
- 1JavaWeb+Vue3前后端分离项目使用JWT技术_vue 3.0使用jwt
- 2找不着工作怎么办?以下六条一定要听我说。_今年找不到工作怎么办
- 3蓝易云 - 在Linux(CentOS和AWS)上安装更新的git2的方法并配置github-ssh
- 4【MindSpore报错解决地图】常见报错问题分类(持续更新)_mindspore eof buffer encountered.
- 5微信小程序基础学习(WXSS+组件)_text-stroke 小程序
- 6使用自己训练的yolov3或yolov4模型自动标注成voc格式数据_yolov4标注格式
- 7AndroidStudio打包APK文件发生 (Error:Unknown host ‘dl.google.com‘. You may need to adjust the proxy setting
- 8Linux && Windows Git 工具 配置Gerrit代码下载上传_windows通过git从gerrit服务器上下代码
- 9Hinton揭秘Ilya成长历程:Scaling Law是他学生时代就有的直觉
- 10Kubernetes(k8s)基础入门_kubernetes入门
数据库 explain 关键字解析_explain的关键词
赞
踩
目录
1. explain 概述
有些同学可能不知道,我们在数据库中运行 SQL 语句时,底层优化器会选择最优的执行方式来执行我们的 SQL 语句,也就是说,底层执行 SQL 语句的顺序并不一定跟我们写的 SQL 语句的顺序是一致的。MySQL 中有专门优化 SELECT 语句的优化器模块,主要功能是:通过计算分析系统中收集到的统计信息,为客户端请求的 Query(查询) 提供它认为最优的执行计划。
(这里要注意一点,这里最优的执行计划是服务器通过计算得出的,但不见得是我们开发人员认为是最优的,所以实际开发过程中我们的DBA不一定会采用它所提供的执行计划,而是在所提供的执行计划上综合业务逻辑做一些调整)
而通过 explain 关键字就可以让我们知道数据库对 SQL 语句的执行计划是怎么样的,比如多表连接的顺序是什么,执行一条 SQL 语句时,数据库在执行的时候先做什么,再做什么,都可以通过 explain 关键字来查看。explain 语句有很多的输出项,我们就可以通过这些输出项的数据来对 SQL 语句做判断,从而优化那些查询慢的 SQL 语句。
2. explain 关键字的使用方式
explain 关键字的使用方式极其简单,我们只需要将它加在SQL 语句的最前面就可以了,如下所示
- # 加在 SELECT 查询语句的前面
- EXPLAIN SELECT * FROM t_patent WHERE pid > 115;
- # 加在 DELETE 删除语句的前面
- EXPLAIN DELETE FROM t_patent WHERE pid = 110;
- # 加在 UPDATE 更新语句的前面
- EXPLAIN UPDATE t_patent
- SET t_patent.patent_name = "张三" WHERE pid = 130;
3. explain 的版本迭代
(1)在 MySQL5.6.3 版本以前,explain 只能分析 SELECT 语句的执行计划,但是在 MySQL5.6.3 版本以后,explain 不仅可以分析 SELECT 语句的执行计划,还可以分析UPDATE,DELETE语句的执行计划,只是我们更多的是用于分析 SELECT 查询语句,这一点作为了解即可;
(2)在 MySQL5.7 以前的版本中,想要显示 partitions 需要使用 explain partitions 命令,想要显示 filtered 需要使用 explain extended 命令。而 5.7 版本之后,默认 explain 将直接显示 partitions 和 filtered 中的信息。也许现在有些同学还不 partitions 和 filtered 是什么,这里先不用关心,看到下面的讲解自然就会明白了。这里你先可以简单理解为,在 5.7 版本之后,explain 关键字做了增强,explain 将另外两个关键字的功能也包含进去了,不需要再像以前一样执行三个关键字。
4. explain 只分析SQL语句,不执行SQL语句
这句话应该很好理解,我们使用 explain 关键字执行一条语句时,它只是输出当前 SQL 语句最优的执行计划,但并没有真正的去执行这条 SQL 语句。
我简单举个例子演示一下
(1)如下为 patent 数据库中的 t_patent 表,表中有一些数据
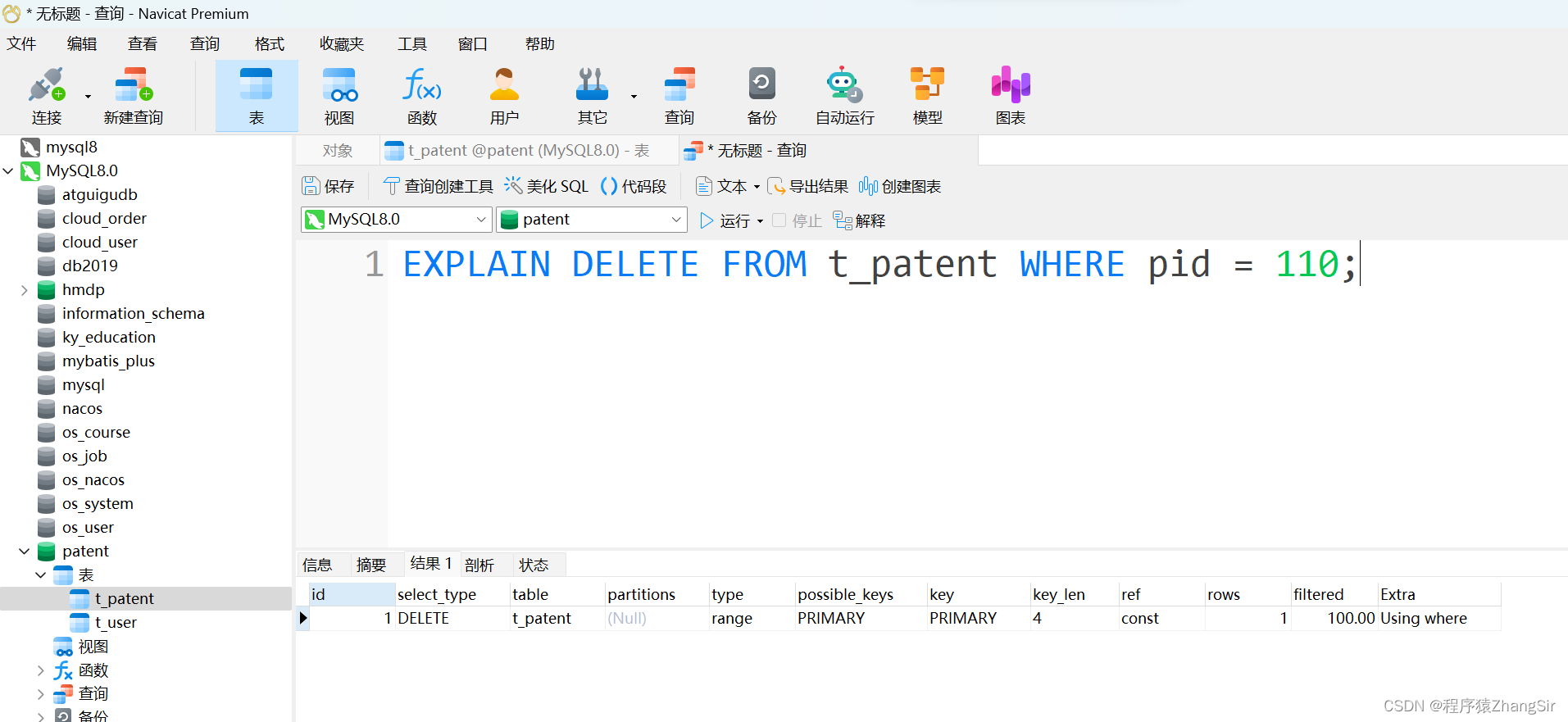
(2)然后,我使用 explain 关键字查询输出当前 DELETE 语句的执行计划,运行成功输出了结果,这里暂时不关心结果中的各个字段含义是什么
(3)我们再来查询一下刚才 pid = 110 的那条数据是否存在,如下,我们发现仍然可以查询到 pid = 110 的这条数据。
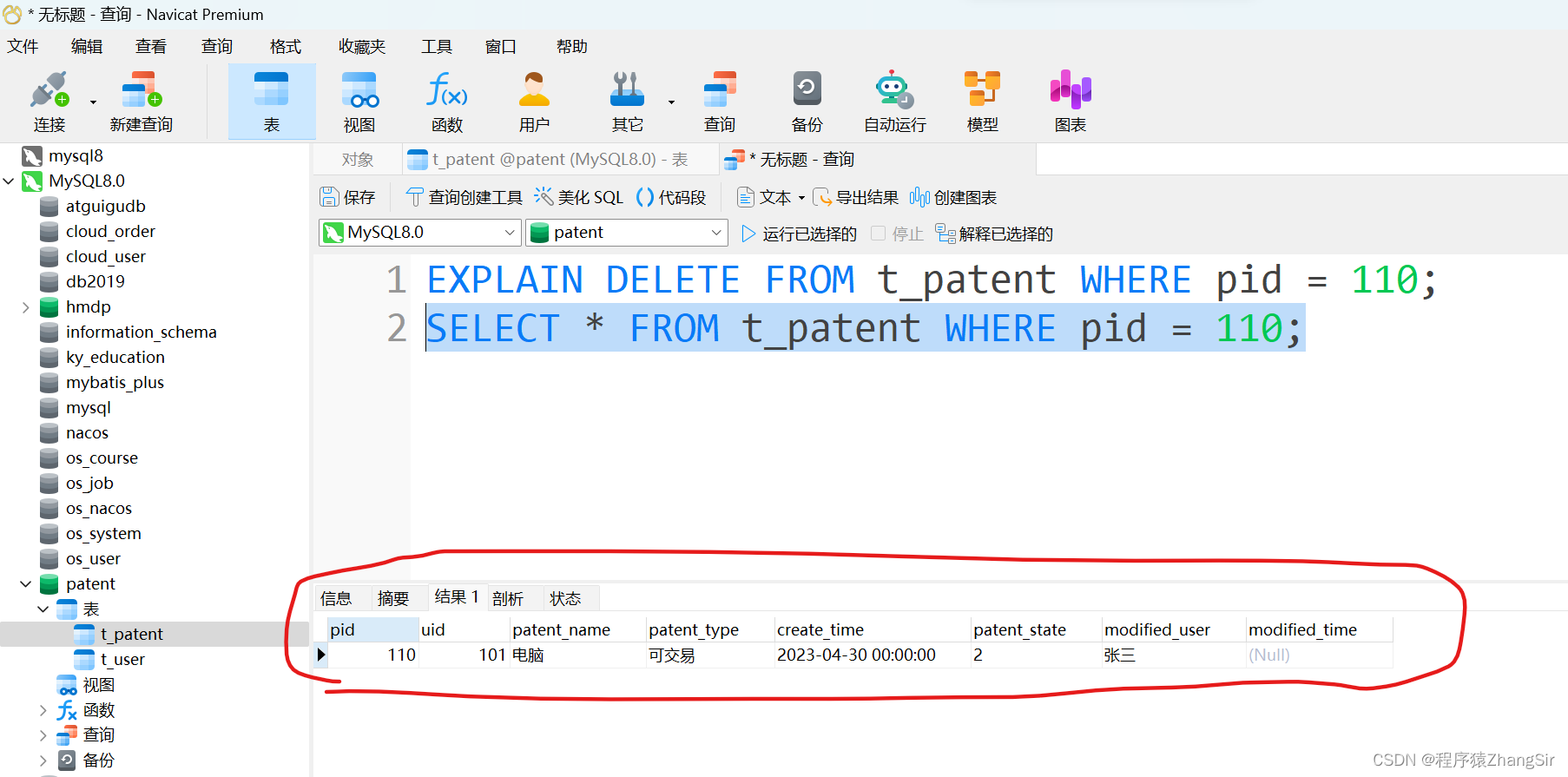
通过这个例子也证实了刚才的结论,explain 只负责输出最优的执行计划,但并没有真正的去执行 SQL 语句。
5. explain 输出结果中各个字段的含义
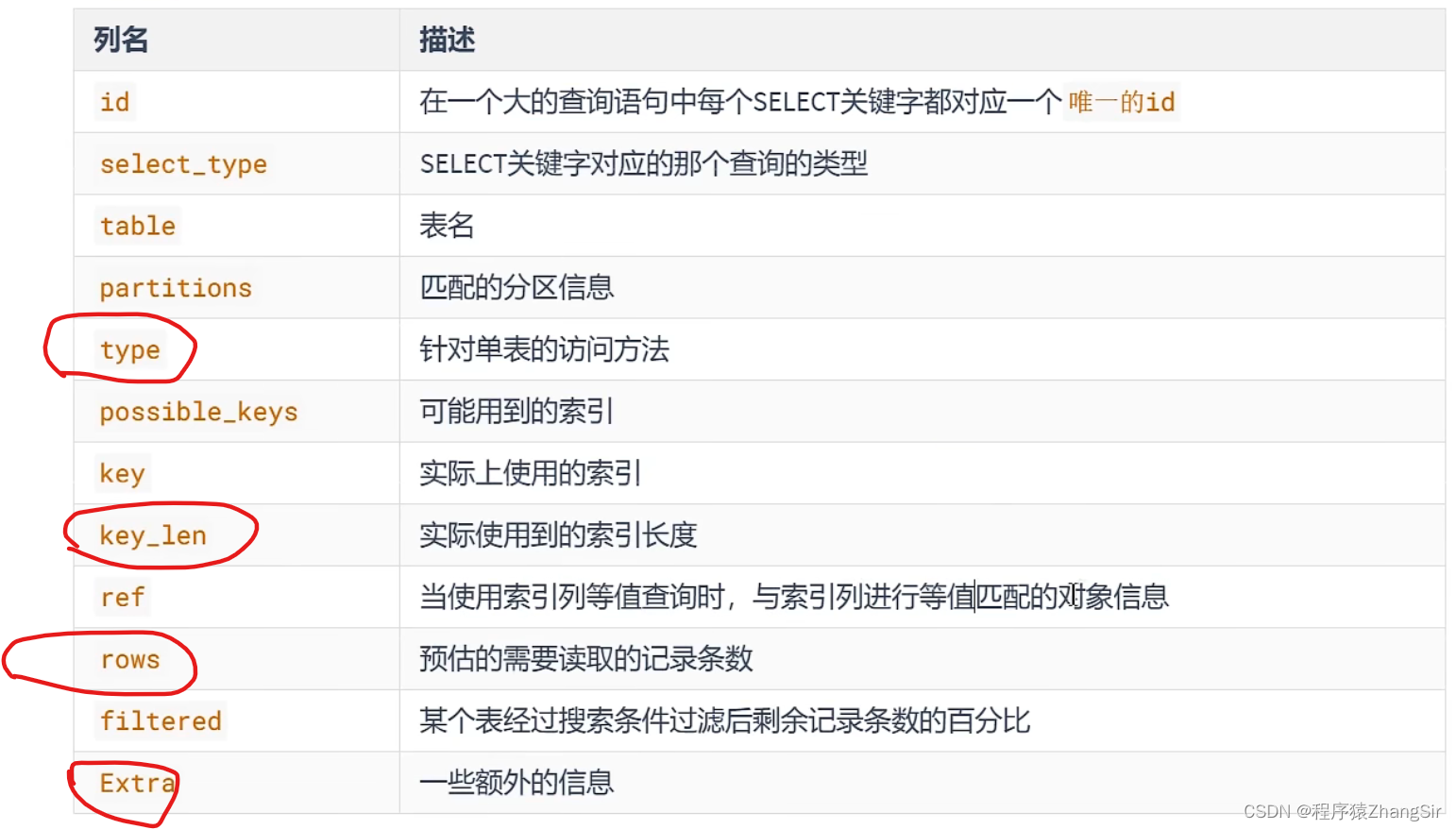
刚才在第四小节的演示中,我们看到了执行 explain 会输出很多的字段,一共有12个,每个字段代表了不同的涵义,列举如下
在这12个字段中,我们需要重点关注 type,key_len,rows,Extra 这个四个字段,他们是面试过程中最容易问到的点,而且是SQL语句调优的关键点,我们的 SQL 的调优就是基于这个四个关键字段来调的。
6. type 表示检索表数据的方式
执行计划中的 type 的一条记录就代表 MySQL 对某个表执行查询时的访问方式,也称"访问类型"。它有众多访问方式,查询的效率从高到低依次是
system > const > eq > ref > fulltext > ref or null > range > index > ALL
在实际开发过程中,我们希望一条 SQL 语句的查询效率越高越好,大多数情况下应当把访问方式至少定位在 "range" 以上,ALL(全表扫描)是我们最不希望看到的结果,所以在编写 SQL 时要尽量避免此访问类型的发生。
7. key_len表示使用的索引的长度
key_len 通常应用于联合索引,开发过程中,一个表会有很多的字段,为了提高查询效率,我们会为查询频率较高的几个字段建立联合索引,通过 explain 就可以得到使用而索引字段的长度,从而得知当前SQL语句中都是用到了联合索引中的那个字段,以便做进一步的优化。
不同的类型的字段计算规则也不一样,如下所示
(1)字符串类型计算
char(n):算作 n 个字节;
varchar:如果是 utf-8 则算作 3n+2 个字节,如果是utf-mb4,则算作 4n+2 个字节;
(2)数值类型计算
tinyint:1字节;
smaillint:2字节;
int:4字节;
bigint:8字节;
(3)事件类型计算
date:3字节;
timestamp:4字节;
datetime:8字节;
此外,字段如果为空,需要1个字段记录是否为空。
通过 explain 得出的索引时应长度,配合上述三种类型长度的计算,我们就能精准得出联合索引中的那些字段被使用到,那些没有被使用到,可以进一步优化sql语句的编写,提高程序运行效率。
8. rows 表示预估读取到的行数
rows 字段的值通常可以搭配 filtered 字段的值,rows 表示预估会读取到的行数,filtered 则表示经过条件筛选之后剩余记录条数的百分比,而两者想成得出的结果通常就是我们最终查询所得到的数据行数。
9. Extra 表示SQL执行时的一些额外信息
这里的额外信息包含很多种,如下
(1)Using Index:使用非主键索引数就可以查询到所需要的数据,一般是覆盖索引,即想要查询的数据都包含在非剧组索引数中,不需要进行回表操作。
(2)Using where:不通过索引查询所需要的数据,这句话也很好理解,就是我们 where 筛选条件的字段不是索引字段。那么就会进行全表扫描,即 type 字段值为 ALL。
(3)Using index condition:表示查询列不被索引覆盖,where 条件中是一个索引范围查找,过滤玩索引后会回表找到所有符合条件的数据行。例如 SELECT * FROM table where 主键 > 某个值,这种 SQL 语句就符合上面这种情况,
(4)Using temporary:表示在查询的过程中需要利用临时表来处理查询,比如我们使用 union all 取两个表满足条件的并集,得到的数据表实际上是一张临时表;
(5)Using filesort:当查询中包含 order by 操作而且无法利用索引完成的排序操作时,若数据量小就在内存中进行排序,若数据量多就在硬盘中进行排序。
当遇到 Using temporary 或 Using filesort 时,我们可以通过添加索引对 SQL 进行优化。
(6)Select table optimized away:当我们通过聚合函数访问某些索引数据时,在 Extra 中就会显示 Select table optimized away,如果通过聚合函数访问普通非索引字段,在 Extra 中就会显示 null。

