annotation(com.crestv.lgpt.config.annotation.RateLimit)") 定义了一个切入点,表示所有被@RateLimit注解标注的方法都是切入点。当程序运行到切入点时,切面会被激活,并执行其中定义的逻辑。在本例中,切面会对传入的参数进行处理,然后进行限流处理。
使用@Pointcut定义切入点的好处在于,它可以让多个切面共用同一个切入点,从而避免代码重复。另外,使用注解来定义切入点也可以使代码更加简洁易读,增加代码的可维护性。
最后在方法上添加:
@Around("pointcut()")
- 1
@Around 是一个AOP注解,用于定义环绕通知。它可以用来修饰一个方法,使该方法成为一个环绕通知。
除了 @Around 之外,AOP还有其他几种通知类型,包括:
@Before:前置通知,该注解修饰的方法会在目标方法执行之前被执行。@AfterReturning:后置通知,该注解修饰的方法会在目标方法返回之后被执行。@AfterThrowing:异常通知,该注解修饰的方法会在目标方法抛出异常之后被执行。@After:最终通知,该注解修饰的方法会在目标方法执行结束之后被执行,无论是否抛出异常都会执行。
这几种通知类型的作用和执行顺序如下:
-
1、
Spring 4或Spring Boot 1.x正常执行
正常执行顺序为:
(1)
@Around(环绕通知)(2)
@Before(前置通知)(3)执行方法逻辑
(4)
@Around(环绕通知)(5)
@After(后置通知)(6)
@AfterReturning(返回后通知)异常执行
异常执行顺序为:
(1)
@Around(环绕通知)(2)
@Before(前置通知)(3)执行方法逻辑
(4)
@After(后置通知)(5)
@AfterThrowing(方法异常通知)(6)抛出异常
2、
Spring 5或Spring Boot 2.x正常执行
正常执行顺序为:
(1)
@Around(环绕通知)(2)
@Before(前置通知)(3)执行方法逻辑
(4)
@AfterReturning(返回后通知)(5)
@After(后置通知)(6)
@Around(环绕通知)异常执行顺序为:
异常执行
(1)
@Around(环绕通知)(2)
@Before(前置通知)(3)执行方法逻辑
(4)
@AfterThrowing(方法异常通知)(5)
@After(后置通知)(6)抛出异常
Spring 4或Spring Boot 1.x:环绕通知执行完了后,然后再执行后置通知,最后执行的是返回后通知或者方法异常通知。Spring 5或Spring Boot 2.x:环绕通知就真的如其名一样环绕着所有通知,并且最后执行的变成了后置通知了,返回后通知或者方法异常通知在后置通知之前执行了。
package com.crestv.lgpt.config.annotation; import com.alibaba.fastjson.JSONObject; import com.crestv.lgpt.dto.Result; import com.crestv.lgpt.utils.HttpUtil; import com.crestv.lgpt.config.RedisKeyUtil; import com.crestv.lgpt.utils.RedisUtil; import com.crestv.lgpt.utils.digest.AesSignUtil; import com.crestv.lgpt.utils.digest.SignatureUtils; import com.crestv.lgpt.vo.BaseOutVo; import com.crestv.lgpt.vo.outer.OuterRequestVo; import com.crestv.lgpt.vo.outer.ReqDataVo; import com.crestv.lgpt.vo.outer.OuterDataVo; import com.google.common.cache.CacheBuilder; import com.google.common.cache.CacheLoader; import com.google.common.cache.LoadingCache; import io.github.resilience4j.ratelimiter.RateLimiter; import io.github.resilience4j.ratelimiter.RateLimiterRegistry; import lombok.extern.slf4j.Slf4j; import org.apache.commons.lang3.ObjectUtils; import org.aspectj.lang.ProceedingJoinPoint; import org.aspectj.lang.annotation.Around; import org.aspectj.lang.annotation.Aspect; import org.aspectj.lang.annotation.Pointcut; import org.springframework.stereotype.Component; import javax.annotation.Resource; import javax.servlet.http.HttpServletRequest; import java.util.Arrays; import java.util.Map; import java.util.Optional; import java.util.concurrent.TimeUnit; @Slf4j @Aspect @Component public class RateLimitAspect { @Resource private RateLimiterRegistry rateLimiterRegistry; @Resource private RedisUtil redisUtil; @Resource private HttpUtil httpUtil; // 验签方法还需修改 todo 想法,不需要用户再传签名密钥和加密密钥,只要正常传数据即可,进行验签即可判断签名密钥是否正确,加密密钥同理 private final LoadingCache<String, RateLimiter> requestCaches = CacheBuilder.newBuilder() .maximumSize(1000) .expireAfterWrite(1, TimeUnit.MINUTES) .build(new CacheLoader<String, RateLimiter>() { @Override public RateLimiter load(String appId) { return rateLimiterRegistry.rateLimiter(appId); } }); @Pointcut("@annotation(com.crestv.lgpt.config.annotation.RateLimit)") public void pointcut() { } @Around("pointcut()") public Object around(ProceedingJoinPoint joinPoint) throws Exception { Optional<Object> optional = Arrays.stream(joinPoint.getArgs()) .filter(arg -> arg instanceof OuterRequestVo) .findFirst(); OuterRequestVo vo = optional.isPresent() ? (OuterRequestVo) optional.get() : null; //获取客户端所有信息 HttpServletRequest request = httpUtil.getRequest(); //获取客户端ip地址 String ipAddr = httpUtil.getRequestIP(request); String appId = vo.getAppId(); //appid限流 return getRateLimiter(appId).executeSupplier(() -> { try { return joinPoint.proceed(); } catch (Throwable e) { log.error(e.getMessage()); } return null; }); } private RateLimiter getRateLimiter(String appId) { if (null == requestCaches.getIfPresent(appId)) { requestCaches.put(appId, rateLimiterRegistry.rateLimiter(appId)); } RateLimiter rateLimiter = requestCaches.getIfPresent(appId); return null != rateLimiter ? rateLimiter : rateLimiterRegistry.rateLimiter(appId); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
配置为:
# 每个周期限制访问量
ratelimit.limitForPeriod=5
# 刷新周期 秒
ratelimit.limitRefreshPeriod=1
# 线程等待时间 秒
ratelimit.timeoutDuration=1
- 1
- 2
- 3
- 4
- 5
- 6
这段代码是一个基于AOP的限流切面,用于对带有@RateLimit注解的方法进行限流。执行流程如下:
- 定义@RateLimit注解;
- 定义pointcut()方法,用于匹配带有@RateLimit注解的方法;
- 定义around()方法,用于在方法执行前后对方法进行限流;
- 使用guava的LoadingCache实现对不同appId的请求进行限流;
- 在around()方法中,通过HttpServletRequest获取请求的ip地址,以及从参数中获取请求的appId;
- 通过getRateLimiter()方法获取对应的限流器进行限流,并执行被切入方法;
- 若限流器被限流,则返回null,不执行被切入方法。
2.实现获取appId和限流进行解耦
1.新建注解
package com.crestv.lgpt.config.annotation;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface AppId {
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2.创建切面
package com.crestv.lgpt.config.annotation; import com.crestv.lgpt.vo.outer.OuterRequestVo; import org.aspectj.lang.ProceedingJoinPoint; import org.aspectj.lang.annotation.Around; import org.aspectj.lang.annotation.Aspect; import org.aspectj.lang.annotation.Pointcut; import org.springframework.stereotype.Component; import javax.annotation.Resource; @Aspect @Component public class AppIdAspect { @Resource private RateLimitAspect rateLimitAspect; /** * 获取appid切点 */ @Pointcut("@annotation(com.crestv.lgpt.config.annotation.AppId) && args(outerRequestVo,..)") public void getAppIdAround(OuterRequestVo outerRequestVo) { } /** * 获取appid环绕通知 */ @Around(value = "getAppIdAround(outerRequestVo)", argNames = "joinPoint,outerRequestVo") public Object around(ProceedingJoinPoint joinPoint, OuterRequestVo outerRequestVo) throws Throwable { // 获取appid String appId = outerRequestVo.getAppId(); // 将获取到的appid存入ThreadLocal中,方便后续使用 AppIdHolder.setAppId(appId); try { // 执行限流切面的环绕通知 return rateLimitAspect.around(joinPoint); } finally { // 执行完后清空ThreadLocal AppIdHolder.clearAppId(); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
3.创建线程局部变量
package com.crestv.lgpt.config.annotation; public class AppIdHolder { private static final ThreadLocal<String> APP_ID_THREAD_LOCAL = new ThreadLocal<>(); public static void setAppId(String appId) { APP_ID_THREAD_LOCAL.set(appId); } public static String getAppId() { return APP_ID_THREAD_LOCAL.get(); } public static void clearAppId() { APP_ID_THREAD_LOCAL.remove(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
4.创建限流切面
package com.crestv.lgpt.config.annotation; import com.crestv.lgpt.vo.outer.OuterRequestVo; import org.aspectj.lang.ProceedingJoinPoint; import org.aspectj.lang.annotation.Around; import org.aspectj.lang.annotation.Aspect; import org.aspectj.lang.annotation.Pointcut; import org.springframework.stereotype.Component; import javax.annotation.Resource; @Aspect @Component public class AppIdAspect { @Resource private RateLimitAspect rateLimitAspect; /** * 获取appid切点 */ @Pointcut("@annotation(com.crestv.lgpt.config.annotation.AppId) && args(outerRequestVo,..)") public void getAppIdAround(OuterRequestVo outerRequestVo) { } /** * 获取appid环绕通知 */ @Around(value = "getAppIdAround(outerRequestVo)", argNames = "joinPoint,outerRequestVo") public Object around(ProceedingJoinPoint joinPoint, OuterRequestVo outerRequestVo) throws Throwable { // 获取appid String appId = outerRequestVo.getAppId(); // 将获取到的appid存入ThreadLocal中,方便后续使用 AppIdHolder.setAppId(appId); try { // 执行限流切面的环绕通知 return rateLimitAspect.around(joinPoint); } finally { // 执行完后清空ThreadLocal AppIdHolder.clearAppId(); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
十五、密码学
1.非对称加密
1.1简介:
① 非对称加密算法又称现代加密算法。
② 非对称加密是计算机通信安全的基石,保证了加密数据不会被破解。
③ 与对称加密算法不同,非对称加密算法需要两个密钥:公开密钥(publickey) 和私有密(privatekey)
④ 公开密钥和私有密钥是一对
⑤ 如果用公开密钥对数据进行加密,只有用对应的私有密钥才能解密。
⑥ 如果用私有密钥对数据进行加密,只有用对应的公开密钥才能解密。
⑦ 因为加密和解密使用的是两个不同的密钥,所以这种算法叫作非对称加密算法。
- 示例
- 首先生成密钥对, 公钥为(5,14), 私钥为(11,14)
- 现在A希望将原文2发送给B
- A使用公钥加密数据. 2的5次方mod 14 = 4 , 将密文4发送给B
- B使用私钥解密数据. 4的11次方mod14 = 2, 得到原文2
- 特点
- 加密和解密使用不同的密钥
- 如果使用私钥加密, 只能使用公钥解密
- 如果使用公钥加密, 只能使用私钥解密
- 处理数据的速度较慢, 因为安全级别高
- 常见算法
- RSA
- ECC
列:我使用公钥加密,把信发给你,你使用私钥解密,我自己没有私钥也不能进行解密,就很安全
1.2Class key PairGeneratir
用于生成公钥和私钥对,密码使用getInstance工厂方法(返回给定类的实例的静态方法)构造
给定的算法有:
- DiffieHellman(1024)
- DSA(1024)
- RSA(RSA)
1.3详细理解非对称加密
非对称加密: 在非对称加密中,加密和解密使用的是一对密钥,分别是公钥和私钥。公钥可以公开分享,而私钥需要保密。在这种情况下,服务端和客户端都有各自的一对密钥。
以客户端与服务端通信为例:
- 客户端拥有:客户端的私钥(C_pri)和服务端的公钥(S_pub)
- 服务端拥有:服务端的私钥(S_pri)和客户端的公钥(C_pub)
当客户端向服务端发送信息时,客户端使用服务端的公钥(S_pub)进行加密,服务端收到加密信息后,使用自己的私钥(S_pri)进行解密。
当服务端向客户端发送信息时,服务端使用客户端的公钥(C_pub)进行加密,客户端收到加密信息后,使用自己的私钥(C_pri)进行解密。
总结:在非对称加密通信中,服务端持有自己的私钥和客户端的公钥,客户端持有自己的私钥和服务端的公钥。这样可以确保通信的安全性。
所有人都用我发给外面的公钥把数据加密发送给我,然后我用自己的私钥进行解密,之后我在用客户端给我的公钥把数据进行加密,之后发给客户端,客户端用自己的数据进行解密,所以服务端可以有很多其他客户端的公钥但是只有一把自己的私钥,一个客户端只会有我服务端给他的公钥和她自己的私钥对吗
//指定为RSA算法 private static final String ALGORITHM = "RSA"; /** * 生成密钥对方法 * @return * @throws BaseException */ public static RsaKeyPair rsaKeyPair() throws BaseException { try { //通过keyPairGenerator生成公钥和私钥,返回一个包含RSA密钥对的实体类RsaKeyPair KeyPairGenerator keyPairGenerator = KeyPairGenerator.getInstance(ALGORITHM); //初始化 RSA 密钥对的长度为 1024 位 keyPairGenerator.initialize(1024); //生成一个密钥对 KeyPair keyPair = keyPairGenerator.generateKeyPair(); //获取公钥和私钥 PublicKey publicKey = keyPair.getPublic(); PrivateKey privateKey = keyPair.getPrivate(); return RsaKeyPair.builder() .publicKey(publicKey) .rsaBase64PublicKey(Base64.getEncoder().encodeToString(publicKey.getEncoded())) .privateKey(privateKey) .rsaBase64PrivateKey(Base64.getEncoder().encodeToString(privateKey.getEncoded())) .build(); } catch (Exception e) { throw new BaseException("1111", e.getMessage()); } } //这段代码返回了一个包含 RSA 密钥对的实体类 RsaKeyPair。该实体类中包含了公钥和私钥两个成员变量,同时也将这两个成员变量分别以 Base64 编码的形式存储在 rsaBase64PublicKey 和 rsaBase64PrivateKey 中,方便传输和存储。可以使用 Lombok 中的 @Builder 注解进行简洁的构造器生成。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 服务端将其公钥发送给客户端,客户端也将自己的公钥发送给服务端。这样,双方都拥有对方的公钥。
- 当客户端需要向服务端发送加密信息时,使用服务端的公钥对信息进行加密,然后将加密后的信息发送给服务端。服务端收到加密信息后,使用自己的私钥进行解密,得到原始信息。
- 当服务端需要向客户端发送加密信息时,使用客户端的公钥对信息进行加密,然后将加密后的信息发送给客户端。客户端收到加密信息后,使用自己的私钥进行解密,得到原始信息。
总结一下,服务端会有很多其他客户端的公钥和一把自己的私钥;每个客户端会有服务端的公钥和自己的私钥。通过这种方式,可以确保信息在传输过程中的安全性。
2.对称加密
- 采用单钥密码系统的加密方法,同一个密钥可以同时用作信息的加密和解密,这种加密方法称为对称加密,也称为单密钥加密。
- 示例
- 我们现在有一个原文3要发送给B
- 设置密钥为108, 3 * 108 = 324, 将324作为密文发送给B
- B拿到密文324后, 使用324/108 = 3 得到原文
- 常见加密算法
- DES : Data Encryption Standard,即数据加密标准,是一种使用密钥加密的块算法,1977年被美国联邦政府的国家标准局确定为联邦资料处理标准(FIPS),并授权在非密级政府通信中使用,随后该算法在国际上广泛流传开来。
- AES : Advanced Encryption Standard, 高级加密标准 .在密码学中又称Rijndael加密法,是美国联邦政府采用的一种区块加密标准。这个标准用来替代原先的DES,已经被多方分析且广为全世界所使用。
- 特点
- 加密速度快, 可以加密大文件
- 密文可逆, 一旦密钥文件泄漏, 就会导致数据暴露
- 加密后编码表找不到对应字符, 出现乱码
- 一般结合Base64使用
3.RSA签名
RSA数字签名通常分为两个步骤:签名和验证。签名是使用私钥对数据进行加密的过程,验证是使用公钥对签名进行解密和比对的过程。
具体步骤如下:
- 生成RSA密钥对,包括公钥和私钥。
- 使用私钥对数据进行签名操作,生成一个签名值。签名值通常使用BASE64编码,以便在传输和存储时方便处理。
- 将签名值和原始数据一起传输给接收方。
- 接收方使用公钥对签名值进行解密操作,得到一个消息摘要值。
- 接收方对原始数据进行哈希计算,得到一个消息摘要值。
- 比对步骤4和步骤5中的消息摘要值,如果相同,则说明签名验证成功,否则说明签名验证失败。
为什么要使用私钥进行签名?这是因为私钥是唯一的,具有独特性和安全性,只有持有私钥的人才能对数据进行签名操作,从而确保签名的真实性和完整性。同时,私钥通常被保存在安全的地方,不会被泄露或被篡改,因此可以确保签名的安全性和可靠性。另外,使用私钥进行签名操作还可以避免中间人攻击等安全威胁,提高数据传输的安全性和可靠性。
3.1为什么数据加密使用对称加密
数据加密通常使用对称加密算法,是因为对称加密算法具有以下优点:
- 速度快:对称加密算法的加解密速度非常快,特别适合对大量数据进行加密操作。
- 安全性高:尽管对称加密算法的密钥长度相对较短,但由于加密和解密使用的是同一个密钥,因此在加密算法本身的安全性没有问题的情况下,使用对称加密算法进行数据加密可以保证数据的机密性和完整性。
- 适用范围广:对称加密算法可以应用于各种数据传输场景,包括网络通信、数据存储等。
- 实现简单:对称加密算法的实现比较简单,常见的对称加密算法如AES、DES等都有成熟的实现方案,容易应用于各种编程语言和开发环境中。
总之,对称加密算法具有速度快、安全性高、适用范围广、实现简单等优点,因此被广泛应用于数据传输的加密和认证过程中。当然,在进行密钥交换和认证等操作时,需要使用非对称加密算法来确保密钥的安全性和可靠性。
3.2为什么签名使用非对称加密
签名使用非对称加密是因为非对称加密算法具有数字签名的功能,可以保证签名的可信性和不可伪造性。具体来说,使用私钥对消息进行签名时,可以保证只有私钥持有者才能对消息进行签名,因此签名的可信度很高。而在验证签名时,使用公钥对签名进行验证,可以保证签名的不可伪造性,即只有私钥持有者才能对消息进行签名,从而保证了数据的完整性和真实性。
此外,使用非对称加密算法进行签名还具有以下优点:
- 安全性高:非对称加密算法可以使用非常长的密钥长度,远远超过对称加密算法的密钥长度,从而提高了签名算法的安全性。
- 不需要传输密钥:与对称加密算法不同,非对称加密算法不需要传输密钥,可以在不安全的通信环境中进行签名操作。
- 可扩展性强:非对称加密算法可以方便地扩展到多方通信和分布式系统中,从而适应了现代通信技术的需要。
总之,使用非对称加密算法进行签名可以保证签名的可信度和不可伪造性,具有安全性高、不需要传输密钥、可扩展性强等优点,因此被广泛应用于数据传输的认证和授权过程中。
4.消息摘要
消息摘要(Message Digest)是指将任意长度的消息(Message)作为输入,经过不可逆的哈希算法(Hash Function)处理,生成固定长度的哈希值(Hash Value)的过程。消息摘要通常也称为哈希摘要(Hash Digest)或摘要值(Digest Value)。
消息摘要的主要作用是保证消息的完整性和真实性。通过对消息进行哈希运算,可以生成一个唯一的摘要值,该摘要值具有如下特点:
- 摘要值长度固定,通常为128位、160位、256位或512位。
- 摘要值是一段数字序列,无法还原成原始数据。
- 任何对原始数据的修改都会导致摘要值的改变。
- 不同的原始数据生成的摘要值不同,但相同的原始数据生成的摘要值相同。
消息摘要广泛应用于数字签名、消息认证码、密码学等领域。它可以用于验证数据的完整性和真实性,检测数据篡改和传输错误,防止数据被篡改或伪造,从而确保数据的安全性和可靠性。
十六、docker
1.修改docker中mysql的配置文件
要更改Docker中MySQL的配置文件,可以按照以下步骤操作:
- 进入Docker容器内部。可以使用以下命令进入容器的bash终端:
docker exec -it <容器ID> bash
- 1
其中,<容器ID>是MySQL容器的ID
- 进入MySQL的配置文件目录。在容器内部,MySQL的配置文件通常存储在
/etc/mysql目录下。使用以下命令进入该目录:
cd /etc/mysql
- 1
- 修改MySQL配置文件。MySQL的主要配置文件是
my.cnf文件,可以使用vim等编辑器进行编辑。例如,使用以下命令编辑my.cnf文件:
vim my.cnf
- 1
- 保存并退出编辑器。在vim编辑器中,可以使用以下命令保存并退出文件:
- 重启MySQL服务。在容器内部,可以使用以下命令重启MySQL服务:
service mysql restart
- 1
如果出现权限问题,可以使用以下命令以root用户身份执行:
sudo service mysql restart
- 1
在重启服务之前,可以使用以下命令查看MySQL的运行状态:
service mysql status
- 1
如果MySQL服务已经运行,可以使用以下命令停止服务:
service mysql stop
- 1
完成上述步骤后,MySQL的配置文件就被修改成功了。注意,这种修改方式只对当前运行的MySQL容器有效,如果删除容器后再创建一个新的MySQL容器,新容器的配置文件仍然是默认的。如果需要永久修改MySQL配置文件,可以将修改后的文件打包成新的Docker镜像,然后使用新镜像创建MySQL容器。
十七、给项目配置swagger
1.给项目添加依赖
<dependency> <groupId>io.swagger</groupId> <artifactId>swagger-annotations</artifactId> <version>1.5.21</version> </dependency> <dependency> <groupId>io.swagger</groupId> <artifactId>swagger-models</artifactId> <version>1.5.21</version> </dependency> <dependency> <groupId>io.springfox</groupId> <artifactId>springfox-swagger2</artifactId> <version>2.9.2</version> </dependency> <dependency> <groupId>io.springfox</groupId> <artifactId>springfox-swagger-ui</artifactId> <version>2.9.2</version> </dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
十八、stream流
1.stream中的.map()方法
List<PaymentInfoDto> payList = paymentOrderDto.getPayList().stream()
.map(paymentInfoDto -> {
PaymentInfoDto newPaymentInfoDto = new PaymentInfoDto();
newPaymentInfoDto.setAccount(paymentInfoDto.getAccount());
newPaymentInfoDto.setPayee(paymentInfoDto.getPayee());
newPaymentInfoDto.setIdCard(paymentInfoDto.getIdCard());
newPaymentInfoDto.setPhone(paymentInfoDto.getPhone());
newPaymentInfoDto.setAmount(paymentInfoDto.getAmount() * 2);
return newPaymentInfoDto;
})
.collect(Collectors.toList());
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
使用 map() 方法将对象转换为新的对象,是为了创建一个新的、独立的对象,以便在修改其属性值时不会影响原始对象。在上述代码中,使用 map() 方法将原始 PaymentInfoDto 列表中的每个对象都映射为一个新的 PaymentInfoDto 对象,并使用新的 amount 属性值来更新每个对象。
这种方法通常用于创建一个新的列表,该列表包含原始列表中的对象,但在新列表中具有不同的属性值或状态。这样做的好处是,我们可以在不影响原始列表的情况下对新列表进行更改,从而避免对原始列表造成潜在的问题。
在上述代码中,我们使用 map() 方法将 PaymentInfoDto 对象映射为新的 PaymentInfoDto 对象,因为我们希望在创建一个新的支付列表时避免对原始支付列表造成影响。这种方式使得代码更加清晰、可读性更好,并且更容易维护和测试。
2.方法
Java中的Stream是一种用于操作集合(包括数组、集合、Map等)的便捷工具。它提供了一种声明式的、函数式的、可并行的操作集合的方式,使代码更加简洁、易读、易维护。下面是一些常见的Stream用法示例:
- 从集合创建一个Stream对象:
phpCopy codeList<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> stream = list.stream();
- 1
- 2
- 对Stream进行过滤操作:
phpCopy codeList<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> stream = list.stream();
Stream<Integer> filteredStream = stream.filter(n -> n % 2 == 0);
- 1
- 2
- 3
- 对Stream进行映射操作:
rustCopy codeList<String> list = Arrays.asList("apple", "banana", "orange");
Stream<String> stream = list.stream();
Stream<String> mappedStream = stream.map(s -> s.toUpperCase());
- 1
- 2
- 3
- 对Stream进行排序操作:
phpCopy codeList<Integer> list = Arrays.asList(5, 3, 1, 4, 2);
Stream<Integer> stream = list.stream();
Stream<Integer> sortedStream = stream.sorted();
- 1
- 2
- 3
- 对Stream进行聚合操作:
sqlCopy codeList<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> stream = list.stream();
int sum = stream.reduce(0, Integer::sum);
- 1
- 2
- 3
以上仅是Stream的一些常用方法,Stream还提供了很多其他的操作,比如distinct、flatMap、peek等。需要根据具体的场景选择不同的方法来操作Stream。
Java中的Stream流可以用来对集合(如List、Set等)和数组进行操作。它提供了一种非常便捷的方式来处理集合中的元素,可以进行筛选、映射、排序、统计等操作。下面是一些Stream流的使用示例:
- 对集合进行筛选:
scssCopy codeList<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
List<Integer> evenNumbers = numbers.stream()
.filter(n -> n % 2 == 0)
.collect(Collectors.toList());
- 1
- 2
- 3
- 4
这段代码将集合中的偶数筛选出来,并将它们放入一个新的集合中。
- 对集合进行映射:
rustCopy codeList<String> words = Arrays.asList("hello", "world");
List<Integer> wordLengths = words.stream()
.map(String::length)
.collect(Collectors.toList());
- 1
- 2
- 3
- 4
这段代码将集合中的字符串映射成它们的长度,并将它们放入一个新的集合中。
- 对集合进行排序:
scssCopy codeList<Integer> numbers = Arrays.asList(3, 1, 4, 1, 5, 9, 2, 6, 5, 3);
List<Integer> sortedNumbers = numbers.stream()
.sorted()
.collect(Collectors.toList());
- 1
- 2
- 3
- 4
这段代码将集合中的数字排序,并将它们放入一个新的集合中。
- 对集合进行统计:
scssCopy codeList<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
long count = numbers.stream()
.count();
int max = numbers.stream()
.mapToInt(Integer::intValue)
.max()
.orElseThrow(NoSuchElementException::new);
int sum = numbers.stream()
.mapToInt(Integer::intValue)
.sum();
double average = numbers.stream()
.mapToInt(Integer::intValue)
.average()
.orElseThrow(NoSuchElementException::new);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
这段代码对集合中的元素进行统计,包括元素个数、最大值、总和和平均值。
以上只是一些常用的Stream流的使用示例,实际上Stream流可以进行的操作非常丰富。在使用Stream流时,需要注意它是一种惰性求值的方式,也就是说,在对集合进行操作时,它并不会立即执行,而是等到真正需要结果的时候才会开始执行。因此,Stream流可以帮助我们避免创建不必要的中间集合,提高程序的性能。
3.peek和forEach有什么区别
peek 和 forEach 都是 Java 8 引入的 Stream API 中的方法。它们之间的主要区别在于它们在 Stream 管道中的角色。以下是关于它们的详细解释:
peek:peek是一个中间操作,它允许在不终止流的情况下执行某些操作。peek通常用于调试目的,因为它允许您在流的每个元素上执行某些操作(例如打印元素),同时保持流的原始状态。需要注意的是,由于peek是中间操作,除非有一个终止操作触发流的执行,否则它不会执行任何操作。
例子:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
List<Integer> doubledNumbers = numbers.stream()
.peek(n -> System.out.println("Original: " + n))
.map(n -> n * 2)
.peek(n -> System.out.println("Doubled: " + n))
.collect(Collectors.toList());
- 1
- 2
- 3
- 4
- 5
- 6
在上述示例中,peek 被用来在两个操作之间打印原始数字和加倍后的数字。
forEach:forEach是一个终止操作,它用于对流中的每个元素执行某个操作,并终止流。它通常用于执行诸如打印、修改列表元素或将元素添加到新集合等操作。因为它是终止操作,它确保流的执行。
例子:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
numbers.stream()
.filter(n -> n % 2 == 0)
.forEach(System.out::println);
- 1
- 2
- 3
- 4
在上述示例中,forEach 用于打印过滤后的偶数。
总结:
peek是一个中间操作,它不会触发流的执行。它主要用于调试目的,因为它允许您在保持流状态的同时对每个元素执行操作。forEach是一个终止操作,用于对流中的每个元素执行操作并终止流。它用于执行诸如打印、修改元素或将元素添加到新集合等操作。
当您需要对流中的每个元素执行操作并确保流执行时,请使用 forEach。如果您只是想在流的中间阶段查看元素或执行一些调试操作,请使用 peek。
十九、线程问题和并发问题
线程问题和并发问题是计算机科学中两个密切相关的概念,它们涉及到多个任务如何在计算机系统中同时运行和相互协作。
线程问题:线程是操作系统调度的基本单位,它是程序中一个独立执行的路径。多线程就是一个程序中有多个线程在同时运行。线程问题通常涉及线程之间的同步、通信和资源共享。当线程之间出现争用条件、死锁或者数据不一致等问题时,这些都属于线程问题。为了解决线程问题,程序员需要使用互斥量、信号量、条件变量等同步机制来确保线程之间的正确执行顺序和数据的完整性。
并发问题:并发是指多个任务在同一时间段内交替执行,但不一定是同时执行。并发问题是指在并发环境下,多个任务之间可能存在的相互影响、资源竞争或者执行顺序不确定性等问题。为了解决并发问题,程序员需要设计并发控制策略,如锁、原子操作、事务等,以确保多个任务的正确执行。
总之,线程问题主要关注多线程环境下线程之间的同步和通信,而并发问题关注多任务同时执行过程中的资源竞争和执行顺序。两者都是为了解决多任务环境下程序的正确性和性能问题。
1.线程问题和并发问题分别对应什么问题
线程问题和并发问题是多线程编程中常见的两类问题。它们有一定的关联性,但侧重点不同。
线程问题主要是指与单个线程相关的问题,包括:
- 线程安全:当多个线程访问共享资源时,需要确保这些线程的行为是正确的,不会出现数据错乱或者异常情况。通常需要通过同步措施(如锁、原子操作等)来保证线程安全。
- 线程死锁:多个线程在执行过程中,相互等待对方持有的锁而导致的阻塞现象。这种情况下,所有涉及的线程都无法继续执行,程序陷入死循环。为避免死锁,可以采用避免、预防、检测和解除死锁等方法。
- 线程活锁:多个线程在执行过程中,由于互相干扰或者竞争资源而导致的无法继续执行的现象。与死锁不同,活锁中的线程并没有阻塞,但是它们在不断地尝试执行,却无法取得进展。
- 线程饥饿:由于线程调度策略或者资源竞争等原因,导致某些线程无法获得足够的CPU时间片,从而无法执行或者执行速度极慢。线程饥饿可能会导致程序性能下降,甚至无法完成任务。
并发问题主要是指在并发执行的过程中出现的问题,包括:
- 临界区竞争:多个线程同时访问共享资源,导致资源访问冲突。为解决临界区竞争问题,可以使用互斥锁、信号量等同步机制,确保任意时刻只有一个线程能访问共享资源。
- 数据不一致:多个线程对共享资源的操作顺序不当,导致数据的状态不一致。这通常需要采用原子操作、锁或者事务等手段,确保数据操作的完整性和一致性。
- 可见性问题:由于线程之间的缓存不一致或者编译器优化等原因,导致一个线程对共享变量的修改无法立即对其他线程可见。解决可见性问题,可以使用volatile关键字、原子操作或者锁等机制,确保共享变量的修改能及时地通知到其他线程。
- 顺序性问题:在并发执行的过程中,多个线程的操作顺序可能会导致程序执行
线程问题和并发问题都可以用锁解决
对于线程问题:
- 线程安全:使用锁可以确保在同一时刻只有一个线程访问共享资源,保证资源访问的正确性。
- 线程死锁:虽然锁本身可能导致死锁,但通过合理的锁设计和使用策略,可以避免死锁的发生。
- 线程活锁:使用锁可以避免活锁,但需要谨慎设计锁的粒度和获取顺序,以免引发活锁。
- 线程饥饿:通过合理的锁策略和线程调度,可以避免线程饥饿的发生。
对于并发问题:
- 临界区竞争:通过使用锁,可以确保在同一时刻只有一个线程能访问共享资源,避免竞争。
- 数据不一致:使用锁可以保证对共享资源的操作顺序得到控制,避免数据状态不一致的问题。
- 可见性问题:虽然锁主要用于同步,但在一定程度上也可以解决可见性问题。当一个线程释放锁时,其他等待该锁的线程能看到最新的数据状态。
- 顺序性问题:通过使用锁,可以控制多个线程对共享资源的操作顺序,从而解决顺序性问题。
需要注意的是,虽然锁可以解决很多线程问题和并发问题,但使用锁也会带来一定的性能开销。因此,在实际应用中需要权衡锁的使用,尽量减小锁粒度,并尽可能使用非阻塞性的锁(如自旋锁、读写锁等)以提高性能。同时,可以考虑使用其他同步机制(如原子操作、信号量等)来解决特定的问题。
二十、锁
1.Redis分布式锁
Redis分布式锁是一种基于Redis的实现方式,用于保证在分布式系统中的多个节点之间实现资源的同步访问。其主要目的是解决在分布式环境下,多个节点对共享资源的竞争访问问题。
原理:Redis分布式锁的实现原理是使用Redis的原子性操作SET命令,为一个指定的key设置一个唯一的值,并设置一个过期时间。当多个节点尝试获取锁时,只有一个节点能成功设置这个key,从而获得锁。其他节点在尝试获取锁时,发现这个key已经存在,只能等待锁释放。
以下是Redis分布式锁的主要步骤:
- 尝试获取锁:使用
SET命令尝试为一个指定的key设置一个唯一值,并设置一个过期时间。设置成功说明获取锁成功,设置失败说明锁已被其他节点获取。
public boolean tryLock(String key, long timeout, TimeUnit unit) {
String value = UUID.randomUUID().toString();
return redisTemplate.opsForValue().setIfAbsent(key, value, timeout, unit);
}
- 1
- 2
- 3
- 4
- 执行业务逻辑:获取锁成功后,执行相应的业务逻辑。
- 释放锁:业务逻辑执行完毕后,需要释放锁,以便其他节点可以获取到锁。在释放锁时,需要判断当前的锁是否属于自己,以避免错误地释放了其他节点的锁。
public void unlock(String key) {
String value = redisTemplate.opsForValue().get(key);
if (value != null && value.equals(myValue)) {
redisTemplate.delete(key);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
需要注意的是,为了避免死锁的发生,需要在设置锁时设定一个合理的过期时间,以便在发生异常或者节点宕机时,锁能自动释放。另外,Redis分布式锁在使用过程中可能会遇到一些问题,如锁续命问题、锁误删问题等,可能需要使用RedLock算法或者其他分布式锁组件(如Zookeeper、Etcd等)来解决这些问题
2.分布式锁和其他锁的区别
分布式锁和其他锁(如Java中的synchronized关键字、ReentrantLock等)主要区别在于它们适用的场景和目的。
- 应用场景:
- 分布式锁:主要应用于分布式系统中,多个独立节点对共享资源进行互斥访问。分布式锁通常需要借助外部存储系统(如Redis、Zookeeper等)来实现。
- 其他锁(如synchronized、ReentrantLock):主要应用于单个JVM进程内的多线程环境中,对共享资源进行互斥访问。这些锁是Java语言本身提供的线程同步机制,无需外部存储系统支持。
- 目的:
- 分布式锁:解决分布式系统中的多个节点之间的竞争访问问题,保证系统的一致性和正确性。
- 其他锁:解决单个JVM进程内的多线程之间的竞争访问问题,保证线程安全。
- 实现原理:
- 分布式锁:通常依赖外部存储系统(如Redis、Zookeeper等),利用其原子性操作和超时机制等特性实现。
- 其他锁:依赖Java语言提供的线程同步机制(如synchronized关键字、ReentrantLock等),通过内部锁对象实现。
- 性能:
- 分布式锁:因为涉及到网络通信和外部存储系统,性能通常不如单机锁。但在分布式环境中,分布式锁是必要的。
- 其他锁:在单个JVM进程内,其他锁(如synchronized、ReentrantLock)的性能通常优于分布式锁。
总结:分布式锁和其他锁主要的区别在于它们适用的场景。分布式锁适用于分布式系统中,确保多个节点对共享资源的互斥访问;而其他锁适用于单个JVM进程内的多线程环境,确保线程间的同步和线程安全。
二十一、Windows安装ab压测工具
1. 安装
在Windows系统中使用ab工具进行并发测试,可以通过以下步骤完成:
- 下载Apache HTTP Server,下载地址为https://httpd.apache.org/download.cgi。根据系统版本下载对应的安装包,例如Windows 64位系统下载httpd-2.4.46-win64-VS16.zip。
- 解压安装包,将其中的bin目录添加到系统环境变量中。在Windows 10系统中,可以右键点击“此电脑”,选择“属性”,在左侧菜单中选择“高级系统设置”,点击“环境变量”,在“系统变量”中找到“Path”,点击“编辑”,在弹出的窗口中点击“新建”,将bin目录添加到环境变量中。
- 打开命令行窗口,输入以下命令检查ab工具是否安装成功:
ab -V
- 1
如果安装成功,会输出ab工具的版本信息。
- 在命令行中使用ab工具进行并发测试,例如:
ab -n 1000 -c 100 http://localhost:8080/myurl
- 1
其中,-n参数表示请求数量,-c参数表示并发请求数量,http://localhost:8080/myurl为需要测试的URL。
- 查看测试结果,ab工具会在命令行中输出测试结果。
注意事项:
在Windows系统中使用ab工具进行并发测试时,可能会遇到一些问题,例如无法创建大量的并发连接。这时可以在命令行中添加“-k”参数,表示使用HTTP keep-alive连接。例如:
ab -n 1000 -c 100 -k http://localhost:8080/myurl
- 1
此外,还可以通过增加系统资源、优化代码逻辑等方式提升系统性能,以应对高并发场景的测试。
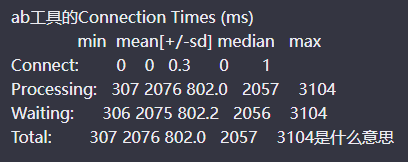
ab工具的Connection Times (ms)是针对HTTP请求的连接时间、处理时间和等待时间的统计结果,具体含义如下:
- Connect:连接时间,表示从发起请求到建立TCP连接的时间,单位为毫秒。min、mean、median、max分别表示连接时间的最小值、平均值、中位数和最大值。
- Processing:处理时间,表示从建立TCP连接到收到服务器响应的时间,单位为毫秒。min、mean、median、max分别表示处理时间的最小值、平均值、中位数和最大值。
- Waiting:等待时间,表示从建立TCP连接到收到第一个字节的时间,单位为毫秒。min、mean、median、max分别表示等待时间的最小值、平均值、中位数和最大值。
- Total:总时间,表示从发起请求到接收完整响应的时间,单位为毫秒。min、mean、median、max分别表示总时间的最小值、平均值、中位数和最大值。
例如,上述结果中的Processing块表示,针对测试中的每个请求,从建立TCP连接到收到服务器响应的时间最小值为307ms,平均值为2076ms,中位数为2057ms,最大值为3104ms。
通过分析Connection Times的统计结果,可以帮助开发
2.命令
在使用ab工具进行并发测试时,可以使用以下命令选项来查看发送了多少请求、响应状态码等信息:
- -n:指定测试的请求数量。例如,ab -n 1000 http://localhost:8080/myurl表示测试1000个请求。
- -k:使用HTTP keep-alive连接。在发送多个请求时,使用keep-alive连接可以提高性能。例如,ab -n 1000 -k http://localhost:8080/myurl表示使用keep-alive连接测试1000个请求。
- -s:指定请求发送的超时时间。例如,ab -n 1000 -s 10 http://localhost:8080/myurl表示设置超时时间为10秒,测试1000个请求。
- -C:添加Cookie头信息。例如,ab -n 1000 -C “sessionid=xxxxx” http://localhost:8080/myurl表示在请求头中添加名为sessionid的Cookie信息。
- -H:添加请求头信息。例如,ab -n 1000 -H “User-Agent: ab-test” http://localhost:8080/myurl表示在请求头中添加名为User-Agent的信息。
- -v:显示详细输出信息。例如,ab -n 1000 -v 4 http://localhost:8080/myurl表示显示4级别的详细输出信息。
通过上述命令选项,可以查看ab工具发送了多少请求、接收了多少响应、响应状态码、请求头信息、Cookie信息等详细信息。如果请求被拦截,可以在输出信息中查看响应状态码和详细的错误信息。
二十二、querywrapper中各类参数及其作用
1.方法
queryWrapper是MyBatis-Plus提供的一个查询构造器,用于构建查询条件。它包含了多个方法,每个方法都可以设置不同的查询条件,具体的各类参数及作用如下:
- eq(String column, Object value): 等于某个值,column为数据库表中的列名,value为对应的值。
- ne(String column, Object value): 不等于某个值,column为数据库表中的列名,value为对应的值。
- gt(String column, Object value): 大于某个值,column为数据库表中的列名,value为对应的值。
- ge(String column, Object value): 大于等于某个值,column为数据库表中的列名,value为对应的值。
- lt(String column, Object value): 小于某个值,column为数据库表中的列名,value为对应的值。
- le(String column, Object value): 小于等于某个值,column为数据库表中的列名,value为对应的值。
- like(String column, Object value): 模糊匹配,column为数据库表中的列名,value为对应的值。
- in(String column, Collection<?> values): 包含在某个集合中,column为数据库表中的列名,values为对应的值的集合。
- notIn(String column, Collection<?> values): 不包含在某个集合中,column为数据库表中的列名,values为对应的值的集合。
- isNull(String column): 判断某个列的值是否为null,column为数据库表中的列名。
- isNotNull(String column): 判断某个列的值是否不为null,column为数据库表中的列名。
- and(): 并且关系,用于连接多个查询条件。
- or(): 或者关系,用于连接多个查询条件。
- orderByAsc(String… columns): 根据指定的列名升序排序。
- orderByDesc(String… columns): 根据指定的列名降序排序。
- last(String sql): 直接拼接在SQL语句的最后,可用于传递自定义的SQL语句。
以上是queryWrapper中常用的方法及作用,根据具体的查询需求可以选择合适的方法进行使用。需要注意的是,queryWrapper中的大部分方法都是可链式调用的,例如eq()和like()方法可以直接在and()和or()方法之后进行调用,以构建复杂的查询条件。
二十三、异步编程
Java实现异步通常有以下几种方式:
- 回调函数:回调函数是一种基于事件驱动的编程模型,通过回调函数可以在异步操作完成后回调特定的方法来处理异步操作的结果。Java中可以通过接口或Lambda表达式来实现回调函数。
- Future和CompletableFuture:Future是Java中用于处理异步操作的接口,通过Future可以获得异步操作的状态和结果。Java 8引入的CompletableFuture是Future的扩展,可以更方便地实现异步操作和组合多个异步操作。
- 线程池:Java中的线程池可以用来管理多个线程,并可以将任务提交到线程池中进行异步处理。线程池可以避免频繁创建和销毁线程的开销,提高应用程序的性能。
- 异步IO:Java NIO(New IO)提供了异步IO的支持,通过异步IO可以在进行IO操作的同时执行其他任务,提高应用程序的吞吐量和并发性能。
需要注意的是,异步操作需要注意线程安全性和资源管理等问题,否则可能会出现竞态条件、内存泄漏等问题。因此,在实现异步操作时需要仔细考虑设计和实现方案。
二十四、各种O
1.VO(值对象)和PO(持久对象)
- VO(值对象)通常用于业务层之间的数据传递,是业务逻辑使用的,可以看成是业务对象。它存活的目的就是为数据提供一个生存的地方。
- PO(持久对象)是与数据库中的表相映射的Java对象,代表物理数据的对象表示。它是有状态的,每个属性代表其当前的状态。使用它,可以使我们的程序与物理数据解耦,并且可以简化对象数据与物理数据之间的转换。
两者的区别在于,VO是用new关键字创建的由GC回收的对象,而PO是向数据库中添加新数据时创建,删除数据库中数据时削除的对象。此外,VO的属性是根据当前业务的不同而不同的,而PO的属性是跟数据库表的字段一一对应的。
2.TO(数据传输对象)和BO(业务对象)
- TO(数据传输对象)是用于不同层之间的数据传输的对象,通常用于远程调用等需要大量传输对象的地方。
- BO(业务对象)是封装业务逻辑的Java对象,通过调用DAO方法,结合PO和VO进行业务操作。它是从业务模型的角度看,封装业务逻辑的Java对象。主要作用是把业务逻辑封装为一个对象。比如一个简历,有教育经历、工作经历、社会关系等等,我们可以把教育经历对应一个PO,工作经历对应一个PO,社会关系对应一个PO。建立一个对应简历的BO对象处理简历,每个BO包含这些PO。这样处理业务逻辑时,我们就可以针对BO去处理。
3.QO(查询对象)和DAO(数据访问对象)
- QO(查询对象)是用于封装查询条件的对象,它与DAO结合使用,可以方便地进行数据库查询操作。
- DAO(数据访问对象)是用于访问数据库的对象,通常和PO结合使用。DAO中包含了各种数据库的操作方法。通过它的方法,结合PO对数据库进行相关的操作。夹在业务逻辑与数据库资源中间。配合VO,提供数据库的CRUD操作。
4.POJO(简单无规则Java对象)
- POJO(简单无规则Java对象)是一个符合Java Bean规范的纯Java对象,没有增加别的属性和方法。它在一些Object/Relation Mapping工具中,能够做到维护数据库表记录的Persistent Object完全是一个符合Java Bean规范的纯Java对象。
5.DTO(数据传输对象)
-
DTO(数据传输对象)主要用于远程调用等需要大量传输对象的地方。比如我们一张表有100个字段,那么对应的PO就有100个属性。但是我们界面上只要显示10个字段,客户端用Web service来获取数据,没有必要把整个PO对象传递到客户端,这时我们就可以用只有这10个属性的DTO来传递结果到客户端,这样也不会暴露服务端表结构。到达客户端以后,如果用这个对象来对应界面显示,那此时它的身份就转为VO。
其他相关概念
- BOF(Business Object Framework):业务对象框架。
- SOA(Service Orient Architecture):面向服务的设计。
- EMF(Eclipse Model Framework):Eclipse建模框架。
- DAL(数据访问层):数据访问层。
- IDAL(接口层):接口层。
- BLL(业务逻辑层):业务逻辑层。
- O/R Mapper(对象/关系映射):将对象与关系数据库绑定,用对象来表示关系数据。
- 实体模式:一种数据库设计模式,通过将关系型数据模型映射到对象模型上,可以实现对象级别的操作。
在Java开发中,通常会使用dto、entity和vo三个对象来传输数据。其中,dto用于接收参数,entity用于保存数据,vo用于返回整理过的数据。
6.此外,在Java开发中还有一些常用的对象命名方式:
- PO(Persistant Object):持久对象,通常对应数据模型(数据库),同时也具有一定的业务逻辑处理能力。可以看成是与数据库中的表相映射的Java对象。
- VO(Value Object):值对象,通常用于业务层之间的数据传递。它是抽象出的业务对象,可以与表对应,也可以不对应,这取决于业务需要。
- TO(Transfer Object):数据传输对象,在应用程序不同层之间传输的对象。
- BO(Business Object):业务对象,是封装业务逻辑的Java对象。通过调用DAO方法,结合PO和VO进行业务操作。
- DAO(Data Access Object):数据访问对象,是一个用于访问数据库的对象。通常和PO结合使用,DAO中包含了各种数据库的操作方法,可以通过它的方法结合PO对数据库进行相关的操作。
- POJO(Plain Ordinary Java Object):简单无规则Java对象,就是符合Java Bean规范的纯Java对象,没有增加别的属性和方法。
- QO(Query Object):查询对象,通常用于封装查询条件和查询结果。
以上这些对象命名方式在Java开发中非常常见,也是Java语言开发中的重要概念之一。每个对象都有其特定的作用和使用场景,开发者在实际开发过程中需要根据具体的业务需求来选择适合的对象命名方式。
8.他们的作用
VO(值对象)通常用于业务层之间的数据传递,可以看成是业务对象。它存活的目的就是为数据提供一个生存的地方。VO的作用是封装业务逻辑后返回给用户查看或处理。
PO(持久对象)是与数据库中的表相映射的Java对象,代表物理数据的对象表示。它是有状态的,每个属性代表其当前的状态。使用它,可以使程序与物理数据解耦,并且可以简化对象数据与物理数据之间的转换。PO的作用是作为持久化的数据模型,将数据库的表映射为对象。
TO(数据传输对象)主要用于远程调用等需要大量传输对象的地方,用于不同层之间的数据传输的对象。
BO(业务对象)是封装业务逻辑的Java对象,通过调用DAO方法,结合PO和VO进行业务操作。BO的作用是封装业务逻辑,对外提供业务处理的能力。
DAO(数据访问对象)是用于访问数据库的对象,通常和PO结合使用。DAO中包含了各种数据库的操作方法。通过它的方法,结合PO对数据库进行相关的操作。夹在业务逻辑与数据库资源中间。配合VO,提供数据库的CRUD操作。
POJO(简单无规则Java对象)是一个符合Java Bean规范的纯Java对象,没有增加别的属性和方法。它在一些ORM(Object-Relational Mapping)工具中,能够做到维护数据库表记录的Persistent Object完全是一个符合Java Bean规范的纯Java对象。
QO(查询对象)是用于封装查询条件的对象,它与DAO结合使用,可以方便地进行数据库查询操作。
二十五、将sdk提交到中央仓库
1.注册Sonatype账号
Sonatype 地址: https://issues.sonatype.org/secure/Dashboard.jspa
- Email: 填写自己的邮箱帐号即可,在 Sonatype 上的相关操作,会通知到这个邮箱帐号来提醒你相关进度。
- Full name: 填写联系人名称。
- Username: 这个就是你在 Sonatype 的登录帐号了。
- Password: 为登录密码,要求至少8位,并带有大小写字母和字符。
用户名和密码会在后面发布jar包到中央仓库上用的到
2.创建一个Project

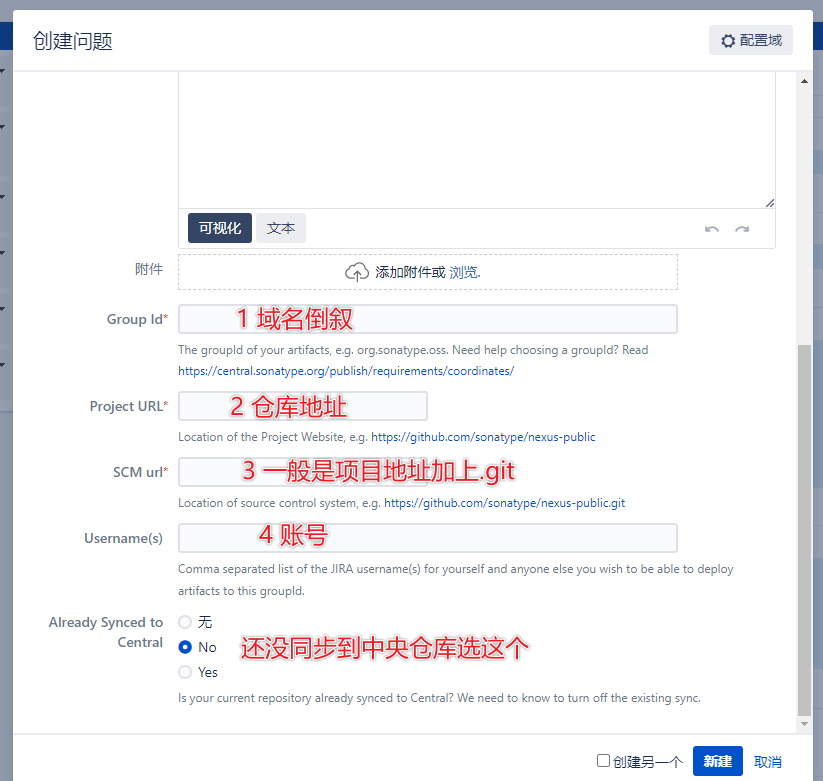
示例:
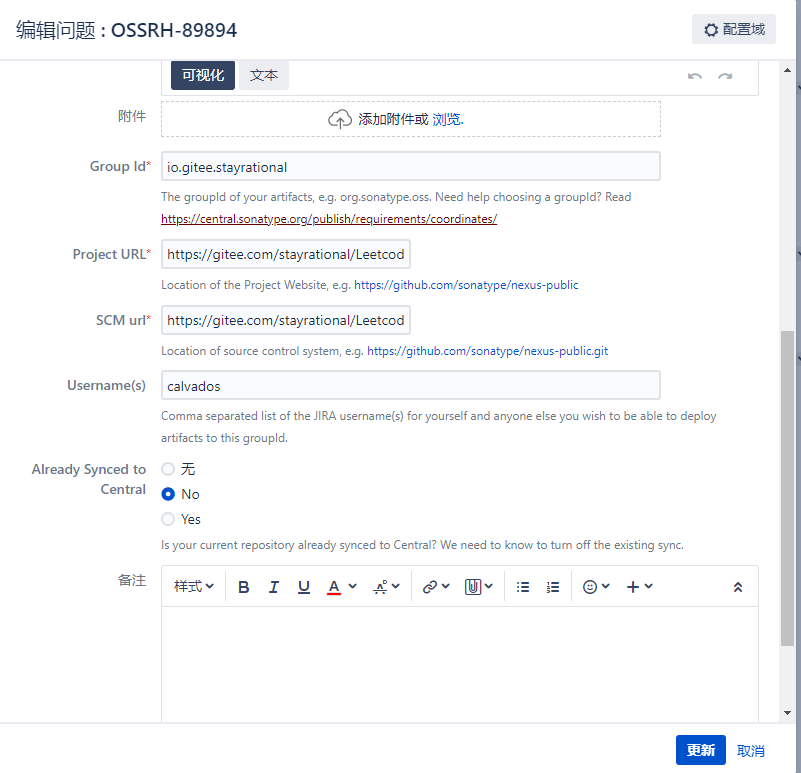
3.等待管理员回复,
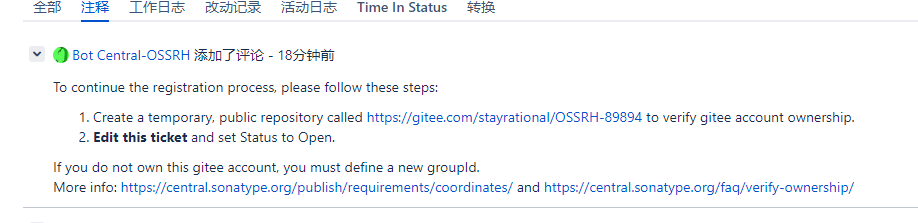
4. 根据要求创建一个他需要创建的仓库
用于认证这个仓库的所属权,创建后回复他:Already created
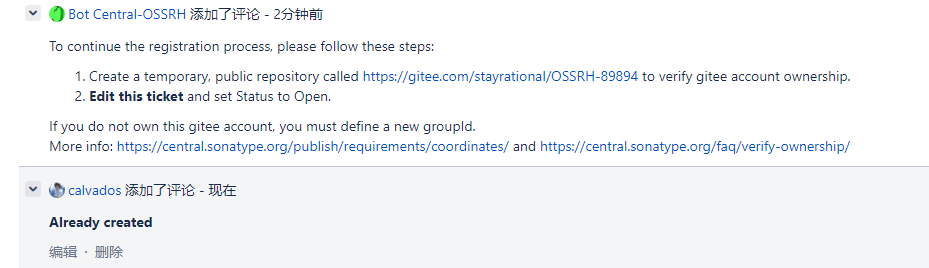
如果在之前填错了gorup id,管理员会提示

注意,他要求创建的仓库需要是公开的
以上全部完成后会收到
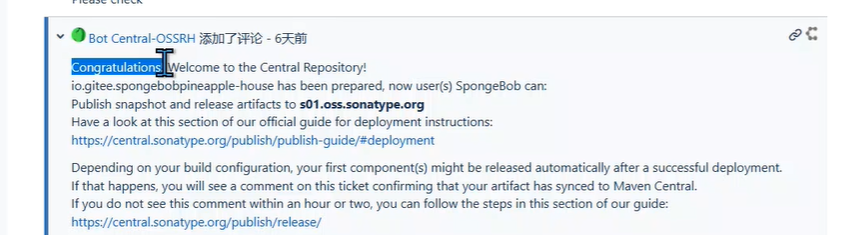
收到此消息表示创建成功
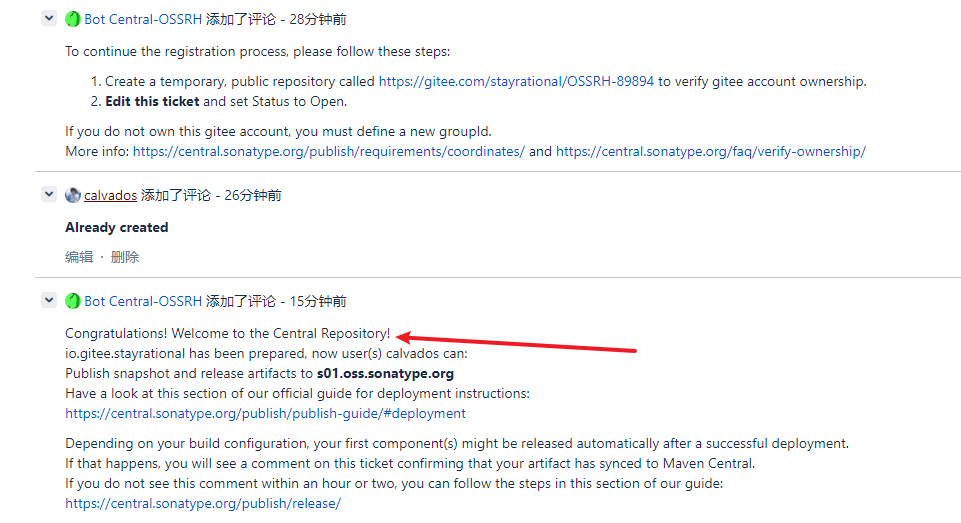
之后进行下一步
5.下载软件
链接:https://www.gpg4win.org/download.html
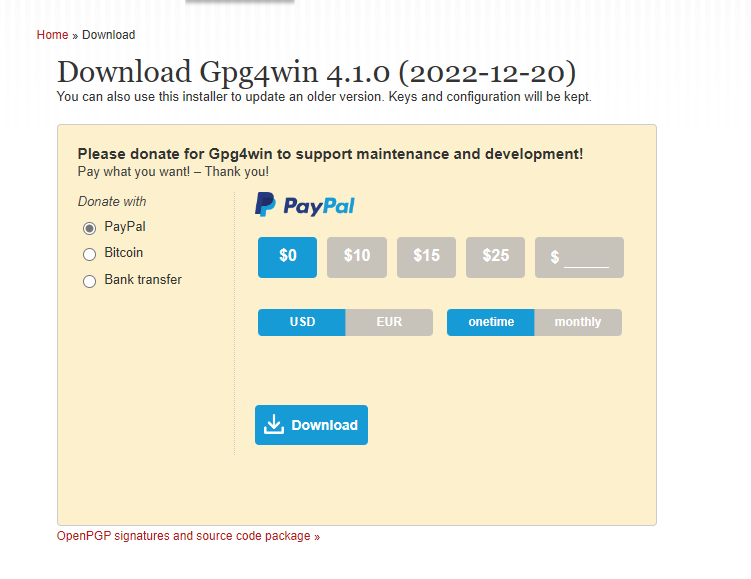
进链接下载软件会弹出赞助界面,选择0
6.安装
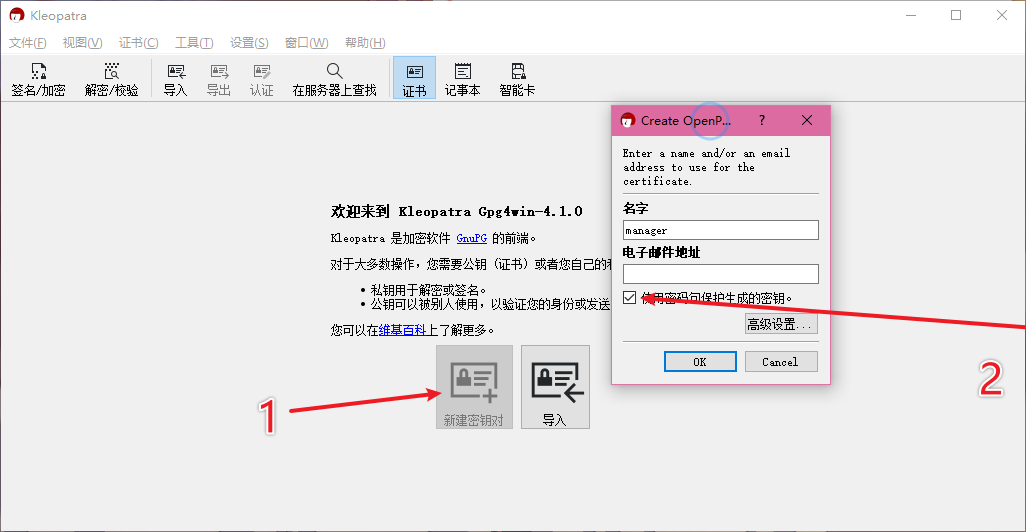
7.新建密钥对
8.上传密钥

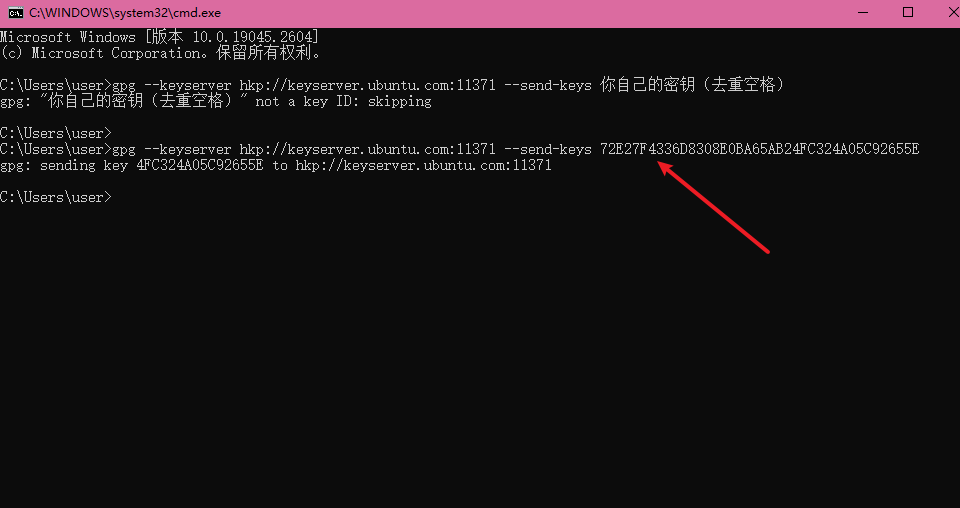
命令:
上传到服务器
gpg --keyserver hkp://keyserver.ubuntu.com:11371 --send-keys 自己的密钥
- 1
检查是否上传成功
gpg --keyserver hkp://keyserver.ubuntu.com:11371 --recv-keys 自己的密钥
- 1

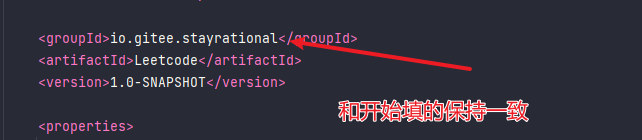
9.配置pom.xml
1.填写groupId
2.填写地址

<properties>
<java.version>1.8</java.version>
<projectUrl>https://gitee.com/spongebobpineapple-house/testmaven.git</projectUrl>
<serverId>ossrh</serverId><!-- 服务id 也就是setting.xml中的servers.server.id -->
</properties>
- 1
- 2
- 3
- 4
- 5
- 6
3.填入开发者信息
<!--填入开发者信息,姓名、邮箱、项目地址-->
<developers>
<developer>
<name>white</name>
<email>2487107665@qq.com</email>
<url>${projectUrl}</url>
</developer>
</developers>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
4.剩下的直接赋值粘贴
<!--以下部分内容不需要修改,直接复制咱贴即可--> <url>${projectUrl}</url> <licenses> <license> <name>The Apache Software License, Version 2.0</name> <url>http://www.apache.org/licenses/LICENSE-2.0.txt</url> <distribution>repo,manual</distribution> </license> </licenses> <scm> <!-- 采用projectUrl变量代替这个值,方便给重复利用这个配置,也就是上面的标签替换一下值就行 --> <connection>${projectUrl}</connection> <developerConnection>${projectUrl}</developerConnection> <url>${projectUrl}</url> </scm> <distributionManagement> <snapshotRepository> <!--这个id和settings.xml中servers.server.id要相同,因为上传jar需要登录才有权限--> <id>${serverId}</id> <name>OSS Snapshots Repository</name> <url>https://s01.oss.sonatype.org/content/repositories/snapshots/</url> </snapshotRepository> <repository> <!--这个id和settings.xml中servers.server.id要相同,因为上传jar需要登录才有权限--> <id>${serverId}</id> <name>OSS Staging Repository</name> <url>https://s01.oss.sonatype.org/service/local/staging/deploy/maven2/</url> </repository> </distributionManagement>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
<build> <plugins> <!-- 编译插件,设置源码以及编译的jdk版本 --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>8</source> <target>8</target> </configuration> </plugin> <!--打包源码的插件--> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-source-plugin</artifactId> <version>2.2.1</version> <executions> <execution> <id>attach-sources</id> <goals> <goal>jar-no-fork</goal> </goals> </execution> </executions> </plugin> <!-- Javadoc 文档生成插件--> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-javadoc-plugin</artifactId> <version>2.9.1</version> <configuration> <!-- 忽略生成文档中的错误 --> <additionalparam>-Xdoclint:none</additionalparam> <aggregate>true</aggregate> <charset>UTF-8</charset><!-- utf-8读取文件 --> <encoding>UTF-8</encoding><!-- utf-8进行编码代码 --> <docencoding>UTF-8</docencoding><!-- utf-8进行编码文档 --> </configuration> <executions> <execution> <id>attach-javadocs</id> <goals> <goal>jar</goal> </goals> </execution> </executions> </plugin> <!--公钥私钥插件,也就是上传需要进行验证用户名和密码过程中需要用到的插件--> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-gpg-plugin</artifactId> <version>1.5</version> <executions> <execution> <id>sign-artifacts</id> <phase>verify</phase> <goals> <goal>sign</goal> </goals> </execution> </executions> </plugin> <!--部署插件--> <plugin> <groupId>org.sonatype.plugins</groupId> <artifactId>nexus-staging-maven-plugin</artifactId> <version>1.6.7</version> <extensions>true</extensions> <configuration> <serverId>${serverId}</serverId> <nexusUrl>https://s01.oss.sonatype.org/</nexusUrl> <autoReleaseAfterClose>true</autoReleaseAfterClose> </configuration> </plugin> </plugins> </build>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
10.配置maven的setting.xml
<servers>
<server>
<id>ossrh</id>
<username>SpongeBob</username>
<password>(你自己的)</password>
</server>
</servers>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
<profile>
<id>ossrh</id>
<activation>
<activeByDefault>true</activeByDefault>
</activation>
<properties>
<gpg.executable>gpg</gpg.executable>
<gpg.passphrase>(你自己的)</gpg.passphrase>
</properties>
</profile>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
11.用idea部署
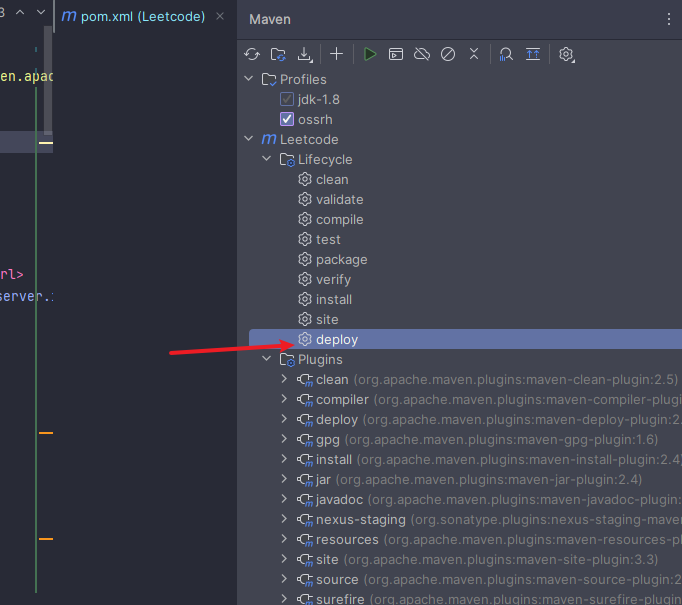
部署的时候报错" Failed to execute goal org.apache.maven.plugins:maven-gpg-plugin:1.5:sign (sign-artifacts) on proje"
在pom中添加如下配置
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-gpg-plugin</artifactId>
<version>1.6</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
12.打开链接登录账号
https://s01.oss.sonatype.org/#welcome
账号密码和第一次注册的sonatype一样
部署成功后登录,搜索仓库
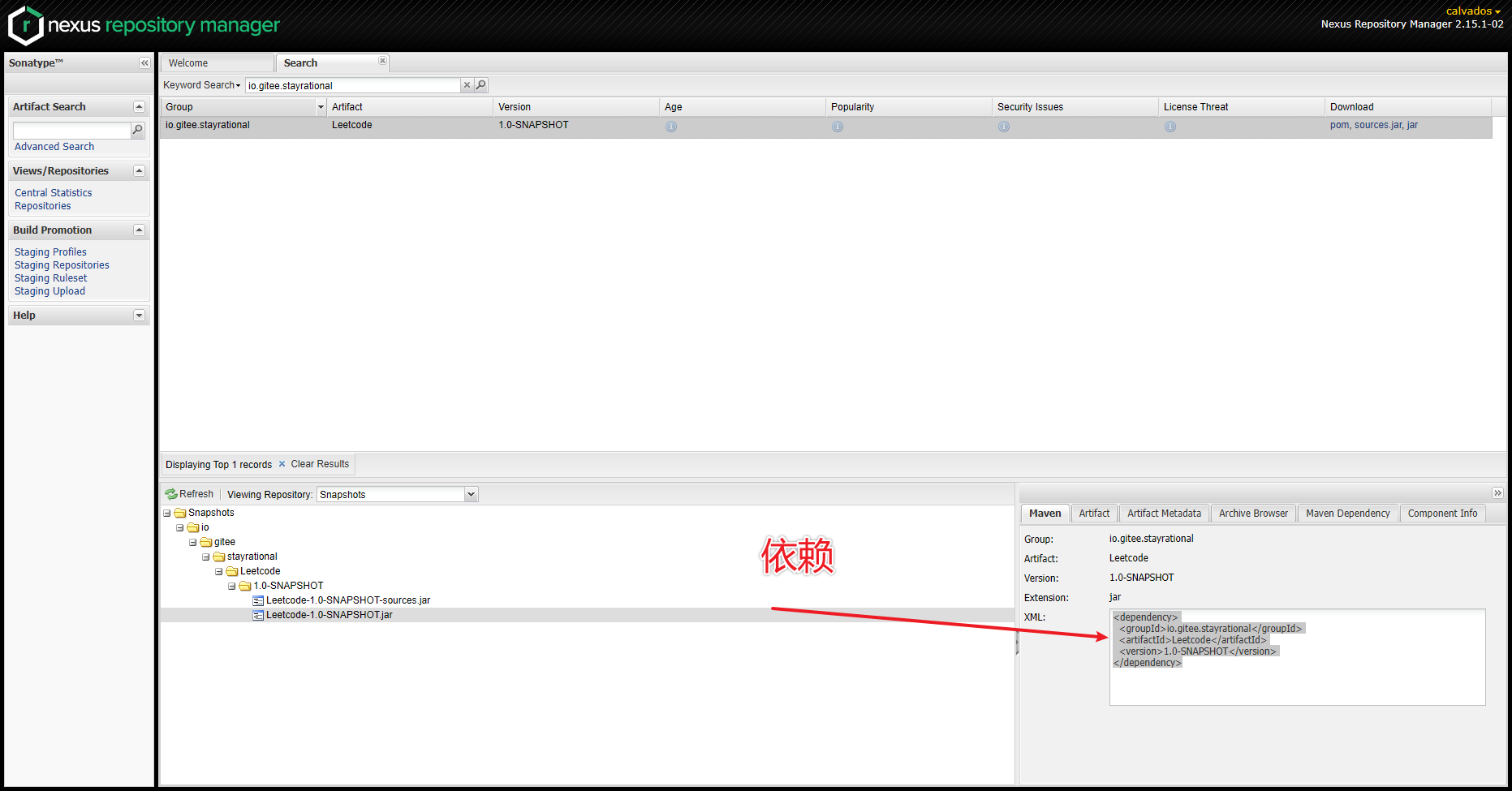
直接在pom中引入即可
注意!!!一些大坑
1.下面是完整的pom,去掉了一些依赖,只保留了发布项目的相关配置
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>io.gitee.stayrational</groupId> <artifactId>sdk</artifactId> <version>1.0</version> <packaging>jar</packaging> <name>crestv-sdk::凯盈资讯sdk</name> <url>https://gitee.com/stayrational/sdk.git</url> <description>凯盈资讯sdk</description> <properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>8</source> <target>8</target> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-source-plugin</artifactId> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-toolchains-plugin</artifactId> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-gpg-plugin</artifactId> </plugin> </plugins> <pluginManagement> <plugins> <plugin> <artifactId>maven-assembly-plugin</artifactId> <version>2.2-beta-5</version> <configuration> <tarLongFileMode>gnu</tarLongFileMode> </configuration> <executions> <execution> <id>package</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>1.8</source> <target>1.8</target> <encoding>UTF-8</encoding> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-source-plugin</artifactId> <version>2.1</version> <configuration> <attach>true</attach> </configuration> <executions> <execution> <phase>compile</phase> <goals> <goal>jar</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-gpg-plugin</artifactId> <version>1.6</version> <executions> <execution> <id>sign-artifacts</id> <phase>verify</phase> <goals> <goal>sign</goal> </goals> </execution> </executions> </plugin> </plugins> </pluginManagement> </build> <!-->项目的协议<--> <licenses> <license> <name>The Apache Software License, Version 2.0</name> <url>http://www.apache.org/licenses/LICENSE-2.0.txt</url> <distribution>repo,manual</distribution> </license> </licenses> <scm> <url>https://gitee.com/stayrational/sdk.git</url> <connection>https://gitee.com/stayrational/sdk.git</connection> <developerConnection>https://gitee.com/stayrational/sdk.git</developerConnection> </scm> <developers> <developer> <name>gp</name> <email>kaerwaduosi@gmail.com</email> <url>https://github.com/calvados1</url> </developer> </developers> <profiles> <profile> <id>ossrh</id> <activation> <activeByDefault>true</activeByDefault> </activation> <distributionManagement> <repository> <id>ossrh</id> <name>OSS Staging Repository</name> <url>https://s01.oss.sonatype.org/service/local/staging/deploy/maven2/</url> </repository> <snapshotRepository> <id>ossrh</id> <name>OSS Snapshots Repository</name> <url>https://s01.oss.sonatype.org/content/repositories/snapshots/</url> </snapshotRepository> </distributionManagement> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-javadoc-plugin</artifactId> <version>2.10.4</version> <executions> <execution> <phase>package</phase> <goals> <goal>jar</goal> </goals> </execution> </executions> </plugin> </plugins> </build> </profile> </profiles> </project>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
2.大坑!
1.groupId不要写错,必须写成在中央仓库请求的地址,我的是git的命名
2.每个人的配置都不一样,可能有版本的问题, https://s01.oss.sonatype.org/content/repositories/snapshots/变了也可能出问题
3.必须配置Javac插件用来生成文档,否则通不过发布的审核
4.主义maven的配置文件,里面必须有中央库的账号密码,还有生成的密钥
二十六、SQL
1.批量更新
<update id="updateBatchBalance"> update bank_sub_account <trim prefix="set" suffixOverrides=","> <trim prefix="total_amount = case" suffix="end"> <foreach collection="coll" item="bankSubAccount" index="index"> WHEN bank_main_account_id = #{bankSubAccount.bankMainAccountId} and account = #{bankSubAccount.account} then #{bankSubAccount.totalAmount} </foreach> </trim> </trim> <foreach collection="coll" item="bankSubAccount" index="index" open="where bank_main_account_id in (" separator="," close=")"> #{bankSubAccount.bankMainAccountId} </foreach> <foreach collection="coll" item="bankSubAccount" index="index" open="and account in (" separator="," close=")"> #{bankSubAccount.account} </foreach> </update>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
转换后:
UPDATE bank_sub_account
SET total_amount = CASE
WHEN bank_main_account_id = ? AND account = ? THEN ?
WHEN bank_main_account_id = ? AND account = ? THEN ?
...
END
WHERE bank_main_account_id IN (?, ?, ...)
AND account IN (?, ?, ...)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
在实际执行此SQL语句时,需要将问号(?)占位符替换为实际值。此外,<foreach>标签用于循环遍历集合中的每个元素,并将其添加到生成的SQL语句中。因此,在实际生成的SQL语句中,WHERE子句和AND子句将包含所有bank_main_account_id和account的值,用逗号分隔。
实际执行时的SQL语句可能类似于以下格式:
UPDATE bank_sub_account
SET total_amount = CASE
WHEN bank_main_account_id = 1 AND account = 'A' THEN 1000
WHEN bank_main_account_id = 2 AND account = 'B' THEN 2000
...
END
WHERE bank_main_account_id IN (1, 2, 3, ...)
AND account IN ('A', 'B', 'C', ...)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
请注意,这里的数值和字符仅作为示例,实际执行时需要根据实际情况进行替换。
因为使用了suffixOverrides=","所以不需要逗号分隔
这段代码是Mybatis中的一个update语句,具体的作用如下:
- 通过id属性指定该update语句的唯一标识符为"updateBatchBalance"。
- 执行一个更新操作,更新的表为"bank_sub_account"。
- 使用trim标签拼接SQL语句中的"set"关键字,suffixOverrides属性表示去除最后一个", ",避免出现SQL语法错误。
- 在trim标签内再使用trim标签拼接SQL语句中的"total_amount = case",suffix属性表示拼接"end"字符串,表示这个case语句块的结束位置。
- 在第四步的trim标签中使用foreach标签遍历集合"coll",获取其中的每个"bankSubAccount"对象,根据这个对象中的"bankMainAccountId"和"account"属性,使用case语句块更新"bank_sub_account"表中的"total_amount"字段。
- 在第三步的trim标签中,SQL语句的"set"和"total_amount = case"之间会被拼接成一个完整的SQL语句片段。
- 在foreach标签中再次遍历集合"coll",获取其中的每个"bankSubAccount"对象,使用其"bankMainAccountId"属性拼接SQL语句的"where bank_main_account_id in"子句。
- 在第七步的foreach标签中再次遍历集合"coll",获取其中的每个"bankSubAccount"对象,使用其"account"属性拼接SQL语句的"and account in"子句。
- 最终拼接出来的SQL语句会根据"bankMainAccountId"和"account"更新"bank_sub_account"表中对应记录的"total_amount"字段。
2.更新子账号
<update id="updateAvailableAndWillpayAmountBatch"> UPDATE bank_sub_account bsa INNER JOIN ( SELECT SUM(total_amount) settled_amount FROM pay_order <foreach collection="coll" item="bankSubAccount" index="index" open="WHERE bank_main_account_id in (" separator="," close=")"> #{bankSubAccount.bankMainAccountId} </foreach> <foreach collection="coll" item="bankSubAccount" index="index" open="and company_id in (" separator="," close=")"> #{bankSubAccount.companyId} </foreach> <foreach collection="coll1" item="state" index="index" open="and state in (" separator="," close=")"> #{state} </foreach> GROUP BY bank_main_account_id, company_id ) po ON bsa.bank_main_account_id = bank_main_account_id <trim prefix="set" suffixOverrides=","> <trim prefix="willpay_amount = case" suffix="end,"> <foreach collection="coll" item="bankSubAccount" index="index"> <include refid="when"/> then IFNULL(po.settled_amount, 0) </foreach> </trim> <trim prefix="available_amount = case" suffix="end"> <foreach collection="coll" item="bankSubAccount" index="index"> <include refid="when"/> then bsa.total_amount - IFNULL(po.settled_amount, 0) </foreach> </trim> </trim> <foreach collection="coll" item="bankSubAccount" index="index" open="WHERE bsa.bank_main_account_id in (" separator="," close=")"> #{bankSubAccount.bankMainAccountId} </foreach> <foreach collection="coll" item="bankSubAccount" index="index" open="and bsa.account in (" separator="," close=")"> #{bankSubAccount.account} </foreach> </update> <sql id="when"> when bsa.bank_main_account_id = #{bankSubAccount.bankMainAccountId} and bsa.account = #{bankSubAccount.account} </sql>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
转换为sql后如下:
UPDATE bank_sub_account bsa INNER JOIN ( SELECT SUM(total_amount) settled_amount FROM pay_order WHERE bank_main_account_id in (bank_main_account_id1, bank_main_account_id2, ...) AND company_id in (company_id1, company_id2, ...) AND state in (state1, state2, ...) GROUP BY bank_main_account_id, company_id ) po ON bsa.bank_main_account_id = po.bank_main_account_id SET willpay_amount = CASE WHEN <condition> THEN IFNULL(po.settled_amount, 0) -- Add more WHEN clauses if needed END, available_amount = CASE WHEN <condition> THEN bsa.total_amount - IFNULL(po.settled_amount, 0) -- Add more WHEN clauses if needed END WHERE bsa.bank_main_account_id in (bank_main_account_id1, bank_main_account_id2, ...) AND bsa.account in (account1, account2, ...);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
<foreach>标签:用于循环遍历集合,根据集合中的元素生成SQL语句的一部分。它有以下属性:collection:需要遍历的集合变量名。item:用于表示集合中每个元素的变量名。index:用于表示集合中元素的索引。open:循环生成的SQL片段的开始部分。separator:在生成的SQL片段中,各部分之间的分隔符。close:循环生成的SQL片段的结束部分。
#{...}:用于表示参数占位符。在SQL语句中,这些占位符会被实际传入的参数值替换。例如:#{bankSubAccount.bankMainAccountId}表示从bankSubAccount对象中获取bankMainAccountId属性的值。
在这个XML中,<foreach>标签主要用于根据传入的集合生成WHERE子句中的IN条件。例如,如果传入一个包含多个bank_main_account_id的集合,<foreach>标签会生成类似于WHERE bank_main_account_id IN (id1, id2, id3)的SQL片段。
<update id="updateAvailableAndWillpayAmountBatch"> UPDATE bank_sub_account bsa INNER JOIN ( SELECT SUM(total_amount) settled_amount FROM pay_order <foreach collection="coll" item="bankSubAccount" index="index" open="WHERE bank_main_account_id in (" separator="," close=")"> #{bankSubAccount.bankMainAccountId} </foreach> <foreach collection="coll" item="bankSubAccount" index="index" open="and company_id in (" separator="," close=")"> #{bankSubAccount.companyId} </foreach> <!--不查询状态码为200被删除的--> AND rec_state = 100 <foreach collection="coll1" item="state" index="index" open="and state in (" separator="," close=")"> #{state} </foreach> GROUP BY bank_main_account_id, company_id ) po ON bsa.bank_main_account_id = bank_main_account_id <trim prefix="set" suffixOverrides=","> <trim prefix="willpay_amount = case" suffix="end,"> <foreach collection="coll" item="bankSubAccount" index="index"> <include refid="when"/> then IFNULL(po.settled_amount, 0) </foreach> </trim> <trim prefix="available_amount = case" suffix="end"> <foreach collection="coll" item="bankSubAccount" index="index"> <include refid="when"/> <choose> <when test="bankSubAccount.companyId == null"> then bsa.total_amount </when> <otherwise> then bsa.total_amount - IFNULL(po.settled_amount, 0) </otherwise> </choose> </foreach> </trim> </trim> <foreach collection="coll" item="bankSubAccount" index="index" open="WHERE bsa.bank_main_account_id in (" separator="," close=")"> #{bankSubAccount.bankMainAccountId} </foreach> <foreach collection="coll" item="bankSubAccount" index="index" open="and bsa.account in (" separator="," close=")"> #{bankSubAccount.account} </foreach> </update>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
在这个修改中,我们的目标是在计算可用余额 available_amount 时,对于默认子账号(满足条件 companyId 为 null),让总金额 total_amount 等于可用余额。对于非默认子账号,我们沿用原来的计算方法(bsa.total_amount - IFNULL(po.settled_amount, 0))。
为了实现这个目标,我们使用了 <choose> 标签。<choose> 标签在 MyBatis 中类似于 SQL 中的 CASE 语句,用于根据不同的条件执行不同的操作。在 <choose> 标签内,我们可以使用 <when> 标签来定义满足某个条件时要执行的操作,以及使用 <otherwise> 标签来定义在没有满足任何 <when> 标签中定义的条件时要执行的操作。
在本例中,我们的 <choose> 标签包含了一个 <when> 标签和一个 <otherwise> 标签。<when> 标签的条件是 bankSubAccount.companyId == null,表示当 companyId 为 null 时(即默认子账号),我们执行 then bsa.total_amount 操作,即将总金额 total_amount 直接赋值给可用余额 available_amount。<otherwise> 标签用于处理不满足 <when> 标签条件的情况,即非默认子账号。在这种情况下,我们沿用原来的计算方法:then bsa.total_amount - IFNULL(po.settled_amount, 0)。
总之,我们通过添加一个 <choose> 标签,根据不同的条件(默认子账号或非默认子账号),执行不同的计算方法来更新可用余额 available_amount。这样,对于默认子账号,总金额 total_amount 会等于可用余额 available_amount。
3.group by
GROUP BY子句在SQL查询中用于对查询结果进行分组。它通常与聚合函数(如COUNT()、SUM()、AVG()、MIN()和MAX())一起使用,以对每个分组应用聚合操作。
GROUP BY子句按一个或多个列对查询结果进行分组。分组操作将具有相同列值的记录归为一组,并对每个组应用聚合函数。最终结果只显示每个组的一个记录,而不是所有符合条件的记录。
例如,假设您有一个销售表,包含以下字段:product_id(产品ID)、sales_date(销售日期)和quantity(销售数量)。如果您想查看每种产品的总销售数量,可以使用以下查询:
sqlCopy codeSELECT product_id, SUM(quantity) as total_quantity
FROM sales
GROUP BY product_id;
- 1
- 2
- 3
在这个查询中,GROUP BY子句按product_id对查询结果进行分组,然后使用SUM()函数计算每个分组的quantity总和。这样,您可以得到每种产品的总销售数量。
4.什么时候用on 什么使用用where 什么时候用then
ON:ON子句在SQL查询中主要用于指定连接两个表时的条件,它主要在JOIN操作(如INNER JOIN、LEFT JOIN、RIGHT JOIN等)中使用。例如:
SELECT a.id, a.name, b.amount
FROM table_a a
INNER JOIN table_b b ON a.id = b.a_id;
- 1
- 2
- 3
在这个查询中,ON子句指定了table_a和table_b连接的条件,即a.id等于b.a_id。
WHERE:WHERE子句用于筛选查询结果中符合特定条件的记录。它可以与多个逻辑运算符(如AND、OR、NOT等)结合使用,以满足复杂的筛选需求。例如:
SELECT id, name, age
FROM users
WHERE age > 18 AND gender = 'male';
- 1
- 2
- 3
在这个查询中,WHERE子句筛选出年龄大于18且性别为男性的记录。
THEN:THEN子句主要用在CASE语句中,用于指定当满足某个条件时应执行的操作。CASE语句允许根据一个或多个条件执行不同的操作。例如:
SELECT id, name, age,
CASE
WHEN age < 18 THEN 'minor'
WHEN age >= 18 AND age <= 60 THEN 'adult'
ELSE 'senior'
END as age_group
FROM users;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
在这个查询中,THEN子句用于指定当满足不同年龄条件时,将记录分为minor(未成年)、adult(成年)和senior(老年)三个年龄段。
- WHEN:
WHEN关键字用于在CASE语句中定义条件。它可以与THEN一起使用,用于指定当满足某个条件时应返回的结果。例如,在上面的CASE语句示例中,WHEN用于定义条件age < 18和age >= 18 AND age <= 60。
总之,在SQL查询中,ON子句用于指定连接条件,WHERE子句用于筛选符合条件的记录,而THEN子句用于指定满足CASE语句中某个条件时的操作。
5.关键字
MySQL是一个开源的关系型数据库管理系统,使用结构化查询语言(SQL)进行数据操作。以下是MySQL中一些常用关键字的简要介绍:
- SELECT:用于从表中检索数据。您可以选择获取表中的全部数据或仅获取特定列的数据。
- FROM:用于指定查询数据所在的表。
- WHERE:用于设置查询的条件,只返回满足条件的记录。
- AND / OR:用于组合多个条件,AND表示同时满足所有条件,OR表示满足任意一个条件即可。
- GROUP BY:用于对查询结果进行分组,通常与聚合函数(如COUNT、SUM、AVG)一起使用。
- HAVING:用于对分组后的结果进行筛选,类似于WHERE,但用于GROUP BY语句。
- ORDER BY:用于对查询结果进行排序,可以指定升序(ASC)或降序(DESC)。
- LIMIT:用于限制查询结果的数量,例如LIMIT 10表示只返回前10条记录。
- DISTINCT:用于去除查询结果中的重复记录。
- INNER JOIN / LEFT JOIN / RIGHT JOIN:用于将多个表中的数据连接在一起,根据共享的列进行匹配。INNER JOIN表示只返回匹配的记录,LEFT JOIN表示返回左表的所有记录以及匹配的右表记录(不匹配的记录用NULL填充),RIGHT JOIN与LEFT JOIN相反,返回右表的所有记录以及匹配的左表记录。
- ON:用于指定连接条件,通常与JOIN一起使用。
- INSERT INTO:用于向表中插入新数据。
- UPDATE:用于修改表中已有的数据。
- DELETE:用于删除表中的数据。
- CREATE TABLE:用于创建新表。
- DROP TABLE:用于删除表。
- ALTER TABLE:用于修改表结构,如添加/删除列、修改列类型等。
- INDEX:用于创建索引,以加速查询速度。
这些关键字可以组合使用,以执行各种复杂的数据操作。在编写SQL查询时,请注意正确使用关键字并遵循语法规则,以确保查询可以正常执行。
6.trim和set标签
MyBatis 中的一些常用标签包括 <trim> 和 <set>,它们在动态 SQL 中非常有用。下面我们来详细介绍一下这两个标签。
<trim>标签:
<trim> 标签用于在生成的 SQL 语句中修剪字符。它允许你在前面、后面或覆盖特定字符,如逗号、空格等。它有以下属性:
prefix:给生成的 SQL 语句添加前缀。suffix:给生成的 SQL 语句添加后缀。prefixOverrides:用于覆盖在 SQL 语句开头匹配的字符串。suffixOverrides:用于覆盖在 SQL 语句结尾匹配的字符串。
例如:
<trim prefix="SET" suffixOverrides=",">
<if test="name != null">name=#{name},</if>
<if test="age != null">age=#{age},</if>
</trim>
- 1
- 2
- 3
- 4
在这个例子中,<trim> 标签用于添加前缀 “SET”,并在生成的 SQL 语句末尾覆盖逗号。这在动态更新语句中非常有用,可以确保 SQL 语句具有正确的格式。
<set>标签:
<set> 标签是 <trim> 标签的一个特例,它用于动态生成 SQL 更新语句中的 SET 子句。它自动为生成的 SQL 语句添加 “SET” 前缀,并在末尾覆盖逗号。它没有特定的属性,只需在标签内部包含用于生成 SET 子句的条件即可。
例如:
<set>
<if test="name != null">name=#{name},</if>
<if test="age != null">age=#{age},</if>
</set>
- 1
- 2
- 3
- 4
在这个例子中,<set> 标签用于动态生成 SET 子句。它会自动添加 “SET” 前缀,并在生成的 SQL 语句末尾覆盖逗号。这对于动态更新语句非常有用。
总之,<trim> 和 <set> 标签在 MyBatis 中非常有用,它们可以帮助你生成更灵活、格式正确的 SQL 语句。<trim> 标签可以更通用地修剪字符,而 <set> 标签专门用于生成 SET 子句。
除了 <trim> 和 <set> 标签之外,MyBatis 还提供了许多其他有用的标签,以帮助你创建动态 SQL。下面是一些常用的标签:
<if>标签:
<if> 标签允许你根据某个条件包含或排除 SQL 片段。例如:
<if test="name != null">
AND name=#{name}
</if>
- 1
- 2
- 3
在这个例子中,如果参数 name 不为空,则会将 “AND name=#{name}” 添加到 SQL 语句中。
<choose>、<when>和<otherwise>标签:
这些标签允许你在多个条件中选择一个 SQL 片段。<choose> 标签内部包含一个或多个 <when> 标签,以及一个可选的 <otherwise> 标签。当某个 <when> 标签的条件为真时,它的内容将被添加到 SQL 语句中;如果没有 <when> 标签的条件为真,将使用 <otherwise> 标签的内容。
<choose>
<when test="name != null">
AND name=#{name}
</when>
<when test="age != null">
AND age=#{age}
</when>
<otherwise>
AND id=#{id}
</otherwise>
</choose>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
在这个例子中,如果参数 name 不为空,则将 “AND name=#{name}” 添加到 SQL 语句中;如果参数 age 不为空,则将 “AND age=#{age}” 添加到 SQL 语句中;如果两者都为空,则将 “AND id=#{id}” 添加到 SQL 语句中。
<foreach>标签:
<foreach> 标签用于迭代集合,为集合中的每个元素生成 SQL 片段。它的属性包括:
collection:要迭代的集合。item:集合中每个元素的变量名。index:集合中每个元素的索引名(可选)。open:生成的 SQL 片段的开始部分。separator:生成的 SQL 片段的分隔符。close:生成的 SQL 片段的结束部分。
<foreach collection="names" item="name" index="index" open="(" separator="," close=")">
#{name}
</foreach>
- 1
- 2
- 3
在这个例子中,<foreach> 标签用于迭代名为 names 的集合,并在生成的 SQL 语句中使用逗号分隔每个元素。
二十七、正则表达式
1.校验空格和特殊字符
public static final String REGULAR_NO_SPACE_OR_SPECIAL_CHARS = "^[^\\s~!@#$%^&*()_+`\\-=\\[\\]\\\\{}|;':\",./<>?]*$";
- 1
这个正则表达式可以匹配除了空格和特殊字符以外的任何字符,而 ^ 和 $ 保证了输入数据必须完全符合这个匹配规则,否则校验不通过。
如果你需要修改这个正则表达式以匹配其他特殊字符,只需要在方括号 [] 中添加需要匹配的特殊字符即可。例如,如果你想允许输入数据中出现小数点和下划线,可以修改正则表达式为:
public static final String REGULAR_NO_SPACE_OR_SPECIAL_CHARS = "^[^\\s~!@#$%^&*()_+`\\-=\\[\\]\\\\{}|;':\",./<>?._]*$";
- 1
- 2
public static final String REGULAR_NO_SPACE_OR_SPECIAL_CHARS = "^[a-zA-Z0-9]*$";
- 1
这个正则表达式将会匹配仅包含字母(大写或小写)和数字的字符串。所有的空格和特殊字符都将被排除。
2.其他一些校验
//手机号正则校验 public static final String REGULAR_PHONE_NUMBER = "^1(3|4|5|6|7|8|9)\\d{9}$"; //合同时间正则校验 public static final String REGULAR_CONTRACT_TIME = "^\\d{4}-\\d{2}-\\d{2}$"; //状态类型 public static final String REGULAR_STATUS_TYPE = "[1,2]"; //省份中号码正则校验 public static final String REGULAR_ID_NUMBER = "^(\\d{18}|\\d{15}|\\d{17}X)$"; //银行卡号正则校验 public static final String REGULAR_BANK_CARD_NO = "^([1-9]{1})(\\d{15}|\\d{16}|\\d{18})$"; //交易类型正则校验 public static final String REGULAR_TRANSACTION_TYPE = "[-1,10,20]"; //交易状态正则校验 public static final String REGULAR_TRANSACTION_STATUS = "[-1,0,50,100]"; //校验空格和特殊字符,如果存在则不通过校验 public static final String REGULAR_NO_SPACE_OR_SPECIAL_CHARS = "^[^\\s~!@#$%^&*()_+`\\-=\\[\\]\\\\{}|;':\",./<>?]*$";
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
二十八、rabbitMQ
1.优势
- 削峰
- 异步
- 解耦
2.劣势
- 系统可用性降低:一旦mq宕机就会对业务产生影响
- 系统复杂度提高:通过mq异步调用如何保证消息没有被重复消费?怎么处理消息丢失?怎么保证消息传递的顺序性?
- 一致性问题:通过MQ给B、C、D三个系统发消息数据,如果B系统、C系统处理成功,D系统处理
失败。如何保证消息数据处理的一致性?
3.需要满足什么条件才能使用mq?
- 生产者不需要从消费者处获得反馈。引入消息队列之前的直接调用,其接口的返回值应该为空,这才让明
明下层的动作还没做,上层却当成动作做完了继续往后走,即所谓异步成为了可能。 - 容许短暂的不一致性
- 确实是用了有效果。即解耦、提速、削峰这些方面的收益,超过加入MQ,管理MQ这些成本。
4.架构

- 很多个channel原因:为了节省资源,不能每次发送都建立一个新的连接,所以一个connection中有很多channel
RabbitMQ中的相关概念:
- Broker:接收和分发消息的应用,RabbitMQ Server就是Message Broker
- ·Virtual host:出于多租户和安全因素设计的,把AMQP的基本组件划分到一个虚拟的分组中,类似于网
络中的namespace概念。当多个不同的用户使用同一个RabbitMQ server提供的服务时,可以划分出多
个vhost,.每个用户在自己的vhost创建exchange/queue等 - ·Connection:publisher/consumer和broker之间的TCP连接
- ·Channel:如果每一次访问RabbitMQ都建立一个Connection,在消息量大的时候建立TCP Connection
的开销将是巨大的,效率也较低。Channel是在connection内部建立的逻辑连接,如果应用程序支持多线
程,通常每个thread创建单独的channel进行通讯,AMQP method包含了channel id帮助客户端和
message broker识别channel,所以channel之间是完全隔离的。Channel作为轻量级的Connection
极大减少了操作系统建立TCP connection的开销
5.六种工作模式
- 简单模式
- work queues
- publish/Subscribe 发布与订阅模式
- Routing路由模式
- TRipics主题模式
- RPC远程调用模式(远程调用,不太算MQ,不做介绍)
6.小结
- RabbitMQ是基于AMQP协议使用Erlang语言开发的一款消息队列产品。
- RabbitMQ提供了6种工作模式,我们学习5种。这是今天的重点。
- AMQP是协议,类比HTTP
- JMS是API规范接口,类比JDBC。
7.实现
7.1配置
package com.crestv.lgpt.config.rabbitmq; import org.springframework.amqp.core.*; import org.springframework.beans.factory.annotation.Qualifier; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; /** * @Description: * @Author guop * @Date 2023/5/20 16:31 */ @Configuration public class RabbitMQTest { @Bean("testExchange") public Exchange exchange() { return ExchangeBuilder.topicExchange("test_exchange").build(); } @Bean("testQueue") public Queue queue() { return QueueBuilder.durable("test_mq").build(); } @Bean public Binding binding(@Qualifier("testExchange")Exchange exchange,@Qualifier("testQueue") Queue queue) { return BindingBuilder.bind(queue).to(exchange).with("test.#").noargs(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
7.2消息可靠性投递
package com.crestv.lgpt.config.rabbitmq; import com.crestv.lgpt.utils.ExtLogger; import org.springframework.amqp.core.ReturnedMessage; import org.springframework.amqp.rabbit.connection.CorrelationData; import org.springframework.amqp.rabbit.core.RabbitTemplate; import org.springframework.stereotype.Component; import javax.annotation.PostConstruct; import javax.annotation.Resource; import java.nio.charset.StandardCharsets; /** * 自定义消息发送确认的回调 * 实现接口:implements RabbitTemplate.ConfirmCallback, RabbitTemplate.ReturnCallback * ConfirmCallback:只确认消息是否正确到达交换机中,不管是否到达交换机,该回调都会执行;(不安全),被淘汰了, * 因为消息只要不到达队列都算丢失 * returnedMessage:如果消息从交换机未正确到达队列中将会执行,正确到达则不执行;把消息记录到日志,至少没丢 * 还可以记录到数据库或者Redis */ @Component public class CustomConfirmAndReturnCallback implements RabbitTemplate.ConfirmCallback, RabbitTemplate.ReturnsCallback { private static final ExtLogger LOGGER = ExtLogger.getLogger(CustomConfirmAndReturnCallback.class); @Resource private RabbitTemplate rabbitTemplate; @PostConstruct public void init() { rabbitTemplate.setConfirmCallback(this); rabbitTemplate.setReturnsCallback(this); } @Override public void confirm(CorrelationData correlationData, boolean ack, String cause) { if(ack) { LOGGER.message("{} 到达队列成功!", correlationData.getId()); } else { LOGGER.message("{} 到达队列失败! 原因: {}", correlationData.getId(), cause); } } @Override public void returnedMessage(ReturnedMessage returnedMessage) { LOGGER.message("消息: {}, 错误码: {}, 错误原因: {}, 交换机: {}, 路由: {}", new String(returnedMessage.getMessage().getBody(), StandardCharsets.UTF_8), returnedMessage.getReplyCode(), returnedMessage.getReplyText(), returnedMessage.getExchange(), returnedMessage.getRoutingKey()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
二十九、腾讯云COS
1.pom文件
<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.4.0</version> </parent> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <!--web 需要启动项目--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-validation</artifactId> </dependency> <!--lombok库--> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.10</version> </dependency> <!--fastjson--> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.76</version> </dependency> <!--AES加密等--> <dependency> <groupId>org.bouncycastle</groupId> <artifactId>bcprov-jdk16</artifactId> <version>1.46</version> </dependency> <!--指定了 Commons BeanUtils 库 用来操作JavaBean--> <dependency> <groupId>commons-beanutils</groupId> <artifactId>commons-beanutils</artifactId> <version>1.9.4</version> </dependency> <!--jackson--> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> </dependency> <!--指定了 Apache HttpComponents 库中的 httpclient 模块--> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.13</version> </dependency> <!--用于压缩和解压缩数据的 Java 库--> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-compress</artifactId> <version>1.20</version> </dependency> <!--是一个用于处理 HTTP 请求的 MIME 实体的 Java 库--> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpmime</artifactId> <version>4.5.13</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> </dependency> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-lang3</artifactId> <version>3.12.0</version> </dependency> <dependency> <groupId>io.swagger</groupId> <artifactId>swagger-annotations</artifactId> <version>1.5.21</version> </dependency> <dependency> <groupId>io.swagger</groupId> <artifactId>swagger-models</artifactId> <version>1.5.21</version> </dependency> <dependency> <groupId>io.springfox</groupId> <artifactId>springfox-swagger2</artifactId> <version>2.9.2</version> <exclusions> <exclusion> <groupId>io.swagger</groupId> <artifactId>swagger-annotations</artifactId> </exclusion> <exclusion> <groupId>io.swagger</groupId> <artifactId>swagger-models</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>io.springfox</groupId> <artifactId>springfox-swagger-ui</artifactId> <version>2.9.2</version> </dependency> <dependency> <groupId>com.github.xiaoymin</groupId> <!--使用Swagger2--> <artifactId>knife4j-spring-boot-starter</artifactId> <version>2.0.9</version> </dependency> <dependency> <groupId>io.github.resilience4j</groupId> <artifactId>resilience4j-ratelimiter</artifactId> <version>1.7.1</version> </dependency> <dependency> <groupId>com.qcloud</groupId> <artifactId>cos_api</artifactId> <version>5.6.97</version> </dependency> </dependencies>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
2.配置文件
#腾讯云 cos
tencent.cos.SecretId=自己的
tencent.cos.SecretKey=自己的
tencent.cos.region=ap-guangzhou
tencent.cos.bucketName=crest-test-1305644510
# 端口
server.port=6066
#修改文件大小限制
spring.servlet.multipart.max-file-size=100MB
spring.servlet.multipart.max-request-size=1000MB
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
3.控制层
package com.test.costest.controller; import com.test.costest.service.FileService; import io.swagger.annotations.Api; import io.swagger.annotations.ApiOperation; import org.springframework.web.bind.annotation.*; import org.springframework.web.multipart.MultipartFile; import javax.annotation.Resource; @Api(tags = "腾讯云demo") @RestController @RequestMapping("/front") public class FrontFileController { @Resource private FileService fileService; @PostMapping(value="/fillLoad") @ApiOperation(value = "上传文件") public void addUser(@RequestPart("file") MultipartFile file) { fileService.upload(file); } @GetMapping(value = "/downFile") @ApiOperation(value = "下载文件") public void down(String key,String localFolderPath) { fileService.download(key, localFolderPath); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
4.服务层
package com.test.costest.service; import org.springframework.web.multipart.MultipartFile; public interface FileService { /** * cos上传对象 * @param file */ void upload(MultipartFile file); /** * 下载对象 * @param key * @param localFolderPath */ void download(String key,String localFolderPath); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
package com.test.costest.service.impl; import com.qcloud.cos.COSClient; import com.qcloud.cos.ClientConfig; import com.qcloud.cos.auth.BasicCOSCredentials; import com.qcloud.cos.auth.COSCredentials; import com.qcloud.cos.exception.CosClientException; import com.qcloud.cos.exception.CosServiceException; import com.qcloud.cos.http.HttpProtocol; import com.qcloud.cos.model.*; import com.qcloud.cos.region.Region; import com.qcloud.cos.transfer.Download; import com.qcloud.cos.transfer.TransferManager; import com.qcloud.cos.transfer.TransferManagerConfiguration; import com.qcloud.cos.transfer.Upload; import com.test.costest.service.FileService; import org.joda.time.DateTime; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.beans.factory.annotation.Value; import org.springframework.stereotype.Service; import org.springframework.web.multipart.MultipartFile; import java.io.File; import java.io.IOException; import java.util.UUID; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; /** * @Description: 腾讯云demo * @Author guop * @Date 2023/4/21 8:34 */ @Service public class FileServiceImpl implements FileService { @Value("${tencent.cos.SecretId}") private String secretId; @Value("${tencent.cos.SecretKey}") private String secretKey; @Value("${tencent.cos.region}") private String region; @Value("${tencent.cos.bucketName}") private String bucketName; /** * cos上传对象 * @param file */ @Override public void upload(MultipartFile file) { // 使用高级接口必须先保证本进程存在一个 TransferManager 实例,如果没有则创建 // 详细代码参见本页:高级接口 -> 创建 TransferManager TransferManager transferManager = createTransferManager(); String folder = new DateTime().toString("yyyy/MM/dd/"); //文件名:uuid.扩展名 String fileName = UUID.randomUUID().toString(); String originalFilename = file.getOriginalFilename(); String fileExtension = originalFilename.substring(originalFilename.lastIndexOf(".")); String key = folder + fileName + fileExtension; // 对象键(Key)是对象在存储桶中的唯一标识。 File tempFile = null; try { tempFile = File.createTempFile("temp", null); file.transferTo(tempFile); tempFile.deleteOnExit(); } catch (IOException e) { e.printStackTrace(); } // 创建 PutObjectRequest 对象 PutObjectRequest putObjectRequest = new PutObjectRequest(bucketName, key, tempFile); // 设置存储类型(如有需要,不需要请忽略此行代码), 默认是标准(Standard), 低频(standard_ia) // 更多存储类型请参见 https://cloud.tencent.com/document/product/436/33417 putObjectRequest.setStorageClass(StorageClass.Standard_IA); try { // 高级接口会返回一个异步结果Upload // 可同步地调用 waitForUploadResult 方法等待上传完成,成功返回 UploadResult, 失败抛出异常 Upload upload = transferManager.upload(putObjectRequest); UploadResult uploadResult = upload.waitForUploadResult(); } catch (CosServiceException e) { e.printStackTrace(); } catch (CosClientException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } // 确定本进程不再使用 transferManager 实例之后,关闭之 // 详细代码参见本页:高级接口 -> 关闭 TransferManager shutdownTransferManager(transferManager); } /** * 下载对象 * * @param key * @param localFolderPath */ @Override public void download(String key, String localFolderPath) { // 使用高级接口必须先保证本进程存在一个 TransferManager 实例,如果没有则创建 // 详细代码参见本页:高级接口 -> 创建 TransferManager TransferManager transferManager = createTransferManager(); // 对象键(Key)是对象在存储桶中的唯一标识。详情请参见 [对象键](https://cloud.tencent.com/document/product/436/13324) // 提取文件名 String fileName = key.substring(key.lastIndexOf("/") + 1); // 构建本地文件路径 String localFilePath = localFolderPath + File.separator + fileName; File downloadFile = new File(localFilePath); GetObjectRequest getObjectRequest = new GetObjectRequest(bucketName, key); try { // 返回一个异步结果 Download, 可同步的调用 waitForCompletion 等待下载结束, 成功返回 void, 失败抛出异常 Download download = transferManager.download(getObjectRequest, downloadFile); download.waitForCompletion(); } catch (CosServiceException e) { e.printStackTrace(); } catch (CosClientException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } // 确定本进程不再使用 transferManager 实例之后,关闭之 // 详细代码参见本页:高级接口 -> 关闭 TransferManager shutdownTransferManager(transferManager); } void shutdownTransferManager(TransferManager transferManager) { // 指定参数为 true, 则同时会关闭 transferManager 内部的 COSClient 实例。 // 指定参数为 false, 则不会关闭 transferManager 内部的 COSClient 实例。 transferManager.shutdownNow(true); } // 创建 TransferManager 实例,这个实例用来后续调用高级接口 TransferManager createTransferManager() { // 创建一个 COSClient 实例,这是访问 COS 服务的基础实例。 // 详细代码参见本页: 简单操作 -> 创建 COSClient COSClient cosClient = createCOSClient(); // 自定义线程池大小,建议在客户端与 COS 网络充足(例如使用腾讯云的 CVM,同地域上传 COS)的情况下,设置成16或32即可,可较充分的利用网络资源 // 对于使用公网传输且网络带宽质量不高的情况,建议减小该值,避免因网速过慢,造成请求超时。 ExecutorService threadPool = Executors.newFixedThreadPool(32); // 传入一个 threadpool, 若不传入线程池,默认 TransferManager 中会生成一个单线程的线程池。 TransferManager transferManager = new TransferManager(cosClient, threadPool); // 设置高级接口的配置项 // 分块上传阈值和分块大小分别为 5MB 和 1MB TransferManagerConfiguration transferManagerConfiguration = new TransferManagerConfiguration(); transferManagerConfiguration.setMultipartUploadThreshold(5 * 1024 * 1024); transferManagerConfiguration.setMinimumUploadPartSize(1 * 1024 * 1024); transferManager.setConfiguration(transferManagerConfiguration); return transferManager; } // 创建 COSClient 实例,这个实例用来后续调用请求 COSClient createCOSClient() { // 设置用户身份信息。 // SECRETID 和 SECRETKEY 请登录访问管理控制台 https://console.cloud.tencent.com/cam/capi 进行查看和管理 COSCredentials cred = new BasicCOSCredentials(secretId, secretKey); // ClientConfig 中包含了后续请求 COS 的客户端设置: ClientConfig clientConfig = new ClientConfig(); // 设置 bucket 的地域 // COS_REGION 请参见 https://cloud.tencent.com/document/product/436/6224 clientConfig.setRegion(new Region(region)); // 设置请求协议, http 或者 https // 5.6.53 及更低的版本,建议设置使用 https 协议 // 5.6.54 及更高版本,默认使用了 https clientConfig.setHttpProtocol(HttpProtocol.https); // 以下的设置,是可选的: // 设置 socket 读取超时,默认 30s clientConfig.setSocketTimeout(30 * 1000); // 设置建立连接超时,默认 30s clientConfig.setConnectionTimeout(30 * 1000); // 如果需要的话,设置 http 代理,ip 以及 port // clientConfig.setHttpProxyIp("httpProxyIp"); // clientConfig.setHttpProxyPort(80); // 生成 cos 客户端。 return new COSClient(cred, clientConfig); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
5.dto
package com.test.costest.dto; import lombok.Data; @Data public class ResponseDto<T> { /** * 状态码 */ private Integer code; /** * 状态信息 */ private String message; /** * 数据 */ private T data; public ResponseDto(Integer code, String message, T data) { this.code = code; this.data = data; this.message = message; } public ResponseDto(T data) { this.code = 10000; this.data = data; this.message = "成功并返回数据"; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
6.config配置
package com.test.costest.config; import com.qcloud.cos.COSClient; import com.qcloud.cos.ClientConfig; import com.qcloud.cos.auth.BasicCOSCredentials; import com.qcloud.cos.auth.COSCredentials; import com.qcloud.cos.region.Region; import lombok.Data; import org.springframework.beans.factory.annotation.Value; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration @Data public class ConstantProperties { @Value("${tencent.cos.SecretId}") private String secretId; @Value("${tencent.cos.SecretKey}") private String secretKey; @Value("${tencent.cos.region}") private String region; @Value("${tencent.cos.bucketName}") private String bucketName; // @Value("${tencent.cos.url}") // private String path; @Bean public COSClient cosClient(){ // 1 初始化用户身份信息(secretId, secretKey)。 COSCredentials cred = new BasicCOSCredentials(this.secretId, this.secretKey); // 2 设置 bucket 的区域, COS 地域的简称请参照 Region region = new Region(this.region); ClientConfig clientConfig = new ClientConfig(region); // 3 生成 cos 客户端。 COSClient cosClient = new COSClient(cred, clientConfig); return cosClient; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
package com.test.costest.config; import com.github.xiaoymin.knife4j.spring.annotations.EnableKnife4j; import org.springframework.boot.autoconfigure.condition.ConditionalOnExpression; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import springfox.documentation.builders.ApiInfoBuilder; import springfox.documentation.builders.PathSelectors; import springfox.documentation.builders.RequestHandlerSelectors; import springfox.documentation.service.ApiInfo; import springfox.documentation.spi.DocumentationType; import springfox.documentation.spring.web.plugins.Docket; import springfox.documentation.swagger2.annotations.EnableSwagger2; @Configuration @EnableKnife4j @EnableSwagger2 @ConditionalOnExpression public class Knife4jConfig { @Bean(value = "createRestApi") public Docket createRestApi() { return new Docket(DocumentationType.SWAGGER_2) .apiInfo(apiInfo()) .select() .apis(RequestHandlerSelectors.basePackage("com.test.costest.controller")) .paths(PathSelectors.any()) .build(); } private ApiInfo apiInfo() { return new ApiInfoBuilder().title("lgpt项目对接文档").version("1.0").build(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
7.启动类
package com.test.costest; import lombok.extern.slf4j.Slf4j; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @Slf4j @SpringBootApplication public class CosProjectApplication { public static void main(String[] args) { SpringApplication.run(CosProjectApplication.class, args); log.info("http://localhost:6066/doc.html"); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
三十、mysql题解
1.金额排序
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT BEGIN SET N := N-1; RETURN ( # Write your MySQL query statement below. SELECT salary FROM employee GROUP BY salary ORDER BY salary DESC LIMIT N, 1 ); END
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
这是一个 MySQL 存储过程,它的目的是返回员工工资表中第 N 高的薪资数额。下面是对存储过程中各个部分的解释:
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT:这一行代码定义了一个名为getNthHighestSalary的函数,该函数需要一个名为 N 的整数参数,并且将返回一个整数。BEGIN:这标志着存储过程代码的开始。set n:=n-1;:这一行将传递给函数的参数N减去 1 并赋值给变量n。这是因为在 SQL 中,limit从 0 开始计数,所以我们需要将N减 1 才能获得正确的结果。RETURN:这个关键字表明函数要返回一个值。select salary from employee group by salary order by salary desc limit n,1:这是实际执行查询的代码。它从employee表中选择salary列,然后按照salary列进行分组,并按照salary列的降序对组进行排序。最后,它使用limit子句返回第n行,而1表示只返回一行。END:这表示存储过程代码的结束。
综上所述,该函数返回第 N 高的薪资数额,它使用了 SQL 中的分组和排序功能以及 limit 子句来实现。
2.分数排名
SELECT Score,
dense_rank() over(order by Score desc) as 'Rank'
FROM Scores
- 1
- 2
- 3
这段 SQL 查询语句使用了窗口函数 dense_rank() 来为 Scores 表中的每个成绩计算排名,并将结果集中每个成绩的排名作为一个新的列名 Rank 返回。下面对这段 SQL 查询语句进行逐一解释:
SELECT Score,
dense_rank() over(order by Score desc) as 'Rank'
FROM Scores
- 1
- 2
- 3
SELECT Score:选取Scores表中的Score列,这是查询的输出列之一。dense_rank() over(order by Score desc):使用窗口函数dense_rank()计算每个成绩在所有成绩中的排名。在over()子句中,order by Score desc指定按照Score列的降序排列来计算排名。因此,排名最高的成绩的排名为 1,排名第二的成绩的排名为 2,以此类推。as 'Rank':将计算出的排名结果命名为一个新的列名Rank。FROM Scores:指定查询的数据源是Scores表。
综合来看,这段 SQL 查询语句将返回一个结果集,其中包含了 Scores 表中每个成绩的值和其在所有成绩中的排名。例如,如果 Scores 表中有以下成绩数据:
Score
-----
80
90
75
85
- 1
- 2
- 3
- 4
- 5
- 6
那么,这段 SQL 查询语句将返回以下结果:
Score | Rank
------+------
90 | 1
85 | 2
80 | 3
75 | 4
- 1
- 2
- 3
- 4
- 5
- 6
其中,每个成绩的排名根据其在所有成绩中的位置进行计算,且按照成绩的降序排列来排序。因此,90 分是所有成绩中排名第一,85 分是排名第二,80 分是排名第三,75 分是排名第四。
三十一、mysql的技巧以及函数
1.dense_rank()函数
dense_rank() 是 MySQL 中的一种窗口函数,它用于计算在一个有序集合中的某个元素的密集排名。与 rank() 和 row_number() 函数不同,dense_rank() 在处理重复值时,会跳过重复值并根据下一个可用的排名计算密集排名。
具体来说,dense_rank() 函数在对一个数据集中的某一列进行排序后,为每一行计算一个排名值,排名值与该行在排序后的数据集中的位置相关。如果有多个行具有相同的排序键(排序列的值),则它们的密集排名将相同,并且下一个可用的排名将是它们的下一个非重复值的密集排名。
以下是使用 dense_rank() 函数计算密集排名的示例:
假设有一个包含以下数据的表:
Score
-----
80
90
75
85
80
- 1
- 2
- 3
- 4
- 5
- 6
- 7
要计算 Score 列中每个值的密集排名,可以使用以下 SQL 语句:
SELECT Score, dense_rank() over(order by Score desc) as 'Rank' FROM Scores;
- 1
执行这个查询语句后,将得到如下结果:
Score | Rank
------+------
90 | 1
85 | 2
80 | 3
80 | 3
75 | 4
- 1
- 2
- 3
- 4
- 5
- 6
- 7
在这个例子中,dense_rank() 函数按 Score 列的值进行降序排序,并为每个值计算一个密集排名。在数据集中,有两个值为 80,它们的密集排名相同,都是第 3 名。第 4 名是值为 75 的行,因为前面有三个不同的值(90、85 和 80),它们的密集排名分别是第 1、第 2 和第 3 名。
2.RANK(),DENSE_RANK()和ROW_NUMBER()
在 MySQL 中,有三种常用的窗口函数:RANK()、DENSE_RANK() 和 ROW_NUMBER()。它们都可以用于计算排名和行号,但计算方式略有不同。
RANK():计算排名,排名相同的数据具有相同的排名,并跳过下一个排名。例如,如果有两个数据的排名是第 1 名,则下一个排名应该是第 3 名。因此,RANK()函数会跳过第 2 名。例如,如果有以下成绩数据:
Score
-----
80
90
75
85
80
- 1
- 2
- 3
- 4
- 5
- 6
- 7
那么,RANK() 函数将返回以下排名结果:
Score | Rank
------+-----
90 | 1
85 | 2
80 | 3
80 | 3
75 | 5
- 1
- 2
- 3
- 4
- 5
- 6
- 7
DENSE_RANK():计算密集排名,与RANK()函数类似,但是对于排名相同的数据,密集排名不会跳过下一个排名。例如,如果有两个数据的排名是第 1 名,则下一个密集排名仍然是第 2 名。因此,DENSE_RANK()函数不会跳过任何排名。例如,如果有以下成绩数据:
Score
-----
80
90
75
85
80
- 1
- 2
- 3
- 4
- 5
- 6
- 7
那么,DENSE_RANK() 函数将返回以下密集排名结果:
Score | Rank
------+-----
90 | 1
85 | 2
80 | 3
80 | 3
75 | 4
- 1
- 2
- 3
- 4
- 5
- 6
- 7
ROW_NUMBER():计算行号,为每行分配一个唯一的行号。行号不考虑任何排名或排序规则,只与结果集中的行顺序相关。例如,如果有以下成绩数据:
Score
-----
80
90
75
85
- 1
- 2
- 3
- 4
- 5
- 6
那么,ROW_NUMBER() 函数将返回以下行号结果:
Score | RowNumber
------+----------
80 | 1
90 | 2
75 | 3
85 | 4
- 1
- 2
- 3
- 4
- 5
- 6
需要注意的是,这些函数都是 MySQL 中的窗口函数,它们只能在 OVER() 子句中使用,以指定窗口的范围和排序规则。
三十二、泛型
1.泛型类和泛型方法怎么声明和使用,T在不同位置代表什么
泛型类和泛型方法是 Java 语言提供的一种类型安全机制,可以让程序员在编写代码时更加灵活地处理不同类型的数据。
泛型类的声明和使用
声明一个泛型类需要在类名后加上尖括号,括号内是一个或多个用逗号分隔的类型参数。例如,下面是一个用于表示一对值的泛型类 Pair:
public class Pair<T, U> { private T first; private U second; public Pair(T first, U second) { this.first = first; this.second = second; } public T getFirst() { return first; } public U getSecond() { return second; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
在上面的例子中,T 和 U 是类型参数,表示 Pair 类可以存储两个不同类型的对象。当创建 Pair 类的对象时,需要指定类型参数的具体类型。例如:
Pair<String, Integer> pair = new Pair<>("hello", 123);
String first = pair.getFirst();
int second = pair.getSecond();
- 1
- 2
- 3
在上面的代码中,我们创建了一个 Pair 对象,指定了 T 类型为 String,U 类型为 Integer。可以通过 getFirst 和 getSecond 方法获取存储在 Pair 对象中的值。
泛型方法的声明和使用
声明一个泛型方法需要在方法名前加上尖括号,括号内是一个或多个用逗号分隔的类型参数。例如,下面是一个用于打印数组元素的泛型方法 printArray:
public static <T> void printArray(T[] array) {
for (T element : array) {
System.out.println(element);
}
}
- 1
- 2
- 3
- 4
- 5
在上面的例子中,T 是类型参数,表示 printArray 方法可以接受任意类型的数组。可以调用该方法并传入一个具体类型的数组,例如:
String[] strings = {"hello", "world"};
Integer[] integers = {1, 2, 3};
printArray(strings); // 输出 "hello" 和 "world"
printArray(integers); // 输出 1、2 和 3
- 1
- 2
- 3
- 4
在上面的代码中,我们调用了 printArray 方法并分别传入了一个 String 数组和一个 Integer 数组。由于 printArray 是一个泛型方法,它可以接受任意类型的数组作为参数。
T 在不同位置代表的含义
在泛型类或泛型方法中,类型参数 T 可以出现在多个不同的位置,具体代表的含义如下:
- 在泛型类或泛型方法的参数列表中,T 表示一个类型参数,用于指定该类或方法的参数类型;
- 在泛型类或泛型方法的返回值类型中,T 表示一个类型参数,用于指定该类或方法的返回值类型;
- 在泛型类的成员变量或成员方法中,T 表示一个类型参数,用于指定该成员变量或成员方法的参数类型或返回值类型。
需要注意的是,在一个泛型类中,类型参数可以被多次使用,并且可以用不同的字母来表示不同的类型参数。例如,下面是一个泛型类 Triple,它用于表示三个值:
public class Triple<T, U, V> { private T first; private U second; private V third; public Triple(T first, U second, V third) { this.first = first; this.second = second; this.third = third; } public T getFirst() { return first; } public U getSecond() { return second; } public V getThird() { return third; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
在上面的例子中,我们定义了三个类型参数 T、U 和 V,用于表示 Triple 类可以存储三个不同类型的值。在 Triple 类的构造方法和成员方法中,我们使用了类型参数 T、U 和 V 来指定参数类型或返回值类型。
可以通过下面的代码来创建 Triple 类的对象:
Triple<String, Integer, Boolean> triple = new Triple<>("hello", 123, true);
String first = triple.getFirst();
int second = triple.getSecond();
boolean third = triple.getThird();
- 1
- 2
- 3
- 4
在上面的代码中,我们创建了一个 Triple 对象,指定了 T 类型为 String,U 类型为 Integer,V 类型为 Boolean。可以通过 getFirst、getSecond 和 getThird 方法获取存储在 Triple 对象中的值。
总的来说,泛型类和泛型方法可以让我们在编写代码时更加灵活地处理不同类型的数据,从而提高代码的可复用性和可读性。通过使用类型参数,我们可以将代码从特定的数据类型中解耦出来,使代码更加通用和易于维护。
2.泛型方法有什么用,为什么要在方法前声明
泛型方法是 Java 语言中的一种特殊方法,它可以接受任意类型的参数,并且可以在方法内部使用泛型类型。相比于普通方法,泛型方法具有以下优点:
-
提高代码复用性:泛型方法可以接受任意类型的参数,因此可以被多个不同类型的对象调用,从而提高代码的复用性。
-
增加代码灵活性:泛型方法可以在方法内部使用泛型类型,因此可以处理不同类型的数据,从而增加代码的灵活性。
-
增加代码安全性:泛型方法可以在编译时检查类型安全,防止因为类型转换错误导致的运行时异常。
在方法前声明泛型类型参数的语法如下:
public <T> void methodName(T param) {
// 方法体
}
- 1
- 2
- 3
在上面的代码中, 表示声明一个类型参数 T,它可以在方法内部使用。可以在方法参数列表中使用泛型类型参数 T,如上面的例子中的 param 参数。在方法体内部,可以使用 T 类型参数来声明变量、调用方法等。
当调用泛型方法时,编译器会根据传入的参数类型推断出泛型类型参数 T 的具体类型。例如,下面是一个使用泛型方法的例子:
public static <T> void printArray(T[] array) {
for (T element : array) {
System.out.println(element);
}
}
public static void main(String[] args) {
Integer[] integers = {1, 2, 3};
String[] strings = {"hello", "world"};
printArray(integers);
printArray(strings);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
在上面的例子中,我们声明了一个泛型方法 printArray,它可以接受任意类型的数组作为参数,并且可以打印数组中的每一个元素。在 main 方法中,我们分别传入了一个 Integer 数组和一个 String 数组,printArray 方法会根据传入的参数类型自动推断出泛型类型参数 T 的具体类型,从而可以正确地打印数组中的元素。
需要注意的是,泛型方法只对当前方法有效,并不会对整个类产生影响。因此,如果要在类中多个方法中使用泛型类型参数,需要在每个方法前都声明一次。
3.泛型和Object有什么区别
泛型和 Object 是 Java 语言中两种不同的类型处理机制,它们有以下区别:
-
类型安全性不同:泛型提供了编译时的类型检查机制,可以在编译期间检测类型错误,从而提高了类型安全性。而 Object 类型在编译期间不会检查类型,需要在运行时进行类型转换,容易导致 ClassCastException 异常。
-
可读性和可维护性不同:使用泛型可以提高代码的可读性和可维护性,因为它能够使代码更加清晰明了。相反,使用 Object 类型需要手动进行类型转换,增加了代码的复杂性,降低了代码的可读性和可维护性。
-
代码重用性不同:泛型可以让代码更加通用,从而提高代码的重用性。因为泛型可以在不同的类型之间进行转换,使得同一个方法可以处理不同类型的数据。而使用 Object 类型,则需要针对不同类型写不同的方法,代码重用性较低。
-
性能方面不同:在性能方面,使用 Object 类型进行类型转换会降低程序的性能,因为需要在运行时进行类型检查和转换。而泛型在编译时已经确定了类型,因此可以避免这种性能损失。
综上所述,泛型和 Object 在类型安全性、可读性和可维护性、代码重用性以及性能方面有不同的表现。在编写代码时,应根据实际情况选择使用泛型还是 Object。如果需要在编译时检查类型安全性,并且希望代码更加通用和易于维护,应使用泛型;如果对类型安全性要求不高,或者需要处理多个不相关的类型,可以使用 Object 类型。
三十三、JSON的各种转换
1.类转换为JSON格式的String
要将 OuterRequestVo 对象转换为 JSON 格式的字符串,可以使用 JSON 库来实现。常用的 JSON 库有 Google 的 Gson、阿里巴巴的 Fastjson 等。
以 Gson 为例,可以使用以下代码将 OuterRequestVo 对象转换为 JSON 格式的字符串:
Gson gson = new Gson();
String json = gson.toJson(outerRequestVo);
- 1
- 2
在上面的代码中,我们先创建了一个 Gson 对象,然后使用 toJson 方法将 outerRequestVo 对象转换为 JSON 格式的字符串。转换后的字符串可以通过 json 变量获取到。
如果使用 Fastjson,则可以使用以下代码将 OuterRequestVo 对象转换为 JSON 格式的字符串:
String json = JSON.toJSONString(outerRequestVo);
- 1
在上面的代码中,我们使用 JSON 工具类的 toJSONString 方法将 outerRequestVo 对象转换为 JSON 格式的字符串。转换后的字符串可以直接通过 json 变量获取到。
需要注意的是,转换为 JSON 格式的字符串需要保证 OuterRequestVo 对象中的属性都是可序列化的,否则可能会出现异常。通常情况下,只要 OuterRequestVo 中的属性都是基本数据类型、字符串、集合或其他可序列化的类型,就可以顺利进行转换。
2. JSON,JsonString,JsonObject,String之间的关系
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,它以简洁、易读的方式表示结构化数据。JSON 是一种文本格式,常用于数据的序列化和传输。
-
String:在编程中,String 是一种数据类型,表示一串字符。在 JSON 中,数据通常以字符串形式表示。
-
JSONString:JSONString 是 Java 中的一个接口,它定义了将对象转换为 JSON 格式的方法。实现该接口的类可以自定义对象转换为 JSON 字符串的逻辑。
-
JsonObject:JsonObject 是 JSON 中的一个概念,表示一个 JSON 对象,它由一组键值对组成,键是字符串,值可以是 JSON 的各种类型(字符串、数字、布尔值、数组、嵌套的 JSON 对象等)。
在 Java 中,可以使用不同的库进行 JSON 的解析和生成。其中,fastjson 是一种常用的 JSON 处理库,它提供了丰富的 API 来处理 JSON 数据。下面是使用 fastjson 进行相互转换的示例:
-
JSON 字符串与 Java 对象之间的转换:
- 将 JSON 字符串转换为 Java 对象:
String jsonString = "{\"name\":\"John\",\"age\":30}"; JSONObject jsonObject = JSON.parseObject(jsonString);- 1
- 2
- 将 Java 对象转换为 JSON 字符串:
Person person = new Person("John", 30); String jsonString = JSON.toJSONString(person);- 1
- 2
- 将 JSON 字符串转换为 Java 对象:
-
JSON 字符串与 JsonObject 之间的转换:
- 将 JSON 字符串转换为 JsonObject:
String jsonString = "{\"name\":\"John\",\"age\":30}"; JSONObject jsonObject = JSON.parseObject(jsonString);- 1
- 2
- 将 JsonObject 转换为 JSON 字符串:
JSONObject jsonObject = new JSONObject(); jsonObject.put("name", "John"); jsonObject.put("age", 30); String jsonString = jsonObject.toJSONString();- 1
- 2
- 3
- 4
- 将 JSON 字符串转换为 JsonObject:
-
Java 对象与 JsonObject 之间的转换:
- 将 Java 对象转换为 JsonObject:
Person person = new Person("John", 30); JSONObject jsonObject = (JSONObject) JSON.toJSON(person);- 1
- 2
- 将 JsonObject 转换为 Java 对象:
JSONObject jsonObject = new JSONObject(); jsonObject.put("name", "John"); jsonObject.put("age", 30); Person person = JSON.toJavaObject(jsonObject, Person.class);- 1
- 2
- 3
- 4
- 将 Java 对象转换为 JsonObject:
通过上述示例,你可以看到 fastjson 提供了 parseObject() 方法用于将 JSON 字符串解析为 JsonObject 或 Java 对象,toJSONString() 方法用于将 JsonObject 或 Java 对象转换为 JSON 字符串。同时,你还可以通过 toJSON() 方法将 Java 对象转换为 JsonObject,或者使用 toJavaObject() 方法将 JsonObject 转换为 Java 对象。
需要注意的是,以上示例中的 Person 类是一个自定义的类,你可以根据实际需要定义自己的 Java 类来映射 JSON 数据。
3.JSONobject和jsonstirng有什么区别
JSONObject 和 JSONString 是 JSON 数据处理中的两个不同的概念和类:
-
JSONObject:JSONObject是一种数据结构或数据类型,在不同的编程语言中具有不同的实现。在 Java 中,JSONObject是 fastjson 库提供的一个类,用于表示 JSON 对象。它由一组键值对组成,键是字符串,值可以是各种 JSON 数据类型(字符串、数字、布尔值、数组、嵌套的 JSON 对象等)。JSONObject类提供了方法来访问和操作 JSON 对象的键值对。 -
JSONString:JSONString是一个接口,用于表示可以被转换为 JSON 字符串的对象。在 Java 中,fastjson 库为JSONString提供了默认的实现。当一个类实现了JSONString接口,并重写了toJSONString()方法时,fastjson 在将该类转换为 JSON 字符串时会使用该方法的逻辑,而不是默认的对象转换规则。通过实现JSONString接口,你可以对对象转换为 JSON 字符串的行为进行自定义。
区别:
JSONObject是表示 JSON 对象的数据结构或类,用于在代码中操作和访问 JSON 数据的键值对。JSONString是一个接口,用于定义对象如何转换为 JSON 字符串的规则。它允许你自定义对象转换为 JSON 字符串的逻辑,而不依赖于默认的转换规则。
在 fastjson 中,JSONObject 类用于表示和操作 JSON 对象,而 JSONString 接口可以让你自定义对象如何转换为 JSON 字符串。
三十四、单点登录和单会话限制
1.单点登录
单点登录(Single Sign-On,简称 SSO)是一种身份验证机制,允许用户使用一组凭据(如用户名和密码)登录多个与之关联的系统或服务。通过这种方式,用户无需为每个系统或服务单独登录,从而提高了用户体验和操作便利性。在用户登录某个系统或服务后,其他关联的系统将自动识别该用户,无需再次验证身份。
单点登录的使用场景包括:
- 企业内部系统集成:大型企业通常拥有多个内部系统,如企业资源计划(ERP)系统、客户关系管理(CRM)系统、人力资源管理系统等。通过单点登录,员工只需使用一组凭据登录企业门户,即可访问所有关联的内部系统,提高工作效率。
- 跨组织协作:在多个组织之间进行合作时,单点登录可以实现跨组织的身份验证,简化跨组织访问控制。例如,大学和图书馆可以使用单点登录,使学生和教师使用学校提供的凭据访问图书馆的电子资源。
- 社交媒体与第三方服务集成:许多社交媒体网站(如 Facebook、Google 等)允许用户使用其账户凭据登录其他第三方应用和服务。通过单点登录,用户无需为每个第三方服务创建新的账户,简化了注册和登录流程。
实现单点登录的方法有多种,如 OAuth、OpenID Connect、SAML(安全断言标记语言)等。这些方法都有各自的优缺点,具体选择需要根据实际场景和需求进行评估。
2.Java一般怎么实现单点登录,怎么实现单会话限制
在 Java 中实现单点登录(Single Sign-On, SSO)和单会话限制(Single Session Restriction)的方法有很多。这里我将简要介绍两种常见的方法。
- 实现单点登录(SSO)
使用 Spring Security 可以轻松实现单点登录。常见的方法是使用 OAuth2 和 OpenID Connect。以下是实现 SSO 的简要步骤:
- 创建一个认证服务器(Authorization Server),用于处理用户的认证和授权。可以使用 Spring Security OAuth2 创建并配置一个认证服务器。
- 在认证服务器上配置一个用户存储,例如内存用户存储、数据库用户存储或 LDAP 用户存储。
- 在关联的客户端应用程序中,配置一个 OAuth2 客户端,用于与认证服务器进行通信。可以使用 Spring Security OAuth2 Client 配置一个 OAuth2 客户端。
- 当用户尝试登录客户端应用程序时,客户端将重定向用户到认证服务器进行身份验证。验证成功后,认证服务器将向客户端颁发一个访问令牌(access token)或 ID 令牌(ID token)。
- 客户端应用程序可以使用这些令牌来访问其他关联的服务,而无需再次验证用户的身份。
- 实现单会话限制(Single Session Restriction)
要在 Spring Security 中实现单会话限制,可以使用其内置的会话管理功能。以下是实现单会话限制的简要步骤:
-
在 Spring Security 配置类中,启用会话管理:
@Configuration @EnableWebSecurity public class SecurityConfig extends WebSecurityConfigurerAdapter { @Override protected void configure(HttpSecurity http) throws Exception { http.sessionManagement() .sessionCreationPolicy(SessionCreationPolicy.IF_REQUIRED) .maximumSessions(1) .expiredUrl("/session-expired"); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
在这个示例中,我们设置了
maximumSessions(1),这意味着每个用户只允许有一个活跃会话。如果用户尝试在另一个设备或浏览器上登录,之前的会话将失效,并将用户重定向到/session-expired页面。 -
根据需要,创建一个
/session-expired页面,用于告知用户他们的会话已过期。
这些方法可以帮助您在 Java 应用程序中实现单点登录和单会话限制。当然,实际的实现可能需要更多详细的配置和调整,以满足特定的需求和场景。
三十五、Flyway
1.配置
flyway:
enabled: true
locations: classpath:db/migration/mysql
# 当迁移时发现目标schema非空,而且带有没有元数据的表时,是否自动执行基准迁移
baseline-on-migrate: true
# 是否允许无序的迁移 开发环境最好开启, 生产环境关闭
out-of-order: true
# 关闭占位符替换,因为插入的sql里边可能包含${}关键字
placeholder-replacement: false
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这是一个Spring Boot应用中的Flyway配置。以下是每个属性的含义:
-
flyway.enabled: true:这个属性表示启用Flyway。如果设置为false,Flyway将被禁用,不会执行任何数据库迁移。 -
flyway.locations: classpath:db/migration/mysql:这个属性指定了存放SQL迁移脚本的位置。在这个例子中,脚本位于src/main/resources/db/migration/mysql目录下。 -
flyway.baseline-on-migrate: true:当你的数据库不是空的,且还没有Flyway的元数据表时,这个属性决定了是否在首次迁移时创建一个基线。也就是说,Flyway会假设现有的数据库所有的表都已经在基线版本中,然后只执行基线版本之后的迁移。 -
flyway.out-of-order: true:这个属性决定了当发现迁移脚本的版本号比已经迁移的版本号小的时候,是否应该运行这个迁移脚本。在开发环境中,开发人员可能会并行开发多个特性,这时可能需要这个选项。在生产环境中,通常应该保持版本号的严格顺序,所以这个选项通常应该关闭。 -
flyway.placeholder-replacement: false:这个属性用于开启或关闭占位符替换。占位符是SQL脚本中的特殊字符串,比如${tableName},Flyway会在运行SQL脚本之前替换这些占位符。在这个例子中,由于SQL脚本中可能包含${},但并不希望它们被替换,所以关闭了占位符替换。
2.简单来说
Flyway是一个开源的数据库版本控制和迁移工具。它可以帮助你管理和控制数据库的版本,包括表结构和数据的变化。Flyway使用一系列的SQL脚本(也可以是Java代码)来进行数据库的迁移,每个脚本对应数据库的一个版本。
简单来说,你提供的Flyway配置做的事情如下:
-
启用Flyway:Flyway会在你的应用启动时运行。
-
指定SQL脚本的位置:Flyway会在
classpath:db/migration/mysql这个路径下查找SQL脚本。 -
在数据库不是空的情况下执行基线迁移:如果你的数据库已经有一些表,但还没有使用Flyway管理,Flyway会把当前的数据库状态作为初始版本,然后只执行新的迁移。
-
允许无序的迁移:如果你有新的SQL脚本,即使它的版本号比已经执行的版本号小,Flyway也会执行它。
-
关闭占位符替换:在你的SQL脚本中,Flyway不会尝试替换
${}这样的占位符。
总的来说,Flyway会在你的应用启动时,按照SQL脚本的版本顺序(可以不严格按照顺序)执行这些脚本,以此来升级(或降级)你的数据库。这对于在多个环境(如开发、测试、生产环境)保持数据库的一致性,以及追踪数据库的变化非常有用。
N、其他
1.@Configuration
@Configuration是一个注解,表示这个类是一个Java配置类,用于定义Bean的配置信息。在Spring中,Bean是一个由Spring容器实例化、管理和组装的对象,可以是任何的Java对象。
@Configuration通常与@Bean一起使用,@Bean用于定义一个Bean,其返回值就是Bean的实例。在@Configuration类中,我们可以定义多个@Bean方法,用于实例化不同的Bean,并配置它们之间的依赖关系。当Spring容器初始化时,会自动调用这些@Bean方法来创建Bean实例,然后将它们装配到应用程序中。
@Configuration也可以使用@ComponentScan注解来扫描指定的包,自动装配标有@Component等注解的Bean。此外,@Import注解可以用来导入其他配置类,从而将它们的Bean定义合并到当前配置类中。
2.定时任务
定时任务是指按照一定的时间间隔或特定的时间点自动执行的任务。在Java中,我们可以使用Spring框架提供的@Scheduled注解来实现定时任务。该注解可以标注在方法上,并且可以设置定时任务执行的时间间隔、执行时间点等属性。
下面是一个简单的定时任务的示例:
@Component
public class MyTask {
@Scheduled(fixedRate = 5000) //每隔5秒执行一次
public void task() {
//定时任务的具体逻辑
System.out.println("定时任务执行了");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在上述示例中,我们创建了一个名为MyTask的定时任务类,并标注了@Scheduled注解。该注解中的fixedRate属性表示每隔5秒执行一次该方法。
除了fixedRate属性外,@Scheduled注解还支持其他属性,如cron、fixedDelay等,可以根据具体需求进行设置。
需要注意的是,我们需要在Spring的配置类中添加@EnableScheduling注解,以开启定时任务的支持。例如:
@Configuration
@EnableScheduling
public class AppConfig {
//其他配置
}
- 1
- 2
- 3
- 4
- 5
3.@RequestParam和@RequestBody
@RequestParam和@RequestBody是Spring MVC框架中常用的两种参数传递方式:
@RequestParam用于获取请求参数,一般用于接收GET请求中的参数或者POST请求中的简单参数,比如字符串或数字等。在方法中使用@RequestParam注解,指定参数名和是否必填,如:
@GetMapping("/user")
public User getUser(@RequestParam("id") Long id, @RequestParam(value = "name", required = false) String name) {
// ...
}
- 1
- 2
- 3
- 4
@RequestBody用于获取请求体中的数据,一般用于接收POST请求中的复杂参数,比如JSON格式的数据。在方法中使用@RequestBody注解,将请求体中的数据绑定到指定的Java对象上,如:
@PostMapping("/user")
public User createUser(@RequestBody User user) {
// ...
}
- 1
- 2
- 3
- 4
需要注意的是,@RequestBody只能用于POST请求,且请求体中的数据需要是可读取的字符流,因此需要设置Content-Type为application/json等格式。
加上@RequestBody后请求类型变成"body",也是是接收的数据是个对象,如果不加注解那么请求类型就会变成query,拼接在请求地址上,这样就会变的不安全,所以post方法都加上@requestbody注解,并且params的值只能是一个字符串,不能传递对象类型的参数。在HTTP协议中,GET请求是通过URL传递参数的,而POST请求是通过请求体(RequestBody)传递参数的。因此,当使用@RequestBody注解时,Spring会将请求体中的数据解析为参数。而不使用@RequestBody注解时,Spring会将参数解析为URL中的查询参数(query parameter)。
4.为什么@RequestParam可以接收MultipartFile
@RequestParam 是 SpringMVC 提供的一种用于获取请求参数的注解。它可以用来获取 GET 和 POST 请求中的参数,它主要用于获取简单类型的参数,比如 String、int 等。
而对于文件上传的情况,我们一般使用 MultipartFile 来接收文件。但是,在 SpringMVC 中,如果我们使用 @RequestParam 注解来接收参数,如果参数的类型是 MultipartFile,它会自动将上传的文件转化为 MultipartFile 对象。
这是因为,SpringMVC 内部会使用 CommonsMultipartResolver 来处理文件上传,而 CommonsMultipartResolver 可以将 multipart/form-data 类型的请求中的参数封装成 MultipartFile 类型的对象,供开发者使用。因此,即使使用 @RequestParam 注解来接收参数,也可以获取到上传的文件。
5.html,css,js和vue之间的关系
HTML、CSS、JavaScript 和 Vue 之间的关系是相辅相成的。它们在构建一个 Web 项目时各司其职,共同完成用户界面和交互功能。下面详细解释它们之间的关系:
- HTML(HyperText Markup Language,超文本标记语言):HTML 是 Web 页面的基础结构,用于描述网页的结构和内容。它是由一系列标签(如
<div>、<p>等)组成的,用于定义页面的各个部分,如标题、段落、列表等。 - CSS(Cascading Style Sheets,层叠样式表):CSS 用于控制 HTML 元素的样式,包括颜色、字体、布局等。通过 CSS,我们可以为 HTML 页面添加各种视觉效果和布局样式,使页面更具吸引力。
- JavaScript(简称 JS):JavaScript 是一种脚本语言,用于为网页添加交互功能。与 HTML 和 CSS 不同,JavaScript 可以直接操作 DOM(文档对象模型),响应用户操作,实现动态效果,以及与后端服务器进行通信。
- Vue.js:Vue.js 是一个用于构建用户界面的 JavaScript 框架。它通过将 HTML、CSS 和 JavaScript 结合起来,提供了一个简洁、可扩展的方法来构建 Web 应用程序。Vue.js 采用组件化的开发方式,将 UI 拆分成多个独立的、可复用的组件,提高了开发效率和代码可维护性。
综上所述,HTML、CSS、JavaScript 和 Vue 之间的关系如下:
- HTML 提供了网页的基本结构和内容。
- CSS 控制了网页的样式和布局。
- JavaScript 提供了网页的交互功能。
- Vue.js 将 HTML、CSS 和 JavaScript 结合起来,提供了一种组件化的开发方式,简化了 Web 应用程序的开发和维护。
在使用 Vue.js 开发项目时,你依然需要使用 HTML、CSS 和 JavaScript 这三个基本技术。Vue.js 只是为你提供了一个更加高效、组织化的方式来组合和管理它们。
6.@Builder.Default
@Builder.Default 是Lombok库中的注解,可以在使用 @Builder 注解时提供默认值。使用该注解可以方便地为一个或多个属性指定默认值,如果在调用 build() 方法时没有为这些属性提供值,则会使用默认值。
@Builder 注解可以让我们编写更简洁的代码,可以使用链式调用的方式设置属性值,并且可以在不使用构造函数的情况下创建对象。 @Builder.Default 则是 @Builder 注解的一个补充,用于设置默认属性值。
例如,以下代码使用了 @Builder 和 @Builder.Default 注解:
@Builder
public class Person {
private String name;
private int age;
@Builder.Default
private String gender = "unknown";
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这表示 gender 属性的默认值为 "unknown",如果在使用 Person.builder() 创建对象时没有设置 gender 属性的值,则使用该默认值。
7.IDEA配置类的注释模板
- File–>settings–>Editor–>File and Code Templates–>Files
8. @Getter @Setter @NoArgsConstructor @AllArgsConstructor @SuperBuilder
这是五个常用的Java注解。
- @Getter和@Setter注解用于自动生成JavaBean的getter和setter方法;
- @NoArgsConstructor和@AllArgsConstructor注解分别用于生成无参构造函数和全参构造函数;
- @SuperBuilder注解是Lombok库中的一个注解,它可以自动生成一个建造者模式的构造器,使得代码更加简洁易读。
在Java中,通常使用构造函数来初始化类的实例。但是,当有很多属性需要初始化时,构造函数就会变得很长并且难以管理。此时,可以使用建造者模式来创建对象,使代码更加简洁易读。
使用建造者模式需要定义一个内部静态类来作为建造者。这个建造者类包含与目标类相同的属性,并提供一个方法链来设置属性的值。最后,该建造者类提供一个
build()方法来创建目标类的实例。使用Lombok库中的
@SuperBuilder注解可以自动生成这个建造者模式的代码。这个注解会自动添加一个带有所有属性的参数的构造函数、一个无参数构造函数、一个名为builder()的静态方法,以及一个名为build()的实例方法。使用
@SuperBuilder注解可以让代码更加简洁易读,而且省去了手动编写建造者模式的代码的时间和精力。
9.lambda中的@build注解
使用 Lombok 中的 @Builder 注解可以生成一个简洁易用的构造器,无需手动编写繁琐的构造器代码。@Builder 注解会自动生成一个静态内部类 Builder,该 Builder 中包含了所有字段的 set 方法,以及一个 build 方法。在使用时,只需在类上加上 @Builder 注解,并在需要创建对象时使用 Builder 进行链式调用即可。
例如,对于以下类:
public class User {
private String name;
private int age;
private String address;
public User(String name, int age, String address) {
this.name = name;
this.age = age;
this.address = address;
}
// 省略 getter 和 setter 方法
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
使用 @Builder 注解后的代码如下:
import lombok.Builder;
@Builder
public class User {
private String name;
private int age;
private String address;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
使用时,可以通过链式调用 Builder 中的 set 方法来设置对象的属性,并最终调用 build 方法创建对象,如下所示:
User user = User.builder()
.name("Tom")
.age(18)
.address("China")
.build();
- 1
- 2
- 3
- 4
- 5
- 6
10.MapStruct
如果MapStruct中的映射没映射成功,build一下就可以了
11.@EqualsAndHashCode(callSuper = true)
@EqualsAndHashCode(callSuper = true) 表示在生成 equals 和 hashCode 方法时,同时调用父类的 equals 和 hashCode 方法。
在 Java 中,equals 和 hashCode 是用于比较对象相等性的方法。当一个类需要进行对象相等性比较时,通常需要重写这两个方法。在重写时,需要注意保留父类的实现,否则可能会导致不正确的结果。使用 @EqualsAndHashCode(callSuper = true) 可以确保在生成这两个方法时,同时调用父类的方法,从而保证正确性。
12.@requestBody的作用
如果传输的是单层json对象,我们后台可以直接用 @RequestParam接收
如果传输的是多层嵌套json对象,这个时候会就会出现数据丢失问题,所以我们使用@requestBody
13.实现序列化作用
当我们需要在 Java 应用程序之间或将 Java 对象存储到文件或数据库等持久化媒介中时,我们需要将 Java 对象序列化成字节流,然后再反序列化回 Java 对象。Java 序列化机制提供了将 Java 对象序列化成字节流的功能,同时也提供了将字节流反序列化回 Java 对象的功能。
当一个 Java 类实现了 Serializable 接口时,表示该类的对象可以被序列化。序列化后,Java 对象就可以被以二进制的形式保存到文件或数据库中,或者通过网络传输到远程节点。在反序列化时,Java 对象会从字节流中被还原出来。
当一个类实现 Serializable 接口后,需要指定一个 serialVersionUID。这个 serialVersionUID 是用来确定类的版本的。在反序列化时,如果序列化的字节流中的 serialVersionUID 与反序列化时类中的 serialVersionUID 不匹配,就会抛出 InvalidClassException 异常,这是因为序列化的字节流可能是从不同版本的类中序列化出来的。
因此,实现序列化并生成 serialVersionUID,可以确保在序列化和反序列化时类的版本一致,从而避免版本不兼容的问题。虽然不实现序列化也可以进行数据传输,但实现序列化可以提高数据传输的效率和可靠性,同时也方便将对象保存到文件或数据库中进行持久化存储。
13.1如果实现快捷键生成序列化UUID
如图搜索:serialVersionUID

14.IDEA快捷键
- CTRL + G 输入行号,快速切换到指定行
- CTRL + SHIFT + 数字键 :标记一行,之后可以通过CTRL + 数字快速跳转过去
15.使用单键代替分布式锁
16.枚举转JSON
@JsonFormat(shape = JsonFormat.Shape.OBJECT)
- 1
ObjectMapper mapper = new ObjectMapper();
String json = mapper.writeValueAsString(OuterRequestCode.SUCCESS);
System.out.println(json); // {"code":"0","message":"success"}
- 1
- 2
- 3
17.bit
在32位虚拟机中,1字宽等于4字节,即32bit
18. trim
“.trim” 是一个字符串方法,用于去除字符串开头和结尾的空白字符(包括空格、制表符、换行符等)。具体来说,它会返回一个新的字符串,其中不包含开头和结尾的空白字符。
在代码中,通常会使用 “.trim” 方法来对用户输入的字符串进行预处理,去除可能存在的空白字符,以免对后续的数据处理和查询造成影响。例如,在查询条件中使用 “like” 条件进行模糊查询时,如果不去除字符串中的空白字符,可能会出现查询不到想要的结果的情况。
使用 “.trim” 方法的语法很简单,只需要在字符串后面加上 “.trim()” 即可。例如,“abc “.trim()” 的返回结果是 “abc”。需要注意的是,”.trim" 方法不会改变原始字符串,而是返回一个新的字符串。
19.获取当前月的起始和结束日期
// 获取当月的起始日期和结束日期
LocalDate currentDate = LocalDate.now();
LocalDate startDate = currentDate.withDayOfMonth(1);
LocalDate endDate = currentDate.plusMonths(1).withDayOfMonth(1).minusDays(1);
- 1
- 2
- 3
- 4
20.concat方法
concat() 方法是一种用于将两个或多个字符串连接起来创建一个新字符串的 JavaScript 字符串方法。它可以用于字符串、数组和类数组对象。
语法:
str.concat(string2, string3, ..., stringX)
- 1
其中,str 是必需的,而 string2 到 stringX 则是可选的。这些参数是要连接在一起的字符串,可以是常量字符串、变量、字符串表达式等。
示例:
var str1 = "Hello";
var str2 = "world!";
var str3 = " How are you?";
var res = str1.concat(" ", str2, str3);
console.log(res); // 输出 "Hello world! How are you?"
- 1
- 2
- 3
- 4
- 5
- 6
注意,如果你只是想将两个字符串连接起来,可以使用加号运算符 “+”,它也可以将两个或多个字符串连接起来,如下所示:
var str1 = "Hello";
var str2 = "world!";
var res = str1 + " " + str2;
console.log(res); // 输出 "Hello world!"
- 1
- 2
- 3
- 4
- 5
但如果你需要连接多个字符串,推荐使用 concat() 方法,因为它比使用加号运算符更高效。
21.参数校验注解
@Size(max = 20, message = "园区publicId限制")
- 1
package com.crestv.openapitest.exception; import com.crestv.openapitest.vo.Result; import org.springframework.validation.BindException; import org.springframework.validation.FieldError; import org.springframework.web.bind.annotation.ExceptionHandler; import org.springframework.web.bind.annotation.ResponseBody; import org.springframework.web.bind.annotation.RestControllerAdvice; import java.util.List; /** * @author guop * @ClassName: GlobalExceptionHandler * @Description: 全局异常处理器 * @date 2023/4/19 */ @RestControllerAdvice public class GlobalExceptionHandler { // 参数校验异常异常处理 @ExceptionHandler(value = BindException.class) @ResponseBody public Result validExceptionHander(BindException e) { List<FieldError> fieldErrors = e.getFieldErrors(); StringBuffer errMessage = new StringBuffer(); fieldErrors.forEach(err -> { errMessage.append(err.getDefaultMessage()); errMessage.append("! "); }); return Result.failure(errMessage.toString()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
-
首先,我们需要安装 Node.js 和 npm(Node 包管理器)。可以访问 Node.js 官网(https://nodejs.org/)下载并安装最新版本。
-
使用 npm 全局安装 Vue CLI:
npm install -g @vue/cli- 1
-
创建一个 Vue 项目:
vue create my-project- 1
其中,
my-project是你的项目名称,可以根据实际情况更改。 -
切换到项目目录:
cd my-project- 1
-
编译项目:
npm run build- 1
这将生成一个
dist文件夹,其中包含编译后的文件。 -
将
dist文件夹上传到你的服务器。你可以使用 FTP 工具,如 FileZilla,或者使用 SSH 进行上传。 -
安装并配置 Nginx。在你的服务器上安装 Nginx,然后编辑 Nginx 的配置文件,通常位于
/etc/nginx/conf.d/或/etc/nginx/sites-available/目录下。创建一个新的配置文件,如my-project.conf,并添加以下内容:server { listen 80; server_name example.com; # 将此处更改为你的域名 location / { root /path/to/your/dist; # 将此处更改为你的 dist 文件夹路径 try_files $uri $uri/ /index.html; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
保存文件后,创建一个符号链接到
sites-enabled目录(如果需要):sudo ln -s /etc/nginx/sites-available/my-project.conf /etc/nginx/sites-enabled/- 1
-
重启 Nginx 服务:
sudo service nginx restart- 1
22.Collections.singletonList作用
Collections.singletonList() 方法用于创建一个只包含一个元素的不可变列表。该方法接受一个参数,即要包含在列表中的元素,然后返回一个不可变列表。
由于返回的列表是不可变的,因此不能添加、删除或修改它的元素。这使得它非常适合用作只有一个元素的参数传递,尤其是在需要传递一个集合时。
23.Comparator.comparingInt方法有什么用
Comparator.comparingInt方法是Java中的一个工具方法,用于根据提供的函数生成一个整数类型的比较器。它是java.util.Comparator接口的一个静态方法。
这个方法的主要作用是根据提供的函数生成一个新的比较器,用于比较两个对象的整数值。这个函数通常是一个lambda表达式或方法引用,它接受一个对象作为输入参数,返回一个整数值。生成的比较器可以用于对整数值进行升序排序。
在我们的示例中,我们使用Comparator.comparingInt()方法根据AmountAndServiceADto对象的periodicTime属性(即月份)生成一个比较器:
yearCollect.sort(Comparator.comparingInt(e -> Integer.parseInt(e.getPeriodicTime())));
- 1
这里,我们传入一个lambda表达式e -> Integer.parseInt(e.getPeriodicTime())作为提供的函数。这个函数将AmountAndServiceADto对象作为输入,使用Integer.parseInt()方法将periodicTime属性(月份的字符串表示)转换为整数,用于排序。
最后,将生成的比较器传递给sort()方法,对yearCollect列表进行升序排序。这样我们就可以确保返回的月份顺序从1到12。
24.空结果集和 null
空结果集和 null 是不同的概念:
- 空结果集(Empty result set):当你执行一个 SQL 查询,如果没有符合条件的记录,查询结果将返回一个空结果集。空结果集表示查询没有找到任何匹配的行,但查询本身是有效的。换句话说,空结果集是一个没有数据的表,但它仍然具有列名和列结构。
null:在数据库中,null是一个特殊的值,表示缺失或未知的数据。当某个字段没有值时,它的内容将被设置为null。null不等于空字符串或零,它表示数据根本不存在。在查询结果中,null会以特定的方式对待,例如在聚合函数和连接操作中。
当你执行一个查询并得到一个空结果集时,它表示查询已经执行,但没有找到符合条件的数据。而当查询结果中的某个字段值为 null 时,表示该字段的数据不存在或未知。
回到你的问题,当使用 LIMIT 1 OFFSET 1 查询第二高的薪水时,如果只有一个薪水值,查询会返回空结果集,而不是 null。这是因为查询确实执行了,但没有找到符合条件的第二高的薪水。为了在这种情况下返回 null,你需要使用子查询的方法,如我之前所示。
25.sql查询
你提供的查询语句本身是正确的,可以用来获得第二高的薪水。以下是你的查询:
SELECT DISTINCT
Salary AS SecondHighestSalary
FROM
Employee
ORDER BY Salary DESC
LIMIT 1 OFFSET 1;
- 1
- 2
- 3
- 4
- 5
- 6
这个查询将会选取所有不同的薪水(使用 DISTINCT),然后按降序排列。接着,使用 LIMIT 1 OFFSET 1 选择第二行,也就是第二高的薪水。
然而,如果表中只有一个薪水值时,这个查询将返回空结果集,而不是返回 null。为了确保在这种情况下返回 null,可以使用子查询,如我之前给出的示例:
SELECT
(SELECT DISTINCT salary
FROM Employee
ORDER BY salary DESC
LIMIT 1 OFFSET 1) AS SecondHighestSalary;
- 1
- 2
- 3
- 4
- 5
使用子查询,当表中只有一个薪水值时,子查询将返回空结果集,而外部查询将返回 null。
1.为什么使用子查询会返回null
使用子查询时,查询会尝试查找第二高的薪水。当子查询找不到符合条件的记录时,它会返回空结果集。然后,子查询的结果将被外部查询所引用。在这种情况下,如果子查询返回空结果集,外部查询将无法找到对应的值,因此将返回 null。
这是因为在子查询的外部,我们使用 SELECT 语句查询一个可能不存在的值(即,第二高的薪水)。当子查询找不到第二高的薪水时,外部查询将返回 null,表示没有找到这个值。
下面是一个查询示例,用于找到第二高的薪水,如果不存在第二高的薪水,则返回 null:
SELECT
(SELECT DISTINCT
Salary
FROM
Employee
ORDER BY Salary DESC
LIMIT 1 OFFSET 1) AS SecondHighestSalary;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
在这个查询中,子查询首先尝试找到第二高的薪水。如果找到了,子查询会返回这个值,否则返回空结果集。外部查询会将子查询的结果作为 SecondHighestSalary 列的值。如果子查询返回空结果集,外部查询将返回 null 作为 SecondHighestSalary 的值。
26.object,JSONobject,string之间的关系
在编程和数据处理中,对象(object)、JSON 对象(JSON object)和字符串(string)之间有着密切的关系。我们可以这样理解它们之间的关系:
-
对象(Object):在许多编程语言(如 JavaScript、Python 等)中,对象是一种复合数据类型,通常用于存储和操作一组有序的键值对。对象的键通常是字符串,值可以是各种不同的数据类型,如字符串、数字、布尔值、数组、函数或其他对象。对象是编程中常用的一种数据结构。
-
JSON 对象(JSON object):JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,它易于阅读和编写,同时也易于机器解析和生成。JSON 对象是一种特殊的对象,它的格式类似于 JavaScript 对象,但只能包含字符串、数字、布尔值、数组和其他 JSON 对象。JSON 对象通常用于在不同系统和应用程序之间传输和存储数据。
-
字符串(String):字符串是一种基本的数据类型,用于表示一系列字符。在许多编程语言中,字符串可以用单引号或双引号括起来。字符串可以包含文本、数字、标点符号等各种字符。
对象、JSON 对象和字符串之间的关系在于,它们在不同层面上处理和表示数据。对象通常用于编程中的数据结构和操作,JSON 对象用于数据交换和存储,而字符串是一种基本的数据类型,可以用于表示对象的键或值。
在实际应用中,你可能会遇到需要将对象转换为 JSON 对象或字符串的情况,以便于数据传输或存储。例如,在 JavaScript 中,你可以使用 JSON.stringify() 方法将一个对象转换为 JSON 字符串,或使用 JSON.parse() 方法将一个 JSON 字符串转换为一个 JavaScript 对象。类似地,在 Python 中,你可以使用 json.dumps() 和 json.loads() 函数实现这些转换。
27…map(taskIdStr -> taskIdStr.replaceAll(“[
当然,我很高兴为您解释这段代码。这行代码的主要目的是将 taskId 字符串(如 "[28,29]")转换为一个不包含方括号的字符串数组(如 {"28", "29"})。
让我们逐步分析这段代码:
-
.map(taskIdStr -> ...): 这是一个map操作,它对流中的每个元素应用一个函数。在这个例子中,每个元素都是一个taskId字符串(如"[28,29]"),我们将对其进行处理。 -
taskIdStr.replaceAll("[\\[\\]]", ""): 这个方法调用将删除taskId字符串中的方括号。"[\\[\\]]"是一个正则表达式,它匹配左方括号[和右方括号]。我们使用两个反斜杠\\对方括号进行转义,因为它们在正则表达式中有特殊含义。replaceAll方法将匹配到的所有字符替换为空字符串"",因此方括号会被删除。例如,对于输入字符串"[28,29]",该方法调用将返回"28,29"。 -
.split(","): 这个方法调用会根据逗号对字符串进行分割。在我们的示例中,"28,29"将被分割为一个字符串数组,包含两个元素:"28"和"29"。
所以,.map(taskIdStr -> taskIdStr.replaceAll("[\\[\\]]", "").split(",")) 这段代码的作用是将一个类似于 "[28,29]" 的 taskId 字符串转换为一个不包含方括号的字符串数组,如 {"28", "29"}。后续的代码将处理这个字符串数组,将其转换为整数并收集到一个列表中。
28.cron表达式
1.写一个cron,凌晨十二点运行
要创建一个 cron 表达式,在凌晨 12 点(午夜)运行,您可以使用以下表达式:
0 0 0 * * ?
- 1
这个 cron 表达式的含义如下:
- 第一个字段(秒):0 - 在第 0 秒触发任务。
- 第二个字段(分):0 - 在第 0 分钟触发任务。
- 第三个字段(时):0 - 在第 0 小时(即午夜)触发任务。
- 第四个字段(日):* - 每天都触发任务。
- 第五个字段(月):* - 每个月都触发任务。
- 第六个字段(星期):? - 不关心星期几,因为已经指定了每天都触发任务。
这个 cron 表达式表示每天凌晨 12 点(午夜)触发任务。
lable/my-project.conf /etc/nginx/sites-enabled/
8. 重启 Nginx 服务:
```bash
sudo service nginx restart
- 1
- 2
- 3
- 4
- 5
22.Collections.singletonList作用
Collections.singletonList() 方法用于创建一个只包含一个元素的不可变列表。该方法接受一个参数,即要包含在列表中的元素,然后返回一个不可变列表。
由于返回的列表是不可变的,因此不能添加、删除或修改它的元素。这使得它非常适合用作只有一个元素的参数传递,尤其是在需要传递一个集合时。
23.Comparator.comparingInt方法有什么用
Comparator.comparingInt方法是Java中的一个工具方法,用于根据提供的函数生成一个整数类型的比较器。它是java.util.Comparator接口的一个静态方法。
这个方法的主要作用是根据提供的函数生成一个新的比较器,用于比较两个对象的整数值。这个函数通常是一个lambda表达式或方法引用,它接受一个对象作为输入参数,返回一个整数值。生成的比较器可以用于对整数值进行升序排序。
在我们的示例中,我们使用Comparator.comparingInt()方法根据AmountAndServiceADto对象的periodicTime属性(即月份)生成一个比较器:
yearCollect.sort(Comparator.comparingInt(e -> Integer.parseInt(e.getPeriodicTime())));
- 1
这里,我们传入一个lambda表达式e -> Integer.parseInt(e.getPeriodicTime())作为提供的函数。这个函数将AmountAndServiceADto对象作为输入,使用Integer.parseInt()方法将periodicTime属性(月份的字符串表示)转换为整数,用于排序。
最后,将生成的比较器传递给sort()方法,对yearCollect列表进行升序排序。这样我们就可以确保返回的月份顺序从1到12。
24.空结果集和 null
空结果集和 null 是不同的概念:
- 空结果集(Empty result set):当你执行一个 SQL 查询,如果没有符合条件的记录,查询结果将返回一个空结果集。空结果集表示查询没有找到任何匹配的行,但查询本身是有效的。换句话说,空结果集是一个没有数据的表,但它仍然具有列名和列结构。
null:在数据库中,null是一个特殊的值,表示缺失或未知的数据。当某个字段没有值时,它的内容将被设置为null。null不等于空字符串或零,它表示数据根本不存在。在查询结果中,null会以特定的方式对待,例如在聚合函数和连接操作中。
当你执行一个查询并得到一个空结果集时,它表示查询已经执行,但没有找到符合条件的数据。而当查询结果中的某个字段值为 null 时,表示该字段的数据不存在或未知。
回到你的问题,当使用 LIMIT 1 OFFSET 1 查询第二高的薪水时,如果只有一个薪水值,查询会返回空结果集,而不是 null。这是因为查询确实执行了,但没有找到符合条件的第二高的薪水。为了在这种情况下返回 null,你需要使用子查询的方法,如我之前所示。
25.sql查询
你提供的查询语句本身是正确的,可以用来获得第二高的薪水。以下是你的查询:
SELECT DISTINCT
Salary AS SecondHighestSalary
FROM
Employee
ORDER BY Salary DESC
LIMIT 1 OFFSET 1;
- 1
- 2
- 3
- 4
- 5
- 6
这个查询将会选取所有不同的薪水(使用 DISTINCT),然后按降序排列。接着,使用 LIMIT 1 OFFSET 1 选择第二行,也就是第二高的薪水。
然而,如果表中只有一个薪水值时,这个查询将返回空结果集,而不是返回 null。为了确保在这种情况下返回 null,可以使用子查询,如我之前给出的示例:
SELECT
(SELECT DISTINCT salary
FROM Employee
ORDER BY salary DESC
LIMIT 1 OFFSET 1) AS SecondHighestSalary;
- 1
- 2
- 3
- 4
- 5
使用子查询,当表中只有一个薪水值时,子查询将返回空结果集,而外部查询将返回 null。
1.为什么使用子查询会返回null
使用子查询时,查询会尝试查找第二高的薪水。当子查询找不到符合条件的记录时,它会返回空结果集。然后,子查询的结果将被外部查询所引用。在这种情况下,如果子查询返回空结果集,外部查询将无法找到对应的值,因此将返回 null。
这是因为在子查询的外部,我们使用 SELECT 语句查询一个可能不存在的值(即,第二高的薪水)。当子查询找不到第二高的薪水时,外部查询将返回 null,表示没有找到这个值。
下面是一个查询示例,用于找到第二高的薪水,如果不存在第二高的薪水,则返回 null:
SELECT
(SELECT DISTINCT
Salary
FROM
Employee
ORDER BY Salary DESC
LIMIT 1 OFFSET 1) AS SecondHighestSalary;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
在这个查询中,子查询首先尝试找到第二高的薪水。如果找到了,子查询会返回这个值,否则返回空结果集。外部查询会将子查询的结果作为 SecondHighestSalary 列的值。如果子查询返回空结果集,外部查询将返回 null 作为 SecondHighestSalary 的值。
26.object,JSONobject,string之间的关系
在编程和数据处理中,对象(object)、JSON 对象(JSON object)和字符串(string)之间有着密切的关系。我们可以这样理解它们之间的关系:
-
对象(Object):在许多编程语言(如 JavaScript、Python 等)中,对象是一种复合数据类型,通常用于存储和操作一组有序的键值对。对象的键通常是字符串,值可以是各种不同的数据类型,如字符串、数字、布尔值、数组、函数或其他对象。对象是编程中常用的一种数据结构。
-
JSON 对象(JSON object):JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,它易于阅读和编写,同时也易于机器解析和生成。JSON 对象是一种特殊的对象,它的格式类似于 JavaScript 对象,但只能包含字符串、数字、布尔值、数组和其他 JSON 对象。JSON 对象通常用于在不同系统和应用程序之间传输和存储数据。
-
字符串(String):字符串是一种基本的数据类型,用于表示一系列字符。在许多编程语言中,字符串可以用单引号或双引号括起来。字符串可以包含文本、数字、标点符号等各种字符。
对象、JSON 对象和字符串之间的关系在于,它们在不同层面上处理和表示数据。对象通常用于编程中的数据结构和操作,JSON 对象用于数据交换和存储,而字符串是一种基本的数据类型,可以用于表示对象的键或值。
在实际应用中,你可能会遇到需要将对象转换为 JSON 对象或字符串的情况,以便于数据传输或存储。例如,在 JavaScript 中,你可以使用 JSON.stringify() 方法将一个对象转换为 JSON 字符串,或使用 JSON.parse() 方法将一个 JSON 字符串转换为一个 JavaScript 对象。类似地,在 Python 中,你可以使用 json.dumps() 和 json.loads() 函数实现这些转换。
27…map(taskIdStr -> taskIdStr.replaceAll(“[
当然,我很高兴为您解释这段代码。这行代码的主要目的是将 taskId 字符串(如 "[28,29]")转换为一个不包含方括号的字符串数组(如 {"28", "29"})。
让我们逐步分析这段代码:
-
.map(taskIdStr -> ...): 这是一个map操作,它对流中的每个元素应用一个函数。在这个例子中,每个元素都是一个taskId字符串(如"[28,29]"),我们将对其进行处理。 -
taskIdStr.replaceAll("[\\[\\]]", ""): 这个方法调用将删除taskId字符串中的方括号。"[\\[\\]]"是一个正则表达式,它匹配左方括号[和右方括号]。我们使用两个反斜杠\\对方括号进行转义,因为它们在正则表达式中有特殊含义。replaceAll方法将匹配到的所有字符替换为空字符串"",因此方括号会被删除。例如,对于输入字符串"[28,29]",该方法调用将返回"28,29"。 -
.split(","): 这个方法调用会根据逗号对字符串进行分割。在我们的示例中,"28,29"将被分割为一个字符串数组,包含两个元素:"28"和"29"。
所以,.map(taskIdStr -> taskIdStr.replaceAll("[\\[\\]]", "").split(",")) 这段代码的作用是将一个类似于 "[28,29]" 的 taskId 字符串转换为一个不包含方括号的字符串数组,如 {"28", "29"}。后续的代码将处理这个字符串数组,将其转换为整数并收集到一个列表中。
28.cron表达式
1.写一个cron,凌晨十二点运行
要创建一个 cron 表达式,在凌晨 12 点(午夜)运行,您可以使用以下表达式:
0 0 0 * * ?
- 1
这个 cron 表达式的含义如下:
- 第一个字段(秒):0 - 在第 0 秒触发任务。
- 第二个字段(分):0 - 在第 0 分钟触发任务。
- 第三个字段(时):0 - 在第 0 小时(即午夜)触发任务。
- 第四个字段(日):* - 每天都触发任务。
- 第五个字段(月):* - 每个月都触发任务。
- 第六个字段(星期):? - 不关心星期几,因为已经指定了每天都触发任务。
这个 cron 表达式表示每天凌晨 12 点(午夜)触发任务。

