
- 1分布式缓存之redis介绍、安装、主从、集群实例_分布式有几个redis实例
- 2cpu通过http接口部署qwen1.8b_qwen-1.8b下载
- 3springboot整合ehcache实现二级缓存踩坑_cacheable 踩坑
- 4Android可穿戴设备世界之旅
- 5Docker常用容器命令_docker logs -f -t
- 6简要讲解高速信号的眼图_加重_均衡(高速收发器六)_高速信号眼图
- 7思科校园网络设计,cisco校园网设计,适合毕设,满满的干货_思科毕业设计
- 8基于Java+SpringBoot制作一个景区导览小程序
- 9C++中的stringstream用法_c++ stringstream
- 10github合作_在github上合作
Qt常见中文乱码问题解决方法总结_qt 中文乱码
赞
踩
中文乱码解决方法一
默认编码错误
这种情况是Qt的编码不正确,没有使用UTF-8,但是我觉得大多数人都不是这种,现在Qt在安装之后似乎默认就是UFT-8,若是这种情况,可以参考以下解决方案对默认编码进行一个修改:
在Qt上方工具栏中找到 工具-》选项 并单击

在更改了编码之后,能解决因为编码无法解析汉字而导致的乱码问题。但是在大多数时候并不是这个情况,下面的情况更常见一点。
中文乱码解决方法二
- 1、QString str = QStringLiteral("1你好世界 abc")); //推荐
-
- 2、QString str = QObject::tr("2你好世界 abc")); //推荐国际化软件使用,其余不推荐
-
- 8、QString str = (u8"8你好世界 abc"); //推荐 在中文字符前加上 u8,然后把中文字符用双引号包括
-
- 3、QString str = QString::fromLocal8Bit("3你好世界 abc"); //不推荐,
-
- 4、QString str = QString::fromLatin1("4你好世界 abc"); //不推荐
-
- 5、QString str = QString::fromUtf8("5你好世界 abc"); //推荐
-
- 6、QString str = QString::fromWCharArray(L"6你好世界 abc"); //不推荐,字符串的编码取决于 wchar 的大小。
-
- 7、QString str = QStringLiteral("7你好世界 abc"); //不推荐,
-
-
- 10、在头文件的类前面放入这一行,设置源文件的编码格式:
-
- # pragma execution_character_set("utf-8")
中文乱码解决方法三
mian入口使用 QTextCodec 一步到位
本方法,仅适用于Qt4
- int main(int argc, char *argv[])
- {
- QApplication a(argc, argv);
-
- #ifdef Q_OS_LINUX
- QTextCodec::setCodecForTr(QTextCodec::codecForName("UTF-8"));
- QTextCodec::setCodecForCStrings(QTextCodec::codecForName("UTF-8"));
- QTextCodec::setCodecForLocale(QTextCodec::codecForName("UTF-8"));
- #else
- QTextCodec::setCodecForTr(QTextCodec::codecForName("system"));
- QTextCodec::setCodecForCStrings(QTextCodec::codecForName("system"));
- QTextCodec::setCodecForLocale(QTextCodec::codecForName("system"));
- #endif
-
- QMyTest w;
- w.show();
- return a.exec();
- }
- int main(int argc,char *argv[]){
- //更改编码
- QTextCodec *codec = QTextCodec::codecForName("UTF-8");
- QTextCodec::setCodecForLocale(codec);
-
- QApplication a(argc,argv);
- MainWindow w;
- w.show();
- return a.exec();
- }
中文乱码解决方法四
中文编译错误
1、选择 编辑---》select encoding

2、选择 system 点击 按编码保存 即可

术语解释
1、编辑器(editor)
就是我们编辑源文件用的文本编辑器
当然集成开发环境都带有非常优秀的文本编辑功能啦,比如VS、QtCreator等。我们日常开发是不是直接打开IDE,经过一系列创建项目、配置项目等操作就可以撸代码啦,通常很少去设置什么字符编码之类的东西,但是QtCreator里边有设置字符编码的选项,不知道大家有没有操作过呢?
2、编译器(compiler)
就是把我们撸好的源文件编译成二进制文件的主要的软件啦,这里我们不谈链接器
比如有GCC编译器、MSVC编译器等
3、源文件字符编码
就是我们的编辑器所用的字符编码
我们用Visual Studio撸的源文件的编码是ANSI。这个ANSI编码还得啰嗦两句,它本身呀并不是真正的字符编码,只是微软为了让用户看起来自己的产品(Windows操作系统)的功能是一致的,所以起了一个ANSI的统称而已。在Windows系统里边有个代码页的东东,在不同的语言版本活跃的代码页是不同的。对于简体中文版本的Windows来说,活跃代码页是936,也就是ANSI表示的中文编码是GBK,英文编码就不用说了当然是ASCII或者更准确一点是Latin-1。对于日文版本的Windows系统来说,活跃的代码页、ANSI表示的编码又不同了。
用QtCreator撸的源文件的编码就是上图中设置的编码了,你也可以用其他的编辑器比如记事本、notepad++、Vi、UltraEdit等撸代码,那么源文件的字符编码就是对应editor所用的编码了。
4、执行文件字符编码
我们知道二进制可执行文件里边包含的大致就是一堆指令和数据,那么数据里边很有可能包含非英文字符,比如下面这段代码:
- #include <stdio.h>
- int main(void)
- {
- const char *p = "字符编码";
- printf("%s\n", p);
- return 0;
- }
程序中的“字符编码”这四个大字肯定保存在可执行文件(exe)的某个位置,当然是用二进制保存的。能决定可执行文件字符编码的就只有编译器啦,因为你的exe是编译器生成的嘛。当然程序中全部用英文那是没有问题的,但是作为一个非英语国家的程序员,你开发一个英文版的软件出来,别说自己英语水平不行,就算是能开发出来,把它卖给国内客户销路也不好吧哈哈。
那么编译器是如何决定可执行文件中的字符编码的呢?这个问题不同编译器的策略就不一样了,并且都有编译选项可以设置
GCC编译器:它生成的可执行文件的字符编码默认跟源文件的字符编码是一致的,可以通过-finput-charset和-fexec-charset选项显式告诉GCC源文件的字符编码是什么,生成的可执行文件字符编码是什么。大家可以做一个实验:在Windows下用记事本编辑上面的程序,把它拷贝到Linux下编译运行,输出的肯定是乱码。gcc --finput-charset=GBK -fexec-charset=UTF8 main.c这样编译就不会乱码了。
MSVC编译器:它生成的可执行文件的字符编码默认是locale(本地)编码,即跟活跃的代码页一致。它编译的时候会把源文件的字符编码翻译成本地编码,比如我们用notepad++使用UTF8编码编辑上面的代码,再用MSVC编译运行,Debug一下看看指针p的内存是怎样的,你会惊奇的发现,p指向了8个字节的内存,就是“字符编码”的GBK内码(0XD7D6 0XB7FB 0XB1E0 0XC2EB),GBK每个汉字用2字节编码。MSVC字符编码相关的编译选项是/source-charset和/execution-charset。
5、Unicode
Unicode本质上只是一个字符编码方案,或者叫字符编码标准,它本身并不提供具体的编码实现。可以把Unicode理解为一本字典,里边收录了全世界所有国家的文字,每个字符映射一个编号,用2字节表示,这个编号也叫做码点(值)。可能有人会问2字节只能表示65536个字符,全世界的语言文字应该不止这么多吧,我们中国就好几万了,确实不太够。这里又有一个平面(plane)的概念,把它理解为字典里的一页就好了,Unicode总共定义了17个平面。那么就可以这样理解:Unicode这本字典呢总共有17页,每一页有65536个字符,这下够了吧哈哈,当然有些页还是空白的呢(未定义)。这里边最重要的就是第一个平面(the first page),这个平面里边收录了大部分国家的最常用的字符,当然也有我们中文常见的汉字啦,称为基本平面BMP。
有了这个Unicode标准之后,就可以实现不同的字符编码了,比如英文的Latin-1,简体中文的GB2312、GBK,繁体中文的Big5,日文的Shift-JIS,俄语的KOI8-R,还有UTF8、UTF32、UTF16等等
Qt中的字符串
1.char*和std::string
不知道是否有人纠结过C/C++语言的char*和string到底表示的是什么编码呢?
对于这个问题呀,还是跟编译器有关,char*和string表示的就是执行文件的字符编码。如果没有指定字符编码编译选项,Linux下GCC编译char*和string表示的就是UTF8,Windows下MSVC编译char*和string表示的就是ANSI(中文是GBK)
2.QString
QString是对QChar的封装,使用的是Unicode编码,具体实现呢是用UTF16实现的。对于码点值超过65535的字符呢UTF16有自己的实现方案,用两个QChar表示一个字符,具体的编解码方法这里不讨论了,感兴趣自己研究吧。
3.QTextCodec
这个类为不同字符编码(比如GBK、Shift-JIS等)与Unicode即QString(QChar)之间进行翻译,它支持很多种字符编码,具体可以查看Qt帮助文档。
- // 这里特别要注意!
- // codecForName()函数用来设置将要被翻译的字符编码,例如本例中的"智能导航"
- // 这个字符编码指的是执行文件的字符编码,不是源文件的字符编码
- QTextCodec *codec = QTextCodec::codecForName("GB18030");
-
- // 即使源文件是UTF8编码,这里我用MSVC去编译,MSVC会自动把
- // "智能导航"翻译成Windows本地编码即GBK
- // 所以,codecForName()要设置为GB18030(它兼容GBK)而不是UTF8
- QString chi = codec->toUnicode("智能导航");
-
- // 这个是上面的逆操作,所以gbk的内存刚好就是"智能导航"的GBK内码
- QByteArray gbk = codec->fromUnicode(chi);
-
- // 这里要非常非常注意
- // toStdString()转换的结果跟源文件的字符编码一致!!!
- // 如果源文件是用UTF8编辑的,那么这里的cstr就是UTF8编码
- std::string cstr = fmt.toStdString();
-
- // txt跟执行文件编码一致,如果用MSVC编译就是GBK编码
- const char *txt = "智能导航";
请仔细理解上面代码段中的注释!尤其是toStdString()这个函数要注意
Qt中乱码总结
Qt中的API和字符串相关的参数都是使用QString,也就是使用Unicode(UTF16)编码,只要我们使用的QString对象是Unicode编码,那么调用Qt API肯定不会乱码。Qt中出现乱码从如下几个方面考虑解决:
1、源文件是什么编码
2、Qt程序使用什么编译器
3、使用QTextCodec进行编码转换
4、使用QCoreApplication::translate()或QObject::tr()翻译
在Windows下用QtCreator开发可以配置MinGW(GCC的Windows版)和MSVC编译器,这个时候要注意理清源文件编码和执行文件编码。
在Linux下使用QtCreator开发通常都是UTF8编码和GCC编译器,源文件编码和执行文件编码一致
但是如果从Windows下拷贝文件到Linux中要注意,Windows的文件基本是ANSI编码,Linux文件通常是UTF8编码
QT5乱码问题解决
以上描述的都是Qt4中存在的问题,在Qt5中就简单很多了,用宏QStringLiteral转换即可
- #include <QDebug>
- int main(void)
- {
- QString str(QStringLiteral("智能导航"));
- qDebug() << str;
- return 0;
- }
问题分析
一、Qt Creator环境设置
1、cpp或h文件从window上传到Ubuntu后会显示乱码,原因是因为ubuntu环境设置默认是utf-8,Windows默认都是GBK.
我们使用的Windows系统本地字符集编码为GBK。
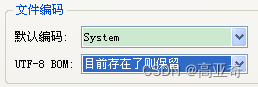
2、Windows环境下,Qt Creator,菜单->工具->选项->文本编辑器->行为->文件编码->默认编码,常用的选项有以下几个:
System(简体中文windows系统默认指的是GBK编码)
GBK/windows-936-2000/CP936/MS936/windows-936
UTF-8
二、编码知识科普
Qt常见的两种编码是:UTF-8和GBK
★UTF-8:Unicode TransformationFormat-8bit,允许含BOM,但通常不含BOM。是用以解决国际上字符的一种多字节编码,它对英文使用8位(即一个字节),中文使用24为(三个字节)来编码。UTF-8包含全世界所有国家需要用到的字符,是国际编码,通用性强。UTF-8编码的文字可以在各国支持UTF8字符集的浏览器上显示。如果是UTF8编码,则在外国人的英文IE上也能显示中文,他们无需下载IE的中文语言支持包。
★GBK是国家标准GB2312基础上扩容后兼容GB2312的标准。GBK的文字编码是用双字节来表示的,即不论中、英文字符均使用双字节来表示,为了区分中文,将其最高位都设定成1。GBK包含全部中文字符,是国家编码,通用性比UTF8差,不过UTF8占用的数据库比GBD大。GBK是GB2312的扩展,除了兼容GB2312外,它还能显示繁体中文,还有日文的假名。
★GBK、GB2312等与UTF8之间都必须通过Unicode编码才能相互转换:
GBK、GB2312--Unicode--UTF8
UTF8--Unicode--GBK、GB2312
★在简体中文windows系统下,ANSI编码代表GBK/GB2312编码,ANSI通常使用0x80~0xFF范围的2个字节来表示1个中文字符。0x00~0x7F之间的字符,依旧是1个字节代表1个字符。Unicode(UTF-16)编码则所有字符都用2个字节表示。
三、编码转换
Windows自带的记事本,无法查看UTF-8编码的文件到底有无BOM,需要使用其他文件编辑器,比如EditPlus或者SublimeText。
UTF-8与ANSI(即GBK)的互转,可以使用EditPlus工具"文件另存为"或者Encodersoft编码转换工具对.cpp和.h源文件文本进行批量转换.
四、QString显示中文乱码的原因
我们使用的Windows系统本地字符编码(Local字符集)为GBK。编译器分析出源文件字符编码之后,会进行解码再编码,将源字符集转码成执行字符集。执行字符集一般默认为使用本地字符编码(Local字符集)。
- QTextCodec *codec = QTextCodec::codecForName("UTF-8");//或者"GBK",不分大小写
- QTextCodec::setCodecForLocale(codec);
-
Qt5可以设置Local字符集,GBK/UTF-8
Qt5中QString内部采用unicode字符集,utf-16编码。构造函数QString::QString(const char *str)默认使用fromUtf8(),将str所指的执行字符集从utf-8转码成utf-16。
由上面fromUtf8()可知,QString需要执行字符集编码为utf-8,然后以utf-8进行解码,再编码为utf-16才能获得正确的字符编码。显示中文乱码的原因其实就是QString转码方式与执行字符集不一致。(比如,源字符集为本地字符集GBK编码,QString以utf-8的方式进行解码,会导致获得错误的二进制编码,再将错误二进制转为utf-16就会出现乱码。)
五、Qt编码指定
Qt需要在main()函数指定使用的字符编码:
- #include <QTextCodec>
-
- int main(int argc, char *argv[])
- {
- QApplication a(argc, argv);
-
- //设置中文字体
- a.setFont(QFont("Microsoft Yahei", 9));
-
- //设置中文编码
- #if (QT_VERSION <= QT_VERSION_CHECK(5,0,0))
- #if _MSC_VER
- QTextCodec *codec = QTextCodec::codecForName("GBK");
- #else
- QTextCodec *codec = QTextCodec::codecForName("UTF-8");
- #endif
- QTextCodec::setCodecForLocale(codec);
- QTextCodec::setCodecForCStrings(codec);
- QTextCodec::setCodecForTr(codec);
- #else
- QTextCodec *codec = QTextCodec::codecForName("UTF-8");
- QTextCodec::setCodecForLocale(codec);
- #endif
-
- return a.exec();
- }
这里只列举大家最常用的3个编译器(微软VC++的cl编译器,Mingw中的g++,Linux下的g++),源代码分别采用GBK和无BOM的UTF-8以及有BOM的UTF-8这3种编码进行保存,发生的现象如下表所示。
情况1:指的是Local字符集为GBK
情况2:指的是Local字符集为UTF-8

如果您使用的是Visual C++编译器,则默认情况下不会将您的源代码视为utf-8编码。除非有BOM,否则它将使用您当前的代码页进行解释。就是说,当使用Visual C++编译程序的时候,它会分析源文件采用何种编码,有BOM标识符则可以正确识别其编码是UTF-8,若没有BOM标识符则认为其使用本地字符集编码(Local字符集)。Local字符集是什么?取决于你的设置QTextCodec *codec = QTextCodec::codecForName(???);
如果源文件是UTF-8+BOM的编码方式,还需要在头文件加入
- #if defined(_MSC_VER) && (_MSC_VER >= 1600)
- # pragma execution_character_set("utf-8")
- #endif
或者添加QMAKE_CXXFLAGS += /utf-8到您的.pro文件中。
如果源文件是UTF-8+无BOM的编码方式,则一定不能加#pragma execution_character_set(“utf-8”),不然会产生乱码。
六、测试案例
案例1、中文字符串测试
- #if defined(_MSC_VER) && (_MSC_VER >= 1600)
- # pragma execution_character_set("utf-8")
- #endif
-
- #include <QApplication>
- #include <QFont>
- #include <QTextCodec>
- #include <QPushButton>
- #include <QDebug>
- #include <QString>
-
- int main(int argc, char *argv[])
- {
- QApplication a(argc, argv);
-
- //设置中文字体
- a.setFont(QFont("Microsoft Yahei", 9));
-
- //设置中文编码
- #if (QT_VERSION <= QT_VERSION_CHECK(5,0,0))
- #if _MSC_VER
- QTextCodec *codec = QTextCodec::codecForName("gbk");
- #else
- QTextCodec *codec = QTextCodec::codecForName("utf-8");
- #endif
- QTextCodec::setCodecForLocale(codec);
- QTextCodec::setCodecForCStrings(codec);
- QTextCodec::setCodecForTr(codec);
- #else
- QTextCodec *codec = QTextCodec::codecForName("utf-8");
- QTextCodec::setCodecForLocale(codec);
- #endif
-
- QString str(QObject::tr("1中文"));
- qDebug() << str;
- qDebug() << QStringLiteral("2中文");
- qDebug() << QString::fromLatin1("3中文");
- qDebug() << QString::fromLocal8Bit("4中文");
- qDebug() << QString::fromUtf8("5中文");
- qDebug() << QString::fromWCharArray(L"6中文");
-
- return a.exec();
- }
当QTextCodec::codecForName("utf-8");时,
QString::fromLocal8Bit和QString::fromUtf8是等效的。
当QTextCodec::codecForName("gbk");时,
QString::fromLocal8Bit和QString::fromUtf8是不等效的。
案例2、QCom跨平台串口调试助手
源代码qcom\mainwindow.cpp,aboutdialog.cpp等文件用的是UTF-8编码(无BOM);但是qcom\qextserial\*.*文件用的是ANSI编码.
在linux环境编译完全OK.
笔者Windows环境的Qt Creator+微软VC++编译器,环境设置用的是ANSI(即GBK)编码.编译源文件会报错.
错误提示"fatal error C1018: 意外的 #elif".
解决方法由两种:
方法1:
把qcom\的所有cpp和h文件都用工具转换成ANSI编码,main()函数使用QTextCodec::setCodecForTr(QTextCodec::codecForName("GBK"));
方法2:

先把Qt Creator环境设置用的是UTF-8编码,
再把qcom\的所有cpp和h文件都用工具转换成UTF-8+BOM编码,请注意,如果文件转换成UTF-8(无BOM),编译仍会失败.main()函数使用QTextCodec::setCodecForTr(QTextCodec::codecForName("GBK"));//注意,此处仍是"GBK",不是"UTF-8"
重新编译,OK!
七、结论
Windows环境下,Qt Creator+微软VC++编译器,新建工程,
1、如果该工程不需要跨平台使用(只在win),那么工程设置请使用GBK的编码方式.
2、如果该工程要跨平台使用(win+linux),那么工程设置请使用UTF-8+BOM的编码方式.

另外,还需要在预编译头文件加入
- CONFIG += c++11
- #可以在项目中使用预编译头文件的支持
- CONFIG += precompile_header
- #预编译头文件路径
- PRECOMPILED_HEADER = $$PWD/stdafx.h
- #if defined(_MSC_VER) && (_MSC_VER >= 1600)
- # pragma execution_character_set("utf-8")
- #endif
或者添加QMAKE_CXXFLAGS += /utf-8到您的.pro文件中。
3、Linux环境下,Qt Creator+gcc,新建工程,
没有GBK编码可选,默认是UTF-8(无BOM)编码方式,考虑到跨平台,建议选择UTF-8+BOM的编码方式.
综上所述,解决乱码的方法概括如下:
1、如果IDE是Qt Creator,把它的环境设置为“UTF-8+BOM”编码。
2、如果IDE是Visual Studio,请下载插件,名称是ForceUTF8 (with BOM),所有源文件和头文件都会保存为“UTF-8+BOM”编码。
3、如果编译器是MSVC,请在预编译头stdafx.h文件加入
- #if defined(_MSC_VER) && (_MSC_VER >= 1600)
- # pragma execution_character_set("utf-8")
- #endif
4、源码文件main函数入口设置中文编码:
- #include <QFont>
-
- #include <QTextCodec>
-
- int main(int argc, char *argv[])
-
- {
-
- QApplication a(argc, argv);
-
- //设置中文字体
- a.setFont(QFont("Microsoft Yahei", 9));
-
- //设置中文编码
- #if (QT_VERSION <= QT_VERSION_CHECK(5,0,0))
- #if _MSC_VER
- QTextCodec *codec = QTextCodec::codecForName("gbk");
- #else
- QTextCodec *codec = QTextCodec::codecForName("utf-8");
- #endif
- QTextCodec::setCodecForLocale(codec);
- QTextCodec::setCodecForCStrings(codec);
- QTextCodec::setCodecForTr(codec);
- #else
- QTextCodec *codec = QTextCodec::codecForName("utf-8");
- QTextCodec::setCodecForLocale(codec);
- #endif
-
- MainView w;
-
- w.show();
-
- return a.exec();
-
- }
5、如此一来,不管是MSVC编译器还是MinGW编译器,都能编译通过,且支持中文!

