
- 1研发效能DevOps: Git安装_gitee devops本地安装
- 2Doris 0.14.7 版本发布啦_doris update
- 3【Android】Gradle 切换 国内源_gradle源服务器换源
- 42021年春季学期期末统一考试品牌管理 试题_以下哪些属于cc品牌管理模式的发展原则
- 5搭建nacos集群 和 网关_nacos c#
- 6cartographer安装(过程超简单,成功安装经验)
- 7cmake应用:集成gtest进行单元测试_cmake 使用 gtest_gtest集成至make
- 8干货!java实现如何把PPT转PDF的两种方法,别再说你不会!(一)_java ppt转pdf
- 9基于 Python+Django 构建智能互动拍照系统_基于django的图片
- 10本地部署DbGate数据库管理工具并实现异地远程访问查询数据_dbgate教程
李宏毅机器学习--self-supervised:BERT、GPT、Auto-encoder_自编码器和bert
赞
踩
目录
next sentence prediction(预测前后两个句子是否相接)
为什么可以做到Multi-lingual BERT:Cross-lingual Alignment
Self-supervesed Learning Beyond Text
De-noising auto-encoder:Auto-Encoder 的变形
feature disentangle(低维向量的功能区分)
discrete representation(离散表示法)—控制Embedding的形式,便于充分利用
discrete representation的应用:VQVAE
Self-Supervised Learning
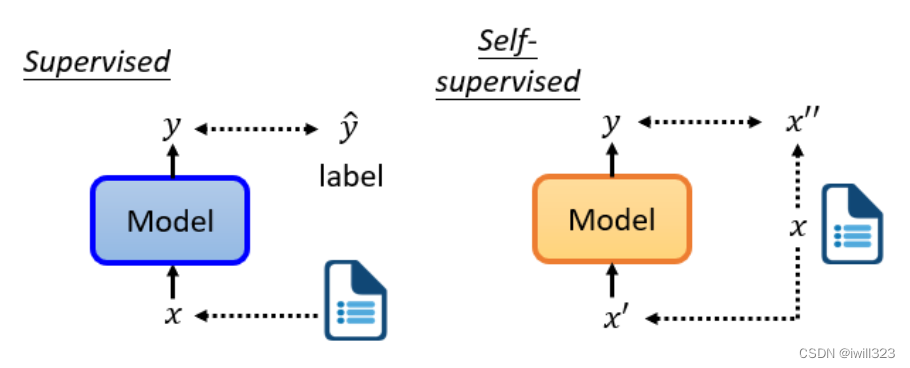
supervised learning是需要有标签的资料的,而self-supervised learning不需要外界提供有标签的资料,“带标签”的资料源于自身。x分两部分,x'和x'',一部分用作模型的输入,另一部分作为y要学习的label资料。为什么不叫无监督学习呢?因为无监督学习是一个比较大的家族,里面有很多不同的方法,Self-supervised Learning就是其中之一。
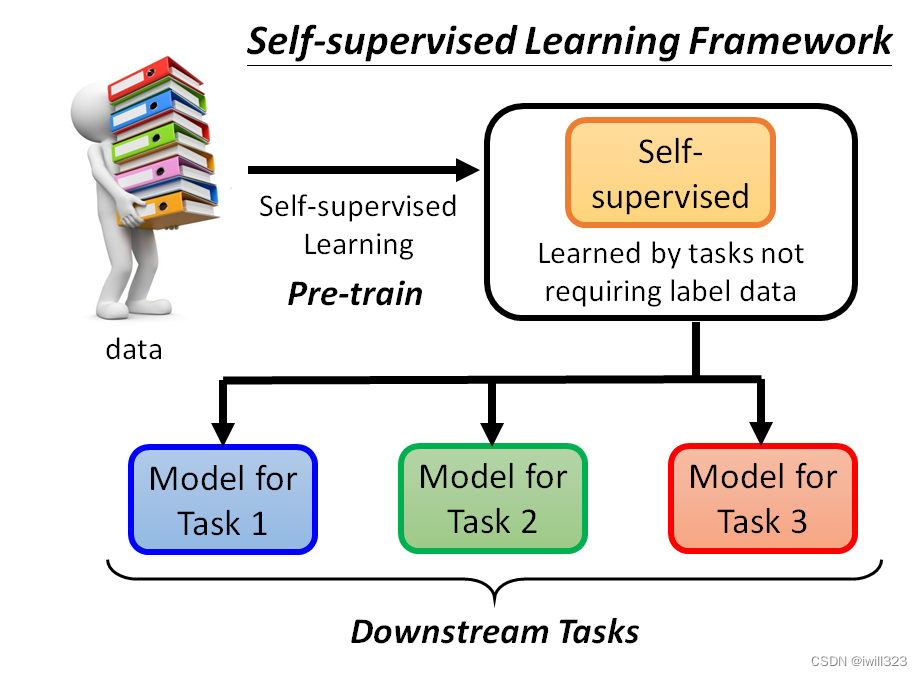
用这些不用标注资料的任务学完一个模型以后,它本身没有什麽用,BERT 只能做填空题,GPT 只能够把一句话补完,可以把 Self-Supervised Learning 的 Model做微微的调整,把它用在其他下游的任务裡面

BERT
BERT是一个transformer的Encoder,BERT可以输入一行向量,然后输出另一行向量,输出的长度与输入的长度相同。BERT不仅用于NLP,或者用于文本,它也可以用于语音和视频。
作为transformer,理论上BERT的输入长度没有限制。但是为了避免过大的计算代价,在实践中并不能输入太长的序列。 事实上,在训练中,会将输入截成片段输入BERT进行训练,避免距离过长的问题。
BERT训练
当我们训练时,我们要求BERT学习两个任务,masking input 和next sentence prediction这两个操作。
masking input(随机遮盖一些输入单位)
当BERT进行训练时,向BERT输入一个句子,先随机决定哪一些token将被mask。随机遮盖的方法有两种:
- 使用特殊单位来代替原单位,这个特殊单位完全是一个新词,它不在你的字典里,这意味着mask了原文
- 随机使用其他的单位来代替原单位。
两种方法都可以使用,使用哪种方法也是随机决定的。台□大学就是x'(作为模型的输入),台湾大学等字体就是x''(作为输出要学习的label资料)。

训练方法:
- 向BERT输入一个序列,先随机决定哪一部分将被mask。
- 把BERT的相应输出看作是另一个序列,寻找mask部分的相应输出向量,将这个向量通过一个Linear transform(矩阵相乘),并做Softmax得到一个分布。
- 用一个one-hot vector来表示MASK的字符,并使输出和one-hot vector之间的交叉熵损失最小。
这与Seq2Seq模型中提到的使用transformer进行翻译时的输出分布相同:输出是一个很长的向量,每一个token都有一个分数对应。本质上是在解决一个分类问题,BERT要做的是预测什么被盖住。

next sentence prediction(预测前后两个句子是否相接)
从数据库中拿出两个句子,在句子的开头添加一个特殊标记[cls],两个句子之间添加一个特殊标记[SEP],这样BERT就可以知道,这两个句子是不同的句子。
把两个句子(包括SEP标记和CLS标记)传给BERT,只看CLS的输出,CLS的输出经过和masking input一样的操作,目的是预测第二句是否是第一句的后续句。这是一个二分类问题,有两个可能的输出:是或不是。
很多文献说这个方法对于预训练的效果并不是很大,没有学到什么太有用的东西,原因之一可能是,Next Sentence Prediction 太简单了,通常,当我们随机选择一个句子时,它看起来与前一个句子有很大不同,因此对于BERT来说,预测两个句子是否相连并不是太难。
有另外一招叫做Sentence order prediction,SOP,预测两个句子谁在前谁在后。也许因为这个任务更难,它似乎更有效

BERT的fine-tune应用
BERT框架
产生BERT的过程就是Pre-train,它只会做填空题,做过fine-tune(微调)之后才能做各式各样的下游任务Downstream Tasks。微调的过程中,对于下游任务的训练,仍然需要少量的标记数据。
生成BERT的过程就是Self-supervised学习(资料来源于自身),fine-tune过程是supervised learning(有标注的资料),所以整个过程是semi-supervised。所谓的 "半监督 "是指有大量的无标签数据和少量的有标签数据。

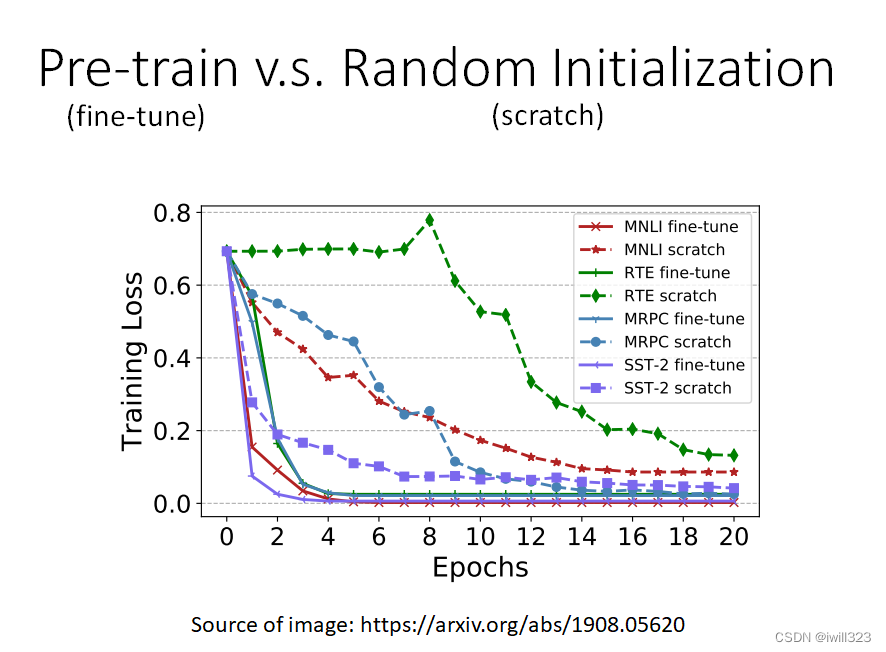
对比预训练与随机初始化
- "fine-tune"是指模型被用于预训练,该部分的参数是由学习到的BERT的参数来初始化的。
- scratch表示整个模型,包括BERT和Encoder部分都是随机初始化的。
横轴是训练周期,纵轴是训练损失。在训练网络时,scratch与用学习填空的BERT初始化的网络相比,损失下降得比较慢,最后,用随机初始化参数的网络的损失高于用学习填空的BERT初始化的参数。
GLUE(测试BERT的能力)
为了测试Self-supervised学习的能力,通常会在多个任务上测试它。GLUE是自然语言处理任务,总共有九个任务。BERT分别微调之后做这9个任务,将9个测试分数做平均后代表BERT的能力高低。

人类的准确度是1,如果他们比人类好,这些点的值就会大于1。9个任务的平均得分逐年增加。每个任务使用的评价指标是不同的,可能不是准确度。如果我们只是比较它们的值,可能是没有意义的。所以,这里我们看的是人类之间的差异。这只是这些数据集的结果,并不意味着机器真的在总体上超过了人类。
在这里展示的例子属于自然语言处理。语音、文本和图像都可以表示为一排向量,可以把这些例子改成其他任务,例如,把它们改成语音任务,或者改成计算机视觉任务。
case 1-语句分类
输入句子,输出类别。比如说Sentiment analysis情感分析,就是给机器一个句子,让它判断这个句子是正面的还是负面的。
把CLS标记放在这个句子的前面,只看CLS的输出向量,对它进行Linear transform+Softmax,得到类别。需要向BERT提供大量的句子,以及它们的正负标签,来训练这个BERT模型。
Linear transform的参数是随机初始化的,而BERT的参数是由学会填空的BERT初始化的,训练就是利用梯度下降更新BERT和linear这两个模型里的参数。

case 2-词性标注
输入一个序列,然后输出另一个序列,而输入和输出的长度是一样的。例如,POS tagging词性标记,给机器一个句子,它必须告诉你这个句子中每个词的词性。
对于这个句子中的每一个标记,有一个代表这个单词的相应向量。然后,这些向量会依次通过Linear transform和Softmax层。最后,网络会预测给定单词的词性。

case 3-句意立场分析
输入两个句子,输出类别。输出的类别是三个中的一个:contradiction(对立的)、entailment(同边)、neutral(中立的)。最常见的是Natural Language Inference,机器要做的是判断是否有可能从前提中推断出假设,前提与假设相矛盾吗?例如,舆情分析。给定一篇文章,下面有一个评论,这个消息是同意这篇文章,还是反对这篇文章

给BERT两个句子,在这两个句子之间放一个特殊的标记SEP,并在最开始放CLS标记。把CLS标记作为Linear transform的输入。它决定这两个输入句子的类别

