
- 1python虚拟环境下多进程用queue提示PermissionError: [WinError 5]和put卡住的问题_queue 满了 put 卡死
- 2基于Python爬虫山西太原酒店数据可视化系统设计与实现(Django框架) 研究背景与意义、国内外研究现状
- 3批量测试图像的LPIPS、SSIM、PSNR指标,并生成CSV文件结果_python lpips 评价指标批量评价
- 4访问Github慢如牛,这9种方法让你轻松访问github
- 5Dos命令行基础知识讲解及批处理的编写_dos批处理文件怎么写
- 6Windows 闪退问题排查分析
- 7Unity3D 控制角色八个方向移动也就是斜方向的朝和移动,找了好久没找到就自己写了_unity 2.5d 人物八向移动
- 8C:时间函数 localtime localtime_r
- 9解决windows下安装python并终端运行python弹出windows商店的最终解决方案_pycharm终端输入python跳转到微软商店
- 10AI一键生成原创文案,方法很简单!
深度学习pytorch常见编程技巧
赞
踩
文章目录
- 一、画图、路径、csv、txt、导模块、类继承调用方法
- 写进日志log里面
- pytorch ,可视化1,输出每一层的名字,输出shape,参数量
- 获取当前文件夹路径
- python 获取当前目录 上一级目录 上上一级目录
- 写入xlsx或者csv等文件,如果没有文件夹,则自动创建文件夹
- 保存文件到txt,读取txt文件数值
- 汇总fpr、tpr到excel
- 画多个loss曲线和auc并将数值保存到csv文件
- 将数据保存为.csv,将作图保存到指定文件夹
- 将数据写入txt文件
- 数据写入csv+画图
- pytorch常见的坑解决办法
- 添加同一目录其他文件夹下的其他自己编写的模块
- 导入同一文件夹下其他自己编写的模块
- 类的继承与调用类下的def方法
- 调用同一目录下的数据集
- 获取同一文件夹下的数据集+获取上一级文件夹下的数据集
- 二、数据集重写、遍历、加载
- 三、数据处理
- 取list(numpy)纬度
- 卷积与反卷积公式
- 正则化提高效果
- 将数据由numpy转为list开头的numpy
- 将数据从numpy转到tensor
- 改变数据形状
- 建立长度为3100的一个一维全1列表
- 建立一个全为0的torch
- 将多维list转为一维list
- 将列表中所有数据由numpy转为tensor
- l2-normalize ,z-score normalize
- 创建一个集合将数据放入
- np.random.permutation():随机排列序列
- 将数据放于空列表
- 将一个列表转换成三维ndrray元素
- 删除纬度为1的元素
- 创建指定长度的ndarray的一维列表(值全为1或者0)
- 创建指定长度的ndarray的二维列表(值全为1)
- 将两个元组合并为一个列表zip
- 另一种合并列表的方式
- 调用自定义的数据库并在train函数加载它
- 取某一列的值
- 建立二维值为1的ndarry
- 建立所需纬度的tensor全0值
- 将示例个数小于最大示例个数的包都用-1进行填充(np.concatenate)
- torch.where()函数按指定条件合并两个tensor
- np.where的合理定位选取列表中合适的数值
- 返回随机整型数
- 阈值化处理
- 全连接层操作指南
- squeeze()减少纬度和unsqueeze()增加纬度
- 求三维数据第二维度的最大最小值
- torch.clamp按指定条件裁剪
- 取出tensor中的值
- 把二维list列表转化为一维,实际上是取二维向量的值再放进list列表
- 把三维list列表转化为二维,实际上是取二维向量再放进list列表
- 取某一纬度的最大最小值
- tensor数学操作,相乘最大最小等
- 寻找某一列对应的最大值
- 四、其他
一、画图、路径、csv、txt、导模块、类继承调用方法
写进日志log里面
ma =0
correct = 1
class_num=1
open( str(ma) + ".log", "a+").write("Test " + str(correct / class_num) + "\n")
- 1
- 2
- 3
- 4
pytorch ,可视化1,输出每一层的名字,输出shape,参数量
pytorch ,可视化1,输出每一层的名字,输出shape,参数量
修改此源码为四维输入
获取当前文件夹路径
import os
path = os.path.dirname(__file__) + r"/"
- 1
- 2
python 获取当前目录 上一级目录 上上一级目录
写入xlsx或者csv等文件,如果没有文件夹,则自动创建文件夹
import pandas as pd import os import openpyxl #DataFrame 数据帧,相当于工作簿中的一个工作表 df = pd.DataFrame({ 'id':[1,2,3,4], 'name':['张三','李四','王五','赵刘'], 'arg': [10,20,30,40], 'score':[99,88,77,66] }) #自定义索引,否则pandas会使用默认索引,导致工作表也会存在这些索引 cf = df.set_index('id') # print(cf) #设置文件保存路径 data_path = "../text" #没有,则创建 if not os.path.exists(data_path): # os.mkdir(path) 创建目录第一个ly目录必须存在,第二个目录不存在则会创建第二个目录ly。 # os.makedirs() 用于递归创建目录。只要目录路径下有不存在的目录,就会创建该目录,然后递归的创建文件目录。 os.mkdir(data_path) #设置文件名,以xlsx格式 data_name = os.path.join(data_path,'data.xlsx') #把DataFrame的数据写入excel表 cf.to_excel(data_name) # print("done") #读 data = pd.read_excel('data.xlsx') #查看所有的值 print(data.values)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
保存文件到txt,读取txt文件数值
f = open('adaboost_label.txt', 'w+')
f.write("pre_label_sum:"+str(pre_label_sum)+"\n")
f.write("val_label_sum:"+str(val_label_sum)+"\n")
- 1
- 2
- 3
# txt里面是我保存的两行list
# 读取txt,头文件为空,以:分割
df_test =pd.read_table("test_adaboost_label.txt",header=None,sep=":")
print(df_test)
# 读取loc[0]表示第一行,values表示取值,[1:]表示切片,eval表示将str里面的值取出来
pre_label_sum_test = eval(df_test.loc[0].values[1:][0])
val_label_sum_test = eval(df_test.loc[1].values[1:][0])
print_auc(pre_label_sum_test,val_label_sum_test)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
汇总fpr、tpr到excel
roc = metrics.roc_auc_score(label, score)
fpr, tpr, thresholds = metrics.roc_curve(label, score)
result = (np.vstack((fpr, tpr))).T
nauc = cal_auc_001(fpr, tpr)
print('NAUC:', nauc)
data=pd.DataFrame(result)
writer=pd.ExcelWriter('all4type.xlsx')
data.to_excel(writer,'page_3')
writer.save()
writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
画多个loss曲线和auc并将数值保存到csv文件
#作出训练过程中两个损失随epoch的变化曲线 x = list(range(len(class_loss_history))) f, (ax1, ax2) = plt.subplots(2, 1) ax1.plot(x, feature_loss_history, linewidth=1.8, label='feature loss', color='red') ax1.legend(loc='upper right', prop={'family': 'Times New Roman', 'size': 10}) # 设置图例 ax2.plot(x,class_loss_history, linewidth=1.8, label='classify loss', color='blue') # ax2.plot(x, val_loss_history, linewidth=1.8, label='valid classify loss', color='brown') ax2.legend(loc='upper right', prop={'family': 'Times New Roman', 'size': 10}) # 设置图例 plt.suptitle('Loss change with different epoches') ax1.set_ylabel('Loss', font) ax2.set_xlabel('epoch', font) ax2.set_ylabel('Loss',font) plt.savefig('imag/'+type+'/'+str(type)+'_Loss'+add_part+'.png') plt.show() #作出训练过程中验证集上的AUC/NAUC随epoch的变化曲线 fnew, (ax3, ax4) = plt.subplots(2, 1) ax3.plot(x, val_aucs, linewidth=1.8, label='AUC', color='green') ax3.legend(loc='lower right', prop={'family': 'Times New Roman', 'size': 10}) # 设置图例 ax4.plot(x, val_naucs, linewidth=1.8, label='NAUC', color='black') ax4.legend(loc='lower right', prop={'family': 'Times New Roman', 'size': 10}) # 设置图例 plt.suptitle('AUC/NAUC change with different epoches') ax3.set_ylabel('AUC', font) ax4.set_xlabel('epoch', font) ax4.set_ylabel('NAUC', font) plt.savefig('imag/'+type+'/' + str(type) + '_AUC&NAUC'+add_part+'.png') plt.show() # #模型测试 auc,nauc = model_test(model,test_pos_data,test_neg_data,test_data['GT']) print(type+"_test AUC:",auc) print(type+"_test NAUC:",nauc) #将损失和AUC/NAUC变化保存到csv表格中 dfa = pd.DataFrame() dfa['feature_loss'] = np.array(feature_loss_history) dfa['class_loss'] = np.array(class_loss_history) dfa.to_csv( "results-valid-test/results-toydata/" + type + "-target/siamese_model_res/two_loss/res-fpr-tpr/" + type + '-loss-' + add_part + '_'+ str( auc)[:7] + '.csv', index=False) dfb = pd.DataFrame() dfb['AUC'] = np.array(val_aucs) dfb['NAUC'] = np.array(val_naucs) dfb.to_csv( "results-valid-test/results-toydata/" + type + "-target/siamese_model_res/two_loss/res-fpr-tpr/" + type + '-auc-' + add_part +'_'+ str( auc)[:7] + '.csv', index=False)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
将数据保存为.csv,将作图保存到指定文件夹
import pandas as pd
df = pd.DataFrame()
df['fpr'] = fpr
df['tpr'] = tpr
df.to_csv(modelpath+'-fpr-tpr.csv', index=False)
roc_auc = auc(fpr, tpr)
auc_0001 = cal_auc_001(fpr, tpr)
print(modelpath + "千分之1-auc:", auc_0001)
plt.plot(fpr, tpr, lw=2, alpha=0.3, label='ROC fold %d (AUC = %0.2f)' % (1, roc_auc))
plt.xlim(0, 0.001)
plt.savefig("results-valid-test/results-"+modelpath+"/roc_new-" + str(0) + ".png")
plt.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
将数据写入txt文件
f = open('green.txt', 'a+')
f.write(str(epoch)+':'+str(auc_001)+"\n")
- 1
- 2
数据写入csv+画图
import pandas as pd
df = pd.DataFrame()
df['fpr'] = fpr
df['tpr'] = tpr
df.to_csv(modelpath+'-fpr-tpr.csv', index=False)
roc_auc = auc(fpr, tpr)
auc_0001 = cal_auc_001(fpr, tpr)
print(modelpath + "千分之1-auc:", auc_0001)
plt.plot(fpr, tpr, lw=2, alpha=0.3, label='ROC fold %d (AUC = %0.2f)' % (1, roc_auc))
plt.xlim(0, 0.001)
plt.savefig("results-valid-test/results-"+modelpath+"/roc_new-" + str(0) + ".png")
plt.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
pytorch常见的坑解决办法
添加同一目录其他文件夹下的其他自己编写的模块
方法一:
import sys
sys.path.append(r".\public")
from load_data import loadmat
- 1
- 2
- 3
所有的主程序在fc mil下
想调用public下的load_data.py
方法二:
import os
import sys
path =os.path.dirname(os.path.dirname(__file__))+r"/public"
sys.path.append(path)
from pubilc.load_data import loadmat
- 1
- 2
- 3
- 4
- 5
导入同一文件夹下其他自己编写的模块
# 调用gulfport_fc_model下的FC_weights类
from gulfport_fc_model import FC_weights
# 调用gendata_gulfport_v2.py
import gendata_gulfport_v2 as new_gendata
- 1
- 2
- 3
- 4
类的继承与调用类下的def方法
model = FC_weights()
model.calculate_objective(data_pos, label_pos, 1, int_label)
- 1
- 2
调用同一目录下的数据集
datapath = './data/pea green/'
- 1
代码和data数据集都在fc mil文件夹中,我们调用fc mil文件夹下的data文件夹下的数据集
获取同一文件夹下的数据集+获取上一级文件夹下的数据集
获取同一文件夹下的数据集
datapath = './data/pea green/'
- 1
这些东西同在fc mil文件夹下,数据集和.py文件
获取上一级文件夹下的数据集
.py(代码)文件在fc mil文件夹下,数据集在toydata文件夹下
datapath = '../toydata/015-tar-3-points-25/convex_subpixel_ptmean_05_SNR_30_sigma_50_Nb_2_Train_015.mat'
- 1

二、数据集重写、遍历、加载
自定义数据集
class customDataset(Dataset):
"""custom dataset"""
def __init__(self, samples: List[Tuple]):
self.samples = samples
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
return self.samples[idx]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
""" inout pipline for custom dataset """ from torch.utils.data.dataset import Dataset class CustomDataset(Dataset): def __init__(self): """ 一些初始化过程写在这里 """ # TODO # 1. Initialize file paths or a list of file names. pass def __getitem__(self, index): """ 返回数据和标签,可以这样显示调用: img, label = MyCustomDataset.__getitem__(99) """ # TODO # 1. Read one data from file (e.g. using numpy.fromfile, PIL.Image.open). # 2. Preprocess the data (e.g. torchvision.Transform). # 3. Return a data pair (e.g. image and label). pass def __len__(self): """ 返回所有数据的数量 """ # You should change 9 to the total size of your dataset. return 9 # e.g. 9 is size of dataset
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
遍历三维数据
# pos三维的,我们一层一层的遍历 for idx in range(len(pos)): # 取出二维数据 pos_data = pos[idx] # 25示例取最大 instances_label = [] for data in pos_data: data = torch.FloatTensor(data) data = data.unsqueeze(1).float().to(device).view(1, 1, 1, 64) # shape (batch_size, channel=1, bag_size, sig_dim 91) label = [1.0] label = torch.FloatTensor(label) #label = label.unsqueeze(1) label = label.to(device).view(-1, 1) # shape (batch_size, 1) if usegpu: error, predicted_label, p_prob = model.module.calculate_classification_error(data, label) else: error, predicted_label, p_prob = model.calculate_classification_error(data, label) val_error += error instances_label.append(p_prob.cpu().item()) pre_labels.append([max(instances_label)]) val_label.append(1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
构建一次的train_loder(DataLoader函数)
train_dataloader = DataLoader(
train_dataset,
batch_size=128,
# shuffle=True,#有sampler就不能使用shuffle
sampler=sampler,
num_workers=2,
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
方法如下:
接下来,我们来继承 Dataset类 ,写一个将数据处理成DataLoader的类。
当我们集成了一个 Dataset类之后,我们需要重写 len 方法,该方法提供了dataset的大小; getitem 方法, 该方法支持从 0 到 len(self)的索引
class DealDataset(Dataset): """ 下载数据、初始化数据,都可以在这里完成 """ def __init__(self): xy = np.loadtxt('../dataSet/diabetes.csv.gz', delimiter=',', dtype=np.float32) # 使用numpy读取数据 self.x_data = torch.from_numpy(xy[:, 0:-1]) self.y_data = torch.from_numpy(xy[:, [-1]]) self.len = xy.shape[0] def __getitem__(self, index): return self.x_data[index], self.y_data[index] def __len__(self): return self.len # 实例化这个类,然后我们就得到了Dataset类型的数据,记下来就将这个类传给DataLoader,就可以了。 dealDataset = DealDataset() train_loader2 = DataLoader(dataset=dealDataset, batch_size=32, shuffle=True) for epoch in range(2): for i, data in enumerate(train_loader2): # 将数据从 train_loader 中读出来,一次读取的样本数是32个 inputs, labels = data # 将这些数据转换成Variable类型 inputs, labels = Variable(inputs), Variable(labels) # 接下来就是跑模型的环节了,我们这里使用print来代替 print("epoch:", epoch, "的第" , i, "个inputs", inputs.data.size(), "labels", labels.data.size())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
dataloader获取数据集并进行循环遍历
val_dataloader = DataLoader( neg, batch_size=128, shuffle=False, num_workers=2, ) # 每一个batch获取的是128的元素 for i, batch in enumerate(val_dataloader): data = batch[0].unsqueeze(1).float().to(device) # shape (batch_size, channel=1, bag_size, sig_dim 91) label = batch[1].float().to(device).view(-1, 1) # shape (batch_size, 1) # mask = batch[2].float().transpose(1, 2).to(device) # shape (batch_size, bag_size, 1) if usegpu==True: error, predicted_label, p_prob = model.module.calculate_classification_error(data, label) else: error, predicted_label, p_prob = model.calculate_classification_error(data, label) val_error += error tmp_label = p_prob.squeeze(2).cpu().data.numpy().tolist() pre_labels.extend(tmp_label) val_label.extend([0]*len(tmp_label))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
子类继承父类方法数据处理,重写父类方法
class MyData(data_utils.Dataset): def __init__(self,dataA,dataB,label=None,labelA = None,labelB = None): self.dataA = dataA self.dataB = dataB self.label = label self.labelA = labelA self.labelB = labelB def __len__(self): return len(self.dataA) def __getitem__(self,idx): if self.label: tuple_ = (self.dataA[idx], self.dataB[idx], self.label[idx],self.labelA[idx],self.labelB[idx]) else: tuple_ = (self.dataA[idx], self.dataB[idx]) return tuple_
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
DataLoader技巧: 加载数据
# 构造collate_fn函数秀的一匹
def collate_fn(data):
# data.sort(key=lambda x:len(x[0]),reverse=True)
dataA = [sq[0] for sq in data]
dataB = [sq[1] for sq in data]
label = [sq[2] for sq in data]
labelA = [sq[3] for sq in data]
labelB = [sq[4] for sq in data]
dataA_length = [len(sq) for sq in dataA]
dataB_length = [len(sq) for sq in dataB]
dataA = rnn_utils.pad_sequence(dataA,batch_first=True,padding_value=0)
dataB = rnn_utils.pad_sequence(dataB,batch_first=True,padding_value=0)
# label = rnn_utils.pad_sequence(label,batch_first=True,padding_value=0)
return dataA.unsqueeze(1),dataB.unsqueeze(1),label,labelA,labelB,dataA_length,dataB_length
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
# 好好理解一下collate_fn,这个相当于对数据进一步处理,相当于DataLoader每次迭代的返回值就是collate_fn的返回值,很秀。
data = MyData(bagsA,bagsB,label,labelA,labelB)
data_loader = DataLoader(data,batch_size=self.batch,shuffle=True,collate_fn=collate_fn)
- 1
- 2
- 3
加载.mat数据集+选取指定文件夹+循环遍历将元素放于列表中
加载.mat数据集
pos_data1 = loadmat(path + 'pos_bags1.mat')
- 1
选取指定文件夹
pos_data_tmp = pos_data1['pos_bags']
- 1
循环遍历
pos_data1 = [i for i in pos_data_tmp]
- 1
三、数据处理
取list(numpy)纬度
原数据
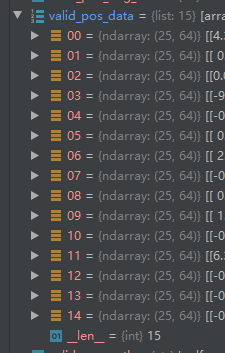
valid_pos_bag_num = len(valid_pos_data)# 15
valid_instance_num = valid_pos_data[0].shape[0]# 25
valid_feature_num = valid_pos_data[0].shape[1]# 64
- 1
- 2
- 3
卷积与反卷积公式
正则化提高效果
#l2-normalize
train_data['X'] = normalize(train_data['X'], norm='l2', axis=1)
#z-score normalize
# train_mean = np.mean(train_data['X'], axis=0)
# train_std = np.std(train_data['X'], axis=0)
# train_data['X'] = (train_data['X']-train_mean)/train_std
- 1
- 2
- 3
- 4
- 5
- 6
- 7
# np.vstack:按垂直方向(行顺序)堆叠数组构成一个新的数组
norm_data = np.vstack((pos_data,neg_data))
# # #z标准化 ### axis=0,计算每一列的均值
norm_data_mean = np.mean(norm_data, axis=0)
norm_data_std = np.std(norm_data,axis=0)
norm_data = (norm_data-norm_data_mean)/norm_data_std
# # #l2 norm标准化
# norm_data = normalize(norm_data, norm='l2', axis=0)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

将数据由numpy转为list开头的numpy
pos_data = list(norm_data[:pos_bag_num*instance_num].reshape(pos_bag_num,instance_num,feature_num))
- 1
数据由numpy类型的(15,25,64)变为

将数据从numpy转到tensor
pos_bags = [torch.from_numpy(bag).float() for bag in self.pos_bags]
- 1
改变数据形状
H = H.reshape(H.shape[0], H.shape[1], H.shape[2] * H.shape[3]) # (batch_size, bag_size, channel * height)
- 1
tmp = np.reshape(tmp, (len(tmp), 25))
- 1
pos_data4 = pos_data4.transpose((0, 2, 1))
- 1

变为

tmp = np.reshape(tmp, (len(tmp), 1))
- 1

变为
data = data.permute(0, 1, 3, 2)
- 1

变为

# 交换第二和第三纬度
H = H.transpose(1, 2) # swap channel and bag_size
- 1
- 2
dense_max = dense_max.repeat(1,dense_out.shape[1],1)
- 1
纬度由([128,1,1])
变为

建立长度为3100的一个一维全1列表
label = []
label += [1] * len(pos_bagsB)
- 1
- 2
结果如下

建立一个全为0的torch
z = torch.zeros(dense_out.shape).to(device)
- 1

将多维list转为一维list
from Tkinter import _flatten
pos_neg_bagsB = list(_flatten(pos_neg_bagsB))
- 1
- 2
- 3
没用函数前pos_neg_bagsB为

用完之后

将列表中所有数据由numpy转为tensor
labelB = [torch.from_numpy(np.array(y)).float() for y in labelB]
- 1
转之前:

转之后:

l2-normalize ,z-score normalize
#l2-normalize
train_data['X'] = normalize(train_data['X'], norm='l2', axis=1)
#z-score normalize
# train_mean = np.mean(train_data['X'], axis=0)
# train_std = np.std(train_data['X'], axis=0)
# train_data['X'] = (train_data['X']-train_mean)/train_std
- 1
- 2
- 3
- 4
- 5
- 6
创建一个集合将数据放入
valid_data_dic = {'pos_bag':[],'neg_bag':[]}
valid_data_dic['pos_bag'] += valid_pos_bag
valid_data_dic['neg_bag'] += valid_neg_bag
- 1
- 2
- 3
结果如下

np.random.permutation():随机排列序列
out = [np.random.permutation(l) for l in bags]
- 1
将数据放于空列表
neg_data_tmp = []
# a =neg_data1.shape
# b=a[1]
# 流程一步步运行看一下
for i in range(neg_data1.shape[1]//25):
tmp = neg_data1[:, i * 25:i * 25 +25]
tmp = np.reshape(tmp, (len(tmp), 25))
# 下采样
if i % 1 == 0:
# i = i + 25
neg_data_tmp.append(tmp)
neg_data1 = neg_data_tmp
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
将一个列表转换成三维ndrray元素
pos_data = [i for i in pos_data if len(i)>0]
pos_data = np.array(pos_data)
- 1
- 2
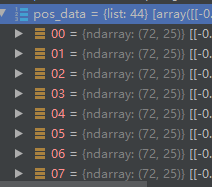
变为
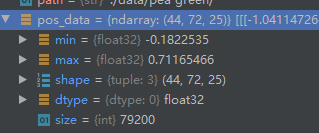
bag = np.transpose(bag_t)
- 1

变为

删除纬度为1的元素
re_band = [0, 1, 2, 3, 68, 69, 70, 71]
pos_data = np.delete(pos_data, re_band, axis=1)
- 1
- 2
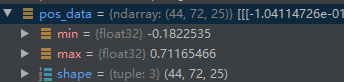
变为
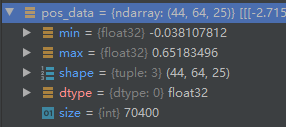
创建指定长度的ndarray的一维列表(值全为1或者0)
#len(pos_data)显示的44即为pos_data三维向量的第一个纬度。
pos_label = np.array([float(1.0)] * len(pos_data))
neg_label = np.array([float(0.0)] * len(neg_data))
- 1
- 2
- 3
- 4

创建指定长度的ndarray的二维列表(值全为1)
#len(pos_data)显示的44即为pos_data三维向量的第一个纬度。
p_int_label = np.array([[float(1.0)]*25 for i in range(len(pos_data))])
- 1
- 2

将两个元组合并为一个列表zip
inputs = list(zip(neg_data, neg_label))
- 1
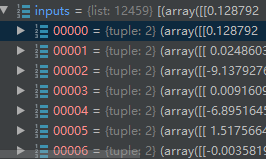

另一种合并列表的方式
poss_ = [pos_data, pos_label]
- 1
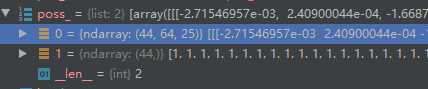
调用自定义的数据库并在train函数加载它
inputs = list(zip(neg_data, neg_label))
train_dataset = customDataset(inputs)
poss_ = [pos_data, pos_label]
return train_dataset, poss_, p_int_label
- 1
- 2
- 3
- 4
datapath = './data/dark green/'
from torch.utils.data.sampler import WeightedRandomSampler
train_dataset, train_pos, pos_int_label = new_gendata.train_dataset(datapath)
weights = [2 if label[1]==1 else 1 for label in train_dataset]
sampler = WeightedRandomSampler(weights, num_samples=len(weights), replacement=True)
train_dataloader = DataLoader(
train_dataset,
batch_size=128,
# shuffle=True,
sampler=sampler,
num_workers=2,
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
取某一列的值
tmp = neg_data4[:, i]
- 1
建立二维值为1的ndarry
bag_mask = np.ones((1, padding_size))
- 1

建立所需纬度的tensor全0值
b = torch.zeros(dense_out.shape).to(device)
- 1
- 2
将示例个数小于最大示例个数的包都用-1进行填充(np.concatenate)
bag = np.concatenate((bag, - np.ones((extra_size, bag.shape[1]))), axis=0)
- 1
torch.where()函数按指定条件合并两个tensor
作用是按照一定的规则合并两个tensor类型。
dense_out_max = torch.where(dense_out_max ==1, dense_out, dense_out_max)
- 1
import torch >>> a=torch.randn(3,5) >>> b=torch.ones(3,5) >>> a tensor([[-0.0310, 1.5895, 1.6003, -1.7584, 1.1478], [ 0.6773, 0.7763, 0.5024, 0.4952, 0.4198], [ 1.5132, 0.5185, 0.2956, -0.6312, -1.4787]]) >>> b tensor([[1., 1., 1., 1., 1.], [1., 1., 1., 1., 1.], [1., 1., 1., 1., 1.]]) >>> torch.where(a>0,a,b) #合并a,b两个tensor a>0的地方保存 tensor([[1.0000, 1.5895, 1.6003, 1.0000, 1.1478], [0.6773, 0.7763, 0.5024, 0.4952, 0.4198], [1.5132, 0.5185, 0.2956, 1.0000, 1.0000]])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
np.where的合理定位选取列表中合适的数值
p_bags = []
a =[]
b=[]
for i in range(num_pos_bags):
# labels ==(i+1)返回ture或者false
b.append(labels==(i+1))
# np.where(labels==(i+1))返回索引的坐标
a.append(np.where(labels==(i+1)))
# 取值
p_bags.append(train_data[np.where(labels==(i+1))])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
返回随机整型数
# len(train_pos[0])为44,所以返回64个0-43之间的随机整形数
ind = np.random.randint(0, len(train_pos[0]), 64)
- 1
- 2
阈值化处理
Y_hat = torch.ge(Y_prob, 0.5).float() # 比较两个张量,Y_prob是否大于等于0.5,成立则放回1,否则返回0
- 1
全连接层操作指南
self.feature_extractor_part2 = nn.Sequential(
# apply a linear transformation on incoming data
# y = Ax + b
nn.Linear(320, self.L),
nn.LeakyReLU(),
)
- 1
- 2
- 3
- 4
- 5
- 6
H = self.feature_extractor_part2(H) # (batch_size, bag_size, L=500)
- 1
对最后一个纬度进行操作

变为

squeeze()减少纬度和unsqueeze()增加纬度
unsqueeze()
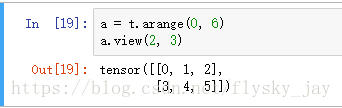
可以看出a的维度为(2,3)
在第二维增加一个维度,使其维度变为(2,1,3)
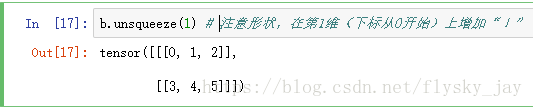
可以看出a的维度已经变为(2,1,3)了,同样如果需要在倒数第二个维度上增加一个维度,那么使用b.unsqueeze(-2)
squeeze()函数介绍
- 首先得到一个维度为(1,2,3)的tensor(张量)
.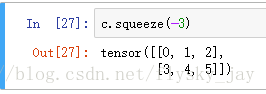
由图中可以看出c的维度为(1,2,3)
2.下面使用squeeze()函数将第一维去掉
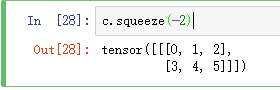
可见,维度已经变为(2,3)
求三维数据第二维度的最大最小值
val1, _ = torch.max(Y_prob.squeeze(2), dim=1)
val2, _ = torch.min(Y_prob.squeeze(2), dim=1)
- 1
- 2
torch.clamp按指定条件裁剪
y_prob = torch.clamp(y_prob, min=1e-5, max=1. - 1e-5)
- 1
取出tensor中的值

把二维list列表转化为一维,实际上是取二维向量的值再放进list列表
pre_labels = [pre_labels[i][0] for i in range(len(pre_labels))]
- 1

变为

把三维list列表转化为二维,实际上是取二维向量再放进list列表
pre_labels = [pre_labels[i][0] for i in range(len(pre_labels))]
- 1

变为

取某一纬度的最大最小值
val1, _ = torch.max(Y_prob.squeeze(2), dim=1)
val2, _ = torch.min(Y_prob.squeeze(2), dim=1)
- 1
- 2
tensor数学操作,相乘最大最小等
寻找某一列对应的最大值
请问像这种数组,我要找第一列数值为十所对应的第二列的最大值代码是什么样的啊,有内置函数吗


四、其他
预参数自动加载argparse.ArgumentParser
# Training settings
def get_parser():
"""get parser for demo_gpu_newdata.py"""
parser = argparse.ArgumentParser(description='PyTorch bags')
parser.add_argument('--epochs', type=int, default=500, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=0.0001, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--reg', type=float, default=1e-4, metavar='R',
help='weight decay')
parser.add_argument('--seed', type=int, default=1234, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--cuda', action='store_true', default=True,
help='use CUDA training')
return parser
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
# 调用
args = get_parser().parse_args()
- 1
- 2
设置随机种子以使得结果是确定的
torch.manual_seed(args.seed) #为CPU设置种子用于生成随机数,以使得结果是确定的
torch.manual_seed(args.seed) # set random seed on CPU
torch.cuda.manual_seed(args.seed) # set random seed on GPU
- 1
- 2
- 3
很有用的采样方法(重采样): WeightedRandomSampler,
它会根据每个样本的权重选取数据,**在样本比例不均衡的问题中,可用它来进行重采样。**构建WeightedRandomSampler时需提供两个参数:每个样本的权重weights、共选取的样本总数num_samples,以及一个可选参数replacement。权重越大的样本被选中的概率越大,待选取的样本数目一般小于全部的样本数目。replacement用于指定是否可以重复选取某一个样本,默认为True,即允许在一个epoch中重复采样某一个数据。如果设为False,则当某一类的样本被全部选取完,但其样本数目仍未达到num_samples时,sampler将不会再从该类中选择数据,此时可能导致weights参数失效。
sampler = WeightedRandomSampler(weights, num_samples=len(weights), replacement=True)
- 1
设备选择(GPU or CPU)
device = torch.device("cuda" if args.cuda and torch.cuda.is_available() else 'cpu')
- 1
加载模型选择gpu、多gpu,cpu
model = FC_weights()
device = torch.device("cuda" if args.cuda and torch.cuda.is_available() else 'cpu')
use_gpu = False
# 使用多gpu
if args.cuda and torch.cuda.device_count() > 1:
print(f'Use {torch.cuda.device_count()} GPUs.')
model = nn.DataParallel(model)
use_gpu = True
else:
print('Use CPU.')
model.to(device)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
加载训练好的模型
path_model = "results-valid-test/results-green/val-model-model-l1-0-0.6223.pt"
checkpoint = torch.load(path_model)
model.load_state_dict(checkpoint['model_state_dict'])
model.eval()
- 1
- 2
- 3
- 4
验证,测试过程必须加上model.eval()否则改变权值
def val(epoch, model, val_data, device, usegpu=True):
model.eval()
- 1
- 2
checkpoints = torch.load('results-valid-test/results-015/val-model-model-l1-0-0.8577.pt')
model.load_state_dict(checkpoints['model_state_dict'])
model.eval()
print("start testing:..........")
pos_test = new_gendata.test_data_loader(testdatapath)
auc001 = test_model(pos_test, device, model, modelpath='015', usegpu=use_gpu)
- 1
- 2
- 3
- 4
- 5
- 6
nn.BatchNorm2d()使用
nn.Conv2d(1, 20, kernel_size=(1, 3)),
nn.BatchNorm2d(20),
- 1
- 2
- 3
在卷积神经网络的卷积层之后总会添加BatchNorm2d进行数据的归一化处理,这使得数据在进行Relu之前不会因为数据过大而导致网络性能的不稳定
下采样
neg_data2 = loadmat(path + 'neg_bags2.mat')['neg_bags']
neg_data_tmp = []
for i in range(neg_data2.shape[1]//25):
tmp = neg_data2[:, i * 25:i * 25 + 25]
tmp = np.reshape(tmp, (len(tmp), 25))
# 下采样(采样数是试出来的)
if i % 1 == 0:
neg_data_tmp.append(tmp)
neg_data2 = neg_data_tmp
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
输出多个变量
print('Epoch: [{}][{}/{}]\t'
'Time {:.3f} ({:.3f})\t'
'Data {:.3f} ({:.3f})\t'
'Loss_ce {:.3f} ({:.3f})\t'
'Loss_tr {:.3f} ({:.3f})\t'
'Prec {:.2%} ({:.2%})'
.format(epoch, i + 1, train_iters,
batch_time.val, batch_time.avg,
data_time.val, data_time.avg,
losses_ce.val, losses_ce.avg,
losses_tr.val, losses_tr.avg,
precisions.val, precisions.avg))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
或者
print(f'epoch {epoch} loss : {epoch_loss}')
- 1
对不需要的文件进行批量删除
''' @Date :2022/1/20 10:03 @Author :ljm @File :delet.py 对不需要的文件进行批量删除 ''' from os import listdir import os def delete(path,num): datasetList = listdir(path) print(datasetList) datasetLength = len(datasetList) # 文件夹中文件数量 for i in range(datasetLength): filename = datasetList[i] # 获取文件名字符串 (filenametmp, extension) = os.path.splitext(filename) classOrder = filenametmp.split('-')[-1] # 以 - 分割提取类别号 if float(classOrder) < num: os.remove(path+'\\'+filename) if __name__ == '__main__': path = r'results-valid-test\results-faux\res-model' num = 0.4 delete(path,num)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24

