
热门标签
当前位置: article > 正文
微软 LoRA| 使用万分之一的参数微调你的GPT3模型_lora微调参数
作者:人工智能uu | 2024-07-18 23:56:56
赞
踩
lora微调参数
一、概述
title:LORA: LOW-RANK ADAPTATION OF LARGE LAN- GUAGE MODELS
论文地址:https://arxiv.org/abs/2106.09685
1.1 Motivation
- NLP重要的范式为在通用数据集上预训练,然后特定领域微调,但是随着模型越来越大,继续全量fine-tuning变得越来越不可能。
1.2 Methods
- 本文提出低秩Adaptation(LoRA),冻结了预先训练的模型参数,将可训练的秩分解矩阵注入到Transformer架构的每一层中,大大减少了下游任务的可训练参数的数量,训练参数只有GPT-3 175B模型的万分之一,GPU内存只需要1/3。
1.3 Conclusion
- 尽管训练参数少很多,LoRA在RoBERTa,DeBERATa,GPT-2和GPT-3的效果甚至比全量fine-tuning要好,并且不像adpers等方法,不会增加推理latency,不需要降低输入序列长度,同时维持高的模型质量。
- 可以快速的进行任务的切换,因为在不同任务重其可以共享绝大部分的模型的参数。
- 可以应用到任意神经网络的dense层。
1.4 Future works
- LoRA和其他有效的adaptation方法结合。
- 研究fine-tuning或者LoRA背后的机制。
- 除了其方式的选择LoRA的权重,是否还有更多的原则来做?
- ΔW(LoRA学习到的权重) 的秩亏表明 W 也可能是秩亏的,这也可以成为未来工作的灵感来源。
二、详细内容
1 模型结构说明
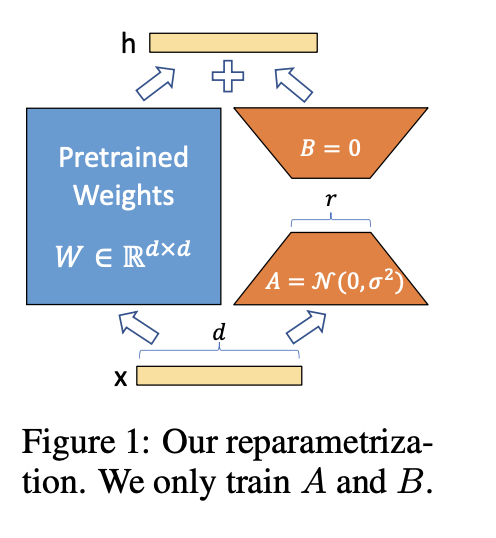
- 冻结模型原始圈子,只训练A和B矩阵,同时B初始化为零,这样初始阶段B不参与更新。
2 LoRA推理latency比adapter方法要好

- Adaper方法在序列长度比较短的时候,推理latency增加非常多
3 LoRA与Fine-tuning方法,其他Adapter方法在Roberta,deberta模型的效果对比
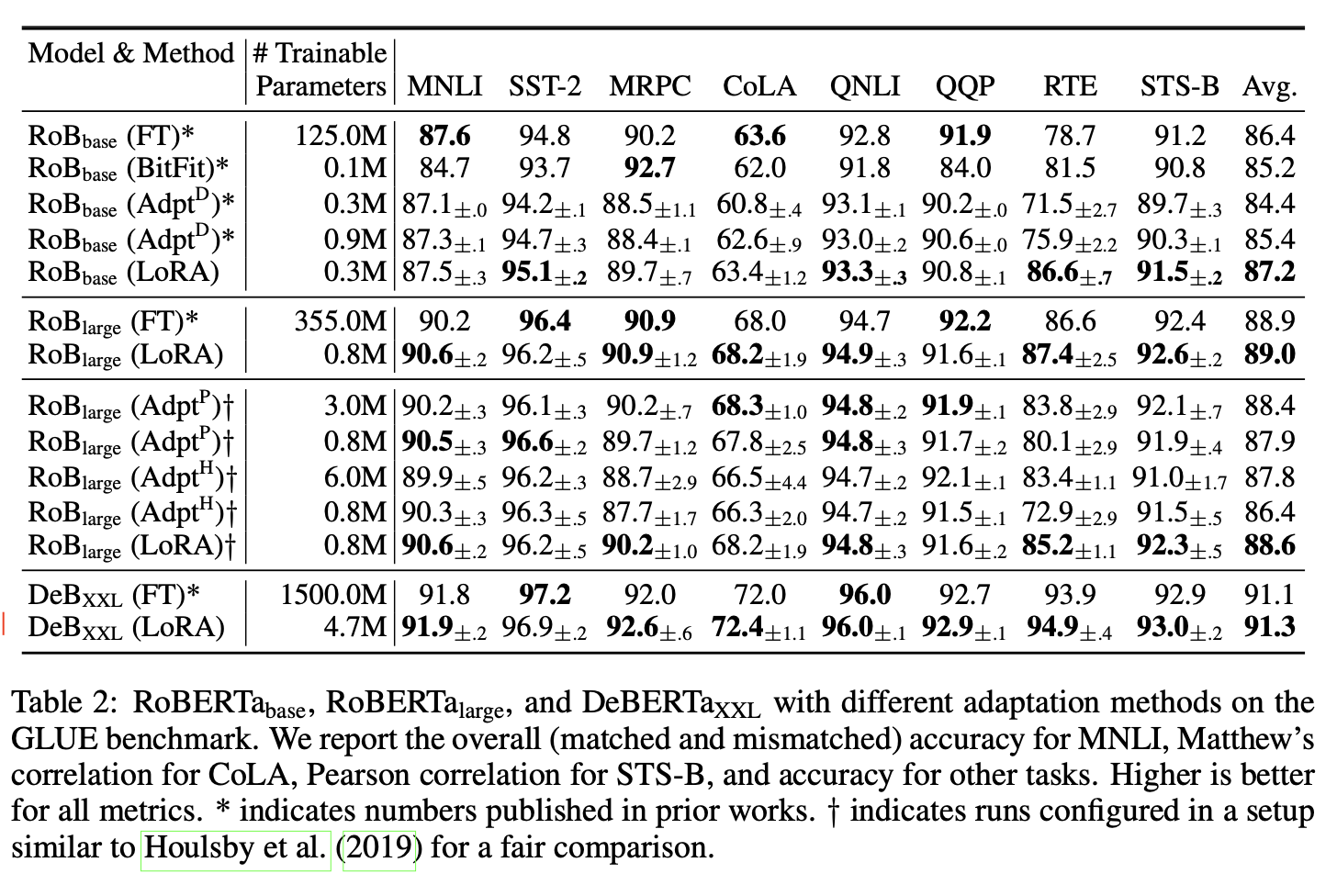
- LoRA和FT方法效果差不多,各有千秋,但是需要训练的参数少很多。
- 效果和其他Adpt方法也各有千秋,但是推理速度更快
4 LoRA与Fine-tuning方法,其他Adapter方法在GPT-2模型的效果对比
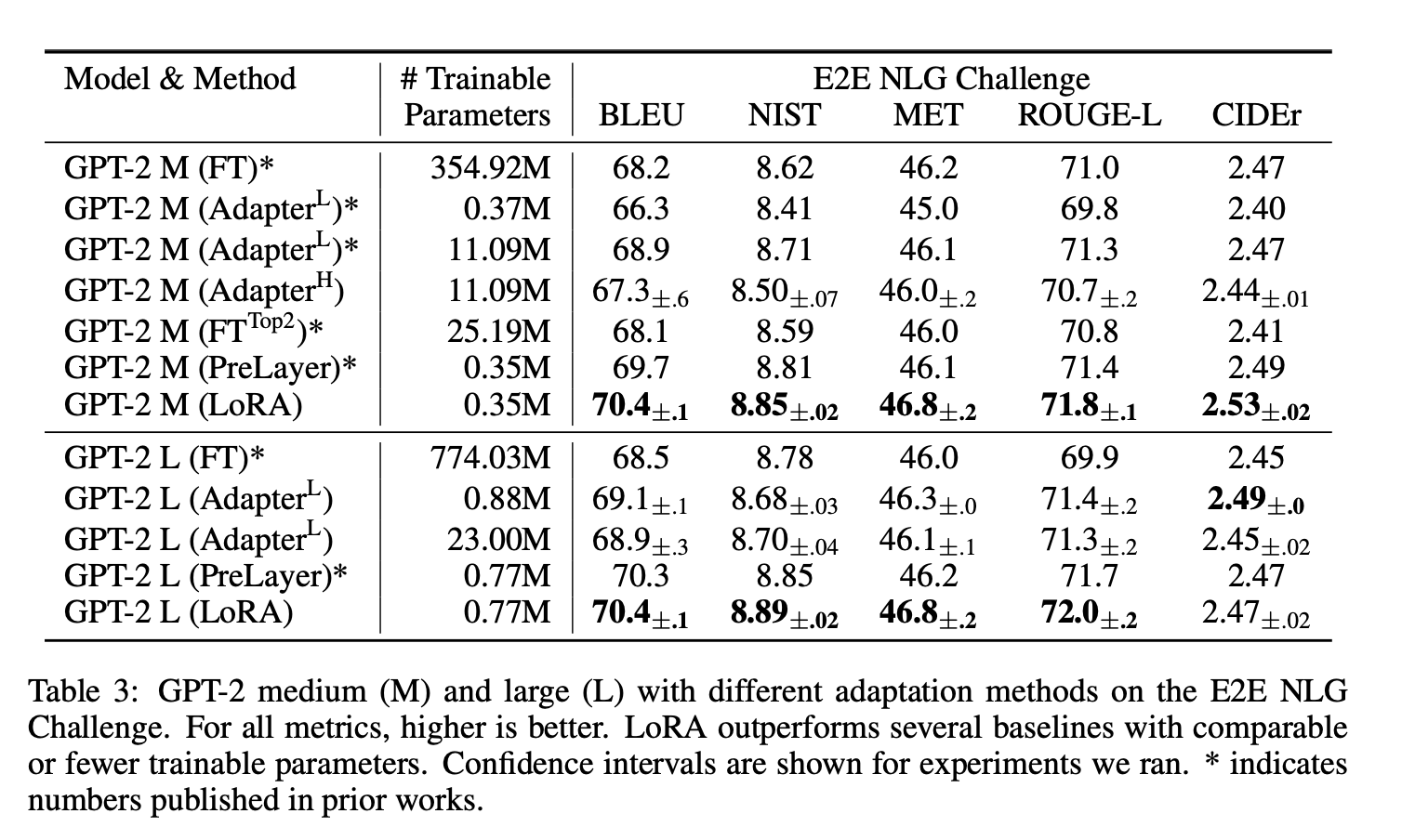
- 在GPT-2系列模型上,比全量fine-tuning以及其他Adapter方法效果都好不少
5 LoRA在GPT3模型上的效果
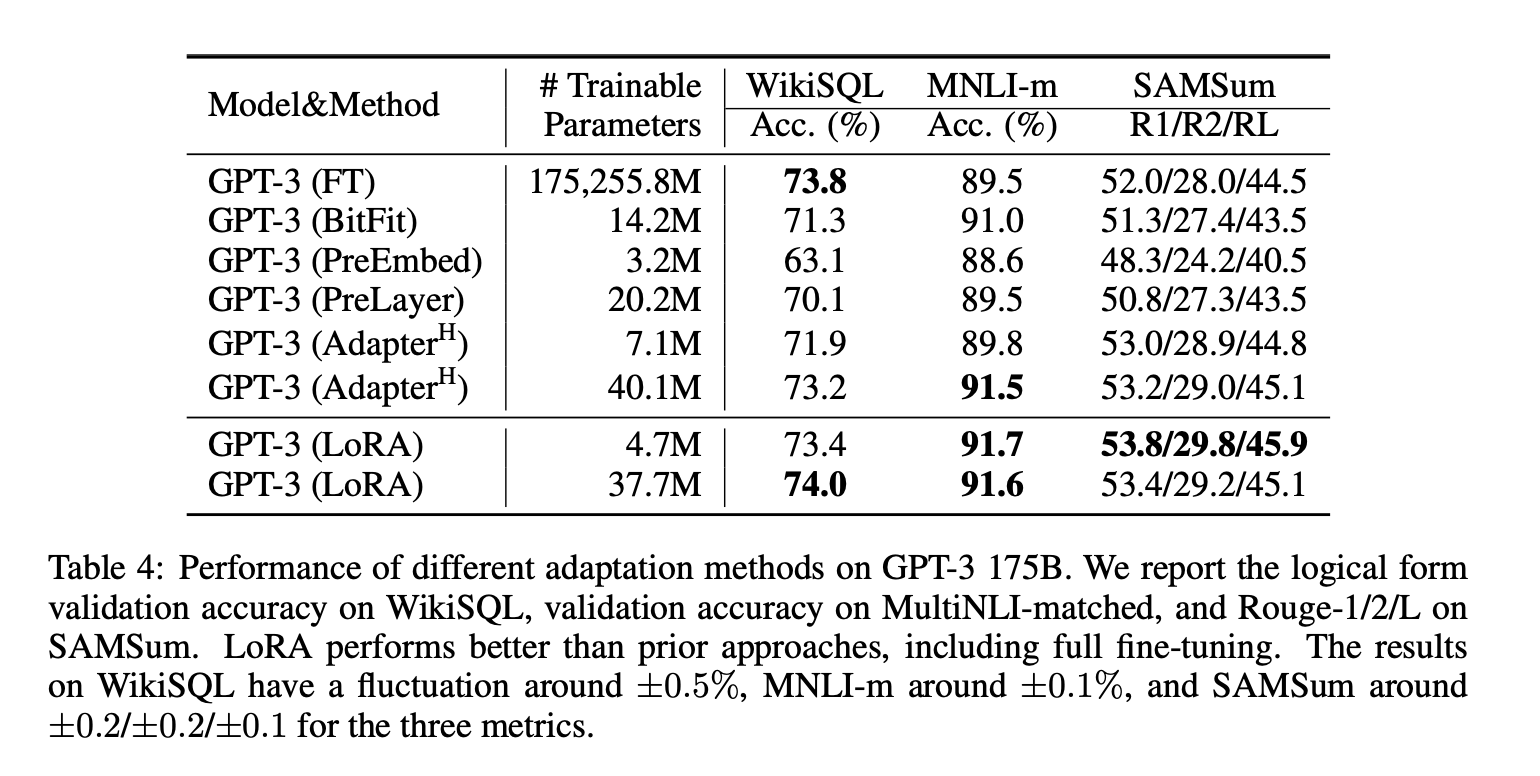
- 看起来比其他fine-tuning方法以及Adapter方法都要好
6 超参数选择上的表现

- 相对于prefixEmbed,prefixLayer,Adapte人(H)等方法,LoRA表现出更好的可拓展性和表现
- LoRA看着对超参数的选择上没那么敏感,稳定性更好
7 同等参数下,LoRA加到Transformer的那一层效果比较好呢?

- 对Wq和Wv矩阵同时做Adapting效果最佳
8 如何选择参数rank r=?【没咋看懂】
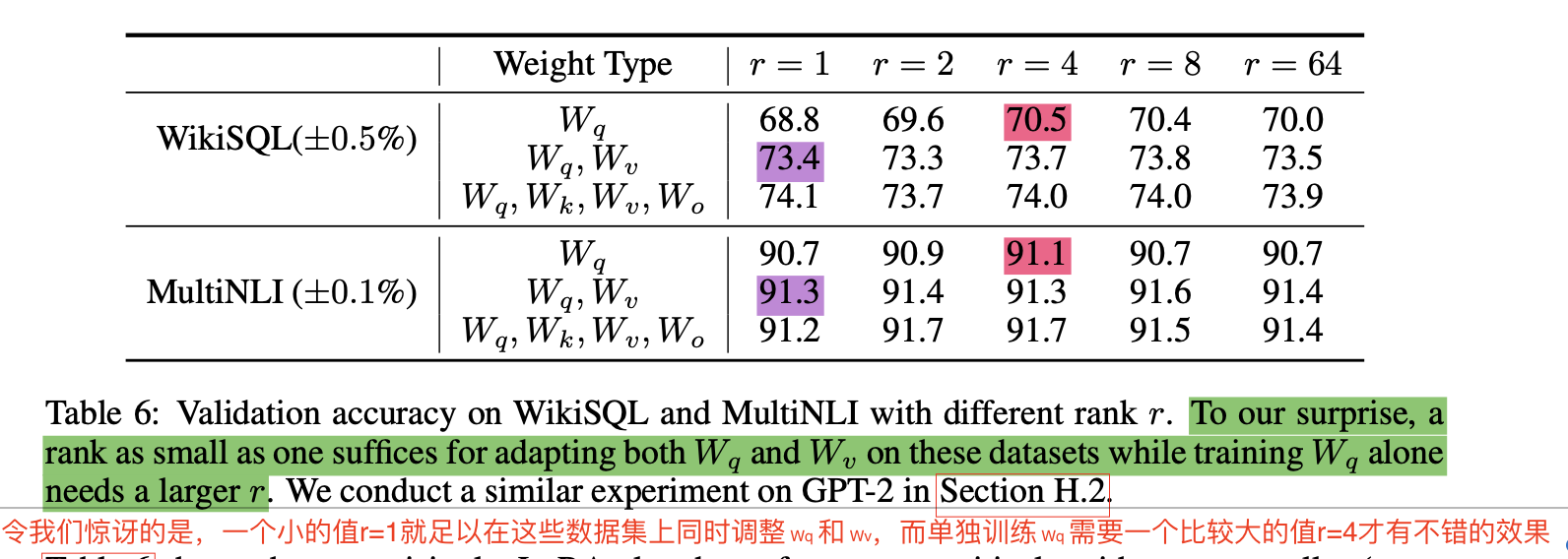
- 同时调整 Wq 和 Wv时候,一个小的值r=1就足以在这些数据集上,而单独训练 Wq 需要一个比较大的值r=4才有不错的效果。
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读

相关标签

