
- 1防止表单重复提交 方法汇总_利用session防止表单重复提交
- 2vs2017工具箱问题(不见工具箱选项卡&此组中没有可用控件&控件灰化)_此组中没有可用的控件
- 3TypeError: ***() got an unexpected keyword argument ‘***‘ self._target(*self._args, **self._kwargs)_typeerror: draw_wrapper() got an unexpected keywor
- 4vue实现轮播图效果_vue轮播图怎么实现
- 5SpringBoot简单使用笔记_springboot exclusion
- 6【一个理想主义者的创业故事之浅谈为什么要学习C++】_一个理想主义者创业者的故事
- 7PCB模块化设计04——USB-Type-C PCB布局布线设计规范_usb c接口 封装
- 8Helix3DToolkit.Wpf.SharpDX学习(一)_helixtoolkit.wpf.sharpdx
- 9震惊:苹果手机电池栏“黑白无常”
- 10uniapp应用生命周期 onLaunch 方法改同步,再调用页面生命周期_vue onlaunch
AI图像(AIGC for PIC)大模型实战|Stable Diffusion_图像大模型
赞
踩
AI GC text to pic 图像生成模型
目前随着AIGC模型的火爆,AI内容创作远超人类创造水平和能力,极大了提升了创作空间。
为此我们要接触新鲜事物,用于尝试新技术。
那针对目前火爆的AImodel我们开始进行学习,尝试本地化部署,生成自己的模型。
先感性的认识下模型的基础知识。
一、AI模型的基本介绍
什么时大模型/底模型,VAE模型和微调模型/fune tuning
大模型/底模型:Stable diffusion:V1.4/v1.5/v2.0/v2.1都是大模型,泛化性通用性好,大模型自带VAE模型,不额外挂在
VAE模型:图形生产的最后为我们解码成可是图形的必备模型,有些大模型会内嵌
微调模型:在大模型基础山的微调模型,可选的,可以特定生产图像
LoRA/Embedding/Hypernetwork:是特定领域图形的微调模型
Dreambooth:是训练后的大模型
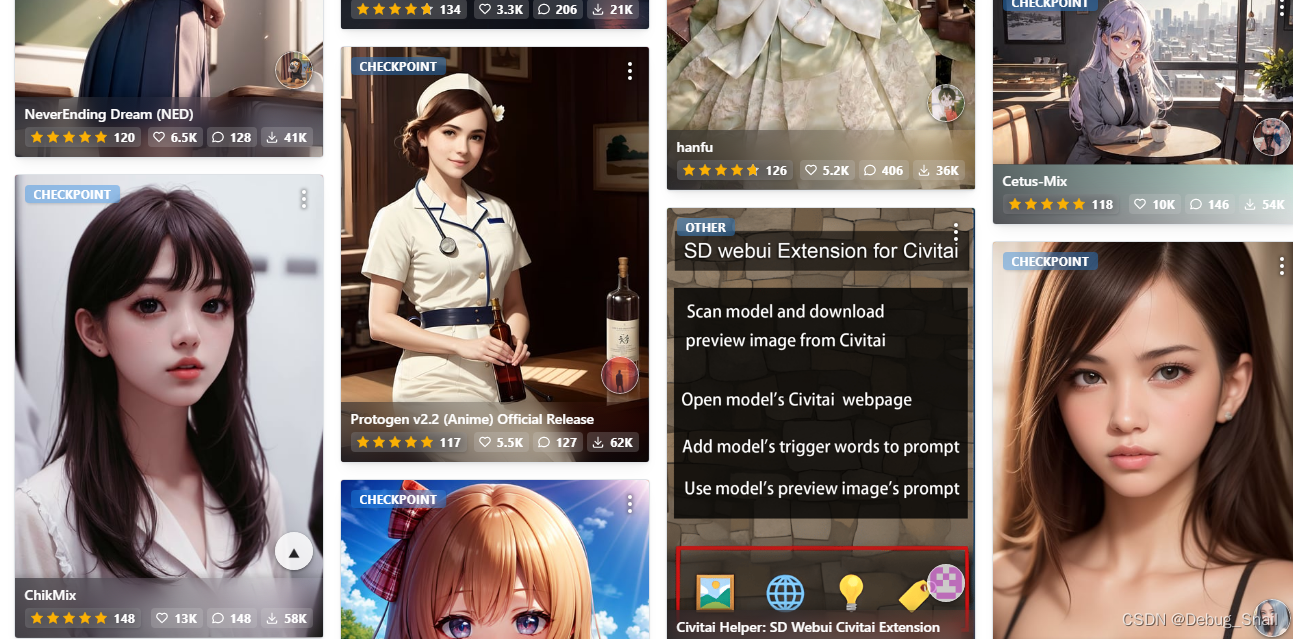
Checkpoint: 模型是某一特定训练后保存参数的模型,某一阶段的模型版本
即checkpoint = 大模型= dreambooth
二、模型后缀
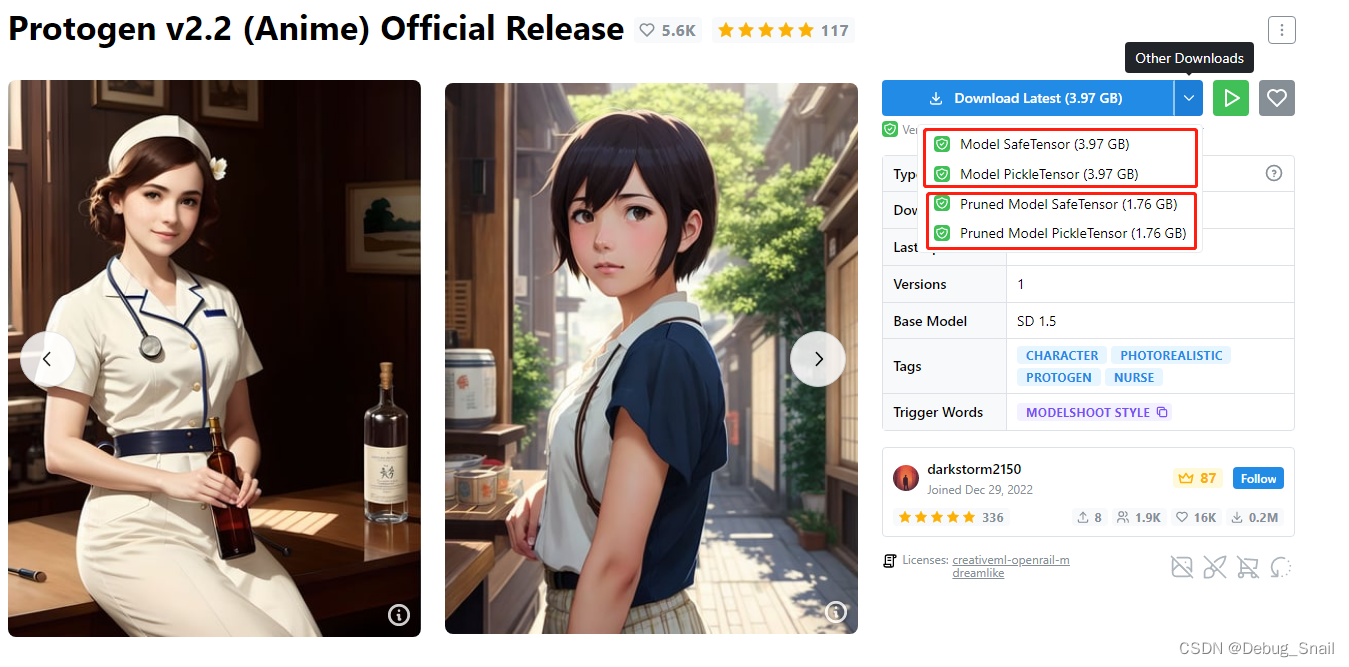
safetensor.以.safetensors为后缀,加载速度快,更加安全
pickletensor以.ckpt为后缀,开源,但可能存在恶意代码,加载速度相对较慢
pruned:剪枝模型,存储小,效率搞,优化后的神经网络
ema:泛化能力强,优化后的神经网络模型
ft/fp: ft16/ft32标识模型精度,推荐ft32
三、stable difussion webui
ComfyUI:https://github.com/comfyanonymous/ComfyUI

