
大数据基础复习_大数据基础知识
赞
踩
第一章
1.大数据的概念:
大数据是指无法在一定时间内用常规软件工具对其内容进行抓取、管理和处理的数据集合。
2.大数据的特点:
(1)Volume:数据存储量大,计算量大。
(2)Value:价值密度低,对未来趋势与模式可预测分析,深度复杂分析。
(3)Variety:数据来源多,数据类型多,关联性强。
(4)velocity:数据存储、传输、处理速度快。数据更新增长速度快。
3.数据中心:
计算机系统及其通信、存储、安全、监控等系统配套设备。
4.大数据的步骤:
(1)数据采集:将数据抽取到临时的文件或数据库中。
(2)数据导入、清洗:数据去重、数据归一、异常处理。
(3)数据统计、分析、挖掘:预设主题,使用各类算法计算。
(4)结果可视化
5.大数据与物联网云计算的关系:
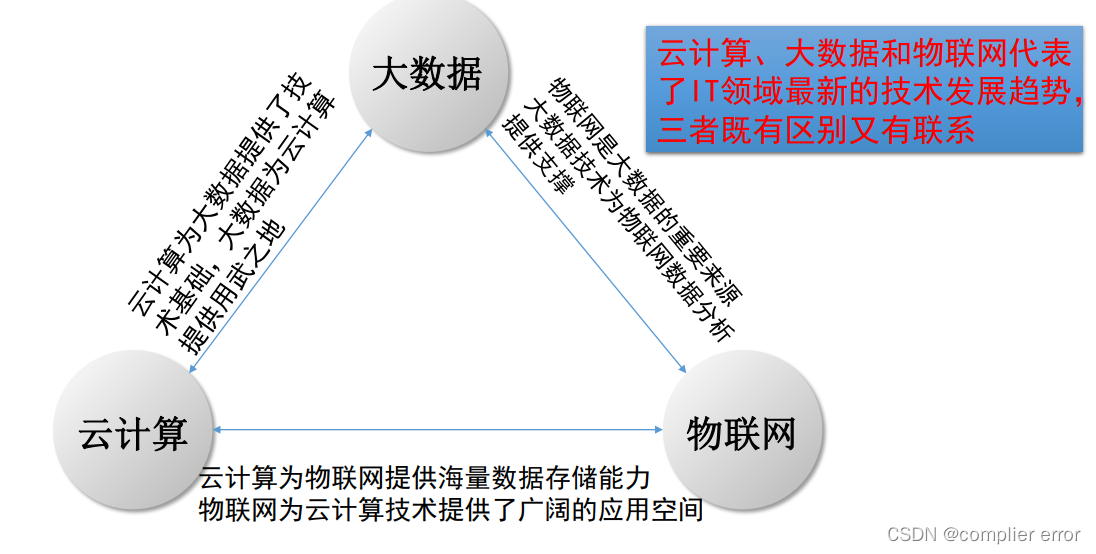
6.大数据与人工智能:
(1)人工智能需要数据来建立其智能,特别是机器学习。
(2)大数据技术为人工智能提供了强大的存储能力和计算能力。
(3)人工智能是一种计算形式,允许计算机执行认知功能;大数据是一种传统计算,它不会根据结果采取行动,只是寻找结果。
7.大数据思维
(1)抽样思维(全数据模式):分析大量数据,推测状况。
(2)容错思维:大量数据产生的价值,可以弥补这些小错误。
(3)相关关系:一个数据数值的变化会影响另外的数据数值的变化。
8.Hadoop的概念
(1)一种分布式系统基础架构。
(2)主要解决海量数据的存储、分析。
(3)
9.Hadoop的特性
(1)扩容能力强:计算机集群分配任务,完成计算。
(2)低成本:廉价机器集群分发处理。
(3)高效率:数据并发
(4)可靠性:自动维护任务,失败重新部署任务。
10.HDFS是什么
一个高度容错性的分布式文件系统。流式访问模式访问应用程序的数据。
适合用于具有超大数据集的应用程序中。
提供了廉价服务器集群,和大规模分布式文件存储能力。
11.MapReduce是什么
一种编程模型,应用于大规模数据并行运算,将任务分发到各个节点上,各节点计算完结果再把结果合并。用于任务调度、负载均衡、容错处理。
12.Spark:
Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop
上存储的大数据进行计算。
13.Hbase
Hbase是一个高可靠、高性能、面向列、可伸缩的分布式数据库,主要存储非结构化和半结构化的松散数据。
14.Nosql
NoSQL数据库可以支持超大规模数据存储、灵活的数据模型支持WEB2.0应用,具有强大的横向扩展能力,有效弥补传统关系型数据库的不足。
15.数据块的概念
HDFS默认一个块64MB,一个文件被分成多个块,以块作为存储单位块的大小远远大于普通文件系统,可以最小化寻址开销和定位开销。
16.HDFS采用抽象块的优势
(1)支持大规模文件储存
文件以块为单位进行存储,一个大规模文件可被分拆成若干个文件块,不同的文件块可以被分发到不同的节点上。其次,一个文件的大小不会受到单个节点的存储容量的限制,可以远远大于网络中任意节点的存储容量。
(2)简化系统设计
简化了存储管理,方便了元数据的管理。
(3)适合数据备份
每个文件块都可以冗余存储到多个节点上,大大提高了系统的容错性和可用性。
17.HDFS节点类型
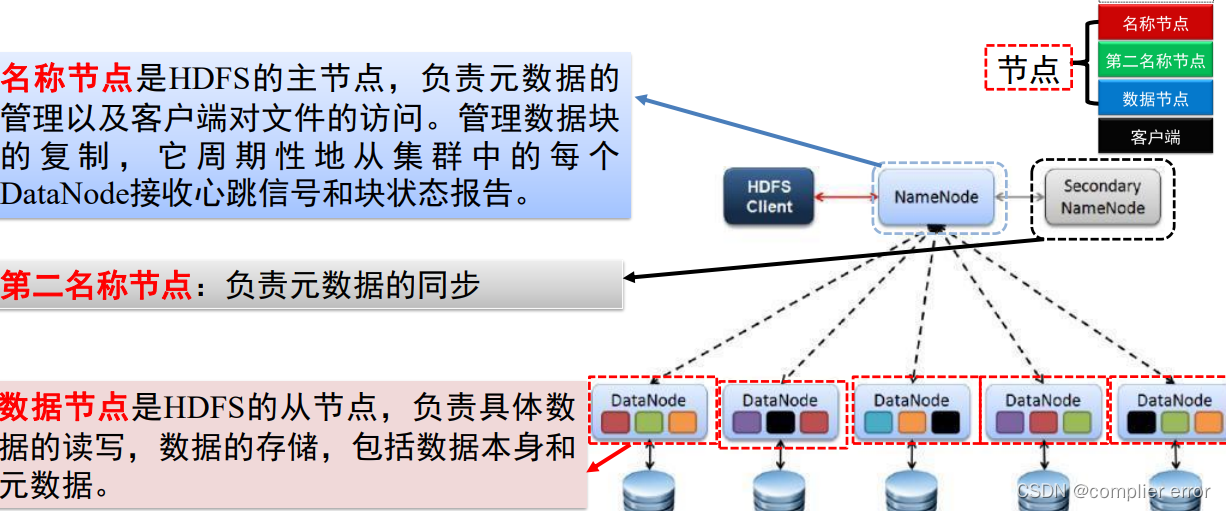
18.HDFS存储管理
(1)数据冗余存储
保证系统的容错性和可用性。一个数据块的多个副本会被分布到不同的数据节点上。
(2)数据错误与恢复
检测数据错误并自动恢复。把这些核心文件同步复制到备份服务器,名称节点出错则备份服务器进行数据恢复。
数据节点向名称节点发送“心跳”报告自己的状态,出现故障“心跳”部分失效,宕机。
(3)数据存取策略
核心内容,影响系统读写性能。以机架为基础,数据放在不同机架上。
19.Hbase数据模型
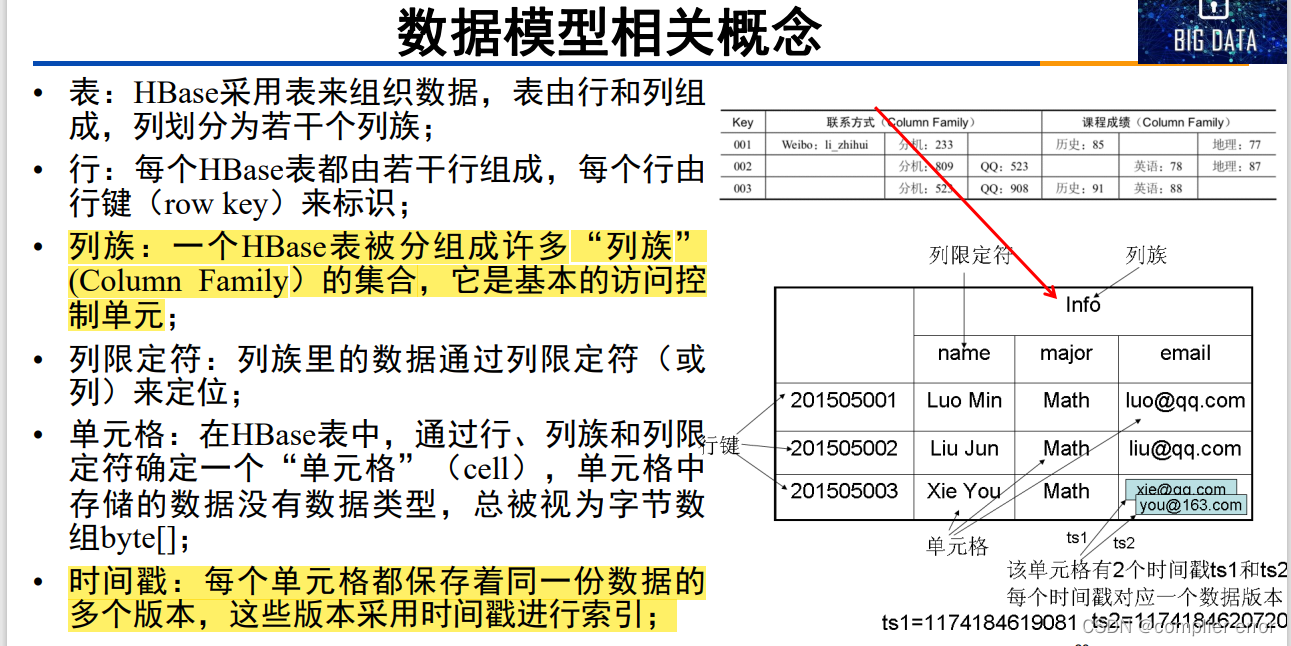
20.Hbase功能组件
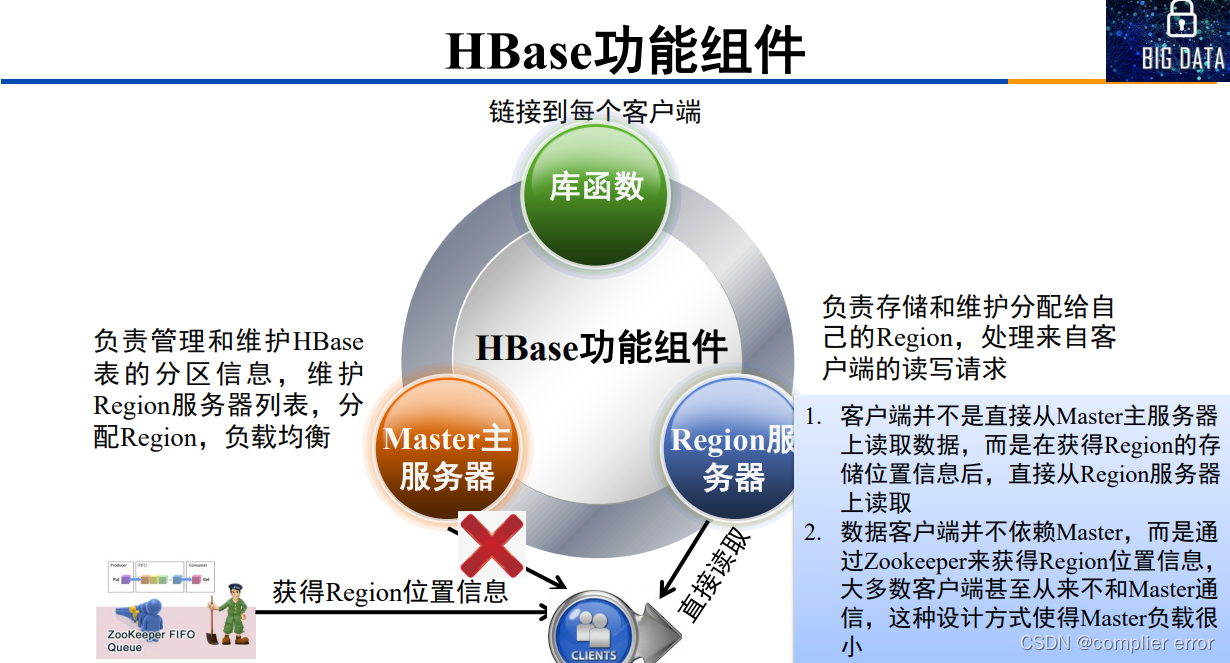
21.Master主服务器
主服务器Master主要负责表和Region的管理工作:
(1)管理用户对表的增加、删除、修改、查询等操作。
(2) 实现不同Region服务器之间的负载均衡。
(3)在Region分裂或合并后,负责重新调整Region的分布。
22.Region服务器
Region服务器是HBase中最核心的模块,负责维护分配给自己的Region,
并响应用户的读写请求。
23.Nosql四大类型
包括键值数据库、列族数据库、文档数据库和图数据库。
24.MapReduce工作流程
(1)一个大的MapReuce作业被拆分多个Map任务在多台机器上并行处理,每个Map任务运行在数据存储节点上。
(2)在所有的 Map 任务完成后 , 会生成<key,value>形式的中间结果,被分发至多个Reduce任务在多台机器上并行执行,其中具有相同key的<key,value>被发送至同一个Reduce任务。
(3)Reduce任务对中间结果进行汇总得到结果并输出至分布式文件系统。
25.YARN的部署
(1)ApplicationMaster、NodeManager组件和HDFS中的数据节点部署在一起.
(2)ResourceManager组件和HDFS中的名称节点部署在一起.
(3)数据节点与CPU、内存和网络等资源部署在一起.
26.YARN相比MapReduce1.0的优势
(1)大大减少了承担中心服务功能的ResourceManager的资源消耗.
(2)YARN适用于多种场景,且资源管理高.
27.什么是RDD
◆RDD (Resillient Distributed Dataset)是弹性分布式数据集的简称,Spark的基本计算单元,可以通过一系列算子进行操作,只有遇到Action算子的时候,代码才会真正的被执行。

28.流计算的概念
实时获取来自不同数据源的海量数据,经过实时分析处理,获得有价值的信息。
基本理念: 数据的价值随时间的流逝而降低。(即事件出现立即处理而不是缓存起来再处理)
计算题
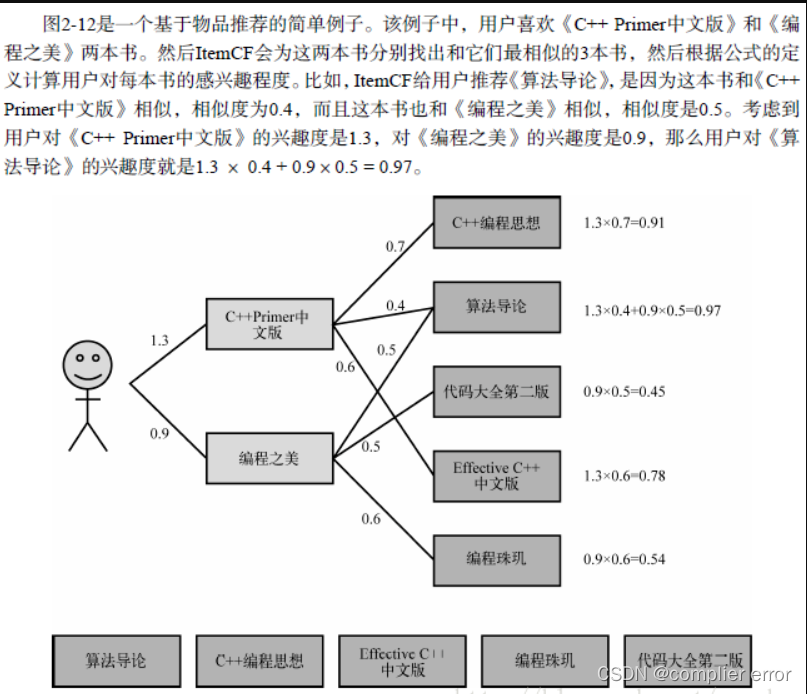
1.推荐系统算法
Item—CF算法流程
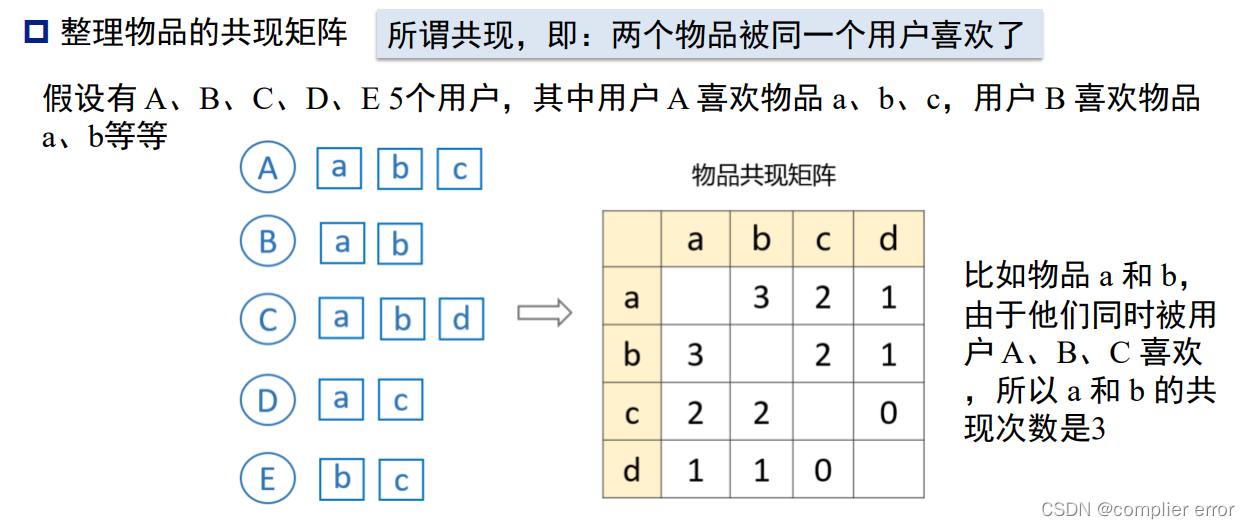
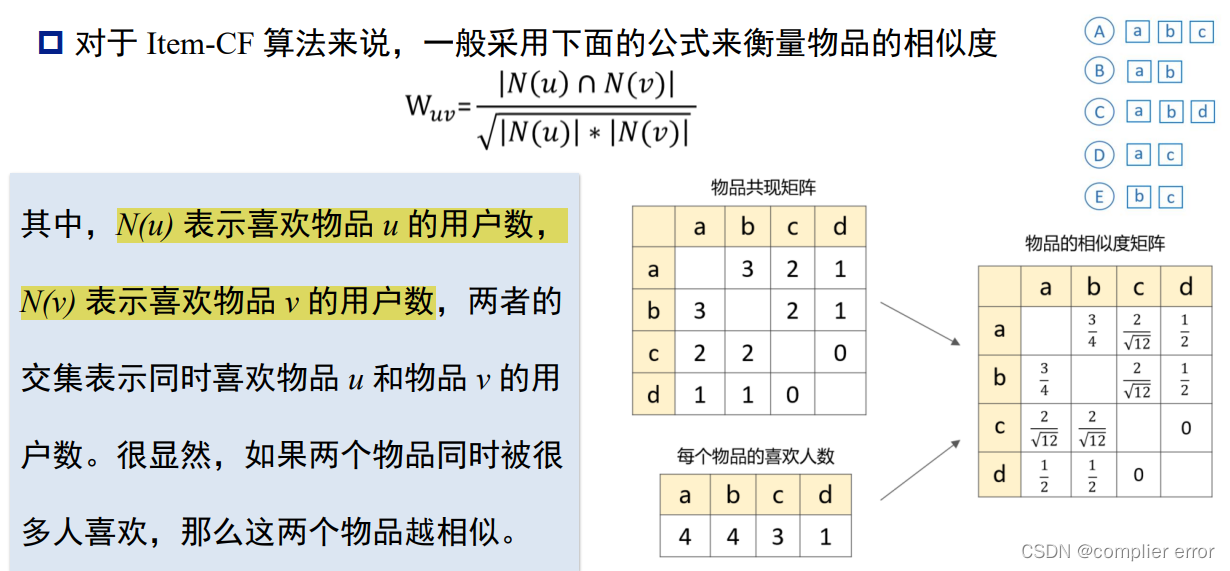
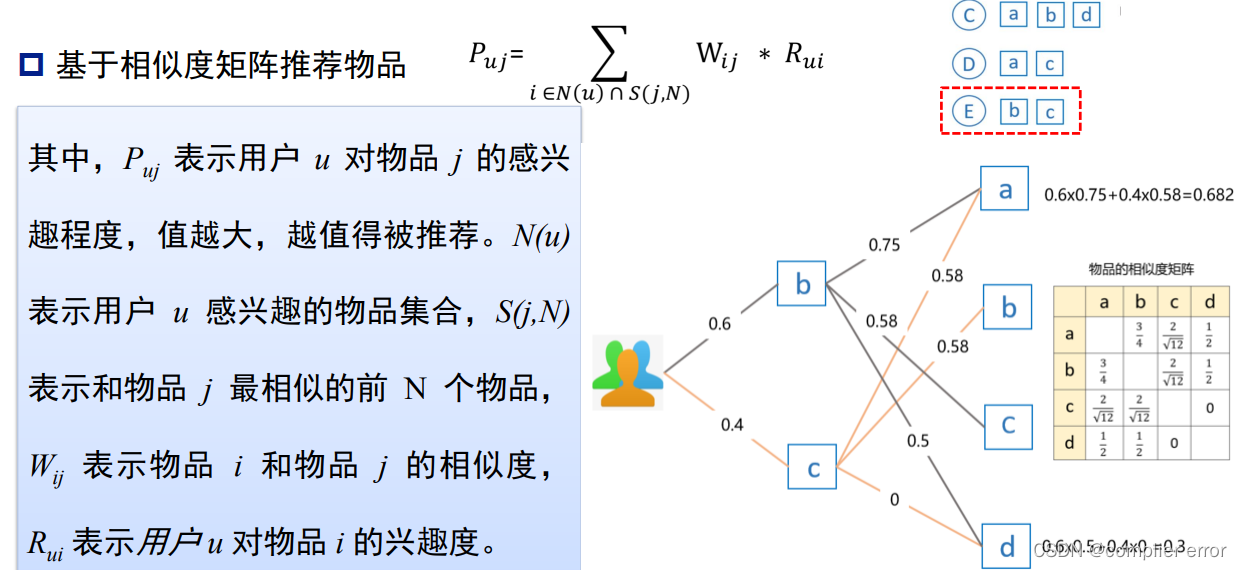
兴趣度的计算:
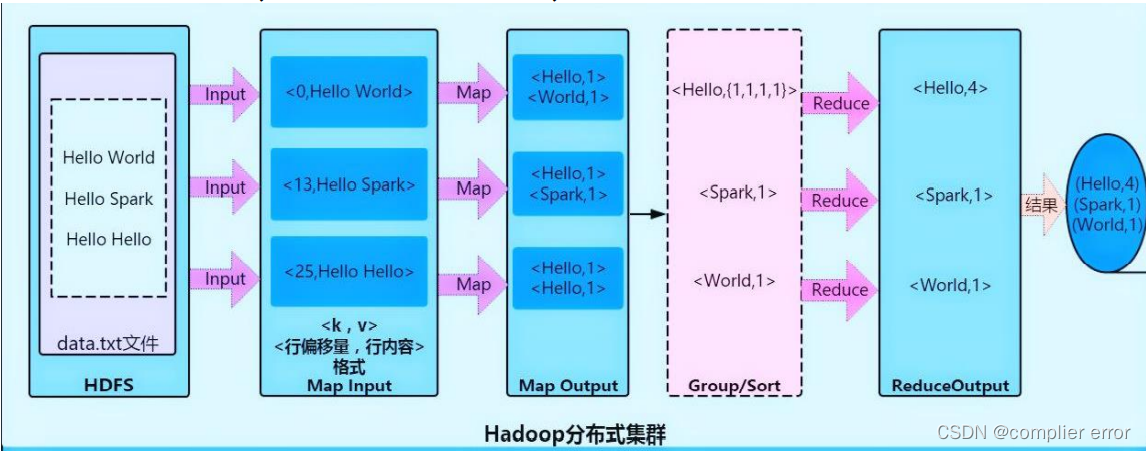
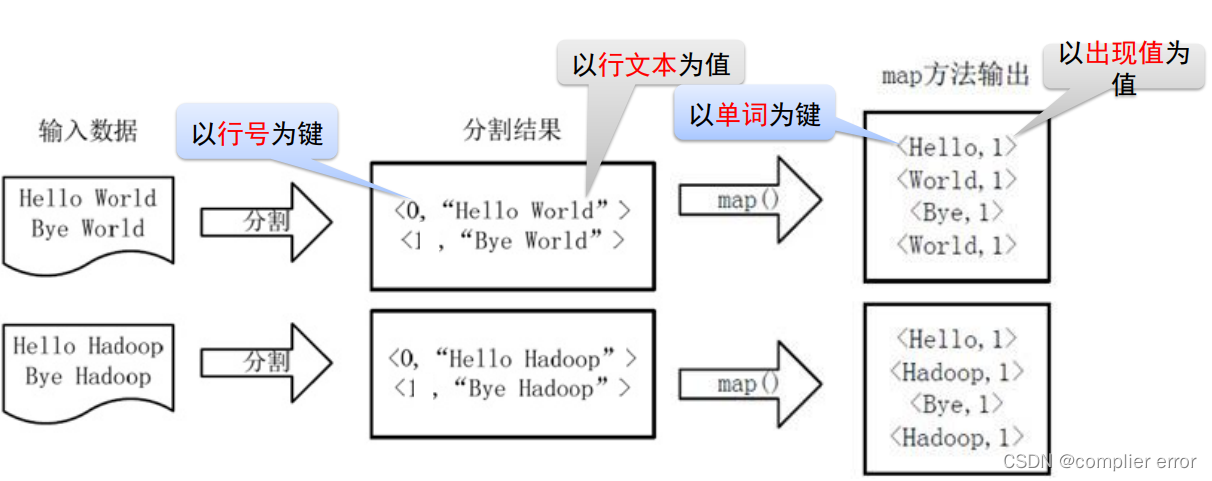
2.MapReduce
确定MapReduce程序的执行过程WordCount设计思路:
以行为单位分配给Map任务算数,Reduce执行汇总
✓ Map阶段:输出<单词,1>形式的中间结果
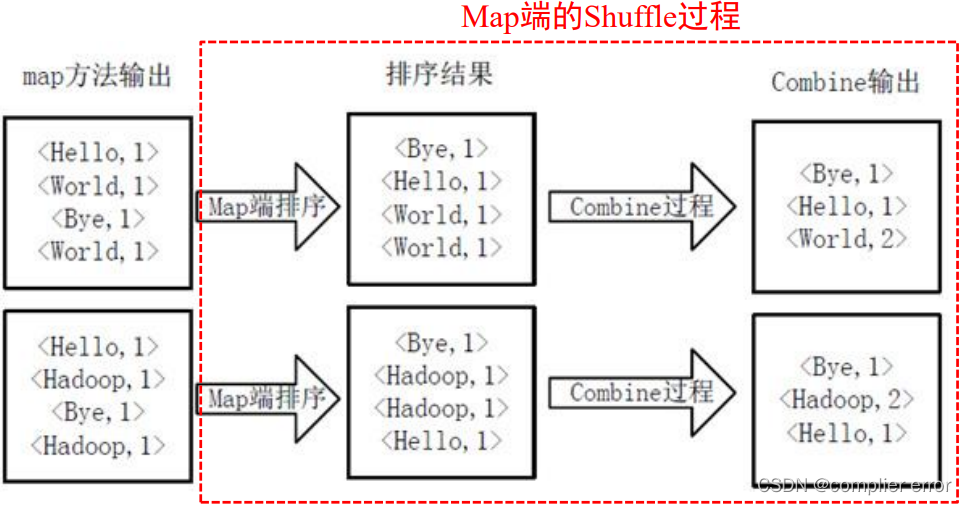
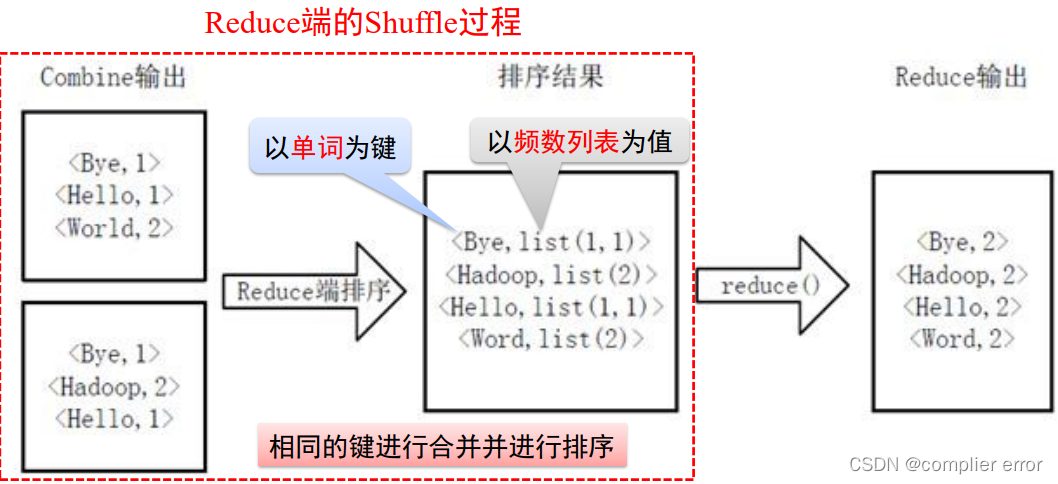
✓ Shuffle阶段:输出<key,valuelist>形式结果,形如<Hadoop,<1,1,1,1>>
✓ Reduce阶段:输出<key,value>形式结果,形如<Hadoop,4>
✓ 输入:key为行号,value为文件行数据
3.spark计算过程
RDD构建: 构建RDD之间的依赖关系,将RDD转换为阶段的有向无环图。
任务调度: 根据空闲计算资源情况进行任务提交,并对任务的运行状态进行监测和处理。
任务计算: 搭建任务运行环境,执行任务并返回任务结果。
Shuffle过程: 两个阶段之间有宽依赖时,需要进行Shuffle操作。
计算结果收集:从每个任务收集并汇总结果。

