
- 1“智算”雄起 | 青云科技:智算中心建设、运营两不误
- 2万界星空科技MES系统:食品加工安全的实时监控与智能管理
- 3【PyTorch】解决 No module named ‘torchvision.models.utils‘_no module named 'torchvision.models.utils
- 4如何提交代码到github仓库(2022最新最详细)_github上传代码到仓库
- 5概念:四种基于模型的嵌入式软件开发、测试与验证方法_嵌入式软件建模技术
- 6vscode找不到git
- 7springboot+mysql网上书店管理系统的设计与实现—计算机毕业设计03780
- 8SVN的使用---Windows环境:概述、安装配置、使用详解、多仓库与权限控制、服务配置与管理、扩展程序_svn配置
- 9Antd Form 表单实现单项自定义请求校验_antd form自定义校验
- 10<12>基础知识——进一步了解路由表_路由表和子网
数据结构-LSM树
赞
踩
N.1 LSM树的诞生背景
| 1)传统关系型数据库使用btree或一些变体作为存储结构,能高效进行查找。但保存在磁盘中时它也有一个明显的缺陷,那就是逻辑上相离很近但物理却可能相隔很远,这就可能造成大量的磁盘随机读写。随机读写比顺序读写慢很多,为了提升IO性能,我们需要一种能将随机操作变为顺序操作的机制,于是便有了LSM树。LSM树能让我们进行顺序写磁盘,从而大幅提升写操作,作为代价的是牺牲了一些读性能。 |
N.2 LSM简介
| 1)LSM树(Log-Structured MergeTree),日志结构合并树。 2)LSM树存储引擎和B+树存储引擎一样,同样支持增、删、读、改、顺序扫描操作。而且通过批量存储技术规避磁盘随机写入问题。当然凡事有利有弊,LSM树和B+树相比,LSM树牺牲了部分读性能,用来大幅提高写性能。 3)LSM树核心思想的核心就是放弃部分读能力,换取写入的最大化能力。LSM Tree ,这个概念就是结构化合并树的意思,它的核心思路其实非常简单,就是假定内存足够大,因此不需要每次有数据更新就必须将数据写入到磁盘中,而可以先将最新的数据驻留在内存中,等到积累到足够多之后,再使用归并排序的方式将内存内的数据合并追加到磁盘队尾(因为所有待排序的树都是有序的,可以通过合并排序的方式快速合并到一起)。 4)日志结构的合并树(LSM-tree)是一种基于硬盘的数据结构,与B+tree相比,能显著地减少硬盘磁盘臂的开销,并能在较长的时间提供对文件的高速插入(删除)。然而LSM-tree在某些情况下,特别是在查询需要快速响应时性能不佳。通常LSM-tree适用于索引插入比检索更频繁的应用系统。 LSM树,log-structured,日志结构的,日志是软件系统打出来的,而且系统写日志不会写错,所以不需要更改,只需要在后边追加就好了。各种数据库的写前日志也是追加型的,因此日志结构的基本就指代追加。注意他还是个 “Merge-tree”,也就是“合并-树”,合并就是把多个合成一个 |
N.3 LSM树基本原理
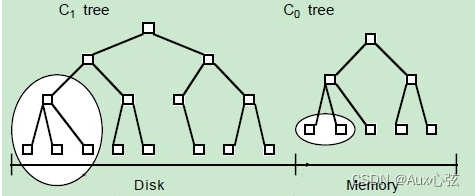
| 1)下图是 LSM-tree 的组成部分,是一个多层结构,就更一个树一样,上小下大。首先是内存的 C0 层,保存了所有最近写入的 (k,v),这个内存结构是有序的,并且可以随时原地更新,同时支持随时查询。剩下的 C1 到 Ck 层都在磁盘上,每一层都是一个在 key 上有序的结构 |
————————————————————————
————————————————————————
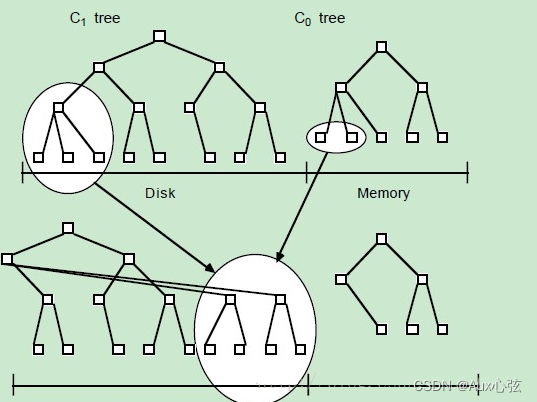
| 2)写入流程:一个 put(k,v) 操作来了,首先追加到写前日志(Write Ahead Log,也就是真正写入之前记录的日志)中,接下来加到 C0 层。当 C0 层的数据达到一定大小,就把 C0 层 和 C1 层合并,类似归并排序,这个过程就是Compaction(合并)。合并出来的新的 new-C1 会顺序写磁盘,替换掉原来的 old-C1。当 C1 层达到一定大小,会继续和下层合并。合并之后所有旧文件都可以删掉,留下新的。注意数据的写入可能重复,新版本需要覆盖老版本. 3)查询流程:在写入流程中可以看到,最新的数据在 C0 层,最老的数据在 Ck 层,所以查询也是先查 C0 层,如果没有查到,再查 C1,逐层查。一次查询可能需要多次单点查询,稍微慢一些。所以 LSM-tree 主要针对的场景是写密集、少量查询的场景。 4)LSM树原理把一棵大树拆分成N棵小树,它首先写入内存中,随着小树越来越大,内存中的小树会flush到磁盘中,磁盘中的树定期可以做merge操作,合并成一棵大树,以优化读性能。 |
————————————————————————
————————————————————————
————————————————————————
N.4 LSM树与B树的差异
| 1)LSM树和B+树的差异主要在于读性能和写性能进行权衡。在牺牲的同时寻找其余补救方案: (1)LSM具有批量特性,存储延迟。当写读比例很大的时候(写比读多),LSM树相比于B树有更好的性能。因为随着insert操作,为了维护B+树结构,节点分裂,性能会逐渐减弱。 (2)B树的写入过程:对B树的写入过程是一次原位写入的过程,主要分为两个部分,首先是查找到对应的块的位置,然后将新数据写入到刚才查找到的数据块中,然后再查找到块所对应的磁盘物理位置,将数据写入去。当然,在内存比较充足的时候,因为B树的一部分可以被缓存在内存中,我们就假定内存很小,只够存一个B树块大小的数据吧。可以看到,在上面的模式中,需要两次随机寻道(一次查找,一次原位写),才能够完成一次数据的写入,代价还是很高的 |
N.5 IO
| 1)对于从磁盘中读取数据的操作,叫做IO操作,这里有两种情况: (1)第一种:假设我们所需要的数据是随机分散在磁盘的不同页的不同扇区中的,那么找到相应的数据需要等到磁臂(寻址作用)旋转到指定的页,然后盘片寻找到对应的扇区,才能找到我们所需要的一块数据,一次进行此过程直到找完所有数据,这个就是随机IO,读取数据速度较慢。 (2)第二种:假设我们已经找到了第一块数据,并且其他所需的数据就在这一块数据后边,那么就不需要重新寻址,可以依次拿到我们所需的数据,这个就叫顺序IO。 |
————————————————————————

————————————————————————

