
- 1毕业设计:python图书管理系统+可视化+Django框架(附源码+论文)✅_基于python+django的图书馆管理系统(内附源代码+部署教程)
- 2k-means聚类中k值与初始簇中心的选择_簇中心初始化
- 3PyQt5创建与MySQL数据库集成的应用程序_python pyqt5+mysql
- 4ai拓客商家联盟_「南博观察」南博会“云上见”背后深意:帮企业拓市场、畅渠道、拿订单...
- 535岁程序员被公司辞退,生活压力太大痛哭,中年危机如何自救?_36程序员 辞退后
- 6openssl升级_CVE-2020-1967:OpenSSL拒绝服务漏洞警报
- 7MySQL学习(二)MySQL的索引_学习mysql 优势
- 8C语言第四章(进程间的通信,管道通信,pipe()函数)_c语言管道通信
- 9FAST-LIO论文阅读_fastlio
- 10Django F()函数
Sentence-BERT实战_sentence-bert(sbert)
赞
踩
引言
本文主要介绍了SBERT作者提供的官方模块的使用实战。
通过Sentence-BERT了解句子表示
Sentence-BERT(下文简称SBERT)用于获取固定长度的句向量表示。它扩展了预训练的BERT模型(或它的变种)来获取句子表示。
SBERT常用于句子对分类、计算句子间的相似度等等任务。
在了解SBERT的细节之前,我们先看下如何使用预训练的BERT模型来计算句子表示。
计算句子表示
考虑句子Paris is a beautiful city,假设我们要计算该句子的向量表示。首先,我们需要分词并增加特殊标记:
tokens = [ [CLS], Paris, is, a, beautiful, city, [SEP] ]
- 1
- 2
接着,我们把这些标记列表喂给预训练的BERT模型,它会返回每个标记的单词表示:
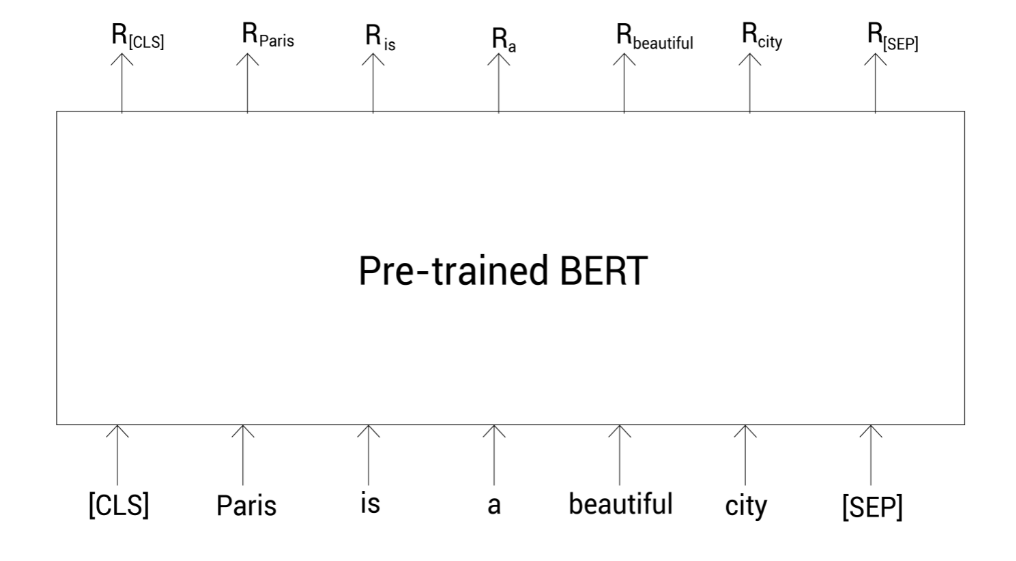
我们已经得到了每个单词的表示,那我们如何得到整个句子的表示呢?我们知道[CLS]标记保存了整个句子的压缩表示。所以我们可以使用该标记对应的向量作为句子表示:
Sentence representation
=
R
[
C
L
S
]
\text{Sentence representation} = R_{[CLS]}
Sentence representation=R[CLS]
但是这样做会有一个问题,就是这种句子表示是不精确的,尤其是我们直接使用未经微调的预训练的BERT。所以,除了这种方式,我们可以使用池化策略。即,我们通过池化所有标记的表示来作为句子表示。
池化可分为平均池化和最大池化。平均池化就是取所有单词表示向量之和的均值,而最大池化则是取[CLS]标记的输出来表示整个句子。
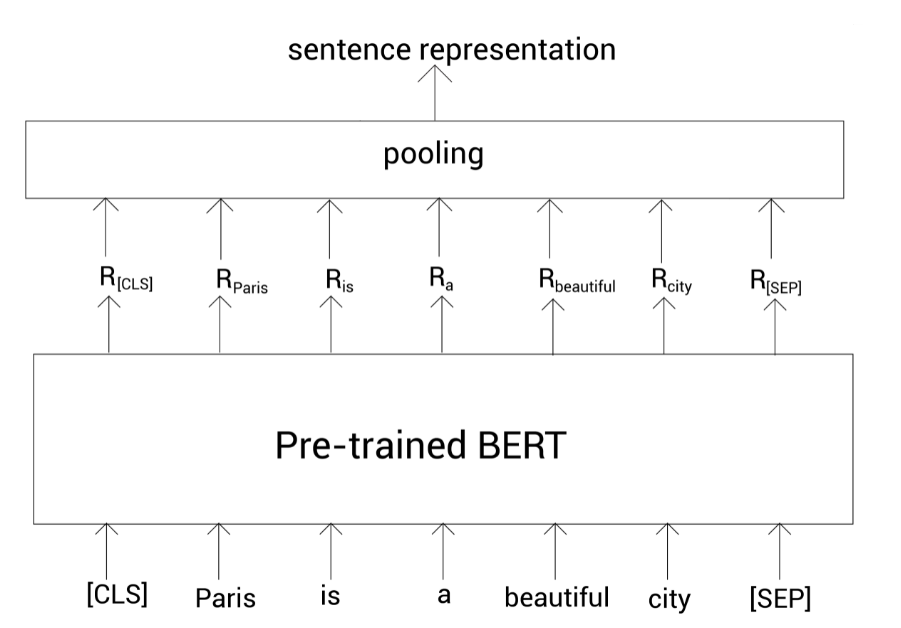
上面介绍的都是取最后一个编码器层的输出进行计算。其实还有其他方法,比如取第一个编码器和最后一个编码器输出之和、以及取倒数第二个编码器层的输出等。
下面我们来看下SBERT。
理解SBERT
SBERT也不是从头开始训练的,它是基于预训练的BERT模型(或变种),然后进行微调获取句子表示。
也就是说,SBERT基本上是一个预训练的BERT模型,并为获取句子表示而微调。
为了微调与训练的BERT模型来获得句子表示,SBERT使用孪生(Siamese)网络和三重态(Triplet)网络,其有助于微调得更快和获取精确的句子表示。
SBERT使用孪生网络来处理涉及句子对输入的任务。并且使用三重态网络来实现三重态损失目标函数。
带有孪生网络的SBERT
SBERT使用孪生网络架构来对句子对任务进行微调。
首先,我们会看到SBERT是如何完成句子对分类任务的,然后我们会学习SBERT是如何用于句子对回归任务的。
SBERT用于句子对分类任务
假设我们有一个数据集包含句子对以及二分类标签,该标签显示这两个句子是相似(1)还是不相似(0)。
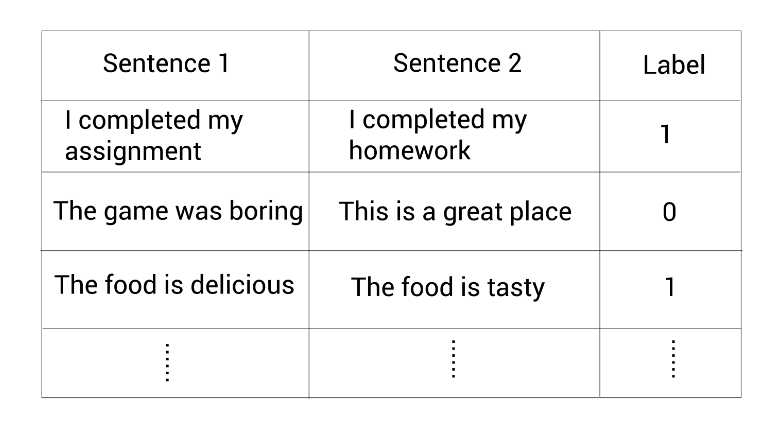
现在,我们看看如何用上面的数据集基于孪生网络来为句子对分类任务微调预训练的BERT模型。首先看看数据集中的第一对句子:
Sentence 1: I completed my assignment
Sentence 2: I completed my homework
- 1
- 2
我们需要判断给定的句子对是相似的(1)还是不相似的(0)。首先,还是老操作:
Tokens 1 = [ [CLS], I completed, my, assignment, [SEP]]
Tokens 2 = [ [CLS], I, completed, my, homework, [SEP]]
- 1
- 2
接着,我们把这些标记喂给预训练的BERT模型(后面如果没有特殊说明的话,简称为BERT模型)然后获得每个标记的向量表示。我们知道了SBERT使用孪生网络。孪生网络其实就是两个共享权重的相同的网络。所以这里我们使用两个完全相同的BERT模型。
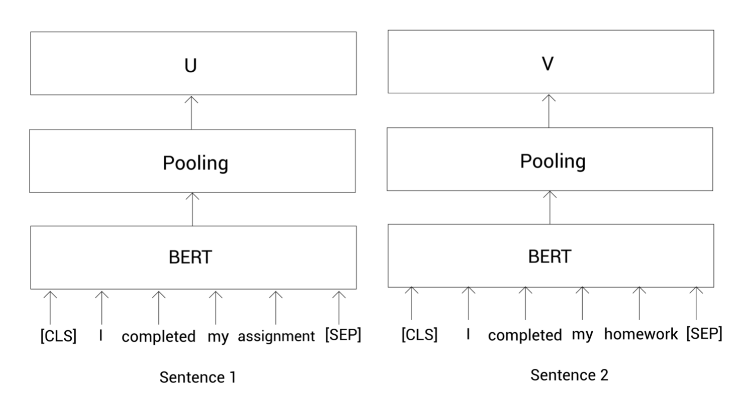
我们把句子1的那些标记列表喂给第一个BERT,把句子2的那些表示列表喂给另一个BERT,然后计算这两个句子的表示向量。
为了计算一个句子的表示向量,我们这里使用平均或最大池化。在SBERT中默认使用平均池化。在应用池化策略之后,我们有了给定句子对的句子表示,如下所示:
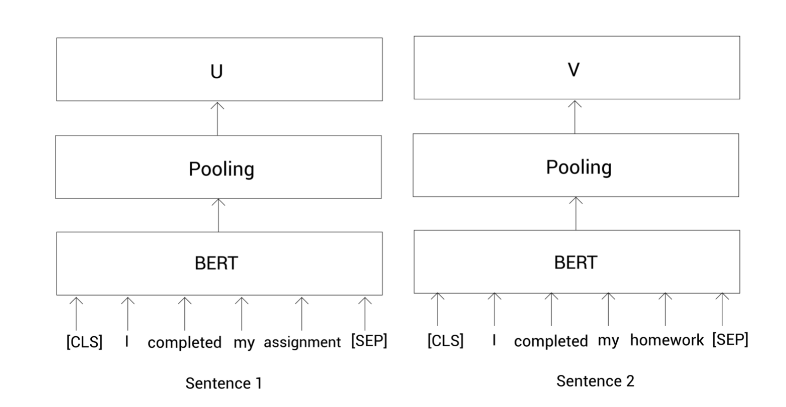
u
u
u代表句1的句子表示;
v
v
v代表句2的句子表示。现在,我们把它们以及它们的元素之差的结果拼接起来,然后乘以一个权重
W
W
W,如下:
(
W
t
(
u
,
v
,
∣
u
−
v
∣
)
)
(W_t(u,v,|u-v|))
(Wt(u,v,∣u−v∣))
注意权重
W
W
W的维度是
n
×
k
n \times k
n×k,其中
n
n
n是句子嵌入的维度;
k
k
k是类别数量。下面,我们把这个结果输入一个Softmax函数,返回给定句子对相似的概率:
Softmax
(
W
t
(
u
,
v
,
∣
u
−
v
∣
)
)
\text{Softmax}(W_t(u,v,|u-v|))
Softmax(Wt(u,v,∣u−v∣))
上面的过程可以用下图描述。首先呢,我们把句子对输入到BERT模型,然后通过池化策略得到句子表示,接着拼接这两个句子表示并乘以一个全球你在
W
W
W,最后经过Softmax函数得到相似概率。
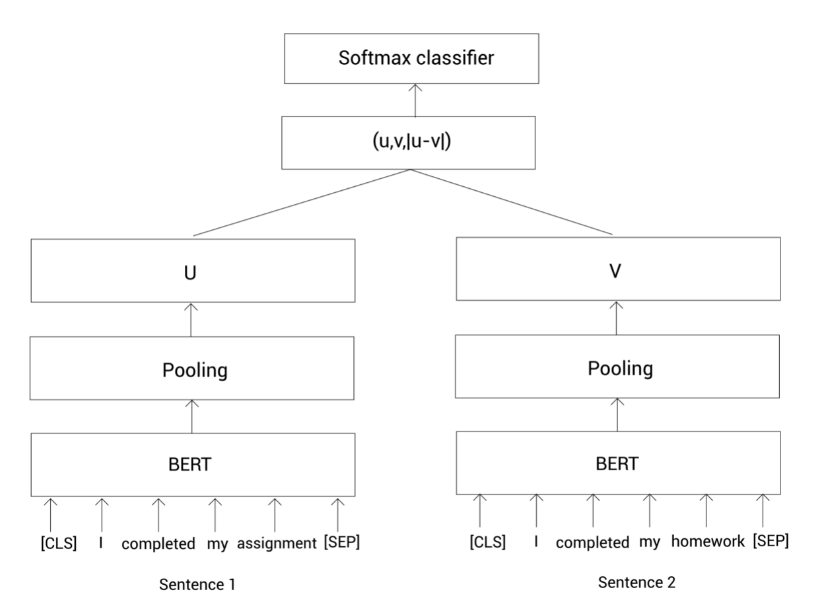
我们通过最小化交叉熵损失来训练上面的网络,同时更新权重 W W W。这样,我们就可以使用SBERT来完成句子对的分类任务。
SBERT用于句子对回归任务
假设我们有一个数据集包含句子对以及它们的相似度值:
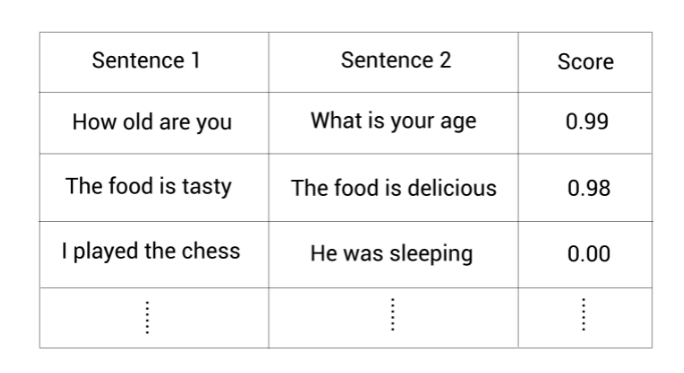
我们看看如何基于上面的数据集使用孪生网络来为句子对回归任务微调BERT模型。在该任务中,我们的目标是预测两个给定句子间的语义相似度。同样看看数据集中第一对句子:
Sentence 1: How old are you
Sentence 2: What is your age
- 1
- 2
现在我们需要计算这两个句子之间的相似度。我们对句子进行一些预处理:
Tokens 1 = [ [CLS], How, old, are, you, [SEP]]
Tokens 2 = [ [CLS], What, is, your, age, [SEP]]
- 1
- 2
然后把这些标记列表输入到BERT模型,并获得每个标记的向量表示。此任务也是基于孪生网络,所以我们有两个一样的BERT模型。我们把句子1喂给第一个BERT模型,把句子2喂给第二个BERT模型,然后计算模型输出的标记表示的均值(池化)。
令
u
u
u代表句子1的表示;
v
v
v代表句子2的表示。然后我们通过余弦相似计算这两个向量表示的相似度:
Similarity
=
cos
(
u
,
v
)
\text{Similarity}=\cos(u,v)
Similarity=cos(u,v)
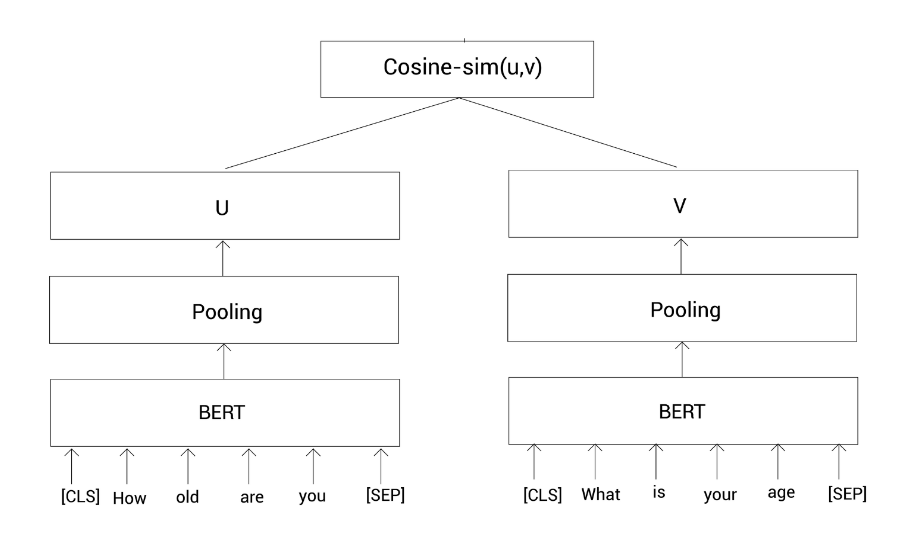
整个过程如上图所示。这里我们通过最小化均方误差损失来训练该网络。这样,我们就可以使用SBERT来做句子对的回归任务。
带有三重态网络的SBERT
假设我们有三个句子,一个Anchor句子,一个正(positive)样本和一个负(negative)样本句子:
- Anchor句子: Play the game
- Positive 句子: He is playing the game
- Negative 句子: Don’t play the game
我们的任务是一个表示让Anchor句子和正样本句子之间的相似度很高,同时Anchor句子和负样本之间的相似度很低。因为我们有三个句子,此时,SBERT使用三重态网络架构。
首先,还是对句子进行预处理,然后喂给三个BERT模型,并通过池化得到每个句子的表示:
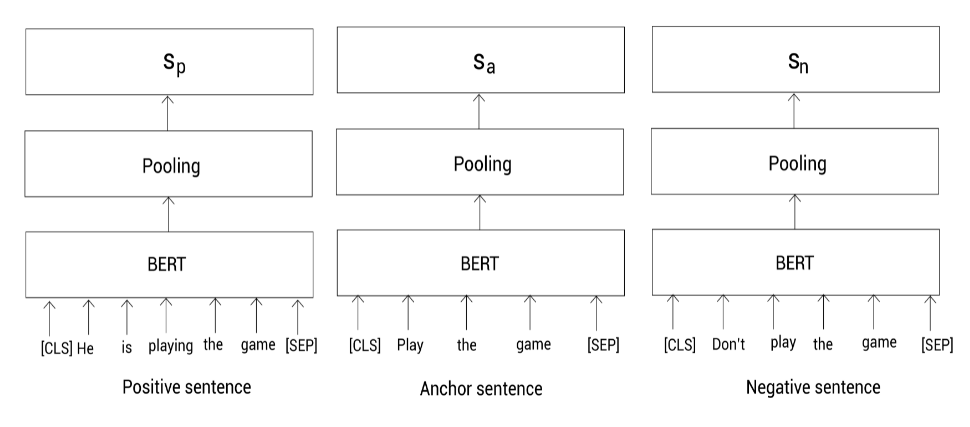
在上图中,我们用
s
a
,
s
p
,
s
n
s_a,s_p,s_n
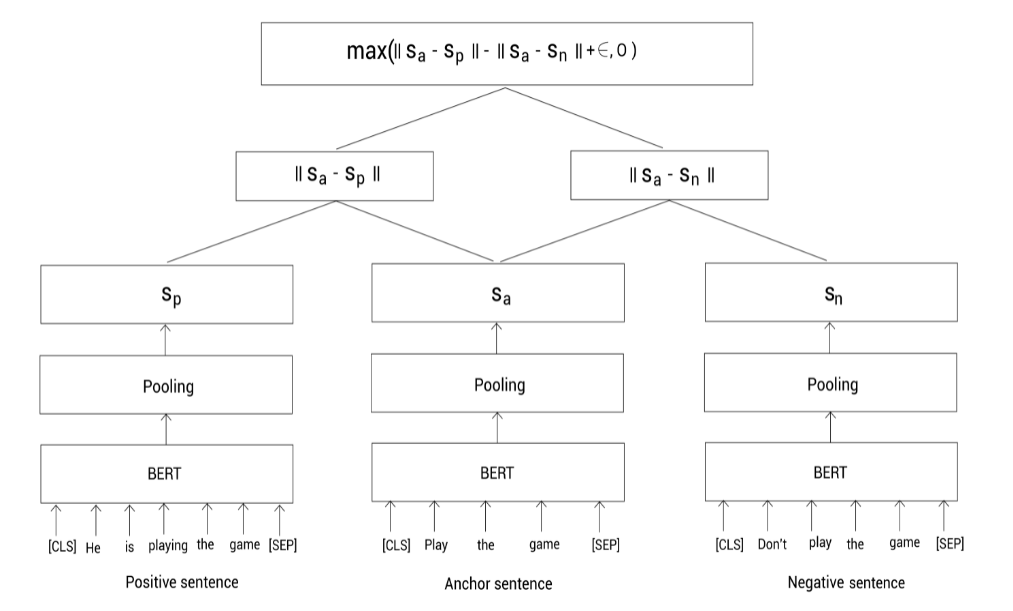
sa,sp,sn分别表示anchor,positive和negative句子的句向量。下面,我们通过最小化下面的三重态目标函数来训练该网络:
max
(
∣
∣
s
a
−
s
p
∣
∣
−
∣
∣
s
a
−
s
n
∣
∣
+
ϵ
,
0
)
\max(||s_a - s_p|| - ||s_a - s_n|| + \epsilon, 0)
max(∣∣sa−sp∣∣−∣∣sa−sn∣∣+ϵ,0)
其中,
∣
∣
⋅
∣
∣
||\cdot||
∣∣⋅∣∣表示距离指标,我们使用欧几里得距离。
ϵ
\epsilon
ϵ表示间隔margin,用于保证正样本句向量
s
p
s_p
sp至少比负样本句向量距离Anchor句向量要近
ϵ
\epsilon
ϵ。
如下图所示,我们分别输入anchor,positive,negative句子到BERT模型,并通过池化得到句向量。然后,训练模型去最小化三重态损失函数。最小化该损失函数确保anchor和positive的相似度要大于和negative的相似度。
SBERT的作者提供了sentence-transformers包来开源他们的代码。
探索sentence-transformers包
理论千遍不如实操一遍。
首先我们通过下面的命令安装这个工具:
pip install -U sentence-transformers
- 1
SBERT的作者发布了他们预训练的SBERT模型。所有预训练的模型可以在这里找到:https://public.ukp.informatik.tu-darmstadt.de/reimers/sentence-transformers/v0.2/ ,可惜没有中文版的。
我们可以返现这些预训练的模型以bert-base-nli-cls-token,bert-base-nli-mean-token,roberta-base-nli-max-tokens,distilbert-base-nli-mean-tokens这样的方式命名。我们来看下是啥意思:
bert-base-nli-cls-token是以预训练BERT-base模型在NLI数据集上进行微调的SBERT模型,并且该模型使用[CLS]标记的输出作为句子表示bert-base-nli-mean-token是以预训练BERT-base模型在NLI数据集上进行微调的SBERT模型,并且该模型使用均值池化策略计算句子表示roberta-base-nli-max-tokens是以预训练RoBERTa-base模型在NLI数据集进行微调的SBERT模型,并且该模型使用均值池化策略计算句子表示distilbert-base-nli-mean-tokens是以预训练DistilBERT-base模型在NLI数据集上进行微调的SBERT模型,并且该模型使用均值池化策略计算句子表示
这样,我们说预训练的SBERT模型,其实基本就是说我们有一个预训练的BERT模型然后使用孪生/三重态网络架构微调它。
那么下面我们就来看看如何使用预训练的SBERT模型。
使用SBERT计算句子表示
首先,我们从sentence_transformers中引入SentenceTransformer模块:
from sentence_transformers import SentenceTransformer
- 1
下载并加载预训练的SBERT:
model = SentenceTransformer('bert-base-nli-mean-tokens')
- 1
定义我们需要计算句子表示的句子:
sentence = 'Peking is a beautiful city'
- 1
使用预训练的SBERT模型的encode函数计算句子表示:
sentence_representation = model.encode(sentence)
- 1
现在,我们来看看该句子表示的维度:
print(sentence_representation.shape)
- 1
(768,)
- 1
嗯,768维。这样我们就使用预训练的SBERT模型得到了固定长度的句子表示。
计算句子相似度
首先引入需要的包:
import scipy
from sentence_transformers import SentenceTransformer, util
- 1
- 2
下载并加载预训练的SBERT模型:
model = SentenceTransformer('bert-base-nli-mean-tokens')
- 1
定义一个句子对:
sentence1 = 'It was a great day'
sentence2 = 'Today was awesome'
- 1
- 2
计算该句子对中每个句子的句子表示:
sentence1_representation = model.encode(sentence1)
sentence2_representation = model.encode(sentence2)
- 1
- 2
接着计算这两个句子表示之间的余弦相似度:
cosin_sim = util.pytorch_cos_sim(sentence1_representation,sentence2_representation)
print(cosin_sim)
- 1
- 2
tensor([[0.9313]])
- 1
我们可以看到相似度有0.93。
加载自定义模型
除了使用官方预定义的模型外,我们也可以使用我们自己的模型。假设我们有一个预训练的ALBERT模型。现在,我们看看如何使用该预训练的ALBERT模型来获得句子表示。
首先,导入必要的模块:
from sentence_transformers import models,SentenceTransformer
- 1
现在,定义我们的词嵌入模型,它可以返回输入句子中每个标记的表示向量。我们使用预训练的ALBERT作为词嵌入模型:
word_embedding_model = models.Transformer('albert-base-v2')
- 1
接下来,我们定义池化模型来对所有标记表示进行池化操作。
我们首先设置池化策略,pooling_mode_mean_tokens = True表示我们使用均值池化来计算定长的句子表示:
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension(),
pooling_mode_mean_tokens=True,
pooling_mode_cls_token=False,
pooling_mode_max_tokens=False)
- 1
- 2
- 3
- 4
好,下面我们使用词嵌入和池化模型来定义SBERT:
model = SentenceTransformer(modules=[word_embedding_model, pooling_model])
- 1
我们可以像下面这样使用该模型计算句子表示:
model.encode('Transformers are awesome')
- 1
该段代码会返回一个768维的向量,代表这个句子的句向量。
通过SBERT查找相似句子
假设我们有一个电子商务网站,假设在我们的数据库中有很多订单相关的问题,比如How to cancel my order?, *Do you provide a refund?*等等。现在当新问题进来时,我们的目标是找到与新问题最相似的问题。
我们看看如何基于SBERT实现这个需求。
首先,导包:
from sentence_transformers import SentenceTransformer, util
import numpy as np
- 1
- 2
加载预训练的SBERT模型:
model = SentenceTransformer('bert-base-nli-mean-tokens')
- 1
定义我们的问题数据库:
master_dict = [
'How to cancel my order?',
'Please let me know about the cancellation policy?',
'Do you provide refund?',
'what is the estimated delivery date of the product?',
'why my order is missing?',
'how do i report the delivery of the incorrect items?'
]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
定义新问题:
inp_question = 'When is my product getting delivered?'
- 1
计算新问题的句子表示:
inp_question_representation = model.encode(inp_question, convert_to_tensor=True)
- 1
然后计算数据库中所有问题的句子表示(实际应该事先计算好):
master_dict_representation = model.encode(master_dict, convert_to_tensor=True)
- 1
现在,计算新问题和数据库中所有问题的余弦相似度:
similarity = util.pytorch_cos_sim(inp_question_representation, master_dict_representation)
- 1
打印最相似的问题:
print('The most similar question in the master dictionary to given input question is:',master_dict[np.argmax(similarity)])
- 1
The most similar question in the master dictionary to given input question is: what is the estimated delivery date of the product?
- 1
这样,我们就可以基于预训练的SBERT模型尝试各种有趣的任务。我们也可以为下游任务继续微调。
参考
- Getting Started with Google BERT

