
- 1代码管理--svnadmin工具介绍_svnadmin2
- 2Blazor第三方组件库推荐:BootstrapBlazor UI_bootstrap blazor
- 3“互联网寒冬”来袭,软件测试人员该如何度过这次危机?_测试人员如何破冰
- 4Hadoop+Spark 大数据分析(一)之 虚拟机安装及Java环境的配置_vmware虚拟机上基于spark的大数据分析
- 5LSTM微博评论情绪识别二分类项目jieba分词遇到的问题
- 6SpringCloud--Eureka集群
- 7Python驱动的智能客服系统构建实录
- 8YOLO标注工具(适用于YOLO-OBB,可画旋转框)——JieLabel(自带训练和识别工具)
- 9C/C++---字符分布分割得到数字,适用于STM32/ESP32等等_stm32 字符串分割转数组
- 10配置 Druid 数据源及密码加密-SpringBoot 2.7 实战基础_druid默认账号密码
AGI 之 【Hugging Face】 的[ 简单介绍 ] [ 基础环境搭建 ] 的简单整理_huggingface 开发环境安装
赞
踩
AGI 之 【Hugging Face】 的[ 简单介绍 ] [ 基础环境搭建 ] 的简单整理
目录
AGI 之 【Hugging Face】 的[ 简单介绍 ] [ 基础环境搭建 ] 的简单整理
一、简单介绍
AGI,即通用人工智能(Artificial General Intelligence),是一种具备人类智能水平的人工智能系统。它不仅能够执行特定的任务,而且能够理解、学习和应用知识于广泛的问题解决中,具有较高的自主性和适应性。AGI的能力包括但不限于自我学习、自我改进、自我调整,并能在没有人为干预的情况下解决各种复杂问题。
AGI能做的事情非常广泛:
- 跨领域任务执行:AGI能够处理多领域的任务,不受限于特定应用场景。
- 自主学习与适应:AGI能够从经验中学习,并适应新环境和新情境。
- 创造性思考:AGI能够进行创新思维,提出新的解决方案。
- 社会交互:AGI能够与人类进行复杂的社会交互,理解情感和社会信号。
关于AGI的未来发展前景,它被认为是人工智能研究的最终目标之一,具有巨大的变革潜力:
- 技术创新:随着机器学习、神经网络等技术的进步,AGI的实现可能会越来越接近。
- 跨学科整合:实现AGI需要整合计算机科学、神经科学、心理学等多个学科的知识。
- 伦理和社会考量:AGI的发展需要考虑隐私、安全和就业等伦理和社会问题。
- 增强学习和自适应能力:未来的AGI系统可能利用先进的算法,从环境中学习并优化行为。
- 多模态交互:AGI将具备多种感知和交互方式,与人类和其他系统交互。
Hugging Face作为当前全球最受欢迎的开源机器学习社区和平台之一,在AGI时代扮演着重要角色。它提供了丰富的预训练模型和数据集资源,推动了机器学习领域的发展。Hugging Face的特点在于易用性和开放性,通过其Transformers库,为用户提供了方便的模型处理文本的方式。随着AI技术的发展,Hugging Face社区将继续发挥重要作用,推动AI技术的发展和应用,尤其是在多模态AI技术发展方面,Hugging Face社区将扩展其模型和数据集的多样性,包括图像、音频和视频等多模态数据。
在AGI时代,Hugging Face可能会通过以下方式发挥作用:
- 模型共享:作为模型共享的平台,Hugging Face将继续促进先进的AGI模型的共享和协作。
- 开源生态:Hugging Face的开源生态将有助于加速AGI技术的发展和创新。
- 工具和服务:提供丰富的工具和服务,支持开发者和研究者在AGI领域的研究和应用。
- 伦理和社会责任:Hugging Face注重AI伦理,将推动负责任的AGI模型开发和应用,确保技术进步同时符合伦理标准
AGI作为未来人工智能的高级形态,具有广泛的应用前景,而Hugging Face作为开源社区,将在推动AGI的发展和应用中扮演关键角色。
二、Hugging Face
Hugging Face 官网:https://huggingface.co/
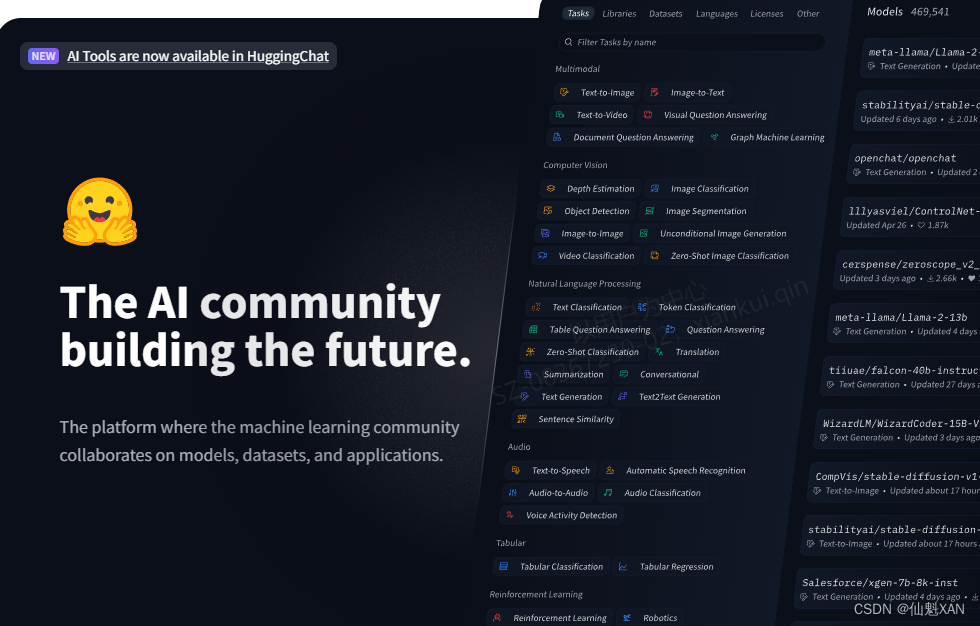
Hugging Face 是一个专注于自然语言处理(NLP)领域的开源人工智能社区和平台。它提供了一系列的工具和库,使得研究人员、开发者和数据科学家能够更容易地构建、训练和部署机器学习模型,特别是在处理文本数据时。Hugging Face 最著名的产品是 Transformers 库,这是一个包含了大量预训练模型(如BERT、GPT-2等)的集合,支持多种NLP任务,如文本分类、问答、机器翻译等 。
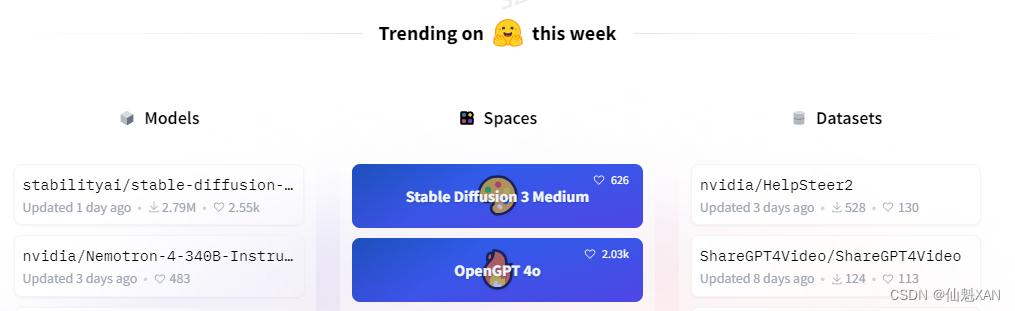
Hugging Face 的名字来源于其创始人对于构建一个有趣、友好且能够与人类进行自然对话的人工智能聊天机器人的愿景。他们希望创建的AI能够像朋友一样与人们拥抱(hug),提供温暖和亲切的交流体验,这正是“Hugging Face”这个名称所要传达的含义。
Hugging Face 的发展:
- Hugging Face 成立于2016年,迅速发展成为一个活跃的开源社区,专注于分享和改进机器学习模型
- 它以开源精神为核心,由创始人Clem Delangue在大学时期就开始构建,最初目标是创建一个开放领域的、会话式的AI聊天机器人
- 通过发布自定义版本的BERT模型,Hugging Face 转型为一个开源社区,其模型在 GitHub 上获得了极大的关注和使用
- Hugging Face 不断扩大其影响力,与谷歌云等大型企业建立战略合作伙伴关系,并在多个领域获得认可和奖项
Hugging Face 的优势:
- 开源精神:Hugging Face 鼓励开放科学和开源,促进了社区的参与和创新
- 丰富的资源:提供了大量的预训练模型和数据集,覆盖了多种NLP任务
- 易用性:通过提供简单易用的API和工具,Hugging Face 使得研究人员和开发人员能够快速集成和使用其资源
- 社区支持:拥有一个活跃的社区,用户可以共享知识、讨论问题并共同推动技术发展
- 技术创新:Hugging Face 通过不断的技术创新,如Transformers库,加速了NLP任务的研究和开发
Hugging Face 能做什么:
- 提供预训练模型:如BERT、GPT系列和Transformer系列等,支持多种NLP任务
- 数据集共享:提供大量真实世界的数据集,涵盖文本分类、命名实体识别、问答系统等多个领域
- 工具和框架:如Transformers库和Datasets库,支持用户构建和训练自己的NLP应用程序
- 模型训练和部署:通过Hugging Face Accelerate项目支持多GPU/TPU训练,以及模型的微调和部署
- 跨模态应用:除了NLP,Hugging Face 还支持计算机视觉、音频处理等多模态任务
- 推理服务:提供推理端点,简化模型部署过程,使得用户可以轻松地将模型集成到应用中
三、环境搭建
系统环境:Windows 10 ,Python, Pycharm
python 环境的搭建
1、Python 安装包下载
下载地址 :Download Python | Python.org,选择单击你需要的版本下载安装即可
2、这里以 下载 Python 3.10.9 为例
1)单击 Download ,跳转下载界面,
2)下拉页面选择对应安装包,点击下载
具体如下图
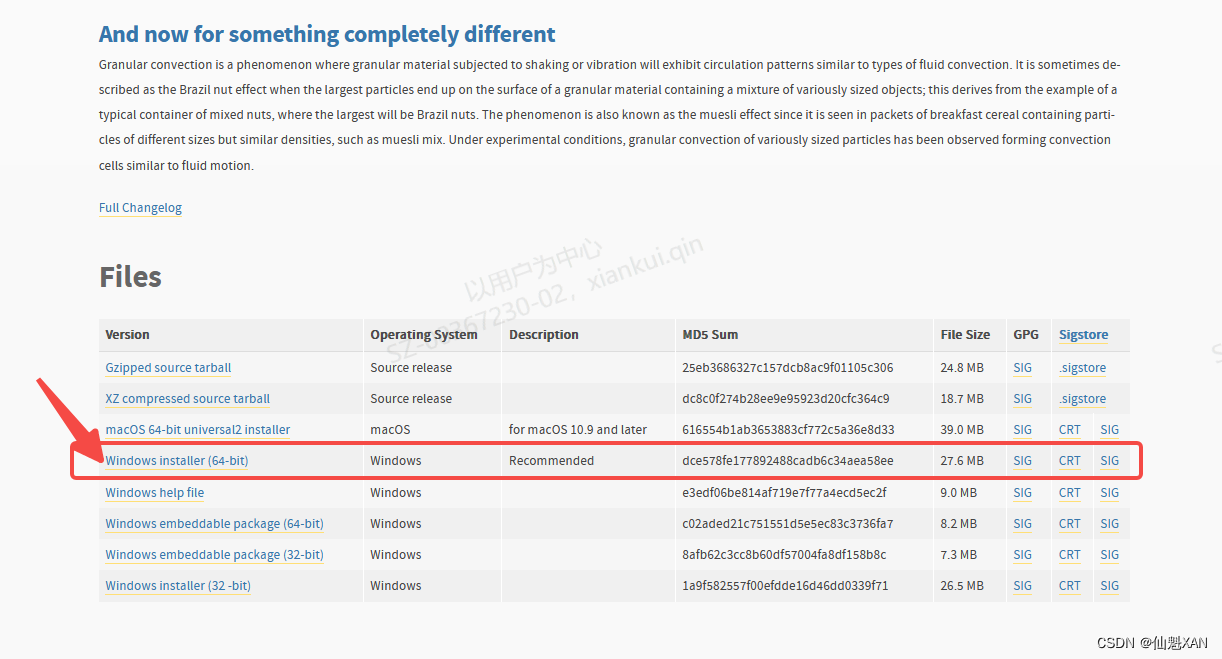
3、安装 Python 3.10.9
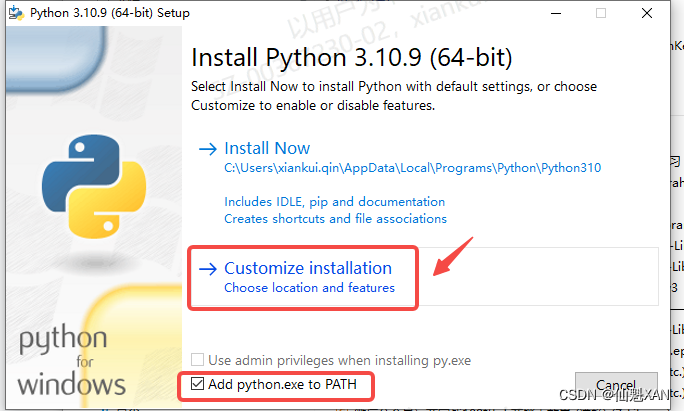
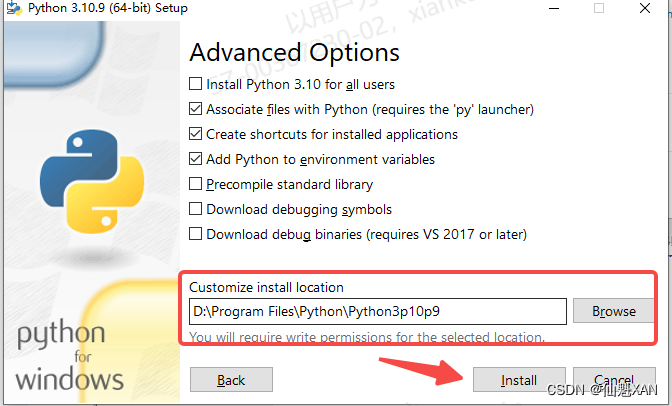
1)双击 安装包,打开安装界面,根据需要选择自定义安装,还是立即安装
2)这里选择自定义安装,选择自己需要安装的路径,避免占用 C 盘过多的空间,建议勾选
Add python.exe to PATH ,添加到环境中,方便以后再 cmd 中直接执行 python
3)依次如图操作,最后安装即可


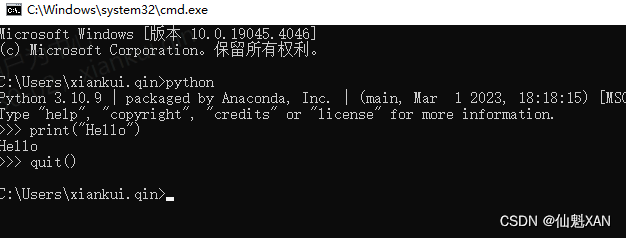
4、检验 python 是否安装成功,win + R 快捷打开 运行,输入 cmd ,打开 cmd
1)由于之前安装 python 的时候把 python.exe 添加到环境变量中
2)所以,输入 python ,即可看到 python 相关信息,并进入 python 状态
3)可以在次状态编写 ptyhon 代码
4)输入 quit() ,退出当前环境

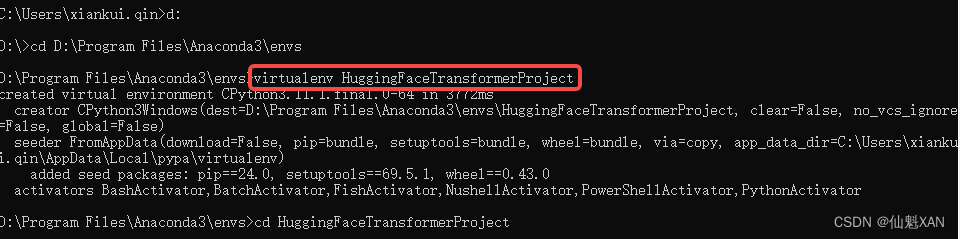
5、创建一个虚拟环境
命令:virtualenv HuggingFaceTransformerProject
可以先切换到自己需要创建文件夹路径,创建管理自己的虚拟环境
(这里没有使用Anacoda ,大家一个可以使用它管理虚拟环境)
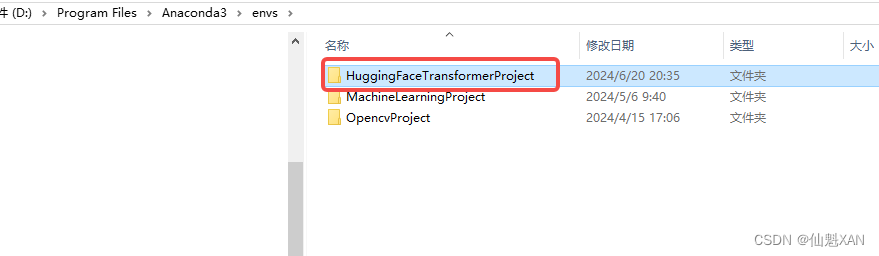
6、对应路径下就会出现你创建的虚拟环境文件夹相关
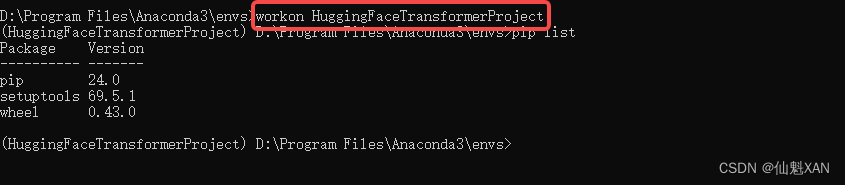
7、可以使用 workon 环境名 激活虚拟环境
命令:workon HuggingFaceTransformerProject
8、输入 deactivate 退出虚拟环境
命令:deactivate

Pycharm 环境搭建
1、下载 Pycharm 安装包
1)在百度上搜索 Pycharm download
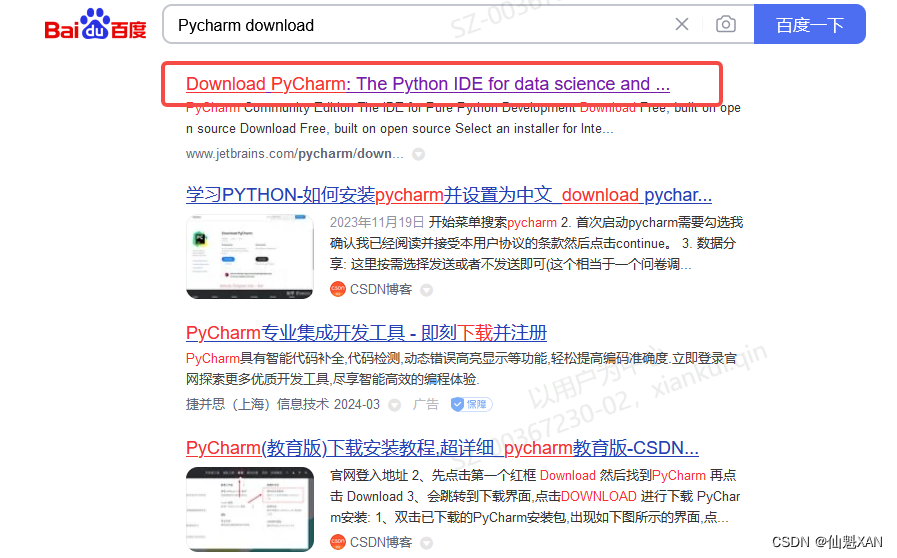
2)或者下面的 下载地址进行下载 :下载 PyCharm:JetBrains 出品的用于数据科学和 Web 开发的 Python IDE
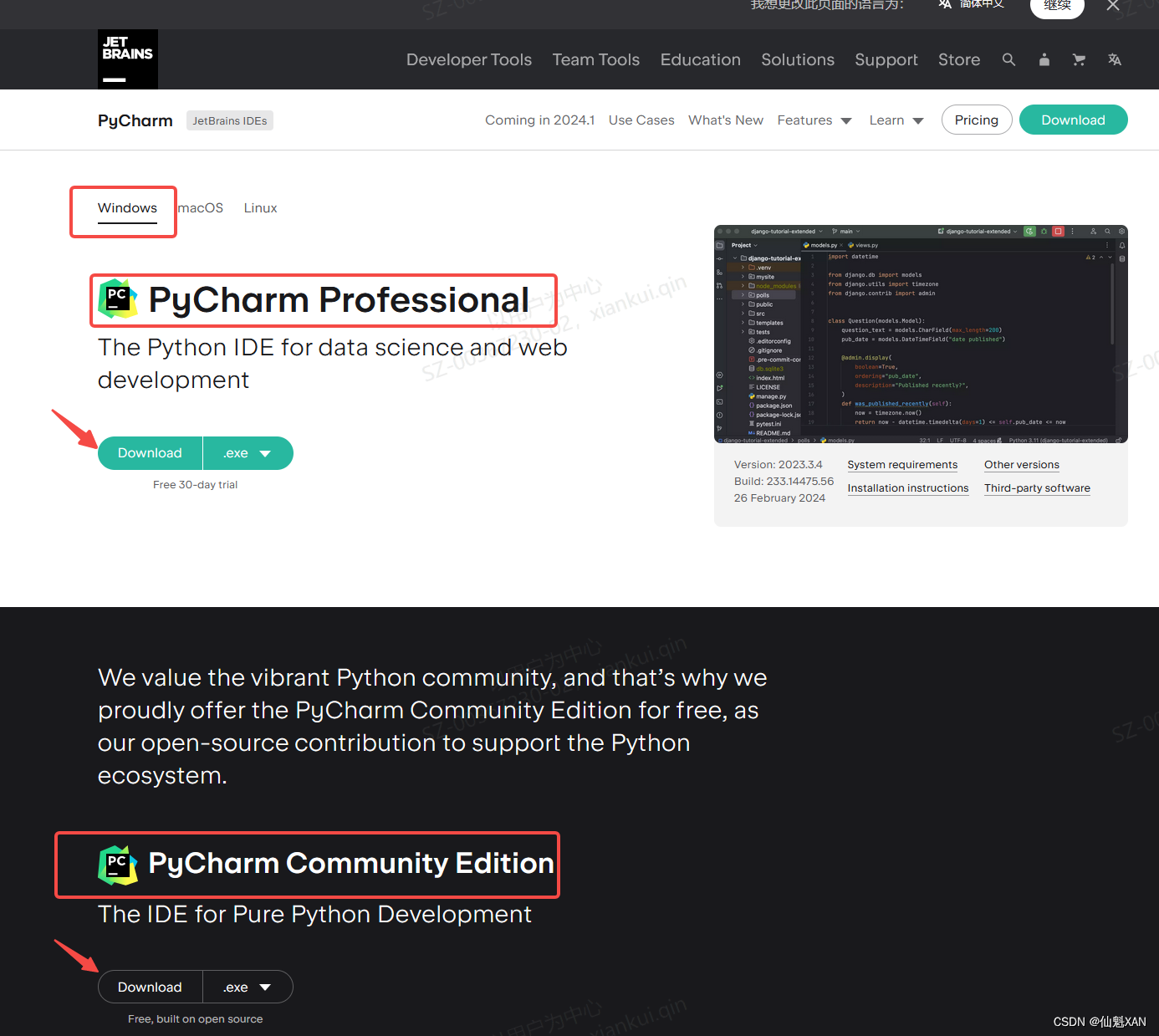
3)根据自己的需要选择版本(专业版、社区版),基础的学习开发社区版本就好
2、安装 Pycharm
1)双击安装包 .exe ,如果你有老版本,根据需要是否卸载

2)由于 Pycharm 安装较大,建议安装到 C 盘之外的大盘中
3)安装中,根据需要,添加桌面启动图标,其他设置根据需要选取即可

4)接着进行安装,等待安装完成即可
3、打开 Pycharm
1)点击图片打开 Pycharm

2)第一次会提示要求配置,如果有配置可以导入进来,如果没有,可以不导入,如下图
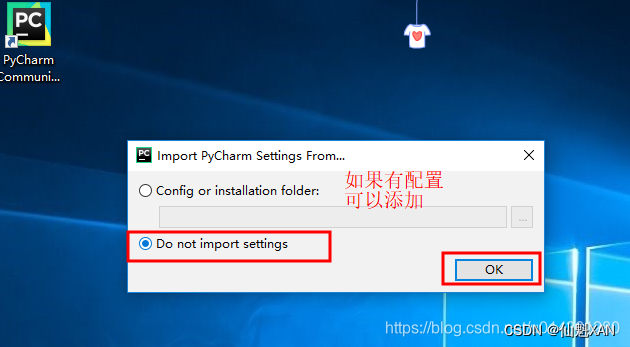
3)查阅条款,勾选接手即可,如下图
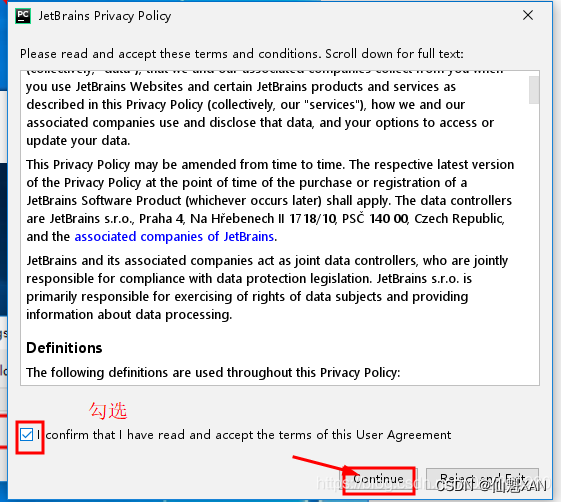
4)根据需要选择是否收集信息发送 Pycharm 开发团队,如下图
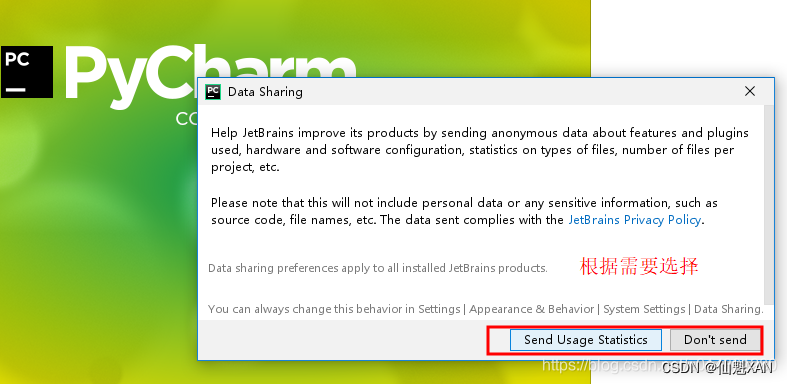
5)选择 Pycharm 界面风格,如下图
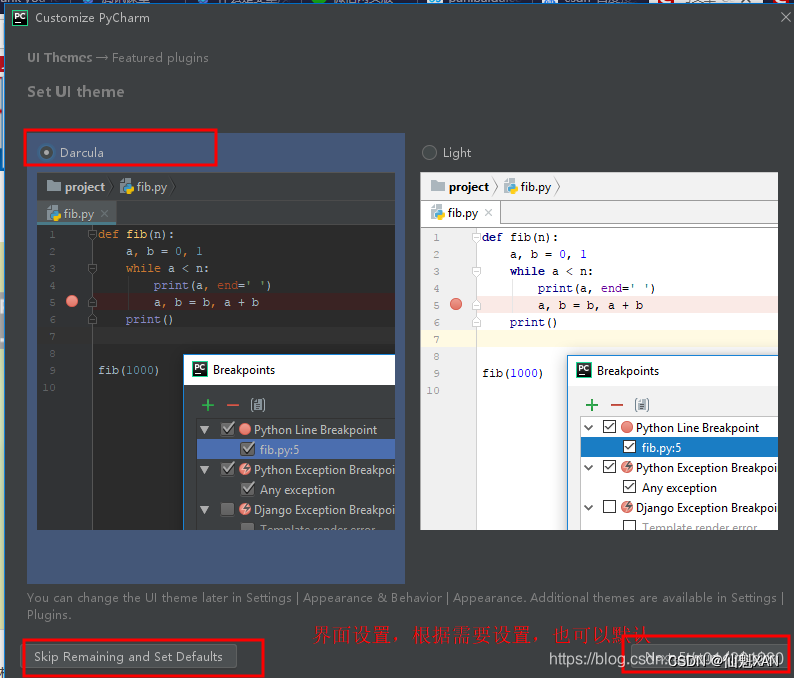
6)新建一个 pyhon 工程

7)选择工程保存的位置,建议不放在 C 盘,并选择Previously configured interpreter(而不是每次新建工程都建立一个虚拟环境,可能较占空间),如下图
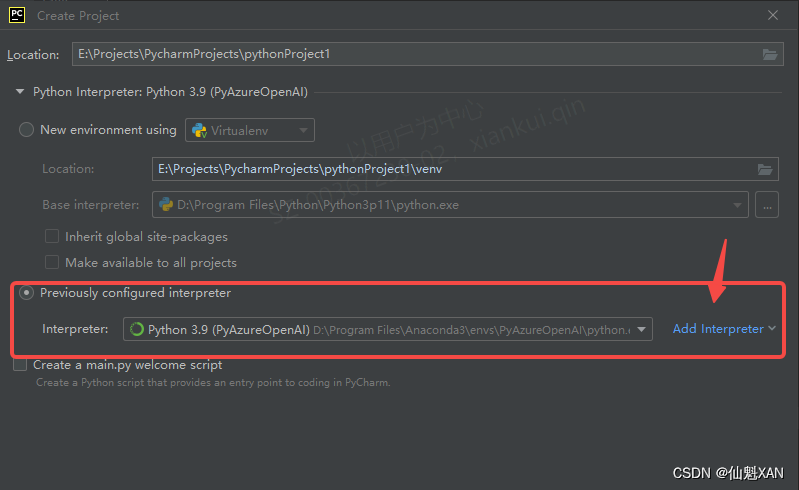
8)Interpreter 为 Python 安装的位置的 python.exe,根据自己的安装的位置,添加即可,如下图
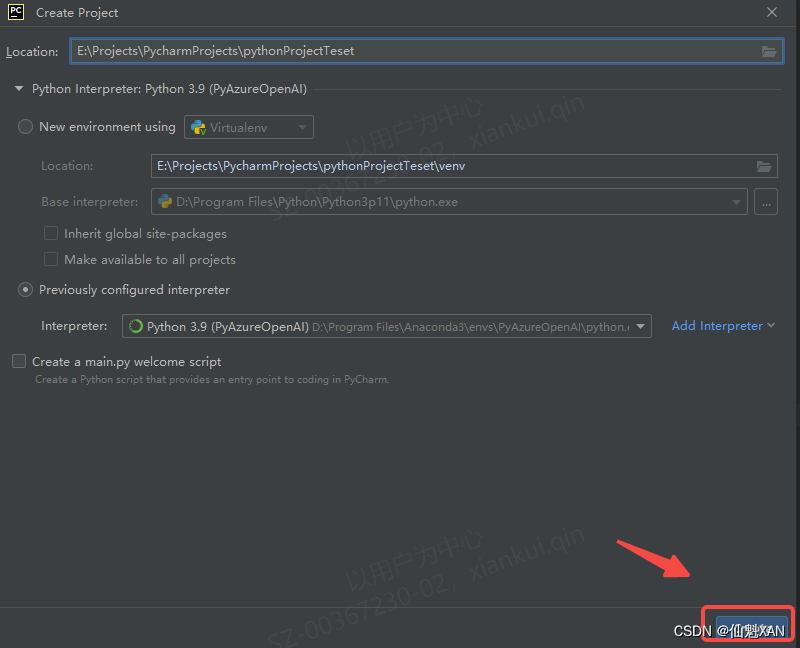
4、Pycharm 的简单使用
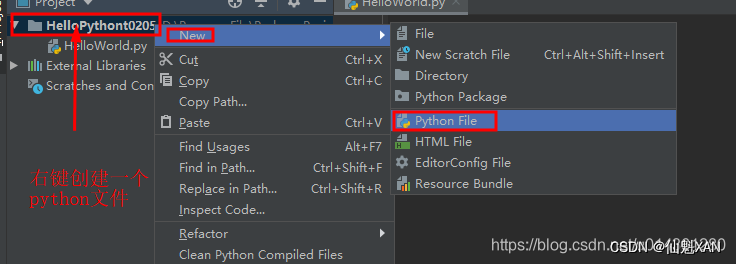
1)选择新建的工程名,右键新建一个 Python File,如下图
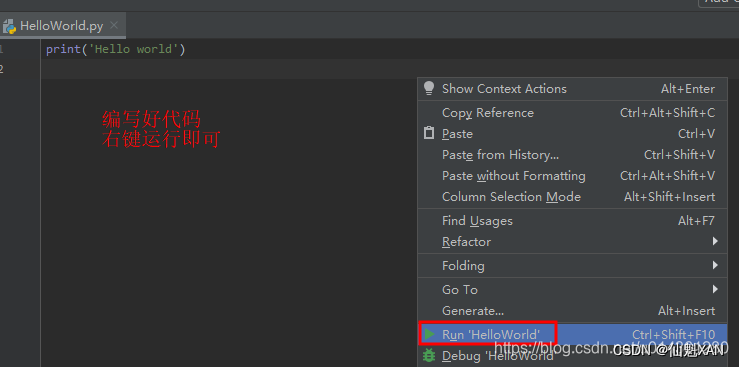
2)然后编写一个,hello world 打印代码,在编辑栏空白处,右键 "Run XXX" 即可,如下图
3)运行后,即可看到运行结果,如下图
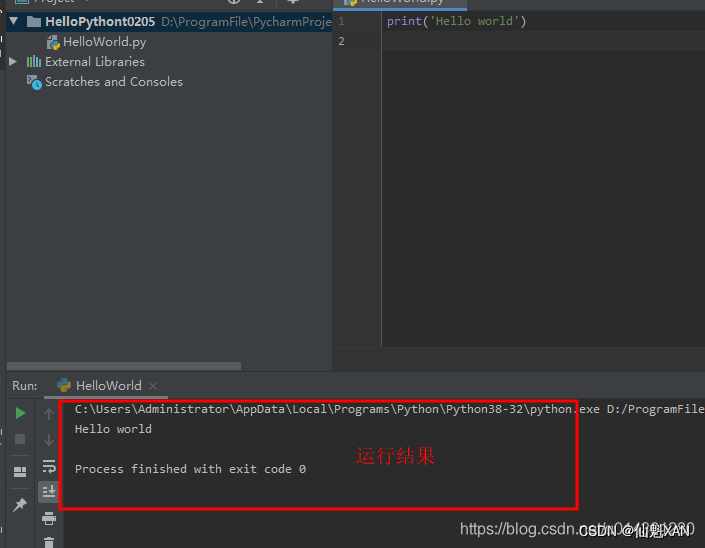
Hugging face 基础环境搭建
1、打开 Pycharm ,创建一个工程
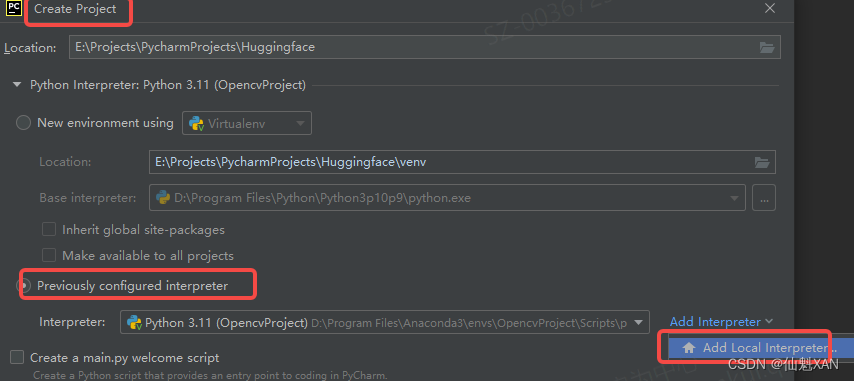
2、选择之前创建的虚拟环境,进行工程创建
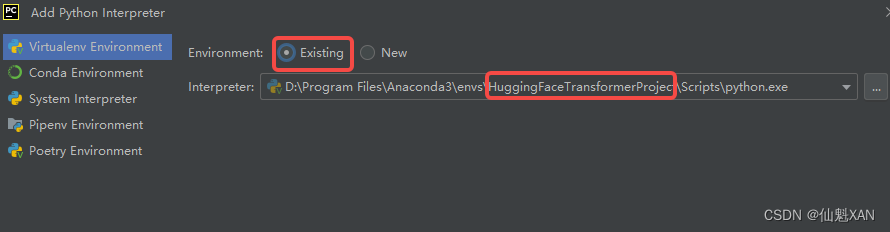
3、之后可以创建工程了
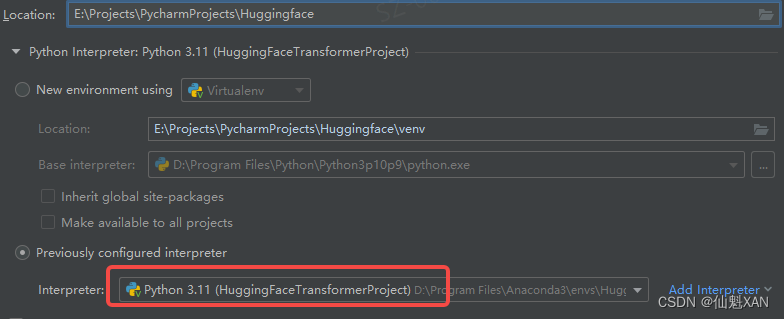
4、 工程中,进入终端,就会自动激活之前创建的环境
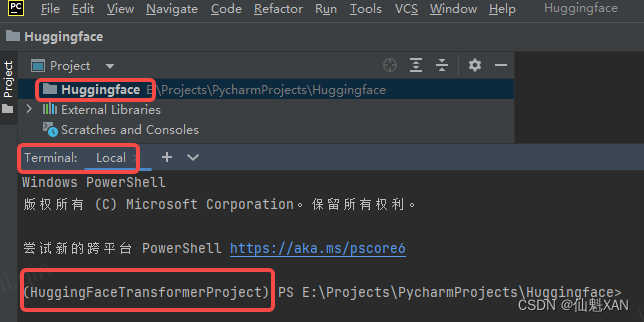
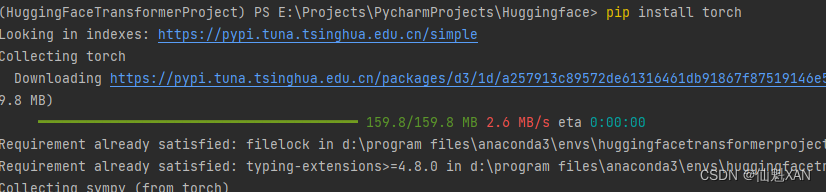
5、终端安装 一些必要的库,例如 transformers 、torch

6、创建脚本,测试 pipeline 文本翻译功能,但是这里可能需要梯子网络
(不能梯子的,可以参考后面本地的)
- # 导入transformers库中的pipeline函数
- from transformers import pipeline
-
- # 定义一个函数func1,它将使用pipeline来执行翻译任务
- def func1():
- # 使用pipeline函数创建一个翻译管道(translator)
- # "translation_en_to_fr"指定了翻译任务是从英文翻译到法语
- # model="google/t5-base"指定了使用的预训练模型是Google的T5-base模型
- translator = pipeline("translation_en_to_fr", model="google/t5-base")
-
- # 使用translator管道翻译示例句子"How old are you?",并打印翻译结果
- print(translator("How old are you?"))
-
- # 调用func1函数执行翻译任务
- func1()
7、如果没有梯子网络,可以把相关模型资源下载到本地,进行加载,这里我们使用Helsinki-NLP/opus-mt-en-zh 的英文翻译为中文
https://huggingface.co/Helsinki-NLP/opus-mt-en-zh/tree/mainHelsinki-NLP/opus-mt-en-zh模型:https://huggingface.co/Helsinki-NLP/opus-mt-en-zh/tree/main
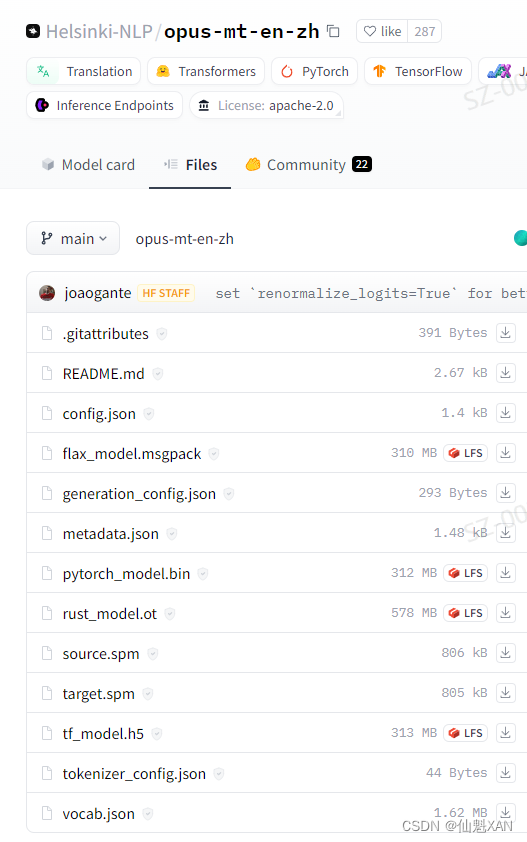
8、若不清楚下载哪些文件,可以都下载
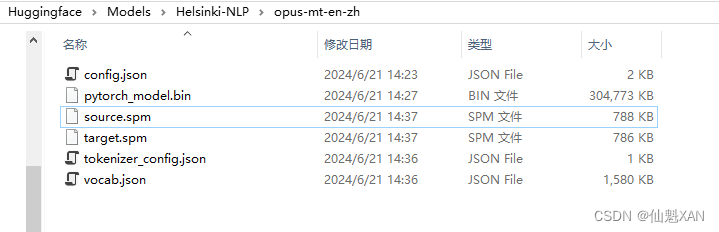
这里我们下载,并添加到工程中 Huggingface\Models\Helsinki-NLP\opus-mt-en-zh 目录下:
config.json:模型的配置文件,包含模型的参数和设置。pytorch_model.bin:模型的权重文件,包含训练过程中学习到的参数。source.spm和target.spm(如果存在):SentencePiece分词器模型文件,用于文本的编码和解码。但在上述代码中,我们使用的是MarianTokenizer,它应该会自动处理这些文件。-
tokenizer_config.json- 分词器的配置文件,包含分词器的设置和参数。 -
vocab.json- 分词器的词汇表文件,包含了模型理解和生成文本时使用的所有词汇和标记。
9、添加代码,进行加载本地模型,进行英文翻译为中文的功能实现,代码如下
- # 导入所需的transformers库中的MarianMTModel和MarianTokenizer类
- from transformers import MarianMTModel, MarianTokenizer
-
- # 指定模型的本地路径
- # 请确保此路径下包含了模型所需的所有文件,如config.json和pytorch_model.bin等
- model_name = 'Models/Helsinki-NLP/opus-mt-en-zh'
-
- # 从本地路径加载MarianTokenizer分词器
- tokenizer = MarianTokenizer.from_pretrained(model_name)
-
- # 从本地路径加载MarianMTModel模型
- model = MarianMTModel.from_pretrained(model_name)
-
- # 设置待翻译的英文文本
- input_text = "How old are you?"
-
- # 使用分词器编码输入文本,准备模型输入
- # return_tensors="pt"指示分词器返回PyTorch张量
- # padding=True表示对序列进行填充以匹配批次中的最大长度
- # truncation=True表示对序列进行截断以避免超过模型的最大输入长度
- inputs = tokenizer(input_text, return_tensors="pt", padding=True, truncation=True)
-
- # 使用模型生成翻译
- # input_ids和attention_mask作为模型的输入
- # num_beams=4表示使用4束束搜索来提高翻译的多样性和准确性
- # max_length=128限制了翻译输出的最大长度
- translated_ids = model.generate(
- input_ids=inputs["input_ids"],
- attention_mask=inputs["attention_mask"],
- num_beams=4,
- max_length=128
- )
-
- # 使用分词器解码模型生成的ID序列回文本字符串
- # skip_special_tokens=True表示跳过解码过程中遇到的特殊的控制标记
- translated_text = tokenizer.decode(translated_ids[0], skip_special_tokens=True)
-
- # 打印原始文本和翻译后的文本
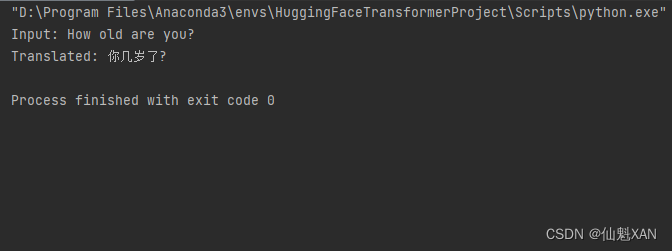
- print("Input:", input_text)
- print("Translated:", translated_text)
10、可能现在还需要安装 tokenizers、和 sentencepiece 库
目前库的版本如下:
transformers 4.24.0
torch 2.2.1
tokenizers 0.13.3
sentencepiece 0.2.0
11、目前工程结构如下:
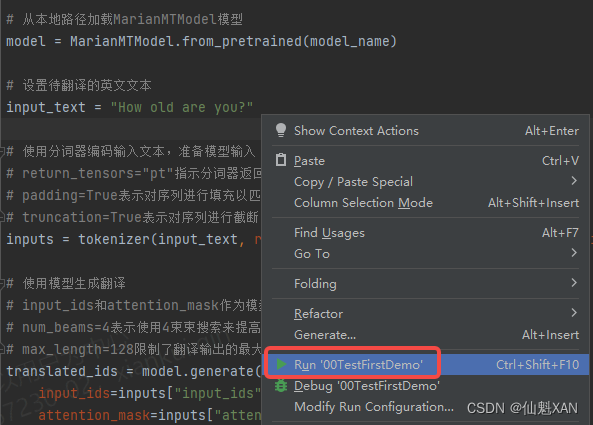
12、运行脚本
13、 结果输出
附录
一、模型中的一些文件说明
-
opus-mt-en-zh- 这似乎是一个文件夹或模型的名称,代表一个英文到中文的机器翻译模型。 -
README.md- 一个Markdown格式的文档,通常包含关于模型的基本信息、如何使用它以及可能的其他说明。 -
config.json- 包含模型的配置信息,如层的数量、类型等,这是初始化模型时必需的。 -
flax_model.msgpack- 一个可能包含Flax框架模型权重的文件。Flax是一个由Google研究人员开发的机器学习库,与PyTorch和TensorFlow兼容。 -
generation_config.json- 可能包含模型生成文本时使用的配置,例如设置renormalize_logits=True以改善性能。 -
metadata.json- 包含模型的元数据,比如模型的名称、版本、作者信息等。 -
pytorch_model.bin- 这是模型的主要权重文件,用于PyTorch框架。它是模型训练后学习到的知识的存储形式。 -
rust_model.ot- 一个可能包含Rust语言模型实现的文件。这表明模型可能也可以在Rust环境中使用。 -
source.spm和target.spm- 这两个文件是SentencePiece模型文件,用于文本的分词(tokenization)。source.spm用于源语言(英文)的分词,而target.spm用于目标语言(中文)的分词。 -
tf_model.h5- 包含TensorFlow模型权重的文件。.h5是HDF5格式的文件,常用于存储TensorFlow模型。 -
tokenizer_config.json- 分词器的配置文件,包含分词器的设置和参数。 -
vocab.json- 分词器的词汇表文件,包含了模型理解和生成文本时使用的所有词汇和标记。
图中还提到了一些提交信息,如joaogante HF STAFF、set 'renormalize_logits=True' for better performance等,这些信息表明了代码仓库的更新历史和一些性能改进的提交。
要本地运行这个模型,主要需要config.json、pytorch_model.bin(或其他框架对应的权重文件)、以及分词器相关的source.spm、target.spm、tokenizer_config.json和vocab.json文件。其他文件可能是模型在不同框架或环境中的实现。
二、本案例的环境中一些关键库的版本
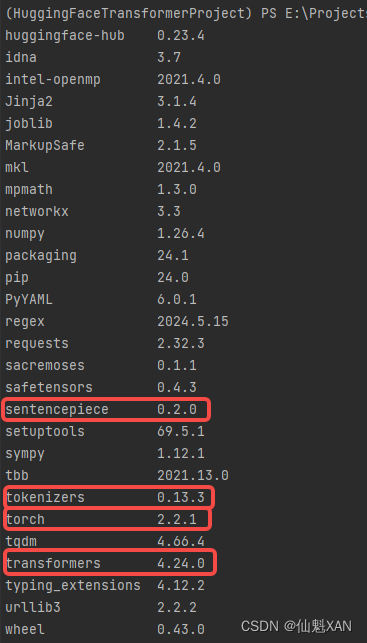
transformers 4.24.0
torch 2.2.1
tokenizers 0.13.3
sentencepiece 0.2.0

