
- 1数据源没有mysql驱动程序_MySQL的ODBC问题:数据源名称未找到和指定默认驱动程序...
- 2【转载】Sim2Real问题[2]
- 35.1.2、【AI技术新纪元:Spring AI解码】Ollama Chat_ollamachatclient
- 4c++编码规范(五)_禁止使用rand生成伪随机数
- 5matlab -定点化(fixed point)使用及输出_fixed point类型
- 6软件测试能干到多少岁?写给像我同样迷茫的人
- 7用 AI 生成 Vue 组件?_vue0
- 8openmv利用模板匹配+控制舵机来控制小车使P点触碰到靶心_openmv靶心识别
- 9线性代数学习笔记5-1:正交的向量/空间、正交补(行空间和零空间正交)_正交补集
- 10Java期末大作业基础项目--在线学生选课系统_javaee期末大作业项目_项目javaweb大作业项目免费
后门攻击阅读笔记,Graph Backdoor
赞
踩
论文标题:Graph Backdoor
论文单位:Pennsylvania State University,Zhejiang University
论文作者:Zhaohan Xi,Ren Pang,Shouling Ji
收录会议:预印版
开源代码:未开源
图后门(攻击)
简单总结
第一个在图神经网络上的后门攻击
- 与之前的工作相比,GTA在很多方面有所不同:面向图:它将触发器定义为特定的子图,包括拓扑结构和描述性特征,为攻击者提供了大量的设计范围;量身定制的输入:它动态地适应触发器到每个图,从而优化攻击的有效性和规避性;与下游模型无关:它可以在不了解下游模型或微调策略的情况下随时启动;而且攻击是可扩展的:它可以被实例化用于直推式(例如,节点分类)和归纳式(例如,图分类)任务。
- 场景:迁移场景、非迁移场景;归纳式学习、直推式学习;针对于GNN分类的上游任务,对图中的结点进行编码,在这个过程中对GNN进行植入后门。
- 使用数据集:七个来自安全敏感领域的数据集
- 触发器特点:不同输入的图会生成自适应的触发器,该触发器的特点会替换原图的子图(保证结点个数一致,边的信息可以修改)
- 模型特点:一个专门生成触发器的生成器(采用神经网络结构的两个生成函数)和 攻击目标(GNN)
- 攻击方法:生成一个木马GNN,训练该模型时的核心是双层优化,对木马GNN和触发器生成器的参数进行轮流优化,因为没有访问下游分类器,因此优化的目标是针对它们的潜在表达形式(可理解为embedding输出)的 L 2 L2 L2距离,详细描述,即要保证正常GNN和木马GNN在干净输入时要保证较为相似的潜在表达输出,也要保证木马GNN在带有木马的输入(非攻击目标类)和目标类干净输入时较为相似的潜在表达输出。(重点阐述了归纳式学习的攻击过程)
- 一些细节:不仅要优化木马GNN的参数,也要优化触发器生成器的参数,还要对图 G G G中选择一个合适的替换的子图 g g g,因此需要大量的计算,作者提出了许多优化方法,可详看论文笔记或原文中查看。
值得做的点(仅从本文出发)
- 这个工作把后门攻击用在了上游任务上,和我最近主导推进的一个项目非常相关,主要也是研究文本上游任务对隐私泄漏的影响,我将文本分类归结为上游任务和下游任务,上游任务即为向量化过程,可以选择使用one-hot、Tfidf、embedding、bert等等,下游任务即为分类过程,可以选择CNN、LSTM、集成树模型等等。所以,跟本文在上游任务植入后门还是比较相似,因此,结合我最近做的是文本上游任务结合隐私泄漏,我们可以提出文本上游任务结合后门攻击来做。
- 其次,针对这种图后门的对抗后门防御也是值得挖掘的,我之前对图神经网络了解的不够深入,在竞赛中曾使用过deepwalk算法,可能需要再继续深入了解后,再去提出相应解决方案。
abstract
-
GTA( Graph Trojaning Attack),对GNN的第一个后门攻击。
-
与之前的工作相比,GTA在很多方面有所不同:面向图:它将触发器定义为特定的子图,包括拓扑结构和描述性特征,为攻击者提供了大量的设计范围;量身定制的输入:它动态地适应触发器到每个图,从而优化攻击有效性和规避;与下游模型无关:它可以在不了解下游模型或微调策略的情况下随时启动;而且攻击是可扩展的:它可以被实例化用于直推式(例如,节点分类)和归纳式(例如,图分类)任务,对一系列安全关键的应用构成严重威胁。
-
通过使用基准数据集和最先进的模型进行广泛的评估,作者证明了GTA的有效性。进一步对其有效性进行了分析论证并讨论了可能的对策,指出了几个有前景的研究方向。
1.introduction
-
图神经网络已经成为部分领域进行分析的最先进工具,并且针对图神经网络的安全问题也有很多人在研究,但是在图神经网络(GNN) 模型上的后门攻击还没有被探索。因此作者给出了三个问题进行探讨:
- GNNs是否会受到后门攻击?
- 在各种实际设置下,该攻击会有多有效?(在现成的GNNs或者输入空间)
- 潜在的防御手段有什么?
-
面向图,与结构化、连续的数据(如图像)不同,图数据本质上是非结构化和离散的,因此要求触发器具有相同的性质。GTA定义触发器为特定的子图,包括拓扑结构和描述性(结点和边)特性,这需要对手很大的设计范围。
-
量身定制的输入,比起为所有的图定义一个固定的触发器,GTA会根据每个图的特征定制触发器,从而优化攻击效果(如错误分类的可信度)和躲避性(如扰动程度)。下图说明了GTA如何根据特定的输入图形调整触发器。

-
与下游模型无关,假设一个真实的设置,其中攻击者不知道关于下游模型或微调策略。比起依赖于最终的预测,GTA优化了木马GNNs的中间表现形式,从而导致了它对变化的系统设计选择有阻力。
-
可扩展的攻击,GTA代表了一个攻击框架,可以被实例化为各种设置,如归纳式(例如,图分类)和直推式(例如,结点分类)任务,从而对一系列安全关键域(例如,有毒化学物质分类)构成严重威胁
-
作者使用一系列最先进的 GNN 模型和基准数据集来验证GTA 的实用性,并回答了上面提出的3个问题。
- 证明了 GNN 在归纳式和直推式设置下都很容易受到后门攻击。 在归纳任务中,特洛伊木马模型迫使它们的主机系统将触发嵌入图错分为目标类,成功率超过 91.4%,而精度下降小于 1.4%;在直推任务中,特洛伊木马模型导致目标结点的错误分类,成功率超过69.1%,而精度下降小于2.4。
- 评估了GTA在重新预处理过的GNN。在多任务设置下预处理的现成模型上,GTA的成功率甚至更高(超过96.4%),这意味着向下游任务迁移性更好的GNN更容易受到攻击。我们进一步考虑了输入空间攻击,其中输入中的非图首先转换为图以便GNN处理,而GTA需要确保扰动图满足输入空间的语义约束。作者证明了,尽管有额外的限制,输入空间GTA的性能与对应的图空间GTA相比是相应的。
- 讨论了潜在的对策及其技术挑战。尽管构想高级别的缓解措施是直接的(如重复使用训练过的GNN),但具体实施这些策略是具有挑战性的。例如,检查一个预先训练过的GNN是否存在潜在的后门,相当于在输入空间中搜索异常的“捷径”模式,由于图形数据的离散结构和GNN令人生畏的复杂性,这就带来了不小的挑战。更糟糕的是,由于GTA的自适应特性,这些“捷径”模式可能会因不同的图表而有所不同,从而让它们更容易逃避检测。
参考:归纳式和直推式的区别(inductive and transductive)
模型训练:Transductive learning在训练过程中已经用到测试集数据(不带标签)中的信息,而Inductive learning仅仅只用到训练集中数据的信息。
模型预测:Transductive learning只能预测在其训练过程中所用到的样本(Specific --> Specific),而Inductive learning,只要样本特征属于同样的欧拉空间,即可进行预测(Specific --> Gerneral)
模型复用性:当有新样本时,Transductive learning需要重新进行训练;Inductive Leaning则不需要。
模型计算量:显而易见,Transductive Leaning是需要更大的计算量的,即使其有时候确实能够取得相比
主要贡献
-
作者提出了GTA,对GNN的第一个后门攻击,它突出了以下特征
(i)它使用子图作为触发器
(ii)不同的图有不同的触发器
(iii)假定不了解下游模型
(iv)可适用于归纳式和直推式任务
-
GTA在一系列安全关键任务中非常有效,逃避检测,与下游模型无关。
-
为GTA的有效性提供分析论证,并讨论潜在的缓解措施。该分析为改进现有的预处理GNN模型重用的实践提供了思路,并指出了一些研究方向。
2.background
GNN
GNN以包含其拓扑结构和描述性特征的图 G G G为输入,对每个结点 v v v生成表示(嵌入) z v z_v zv,以 Z Z Z表示矩阵形式的结点嵌入。
预训练的GNN
随着 GNN 模型的广泛使用,由于标记数据稀疏或训练昂贵,因此重用预训练的GNN变得有吸引力。在迁移设置下,如图 2 所示,预训练的GNN与下游任务的联系。

后门攻击
使用木马模型作为攻击向量,后门攻击向目标系统注入恶意函数,当存在某些预定义的条件(“触发器”) 时触发这种恶意函数。
威胁模型
- 作者假设了威胁模型,如图 2 所示。给定一个预先训练的GNN f θ f_\theta fθ (参数为 θ 0 \theta_0 θ0),攻击者伪造木马 GNN f θ f_\theta fθ 通过扰动其参数而不修改其架构(否则通过检查 f f f的规范可以检测到)。
- 假设攻击者可以访问从下游任务中采样的数据集 D D D。 实验评估表明,通常很小的数量(如1%)来自下游任务的训练数据就足够了。 在将 f θ f_\theta fθ与下游分类器 h h h整合后形成端到端系统后,用户对下游任务进行微调。
- 为了使攻击更实用,假设攻击者不知道使用什么分类器 h h h 或系统是如何微调的。
3.GTA Attack
在高级语义,GTA 伪造特洛伊木马 GNN,一旦集成到下游任务,导致主机系统以高度可预测的方式响应触发器嵌入的图形。
3.1攻击概述
- 为了简单起见,作者用图分类任务举例说明GTA,并讨论其扩展到其他设置(例如,直推式学习)。给定一个预先训练的 GNN θ 0 \theta_0 θ0,攻击者的目标是伪造一个木马模型 θ \theta θ,以便在下游任务中, θ \theta θ迫使主机系统将所有触发嵌入的图错误分类为指定的 y t y_t yt类,而在良性图上正常工作。 形式上,我们将触发器定义为子图 g t g_t gt(包括拓扑结构和描述性特征),以及混合函数 m ( ⋅ ; g t ) m(·;g_t) m(⋅;gt),它将 g t g_t gt与给定的图 G G G混合,生成触发嵌入图 m ( G ; g t ) m(G;g_t) m(G;gt)。 因此,攻击者的目标可以定义为:
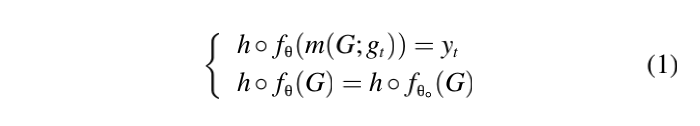
其中 h h h是微调后的下游分类器, G G G表示任务中的任意图。直观地说,第一个目标指定所有触发嵌入图都被 错误地分类为目标类(即攻击有效性),而第二个目标确保原始和特洛伊木马 GNN 在良性图(即良性图)上的行为是不可区分的(即攻击逃逸)。
- 然而,在上式中寻找最优触发 g t g_t gt和木马模型 θ \theta θ是非平凡的挑战。
- 由于对手无法访问下游模型 h h h,基于 E q ( 1 ) E_q(1) Eq(1)直接优化 g t g_t gt和 θ \theta θ是不切实际的。
- 由于 g t g_t gt和 θ \theta θ相互依赖,每次更新 g t g_t gt需要昂贵的重新计算 θ \theta θ。
- 有一些组合方法可以将 g t g_t gt与给定的图 G G G混合,这意味着一个禁止的搜索空间。
- 对所有图形使用通用触发器 g t g_t gt会忽略单个图形的特性,导致了次优的和易于检测的攻击。
-
针对上述挑战,(1)作者没有将 g t g_t gt和 θ \theta θ与最终预测相关联,而是在中间表示方面对它们进行了优化;(2)作者采用了双层优化公式,将 g t g_t gt作为超参数, θ \theta θ作为模型参数,并以交互的方式对它们进行了优化;(3)作者将混合函数 m ( G ; g t ) m(G;g_t) m(G;gt)作为一个有效的替代操作,在 G G G中发现并替换了与 g t g_t gt最相似的子图 g g g;(4)作者引入了自适应触发器的概念,即 g t g_t gt是针对每个给定的图 G G G进行了具体的优化。
-
GTA 的总体框架如下图所示,下面会继续展开详细介绍。

3.2双层的优化
- 回想一下,攻击者可以访问从下游任务采样的数据集 D \mathcal D D,该数据集包括一组实例 ( G , y G ) (G, y_G) (G,yG),其中 G G G是一个图, y G y_G yG是它的类。我们给出了以 g t g_t gt和 θ θ θ为上下变量的双层优化目标[16]:

其中, ℓ a t k \ell_{atk} ℓatk和 ℓ r e t \ell_{ret} ℓret分别代表损失项,量化攻击有效性和精度保持性,对应于定义在 E q ( 1 ) Eq(1) Eq(1)中的目标。
- 没有访问下游分类器 h h h,相较于将 ℓ a t k \ell_{atk} ℓatk与 ℓ r e t \ell_{ret} ℓret最终预测关联起来,作者根据潜在表示来定义它们。将 D \mathcal D D分为两部分, D [ y t ] \mathcal D[yt] D[yt]—标签为目标类 y t y_t yt的图和$\mathcal D[\y_t] — 标 签 为 其 他 类 的 图 ; —标签为其他类的图; —标签为其他类的图;\ell_{atk} 强 制 强制 强制f_θ 为 为 为\mathcal D[y_t] 中 的 图 和 被 中的图和被 中的图和被g_t 嵌 入 的 嵌入的 嵌入的\mathcal D[\y_t] 中 的 图 生 成 类 似 的 嵌 入 。 同 时 , 中的图生成类似的嵌入。同时, 中的图生成类似的嵌入。同时,\ell_{ret} 保 证 了 保证了 保证了f_θ 和 和 和f_{θ_0} 对 对 对\mathcal D$中的图产生相似的嵌入。
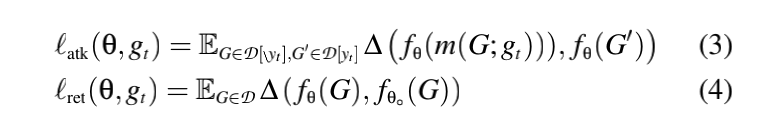
其中, △ ( ⋅ , ⋅ ) \triangle(·,·) △(⋅,⋅)度量嵌入矩阵的不相似性,在实现中,它被实例化为 L 2 L2 L2距离。
-
然而,精确求解 E q ( 2 ) Eq(2) Eq(2)花费是昂贵的。由于双层公式,当 g t g_t gt更新时,需要重新计算 θ θ θ(即在 D \mathcal D D上重新训练 f f f)。因此作者提出了一个近似解,通过交替在 ℓ a t k \ell_{atk} ℓatk和 ℓ r e t \ell_{ret} ℓret上梯度下降迭代优化 g t g_t gt和 θ θ θ。
具体来说,在第i次迭代时,给定当前触发器 g t ( i − 1 ) g_t^{(i-1)} gt(i−1)和模型 θ ( i − 1 ) \theta^{(i-1)} θ(i−1),首先在 g t ( i − 1 ) g_t^{(i-1)} gt(i−1)固定的情况下,通过在 ℓ r e t \ell_{ret} ℓret上梯度计算计算 θ ( i ) \theta^{(i)} θ(i)。在实践中,可以 n i o n_{io} nio次迭代运行此步骤。参数 n i o n_{io} nio,即内外优化比,实质上平衡了 ℓ a t k \ell_{atk} ℓatk和 ℓ r e t \ell_{ret} ℓret的优化。然后,我们通过最小化 ℓ a t k \ell_{atk} ℓatk对 θ ( i ) θ^{(i)} θ(i)进行单步梯度下降优化后获得 g t ( i ) g^{(i)}_t gt(i)。形式上,相对于 g t g_t gt的梯度近似为:
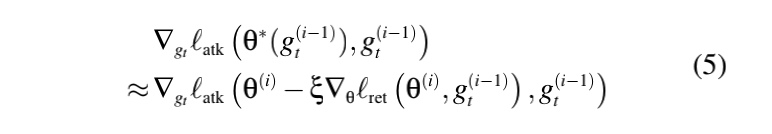
其中, ξ ξ ξ为向前步骤的学习率。
4. 直觉来说,对 g t g_t gt优化 ℓ a t k ( θ ∗ ( g t ) , g t ) \ell_{atk}(\theta^*(g_t),g_t) ℓatk(θ∗(gt),gt)是昂贵的,但作者使用单步展开模型作为 θ ∗ ( g t ) θ^∗{(g_t)} θ∗(gt)的替代品(详见 § A . 1 § A .1 §A.1)。简单来说,式子5括号内左边的式子是一步前移后更新的参数 θ ( i ) \theta^{(i)} θ(i),这个公式涉及到矩阵向量乘法,可以用有限差分近似来近似,减少 ℓ a t k ( θ ∗ ( g t ) , g t ) \ell_{atk}(\theta^*(g_t),g_t) ℓatk(θ∗(gt),gt)的计算量。
3.3混合函数
-
混合函数 m ( G ; g t ) m(G;g_t) m(G;gt)实现了两个目的:(1)对于给定的触发器 g t g_t gt,它在给定的图 G G G中识别出要被替换的子图 g g g;(2)将 g g g替换为 g t g_t gt。显然,有组合的方法来定义 m ( G ; g t ) m(G;g_t) m(G;gt),导致一个禁止搜索空间。
-
为了解决这个问题,我们将混合函数限制为一个有效的替换操作;即 m ( G ; g t ) m (G; gt) m(G;gt)使用 g t g_t gt替换 G G G的子图 g g g。为了最大化攻击逃逸性,需要使用类似 g t g_t gt的子图 g g g。因此指定的约束条件:(1) g g g和 g t g_t gt是相同的大小(即,相同数量的节点),(2)它们有最小图编辑距离(即添加或删除边)。
-
已知在给定图 G G G中找到与 g t g_t gt(子图同构)相同的子图 g g g是NP难的。作者采用基于回溯的算法 V F 2 VF2 VF2来满足设置。根据直接, V F 2 VF2 VF2将 g t g_t gt中的下一个节点映射到G中的一个节点,如果可行递归扩展部分匹配,否则回溯。当搜索到最相似的子图时,保持当前的最高相似度,并在部分匹配超过这个阈值时提前终止。详细实施的做法参照KaTeX parse error: Undefined control sequence: \S at position 1: \̲S̲ ̲ ̲A.2。
3.4触发器生成
-
在方程(2)的公式中,假设了所有图的通用触发器。 尽管它的实现简单,但固定触发器需要很大的优化空间:(1) 它忽略了单个图形的特性,导致不那么有效的攻击;(2)它成为触发器嵌入图形共享的模式,并使它们易于被检测。 因此, 作者假设是否有可能生成针对个别图的触发器,以最大限度地提高攻击的有效性和逃逸性。
-
作者设计了一个自适应触发生成函数 ϕ w ( ⋅ ) \phi_w(·) ϕw(⋅),提出了为给定在图 G G G中的子图 g g g专门定制的触发器 g t g_t gt, ϕ w ( ⋅ ) \phi_w(·) ϕw(⋅)包括两个关键操作:(1)先将 g g g中的每个结点 i i i映射到它的编码 z i z_i zi,该编码包含了 g g g的结点特征和拓扑结构;(2)采用神经网络结构的两个生成函数,第一个映射 g g g的结点编码到 g t g_t gt的拓扑结构,第二个映射 g g g的结点编码到 g t g_t gt的结点特征。接下来,详细介绍 ϕ w ( ⋅ ) \phi_w(·) ϕw(⋅)的设计。
-
如何编码 g g g的特征和语义?
为了在 G G G中编码 g g g的拓扑结构和结点特征以及它的语义,作者使用了最近的图注意力机制。直观地,对于给定的一对节点 i , j i, j i,j,计算注意力系数 α i j α_{ij} αij,基于它们的结点特征和拓扑关系指定 j j j关于 i i i的重要性;然后在应用非线性变换后,我们生成 i i i的编码作为其邻近编码的聚合(根据其相应的注意力系数加权)。最后使用 D \mathcal D D对注意力网络进行训练(详见表10)。下面用 z i ∈ R d z_i∈R^d zi∈Rd表示节点 i i i的编码( d d d为编码的维数)。
-
如何映射 g g g的编码到 g t g_t gt?
g t g_t gt包括两个部分,它的拓扑结构和节点特征。
给定两个节点 i , j ∈ g i, j∈g i,j∈g和对应的编码 z i , z j z_i,z_j zi,zj,用参数化的余弦相似性在 g t g_t gt中定义对应的相关性 A ~ i j \widetilde{A}_{ij} A ij
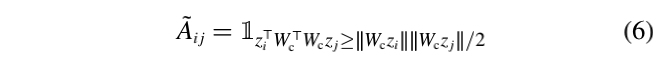
W c ∈ R d × d W_c∈R^{d×d} Wc∈Rd×d是可学的,是 1 p 1_p 1p一个指标函数如果 p p p是真的返回1否则0。直觉上, i i i和 j j j的相似度评分超过0.5时,在 g t g_t gt中连通。同时,对于节点 i ∈ g i∈g i∈g,我们在 g t g_t gt中定义其特征 X ~ i \widetilde{X}_i X i为
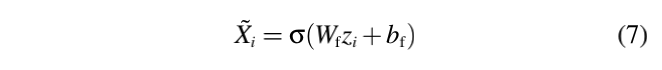
其中 W f ∈ R d × d W_f∈R^{d×d} Wf∈Rd×d, b f ∈ R d b_f∈R^d bf∈Rd都是可学习的, σ ( ⋅ ) σ(·) σ(⋅)是一个非线性激活函数。
下面,将 W c W_c Wc, W f W_f Wf和 b f b_f bf统称为 ω ω ω, g g g的编码到 { X i } ( i ∈ g ) \{X_i\}(i∈g) {Xi}(i∈g)和 { A ~ i j } ( i , j ∈ g ) \{\widetilde{A}_{ij}\}(i,j∈g) {A ij}(i,j∈g)的映射为触发生成函数 ϕ w ( g ) \phi_w(g) ϕw(g)。
-
如何解决 g g g和 g t g_t gt的相关性?
聪明的读者可能会指出,混合函数 g = m ( G , g t ) g=m(G, g_t) g=m(G,gt)和触发生成函数 g t = ϕ w ( g ) g_t =\phi_w(g) gt=ϕw(g)是相互依赖的: g t g_t gt的生成依赖于 g g g, g g g的选择取决于 g t g_t gt。为了解决这个“鸡生蛋还是蛋生鸡”的问题,作者以交叉的方式更新 g g g和 g t g_t gt。
==具体来说,初始化随机选择的一个 g g g,在第 i i i次迭代时,首先基于 g ( i − 1 ) g^{(i-1)} g(i−1)更新触发器 g t ( i ) g^{(i)}_t gt(i),然后基于 g t ( i ) g^{(i)}_t gt(i)更新选中的子图 g ( i ) g^{(i)} g(i)。==在实践中,通过一个阈值 n i t e r n_{iter} niter限制迭代的数量。
3.5实现和优化
把所有的东西放在一起,算法1勾勒出GTA攻击的流程。其核心是更新模型 θ θ θ、触发器生成函数 ϕ w ( g ) \phi_w(g) ϕw(g)和每个KaTeX parse error: Undefined control sequence: \yt at position 14: G∈\mathcal D[\̲y̲t̲]所选择的子图 g g g。

-
周期重置
回想一下,在 ℓ r e t \ell_{ret} ℓret上用梯度下降更新模型。随着更新步骤数的增加,这个估计可能会明显偏离在 D \mathcal D D上训练的真实模型,从而对攻击的有效性产生负面影响。为了解决这个问题,周期性地(例如,每20次迭代),基于当前的触发 g t g_t gt,用真实的模型 θ ∗ ( g t ) θ^∗(g_t) θ∗(gt)替换估计进行训练。
-
子图稳定
这是作者根据实验中观察到的评估,为每个稳定每一个KaTeX parse error: Undefined control sequence: \yt at position 15: G∈ \mathcal D[\̲y̲t̲]选定的子图 g g g,通过运行子图更新步骤(伪代码第6行)多次迭代(例如,5次),触发器生成函数稳定后,往往导致更快的收敛。
-
模型恢复
一旦木马GNN f θ f_θ fθ被训练,攻击者可能选择通过预训练任务恢复分类器 h ◦ h_◦ h◦(不是下游分类器 h h h)。由于后门注入, h ◦ h_◦ h◦可能不匹配 f θ f_θ fθ。攻击者可以使用来自预训练任务的训练数据来调整 h ◦ h_◦ h◦。这一步使得发布的模型 h ◦ ◦ f θ h_◦◦f_θ h◦◦fθ的精度匹配其声明,从而通过模型检查。
3.6扩展到直推式学习
-
现在讨论GTA扩展到一个直推式设置:给定一个图 G G G和一组标记的结点,目标是推断剩余未标记结点 V U V_U VU的类别。
-
作者假设设置如下。攻击者既可以访问 G G G,也可以访问分类器。为简单起见,通过 f θ ( v ; G ) f_θ(v; G) fθ(v;G)表示完整系统,可以对给定在 G G G中的结点 v v v进行分类。
-
此外,给定 G G G中的任意子图 g g g, 攻击者用触发器 g t g_t gt替换 g g g,为了强制无标签结点在 K K K跳后到达 g g g被误分类为目标类 y t y_t yt, K K K是GNN层数。回想一下,对于基于邻域聚合的GNN,一个结点对其他结点的影响最多为 K K K跳;这个目标限制了攻击有效性。
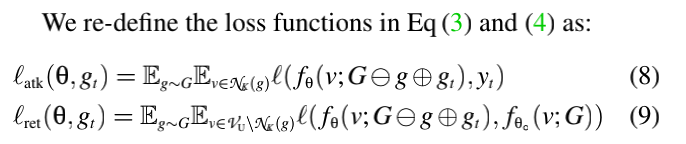
其中, N K ( g ) \mathcal N_K(g) NK(g)是 g g g在 K K K跳以内的结点集, G − g ⊕ g G- g⊕g G−g⊕gt为 g t g_t gt代替 g g g后的 G G G, ℓ ( ⋅ , ⋅ ) \ell(·,·) ℓ(⋅,⋅)是一个合适的损失函数(如交叉熵)。而且,假设 g g g是由攻击者选择的,混合函数是不必要的。
4.Attack Evaluation
-
数据集 :七个来自安全敏感领域的数据集
- Fingerprint – graph representations of fifingerprint shapes from the NIST-4 database
- WinMal – Windows PE call graphs of malware and goodware
- AIDS
- Toxicant – molecular structure graphs of active and inactive compounds
- AndroZoo - call graphs of benign and malicious APKs collected from AndroZoo
- Bitcoin – an anonymized Bitcoin transaction network with each node (transaction) labeled as legitimate or illicit
- Facebook – a page-page relationship network with each node (Facebook page) annotated with the page properties (e.g., place, organization, product)
-
模型 :3个SOTAGNN模型
- GCN
- GRAPHSAGE
- GAT
-
基准:GTA以及变体
GTA是第一个后门攻击GNN。因此,主要将GTA与其变体作为基线进行比较。
B L I BL^I BLI,它将触发器固定为完全子图,并优化其所有节点共享的特征向量
B L I I BL^{II} BLII,它优化了触发器的连通性和每个节点的特征向量。
B L I BL^I BLI和 B L I I BL^{II} BLII都为所有的图假定了一个通用的触发器,而GTA通过优化将触发器的拓扑连通性和节点特性与每个图结合起来。从直觉上看,BLI, BLII和GTA代表了不同水平的触发适应性。
-
评价指标:评价有效性和规避性
- 有效性:
- attack success rate (ASR)
- average misclassifification confifidence (AMC)
- 规避性:
- clean accuracy drop (CAD)
- average degree difference (ADD)
- average eccentricity change (AEC)
- algebraic connectivity change (ACC)
- 有效性:
作者进行实验回答了以下四个问题:
-
它在归纳任务中如何有效/规避?
- 这组实验在归纳式设置下评价GTA,在归纳设置中使用预训练的GNN进行下游图分类任务。基于预训练和下游任务之间的关系,考虑两个场景。
-
非迁移。
在两个任务共享同一个数据集的情况下,将整个数据集 T \mathcal T T分别划分为40%和60%,分别用于预训练和下游任务。假设攻击者可以访问1%的 T \mathcal T T(即 D \mathcal D D)来伪造木马模型。在评估中,从下游数据集随机抽取25%的样本来构建触发器嵌入图,其余的作为干净的输入。
-
迁移。
在两个任务使用不同数据集的情况下,在预处理任务中,使用整个数据集进行GNN预处理;在下游任务中,将数据集T随机划分为40%和60%,分别用于系统微调和测试。默认情况下,假设攻击者可以访问 T \mathcal T T的1%。与非迁移情况类似,从 T \mathcal T T的测试集中抽取25%来构建触发器内嵌图,其余作为干净的输入。
- 效果:在非迁移和迁移设置中,所有攻击都达到了较高的攻击效果

-
它对预训练的,现成的GNN有多有效?
-
除了从头开始训练的模型,进一步考虑现成的、已训练好的GNN模型。使用GCN模型,该模型在ChEMBL数据集上使用图级多任务监督训练进行预训练,该数据集包含456K分子,有1310种不同的生化检测方法。将这个模型迁移到对艾滋病和毒物数据集进行分类的任务中。默认设置与迁移案例相同。
-
效果: G T A > B L I I > B L I GTA >BL^{II}> BL^I GTA>BLII>BLI
-

-
它在直推式任务中有多有效/规避?
-
在每个任务中,将 G G G的结点随机划分为20%作为标记集VL, 80%作为未标记集 V U V_U VU。然后从G中随机抽取100个子图作为目标子图 g {g} g。与归纳攻击相似,分别使用ASR (AMC)和CAD来衡量攻击的有效性和规避性。特别是,ASR (AMC)是在 g g g的 K K K跳内的未标记结点上测量的,而CAD是在所有其他未标记结点上测量的。
-
效果:在比特币数据集上,GTA 分别比 B L I BL^I BLI和 B L I I BL^{II} BLII高 37.6%和 21.1%
-

-
它对下游模型是不可知的吗?
- 现在用代理模型(GNN 固定为 GCN)实例化下游分类器,包括朴素贝叶斯(Nb)、随机森林(RF)和梯度 Boost(Gb)。 评估了分类器对ChEMBL→Toxicant迁移情况下不同攻击的影响,结果见表 6。 观察分类器对 GTA 的影响有限,这意味着它对分类器不敏感。

5.讨论
5.1攻击漏洞的原因
归结于GNN的高度非线性,非凸函数。
5.2可能的对策
现有的防御大致可分为两大类:在模型检查期间识别可疑模型和在推理时检测嵌入触发器的输入。
因此,作者将神经清洁(NC)和随机平滑(RS)扩展为这两类的代表性防御,并评估它们对 GTA 的有效性。
-
NC:NC依赖一个假设,触发器是固定的,这与GTA的自适应攻击的防御相悖,因此NC检测GTA往往是无效的。所有需要针对自适应性去设计更先进的防御。
-
RS:较小的平滑系数 β β β导致较低的ASR,但也导致较大的CAD。因此,RS可能不是对抗GTA的可行选择,因为它可能会对系统性能产生负面影响。
5.3输入空间的攻击
虽然GTA直接对图结构输入进行操作,但也有一些场景将非图输入转换为图,以便 GNN 进行处理。 在这种情况下,攻击者必须确保在应用触发器后对图形的任何扰动都可以真实地投影回输入空间,在输入空间中攻击者执行操作。
简单来说,就是在图上的修改需要映射回输入空间真实存在的值上。

