
- 1Hive习题汇总(持续汇总中)_hive期末机试
- 2浅谈词嵌入(word embedding)_两个单词能不能做词嵌入
- 3AWS Python应用_pycgarm上显示的aws是什么
- 4动态规划及动态规划的应用
- 5C语言结构体声明的妙用,隐藏结构体内部信息_王凯c语言
- 6K8S彻底卸载教程_卸载kubelet
- 7基于eNSP的某大学校园网络规划与设计(开题报告)_ensp论文题目
- 8Python爬虫入门5:模拟浏览器访问网站_python模拟浏览器访问
- 9【阅读源码】Transformer的FFN机制源码解读(dropout)_ffn代码详解
- 10linux SPI驱动代码追踪_linux3.10内核spi驱动
第15章Sqoop(3)_select blobref.getdatastream()
赞
踩
处理导入的数据
一旦数据导入到了HDFS中,现在就应该由自定义的Mapreduce处理这些数据了。文本格式导入的数据,可以很容易的和Hadoop流,被脚本语言运行,或者,和默认的TextInputFormat运行(翻译不恰当这里,原文Text-based imports can be easily used in scripts run with Hadoop
Streaming or in MapReduce jobs run with the default TextInputFormat)。
使用记录中的分割的字段,字段分隔符一定被解析,并且,分割出来的字段一定要转换成合适的数据类型。例如,widget中“sprocker”的id是string类型的1,但是应该被解析成java中的Integer或者int。Sqoop提供的生成代码类,可以自动处理这个过程,允许你只关注Mapreduce job的运行。每一个自动生成代码类,都有好几个重载方法,名叫parse(),这个方法可以操作Text,CharSequence,char[],或者其它的常见类型。
叫做MaxWidgetId的Mapreduce程序会找到有最高ID的widget。
这个类可以和Widget.java一起被编译为一个JAR文件。在编译的时候,Hadoop(hadoop-core-version.jar)和Sqoop(sqoop-version.jar)应该在编译路径中。然后,这些类文件可以被编译成一个JAR文件,并且像如下一样执行:
% jar cvvf widgets.jar *.class
% HADOOP_CLASSPATH=/usr/lib/sqoop/sqoop-version.jar hadoop jar \
> widgets.jar MaxWidgetId -libjars /usr/lib/sqoop/sqoop-version.jar
这个命令保证Sqoop是在本地类路径上面(通过$HADOOP_CLASSPATH),当运行MaxWidgetId.run()方法的时候,就像map tasks运行在集群上面一样(通过 -libjars argument)。
当运行的时候,HDFS中的maxwidget路径会包括一个名叫part-r-00000的文件,期待的文件内容如下:
3,gadget,99.99,1983-08-13,13,Our flagship product
在这个例子中,Mapreduce没有多大意义,一个Widget对象从mappper到reducer;自动生成的Widget类实现了Hadoop提供的Writable接口,这样就允许对象通过Hadoop的序列化机制传递,就像从序列化文件中读写一样。
MaxWidgetId例子是在新的MapReduce API上面编译的。依靠Sqoop自动生成代码的Mapreduce程序可以基于新的或旧的APIs上面编译,尽管在新APIs里面,一些高级特性使用起来更方便。
导入的数据和Hive
12章提到过,对于很多类型的分析,使用Hive这样的系统,处理关系操作可以戏剧性的简少开发的分析管道。尤其,对于关系型数据库中的数据,使用Hive有很大意义。Hive和Sqoop一起组成了一个执行分析的工具链。
假设,在我们的系统中,有另一个数据日志,它来自于基于网站的采购系统。这样的话,就会,返回包括widgte id,质量,邮寄地址,和一个下单日期。
这里是一个这种日志的例子:
1,15,120 Any St.,Los Angeles,CA,90210,2010-08-01
3,4,120 Any St.,Los Angeles,CA,90210,2010-08-01
2,5,400 Some Pl.,Cupertino,CA,95014,2010-07-30
2,7,88 Mile Rd.,Manhattan,NY,10005,2010-07-18
使用Hadoop来分析这种购物日志,我们可以洞察我们的销售业务。把这种数据和从关系型数据库中抽取来的数据组合在一起,我们可以做的更好。在这个例子中,我们会计算我们的销售业绩主要来自哪个地区,这样,我们可以更好的调整我们的销售团队的活动。要实现这些,我们需要销售日志和widget表。
上面的表应该存到本地,并命名为sales.log。
首先,让我们把数据加载到Hive中:
hive> CREATE TABLE sales(widget_id INT, qty INT,
> street STRING, city STRING, state STRING,
> zip INT, sale_date STRING)
> ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
OK
Time taken: 5.248 seconds
hive> LOAD DATA LOCAL INPATH "sales.log" INTO TABLE sales;
Copying data from file:/home/sales.log
Loading data to table sales
OK
Time taken: 0.188 seconds
Sqoop可以,基于一个关系型数据库源中的表,生成一个Hive 表。只要,我们已经把widget数据导入HDFS中了,我们可以生成Hive表定义并且加载HDFS常驻数据:
% sqoop create-hive-table --connect jdbc:mysql://localhost/hadoopguide \
> --table widgets --fields-terminated-by ','
...
10/06/23 18:05:34 INFO hive.HiveImport: OK
10/06/23 18:05:34 INFO hive.HiveImport: Time taken: 3.22 seconds
10/06/23 18:05:35 INFO hive.HiveImport: Hive import complete.
% hive
hive> LOAD DATA INPATH "widgets" INTO TABLE widgets;
Loading data to table widgets
OK
Time taken: 3.265 seconds
当用一个指定的,已经规划好的导入数据集,创建一个Hive表定义的时候,我们需要那个数据集所使用的分隔符。否则的话,Sqoop会允许Hive使用它默认的分隔符(Hive默认的分隔符与Sqoop的是不一样的)。
注:
HIve的数据类型系统比大多数SQL系统少。许多SQL数据类型,在Hive中没有直接对应的类型。当,Sqoop为导入数据,生成一个Hive表定义的时候,它使用最合适的Hive类型来存储值。这可能导致精确度的降低。当这种情况发生的时候,Sqoop会提供一个警告信息,例如:
10/06/23 18:09:36 WARN hive.TableDefWriter:
Column design_date had to be
cast to a less precise type in Hive
往HDFS中导入数据的这三个步骤,创建了Hive表,然后加载HDFS常驻数据到Hive中,其实,如果,你知道你只是想,把数据库中的数据直接导入到Hive中,这三个步骤可以缩短为一个步骤。在导入的过程中,Sqoop可以生成Hive表定义并且加载数据。如果我们没有执行过导入数据的话,我们可能执行过下面这一命令了,这一命令,在Hive中创建了widgets表,基于在MySql中的拷贝。
% sqoop import --connect jdbc:mysql://localhost/hadoopguide \
> --table widgets -m 1 --hive-import
注:
sqoop import 工具有--hive-import参数的时候,就会把数据直接从数据源中加载到Hive中;它会根据数据源中的表的模式,自动推测Hive的模式。使用这个方法,你可以只使用一条命令就可以在Hive中处理你的数据了。
不管我们选择的是哪种导入数据的方式,我们现在都可以用widgets数据集和销售数据,一起来计算出最合适的销售地区。现在我们开始做吧,稍后,保存查询的结果。
hive> CREATE TABLE zip_profits (sales_vol DOUBLE, zip INT);
OK
hive> INSERT OVERWRITE TABLE zip_profits
> SELECT SUM(w.price * s.qty) AS sales_vol, s.zip FROM SALES s
> JOIN widgets w ON (s.widget_id = w.id) GROUP BY s.zip;
...
3 Rows loaded to zip_profits
OK
hive> SELECT * FROM zip_profits ORDER BY sales_vol DESC;
...
OK
403.71 90210
28.0 10005
20.0 95014
导入大对象
大部分数据库提供在一个字段上,存储大量数据的能力。由于,无论这个数据是文本格式的,还是二进制的,通常情况下,在表中是CLOB或者BLOB。这些大对象被数据库自己特殊的处理。尤其,大多数表是像表格15-2那样物理的存储在硬盘上的。当扫描行的时候,决定,哪一行匹配特定的查询,这包括,从磁盘上读取每一行每一列的值。如果大对象以这种方式存储内联,它会影响扫描的性能。因为大对象通常情况下是存储在行之外的(即不存储在表中),像15-3图表一样。访问大对象需要通过行中的对它的索引。

在数据库中,处理大对象的困难,表明了,像Hadoop这样的系统,更适合存储、处理复杂的数据对象。Sqoop可以从表中抽取大对象并且把它们存储到HDFS中,以便后续的处理。

在数据库中,Mapreduce在把记录传递给mapper之前,会分析每一个记录。如果,记录是很大话,这个过程会很低效。
就像之前显示的那样,Sqoop导入的记录存储在磁盘之外,以一种数据库内部存储很相似的方式:an array of records with all fields of a record concatenated together。当运行Mapreduce程序处理记录的时候,买一个map task 必须完全的解析每一条记录的所有字段。如果,大对象字段的内容,仅仅是总共数据的一小部分被作为了Mapreduce程序的输入,那么,分析全部数据会是低效的。更何况,由于大对象的大小,完全的解析的话,内存大小可能不够。
为了克服这些困难,Sqoop会把导入的大对象存储在一个特定的字段,叫做LobFile。LobFile格式可以存储独立的大数据对象的记录。LobFile中的每一个记录存储一个单独的大数据对象。LobFile格式允许客户端存储记录的一个引用,而不用去访问记录的内容。当访问记录,是通过java.io.Input Stream(二进制对象)或者java.io.Reader(字符对象)完成的。
当,一个记录被导入的时候,普通的字段会被解析成一个文本文件,CLOB或者BLOB会被解析成LobFile的索引来存储。例如,假设我们的widgets 表包括BLOB字段,明叫schematic,它存储了每个widget的概要。
这样一个导入的记录看起来可能就是这样的:
2,gizmo,4.00,2009-11-30,4,null,externalLob(lf,lobfile0,100,5011714)
externalLob(lf,lobfile0,100,5011714)这个文本是外部存储对象的引用,它表明,LobFile格式(lf),名叫lobfile,指定的字节偏移量和文件的长度。
当处理这个记录的时候,Widget.get_schematic()方法,会返回一个BlobRef类型的schematic列的引用,但是并不包含相应的内容。BlobRef.getDataStream()方法实际上打开LobFile,并且返回InputStream,来允许你访问schematic字段的内容。
当运行Mapreduce job处理很多Widget 记录的时候,你可能只需要访问schematic字段的一小部分记录。这个系统允许你引发I/O消耗,来访问需要的大对象实体,独立的schematic可能是兆字节或者更大的数据。
执行导出
在Sqoop中,一个导入意味着从数据库系统中把数据导入到HDFS中。相反,导出是把HDFS当做数据源,并且把远程数据库作为目的地。在之前的部分,我们导入了一些数据,并且用Hive分析了。我们可以把这些分析的结果导出到数据库中,以便其它的工具来使用。
在把表从HDFS往数据导出之前,我们必须准备好接受数据的数据库,我们要建立表。尽管,Sqoop可以推测出哪种java类型适合SQL数据的类型,反过来,这种事情就不行了(例如,可能有好几个SQL定义的类型可以存储Java String;这可以是CHAR(64), VARCHAR(200),或者 其它的)。因此,你必须指明哪种类型是更合适的。
我们现在将要把zip_profits表从Hive中导出去。我们需要在MySql中创建一个表。
% mysql hadoopguide
mysql> CREATE TABLE sales_by_zip (volume DECIMAL(8,2), zip INTEGER);
Query OK, 0 rows affected (0.01 sec)
然后,我们执行导出命令:
% sqoop export --connect jdbc:mysql://localhost/hadoopguide -m 1 \
> --table sales_by_zip --export-dir /user/hive/warehouse/zip_profits \
> --input-fields-terminated-by '\0001'
...
10/07/02 16:16:50 INFO mapreduce.ExportJobBase: Transferred 41 bytes in 10.8947
seconds (3.7633 bytes/sec)
10/07/02 16:16:50 INFO mapreduce.ExportJobBase: Exported 3 records.
最后,我们可以检查MySql来区分不同的导出:
% mysql hadoopguide -e 'SELECT * FROM sales_by_zip'
+--------+-------+
| volume | zip |
+--------+-------+
| 28.00 | 10005 |
| 403.71 | 90210 |
| 20.00 | 95014 |
+--------+-------+
当我们在Hive中创建了zip_profits表的时候,我们没有指定分隔符。这样的话,Hive使用它默认的分隔符:一个Ctrl-A字符,(Unicode 0x0001)。当我们使用Hive访问表的内容的时候(在SELECT语句中),Hive把这个分隔符转换成tab分隔符,为了在控制台上显示出来。但是,当直接从文件中读取表的时候,我们需要告诉Sqoop应该使用哪个分隔符。Sqoop假设记录中换行分隔符也是默认的,但是需要被告诉Ctrl-A字段分隔符。--input-fields terminated-by argument to sqoop export 命令指明了这个信息。Sqoop支持几个转义序列(以‘\’开头的字符),当指定分隔符的时候。在上面的例子中,转义序列包括在单引号中。没有单引号的话,反斜杠可能就被转义了(例如,--input-fields-terminated-by \\0001)Sqoop支持的转义字符如下表15-1
Escape Description
\b backspace
\n newline
\r carriage return
\t tab
\' single-quote
\" double-quote
\\ backslash
\0 NUL. This will insert NUL characters between fields or lines, or will disable enclosing/escaping if used for one of the
--enclosed-by, --optionally-enclosed-by, or --escaped-by arguments.
\0ooo The octal representation of a Unicode character’s code point. The actual character is specified by the octal value ooo.
\0xhhh The hexadecimal representation of a Unicode character’s code point. This should be of the form \0xhhh, where
hhh is the hex value. For example, --fields-terminated-by '\0x10' specifies the carriage return
character.
导出:深入的学习
Sqoop的导出架构与导入时很相似的。见表15-4.在导出之前,Sqoop根据数据库连接字符串决定策略。对于大多数系统,Sqoop使用JDBC。Sqoop然后生成一个基于目标表定义的Java类。生成的这个类,有能力从文本文件中解析记录并且向表中插入合适的数据类型。一个Mapreduce job 启动,从HDFS中读取原数据,用生成的代码解析记录。
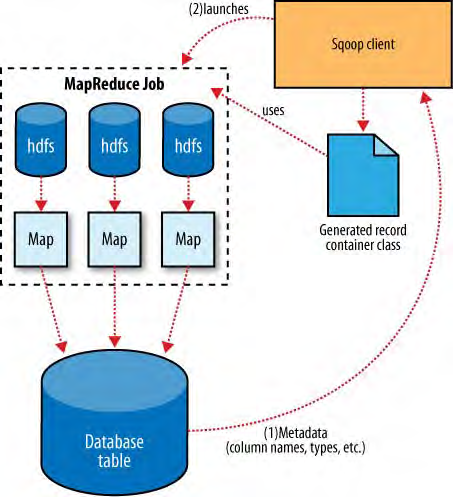
基于JDBC的导出策略,构建了INSERT语句,这些语句会把记录写到目标表格中。在大多数数据库系统中,每条语句插入很多记录,比很多的单行插入语句(译注:即每条插入语句,只插入一条记录)要高效。单独的线程被用来从HDFS中读取数据,并且和数据库交流,也用来保证,I/O操作涉及到不同的系统的时候,尽可能重叠。
对MySql来说,Sqoop可以使用mysqlimport采用直接模式策略。每一个map task 产生一个mysqlimport 进程,这个进程以本地系统FIFO模式(翻译不当,原文Each map task spawns a mysqlimport process that it communicates with via a named FIFO on the local filesystem.)。此时,数据以流的形式,通过FIFO管道,到mysqlimport,然后从那里再到数据库。
然而,大多数从HDFS中读数据的Mapreduce jobs,会选择并行度(即map tasks 的个数),这种选择是依据要处理文件的大小和个数,Sqoop的导出系统,允许用户精确的控制tasks的数量。导出系统的性能,会受到向数据库中写入数据的,分布的wirters的数量的影响,因此,Sqoop使用CombineFileInputFormat类把输入的文件分给少量的map tasks。
导出和事务性
由于线程的并发性,一个导入操作可能并不是原子性的。Sqoop会生成很多tasks 来平行的导出数据片段。这些tasks 可能会在不同的时间段完成,这也就意味着,尽管在tasks中使用了事务,一个task的结果可能在其它tasks结果之前出来。数据库通常采用固定大小的缓冲区来存储交易。结果导致,一个事务不能必要的包括一个task的整组操作。Sqoop每隔几千行就提交一次数据,为了保证,操作不内存溢出。到导出继续的时候,中间结果是可见的。
要使用导出结果的程序,只能等到这个导出过程完全完成的时候,才能使用。要不然的话,程序看到的只是部分数据。
更麻烦的情况是,如果tasks失败了(由于网络问题或者其它的问题),这些tasks会尝试从它们开始导入数据的地方重新开始,会插入重复的记录。这次写数据的时候,Sqoop不提防这种潜在的问题。在启动一个导出job之前,约束条件应该放在数据库表中(例如,把一个列设置为主键列),以保证行的唯一性。Sqoop的未来版本中,可能会用更好的还原逻辑,目前是不支持的。
导出和序列化文件
从Hive表中导出数据的例子中,数据是以文本格式存储在HDFS中的。Sqoop也可以导出不是Hive表的文本文件。例如,Sqoop可以导出Mapreduce job输出的文本文件。
Sqoop也可以导出序列化存储的记录到外部表中,尽管应用范围较窄。一个序列化文件可以包括任意的数据类型。Sqoop的导出工具会从序列化文件中读取对象,并且把它们直接发送到OutputCollector,将对象传递到数据库,导出OutputFormat。使用Sqoop的时候,记录必须存储在,序列化文件的键值对格式的值部分,而且,必须继承com.cloudera.sqoop.lib.SqoopRecord抽象类(Sqoop生成的所有类都是这样做的)。
如果你使用编译工具(sqoop-codegen)为你一条基于你导出的表的的记录,生成一个SqoopRecord的实现,你可以写一个Mapreduce程序,这个程序实现这个类的实例,并且把实例写到序列化文件中。然后Sqoop-export 可以导出这些序列化文件到表中。序列化文件在SqoopRecord实例中的另一种情况是,如果从数据库向HDFS中导入数据的话,中间数据有些修改,并且结果以序列化文件存储,。。(本句翻译不恰当,原文:Another means by which data may be in SqoopRecord instances in SequenceFiles is if data is imported from a database
table to HDFS, modified in some fashion, and the results stored in SequenceFiles holding
records of the same data type.)
在这种情况下,Sqoop应该重用存在的类定义来从序列化文件中读取数据,而不是,生成一个新的包含了执行导入的类的记录,就像转换基于文本的记录到数据库中的行一样。你可以省略掉代码的生成,代替的,使用已经存在的记录类和jar包,使用--class-name and --jar-file参数提供给Sqoop。到导入记录的时候,Sqoop会使用特定的类,会从特定的jar包里加载。
在下面的例子中,我们会重新导入widgets表为序列化文件,并且,把它再以不同的表,导回到数据库中:
% sqoop import --connect jdbc:mysql://localhost/hadoopguide \
> --table widgets -m 1 --class-name WidgetHolder --as-sequencefile \
> --target-dir widget_sequence_files --bindir .
...
10/07/05 17:09:13 INFO mapreduce.ImportJobBase: Retrieved 3 records.
% mysql hadoopguide
mysql> CREATE TABLE widgets2(id INT, widget_name VARCHAR(100),
-> price DOUBLE, designed DATE, version INT, notes VARCHAR(200));
Query OK, 0 rows affected (0.03 sec)
mysql> exit;
% sqoop export --connect jdbc:mysql://localhost/hadoopguide \
> --table widgets2 -m 1 --class-name WidgetHolder \
> --jar-file widgets.jar --export-dir widget_sequence_files
...
10/07/05 17:26:44 INFO mapreduce.ExportJobBase: Exported 3 records.
在导入的时候,我们指定了序列化文件格式,并且,我们想把jar包放进当前目录中(使用--bindir命令),这样我们就能重用它了。否则的话,它将被放在一个临时的目录中。我们可以为导出创建一个目的地的表,这个表有一个稍微不同的模式,尽管它与原始数据是一致的。我们导出数据, 并且使用存在的生成的代码,来从序列化文件中读取记录,并且写到数据库中。

