
- 1Verilog HDL 语言基础_hdl语言
- 2Tkinter 教程-Python Tkinter 单选按钮
- 3c++关联容器,哈希学习笔记。_用哈希函数组织的关联容器是
- 4【opencv】答题卡判分实验
- 5mysql介绍及实操_mysqlcsdn
- 6为ChatGLM-6B模型的训练纪实(三)——阶段性成果展示_chatglm 训练后只会回答训练后的模型数据
- 7【MySQL】事务四大特性以及实现原理
- 8问题解决:Ubuntu安装ROS依赖出现ERROR: the following packages/stacks could not have their rosdep keys resolvedt_could not resolve rosdep key
- 9quartus 13.1自带仿真测试流程_quartusii13.1原理图仿真流程
- 105道Hive典型题目解析_hive 同时在线问题
【自用】NLP算法面经
赞
踩
一、python
1、常用的数据类型
- 字符串(str)
- 列表(list):有序集合,可以向其中添加或删除元素
- 元组(tuple):有序集合,元组不可变
- 字典(dict):无序集合,由键值对构成
- 集合(set):一组key的集合,每个元素都是唯一,不重复且无序
2、字符串常用方法
- 分割,直接在字符串后面跟[a:b],切割的范围为[a,b)
- format控制输出格式
- join连接字符串
- replace字符串替换
- split根据指定字符分割
3、列表常用方法
(1)分割,同str
(2)拼接
- +:返回新的列表
- append:修改原来的列表,会把整个list作为一个元素添加进去
- expend:修改原来的列表,可迭代,把数据拆分成单个元素加进去
(3)删除 - del():根据下标删除元素
- pop():删除最后一个元素
- remove():删除指定元素
(4)排序
sort,默认按照从小到大排序,添加reverse=True可以从大到小排序
4、字典的常用方法
(1)清空,clear()
(2)指定删除,.pop(‘key’)
(3)遍历
三种遍历方式,分别是key,value,item
dict = {
'key1':1,'key2':2}
mykey = [key for key in dict.keys()]
print(mykey)
myvalue = [value for value in dict.values()]
print(myvalue)
myitem = [item for item in dict.items()]
print(myitem)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
(4)创建新字典fromkeys
给一个key列表,然后给一个key值,可接受一个或两个参数,若一个则value为None,若两个则value为指定数
key = ['1','2','3','4','6']
dict = dict.fromkeys(key,0)
- 1
- 2
5、集合的常用方法
(1)创建
set创建可接收可迭代对象
set = {
1,2,3}
set1 = set(list)
- 1
- 2
- 3
(2)删除
- remove()
- discard()
- clear()
remove在元素不存在时会报错,而discard不会。
(3)判断是否存在in
(4)长度获取len()
(5)并union()或|
(6)交intersection()或&
(7)差difference()或-
(8)对称差
仅存在于其中一个集合中的元素构成的集合,symmetric_difference()或^
6、元组的常用方法
元组和数组存储的数据格式大致一致,但无法改变。
count():记录某个元素的出现次数index():返回指定元素在元组中出现的第一个位置
7、is和==的区别
- is比较的是对象的值
- ==比较的是对象的内存地址
8、python函数中的参数类型
- 位置参数:参数是按照它们在函数定义中的位置来传递的
- 关键字参数:通过参数名进行传递的。在函数调用中,指定参数名并提供相应的值。
- 默认参数:函数定义时为参数制定默认值。若在函数调用中为提供该参数的值,则使用默认值。
- 可变参数:允许函数接受任意数量的参数。在函数定义中,使用星号(*)表示可变参数。
9、*arg和**kwargs作用
*arg和**kwargs是用来处理函数调用中的可变数量的参数的常用约定。它们分别用于处理位置参数和关键字参数。
*args将传递给函数的所有位置参数都收集到一个元组中。
**kwargs将传递给函数的所有关键字参数都收集到一个字典中。
10、深浅拷贝
浅拷贝,指的是重新分配一块内存,创建一个新的对象,但里面的元素是原对象中各个子对象的引用,修改里面的子元素,比如说嵌套的list,会导致都改变
深拷贝,是指重新分配一块内存,创建一个新的对象,并将原对象中的元素,以递归的方式,通过创建新的子对象拷贝到新对象中,因此,新对象和原对象没有任何关联。
注意:在python中,元组(tuple)和字符串(str)是不可变对象,这意味着他们的值一旦被创建就无法更改。因此,在进行深拷贝和浅拷贝时,不会创建新的对象副本,而是复制引用。
11、init和new的区别
- __new__是在实例创建之前被调用的,因为它的任务就是创建实例然后返回该实例对象,是个静态方法。
- __init__是当实例对象创建完成后被调用的,然后设置对象属性的一些初始值,通常用在初始化一个类实例的时候,是一个实例方法。
(1)__new__至少要有一个参数cls,代表当前类,此参数在实例化时由python解释器自动识别。
(2)__new__必须要有返回值,返回实例化出来的实例,可以return父类(通过super(当前类名,cls))__new__出来的实例,或者直接是object的__new__出来的实例。
(3)__init__有一个参数self,就是这个__new__返回的实例,__init__在__new__的基础上可以完成一些其他初始化的动作,__init__不需要返回值。
(4)如果__new__创建的是当前类的实例,会自动调用__init__函数,通过return语句里面调用的__new__函数的第一个参数是cls来保证是当前类实例,如果是其他类的类名,那么实际创建返回的就是其他类的实例,其实就不会调用当前类的__init__函数,也不会调用其他类的__init__函数。
12、isinstance和type的区别
isinstance()函数来判断一个对象是否是一个已知的类型,类似type()
- type()不会认为子类是一种父类类型,不考虑继承关系;
- isinstance()会认为子类是一种父类类型,考虑继承关系。
二、深度学习
1、Relu激活函数的作用
f(x)=max(0,x),它的作用是将输入值限制在非负范围内,并且在正半轴上具有线性性质
作用:
- 增强模型非线性表达的能力
- 加速模型训练速度,加大稀疏性,减少模型参数
2、损失函数
(1)均方误差(MSE)
均方误差也叫方法损失函数或最小二乘法。
数学表达式:
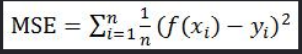
通过计算每个预测值和实际值之间的差值的平方和再求平均,平方损失函数是光滑的,可以用梯度下降法求解,但是当预测值和真实值差异较大时,它的惩罚力度较大,因此对异常点较为敏感。
(2)平方差
两个数先求差值再求平方
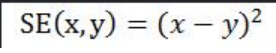
(3)方差以及期望
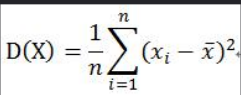
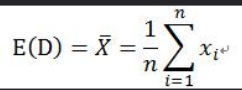
3、IoU
IoU(Intersection over Union,交并比)是衡量两个边界框重叠程度的指标,广泛应用于目标检测任务。计算IoU的步骤如下:
(1)计算交集
- 找到另个边界框的重叠区域
- 计算这个重叠区域的面积
(2)计算并集 - 计算两个边界框的总面积
- 并集面积等于两个边界框总面积-交集面积
(3)计算IoU - 用交集面积除以并集面积
4、模型评估标准
TOP-1和TOP-5
(1)TOP-1准确率
- TOP-1准确率是指在预测结果中,模型输出的最可能的类别与真实标签相符的比例。
- 简单来说,若模型给出的最高概率的类别与真实标签相符,则该样本被视为预测正确。
- TOP-1准确率的计算公式是正确分类的样本数/总样本数。
(2)TOP-5准确率 - TOP-5准确率是指在预测结果中,模型输出的前五个最可能的类别中包含了真实标签的比例。
- 通常来说,TOP-5准确率更宽容,若模型的真实标签在其前五个预测中,则被视为预测正确。
- TOP-5准确率的计算方式是至少有一个正确分类的样本数/总样本数。
5、卷积核与池化层
(1)卷积层
- 输出特征图的宽度 = (输入特征图宽度 - 卷积核宽度 + 2 * 填充)/ 步长 + 1
- 输出特征图的高度 = (输入特征图高度 - 卷积核高度 + 2 * 填充)/ 步长 + 1
- 输出特征图的通道数 = 卷积核个数
- 若有多个输入通道(如RGB图像),则每个通道都会有一个对应的卷积核,最后输出特征图是所有通道的卷积结果的叠加。
(2)池化层
- 输出特征图的宽度 = (输入特征图宽度 - 卷积核宽度) / 步长 + 1
- 输出特征图的高度 = (输入特征图的高度 - 卷积核高度) / 步长 + 1
- 池化操作通常是不填充的,因此输出的尺寸会相应地缩小。
- 池化层不改变特征图的深度(通道数),每个通道的赤化操作是独立进行的。
6、全卷积
核心思想:
- 不含全连接层的全卷积网络,可适应任何尺寸输入;
- 反卷积层增大图像尺寸,输出精细结果;
- 结合不同深度层结果的跳级结构,确保鲁棒性和精确性。
7、梯度下降优化算法
(1)SGD
- 基本思想:SGD在每一步更新中仅使用一个(或一小批)样本来计算梯度,而不是整个数据集。这种方法可以显著减少计算量,使得训练大规模数据集变得可行。
- 学习率:SGD通常需要手动调整学习率,并且可能会使用如学习率衰减这样的技巧来帮助模型收敛。学习率的选择对SGD的性能影响很大。
- 收敛速度:SGD的收敛速度通常比较慢,尤其是在接近最小值的平坦区域。
- 泛化能力:研究表明,由于SGD的噪声更大,它可能有助于模型找到泛化能力更好的解。
(2)Adam(自适应矩估计) - 基本思想:Adam是一种自适应学习率的优化算法,它结合了动量和RMSprop的优点。Adam会为不同的参数计算不同的自适应学习率。
- 学习率:Adam自动调整学习率,通常不需要像SGD那样手动微调学习率,这使得Adam在很多情况下都能较快地收敛;
- 收敛速度:由于自适应学习率的特性,Adam在初期训练阶段通常比SGD收敛得更快。
- 泛化能力:尽管Adam在许多任务中都显示出了较快的收敛速度,但对于某些问题,Adam可能导致过拟合,泛化能力不如SGD。
(3)应用场景 - Adam:由于其易用性和快速收敛的特点,Adam非常适合在需要快速得到结果的场景中使用,特别是在计算资源有限或模型较复杂时。
- SGD:如果模型训练时出现过拟合,或者当你有足够的时间和资源来精细调整学习率时,SGD可能是更好的选择。对于大规模分布式训练,SGD的泛化能力可能更优。
8、层归一化
(1)LayerNorm
对每个样本的特征进行归一化,而不是对整个批次的特征进行归一化。
计算公式:
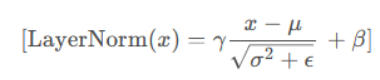
其中,x是输入的特征向量,μ是特征向量的均值,σ是特征向量的标准差,γ和β是学习的缩放系数和平移系数,ε是一个很小的数用于稳定计算。
(2)RMS Norm 均方根Norm
简化了LayerNorm,去掉了计算平均值的部分。计算速度更快,效果甚至略有提升。

