
- 1使用 Python 实现网络设备自动化巡检_python巡检百台设备完全无压力
- 2一篇文章搞懂数据仓库:常用ETL工具、方法,2024年最新面试看哪几个方面_数据转换工具 数据仓库
- 3kafka(八):Kafka高可用性_kafka可用性
- 4关于idea 右侧边栏没有database按钮_idea 右侧没有database
- 5Spring Cloud开发微服务项目_springcloud内置tomcat吗
- 6Flink——最流批的大数据框架(流批一体)
- 7本人使用CUBE时遇到的问题,引脚配置时,有些外设引脚出现黄色感叹号..._cubemx黄色感叹号
- 8毕业设计 基于51单片机的智能门禁系统的设计_门禁报警电路怎么连接单片机
- 9淘宝数据可视化大屏案例(Hadoop实验)_hadoop数据分析可视化案例(1)
- 10深入了解PBKDF2:密码学中的关键推导函数_pbkdf2和cpu
扩展学习|一文明晰推荐系统应用开发核心技术发展_基于用户的和基于项目的cf
赞
踩
文献来源:Lu J, Wu D, Mao M, et al. Recommender system application developments: a survey[J]. Decision support systems, 2015, 74: 12-32.
主题:关于推荐系统应用开发的调查研究
关键词:推荐系统、电子服务个性化、电子商务、电子学习、电子政务
本文拟解决的问题有:
1)由于许多应用领域都需要个性化的电子服务,推荐系统是根据实际需求产生的,但现有的推荐系统调查主要集中在推荐理论和方法上。本文从各个应用领域的需求出发对推荐系统进行了调研,对现有的推荐系统调研进行了补充,为行业从业者和研究者提供了有益的指导;
2)从“系统”的角度全面、感性地总结了推荐系统的研究成果,并将推荐系统应用战略性地划分为八个应用领域,为推荐系统的开发提供了框架。
3)针对每个应用领域,仔细分析了典型的推荐系统框架,有效识别了该领域对推荐技术的具体需求。这将直接激励和支持研究者和从业者推动推荐系统在不同领域的普及和应用;
4)揭示了几种非常新的推荐技术,如基于社交网络的推荐技术和基于上下文感知的推荐技术,并揭示了它们的成功应用领域;
5)最重要的是,从推荐方法(如CF)、推荐系统软件(如BizSeeker)、实际应用领域(如电子商务)和应用平台(如基于移动和基于电视的平台)四个维度系统地考察了所报道的推荐系统;
6)它特别提出了推荐系统领域中几个非常创新的新兴研究课题/方向
一、推荐系统
本文将推荐系统的应用分为八个主要领域:电子政务、电子商务、电子商务/电子购物、电子图书馆、电子学习、电子旅游、电子资源服务和电子团体活动。
(一)推荐系统介绍
推荐系统可以被定义为一种程序,它试图根据物品、用户以及物品与用户之间的交互的相关信息,预测用户对物品的兴趣,从而向特定用户(个人或企业)推荐最合适的物品(产品或服务)。开发推荐系统的目的是从海量的数据中检索最相关的信息和服务,从而减少信息过载,从而提供个性化的服务。推荐系统最重要的特征是它能够通过分析用户的行为和/或其他用户的行为来“猜测”用户的偏好和兴趣,从而生成个性化的推荐。
(二)推荐系统的分类
电子服务个性化技术以推荐系统为代表,在过去的20年里得到了广泛的关注。推荐系统的早期研究来源于信息检索和过滤研究,在20世纪90年代中期,研究者开始关注明确依赖于评级结构的推荐问题,推荐系统成为一个独立的研究领域。常用的推荐技术包括协同过滤(CF)、基于内容(CB)和基于知识(KB)技术。每种推荐方法都有优点和局限性;例如,CF存在稀疏性、可扩展性和冷启动问题,而CB存在过度专门化的建议。为了解决这些问题,人们提出了许多高级推荐方法,如基于社交网络的推荐系统、模糊推荐系统、基于上下文感知的推荐系统和群组推荐系统。
(1)基于内容的推荐技术
基于内容(Content-based, CB)的推荐技术会推荐与特定用户之前喜欢的物品相似的文章或商品。CB推荐系统的基本原则是:
1)分析特定用户偏好的物品描述,以确定可用于区分这些物品的主要共同属性(偏好)。这些首选项存储在用户配置文件中。
2)将每个项目的属性与用户配置文件进行比较,以便只推荐与用户配置文件高度相似的项目。
在CB推荐系统中,有两种技术被用来生成推荐。一种技术是使用传统的信息检索方法,如余弦相似度度量,启发式地生成推荐。另一种技术使用统计学习和机器学习方法生成推荐,主要是构建能够从用户的历史数据(训练数据)中学习用户兴趣的模型。
(2)基于协同过滤的推荐技术
基于协同过滤(Collaborative filtering ,CF)的推荐技术帮助人们根据具有相似兴趣的其他人的意见做出选择。CF技术可分为基于用户的CF方法和基于项目的CF方法。在基于用户的CF方法中,用户将收到类似用户喜欢的商品的推荐。在基于物品的CF方法中,用户将收到与他们过去喜欢的物品相似的物品的推荐。用户或项目之间的相似度可以通过基于Pearson相关性的相似度、基于约束Pearson相关性(CPC)的相似度、基于余弦的相似性或者调整后的基于余弦的度量。当使用上述方法计算项目之间的相似性时,只考虑对两个项目都进行了评分的用户。当获得很少评分的项目与其他项目表达高度相似时,这可能会影响相似度的准确性。为了提高相似性准确度,将调整余弦法与Jaccard度量相结合,提出了一种增强的基于项目的相似性分析方法。来计算对于用户之间的相似性,我们使用Jaccard度量作为CPC的加权方案,以获得加权CPC度量。针对基于单一评级方法的缺点,采用多准则协同过滤被开发出来。
(3)基于知识的推荐技术
基于知识的推荐(Knowledge-Based,KB)基于用户、项目和/或他们之间的关系的知识向用户提供项目。通常,知识库推荐保留了一个功能性知识库,描述了特定项目如何满足特定用户的需求,这可以基于对用户需求和可能的推荐之间关系的推断来执行。基于案例的推理是知识库推荐技术的一种常见表达,其中基于案例的推荐系统将项目表示为案例,并通过检索与用户查询或概要最相似的案例来生成推荐。
本体作为一种形式化的知识表示方法,表示领域概念及其之间的关系。它已被用于在推荐系统中表达领域知识。基于领域本体可以计算项目之间的语义相似度。
(4)混合推荐技术
为了获得更高的性能并克服传统推荐技术的缺点,提出了一种混合推荐技术,将两种或多种推荐技术的最佳特征结合为一种混合推荐技术。根据Burke[2]的研究,推荐系统中有七种基本的组合杂交机制:加权、混合、切换、特征组合、特征增强、级联和元级。在现有的混合推荐技术中,最常见的做法是将CF推荐技术与其他推荐技术相结合,以避免冷启动、稀疏性和/或可扩展性问题。
(5)基于计算智能的推荐技术
计算智能(CI)技术包括贝叶斯技术、人工神经网络、聚类技术、遗传算法和模糊集技术。在推荐系统中,这些计算智能技术被广泛用于构建推荐模型。
贝叶斯分类器是一种解决分类问题的概率方法。贝叶斯分类器在基于模型的推荐系统中很受欢迎,并且经常用于导出CB推荐系统的模型。当在推荐系统中实现贝叶斯网络时,每个节点对应一个项目,状态对应每个可能的投票值。在网络中,每个项目都有一组代表其最佳预测器的父项目。分层贝叶斯网络也被引入作为结合CB和CF方法的框架[36]。
人工神经网络(ANN)是由相互连接的节点和加权链路组成的网络受到生物大脑架构的启发,可用于构建基于模型的推荐系统。Hsu等利用人工神经网络构建了一个电视推荐系统,使用反向传播神经网络方法训练了一个三层神经网络。Christakou等人提出了一种结合CB和CF的混合推荐系统,用于生成精确的电影推荐。系统的内容过滤部分是基于一个训练有素的人工神经网络来表示单个用户的偏好。
聚类需要将项目分配到组中,以便同一组中的项目比不同组中的项目更相似。聚类可以用来减少寻找k个最近邻居的计算成本,例如文献Xue等人提出了聚类在推荐系统中的典型应用。他们的方法使用聚类来平滑单个用户的未评级数据。通过使用一组密切相关的用户的评分信息,可以预测组中单个用户的未评级项目。此外,假设最近的邻居也应该在与活动用户最相似的T top N集群中,则只需要选择T top N集群中最近的邻居,这使得系统具有可伸缩性。聚类技术也被用于通过分组项目来解决推荐系统中的冷启动问题。Ghazanfar和pr gel- bennett[41]使用聚类算法来识别和解决灰羊用户问题。
遗传算法(GA)是一种随机搜索技术,适用于目标函数受硬约束和软约束的参数优化问题。它们主要用于推荐系统[43]的两个方面:聚类和混合用户模型。例如,基于ga的K-means聚类被应用于个性化推荐系统的真实在线购物市场细分案例中,从而提高了细分性能。文献中提出了一种获取最优相似函数的遗传算法方法。结果表明,所得到的相似度函数比传统度量提供的结果质量更好,速度更快。
模糊集理论为非随机不确定性的管理提供了丰富的方法。它非常适合处理不精确的信息,对象或情况类别的不清晰,以及偏好概况的渐变。例如:一个项目的特性或属性的值是与该特性相关的断言子集上的模糊集。用户的有意偏好表示为基本偏好模块,该模块是可以评估项目的组件的有序加权平均。用户的扩展偏好表示为用户经验项的模糊集,其隶属度是评级。根据这种表示,可以推断出用户对某项的偏好。
(6)基于社交网络的推荐技术
近年来,随着基于web的系统中社交网络工具的迅猛发展,社交网络分析(SNA)已被广泛应用于推荐系统中。为了帮助改善用户体验,推荐系统越来越多地为用户提供与其他用户进行社交互动的能力,例如在线交友、发表社交评论、社交标签等。这些趋势为利用用户的社会关系进行推荐提供了机会,特别是对于评级数据过于稀疏而无法进行协同过滤的系统。“信任”是社会网络研究中被广泛讨论的关系。考虑到在现实世界中,一个人的购买决定更有可能受到朋友的建议而不是网站广告的影响,如果用户的社交网络存在于推荐系统中,它可能是一个重要的来源。
同样,由于标准CF方法无法在稀疏数据集中找到足够的相似邻居,用户的社会关系正在成为推荐系统的另一个改进方面。信任代表了对其他用户的直觉意见。在推荐系统中,“信任”一词通常被定义为“关于特定的产品或味道,Alice对Bob的信任程度有多高”。Golbeck提出了一种系统算法TidalTrust来解决基于信任的评级预测问题,该算法被认为在多个系统的数字信任网络形成过程中是有效的。Ben-Shimon等[51]使用广度优先搜索算法构建活跃用户的个人社交树,然后计算活跃用户与其他人之间的距离,这可以看作是信任的反映,作为最终的评级预测权重。
(7)基于上下文感知的推荐技术
被引用最多的上下文定义之一是Dey等人的定义,该定义将上下文定义为“可用于表征实体情况的任何信息”。实体可以是与用户和应用程序(包括用户和应用程序本身)之间的交互相关的人、地点或对象。”上下文信息,如时间、几何信息或其他人(例如朋友、家人或同事)的陪伴,最近在现有的推荐系统中被考虑;例如,随着手机使用的快速增长所获得的信息[63]。上下文信息为推荐提供了额外的信息,特别是对于一些仅考虑用户和项目是不够的应用程序,例如推荐度假包或网站上的个性化内容。在推荐过程中结合上下文信息也很重要,以便能够在特定情况下向用户推荐项目。
在Adomavicius和Tuzhilin的综述中,推荐系统领域的语境是一个跨多个学科使用的多面概念,每个学科采用一定的角度,并在这个概念上打上自己的“印记”。有了上下文感知,评分函数不再是一个二维函数(R: User × Item→rating),而是一个多维函数(R: User × Item × context→rating),其中User和Item分别是用户和项目的域,rating是评级的域,context指定与应用相关的上下文信息。为了将上下文信息整合到推荐系统中,Adomavicius和Tuzhilin提出了一个三步流程,使这些信息可计算且有价值:上下文预过滤(contextual Pre-Filtering)、上下文后过滤(contextual Post-Filtering)和上下文建模(contextual Modeling)。通过处理这三个步骤,系统可以检测出对提出建议有用且可兼容的上下文信息。
(8)群体推荐系统(Group recommender system, GRS)
群体推荐系统(Group recommender system, GRS)被提出,用于当群体成员无法聚集在一起进行面对面协商,或者尽管彼此见面,但偏好不明确时,产生一组用户建议。GRS也被称为e-group活动推荐系统,已经应用于许多领域,包括电影、音乐、网页、事件和复杂的问题,如旅行计划。在社会选择理论和决策过程的启发下,许多策略被用于将所有成员聚集到一个群体中。Masthoff总结了在GRS中最常见的11种策略,包括最少痛苦、平均、最多快乐及其适应。除了聚合方法外,GRS还涉及异步和同步通信,以支持多用户。
二、电子政务推荐系统
电子政府(e-government)是指利用互联网和其他信息通信技术来支持政府向公民和企业提供改进的信息和服务。电子政务的快速发展造成了信息超载,使企业和公民无法从他们所暴露的大量信息中做出有效的选择。这种信息过载的增加显然会妨碍电子政务服务的有效性,而为正确的用户找到正确的信息的困难将日益影响用户的忠诚度。推荐系统可以克服这一问题,并已在电子政务应用中采用。在本节中,我们将回顾电子政务推荐系统的发展和应用,特别是电子政务Web界面的个性化和适应以及电子政务服务推荐,其中包括政府对公民(G2C)和政府对企业(G2B)服务。
(一)G2C业务推荐
为了支持公民获得公共行政办公室提供的个性化和适应性服务,De Meo等人提出了一个多智能体系统。所提出的系统通过考虑用户的配置文件和正在使用的设备的配置文件来识别并建议用户最感兴趣的服务。为了帮助选民在电子选举过程中做出决策,提出了一种推荐系统,该系统使用模糊聚类方法,提供接近选民偏好的候选人信息。
该系统可以在任何地点和任何时间使用,从而节省了差旅和人员成本。它是非常用户友好的,设计的个人与最低的技能和使用模糊语言建模,以提高用户偏好的表示和促进用户-系统交互。TPLUFIB-WEB符合健康网络基金会(HON)、巴塞罗那官方医师学院和安达卢西亚地区政府健康质量机构提出的网络质量标准,认可所提供的健康信息并保证用户的信任。
(二)G2B服务推荐
在G2B服务中,从业务角度来看,许多项目都是一次性项目,例如事件,通常只有在结束后才会收到评级。由于评级数据稀疏,传统的CF技术无法推荐这类项目。为了解决这个问题,Guo和Lu[74]提出了一种新的方法,通过将语义相似度技术与传统的基于项目的CF相结合,来处理属性考虑的推荐问题。一个名为智能贸易展览查找器(STEF)的推荐系统已经开发出来,它可以向企业推荐合适的贸易展览。为了灵活反映G2B领域的分级/不确定信息,Cornelis等[78]将用户和物品相似度建模为模糊关系。
在选择业务伙伴的过程中,信任或声誉信息是至关重要的,对业务用户决定是否与其他业务实体开展业务具有重要影响。提出了一种混合信任增强CF推荐(TeCF)方法,该方法集成了隐式信任过滤和增强的基于用户的CF方法,以缓解稀疏性和冷启动用户问题,并获得更好的准确性。
在上述STEF、BizSeeker和Smart BizSeeker推荐系统中,除了传统的CF和CB技术外,还采用了本体、语义Web、agent和模糊技术,形成了一套混合推荐方法,以提高个性化的电子政务服务性能。
三、电子商务推荐系统(B2B)
一般来说,一些系统侧重于向个人客户生成推荐,这是企业对消费者(B2C)系统,而另一些系统旨在向企业用户提供关于产品和服务的推荐,这是企业对企业(B2B)系统。在本研究中,电子商务推荐系统是指B2B应用程序的推荐系统。电子商务/电子购物推荐系统是指B2C应用的推荐系统。在本节中,将回顾B2B(电子商务)推荐系统。电子商务/电子购物推荐系统将在下一节进行讨论。
为了帮助B2B市场中的目录管理员维护最新的产品数据库,提出了一种基于本体的产品推荐系统,其中使用基于关键字的本体和贝叶斯信念网络技术来生成推荐。为了帮助商业用户选择值得信赖的在线拍卖卖家,设计了一个推荐系统,其中使用交易关系来计算推荐级别。推荐系统也应用于数字生态系统中,其中代理代表许多小公司协商服务。
在电子商务推荐系统中,知识库方法(如本体和语义技术)与CF和CB推荐方法广泛集成。这样做的主要原因是电子商务对领域知识有很高的需求,以协助他们的推荐。
四、电子商务/网购推荐系统(B2C)
在过去的几年里,一些独特的电子购物推荐系统已经被开发出来,为在线个人客户提供指导。电子购物是电子商务的一个专业和高度流行的领域。评级是电子购物系统中常见的功能,尤其是电子产品。例如,在itunes商店中,顾客可以通过为购买的物品(曲目或专辑)分配1到5之间的值来提供反馈。这些评级数据随后可用于提出建议。标记是连接用户-项目数据的另一种方法。例如,电影评论网站Movielens的用户可以通过使用简单的单词自由地为电影分配标签。相应地,CF和社会标签分析是这类系统中单独使用或与评级和标签共同使用来提高推荐性能的两种有效技术。许多大型商务网站,如亚马逊和eBay,已经使用推荐系统来帮助他们的客户找到要购买的产品。在这些B2C电子商务网站中,可以根据最畅销的卖家、客户统计数据或对过去购买的分析来推荐产品.
综上所述,电子购物推荐系统(基于网络和基于手机的)通常用于在线购买数字产品(音乐、电影等)和实体产品(书籍、包包等)。从应用的角度来看,研究人员已经开发了一些成功的电子购物系统,其中采用了他们的新算法。这些系统为开发人员提供了如何实际实现电子购物推荐系统的指导方针。
五、电子图书馆推荐系统
数字图书馆是数字对象的集合,以及向用户社区提供的相关服务。推荐系统可用于数字图书馆应用程序,以帮助用户定位和选择信息和知识来源。在本节中,我们将对电子图书馆推荐系统进行回顾。CYCLADES Fab的主页是斯坦福大学数字图书馆项目的一部分,它是一种结合了CB和CF两种推荐技术的混合型推荐系统。为了提供更好的个性化电子图书馆服务,随后提出了一个名为CYCLADES (http://www.ercim.org/cyclades)的系统。推荐算法以个性化信息组织和用户意见为基础,分别使用CB和CF方法,并将两者结合使用。
在上述讨论的电子图书馆推荐系统中,结合CB、CF和/或KB技术的混合推荐方法被广泛使用。使用混合方法的一个原因是,它们利用了几种不同推荐技术的优点。模糊技术,特别是多颗粒模糊语言建模,被用来表示和处理语言标签的柔性信息。
六、电子学习推荐系统
自21世纪初以来,基于传统电子学习系统的发展,电子学习推荐系统在教育机构中越来越受欢迎。这种类型的推荐系统通常旨在帮助学习者选择他们感兴趣的课程、科目和学习材料,以及他们的学习活动(如课堂讲座或在线学习小组讨论)。在十多年的研究积累中,已经开发出许多实用的电子学习推荐系统。
Zaiane提出了一种构建软件代理的方法,该方法使用关联规则挖掘等数据挖掘技术来构建表示在线用户行为的模型,并使用该模型来建议活动或捷径。生成的建议通过使用推荐的快捷方式更快地找到相关资源,帮助学习者更好地浏览在线材料。Web使用挖掘是将数据挖掘技术应用于发现基于Web点击流数据的行为模式的过程,它提供了帮助理解用户偏好的信息。
从上述综述中可以明显看出,知识库教学规则在电子学习推荐系统中比在其他推荐系统中发挥更重要的作用,因为此类推荐系统通常缺乏CF或CB算法的足够历史数据集。电子学习推荐系统的架构通常包括三个部分:1)利用Web分析技术收集学习者的个人资料,识别学习者的个性化需求;2)收集学习目标元数据,识别特征;3)获取相关的教学知识,评价学习者与学习目标的匹配程度。值得一提的是,在匹配过程中还采用了一些先进的技术来提高系统的性能。
七、电子旅游推荐系统
互联网和移动设备为游客提供了大量获取旅游信息的机会,但可供旅游选择的数量急剧增加,使游客难以选择自己喜欢的旅游选择。电子旅游推荐系统旨在为游客提供建议。一些系统专注于景点和目的地,而其他系统则提供包括交通、餐饮和住宿在内的旅游计划。有几个餐厅推荐系统。例如,Burke等[111]提出了一种基于知识库方法的餐厅推荐系统entracei。entracei从用户那里收集信息,并通过精炼价格和口味等搜索标准来检索类似的选择。
个性化观光规划系统(personal sightseeing planning system, psi)是在葡萄牙波尔图市开发的,用于帮助游客找到个性化的旅游计划[115]。针对当前推荐系统存在的可扩展性、稀疏性、一等性和灰羊问题等缺点,提出了一种混合推荐方法。提出的混合推荐方法采用CF和CB方法,结合聚类技术和关联分类算法,并利用模糊逻辑提高推荐质量。
八、电子资源服务推荐系统
这里所说的电子资源是指用户上传的视频、音乐和文档等内容。一些推荐系统用户将资源共享到互联网上,以便其他用户可以访问他们感兴趣的资源。本节重点介绍推荐系统在资源服务中的几个典型应用:标签推荐、电视节目推荐、网页推荐、文档推荐、视频推荐和电影推荐。
(一)标签推荐
标签是用户对上传至Internet的资源进行标记和管理的任意文字。
用户希望标签具有个性化和便捷性,以便于资源的共享,但是用户往往很难从众多的可能性中选择合适的标签。因此,标签推荐系统对于使标签选择变得简单和个性化变得越来越重要。包含标签推荐系统的大众分类法是基于web的系统,它允许用户上传他们的资源(例如,文档、图片),并用标签对它们进行标记。大众分类法可以看作是由资源、用户和标签组成的三部分系统。Zheng和Li[124]实现了基于CF的民俗分类法推荐系统,他们在推荐过程中利用了标签效应和时间效应。与传统CF中使用评级矩阵不同,他们建立了基于标签和时间关系的矩阵。采用标签权、时间权和混合三种策略,根据相应的矩阵计算相似度。这些建议是由邻居们根据新的相似性来预测的。
(二)电视节目推荐
电视节目可以看作是广播公司释放的一种特殊资源。近年来,由于交互式和双向电视的发展,电视频道和节目的数量大幅增加。即使有电子节目指南,观众也很难从成百上千的节目中找到有趣的节目。为了帮助观众选择自己感兴趣的节目,需要节目推荐系统(PRS)。电视节目的内容信息可以通过特征来描述(例如,类型、演员),因此通常使用CB方法;当电视模式允许用户给出反馈(例如,评级)时,CF方法得到了很好的应用。
(三)网页、新闻、文献推荐
推荐网页、文档和新闻是推荐系统的传统领域,因为这些资源增长迅速。在大多数情况下,新闻、电子邮件、文档和网页等文本内容被描述为关键字列表,可以从历史数据、url和搜索引擎中提取,许多推荐系统都是在分析关键字的基础上设计的。概率模型,如信息检索技术,在这一领域是常见的。上下文资源被转换为一个向量,每个元素代表一个关键字,该关键字考虑了频率和位置(标题或纯文本)。
这些建议是通过检索与用户模式相似的资源生成的。例如,AMALTHAEA通过检查热门列表和浏览历史从url中提取关键字,并通过信息检索(IR)调查用户所显示的兴趣。ifW web采用CB方法来度量页面之间的相似性。如果系统能够收集用户是否通过评分来评价内容的信息,那么CF是可行的。例如新闻推荐系统News Dude使用CF对用户的短期兴趣进行建模。在Eigentaste中,采用主成分分析来推导关键词矩阵的维数,以加快用户聚类和推荐计算的过程。
除了从文本内容中提取关键字外,还考虑了用户的隐式和显式反馈。Lifestyle Finder使用人口统计信息对用户建模并提供网页推荐。ACR新闻向量是基于网页的隐式反馈和观看频率构建的(见图1)。然后训练聚类模型,并通过CB方法在相关聚类上推荐页面。在另一个网页推荐系统ArgueNet中,用户可以处理网站的可信度等标准。用户偏好通过关键字和这些标准进行建模,以生成个性化的推荐。

(四)推荐电影、视频和音乐
近年来,随着移动设备的广泛使用,电影、视频和音乐资源的增长尤为迅速。然而,当用户在移动设备上搜索他们感兴趣的内容时,他们会感到沮丧。为了解决这个问题,许多电影推荐系统音乐推荐系统已经被开发出来。因为这些系统中的大多数都允许用户对资源进行评级,所以CF推荐方法在这21个推荐系统中被广泛使用。在一些系统中,如Flycasting,用户不能直接对音乐进行评分,因此该系统首先将历史收听信息转换为评分,然后进行CF。为了解决CF方法的冷启动和稀疏性问题,在一些系统中加入了CB方法。例如,Melville等利用CB克服了稀疏性和一流性问题。
电影和音乐推荐系统的一个特点是不容易从多媒体资源中获取内容和导航历史。这些资源包含艺术家和类型等特征,如何提取潜在的相关性是这一领域的一个重要问题。基于模型的方法,如语义分析和社会网络也集成到CF中。RACOFI利用语义网技术。CoFoSIM是一个移动音乐推荐系统,它利用多标准决策(multi-criteria decision-making, MCDM)技术分析隐式反馈和部分听音记录,并将它们聚合成一个组合偏好。音乐推荐系统的一个有趣的方面是,一些系统使用隐式反馈来增强或取代用户的显式评分。例如,CoFoSIM[153]和Smart Radio[149]都使用收听历史来推断其用户评级。
通常,这些资源服务推荐系统的目标是组织和管理这种类型的Web服务内容,并使用户不必执行繁琐的搜索。在标签领域,CF方法是主流的推荐技术。对于电视节目,将贝叶斯分类器、决策树、语义分析等智能技术与CF和CB方法相结合,实现推荐系统。推荐上下文内容(如网页和文档)是CB和CF方法的传统应用领域,此外还使用了基于内存的方法和基于模型的方法(如贝叶斯和聚类技术)。社交和情境感知技术在电影和音乐推荐中与传统的CB和CF一起发挥着越来越重要的作用。
十、e群活动推荐系统
在一些场景中(例如,向一群人推荐一个电视节目),用户无法明确地指定他们的偏好,在一些场景中(例如,与他人一起旅游),用户需要在线协商以共同参与活动。在这些情况下,人们需要整个群体的在线决策支持。传统的推荐系统只对个体用户提供建议,因此提出了群体推荐系统(group recommender system, GRS)来结合和平衡群体成员的个体期望,为群体提供满意的推荐。GRS主要有两种类型:一种称为离线GRS,用于已经形成的群体(例如家庭),另一种称为在线GRS,用于需要由系统形成的群体。GRS在这两种类型中都有实际应用。我们在下面总结了四个主要领域。
(一)为团体推荐书籍、文件和网页
许多GRS被设计用来推荐书籍、文件和网页。利用信息检索、贝叶斯和用户-物品矩阵等基于概率的模型来描述物品并表示物品与用户之间的关系。I-SPY是一个向志同道合的用户社区推荐资源的搜索引擎。系统维护一个命中矩阵,连接用户和查询社区,并在用户访问搜索结果时更新矩阵。矩阵更新后,相关资源重新排序,社区内的其他用户可以获得更准确的结果。除了效用外,GRS还考虑了满意度和公平性等22项要求。为了增加浏览活动,Sharon等人提出了一种中介,基于上下文代理的系统(CAPS),用于收集页面的频率和停留时间,它可以作为浏览器的代理,而不需要用户主动输入数据。为一组协作成员和页面排名构建的存储库是为了增强其他成员的浏览和搜索活动。
(二)为团体推荐电影和音乐
有些音乐推荐系统自动向用户播放音乐,无需用户选择;这些被称为基于无线电的推荐系统。例如,MusicFX是一个向健身房所有人推荐音乐的GRS,会员的偏好存储在系统中,根据个人偏好生成推荐音乐,供会员播放,无需进一步选择。PolyLens从MovieLens扩展而来,支持群组创建和管理,是为相对较小的群组推荐电影而设计的。它考虑了群体的性质、群体的形成和演化、隐私、群体推荐的产生和接口。PolyLens通过最近邻方法合并为个人用户生成的推荐,并根据电影的最低评级对合并列表进行排序;因此,它可以为个人和团体提供更多的信息。可以收集用户和项目的特征来衡量多媒体资源与用户之间的相关性,从而生成高度精确的群组推荐。来自领域的知识也被整合到推荐技术中。
(三)团体旅游建议
旅游GRS中经常向团体推荐景点、住宿和餐厅,并利用其特点形成团体推荐列表。Pocket Restaurant Finder是一种为一群人定位餐厅的GRS。每个成员都提出了自己的意见,规定了距离、价格等条件。该GRS建立了一个群体偏好模型,并根据该模型对每个餐厅进行评价。最后的建议以清单的形式提出。CB方法主要用于产生个人偏好。
(四)群体电视节目推荐
电视节目推荐(TPR)已经发展起来,它不仅对个人个性化很重要,而且对群体适应也很重要,比如当家庭成员一起看节目时。使TPR与其他基于web的群组推荐系统不同的一个挑战是,很难识别群组中的成员,因为群组可能是动态的,成员可以随时加入和离开群组。在报道的家庭互动电视系统(FIT)中,观众根据他们的刻板印象和每种类型的首选观看时间的概率进行建模。根据组合概率推荐方案。另一个系统TV4M通过提供登录功能来识别成员。通过最小化特征距离来聚合首选项。
群推荐系统可以被看作是利用个人推荐技术来生成个人偏好或建议,然后使用聚合方法将它们组合起来。从这个角度来看,在GRS中可以采用任何个体推荐技术。GRS不同于单个推荐系统的特殊方法是聚合方法。另一个有趣的方面是对组成员如何沟通进行建模。对于上下文内容、音乐和电影推荐,异步通信被广泛采用。对于电视推荐,可以离线协商。对于旅游推荐,当团队成员希望保证旅游质量时,采用同步沟通。
十一、综合分析、发现和新兴研究课题
(一)推介系统及其应用总结
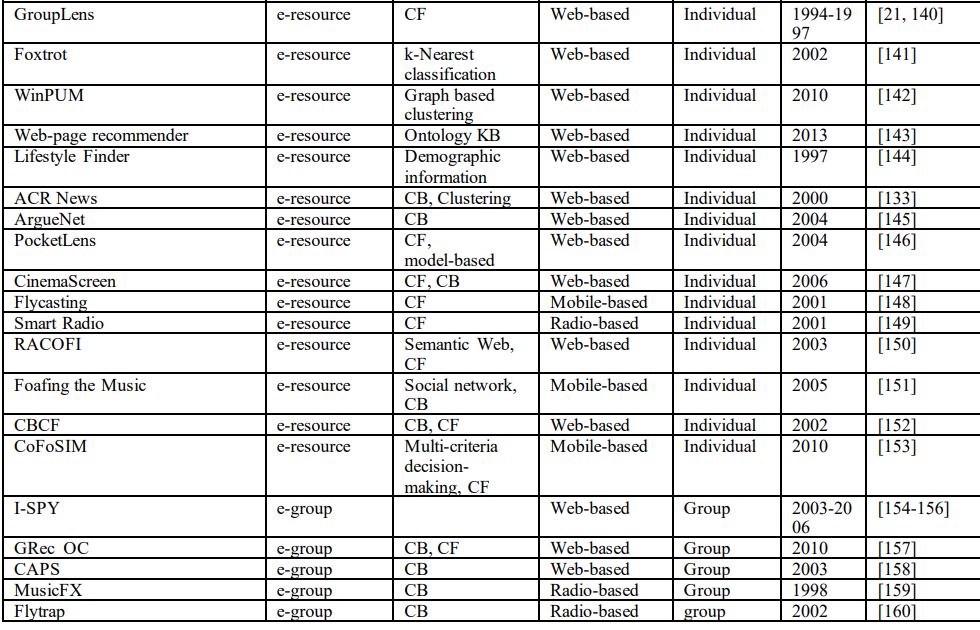
本节总结了上述推荐系统及其应用。对于每个应用领域,审查的推荐系统的数量和系统中使用的推荐技术被总结并呈现在表1中。从推荐系统的总结中,可以提取出以下重要发现:
1)经典的推荐方法,如CF、CB和KB,在近25种应用中仍然占据主导地位,但混合推荐系统比基于单一推荐技术的系统更受欢迎,因为它避免了单个推荐方法的缺点;
2)在8个主要推荐系统应用领域中,电子资源推荐系统被报道最多,面向个人用户的推荐系统占多数;
3)与其他领域相比,电子学习推荐系统大量采用基于知识的推荐方法,而电子资源推荐系统更多采用CF方法;
4)一些新的推荐技术,如基于社交网络的推荐系统和基于上下文感知的推荐系统,在最近的应用发展中发挥了越来越重要的作用;
5)模糊逻辑等计算智能技术已被应用于各种推荐系统的应用领域,以处理各种不确定性。本研究报告了27个使用各种计算智能技术的成功推荐系统;
6)推荐系统的一些新的应用平台(不是传统的基于web的平台),如手机、电视和广播平台,是最近才出现的。本文列举了10个最新的基于手机的推荐系统、9个基于电视的推荐系统和4个基于广播的推荐系统。所审查的每个推荐系统的详细信息,包括其应用领域、应用的推荐技术、应用平台、用户类型和使用周期,列的表1。
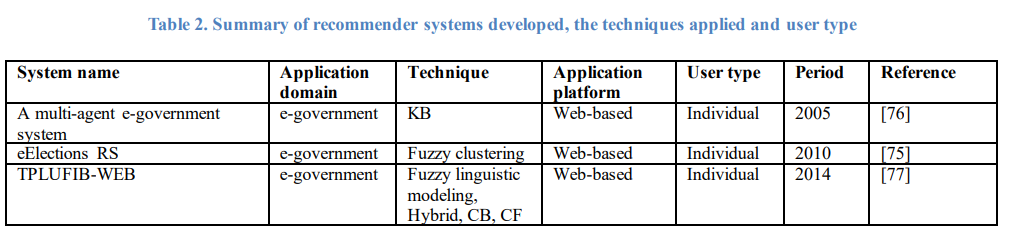
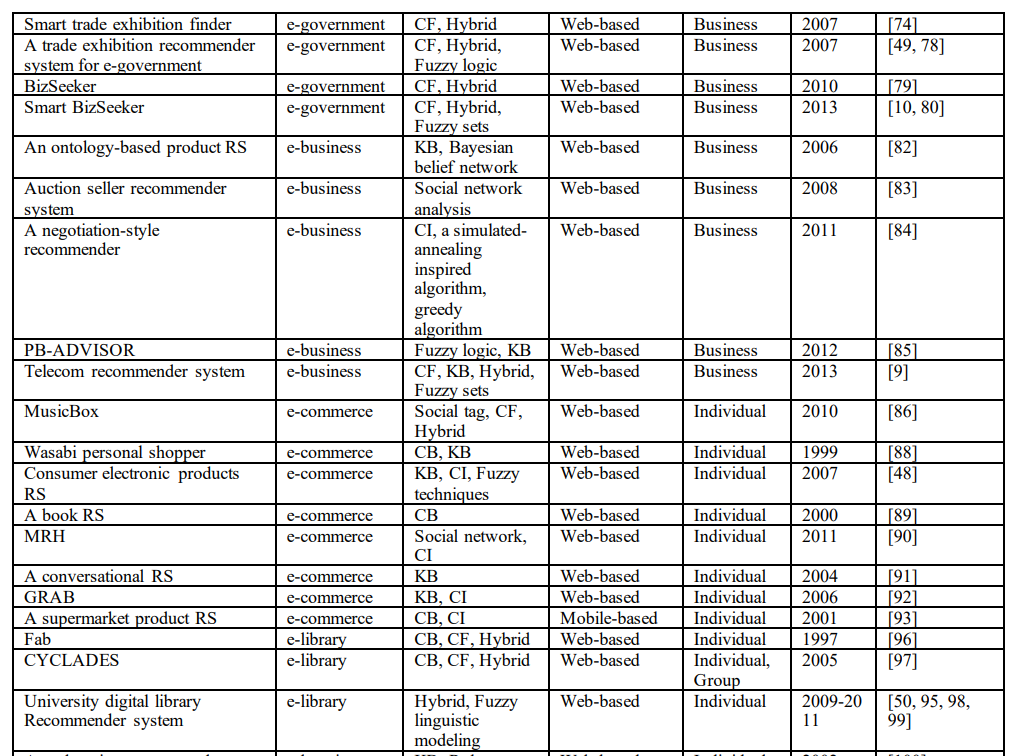
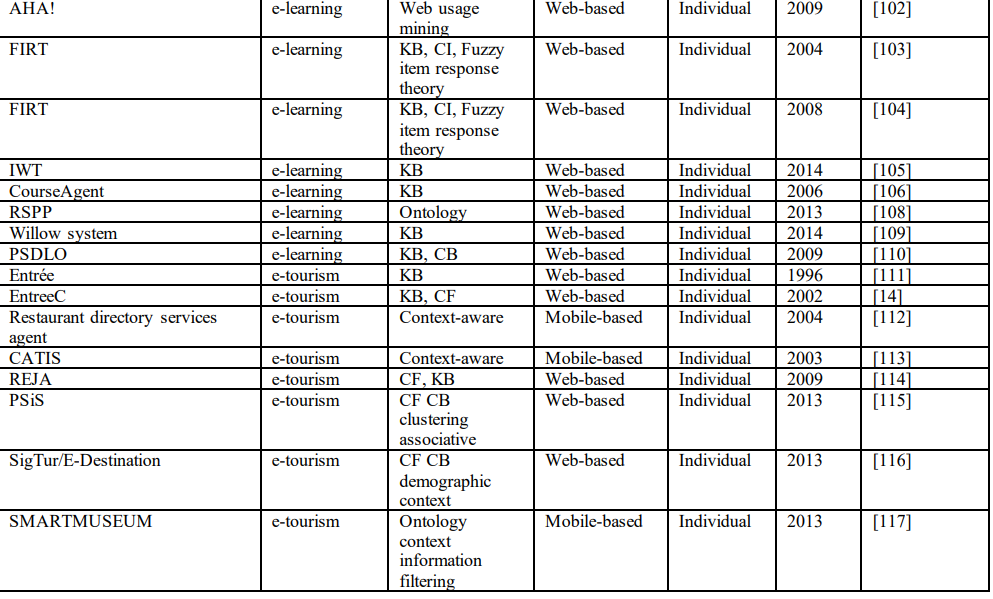
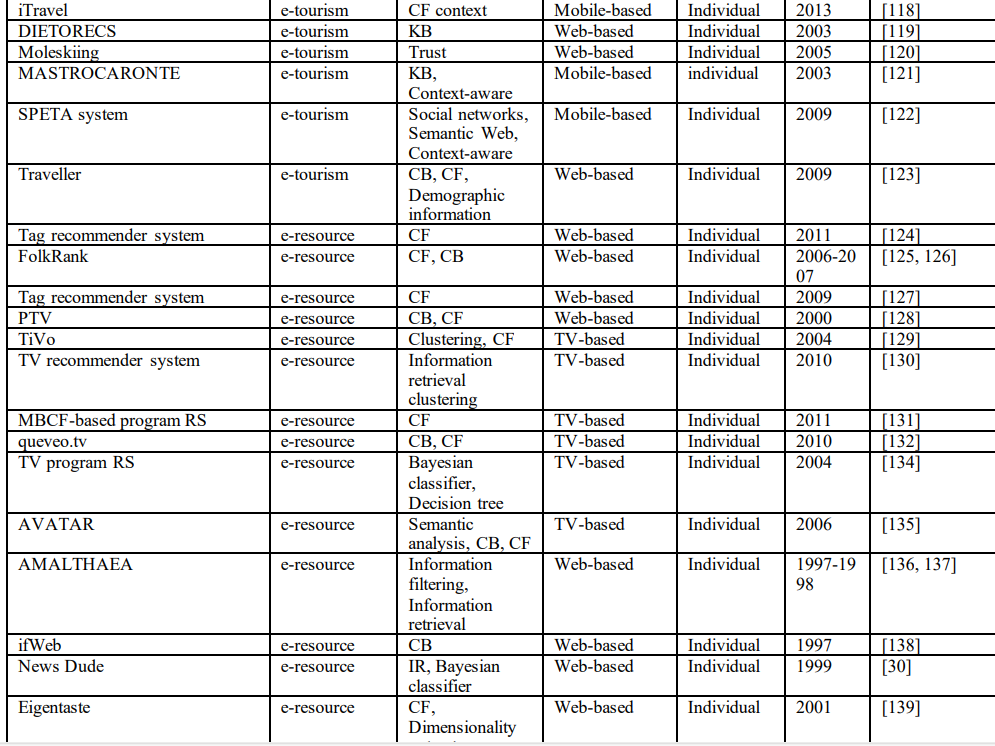

(二)可能待研究的地方
尽管推荐系统的应用已经取得了很大的发展,但随着新的电子服务应用的出现,仍有一些问题需要进一步研究。
1)随着智能手机上网的日益普及,向移动用户提供个性化、情境化的推荐已经成为可能,需要更多的移动推荐系统。然而,移动数据通常更为复杂,具有异质性和噪声,需要时空自相关,并且存在验证和通用性问题。进一步研究基于移动设备的上下文敏感推荐是一个重要的课题。
2)继电子商务之后,电子政务的进一步发展促进了电子政务推荐系统的应用。电子政务通常提供非营利性的公益性服务,这与电子商务领域有很大不同:用户通常基于对政府的信任来选择电子政务服务;有些服务关系到个人和社会的安全。这些因素在未来的电子政务推荐系统研究中还没有被考虑到。
3)在电子旅游或电子购物应用领域,用户更喜欢实时、定位和细粒度的推荐。例如,购物中心的用户希望根据地点和时间获得商店和产品的实时和细粒度推荐。为了满足这些需求,需要进一步研究基于实时上下文感知的推荐方法。
4)在电子购物或电子学习应用领域,数据的分布是不断变化的,例如用户的行为,他们的兴趣/偏好以及某些物品的功能。使用过时的数据来预测用户当前的偏好会导致性能不佳。应该将概念漂移技术引入推荐系统,以模拟用户的偏好漂移,并在快速变化的环境中提高推荐性能。这将是一个新兴的研究课题。
5)尽管针对推荐系统中的数据稀疏性问题已经做了很多研究,但在很多应用领域中,这个问题仍然没有得到很好的解决。迁移学习技术可以将其他领域的相关数据合并到目标领域,为处理这一问题提供了很好的机会。因此,基于迁移学习的推荐系统将是另一个重要的发展方向。
6)推荐系统所采用的推荐方法受到系统信息源的限制。在大数据时代,可以获得众多维度的数据,这有助于更准确、更全面地建模用户的偏好。通过有效和高效地利用大数据,有望开发出更多的推荐系统应用。例如,智能可穿戴设备的发展可以提取更多的人的信息,这些信息可以用于健康和医疗应用领域,从而产生健康推荐系统。
参考引用
[1]B. Sarwar, G. Karypis, J. Konstan, J. Riedl, Item-based collaborative filtering recommendation algorithms, Proceedings of the 10th International Conference on World Wide Web, ACM, 2001, pp. 285 -295.
[2] R. Burke, Hybrid web recommender systems, in: P. Brusilovsky, A. Kobsa, W. Nejdl (Eds.) The Adaptive Web, Springer-Verlag, Berlin Heidelberg2007, pp. 377-408.
[3]
[4]

