
- 1mac游戏排行榜,mac好玩的游戏推荐 (一)_mac游戏推荐
- 2小白学爬虫-进阶-PySpider操作指北
- 32021.8.1头条_signature分析(后续)_头条爬虫signature
- 4【Python 信号处理】-短时傅里叶变换(STFT)-1_python 短时傅里叶变换
- 5Linux Foundation:边缘计算很快超过云计算,你看着办吧
- 6【数学建模-某肿瘤疾病诊疗的经济学分析】数据分析_数学建模智慧诊疗
- 7OpenCV4 快速入门笔记
- 8国产化中间件东方通TongWeb环境安装部署(图文详解)
- 9vue-element-plus-admin应用教程_vue-element-plus-admin入门教学
- 10TraceId 在AspNETCore日志排障中的应用_netcore track id
粗看最近爆火的mem0个性化轻量级框架:兼谈多模态数据的tokenizer
赞
踩
粗看最近爆火的mem0个性化轻量级框架:兼谈多模态数据的tokenizer
老刘说NLP 2024年07月23日 09:42 北京
我们来看两个问题,一个是mem0(Mem0: The Memory Layer for Personalized AI) 是昨天各大自媒体的头条,很多人都在传,我们来粗浅看看大致有啥特点,怎么做的执行。
另一个是直对不同模态的数据是如何进行切分的感到好奇,因此,看到了一个工作,AnyGPT:序列建模的统一多模态 LLM,AnyGPT,里面涉及到一些不同模态的tokenizer,很有趣,可看看细节。
供大家一起思考并参考。
1、也看mem0个性化轻量级框架
mem0(Mem0: The Memory Layer for Personalized AI) 是昨天各大自媒体的头条,很多人都在传,项目在https://github.com/mem0ai/mem0,对应的文档在https://docs.mem0.ai,感兴趣的可以去看原文。
先说粗鄙结论,这个工具跟RAG没啥关系,也没有可比性,没必要比,它更像是一个集成了对话内存管理的轻量化Agent工具,代码写的很简洁,面向的是用户交互,对话状态的管控,所以大家不要和RAG这些混为一谈。
也就是说,Mem0 更像是面向用户交互的,提供更个性化的内容,提升个性化AI的能力。通过记住用户的偏好等用户画像信息,但是,在自定义的记忆管理规则方面,初始化记忆,但完全依赖LLM,成本较大。
1、其官方文档中,与RAG进行对比
Mem0与检索增强生成(RAG)相比有哪些不同?
Mem0为大型语言模型(LLMs)提供的内存实现比检索增强生成(RAG)有几个优势:
实体关系:Mem0能够理解和关联不同交互中的实体,而RAG则是从静态文档中检索信息。这使得Mem0能够更深入地理解上下文和关系。
这一步,看起来是通过抽取结构化信息来做的,包括人工定义meta。
时效性、相关性和衰减:Mem0优先考虑最近的交互,并逐渐忘记过时的信息,确保内存保持相关和最新,以便更准确地响应。
这个其实不太好,记忆本身有中短长,考虑最近交互,其实有损失。
上下文连续性:Mem0在会话之间保留信息,保持对话和交互的连续性,这对于像虚拟伴侣或个性化学习助手这样的长期参与应用至关重要。
这就是session,很自然的。
自适应学习:Mem0根据用户交互和反馈改进其个性化,随着时间的推移,使内存更加准确和适合个别用户。
这个个性化,依靠用户的meta信息做控制,其实也没啥新鲜。
动态更新:Mem0可以动态地用新信息和交互更新其内存,与依赖静态数据的RAG不同。这允许实时调整和改进,增强用户体验。
依靠里面的更新,删除操作实现,是个动态的pool,这个是很好的,但场景不一样,RAG是面向文档搜索的,不是一回事儿。
2、从调用方式上看其执行原理
-
加载模型
- import os
- from mem0 import Memory
-
定义openai-key,可以看到,需要大模型处理
os.environ["OPENAI_API_KEY"] = "xxx"
-
实例化Initialize Mem0
m = Memory()
-
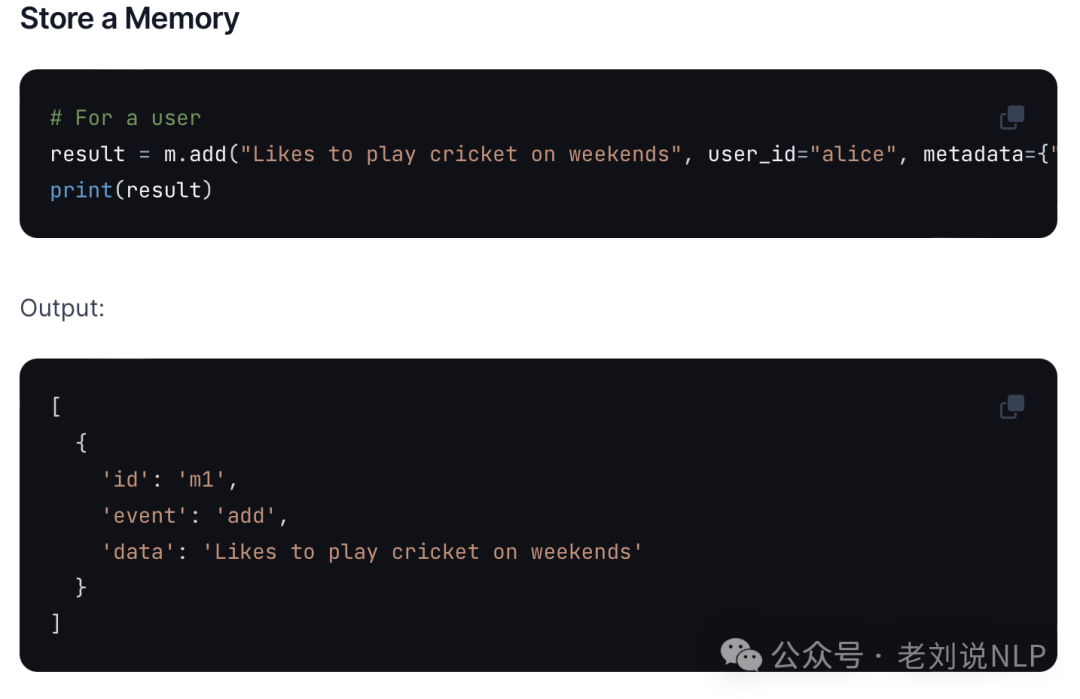
对非结构化文本进行结构化记忆存储,Store a memory from any unstructured text
注意,这个里面的meta信息,需要人工定义,类似于打标签。
- result = m.add("I am working on improving
- my tennis skills.
- Suggest some online courses.",
- user_id="alice",
- metadata={
- "category": "hobbies"}
- )
- print(result)
-
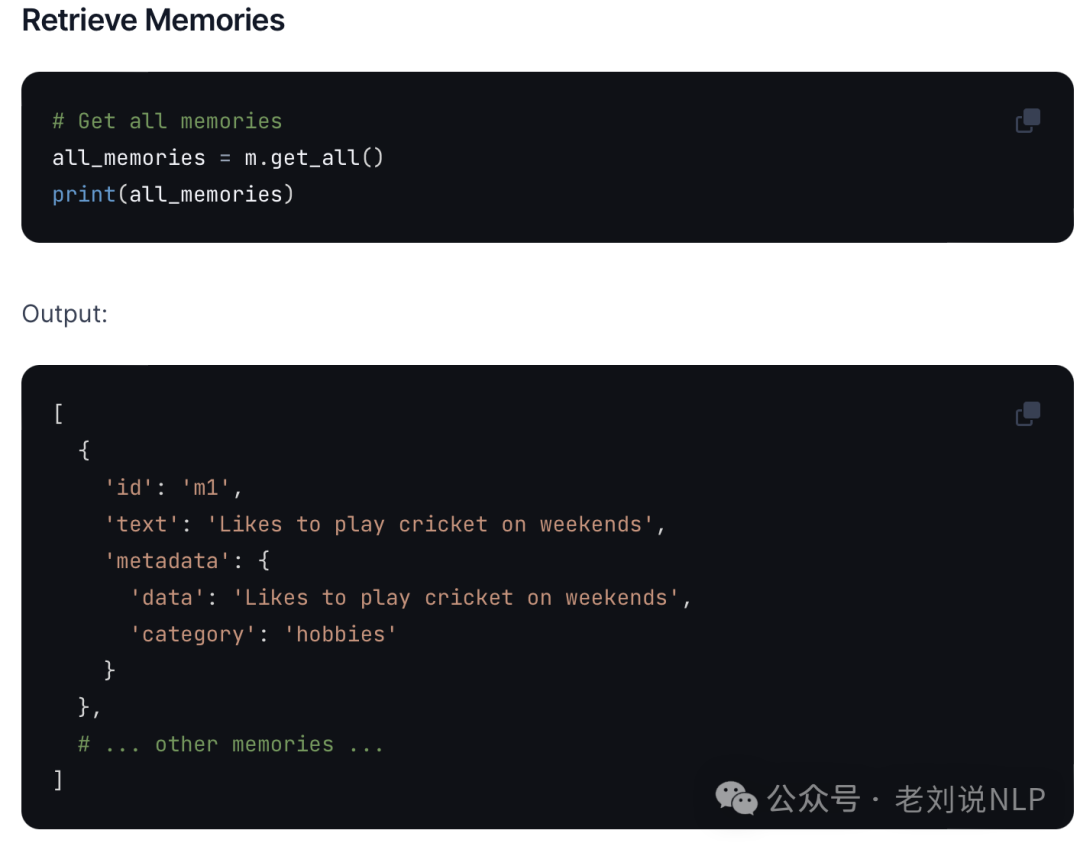
检索记忆,Retrieve memories
这里有点像,RAG的retrieval过程
- all_memories = m.get_all()
- print(all_memories)
-
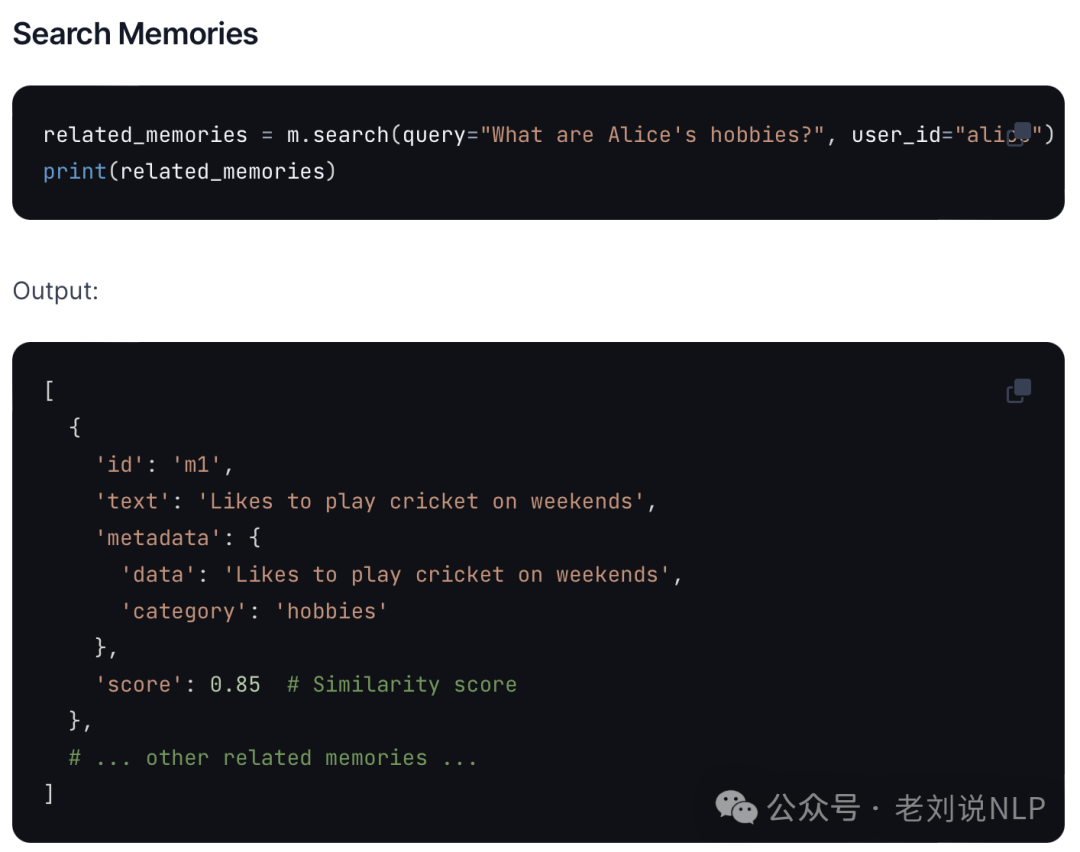
搜索记忆,Search memories
注意,其中引入了user_id这个字段信息,这就是mem0所声称的考虑个性化,也是利用了meta信息,从而作为过滤字段召回记忆。
- related_memories = m.search(
- query="What are Alice's hobbies?",
- user_id="alice")
- print(related_memories)
-
-
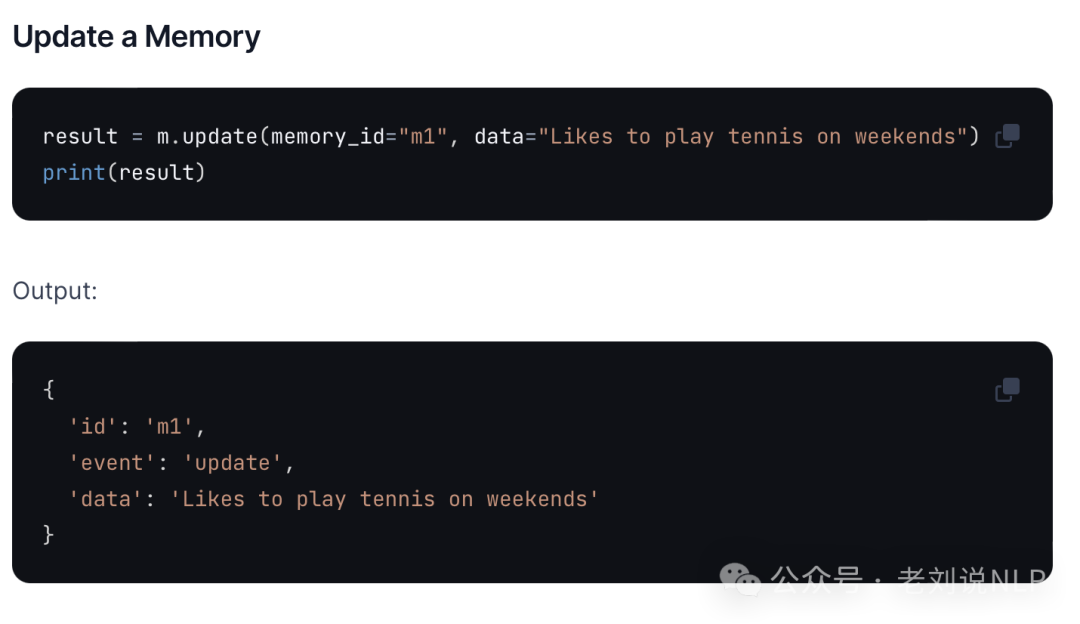
更新记忆,Update a memory
每个记忆都有id,可以更新状态
- result = m.update(
- memory_id="m1",
- data="Likes to play tennis on weekends"
- )
- print(result)
这里是用到了prompt(https://kkgithub.com/mem0ai/mem0/blob/main/mem0/configs/prompts.py):
`UPDATE_MEMORY_PROMPT = """ You are an expert at merging, updating, and organizing memories. When provided with existing memories and new information, your task is to merge and update the memory list to reflect the most accurate and current information. You are also provided with the matching score for each existing memory to the new information. Make sure to leverage this information to make informed decisions about which memories to update or merge.
Guidelines:
-
Eliminate duplicate memories and merge related memories to ensure a concise and updated list.
-
If a memory is directly contradicted by new information, critically evaluate both pieces of information:
-
If the new memory provides a more recent or accurate update, replace the old memory with new one.
-
If the new memory seems inaccurate or less detailed, retain the original and discard the old one.
-
-
Maintain a consistent and clear style throughout all memories, ensuring each entry is concise yet informative.
-
If the new memory is a variation or extension of an existing memory, update the existing memory to reflect the new information.
Here are the details of the task:
-
Existing Memories: {existing_memories}
-
New Memory: {memory} `
-
获取历史记忆,Get memory history,可以根据memory_id进行获取。
- history = m.history(memory_id="m1")
- print(history)

也可以进行记忆删除与重置

关于不同模态的tokenizer
一直对不同模态的数据是如何进行切分的感到好奇,因此,看到了一个工作,AnyGPT:序列建模的统一多模态 LLM,AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling (Arxiv 2024.02),https://arxiv.org/abs/2402.12226v2,https//junzhan2000.github.io/AnyGPT.github.io/,可看看其实现机制。

其中:
1、Image Tokenizer
图像分词器采用SEED实现,这个思路来自于seed_llama。
项目地址:https://ailab-cvc.github.io/seed/seed_llama.html
论文地址:https://arxiv.org/abs/2310.01218
Github地址:https://github.com/AILab-CVC/SEED
可以看看其具体实现细节:
SEED分词器一般由ViT编码器、Causal Q-Former、VQ码本、多层感知器(MLP)和UNet解码器组成。ViT编码器和UNet解码器直接源自预训练的BLIP-2和unCLIP Stable Diffusion(unCLIP-SD)。

其中:
在Tokenize阶段, Causal Q-Former将ViT编码器产生的2D栅格排序特征转换为因果语义嵌入序列,通过VQ码本进一步离散化。
在去标记化阶段,通过MLP将离散的视觉代码解码为生成嵌入。生成嵌入与unCLIP-SD的潜空间对齐,因此可以使用现成的SD-UNet生成具有一致语义的真实图像。
在该工作中,SEED分词器以224×224RGB图像作为输入,经过ViT转成16×16的Patches,再经过CausalQ-Former把Patch的特征转化成32个causalembeddings。另外通过一个大小为8192的codebook将特征转化成量化代码序列。再通过MLP解码成生成嵌入。最后经过UNetdecoder变回原始图像。
2、Speech Tokenizer
语音分词器采用Speech Tokenizer,来自于《Speechtokenizer: Unified speech tokenizer for speech large language models》
github地址:https://github.com/ZhangXInFD/SpeechTokenizer
网页:https://0nutation.github.io/SpeechTokenizer.github.io/
论文地址:https://arxiv.org/pdf/2308.16692v2

SpeechTokenizer采用残差矢量量化RVQ的Encoder-Decoder结构。统一语义和声学标记,SpeechTokenizer在不同的RVQ层上分层地解开语音信息的不同方面。
在该工作中,SpeechTokenizer使用8个分层量化器将单通道音频序列压缩为离散矩阵,每个量化器有1,024个条目,并实现50Hz的帧速率。第1个量化器层捕获语义内容,而第2层到第8层编码副语言细节,可以将10秒的音频转换为500×8的矩阵,分为语义和声学tokens。
3、Music Tokenizer
音乐分词器采用Encodec,来自Meta AI于2022年10月份发表的神经网络音频编解码方法(High Fidelity Neural Audio Compression)。
github地址:github.com/facebookresearch/encodec
论文地址:https://arxiv.org/abs/2210.13438

从模型架构上看,Encodec采用和SoundStream几乎完全一样的Encodecor-Decoder结构。对于24kHz的音频,Encodec和SoundStream一样,经过Encoder之后进行了320倍的降采样,帧率降低至24000/320=75Hz。Encodec还增加了对48kHz音频压缩的支持,经过320倍降采样后帧率降低至150Hz。
在AnyGPT中,该工作使用的Encodec处理32kHz单音音频,实现50Hz的帧速率。生成的嵌入使用具有4个量化器的RVQ进行量化,每个量化器codebook的大小为2048,最终形成8192个组合音乐词表大小。
参考文献
1、https://arxiv.org/abs/2402.12226v2
2、https://docs.mem0.ai/examples/customer-support-agent
总结
本文主要介绍了两件事,一个是mem0,类似于agent,一个是不同模态的tokenizer,这些都是多模态的基础,感兴趣的可以多看看。
- 人人核销 ...
赞
踩

