
- 1sha256加密_【总结】基于 FPGA 的 SHA256 高效数字加密研究(五)
- 2OpenCV直方图均衡化
- 3智公网:公务员行测基础考点
- 4Day17_集合与数据结构(链表,栈和队列,Map,Collections工具类,二叉树,哈希表)
- 5CVPR2022论文列表(中英对照)
- 6【unity3D】Transform组件(如何访问和获取Transform组件)_unity 获得transform
- 7用HTML5和JavaScript实现黑客帝国风格的字符雨效果
- 8Pytorch 训练与测试时爆显存(out of memory)的一个解决方案_pytorch 缓存
- 9MySQL5.7精简操作_mysql share目录精简
- 10Linux内核链表之list_head_linux list_head
通用NER数据集JSON格式转换大全_ner数据集格式
赞
踩
通用NER数据集JSON格式转换大全
前言
最近在做和大模型通用抽取相关的任务,需要将所有数据集转换为相同的格式,便于构建指令微调数据集。在处理数据时需要将不同格式的NER数据集转换为方便处理的json格式数据,这是一项非常繁杂的工作。在NER领域,没有一个统一的格式规范,博主收集了近30份NER数据集,总结出常见的NER数据集格式包括BIO、BIEO、excel格式的BIO、数据标签分离、内嵌式json等,每种格式可能只有两三个数据集,如果单独为其进行编码需要耗费不少精力,拖慢工作进度。虽然在github上有不少开源的已经处理为json格式的数据集,但是这并不能覆盖所有的NER数据集,授人以鱼不如授人以渔,本文将总结NER领域常见的数据集格式,并提供数据集转换为json格式的代码,以供读者自取,此外,已经处理好的数据集可以在这里下载,如果对您有帮助,烦请点赞鼓励一下博主~
1. NER数据集概述
NER领域数据集种类繁多,常见的数据集格式如下表所示:
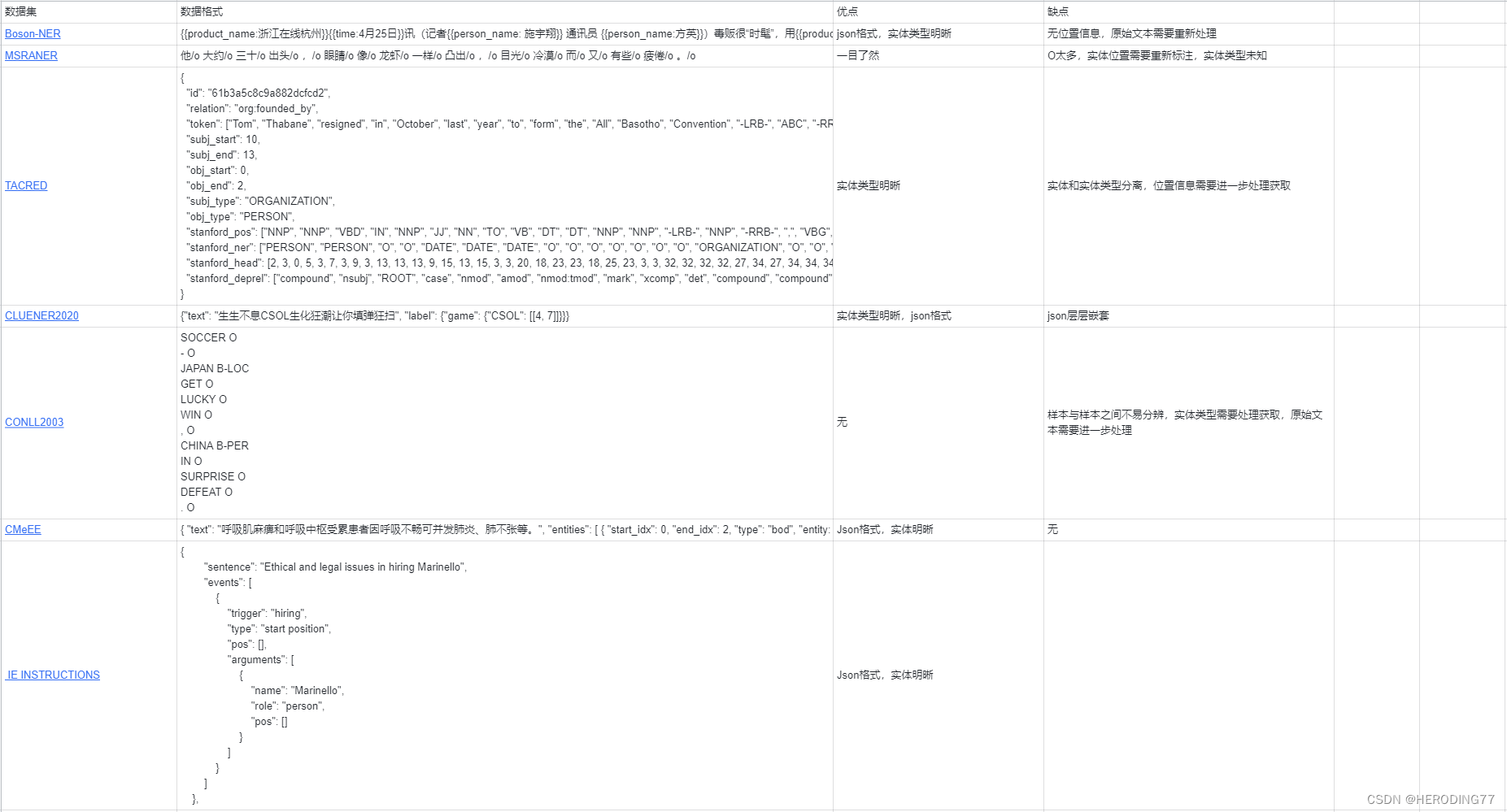
这里我先分析一下不同数据集格式的利弊,以及我选择json格式的理由。
1.1 内嵌json
首先是内嵌json的代表Boson-NER数据集,将实体信息标注在正文中,虽然实体类型非常明晰,但是没有标注位置信息,并且对于一个样本,无法知道有多少个实体类型,难以从外部直接获取。
1.2 BIO
BIO的种类还可以再细分,一个是txt文件中,一行只有一个token,一个token后面跟着其类型,整体内容需要竖向阅读,另一种形式是在原始的文本基础上在每个token后面加上实体类型,这样的类型更容易阅读,只不过处理起来更为复杂。
1.3 分层json
分层json格式比较符合最后需要统一处理的格式,每个样本由一对大括号嵌套,里面包括text内容和标签内容,但是标签、mention、位置信息层层嵌套,不方便提取。
1.4 BIEO
BIEO的格式和BIO的格式类似,只不过多了一个end的特殊符号,在进行处理时需要单独考虑特殊字符。
1.5 数据标签分离
数据标签分离的数据格式观感最差,既不能直接看出实体,也获取不到实体位置的信息,但是它的好处是处理起来比较方便,只需要对照两个文件的相应位置就可以提取出相应的实体和位置信息。
1.6 标准json
这里的标准是我将最终转换为的json数据格式类型,以下面的数据样本为例:

可以看到每个样本包括sentence和实体集合,sentence是样本的内容,实体集合中包含每个实体的mention,类型以及位置信息,这样的数据格式是我认为最好处理的格式,也是本篇博客中代码所处理成的格式。
2. BIO_to_JSON
原始数据类型:
相 O
比 O
之 O
下 O
, O
青 B-ORG
岛 I-ORG
海 I-ORG
牛 I-ORG
队 I-ORG
和 O
广 B-ORG
州 I-ORG
松 I-ORG
日 I-ORG
队 I-ORG
的 O
雨 O
中 O
之 O
战 O
虽 O
然 O
也 O
是 O
0 O
∶ O
0 O
, O
但 O
乏 O
善 O
可 O
陈 O
。 O
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
代码:
import json
import sys
import os
sys.path.append("..")
def bio_to_json(input_files, output_files, label_output_file):
label_set = set()
for input_file, output_file in zip(input_files, output_files):
data = []
with open(input_file, 'r', encoding='utf-8', errors='ignore') as f:
lines = f.readlines()
sentence = ""
entities = []
entity_name = ""
entity_type = ""
start_position = 0
for line in lines:
if line == '\n':
# if there's an entity already being processed, append it to entities
if entity_name:
entities.append({'name': entity_name, 'type': entity_type, 'pos': [start_position, start_position + len(entity_name)]})
entity_name = ""
entity_type = ""
# append the processed sentence to data
data.append({'sentence': sentence, 'entities': entities})
sentence = ""
entities = []
else:
print(line)
word, tag = line.rstrip('\n').split(' ')
if tag.startswith('B'):
# if there's an entity already being processed, append it to entities
if entity_name:
entities.append({'name': entity_name, 'type': entity_type, 'pos': [start_position, start_position + len(entity_name)]})
entity_name = word
entity_type = tag.split('-')[1]
label_set.add(entity_type) # add this entity type to the set
start_position = len(sentence)
elif tag.startswith('I'):
entity_name += word
else:
# if there's an entity already being processed, append it to entities
if entity_name:
entities.append({'name': entity_name, 'type': entity_type, 'pos': [start_position, start_position + len(entity_name)]})
entity_name = ""
entity_type = ""
sentence += word
# for the last entity of the last sentence
if entity_name:
entities.append({'name': entity_name, 'type': entity_type, 'pos': [start_position, start_position + len(entity_name)]})
if sentence:
data.append({'sentence': sentence, 'entities': entities})
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
with open(label_output_file, 'w', encoding='utf-8') as f:
json.dump(list(label_set), f, ensure_ascii=False, indent=4)
currPath = os.path.join("datasets", "Weibo")
input_files = [os.path.join(currPath, "train.txt"), os.path.join(currPath, "test.txt"), os.path.join(currPath, "dev.txt")]
output_files = [os.path.join(currPath, "train.json"), os.path.join(currPath, "test.json"), os.path.join(currPath, "dev.json")]
label_output_file = os.path.join(currPath, "label.json")
bio_to_json(input_files, output_files, label_output_file)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
生成json格式:
{
"sentence": "相比之下,青岛海牛队和广州松日队的雨中之战虽然也是0∶0,但乏善可陈。",
"entities": [
{
"name": "青岛海牛队",
"type": "机构",
"pos": [
5,
10
]
},
{
"name": "广州松日队",
"type": "机构",
"pos": [
11,
16
]
}
]
},
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
3. BIEO_to_JSON
原始数据类型:
中 B-GPE
国 E-GPE
将 O
加 O
快 O
人 O
才 O
市 O
场 O
体 O
系 O
建 O
设 O
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
代码:
import json
def bieo_to_json(input_files, output_files, label_output_file):
num = 0
label_set = set()
for input_file, output_file in zip(input_files, output_files):
data = []
with open(input_file, 'r', encoding='utf-8') as f:
lines = f.readlines()
sentence = ""
entities = []
entity_name = ""
entity_type = ""
start_position = 0
for line in lines:
if line == '\n':
# if there's an entity already being processed, append it to entities
if entity_name:
entities.append({'name': entity_name, 'type': entity_type, 'pos': [start_position, start_position + len(entity_name)]})
entity_name = ""
entity_type = ""
# append the processed sentence to data
data.append({'sentence': sentence, 'entities': entities})
num += 1
sentence = ""
entities = []
else:
word, mid, tag = line.rstrip('\n').split(' ')
if tag.startswith('B'):
entity_name = word
entity_type = tag.split('-')[1]
label_set.add(entity_type) # add this entity type to the set
start_position = len(sentence)
elif tag.startswith('I'):
entity_name += word
elif tag.startswith('E'):
entity_name += word
entities.append({'name': entity_name, 'type': entity_type, 'pos': [start_position, start_position + len(entity_name)]})
entity_name = ""
entity_type = ""
elif tag.startswith('S'):
entity_name = word
entity_type = tag.split('-')[1]
label_set.add(entity_type) # add this entity type to the set
start_position = len(sentence)
entities.append({'name': entity_name, 'type': entity_type, 'pos': [start_position, start_position + len(entity_name)]})
entity_name = ""
entity_type = ""
else:
# if there's an entity already being processed, append it to entities
if entity_name:
entities.append({'name': entity_name, 'type': entity_type, 'pos': [start_position, start_position + len(entity_name)]})
entity_name = ""
entity_type = ""
sentence += word
# for the last entity of the last sentence
if entity_name:
entities.append({'name': entity_name, 'type': entity_type, 'pos': [start_position, start_position + len(entity_name)]})
if sentence:
data.append({'sentence': sentence, 'entities': entities})
num += 1
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
with open(label_output_file, 'w', encoding='utf-8') as f:
json.dump(list(label_set), f, ensure_ascii=False, indent=4)
print(num)
import sys
import os
sys.path.append("..")
currPath = os.path.join( "datasets", "CCKS2017-NER")
input_files = [os.path.join(currPath, "train.txt"), os.path.join(currPath, "test.txt")]
output_files = [os.path.join(currPath, "train.json"), os.path.join(currPath, "test.json")]
label_output_file = os.path.join(currPath, "label.json")
bieo_to_json(input_files, output_files, label_output_file)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
生成json格式:
{
"sentence": "中国将加快人才市场体系建设。",
"entities": [
{
"name": "中国",
"type": "国家",
"pos": [
0,
2
]
}
]
},
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
4. BMEO_to_JSON
原始数据类型:
高 B-NAME
勇 E-NAME
: O
男 O
, O
中 B-CONT
国 M-CONT
国 M-CONT
籍 E-CONT
, O
无 O
境 O
外 O
居 O
留 O
权 O
, O
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
代码:
import json
import sys
import os
sys.path.append("..")
def bmeo_to_json(input_files, output_files, label_output_file):
label_set = set()
for input_file, output_file in zip(input_files, output_files):
data = []
with open(input_file, 'r', encoding='utf-8') as f:
lines = f.readlines()
sentence = ""
entities = []
entity_name = ""
entity_type = ""
start_position = 0
for line in lines:
if line == '\n':
# if there's an entity already being processed, append it to entities
if entity_name:
entities.append({'name': entity_name, 'type': entity_type, 'pos': [start_position, start_position + len(entity_name)]})
entity_name = ""
entity_type = ""
# append the processed sentence to data
data.append({'sentence': sentence, 'entities': entities})
sentence = ""
entities = []
else:
word, tag = line.rstrip('\n').split(' ')
if tag.startswith('B'):
entity_name = word
entity_type = tag.split('-')[1]
label_set.add(entity_type) # add this entity type to the set
start_position = len(sentence)
elif tag.startswith('M'):
entity_name += word
elif tag.startswith('E'):
entity_name += word
entities.append({'name': entity_name, 'type': entity_type, 'pos': [start_position, start_position + len(entity_name)]})
entity_name = ""
entity_type = ""
elif tag.startswith('S'):
entity_name = word
entity_type = tag.split('-')[1]
label_set.add(entity_type) # add this entity type to the set
start_position = len(sentence)
entities.append({'name': entity_name, 'type': entity_type, 'pos': [start_position, start_position + len(entity_name)]})
entity_name = ""
entity_type = ""
else:
# if there's an entity already being processed, append it to entities
if entity_name:
entities.append({'name': entity_name, 'type': entity_type, 'pos': [start_position, start_position + len(entity_name)]})
entity_name = ""
entity_type = ""
sentence += word
# for the last entity of the last sentence
if entity_name:
entities.append({'name': entity_name, 'type': entity_type, 'pos': [start_position, start_position + len(entity_name)]})
if sentence:
data.append({'sentence': sentence, 'entities': entities})
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
with open(label_output_file, 'w', encoding='utf-8') as f:
json.dump(list(label_set), f, ensure_ascii=False, indent=4)
currPath = os.path.join( "datasets", "简历-NER")
input_files = [os.path.join(currPath, "train.txt"), os.path.join(currPath, "test.txt"), os.path.join(currPath, "dev.txt")]
output_files = [os.path.join(currPath, "train.json"), os.path.join(currPath, "test.json"), os.path.join(currPath, "dev.json")]
label_output_file = os.path.join(currPath, "label.json")
bmeo_to_json(input_files, output_files, label_output_file)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
生成json格式:
{
"sentence": "高勇:男,中国国籍,无境外居留权,",
"entities": [
{
"name": "高勇",
"type": "姓名",
"pos": [
0,
2
]
},
{
"name": "中国国籍",
"type": "国籍",
"pos": [
5,
9
]
}
]
},
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
5. D_BIO_JSON
原始数据类型:
交行14年用过,半年准备提额,却直接被降到1K,半年期间只T过一次三千,其它全部真实消费,第六个月的时候为了增加评分提额,还特意分期两万,但降额后电话投诉,申请提...
B-BANK I-BANK O O O O O O O O O O B-COMMENTS_N I-COMMENTS_N O O O O O B-COMMENTS_ADJ I-COMMENTS_ADJ O O O O O O O O O O O O O O O O O O O O O B-COMMENTS_N I-COMMENTS_N O O O O O O O O O O B-COMMENTS_N I-COMMENTS_N O O B-COMMENTS_N I-COMMENTS_N O O O O B-PRODUCT I-PRODUCT O O O O B-COMMENTS_ADJ O O O O O O O O O O O O O
- 1
- 2
代码:
import json
import os
import sys
sys.path.append("..")
def d_bio_to_json(text_file, label_file, output_file, output_label_file):
with open(text_file, 'r', encoding='utf-8') as f_text, open(label_file, 'r', encoding='utf-8') as f_label:
texts = f_text.read().splitlines()
labels = f_label.read().splitlines()
num = 0
data = []
label_set = set()
for text, label in zip(texts, labels):
entities = []
entity = None
start_idx = None
tokens = text.split()
tags = label.split()
for i, (token, tag) in enumerate(zip(tokens, tags)):
if tag.startswith('B'):
if entity is not None:
entities.append(entity)
entity = {
"name": token,
"type": tag[2:],
"pos": [i, i + 1]
}
start_idx = i
label_set.add(tag[2:])
elif tag.startswith('I'):
if entity is None:
entity = {
"name": token,
"type": tag[2:],
"pos": [i, i + 1]
}
start_idx = i
label_set.add(tag[2:])
else:
entity["name"] += token
entity["pos"][1] = i + 1
elif tag == 'O':
if entity is not None:
entities.append(entity)
entity = None
if entity is not None:
entities.append(entity)
sentence = ''.join(tokens) # 去除空格
data.append({
"sentence": sentence,
"entities": entities
})
num += 1
with open(output_file, 'w', encoding='utf-8') as f_out:
json.dump(data, f_out, ensure_ascii=False, indent=4)
with open(output_label_file, 'w', encoding='utf-8') as f_label:
json.dump(list(label_set), f_label, ensure_ascii=False, indent=4)
print(num)
currPath = os.path.join( "datasets", "人民日报2014")
text_file = os.path.join(currPath, "source.txt")
label_file = os.path.join(currPath, "target.txt")
output_file = os.path.join(currPath, "train.json")
output_label_file = os.path.join(currPath, "label.json")
d_bio_to_json(text_file, label_file, output_file, output_label_file)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
生成json格式:
{
"sentence": "交行14年用过,半年准备提额,却直接被降到1K,半年期间只T过一次三千,其它全部真实消费,第六个月的时候为了增加评分提额,还特意分期两万,但降额后电话投诉,申请提...",
"entities": [
{
"name": "交行",
"type": "银行",
"pos": [
0,
2
]
},
{
"name": "提额",
"type": "金融操作",
"pos": [
12,
14
]
},
{
"name": "降到",
"type": "形容词",
"pos": [
19,
21
]
},
{
"name": "消费",
"type": "金融操作",
"pos": [
42,
44
]
},
{
"name": "增加",
"type": "金融操作",
"pos": [
54,
56
]
},
{
"name": "提额",
"type": "金融操作",
"pos": [
58,
60
]
},
{
"name": "分期",
"type": "产品",
"pos": [
64,
66
]
},
{
"name": "降",
"type": "形容词",
"pos": [
70,
71
]
}
]
},
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
6. BIO_JSON_to_JSON
原始数据类型:
{"text": "来一首周华健的花心", "labels": ["O", "O", "O", "B-singer", "I-singer", "I-singer", "O", "B-song", "I-song"]}
- 1
代码:
import json
def bio_json_to_json(input_file, output_file, label_file):
num = 0
label_set = set()
with open(input_file, 'r', encoding='utf-8') as f:
data = f.read().splitlines()
converted_data = []
for sample in data:
sample = json.loads(sample)
sentence = sample['text']
labels = sample['labels']
entities = []
entity_name = ""
entity_start = None
entity_type = None
for i, label in enumerate(labels):
if label.startswith('B-'):
if entity_name:
entities.append({
'name': entity_name,
'type': entity_type,
'pos': [entity_start, i]
})
label_set.add(entity_type)
entity_name = sentence[i]
entity_start = i
entity_type = label[2:]
elif label.startswith('I-'):
if entity_name:
entity_name += sentence[i]
else:
if entity_name:
entities.append({
'name': entity_name,
'type': entity_type,
'pos': [entity_start, i]
})
label_set.add(entity_type)
entity_name = ""
entity_start = None
entity_type = None
if entity_name:
entities.append({
'name': entity_name,
'type': entity_type,
'pos': [entity_start, len(labels)]
})
label_set.add(entity_type)
converted_data.append({
'sentence': sentence,
'entities': entities
})
num += 1
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(converted_data, f, ensure_ascii=False, indent=2)
with open(label_file, 'w', encoding='utf-8') as f_label:
json.dump(list(label_set), f_label, ensure_ascii=False, indent=4)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
生成json格式:
{
"sentence": "来一首周华健的花心",
"entities": [
{
"name": "周华健",
"type": "歌手",
"pos": [
3,
6
]
},
{
"name": "花心",
"type": "歌曲",
"pos": [
7,
9
]
}
]
},
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
7. JSON_to_JSON
原始数据类型:
{ "text": "呼吸肌麻痹和呼吸中枢受累患者因呼吸不畅可并发肺炎、肺不张等。", "entities": [ { "start_idx": 0, "end_idx": 2, "type": "bod", "entity: "呼吸肌" }, { "start_idx": 0, "end_idx": 4, "type": "sym", "entity: "呼吸肌麻痹" }, { "start_idx": 6, "end_idx": 9, "type": "bod", "entity: "呼吸中枢" }, { "start_idx": 6, "end_idx": 11, "type": "sym", "entity: "呼吸中枢受累" }, { "start_idx": 15, "end_idx": 18, "type": "sym", "entity: "呼吸不畅" }, { "start_idx": 22, "end_idx": 23, "type": "dis", "entity: "肺炎" }, { "start_idx": 25, "end_idx": 27, "type": "dis", "entity: "肺不张" } ] }
- 1
代码:
import json
import os
import sys
sys.path.append("..")
def json_to_json(input_files, output_files, label_output_file):
label_set = set()
for input_file, output_file in zip(input_files, output_files):
with open(input_file, 'r', encoding='utf-8') as f_in:
data = json.load(f_in)
converted_data = []
for item in data:
sentence = item['text']
entities = []
for entity in item['entities']:
start_idx = entity['start_idx']
end_idx = entity['end_idx']
entity_type = entity['type']
entity_name = entity['entity']
entities.append({
'name': entity_name,
'type': entity_type,
'pos': [start_idx, end_idx]
})
label_set.add(entity_type)
converted_data.append({
'sentence': sentence,
'entities': entities
})
with open(output_file, 'w', encoding='utf-8') as f_out:
json.dump(converted_data, f_out, ensure_ascii=False, indent=4)
with open(label_output_file, 'w', encoding='utf-8') as f_label:
json.dump(list(label_set), f_label, ensure_ascii=False, indent=4)
currPath = os.path.join( "datasets", "CMeEE-V2")
input_files = [os.path.join(currPath, "CMeEE-V2_train.json"), os.path.join(currPath, "CMeEE-V2_test.json"), os.path.join(currPath, "CMeEE-V2_dev.json")]
output_files = [os.path.join(currPath, "train.json"), os.path.join(currPath, "test.json"), os.path.join(currPath, "dev.json")]
label_output_file = os.path.join(currPath, "label.json")
json_to_json(input_files, output_files, label_output_file)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
生成json格式:
{
"sentence": "呼吸肌麻痹和呼吸中枢受累患者因呼吸不畅可并发肺炎、肺不张等。",
"entities": [
{
"name": "呼吸肌麻痹",
"type": "疾病",
"pos": [
0,
5
]
},
{
"name": "呼吸中枢",
"type": "部位",
"pos": [
6,
10
]
},
{
"name": "呼吸中枢受累",
"type": "症状",
"pos": [
6,
12
]
},
{
"name": "呼吸不畅",
"type": "症状",
"pos": [
15,
19
]
},
{
"name": "肺炎",
"type": "疾病",
"pos": [
22,
24
]
},
{
"name": "肺不张",
"type": "疾病",
"pos": [
25,
28
]
}
]
},
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
8. JSON_to_JSON
原始数据类型:
{"text": "生生不息CSOL生化狂潮让你填弹狂扫", "label": {"game": {"CSOL": [[4, 7]]}}}
- 1
代码:
import json
def nested_json_to_json(input_files, output_files, label_output_file):
num = 0
label_set = set()
for input_file, output_file in zip(input_files, output_files):
with open(input_file, 'r', encoding='utf-8') as f_in:
data = f_in.read().splitlines()
converted_data = []
for item in data:
item = json.loads(item)
sentence = item['text']
entities = []
for label, entity in item['label'].items():
entity_type = label
entity_name = list(entity.keys())[0]
start_idx = list(entity.values())[0][0][0]
end_idx = list(entity.values())[0][0][1]
entities.append({
'name': entity_name,
'type': entity_type,
'pos': [start_idx, end_idx]
})
label_set.add(entity_type)
converted_data.append({
'sentence': sentence,
'entities': entities
})
num += 1
with open(output_file, 'w', encoding='utf-8') as f_out:
json.dump(converted_data, f_out, ensure_ascii=False, indent=4)
with open(label_output_file, 'w', encoding='utf-8') as f_label:
json.dump(list(label_set), f_label, ensure_ascii=False, indent=4)
print(num)
import os
import sys
sys.path.append("..")
currPath = os.path.join( "datasets", "CLUENER")
input_files = [os.path.join(currPath, "CLUENER_train.json"),os.path.join(currPath, "CLUENER_dev.json")]
output_files = [os.path.join(currPath, "train.json"), os.path.join(currPath, "dev.json")]
label_output_file = os.path.join(currPath, "label.json")
nested_json_to_json(input_files, output_files, label_output_file)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
生成json格式:
{
"sentence": "生生不息CSOL生化狂潮让你填弹狂扫",
"entities": [
{
"name": "CSOL",
"type": "游戏",
"pos": [
4,
7
]
}
]
},
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
总结
算是NER领域比较全面的数据集格式转换文章,几乎所有的数据集都可以使用上面的代码轮子进行格式转换,可能会有一些特殊标签,比如BIO中"B-“格式可能为"B_”,或者token与标签之间不是空格分隔的,只需要简单修改一下代码就可以解决,希望本篇博客能够对读者有所帮助,如果有补充的数据格式,也欢迎联系博主~

