
热门标签
热门文章
- 1在 Linux 下搭建 Git 服务器_linux git 服务器
- 2《Python工匠》学习笔记----第四章:条件分支控制流_第四课 条件分支控制流
- 3人间词话_死人又生性,也是一生似乎钱
- 4关于YOLOv5的训练,GPU单卡、多卡设置,加速训练_yolov5 多卡训练
- 5游戏攻略网站设计与实现 毕业设计-附源码96153_关于游戏攻略毕业设计
- 6C语言 AF_UNIX tcp/udp socket实例_udp af unix
- 7商密圈大咖齐聚北京 共商国密开源未来发展方向_openssl 3.0 sm2
- 8基于springboot+vue的家政服务系统(前后端分离)_基于springboot vue家政服务预约平台系统
- 9TCP 连接的建立 & 断开
- 10LLDB(二):基础命令详解_lldb attach
当前位置: article > 正文
【机器学习】k-means_kmeans数据集
作者:从前慢现在也慢 | 2024-02-22 07:18:45
赞
踩
kmeans数据集
一、非监督学习(unsupervised learning)K-means
1)从原始数据到聚类完毕的数据:

2)聚类流程示意图:
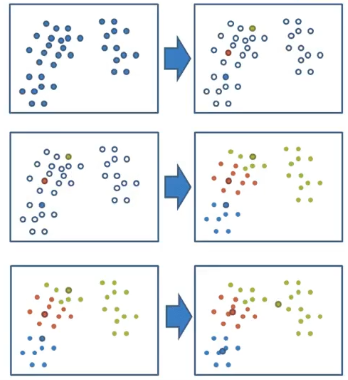
二、k-means步骤
1、随机设置K个特征空间内的点作为初始的聚类中心
2、对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
3、接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
4、如果计算得出的新中心点与原中心点一样,那么结束,否则重新进行第二部过程
三、k-means API
● sklean.cluster.KMeans(n_clusters=8,init='k-means++')
● k-means聚类
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/从前慢现在也慢/article/detail/129062
推荐阅读
相关标签

