
- 1(NeRF学习)3D Gaussian Splatting & Instant-NGP环境配置_训练3d gaussian splatting模型步骤
- 2mac安装phpstorm
- 3ASP.NET Web Pages - HTML 表单
- 4掌握Pandas数据筛选方法与高级应用全解析【第70篇—python:数据筛选】
- 5从标签说前端开发
- 6window版本python安装教程及环境变量配置(非常详细)_windows安装python环境变量
- 7RT-Thread开发学习笔记_rt_thread如何查询硬件定时器中断的优先级
- 8JavaWeb新留言板系统 23年4月原创_文心一言
- 9.Net面试题(3)
- 10Pandas 解决Series对象没有“append”问题_pandas 没有append
神经网络初认识——BP神经网络(7月18,再次认识)_最速下降法和最速下降bp法区别
赞
踩
BP神经网络——Error back Propagtion
BP网络属于多层前向神经网络,BP网络是前向神经网络的核心部分,也是整个人工神经网络体系的精华,解决非线性问题**广泛应用在分类识别,逼近,回归,压缩等领域。**matlab只是一个计算工具,我们学习需要掌握其关键的原理。
BP神经网络的结构
BP神经网络一般是多层的网络,与之相关的另一个概念是多层感知器(MLP)。也就是说BP神经网络具有多个隐含层,BP网络采用误差反向传播的学习算法。

特点
网络由多层构成,层与层之间全连接,同一层之间的神经元无连接。
BP函数的传递函数必须可微。因此感知器的传递函数——二值函数在这里并没有用;
BP网络一般使用sigmoid函数或者线性函数作为传递函数;
- 1
- 2
- 3
根据输出值是否有负值,sigmoid函数有分为两种函数
Log-Sigmoid
Tan-sigmoid
- 1
- 2


当然输出层也可以采用sigmoid函数,这时候输出层的输出被限制在(0.-1)或者是(-1,1)之间
误差反向传播算法
采用误差反向算法进行学习。在BP网络中,数据从输入层经过隐含层向输出层传播,
训练网络的权值时,则是需要沿着减少误差方向进行。从输出层经过中间各层向前修正网络的连接权值,随着学习的不断进行,不断修正,最终误差越来越小;这里并不是说存在反馈环节,只是计算顺序的选择,每修改一次隐含层中的连接层级,就会进行样本训练,然后在判断是否条件;
BP网络的学习算法
BP网络的学习属于有监督学习,需要一组已知目标输出的学习样本集。训练时先使用随机值作为权值,输入学习样本得到网络的输出,然后根据输出值与目标输出计算误差,再由误差根据适当的准则去修改所有的权值,直到误差不再变化,网络就训练完成。
修改权值有不同的规则:
比如标准的BP网络神经沿着误差性能函数梯度的反方向修改权值,即从误差性能函数出发,根据误差变化,不断修改权值
最速下降法
动量最速下降法 属于改进算法
拟牛顿法 属于改进算法
- 1
- 2
- 3
最速下降法
①最速下降法又称梯度下降法,是一种可微函数的最优化算法;
②而前面一篇文章提到的LMS算法体现了纠错原则,与最速下降法本质上没有差别。最速下降法可以求目标函数的最小值,若把目标函数取为均方误差,就得到LMS算法;

反复迭代就可以求出函数的最小值,根据梯度值可以在函数中画出一系列的等值线或等值面,在等值线或等值面上,函数相等。梯度下降法相当于沿着垂直于等值线的方向向着最小值所在位置移动,对于可微函数来说,最速下降法是求最小哦安置或极小值最有效的一种方法。


最速下降BP法
标准的BP网络使用最速下降法来调制各层权值。下面以三层BP网络为例推导标准BP网络的权值学习算法。

输入层有m个神经元(m维输入)——xm
隐含层有i个神经元——ki
输出层有j个神经元-yj
- 1
- 2
- 3
值得注意的是:与单层感知器和线性神经网络的结构不同,从隐含层到输出层之间,BP网络是有连接权值的计算,而前两者则默认为一;
输出层与隐含层之间的连接权值为W(mi);
隐含层与输出层之间的连接权值为W(ij);
- 1
- 2
而且隐含层中使用的计算传递函数是Sigmoid函数,以及输出层的传递函数是线性函数;
以三层网络为例,设定输入为二维,样本为4个,隐含层神经元有三个,输出神经元有一个
用x(n)来表示输入; 实际是一个[2x4]的矩阵, 考虑偏置后,变成一个[3x4]的矩阵,但是输出层神经元的个数并没变,还是两个 用s来表示隐含层的输入; s=w(im)*x(n); 隐含层的神经元有三个,现在的输入层神经元变成了三维,所以w(ij)是一个[3x3]的矩阵 用U来表示隐含层的输出; u=g(s) g()是Sigmoid函数,其输出是一个[3x4]的矩阵; 用v来表示输出层的输入计算; v=w(ij)*u; 作为输出层神经元的输入,若是考虑偏置,也是要变形的[4x4],但是实际上隐含层神经元的个数并没有变,还是三个。若w(ij)的值发生变化的话,影响隐含层神经元的只是其[3x3]的子式; 用y来表示最后的实际输出; y=f(v); f是线性函数; 期望输出用d来表示,误差用e表示; e(j)=d-y; 用均方误差mse作为性能判断指标; e(n)=0.5*e(j)^2; 这个用于串行训练 e(n)=e(j)^2; 这个用于批量训练

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
在调整权值阶段,沿着网络逐层反向进行调整。
①首先调整隐含层与输出层之间的权值:
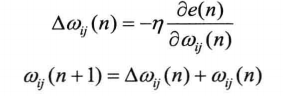
反方向进行调整;梯度Δ可以由偏导求出;根据微分链式法则:
值得注意的是,公式计算时,有时候需要用到点乘;
de(n)/dW(ij) = de(n)/de(j) de(j)/dy dy/dv dv/dW(ij);
- 1
接下来就是分布计算:
de(n)/de(j)=e(j); 是指n个训练样本的性能指标的变化量,
de(j)/dy=-1; 是指网络的误差关于输出的导数,即样本的误差实际的变化
dy/dv=f'(v); 在输出层中,传递函数一般为线性函数,所以可以得到: dy/dv=f'(v)=1,n个样本输出层的传递过程变化量
dv/dW(ij)=u; 输出层的输入量的变化,输出层的输入变化量是隐含层的输出变化量
- 1
- 2
- 3
- 4
所以可以得到这部分的Δ梯度值
de(n)/dW(ij)=-e(j)f'(v)u=e(j)u
- 1
那么权值的修正量为:
Δw(ij)=n*e(j)*u;
- 1
详细的计算过程看实例
同样与上一步类似,也可以求出输入层与隐含层之间的权值调整量ΔWmi:
先求出梯度值Δ
de(n)/dW(mi) = de(n)/du du/ds ds/dW(mi);
- 1
分步计算:
de(n)/du=de(n)/de(j)de(j)/dydy/dvdv/du
=-e(j)f'(v)w(ij); f'(v)=1
上面有这条式子v=w(ij)*u,
值得注意的是,这里w(ij)一定是一个矩阵,在计算前面的梯度值时,若其本身是偏置值的计算的,则需要考虑。
但是在计算这一层时,就算w(ij)矩阵中有偏置值的存在,但是是不需要考虑的,因为隐含层的输出并不包括偏置值,不过呢,也是可以考虑的;做法是将值为1作为一个隐含层的神经元,这样的话,隐含层中W(mi)矩阵的大小会发生改变,需要自己理清楚。我后面的计算,不是采用添加多一个神经元的做法。
不过在计算神经元的输入时,会把权值考虑上。
du/ds=g'(s); 由于g为Sidmoid函数,无法像线性函数一样,求导数是一个常量,所以就写成这种形式;
ds/dW(mi)=x(n) x(n)为输入向量;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
将上面三条式子代入得:
de(n)/dW(mi) =-e(j)f'(v)w(ij)g'(s)*xi;
- 1
然后就能得到这部分的权值修正量:
Δw(mi)=n(e(j)w(ij)g’(s)xi);
值得注意的是,需要随时注意一个样本对应一组的权值矩阵,一个样本对应一种误差变化。
串行与批量学习方式
在串行运行方式中,每个样本依次输入,需要存储的空间更少,训练的样本是随机的,可以降低网络陷入局部最优的可能性;
批量学习方式闭串行方式更容易实现并行化,由于所有样本同时参与运算,因此批量方式的学习速度往往远优于串行方法;
- 1
- 2
设计网络的方法
1.网络层数:对于大部分应用场合,单个隐含层即可满足需求。
2.输入层节点数:节点数取决于输入向量的维数, 例如输入的是64x64的图像,
则输入向量应为图像中所有的像素形成的4096维向量。
3.隐含层节点数:对BP网络的性能有很大的影响,一般教的隐含层节点数可以带来更好的性能,
但是可能导致训练时间过长。通常的做法是经验公式:
- 1
- 2
- 3
- 4
- 5

4.输出层神经元个数:输出层神经元的个数同样需要根据实际问题中得到抽象模型来确定。
5.传递函数的选择:一般隐含层使用Sigmoid函数,而输出层则使用线性函数。
如果输出层也采用sigmoid函数,则输出值会被限制在(0,1)或(-1 1)之间;
6.初始权值的确定:BP网络采用迭代更新的方式确定权值,因此需要一个初始值,一般初始值都是随机给定的;
- 1
- 2
- 3
- 4
经验值为(-2.4/F,2.4/F)或者是(-3/F^0.5,3/F^0.5),其中F为权值输入端连接的神经元个数;
- 1
BP神经网络相关函数详解
logsig Log-Sigmoid函数
tansig Tan-Sigmoid函数
newff 创建一个BP网络
feedforwardnet 创建一个BP网络
newcf 创建级联的前向神经网络
cascadeforwardnet 创建级联的前向神经网络
newfftd 创建前馈输入延迟的BP网络
- 1
- 2
- 3
- 4
- 5
- 6
- 7
实例
①logsig函数
这个函数的特点是(-∞,+∞)范围的数据被映射到区间(0,1)。

logsig是一个神经元传递函数,x为神经元节点的输入,函数返回每一个输入数据对应的函数值。
x=-4:4;
y=logsig(x);
plot(x,y,'-o')
- 1
- 2
- 3
②tansig函数
tansig是双曲正切Sigmoid函数,调用形式于logsig函数相同,同样作为神经元传递函数。不过其输出的范围是(-1,1)。

上图可以看出两种函数的不同之处。
x=-4:4;
y=logsig(x);
plot(x,y,'-o')
hold on
y=tansig(x);
plot(x,y,'-r')
- 1
- 2
- 3
- 4
- 5
- 6
③newff——创建一个BP网络
这是BP网络中最常用的函数,可以用于创建一个误差反向传播的前向网络。新版用feedforwardnet函数来代替。
net=newff(P,T,S)
P:输入矩阵
T:输出层节点数,即输出层的维数
S:用于指定隐含层神经元的个数
- 1
- 2
- 3
- 4
net=newff(P,T,S,TF,BTF,BLF,PF,IPF,OPF,ODF)
TF:第i层的传递函数,隐含层默认为tansig,输出层默认为purelin;
BTF:BP网络的训练函数,默认值为trainlm,表示采用LM法进行训练;
BLF:BP网络的权值和偏置的学习函数,默认为learngdm
PF:性能函数 默认值为mse
- 1
- 2
- 3
- 4
- 5
net=feedforwardnet(hiddenSizes,trainfcn)
hiddenSizes为隐含层的神经元个数,如果有多个隐含层,则hiddenSizes是一个行向量,默认值为10.
trainfcn为训练函数,默认值为“trainlm".
该函数并未确定输入层和输出层的维数,系统将这一步交给train函数。
- 1
- 2
- 3
- 4
x=-4:4; %输入向量
y=x.^2; %目标函数
plot(x,y,'-o') %目标曲线
net=feedforwardnet; %看一下隐含层有多少个神经元
net1=train(net,x,y); %训练BP网络
Z=sim(net1,x) %输入任意相同长度的向量,可以看到输出值与目标函数基本一致
hold on;
plot(x,Z,'-r')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
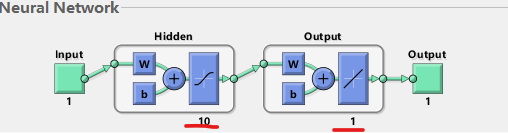
可以看到的是隐含层有十个神经元,输出层有一个神经元。
net=cascadeforwardnet(hiddenSizes,trainFcn)
这个函数是指级联前向BP网络:指的是不同层的网络自荐,不只存在这相邻层的连接。例如,输入层除了与隐含层有权值相连以外,还与输出层有直接的联系。
- 1
- 2
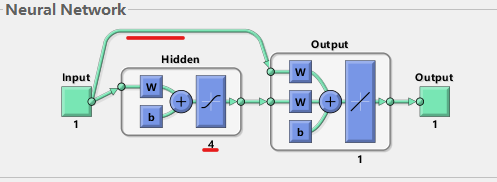
x=-4:4; %输入向量
y=x.^2; %目标函数
plot(x,y,'-o') %目标曲线
net=cascadeforwardnet([4]); %看一下隐含层有多少个神经元
net1=train(net,x,y); %训练BP网络
Z=sim(net1,x) %输入任意相同长度的向量,可以看到输出值与目标函数基本一致
hold on;
plot(x,Z,'-r')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
也是使用前面的列子,我们将其换成是级联前向BP神经网络。

上面是一些创建BP网络比较常见的函数;
④dlogsig/dtansig——sigmoid函数的导数
这个函数对于我们手算BP神经网络有很大的帮助
x=dlogsig(N,A)
其中N是指自变量,A是指logsig函数的结果;
以及
x=dtansig(N,A)
- 1
- 2
- 3
- 4

x=-4:4;
y=logsig(x);
dy=dlogsig(x,y);
plot(x,y,'-o')
hold on;
plot(x,dy,'-r')
- 1
- 2
- 3
- 4
- 5
- 6
x=-4:4;
y=tansig(x);
dy=dtansig(x,y);
plot(x,y,'-o')
hold on;
plot(x,dy,'-r')
- 1
- 2
- 3
- 4
- 5
- 6

## 实例 ——异或 采用批量训练,最速下降BP法.分析非线性网络; ```bash clear all clc %%参数 eb=0.01;%误差容限 n=0.6;%学习率 maxiter=1000000 ;%最大迭代次数 %%初始化网络 nsampNum=4; %输入样本的个数 nsampdim=2; %输入样本的维度 nhidden=3; %隐含层神经元的个数 nout=1; %输出层神经元的个数 %权值经验设置 可知输入层到隐含层之间的权值有三组(6个值),偏置也有三组(三值) w=rand(3,2); b=rand(3,1); wex=[w,b]; %是一个3X3的矩阵,行向量w11 w12 b1 %权值经验设置,可知隐含层到输出层之间的权值也有三组(3个值),偏置只有一组(一个值; W=rand(1,3); B=rand(1,1); WEX=[W,B]; %是一个1X4的矩阵 %%提供训练数据 x=[0 0 1 1; 0 1 0 1; 1 1 1,1]; %训练样本 一行代表一维,三行的意思是两种权值加上偏置 t=[0 ,1 ,1 ,0]; %期望输出 %开始训练 iteration=0; %迭代次数 i=0; while 1 %工作信号正向传播 hp=wex*x; %隐含层的权值计算 3X4 tau=logsig(hp); %隐含层的训练后的输出,这个输出是3X4的矩阵 tauex=[tau',ones(4,1)]'; %设置好隐含层的输入 4X4 hm=WEX*tauex; %1x4 out=logsig(hm); %1x4 err=(t-out); %期望值与输出值做对比 err也是一个矩阵; en(i+1)=sumsqr(err); iteration=iteration+1; %迭代次数加一 %%%%%%%判断网络是否收敛 if (en(i+1)<0.01) %那么系统收敛,跳出while wex1=wex; WEX1=WEX; break; end %%%%%%%接下来,计算权值的修正量de和DE %%%%%%%%%%%%%先计算隐含层和输出层之间的权值修正量 de=n*2*err.*(dlogsig(hm,out))*tauex'; %n为学习率 err是误差 err是1X4,taues‘是4X4,最终也是得到1X4; %%%%%%%%%%%%%%%%%在向前极端输入层与隐含层之间的权值修正量 DE=n*((W'*[2*err.*(dlogsig(hm,out))]).*[(dlogsig(hp,tau))])*x'; WEX=WEX+de; %更新权值 wex=wex+DE; W=WEX(:,1:3); i=i+1; if (i>=maxiter) wex1=wex; WEX1=WEX; break; end end %%%%%%%%%%%%%%%%%%%%%%%%%%%%训练完成后,我们就得到了合适的权值和偏置值,wex和WEX,我们只要设置相同大小的输入矩阵,就能得到输出值; x1=[0 0 1 0; 0 1 1 1; 1 1 1 1]; hp1=wex1*x1; tau1=logsig(hp1); tauex1=[tau1',ones(4,1)]'; hm1=WEX1*tauex1; out1=logsig(hm1) y=out1>=0.5
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
结束
路漫漫,多回头

