
- 1类与类的关系---继承_类与继承
- 2python中运行linux命令_python 代码里 加入linux命令
- 3【二分答案】【数学思维】codeforces1117C Magic Ship_u', 'd', 'l', 'r' 二分答案
- 4云计算与大数据第5章 云计算安全题库及答案_云计算系统使用数字安全身份管控模块来达到集中身份管理及统一身份认证的目的,主
- 5docker-compose编排_docker-compose -t
- 6服务器中tomcat发布web项目路径,JavaWeb项目中的目录结构以及部署到Tomcat服务器中的目录结构...
- 7C语言之通讯录
- 8加一算法(数组或者字符串)_数值字符串加一
- 9java中switch语句用法详解_switch语句java
- 10软件测试:最强面试题整理出炉附答案,一点点小总结,建议收藏_charles常见面试题
论文浅尝 | 在图上思考:基于知识图谱的深度且负责的大语言模型推理
赞
踩

笔记整理:孙硕硕,东南大学硕士,研究方向为自然语言处理
链接:https://arxiv.org/abs/2307.07697
1. 动机
本文的动机是大型语言模型在各种任务中取得了较大的进步,但它们往往难以完成复杂的推理,并且在知识可追溯性、及时性和准确性等至关重要的情况下表现出较差的性能。为了解决这些限制,作者提出了 Think-on-Graph (ToG),这是一个新颖的框架,它利用知识图谱来增强 LLM 的深度和负责任的推理能力。通过使用 ToG,可以识别与给定问题相关的实体,并进行探索和推理以从外部知识数据库中检索相关三元组。这个迭代过程生成多个推理路径,由顺序连接的三元组组成,直到收集到足够的信息以回答问题或达到最大深度。通过对复杂的多跳推理问答任务的实验,作者证明了 ToG 优于现有方法,有效地解决了 LLM 的上述限制,而不会带来额外的训练成本。
2. 贡献
本文的主要贡献包括:
1)提出了一种新的框架 ToG,该框架集成了思维推理和知识图谱链来回答知识密集型问题。
2)ToG框架从类人迭代信息检索中汲取灵感,生成多个高概率推理路径。
3) 实验结果表明,ToG在不增加训练成本的情况下显著增强了现有的提示方法,缓解了LLM中的幻觉问题,展示了将LLM与知识图谱集成用于推理任务的潜力。
3. 方法
本文引入了 ToG,这是一种用于图搜索的新范式,它提示 LLM 根据给定的查询中的实体探索多种可能的推理路径。ToG 不断维护问题 x 的 topN 推理路径 p,每条路径由几个三元组 Ti 组成。ToG 搜索的整个过程可以分为以下三个步骤:实体获取、探索和推理。根据中间步骤的组合,本文提出了两种方法:基于实体的 ToG 和基于关系的 ToG。
基于实体的ToG
ToG 首先提示 LLM 提取问题中的实体并获得每个实体对问题的贡献分数。这与之前将问题分解为子问题的方法不同,ToG 更强调实体。在 ToG 框架中,探索阶段至关重要,因为它旨在识别最相关的 top-N 三元组作为给定问题的推理路径中的中间步骤,基于广度优先搜索。这一阶段包括两个不同的阶段:关系探索和实体探索。作者采用两个步骤来生成当前搜索迭代、搜索和修剪的关系候选集,LLM自动完成这个过程。关系探索阶段首先搜索与当前实体集中每个实体相关联的所有关系。搜索过程可以通过执行两个简单的预定义形式查询轻松完成,这使得 ToG 在没有任何训练成本的情况下很好地适应不同的 KB。一旦获得了候选集和关系搜索,就会对查询贡献较低的边进行剪枝,只保留前 N 个边作为当前探索迭代的终止。可以利用LLM根据给定的问题基于当前实体剪枝,得到与当前关系集,即最相关的top-N关系及其对应的分数。与关系探索类似,实体探索仍然使用 LLM 自动执行的两个步骤,即搜索和修剪。在执行上述两种探索后,可以构建一个综合推理路径,其中每个中间步骤对应于一个顺序相关的三元组。在通过探索过程获得当前推理路径 P 后,提示 LLM 评估当前推理路径是否足以推断答案。如果评估产生积极的结果,对得分进行归一化并提示 LLM 使用以问题为输入的推理路径生成答案。相反,如果评估产生负面结果,重复探索和推理步骤,直到评估为正或达到最大搜索深度。
基于关系的ToG
以往的知识库问答方法,特别是那些利用语义解析的方法,主要依赖于基于关系的信息来生成正式查询。实体的文字信息并不总是完整的,尤其是在对缺少实体“名称”一部分的不完整知识图谱执行查询时,这可能会误导推理。因此,本文提出了基于关系的 ToG,它消除了探索过程中搜索中间实体的需要。它利用 LLM 的推理能力为推理过程中的每个链使用不同的候选集来生成答案。这种方法提供了两个关键好处:1)它消除了对探索实体耗时的过程的需求,从而降低了整体方法成本并显著提高了推理速度。2) 特别是在不完整的 KB 数据集下,这种方法主要关注关系的语义信息,导致更高的准确性。值得注意的是,这两种方法都遵循类似的管道,但在中间步骤中扩展推理链方面有所不同。
与基于实体的 ToG 相比,基于关系的 ToG 只涉及关系的探索和推理,其中推理阶段保持不变。两种方法之间最显著的区别是以下两种方法:实体集合中采样的样本是独立同分布的,通过计算几个样本的平均值,可以推导出实体集内关系的平均值。由于中间步骤不涉及任何实体,需要根据关系、历史路径和实体集合获得候选集,其中实体集是固定的。因此,候选实体集作为推理路径中的终端节点。具体算法步骤如表1所示。

图1 算法步骤
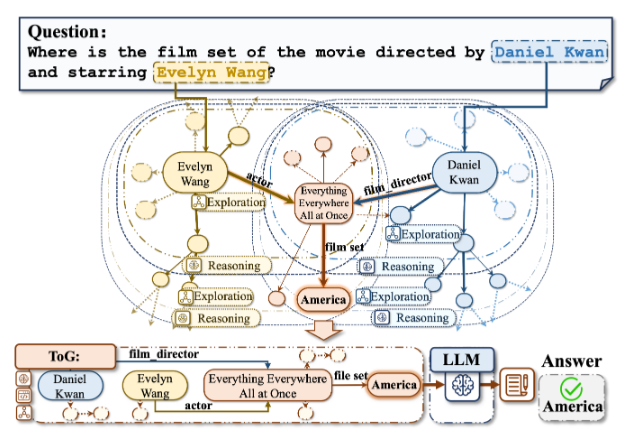
图2 本文方法的总体框架
4. 实验
本文在知识密集型任务上评估提出的方法,问题需要特定的知识来回答,LLM 在这种任务上经常会遇到幻觉问题。Complex Web Questions (CWQ)是一个用于回答需要对多个三元组进行推理的复杂问题的数据集,它包含大量自然语言中的复杂问题。本文前人工作相同,使用完全匹配精度作为评估指标。
对于 CWQ 数据集,作者随机选择 1,000 个样本作为测试集。然后排除了无法成功执行 SPARQL 查询和链接到缺乏“名称”关系答案的实体的样本。最终实验保留了 995 个样本。主要知识库来源是 Freebase。本文将探索、推理和答案生成的温度设置为 0,以实现可重复性,并将生成的最大token长度设置为 256。本文使用了 ChatGPT API 执行上述过程。
对于基线模型,作者使用标准提示 (IO 提示) 和思维链提示 (CoT),其中包含 6 个上下文示例和“逐步”推理链。ToG 在 CWQ 数据集上的性能如表 2 所示。很明显,在仅保留三个推理路径的实验条件下,每条路径的最大长度为 3,ToG(E) 在 CWQ 上的表现优于 CoT 14.86%,ToG(R) 为 17.47%。
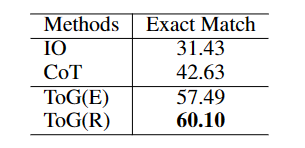
表1 CWQ 数据集的性能。ToG(E) 和 ToG(R) 分别表示基于实体的 ToG 和基于关系的 ToG
5. 总结
在这项工作中,作者提出了一种新的框架 ToG,该框架集成了思维推理和知识图谱链来回答知识密集型问题。ToG框架从类人迭代信息检索中汲取灵感,生成多个高概率推理路径。实验结果表明,ToG在不增加训练成本的情况下显著增强了现有的提示方法,缓解了LLM中的幻觉问题,展示了将LLM与知识图谱集成用于推理任务的潜力。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。

