
- 1传入日期格式错误“message“: “JSON parse error: Cannot deserialize value of type `java.util.Date` from String_msg": "json parse error: cannot deserialize value
- 2基于FPGA的光口通信开发案例_tx diff swing
- 3MAC搭建MySQL,同时使用dataGrip可视化数据库_datagrip download from maven failed
- 4Java增加线程后kafka仍然消费很慢
- 5springcloud+hibernate+JPA+EntityManager Oracle 双数据源配置_java中yml配置hibernate多数据源调用接口
- 6Python课程设计:图书馆管理系统_python图书信息管理系统课设
- 7Dom4j教程详解+XML详解(详解+举例)
- 8产品读书《自卑与超越》_母亲带着三个孩子去动物园看狮子
- 9国密算法SM3
- 10Python针对MAC OS X安装_python3.12.1 mac安装教程
论文阅读14--Association Rules with Graph Patterns
赞
踩
摘要:
我们提出了用于社交媒体营销的图模式关联规则(GPAR)。 GPAR 扩展了项集的关联规则,帮助我们发现社交图中实体之间的规律,并通过探索社会影响力来识别潜在客户。我们研究发现topk多样化GPAR的问题。虽然这个问题是 NP 难题,但我们开发了一种具有精度限制的并行算法。我们还研究了利用 GPAR 识别潜在客户的问题。虽然它也是 NP 难的,但我们提供了一种并行可扩展算法,可以保证随着处理器的增加,相对于顺序算法的多项式加速。使用现实生活和合成图,我们通过实验验证了算法的可扩展性和有效性。
1. INTRODUCTION
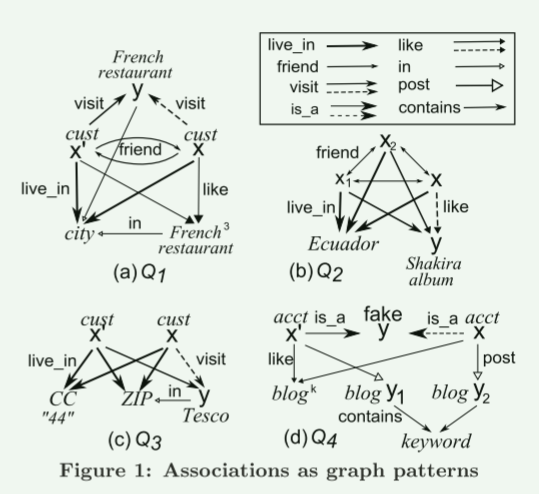
示例1:
(1) 社交图的关联规则是在图上而不是在项集上定义的。下面是一个例子。 ◦ 如果 (a) x 和 x′ 是住在同一个城市 c 的朋友,(b) c 中至少有 3 家 x 和 x′ 都喜欢的法国餐厅,并且如果 (c) x′ 访问一家新开的法国餐厅c 中的餐厅 y,则 x 也可能访问 y。
该规则的前件可以表示为图1(a)所示的图模式Q1(具有实线边缘),后件由虚线边缘visit(x,y)表示。 Q1 的简洁表示将整数 3 与“法国餐厅”相关联,以指示它的 3 个副本。与传统的关联规则不同,Q1 指定条件作为拓扑约束:客户之间的边(朋友关系)、客户和餐馆之间的边(喜欢、访问)、城市和餐馆之间的边(in)以及城市和客户之间的边(居住)。
在社交图G中,对于通过图模式匹配满足先行词Q1的x和y,我们可以将y推荐给x。
(2) 与项目集规则相反,社交图关联规则可能针对具有多个实体的社交群体: ◦ 如果 (a) x、x1 和 x2 是朋友,(b) 他们都住在厄瓜多尔,并且 (c) 如果x1,x2都喜欢夏奇拉的专辑y(哥伦比亚歌手),那么x可能也喜欢y。
该规则如图1(b)所示,其中图形模式Q2(不包括虚线边缘)指定(x,y)的条件作为前件,而像(x,y)这样的虚线边缘表示其结果。我们可以使用该规则来识别潜在客户 x 或 y,其特征是由三名成员组成的社交群体。
(3) 具有图模式的关联规则可以方便地扩展社交网络环境中的数据依赖关系,例如条件函数依赖关系(CFD)。 ◦ 如果 x 和 x′ 的地址具有相同的国家代码“44”和相同的邮政编码,并且如果 x′ 在具有相同邮政编码的 Tesco 商店 y 购物,则 x 也可能在 y 购物。
这样的规则(图 1(c))在其模式 Q3 中嵌入了相应的 CFD,表明如果 x 和 x′ 居住在英国,具有相同的邮政编码,那么他们就住在同一条街道上。该规则在英国有效,其中邮政编码决定街道。
(4)关联规则的应用不限于营销活动。他们还帮助我们检测诈骗。例如,下面的规则用于识别虚假帐户。 ◦ 如果 (a) 帐户 x′ 被确认是假的,(b) x 和 x′ 都像博客 P1,.... ,Pk,(c) x 发布博客 y1,(d) x′ 发布 y2,以及 (e) 如果 y1 和 y2 包含相同的特定内容(关键字),则 x 很可能是假帐户。
如图1(d)所示,其前件由图模式Q4给出(不包括虚线边缘),其结果是虚线边缘是a(x,fake)。在社交图 G 中,规则是识别虚假帐户的嫌疑人,即满足模式 Q4 的结构约束的帐户 x。
在社交媒体营销、社区结构分析、社交推荐、知识提取和链接预测中,对图模式关联规则(GPAR)的需求是显而易见的。然而,此类规则背离了项集的关联规则,并引入了一些挑战。 (1) 传统的支持度和置信度指标不再适用于 GPAR。 (2)传统规则和频繁图模式的挖掘算法不能用于发现实用的多样化GPAR。 (3) GPAR 的一个主要应用是识别社交图中的潜在客户。这是昂贵的:通过子图同构进行图模式匹配是很棘手的。更糟糕的是,现实生活中的社交图谱通常很大,例如 Facebook 拥有 131 亿个节点和 1 万亿个链接。
贡献:
(1)我们引入了社交媒体营销的图形模式关联规则(GPAR)(第 2 节)。 GPAR 在语法和语义上都不同于项集的常规规则。 GPAR 将其先行词定义为图模式,指定社交图中实体之间的关联,并探索社交链接、影响力和推荐。它通过值绑定(例如“44”)和子图同构的拓扑约束来强制执行条件。
(2) 我们定义 GPAR 的拓扑支持和置信度度量(第 3 节)。对项集的传统支持对于 GPAR 来说不再是反单调的。我们通过修改[7]提出的措施来定义不同“潜在客户”的支持。我们通过修改贝叶斯因子[31]以纳入局部封闭世界假设[11, 17],提出了 GPAR 的置信度度量。这使我们能够处理(不完整的)社交图,并识别具有相关前因和后果的有趣 GPAR。
(3)我们研究了一个新的挖掘问题,称为多样化挖掘问题,用DMP表示(第4节)。发现 top-k GPAR 是一个双标准优化问题。虽然 DMP 很有用,但它是 NP 难的。尽管如此,我们开发了一种具有恒定精度范围的并行近似算法。我们还提供优化方法来尽早过滤冗余或无希望的规则。
(4)我们还研究了如何应用GPAR来识别潜在客户,称为实体识别问题,用EIP表示(第5节)。给定社交图 G 和与事件 p(x, y) 相关的 GPAR 集合 Σ,我们通过使用 Σ 中的 GPAR,以高于给定界限 η 的置信度识别 G 中 y 的潜在客户 x。我们证明,甚至决定这样的 x 是否存在也是 NP 困难的。
(5) 使用现实生活和合成图,我们通过实验验证了我们算法的可扩展性和有效性(第 6 节)。我们发现以下内容。 (a) 我们的 DMP 和 EIP 算法随着处理器 (n) 的增加而很好地扩展:当 n 从 4 增加到 20 时,它们在现实社交网络上的平均速度分别快了 3.2 和 3.53 倍。(b)在大型图上工作得相当好:DMP 在具有 3000 万个节点和边的图上花费不到 9 分钟(533.2 秒),而 EIP 在具有 1.5 亿个节点和 24 个 GPAR 的边的图上花费 45 秒, 20 个处理器。 (c) DMP 算法从现实生活中的社交图中找到有趣的 GPAR。 (d) 我们的优化方法是有效的:它们在现实图表上分别将 DMP 和 EIP 处理速度提高了 1.52 倍和 1.27 倍。因此,尽管 GPAR 很复杂,但通过并行化在实践中应用和发现 GPAR 是可行的。
相关工作:
Association rules.在[4]中介绍,关联规则是在交易数据的关系上定义的。先前关于社交网络关联规则 [41] 和 RDF 知识库的工作诉诸于从社交图中提取属性的元组上挖掘传统规则和 Horn 规则(作为连接二元谓词)[17],而不是利用图模式。虽然[6]通过图模式研究时间相关规则,但它侧重于演化图,因此采用不同的语义来提供支持和置信度。
GPAR 将关联规则从关系扩展到图。 (a) 它需要拓扑支持和置信度度量。此外,不完整的信息在社交图中很常见[11, 17],必须纳入指标中。 (b) GPAR 使用同构函数进行解释,因此不能表示为联合查询,联合查询不支持函数所需的否定或不等式。 (c) 应用 GPAR 成为大图中多模式查询处理的一个棘手问题。 (d) 挖掘(多样化)GPAR 超出了项目集的规则挖掘[46]。
Graph pattern mining.图数据库中已有模式挖掘算法[22,24](有关调查,请参阅[25])。大规模挖掘技术也在单个图中进行了研究 [13],特别是 top-k 算法 [16,27,42,44]。为了降低成本,可以采用可扩展的子图同构算法(例如[38])来生成模式候选。那里没有研究图形模式的多样性。
然而,(a) 图数据库 [24,27] 上的模式挖掘不能用于挖掘 GPAR,因为它们的反单调属性在单个图中不成立 [25]。 (b) 虽然挖掘单图仅基于同构计数 [13],但除 [16,44] 之外,DMP 是 GPAR 置信度和多样性的双标准优化问题。我们不知道之前有关于发现多样化图模式的工作。
Graph pattern matching.已经开发了几种用于子图同构的并行算法,例如[28,37,38],以及用于多模式优化的并行算法,例如[23,32]。我们的 EIP 算法与之前的工作有以下不同之处。 (a) EIP 不是枚举同构匹配,而是在找到一个匹配后识别潜在客户,并计算其相关置信度。也就是说,EIP 超越了传统的子图同构。 (b)我们为多模式匹配提供并行可扩展算法。据我们所知,这些是大图上最早的算法之一,随着处理器的增加,保证比顺序算法的多项式加速[30]。 (c) 我们提出了以前的工作没有研究过的优化策略。也就是说,先前的优化技术可以合并到基于 GPAR 的实体识别中;例如,[32]中提取公共子模式的方法。
2. ASSOCIATION VIA GRAPH PATTERNS
2.1 Graphs, Patterns, and Pattern Matching
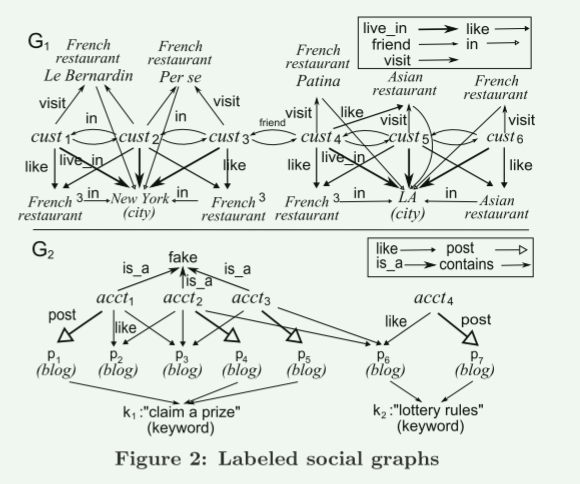
示例2:图2中示出了两个图G1和G2。 (1)图G1描绘了餐厅推荐网络。例如,cust1 和 cust2(标记为 cust)住在纽约;他们对 3 家法国餐厅有共同的兴趣(为简单起见,用上标 3 标记);他们还参观了纽约新开的法国餐厅“Le Bernadin”。 (2)图G2显示社交账户的活动。它包含 (a) 帐户 acct1、. 。 。 、acct4(标记为 acct)、(b) 博客 p1、. 。 。 ,p7; (c) 从帐户到博客的边。例如,edge post(acct1, p1) 表示帐户 acct1 发布博客 p1,其中包含关键字 w1“领取奖品”。
patterns: 模式查询Q是一个图(Vp,Ep,f,C),其中Vp和Ep分别是模式节点和边的集合; Vp 中的每个节点 up(分别为 Ep 中的边缘 ep)都有一个标签 f(up)(分别为 f(ep)),指定搜索条件,例如城市或用于值绑定的“44”(示例 1 的 Q3) 。为了简洁表示,节点 up 可以用整数 C(up) = k 来标记,表示 up 的 k 个副本具有相同的标签和公共邻域中的关联链接。
Graph pattern mining: 我们首先回顾子图的两个概念。 (1) 图 G′ = (V′, E′, L′) 是 G = (V, E, L) 的子图,记为 G′ ⊆ G,若 V′ ⊆ V,E′ ⊆ E,此外,对于每条边 e ∈ E′,L′(e) = L(e),对于每条 v ∈ V′,L′(v) = L(v)。 (2) 如果 G′ ⊆ G 并且 E′ 由 G 中端点都在 V′ 中的所有边组成,则我们说 G′ 是由节点集 V′ 导出的子图。
我们采用子图同构进行模式匹配。图 G 中模式 Q 的匹配是从 Q 的节点到 G 的子图 G′ 的节点的双射函数 h,使得 (a) 对于每个节点 u ∈ Vp,f(u) = L(h(u )),并且 (b) (u, u′) 是 Q 中的一条边当且仅当 (h(u), h(u′)) 是 G′ 中的一条边,并且 f(u, u′) = L(h(u), h(u′))。我们说 G′ 与 Q 匹配。
请注意,可以使用相似谓词代替等式“=”,这对我们的算法没有影响。
我们用 Q(G) 表示 G 中 Q 的所有匹配的集合。对于每个模式节点 u,我们使用 Q(u,G) 表示 Q(G) 中 u 的所有匹配的集合,即 Q( u,G) 由 G 中的节点 v 组成,使得存在一个函数 h,在该函数 h 下,子图 G′ ∈ Q(G) 同构于 Q,v ∈ G′ 且 h(u) = v。
示例3:对于图1的Q1和图2的G1,Q1(G)中的匹配是x |→ cust1,x′ |→ cust2,city|→纽约,y |→ Le Bernardin,和法国餐厅3到 3 家法国餐厅。这里 Q1(x,G1) 包括 cust1–cust3 和 cust5。
模式 Q′ = (V′ p, E′ p, f′, C′) 被另一个模式 Q = (Vp, Ep, f, C) 包含,表示为 Q′ ⊑ Q,如果 (V′ p,E'p)是(Vp,Ep)的子图,函数f'和C'分别是V中f和C的限制。观察到,如果 Q′ ⊑ Q,则对于任何与 Q 匹配的图 G′,都存在 G′ 的子图 G′′,使得 G′′ 与 Q′ 匹配。
2.2 Graph Pattern Association Rules
GPAR: 图模式关联规则 (GPAR) R(x, y) 定义为 Q(x, y) ⇒ q(x, y),其中 Q(x, y) 是图模式,其中x 和y为2个指定节点,q(x,y)是从x到y的标记为q的边,其上施加与Q中相同的搜索条件。我们将 Q 和q分别称为 R 的前件和后件。
该规则规定,对于(社交)图 G 中的所有节点 vx 和 vy,如果存在匹配 h ∈ Q(G),使得 h(x) = vx 且 h(y) = vy,即 vx 和 vy分别匹配 Q 中指定的节点 x 和 y,则结果 q(vx, vy) 可能成立。直观上,vx是vy的潜在客户。
我们通过用(点)边 q(x, y) 扩展 Q,将 R(x, y) 建模为图形模式 PR。当上下文清楚时,我们将模式 PR 称为 R。我们将 q(x, y) 视为模式 Pq,将 q(x,G) 视为 G 中 x 与 Pq 的匹配集。
我们考虑实际和非平凡的 GPAR,要求 (1) PR 是连通的 (2) Q非空,即至少有一条边; (3) q(x, y) 没有出现在 Q 中。
示例 4:回想一下示例 1 中描述的第一个关联规则。它可以表示为 GPAR R1(x, y):Q1(x, y) ⇒ Visit(x, y),其中它的先行词是给出的模式 Q1例1,其结果是visit(x, y)。 GPAR 可以被描述为图 1(a) 的图模式,通过用虚线边visit (x, y)来扩展 Q1(x, y)。示例 1 的最后一条规则写为 R4(x, y): Q4(x, y) ⇒ 是 a(x, y),其中 Q4 中,y = fake 是值绑定。 GPAR如图1(d)所示。在 is a(x, y) 中,施加相同的搜索条件 y = fake。
为了简化讨论,我们按照[4]用单个谓词 q(x, y) 定义 GPAR 的后件。然而,结果可以很容易地扩展到多个谓词,甚至扩展到图模式。 (2) 传统的关联规则[4]和一系列预测,分类规则[39]是GPAR的特殊情况,因为它们的前因可以被建模为节点表示项目的图模式。条件函数依赖[14]也可以用GPAR来表示(见图1(c)的Q3)。
3. SUPPORT AND CONFIDENCE
支持度:图 G 中图模式 Q 的支持度,用 support(Q, G) 表示,表示 Q 的适用频率。对于项集的关联规则,支持度应该是反单调的,即对于模式 Q 和 Q′,如果 Q′ ⊑ Q,则在任意图 G 中,supp(Q′, G) ≥ support(Q, G) )。
人们可能想要将supp(Q, G)定义为数字||Q(G)|| Q(G) 中 Q 的匹配项,遵循项集的对应项 [46]。然而,正如[7,13,25]中所观察到的,这种传统概念并不是反单调的。例如,考虑具有标记为 cust 的单个节点的模式 Q',以及具有单个边(例如(cust,法国餐厅))的 Q。当摆在 G1 上时,||Q(G)|| = 18 > ||Q′(G)|| = 6(因为法国餐厅 3 表示 3 个标记为法国餐厅的节点),尽管 Q′ ⊑ Q.
为了解决这个问题,我们修改了[7]中提出的支持措施。我们将 Q 的指定节点 x 的支持度定义为 ||Q(x,G)||,即 Q(G) 中 x 的不同匹配的数量。我们将 G 中 Q 的支持度定义为
supp(Q, G) = ||Q(x,G)||.
我们可以验证这一支持措施是反单调的。
对于GPAR R(x, y):Q(x, y) ⇒ q(x, y),我们定义 supp(R, G) = ||PR(x,G)||.
示例 5:对于示例4中的 GPAR R1(x, y):Q1(x, y) ⇒ visit(x, y) 和图 2 的图 G1, (1) ||Q1(x,G1)|| = 4(参见示例 3);因此supp(Q1, G1) 是4; (2) support(R1, G1) = ||PR1 (x,G1)|| = 3,其中 x 有 3 个匹配 cust1–cust3。
类似地,考虑 R4(x, y):Q4(x, y) ⇒ is_a(x, y) 和图 2 中的图 G2,其中 y = fake。当k=2时,supp(R4,G2)=supp(Q4,G2)=||Q4(x,G2)||=3,匹配 Q4 中指定节点 x 的 acct1–acct3。
Confidence: 为了找出当 x 和 y 满足 Q(x, y) 约束时 q(x, y) 成立的可能性有多大,我们研究 R(x, y) 在 G 中的置信度,表示为 conf(R, G)。人们可能希望采用关联规则的传统置信度,并将conf(R,G)定义为supp(R,G)supp(Q,G)。也就是说,Q 中但 R 中不存在的每个匹配 x 都被视为 R 的负例。然而,如 [11, 17] 中观察到的,标准置信度对“负”和“未知”之间的区别视而不见。当 G 不完整时,这尤其是一种矫枉过正的行为。
示例 6:考虑图 1(b) 中的模式 Q2。令 Q2(x,G) 包含社交图 G 中 x1、x2、x3 的三个匹配项 v1、v2、v3,均居住在厄瓜多尔,其中 (1) v1 具有类似于 Shakira 专辑的边缘,(2) v2 具有像MJ的专辑一样只有一个边缘,而(3)v3没有像MJ的专辑那样的类型边缘。传统置信度将 v2 和 v3 均视为反例,conf(R2, G) = 1 3 。然而,G可能并不完整:v3还没有进入任何她喜欢的专辑。因此我们应该将 v3 视为“未知”,而不是作为 R2 的反例。
事实上,封闭世界假设可能不适用于社交网络[34]。为了区分不完整社交网络中 GPAR 挖掘的“未知”案例和真负例,我们采用局部封闭世界假设 [11, 17],这通常用于挖掘不完整知识库。
局部封闭世界假设(LCWA)。给定谓词 q(x, y),我们引入以下符号。
(1)supp(q,G)=||Pq(x,G)||,x的匹配数;
(2)supp(¯q, G),G中(a)与x具有相同标签、(b)至少有一条q类型边的节点u的数量,但(c) u 不∈ Pq( x,G);
(3)supp(Q¯q,G),满足(2)的条件(a)至(c)且也在Q(x,G)中的节点的数量。
(1) “正”情况,如果 u ∈ Pq(x,G); (2) “负”情况,对于在supp(¯q, G)中计数的每个u; (3)“未知”情况,对于满足 x 搜索条件但没有标记为 q 的边的每个 u。
也就是说,G 被假定为“局部完整”:它要么给出 u 与谓词 q 相关的所有正确局部信息,要么对节点 u 处的 q 一无所知(因此未知情况)。
基于LCWA,我们通过修改关联规则[31]的贝叶斯因子(BF)来定义conf(R,G)如下:
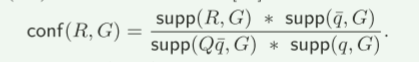
直观上,conf(R,G) 衡量完整性和判别性的乘积。如果 GPAR R(x, y) 持有 Q(x, y) 的更多匹配 x,则它具有更好的完整性,并且如果它不太可能持有来自 Q¯q 的更多节点,则更具判别性。此外,基于 BF 的 conf(R, G) 比传统置信度更合理。正如[26, 31]中所验证的,BF满足一系列合理兴趣度度量的原则,包括在独立性下固定(如果Q和q在统计上独立,则conf(R,G)= 1),在不相容性下固定(conf(R,G)= 1)如果supp(R, G)=0,则G)=0),并且单调性(当supp(¯q, G)、supp(Q, G)和supp(q, G)为固定的)。因此,我们通过结合 LCWA 和拓扑支持来调整 BF。
示例 7:考虑示例 6 中描述的 GPAR R2 和 Q2(x,G)。在 LCWA 下,匹配 v1 说明 R2 为“正”,而 v2 和 v3 分别为“负”和“未知”。事实上,假设G为v2提供了完整的本地信息,那么v2对于居住在厄瓜多尔但不喜欢Shakira专辑的人来说是一个反例;相比之下,G 对 v3 喜欢什么专辑一无所知。可以看到,supp(R2, G) = 1(匹配 v1)、supp(́q, G) = 1(匹配 v2)、supp(Q̅q, G) = 1(匹配 v2)和supp(q , G) = 1(匹配 v1)。基于 BF 的置信度 conf(R2, G) 为 1,大于其传统对应项 (1/3 ),因为 LCWA 消除了未知情况 v3 的影响。

4. DIVERSIFIED RULE DISCOVERY
4.1 The Diversified Mining Problem
我们对特定事件 q(x, y) 的 GPAR 感兴趣。然而,这通常会产生过多的规则,这些规则通常适用于相同或相似的人 [5, 44]。这激励我们研究多样化的挖掘问题,发现有趣且多样化的 GPAR。
目标函数。为了形式化这个问题,我们首先定义一个函数 diff(, ) 来测量 GPAR 的差异。给定两个 GPAR R1 和 R2,diff(R1, R2) 定义为
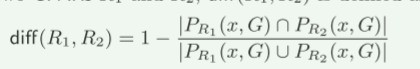
就他们的匹配集(作为社交群体)的杰卡德距离而言。当推荐的项目过于“同质”时,这种多样化已被用来对抗社交推荐系统中的过度集中[5]。
给定属于相同谓词 q(x, y) 的 k 个 GPAR 集合 Lk,我们按照社交推荐系统的实践再次定义目标函数 F(Lk) [19]:
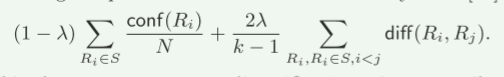
这被称为最大和多样化,旨在通过用户控制的参数 λ 在兴趣性(通过修订的贝叶斯因子衡量)和多样性(通过距离 diff(, ))之间取得平衡。我们用conf(R, G) ∈ [0,supp(R,G)*supp(́q,G)]考虑非平凡的GPAR(第3节),并用N=supp(q, G) ∗supp(¯q, G)(固定 q(x, y) 的常数),以及 (2) 具有2λ/k−1的多样性度量,因为有 k(k−1)/2个数字表示差异sum,而置信度和只有 k 个数字。

示例 8:考虑图 1 中的 GPAR R1 以及图 3 中所示的 R7 和 R8,它们都与visit(x,法国餐厅)有关。然后在图G1(图2)中,(1)supp(q,G1)= 5(cust1-cust4,cust6),supp(¯q,G1)= 1(cust5); (2) R1(x,G1) = R7(x,G1)= {cust1, cust2, cust3}, R8(x,G1) = {cust6}; (3)conf(R1,G1)=conf(R7,G1)=0.6,conf(R8,G1)=0.2; (4) diff(R1, R7) = 0, diff(R1, R8) = diff(R7, R8) = 1。对于 λ = 0.5,这些 GPAR 的 top-2 多样化集合为 {R7, R8},其中F(R7, R8) = 0.5*0.8 5 +1*1 = 1.08(与 {R1, R8} 类似)。事实上,R7 和 R8 发现两个不相交的客户群体分别与他们的朋友分享对法国餐厅和亚洲餐厅的兴趣。
问题: 基于目标函数,多样化GPAR挖掘问题(DMP)表述如下。 ◦ 输入:图 G、谓词 q(x, y)、支持界 σ 以及正整数 k 和 d。 ◦ 输出:与 q(x, y) 相关的 k 个非平凡 GPAR 的集合 Lk,使得 (a) F(Lk) 最大化; (b) 对于每个 GPAR R ∈ Lk,supp(R, G) ≥ σ 且 r(PR, x) ≤ d。
DMP 是一个双标准优化问题,用于发现特定事件 q(x, y) 的 GPAR,具有高支持度、有界半径以及平衡的置信度和多样性。在实践中,用户可以自由指定兴趣的 q(x, y),而适当的参数(例如,支持度、置信度、多样性)可以从查询日志中估计或由领域专家推荐。
4.2 Discovery Algorithm
人们可能想要遵循一种“发现和多样化”方法,即 (1) 首先通过频繁的图模式挖掘找到与 q(x, y) 有关的所有 GPAR [35],然后 (2) 通过结果多样化选择前 k 个 GPAR [19]。然而,这样做的代价是昂贵的: (a) 生成过多数量的 GPAR; (b) 对于生成的所有 GPAR R,它必须计算 conf(R, G) 及其成对距离,并且基于 F() 选择一个 top-k 集合;后者本身就是一个棘手的过程。
定理 2:存在一种 DMP 并行算法,该算法找到前 k 个多样化 GPAR 的集合 Lk,使得 (a) Lk 的近似率为 2,并且 (b) Lk 通过使用 n 个处理器在 d 轮中发现,并且每轮最多需要 t(|G|/n, k, |Σ|) 时间,其中 Σ 是 GPAR R(x, y) 的集合,使得 supp(R, G) ≥ σ 且 r(PR, x) ≤ d.

作为证明,我们给出这样一个算法,记为DMine,如图4所示。它指定一个处理器作为协调器Sc,其余的作为工作器Si。其工作原理如下。
(1) 将 G 分为 n−1 个片段 (F1,...,Fn−1),使得 (a) 对于满足 q(x, y) 中 x 搜索条件的每个“候选”vx,其 d -邻居Gd(vx),即Nd(vx)诱导的G的子图,在某个片段中; (b) 碎片的大小大致均匀。这些都是可能的,因为 98% 的现实生活模式的半径为 1,1.8% 的半径为 2 [18],并且社交图中的平均节点度为 14.3 [8];因此,与片段大小相比,Gd(vx) 通常较小。
(2) DMine 通过批量同步处理在 d 轮中并行发现 GPAR。协调器 Sc 维护一个多样化的 top-k GPAR 列表 Lk,最初是空的。在每一轮中,(a) Sc 向所有工作人员发布一组 M 个 GPAR,最初仅 q(x, y); (b) 每个工作者 Si 在 Fi 本地并行生成 GPAR,如果可能的话,通过用新边扩展 M 中的 GPAR; (c) 这些GPAR由Sc在屏障同步阶段收集和组装;并且,Sc增量更新Lk:尽早过滤掉支持度较低或无法进入top-k的GPAR,并准备一组M个GPAR用于下一轮的扩容。
与“发现+多元化”的方式相反,DMine (a)将多元化与发现结合起来,尽早终止无前途规则的扩张,而不是发现后才进行多元化; (b) 它增量地计算 top-k 多样化匹配,而不是从头开始重新计算多样化函数 F()。接下来我们介绍 DMine 算法的细节。
算法。 DMine 将 Lk 和 Σ 初始化为空,将 M 初始化为 {q(x, y)}(第 1 行)。对于从 1 到 d 的 r,它通过合并半径为 r 的 GPAR(第 2-11 行)并遵循水平方法来改进 Lk。在每一轮中,它都会在所有工作线程中使用 M 调用 localMine(第 4 行)。下面我们就来详细介绍一下。
并行 GPAR 生成(第 13 行)。在第一轮中,过程 localMine 接收来自 Sc 的 q(x, y),并计算以下内容: (a) 三个集合:Ci、在发现的 GPAR 中满足 x 搜索条件的节点 vx、Pq(x,Fi), q(x, y) 中 x 的匹配,和 Fi 中的节点 v 的匹配,该节点 v 说明了supp(¯q, Fi)(第 2.2 节); (b)supp(q, Fi) = ||Pq(x,Fi)||,supp(́q, Fi) = ||Ṕq(x,Fi)||。请注意,supp(q, Fi) 和supp(́q, Fi) 永远不会改变,因此是一次性导出的。每个匹配 vx ∈ q(x,Fi) 被称为中心节点。
在第 r 轮中,在从 Sc 接收到 M 后,localMine 会执行以下操作。对于 M 中的每个 GPAR R(x, y) : Q(x, y) ⇒ q(x, y) 和每个中心节点 vx,它通过包含至少一个位于 vx 跳 r 处的新边来扩展 Q,对于所有这样的边缘。
消息构造(第 14-15 行)。对于每个 GPAR R(x, y): Q(x, y) ⇒ q(x, y),计算其局部置信度conf: (1)supp(R, Fi) 和supp(Q, Fi) 计数节点Pq(x,Fi) 和 Ci 分别与 R(x, y) 和 Q(x, y) 中的 x 匹配; (2)supp(Q¯q, Fi) = ||Q(x,Fi) ∩ P¯q(x,Fi)||。那么conf包含supp(R, Fi)、supp(Q́q, Fi)、supp(q, Fi)和supp(́q(x,Fi));其中supp(q, Fi) 和supp(¯q, Fi) 值来自第一轮。还设置一个布尔标志来指示是否可以通过检查是否存在与 vx 相距 r+1 跳具有边的中心节点 vx 来扩展 R。消息Mi包括每个R的<R,conf,flag>,并且被发送到Sc。
消息组装(第 4-7 行)。在从每个 Si 接收到 Mi 后,协调器 Sc 执行以下操作。 (1) 它将来自所有 Mi 的自同构 GPAR 分组。 (2) 对于引用相同(自同构)R 的每组 mi = <R, confi, flagi>,它将 conf(R) 组装成单个 m = <R, conf(R, G), flag>,其中 (a)conf(R,G)= supp(R,Fi)
supp(́q,Fi)/
supp(Q́q,Fi)
supp(q,Fi) ; (b) flag 是所有 flagi 的析取,因为 i ∈ [1, n − 1]。这就足够了,因为通过图 G 的划分,如果 i 不等于 j,则 Fi 中占本地支持的节点与 Fj 中的节点不相交;因此conf(R)可以直接从Fi的本地conf组装而成。类似地,supp(R, G) =
i∈[1,n−1]supp(R, Fi)。对于每个 GPAR R,如果 supp(R, G) ≥ σ,则将其添加到 ΔE 和 Σ。
增量多样化(第 8-9 行)。接下来,DMine 通过调用过程 incDiv 增量更新 Lk。它使用大小为 ⌈k/2⌉ 的最大优先级队列,其中 (1) 队列中的每个元素都是一对 GPAR,并且 (2) 队列中的所有 GPAR 对都是成对不相交的。在 r 轮中,从半径最大为 r − 1 的 top-k 多样化 GPAR 队列开始,DMine 通过合并来自 ΔE 的半径为 r 的 GPAR 对来改进队列。 (1) 如果队列包含少于 ⌈k/2⌉ 个GPAR 对,则 incDiv 迭代地从 ΔE 中选择两个不同的 GPAR R 和 R′,以最大化修订后的多样化函数:
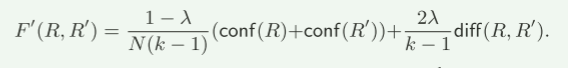
并将(R, R′)插入Queue,直到|Queue| = ⌈k/2⌉。它记录每对 (R, R') 和 F'(R, R')。 (2) 如果 |Queue|=⌈k/2⌉,对于每个新的 GPAR R ε ΔE(不在任何一对 Queue 中)和 R′ ε Σ,它增量计算并添加一个新的对 (R, R′) ε ΔE×Σ 最大化 F′(R, R′) 到队列。如果 F'(R1, R2) < F'(R, R'),这可确保具有最小 F'(R1, R2) 的对 (R1, R2) 被 (R, R') 替换。
Sc 处的消息生成(第 10-11 行)。接下来,DMine 选择有前途的 GPAR,以便在工作线程中进一步并行扩展。其中包括满足两个条件的 R ε ΔE: (1) support(R, G) ≥ σ,因为根据支持的反单调性质,如果 support(R, G) < σ,则 R 的任何扩展都不能具有支持不小于σ; (2) R 是“可扩展的”,即 <R,conf,flag> 中的 flag = true。它将这样的R包含在M中,并将M发布给下一轮的所有工作器。
示例9:假设图 2 中的图 G1 分配给两个工作器 S1 和 S2,其中 S1(S2)包含由 cust1-cust3(cust4-cust6)及其在 G1 中的 2 跳邻域导出的子图。令谓词q 为visits(x, 法国餐厅),λ=0.5,d=2 且k=2。我们使用示例 GPAR R5-R8 演示算法 DMine(图 3)。

(1)协调器Sc将q发送给所有worker,并计算supp(q, G1) = 5 (cust1-cust4, cust6),supp(¯q, G1) = 1 (cust5)。
(2) 在第 1 轮中,R5(以及其他)是在 S1 处从 cust1-cust3 的 1hop 邻居生成的,它们是 q(x,G1) 中的匹配(图 3)。在S2处,R5和R6是通过扩展cust4和cust6生成的。来自 Si 的本地消息 Mi 包括以下内容:
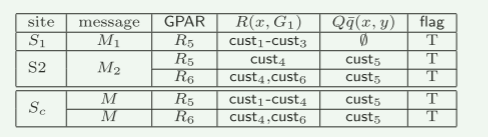
(3)协调器Sc组装M1和M2,并构建包括{R5,R6}的ΔE。它计算conf(R5) = 0.8、conf(R6) = 0.4、diff(R5, R6) = 0.8。它更新 Lk = {R5, R6},其中 F′(R5, R6) = 0.5* 1.2 5 +1*0.8 = 0.92。它在消息M(上表)中包含R5和R6,并将其发布到S1和S2。
(4)在第2轮中,R5在S1和S2处扩展为R7和R1,在S2处R6扩展为R8(图3);这些消息包括:

(5)给定这些,协调器Sc组装消息并计算conf(R7)=0.6、conf(R8)=0.2和diff(R7,R8)=1。 DMine 计算 F′(R7, R8) = 0.5 * 0.8 5 +1 * 1=1.08 > F′(R5, R6)=0.92。因此,它用(R7,R8)替换(R5,R6)并将Lk更新为{R7,R8}。由于 R7 和 R8 在半径 2 处被标记为“不可扩展”(因为 d=2),DMine 将 {R7, R8} 返回为前 2 个多元化 GPAR,总共 2 轮。
5. IDENTIFYING CUSTOMERS
我们研究如何通过 GPAR 识别潜在客户。考虑属于相同 q(x, y) 的 GPAR 集合 Σ,即它们的结果是相同的事件 q(x, y)。我们在(社交)图 G 中定义由 Σ 标识的实体集合,置信度为 η,用 Σ(x,G, η) 表示,如下所示:
![]()
就是找到G中的潜在客户x of y,并由Σ中至少一个GPAR识别,置信度至少为η。
6. EXPERIMENTAL STUDY
使用现实生活和合成图,我们进行了三组实验来评估(1)DMine 算法的可扩展性,(2)DMine 发现有趣 GPAR 的有效性,以及(3)Match 算法在大图中识别潜在客户的可扩展性。
模式生成器。为了评估匹配,我们生成了由数字 |Vp| 控制的 GPAR R和 |Ep|分别是 PR 中的节点和边。 (1) 我们在 Pokec 和 Google+ 上均发现了 48 个有意义的 GPAR,其标签来自其数据(领域、社交群体)。 (2) 对于合成图,我们还生成了 24 个 GPAR,其标签来自 L。我们将 GPAR R 的大小表示为 |R|= (|Vp|, |Ep|)。
算法。我们实现了以下内容,全部用 Java 实现。 (1) 算法 DMine,与 (a) DMineno(其未优化的对应算法(增量、归约和双相似性检查))和 (b) GRAMI [13](一种开源频繁子图挖掘工具 [1])进行比较。由于 GRAMI 使用单台机器 [1],我们仅将 GRAMI 发现的模式的有趣程度与 DMine 发现的 GPAR 进行比较。 (2)算法匹配,与(a)Matchc(第5.1节),(b)disVF2,EIP的VF2的并行实现,以及(c)匹配,使用[38]的方法代替VF2进行匹配。
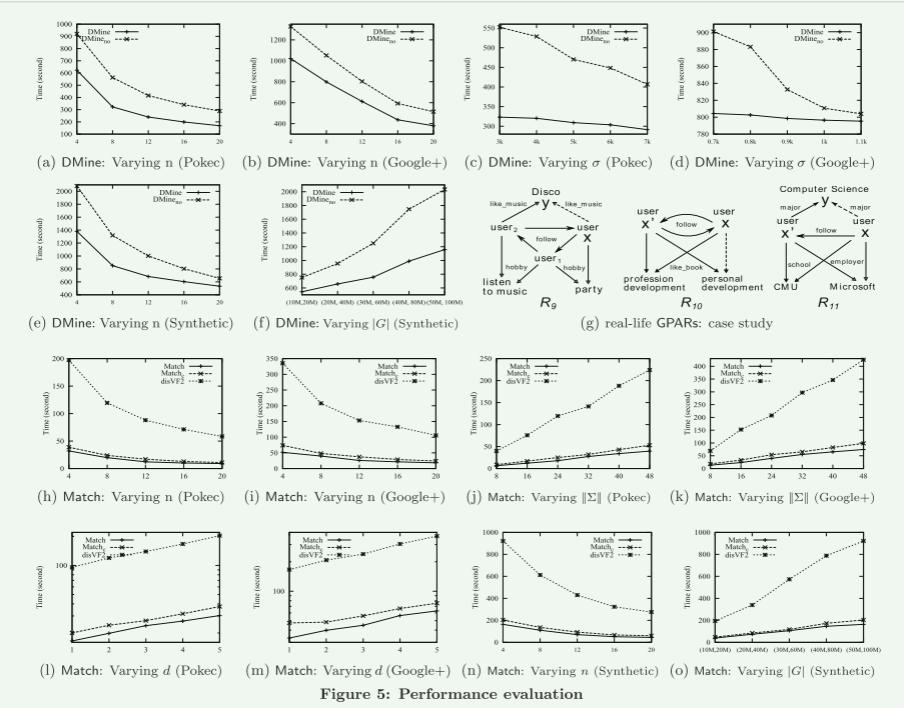
Effectiveness of DMine.我们手动检查了 DMine 从 Pokec 和 Google+ 发现的 GPAR。图 5(g) 显示了三个 GPAR,支持度在 100 以上:
(1)R9(Pokec):如果x关注user1,user1关注user2,user2关注x,user1和user2都有听音乐的爱好,x和user1有聚会的爱好,如果user2喜欢迪斯科音乐,则x喜欢迪斯科。这表明人们喜欢的音乐类型和朋友的爱好之间存在规律性。
(2)R10(Pokec):如果x和x′相互跟随并且都喜欢职业发展书籍,并且如果x′喜欢关于个人发展的书籍,那么x也喜欢。这表明潜在客户喜欢他们朋友喜欢的书籍。
(3)R11(Google+):如果x跟随x′,则x和x′都去了CMU,x和x′都是微软的员工,如果x′是CS专业,那么x也可能是CS专业。这表明了微软员工和卡耐基梅隆大学计算机科学专业学生之间的社交模式。
我们还发现 GRAMI 挖掘的大多数模式都是用户圈子。这些模式虽然相当频繁,但很少揭示有关实体关联的见解。
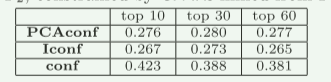
如上表所示,(1) DMine 能够识别“预测”谓词的 GPAR,平均精度高达 42.3%,(2) 按我们的 conf 指标排名的 GPAR 提供比 PCAconf 和 Iconf 更好的预测精度。
概括。我们发现以下内容。 (1)在大型社交网络中挖掘多样化的top-k GPAR并不是很昂贵。例如,DMine 在 |G| 的图表上花费 533.2 秒= (10M,20M) 通过使用 20 个处理器,当 k = 10,σ = 100 和 d = 2 时。 (2) 候选 GPAR 的数量不是很大(最多 300 个),因此 DMine 是“并行可扩展的” (第 5.1 节):在现实世界的社交网络上,当 n 从 4 增加到 20 时,平均速度提高 3.2 倍。 (3) 此外,基于我们的conf度量发现的GPAR比其PCA和基于图像的对应物能够更准确地预测社交网络中的潜在客户。 (4) 匹配是并行可扩展的:当 n 从 4 增加到 20 时,比现实生活中的社交网络平均快 3.53 倍。 (5) 将 GPAR 应用于大图是实用的:在具有 |G| 的图上= (50M, 100M) 和 24 个 GPAR 的集合 Σ,使用 20 个处理器进行匹配只需不到 45 秒。 (6) 我们的优化策略是有效的:平均而言,DMine 比 DMineno 快 1.52 倍,Match 分别比 Matchc 和 disVF2 快 1.27 倍和 6.24 倍。
7. CONCLUSION
我们提出了与图模式(GPAR)的关联规则,从语法、语义到支持度和置信度指标。我们研究了 DMP 和 EIP,分别用于挖掘 GPAR 和通过 GPAR 识别潜在客户,从复杂性到并行(可扩展)算法。我们的实验研究证明,虽然DMP和EIP很困难,但GPAR的发现和实际应用是可行的。我们认为 GPAR 为社交媒体营销以及其他应用提供了一种很有前途的工具。
我们目前正在探索现实生活中的社交图谱进行实验。未来工作的另一个主题是通过支持图模式作为结果并允许其他匹配语义(例如图形模拟)来扩展 GPAR。

